
Lernpfad
Dateningenieur in Python
40 Std.
In einem technischen Interview fangen die Interviewer in der Regel einfach an und konzentrieren sich auf die Grundlagen des Airflow-Frameworks und die Kernkonzepte, bevor sie zu komplexeren und technischen Fragen übergehen.
Achte bei der Beantwortung dieser Fragen darauf, dass du nicht nur technische Details besprichst, sondern auch erwähnst, wie das Ganze in einen Data-Engineering- und/oder Unternehmensdaten-Workflow eingebunden werden kann.
Antwort: Apache Airflow ist ein Open-Source-Tool zur Datenorchestrierung , mit dem Datenexperten mit Hilfe von Python programmatisch Datenpipelines definieren können. Airflow wird vor allem von Data-Engineering-Teams eingesetzt, um ihr Datenökosystem zu integrieren und Daten zu extrahieren, zu transformieren und zu laden.
Erzähl mir mehr: Airflow wird unter der Apache-Software-Lizenz verwaltet (daher das vorangestellte "Apache").
Ein Datenorchestrierungstool bietet Funktionen, mit denen mehrere Quellen und Dienste in eine einzige Pipeline integriert werden können.
Was Airflow als Datenorchestrierungstool auszeichnet, ist die Verwendung von Python zur Definition von Datenpipelines, die ein Maß an Erweiterbarkeit und Kontrolle bietet, das andere Datenorchestrierungstools nicht bieten. Airflow verfügt über eine Reihe integrierter und von Anbietern unterstützter Tools zur Integration des Datenstapels eines jeden Teams sowie über die Möglichkeit, eigene Tools zu entwickeln.
Weitere Informationen zu den ersten Schritten mit Airflow findest du in diesem DataCamp-Tutorial: Erste Schritte mit Apache Airflow. Wenn du noch tiefer in die Welt der Datenorchestrierung mit Airflow eintauchen willst, ist der Kurs Einführung in Airflow der beste Startpunkt für dich.
Antwort: Ein DAG, oder ein gerichteter azyklischer Graph, ist eine Sammlung von Aufgaben und Beziehungen zwischen diesen Aufgaben. Eine DAG hat einen klaren Anfang und ein klares Ende und hat keine "Zyklen" zwischen diesen Aufgaben. Bei der Verwendung von Airflow wird häufig der Begriff "DAG" verwendet, der in der Regel mit einer Datenpipeline gleichgesetzt werden kann.
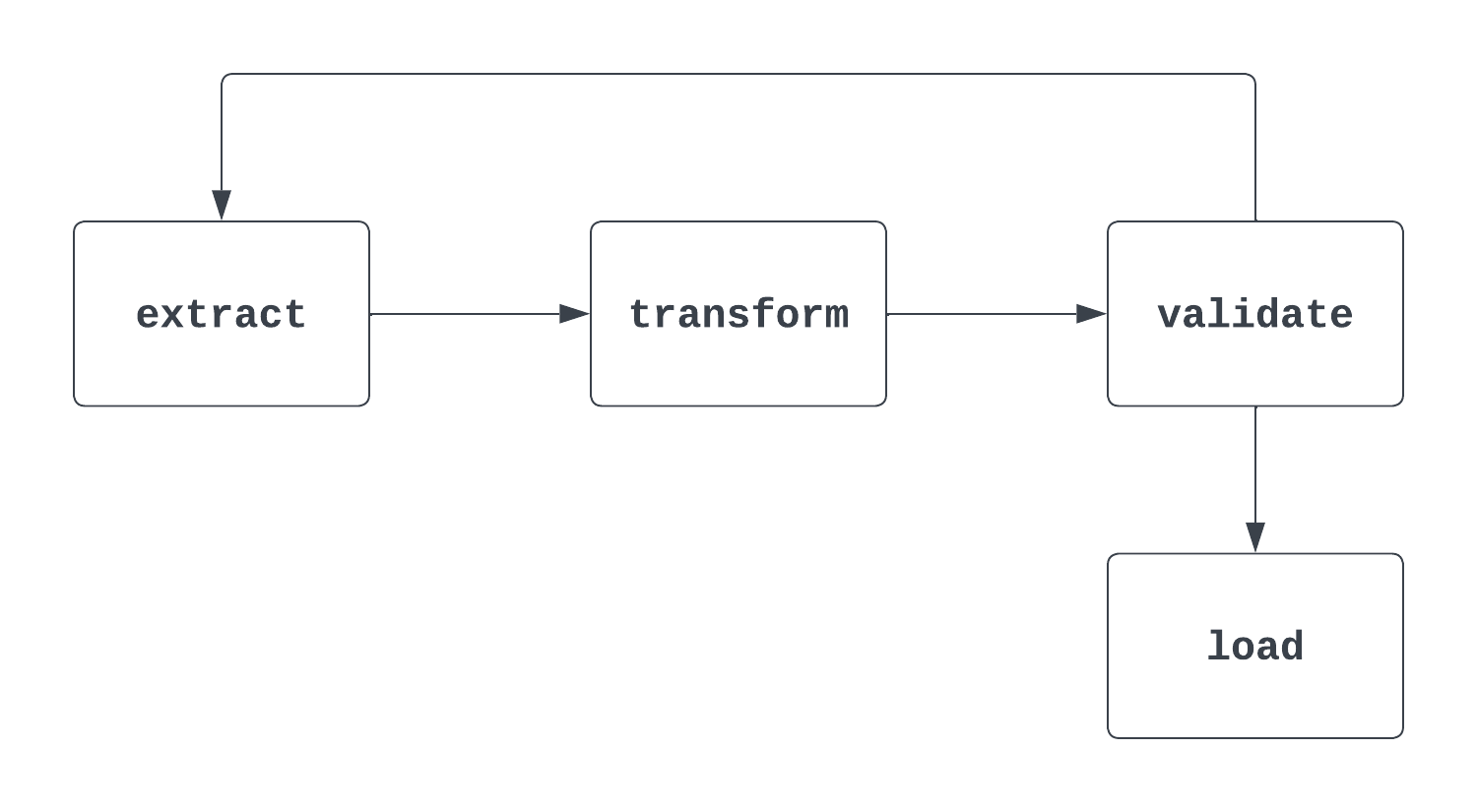
Erzähl mir mehr: Das ist eine knifflige Frage. Wenn ein Interviewer diese Frage stellt, ist es wichtig, sowohl auf die formale "mathematische" Definition einer DAG einzugehen als auch darauf, wie sie in Airflow verwendet wird. Wenn du über DAGs nachdenkst, hilft es, einen Blick auf eine Grafik zu werfen. Das erste Bild unten ist in der Tat ein DAG. Es hat einen klaren Anfang und ein Ende und keine Zyklen zwischen den Aufgaben.

Der zweite unten gezeigte Prozess ist KEINE DAG. Es gibt zwar eine klare Startaufgabe, aber es gibt einen Zyklus zwischen den Extraktions- und Validierungsaufgaben, so dass nicht klar ist, wann die Ladeaufgabe ausgelöst werden kann.
Antwort: Um eine DAG zu definieren, müssen eine ID, ein Startdatum und ein Zeitplanintervall angegeben werden.
Erzähl mir mehr: Die ID identifiziert die DAG eindeutig und ist in der Regel eine kurze Zeichenkette, z. B. "sample_da.". Das Startdatum ist das Datum und die Uhrzeit des ersten Intervalls, in dem eine DAG ausgelöst wird.
Dies ist ein Zeitstempel, d.h. es werden Jahr, Monat, Tag, Stunde und Minute genau angegeben. Das Zeitintervall gibt an, wie oft die DAG ausgeführt werden soll. Das kann jede Woche, jeden Tag, jede Stunde oder auch etwas individueller sein.
In diesem Beispiel wurde die DAG mit einer dag_id von "sample_dag" definiert. Die Funktion datetime aus der Bibliothek datetime wird verwendet, um das Startdatum auf den 1. Januar 2024 um 9:00 Uhr zu setzen. Diese DAG wird täglich (um 9:00 Uhr) ausgeführt, so wie es das @daily geplante Intervall vorsieht. Weitere benutzerdefinierte Zeitintervalle können mit Cron-Ausdrücken oder der Funktion timedelta aus der Bibliothek datetime festgelegt werden.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Antwort: Airflow-Aufgaben sind die kleinste Ausführungseinheit im Airflow-Framework. Ein Task kapselt normalerweise eine einzelne Operation in einer Datenpipeline (DAG). Aufgaben sind die Bausteine für DAGs, und zwischen den Aufgaben innerhalb einer DAG gibt es Beziehungen, die bestimmen, in welcher Reihenfolge sie ausgeführt werden. Drei Beispiele für Aufgaben sind:
In einer ETL-Pipeline würden die Beziehungen folgendermaßen aussehen:
Erzähl mir mehr: Die Aufgaben können sehr allgemein oder sehr individuell sein. Airflow bietet zwei Möglichkeiten, diese Aufgaben zu definieren: traditionelle Operatoren und die TaskFlow-API (dazu später mehr).
Einer der Vorteile von Open Source ist der Beitrag der breiteren Community, die nicht nur aus einzelnen Mitwirkenden besteht, sondern auch aus Akteuren wie AWS, Databricks, Snowflake und vielen anderen.
Die Wahrscheinlichkeit ist groß, dass für die Aufgabe, die du definieren möchtest, bereits ein Airflow-Operator erstellt wurde. Wenn nicht, ist es ganz einfach, deine eigene zu erstellen. Ein paar Beispiele für Airflow-Operatoren sind SFTPToS3Operator, S3ToSnowflakeOperator und DatabricksRunNowOperator.
Antwort: Die Architektur von Airflow besteht aus vier Kernkomponenten: dem Scheduler, dem Executor, der Metadaten-Datenbank und dem Webserver.
Erzähl mir mehr: Der Scheduler prüft jede Minute das DAG-Verzeichnis und überwacht DAGs und Tasks, um alle Tasks zu identifizieren, die ausgelöst werden können. Ein Executor ist der Ort, an dem Aufgaben ausgeführt werden. Aufgaben können lokal (innerhalb des Schedulers) oder ferngesteuert (außerhalb des Schedulers) ausgeführt werden.
Der Executor ist der Ort, an dem die "Rechenarbeit", die jede Aufgabe erfordert, stattfindet. Die Metadaten-Datenbank enthält alle Informationen über die DAGs und Aufgaben, die mit dem Airflow-Projekt zusammenhängen, das du gerade ausführst. Dazu gehören Informationen wie historische Ausführungsdetails, Verbindungen, Variablen und eine Vielzahl anderer Informationen.
Der Webserver ermöglicht die Darstellung der Airflow-Benutzeroberfläche und die Interaktion mit ihr, wenn du DAGs entwickelst, mit ihnen interagierst und sie pflegst.
Dies ist nur ein kurzer Überblick über die Kernkomponenten der Airflow-Architektur.
Du hast deutlich gemacht, dass du die Grundlagen des Airflow-Frameworks und seiner Architektur kennst. Jetzt ist es an der Zeit, dein Wissen über das DAG-Authoring zu testen.
PythonOperator? Welche Voraussetzungen müssen erfüllt sein, um diesen Betreiber zu nutzen? Was ist ein Beispiel dafür, wann du die PythonOperator?Antwort: Die PythonOperator ist eine Funktion, mit der eine Python-Funktion als Airflow-Aufgabe ausgeführt werden kann. Um diesen Operator zu verwenden, muss eine Python-Funktion an den Parameter python_callable übergeben werden. Ein Beispiel, bei dem du einen Python-Operator verwenden solltest, ist der Zugriff auf eine API, um Daten zu extrahieren.
Erzähl mir mehr: Der PythonOperator ist einer der leistungsstärksten Antriebe von Airflow. Es ermöglicht nicht nur die Ausführung von benutzerdefiniertem Code innerhalb einer DAG, sondern die Ergebnisse können auch in XComs geschrieben und von nachgelagerten Aufgaben verwendet werden.
Durch die Übergabe eines Wörterbuchs an den Parameter op_kwargs können Schlüsselwortargumente an den Python-Callable übergeben werden, sodass zur Laufzeit noch mehr Anpassungen möglich sind. Neben op_kwargs gibt es eine Reihe von zusätzlichen Parametern, mit denen die Funktionalität von PythonOperator erweitert werden kann.
Nachfolgend findest du einen Beispielaufruf der PythonOperator. Normalerweise wird die Python-Funktion, die an python_callable übergeben wird, außerhalb der Datei definiert, die die DAG-Definition enthält. Sie wurde hier jedoch aus Gründen der Ausführlichkeit aufgenommen.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Antwort: Es gibt verschiedene Möglichkeiten, dies zu tun. Eine der gebräuchlichsten Methoden ist die Verwendung des >> Bit-Shift-Operators. Eine andere Möglichkeit ist, die Methode .set_downstream() zu verwenden, um eine Aufgabe einer anderen nachzuschalten. Die Funktion chain ist ein weiteres nützliches Werkzeug, um Abhängigkeiten zwischen den einzelnen Aufgaben festzulegen. Hier sind drei Beispiele für diese Vorgehensweise:
# task_1, task_2, task_3 instantiated above
# Using bit-shift operators
task_1 >> task_2 >> task_3
# Using .set_downstream()
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# Using chain
chain(task_1, task_2, task_3)
Erzähl mir mehr: Das Setzen von Abhängigkeiten kann einfach sein, während andere ziemlich komplex werden können! Bei der sequenziellen Ausführung ist es üblich, die Bitverschiebungsoperatoren zu verwenden, um dies ausführlicher zu machen. Wenn du die TaskFlow-API verwendest, kann das Festlegen von Abhängigkeiten zwischen Aufgaben ein wenig anders aussehen.
Wenn es zwei abhängige Aufgaben gibt, kann dies durch die Übergabe eines Funktionsaufrufs an eine andere Funktion angegeben werden, anstatt die oben genannten Techniken zu verwenden. Mehr über die Abhängigkeiten von Airflow-Aufgaben erfährst du in einem separaten Artikel.
Antwort: Aufgabengruppen werden verwendet, um Aufgaben innerhalb einer DAG zusammen zu organisieren. Das macht es einfacher, ähnliche Aufgaben in der Airflow-Benutzeroberfläche zusammen zu kennzeichnen. Es kann sinnvoll sein, Aufgabengruppen zu verwenden, wenn du Daten extrahierst, transformierst und lädst, die zu verschiedenen Teams in derselben DAG gehören.
Aufgabengruppen werden auch häufig verwendet, wenn es darum geht, mehrere ML-Modelle zu trainieren oder mit mehreren (aber ähnlichen) Quellsystemen in einer einzigen DAG zu interagieren.
Wenn du Aufgabengruppen in Airflow verwendest, kann die Grafikansicht etwa so aussehen:
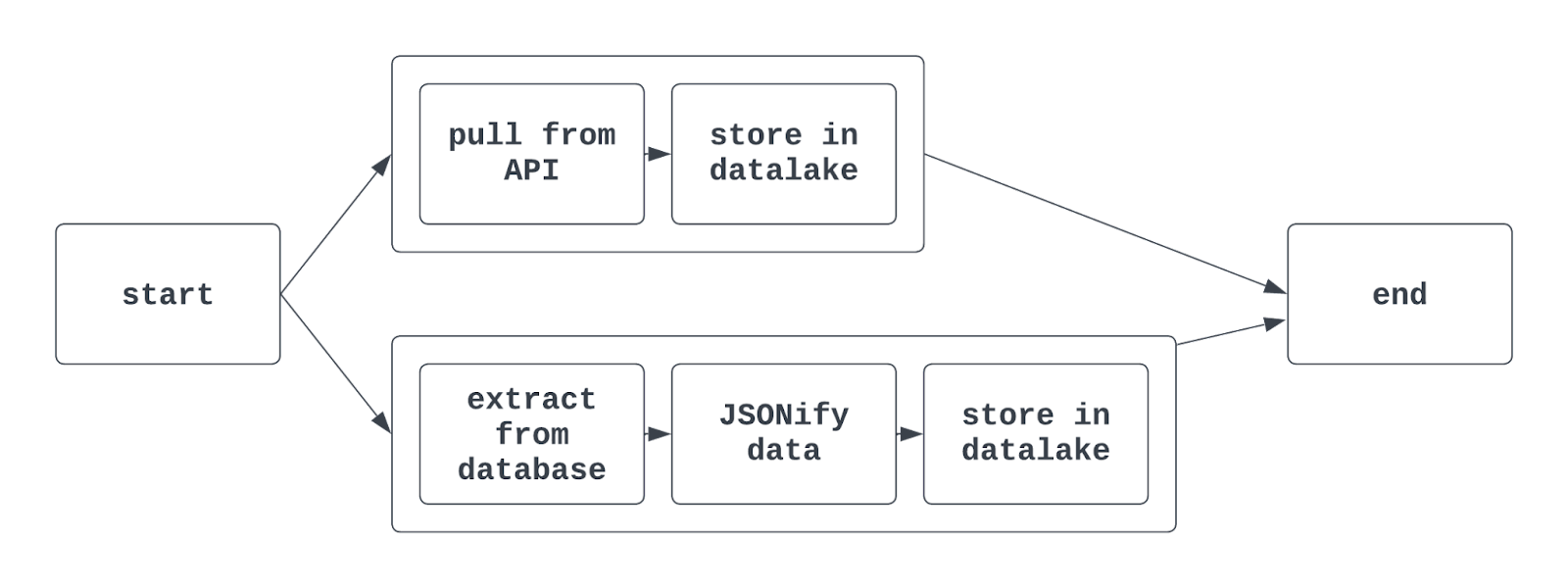
Erzähl mir mehr: Mit der traditionellen Airflow-Syntax wird die Funktion TaskGroup verwendet, um Aufgabengruppen zu erstellen. Aufgabengruppen können explizit oder dynamisch erstellt werden, müssen aber eindeutige IDs haben (ähnlich wie bei DAGs).
Allerdings können verschiedene Aufgabengruppen in derselben DAG Aufgaben mit demselben task_id haben. Die Aufgabe wird dann durch die Kombination aus der Aufgabengruppen-ID und der Aufgaben-ID eindeutig identifiziert. Wenn du die TaskFlow-API nutzt, kannst du mit dem @task_group Dekorator auch eine Aufgabengruppe erstellen.
Antwort: Die dynamische Generierung von DAGs ist eine praktische Technik, um mehrere DAGs mit einem einzigen "Brocken" Code zu erstellen. Das Abrufen von Daten aus mehreren Standorten ist ein Beispiel dafür, wie nützlich die dynamische Erstellung von DAGs ist. Wenn du Daten von drei Flughäfen mit derselben Logik extrahieren, transformieren und laden musst, hilft dir die dynamische Erstellung von DAGs, diesen Prozess zu rationalisieren.
Es gibt verschiedene Möglichkeiten, dies zu tun. Am einfachsten ist es, eine Liste von Metadaten zu verwenden, die in einer Schleife durchlaufen werden kann. Dann kann innerhalb der Schleife ein DAG instanziiert werden. Es ist wichtig zu wissen, dass jede DAG eine eindeutige DAG-ID haben sollte. Der Code dafür könnte in etwa so aussehen:
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# Rest of the DAG definition
...
Dieser Code würde drei DAGs mit den DAG-IDs atl_daily_etl, lax_daily_etl und jfk_daily_etl erzeugen. In der Folge können die Aufgaben mit demselben Flughafencode parametrisiert werden, um sicherzustellen, dass jede DAG wie erwartet ausgeführt wird.
Erzähl mir mehr: Die dynamische Erstellung von DAGs ist eine Technik, die häufig in Unternehmen eingesetzt wird. Bei der Entscheidung zwischen der programmgesteuerten Erstellung von Aufgabengruppen in einer einzigen DAG und der dynamischen Erstellung von DAGs ist es wichtig, an die Beziehungen zwischen den Vorgängen zu denken.
Wenn in unserem obigen Beispiel ein einzelner Flughafen eine Ausnahme auslöst, würde die Verwendung von Aufgabengruppen dazu führen, dass die gesamte DAG fehlschlägt. Wenn die DAGs stattdessen dynamisch generiert werden, würde dieser eine Fehlerpunkt nicht dazu führen, dass die anderen beiden DAGs ausfallen.
Eine Schleife über eine Python-Iterable ist nicht die einzige Möglichkeit, DAGs dynamisch zu erzeugen. Die Definition einer create_dag Funktion, die Verwendung von Variablen/Verbindungen zum Erzeugen von DAGs oder die Nutzung einer JSON-Konfigurationsdatei sind gängige Optionen, um das gleiche Ziel zu erreichen. Tools von Drittanbietern wie gusty und dag-factory bieten zusätzliche konfigurationsbasierte Ansätze zur dynamischen Erstellung von DAGs.
Die Grundlagen der Airflow- und DAG-Entwicklung zu verstehen und zu vermitteln, reicht oft aus, um die Erwartungen an eine Junior-Level-Position im Datenbereich zu erfüllen. Aber Airflow zu beherrschen bedeutet mehr als nur DAGs zu schreiben und auszuführen.
Die folgenden Fragen und Antworten helfen dabei, einem Interviewer ein tieferes Verständnis für die komplexeren Funktionen von Airflow zu vermitteln, was in der Regel für höhere Positionen erforderlich ist.
data_interval_start und data_interval_end, Wann wird eine DAG ausgeführt?Antwort: Wie der Name schon sagt, sind data_interval_start und data_interval_end die zeitlichen Grenzen für den DAG-Lauf. Wenn eine DAG mit Rückständen gefüllt wird und die Zeit, in der die DAG ausgeführt wird, größer ist als die data_interval_end, dann wird die DAG sofort in die Warteschlange gestellt.
Bei einer "normalen" Ausführung wird eine DAG jedoch erst dann ausgeführt, wenn die Zeit, in der sie ausgeführt wird, größer ist als **data_interval_end**.
Erzähl mir mehr: Das ist ein schwieriges Konzept, vor allem, wenn man bedenkt, wie DAG-Läufe beschriftet werden. Hier ist eine gute Möglichkeit, darüber nachzudenken. Du möchtest alle Daten für den 17. März 2024 von einer API abrufen.
Wenn das Zeitplanintervall täglich ist, ist die data_interval_start für diesen Lauf der 2024-03-17, 00:00:00 UTC, und die data_interval_end ist der 2024-03-18, 00:00:00 UTC. Es würde keinen Sinn machen, diese DAG am 17.03.2024, 00:00:00 UTC auszuführen, da dann keine Daten für den 17. März vorhanden wären. Stattdessen wird die DAG auf data_interval_end am 2024-03-18, 00:00:00 UTC ausgeführt.
Antwort: Der Parameter catchup wird definiert, wenn eine DAG instanziiert wird. catchup nimmt den Wert True oder False an und ist standardmäßig auf True eingestellt, wenn er nicht angegeben wird. Wenn True, werden alle DAG-Läufe zwischen dem Startdatum und dem Zeitpunkt, an dem der Status der DAG zum ersten Mal auf aktiv gesetzt wurde, ausgeführt.
Angenommen, das Startdatum einer DAG wird auf den 1. Januar 2024 festgelegt, mit einem Zeitplanintervall von täglich und catchup=True. Wenn das aktuelle Datum der 15. April 2024 ist und diese DAG zum ersten Mal auf aktiv gesetzt wird, wird der DAG-Lauf mit data_interval_start vom 1. Januar 2024 ausgeführt, gefolgt von dem DAG-Lauf für den 2. Januar 2024 (und so weiter).
Das geht so lange, bis die DAG "aufgeholt" hat und ihr normales Verhalten wieder aufnimmt. Dies wird als "Aufschüttung" bezeichnet. Die Verfüllung kann recht schnell erfolgen. Wenn dein DAG-Lauf nur ein paar Minuten dauert, können ein paar Monate historischer DAG-Läufe in nur ein paar Stunden ausgeführt werden.
Wenn False gewählt wird, werden keine historischen DAG-Läufe durchgeführt und der erste Lauf beginnt am Ende des Intervalls, in dem der DAG-Status auf laufen gesetzt wurde.
Erzähl mir mehr: Die Möglichkeit, DAG-Läufe ohne größere Änderungen am Code oder manuellen Aufwand wieder aufzufüllen, ist eine der stärksten Funktionen von Airflow. Angenommen, du arbeitest an einer Integration, die alle Transaktionen des letzten Jahres aus einer API abruft.
Sobald du deine DAG erstellt hast, musst du nur noch dein gewünschtes Startdatum und catchup=True festlegen, um die historischen Daten abzurufen.
Wenn du deine DAG nicht wieder auffüllen willst, wenn du sie zum ersten Mal aktivierst, ist das kein Problem! Es gibt eine Reihe anderer Möglichkeiten, um systematisch Rückverfüllungen auszulösen. Das kannst du mit der Airflow-API und dem Airflow (und Astro CLI) machen.
Antwort: XComs (das steht für Cross-Communications) sind eine ausgefeiltere Funktion von Airflow, mit der Nachrichten zwischen Aufgaben gespeichert und abgerufen werden können.
XComs werden in Schlüssel-Wert-Paaren gespeichert und können auf verschiedene Arten gelesen und geschrieben werden. Bei der Verwendung von PythonOperator können die Methoden .xcom_push() und .xcom_pull() innerhalb des Callables verwendet werden, um Daten aus XComs zu "pushen" und zu "ziehen". XComs werden verwendet, um kleine Datenmengen zu speichern, z. B. Dateinamen oder ein boolesches Flag.
Erzähl mir mehr: Neben der Verwendung von .xcom_push() und .xcom_pull() gibt es noch eine Reihe anderer Möglichkeiten, Daten von XComs zu schreiben und zu lesen. Wenn du PythonOperator verwendest, wird durch die Übergabe von True an die do_xcom_push Parameter der vom Callable zurückgegebene Wert in XComs geschrieben.
Dies ist nicht nur auf PythonOperator beschränkt; jeder Operator, der einen Wert zurückgibt, kann diesen Wert mit Hilfe des do_xcom_push Parameters in XComs schreiben lassen. Hinter den Kulissen verwendet die TaskFlow-API auch XComs, um Daten zwischen Aufgaben auszutauschen (wir werden uns das als Nächstes ansehen).
Weitere Informationen über XComs findest du in diesem tollen Blog von der Airflow-Legende Marc Lamberti.
Antwort: Die TaskFlow-API bietet eine neue Möglichkeit, DAGs auf eine intuitivere, "pythonische" Weise zu schreiben. Anstatt traditionelle Operatoren zu verwenden, werden Python-Funktionen mit dem @task Dekorator dekoriert und können Abhängigkeiten zwischen Aufgaben ableiten, ohne sie explizit zu definieren.
Eine Aufgabe, die mit der TaskFlow-API geschrieben wurde, könnte etwa so aussehen:
import random
...
@task
def get_temperature():
# Pull a temperature, return the value
temperature = random.randint(0, 100)
return temperature
…
Mit der TaskFlow API ist es einfach, Daten zwischen Aufgaben auszutauschen. Anstatt direkt XComs zu verwenden, kann der Rückgabewert einer Aufgabe (Funktion) direkt als Argument an eine andere Aufgabe übergeben werden. Während dieses Prozesses werden XComs immer noch hinter den Kulissen verwendet, was bedeutet, dass große Datenmengen nicht zwischen Aufgaben ausgetauscht werden können, selbst wenn die TaskFlow-API verwendet wird.
Erzähl mir mehr: Die TaskFlow-API ist Teil von Airflows Bestreben, das Schreiben von DAGs zu vereinfachen und das Framework für ein breiteres Publikum von Datenwissenschaftlern und Analysten attraktiv zu machen. Die TaskFlow-API erfüllt zwar nicht die Anforderungen von Data-Engineering-Teams, die ein Cloud-Daten-Ökosystem integrieren wollen, aber sie ist besonders nützlich (und intuitiv) für grundlegende ETL-Aufgaben.
Die TaskFlow-API und herkömmliche Operatoren können in derselben DAG verwendet werden, sodass die Integrierbarkeit herkömmlicher Operatoren mit der Benutzerfreundlichkeit der TaskFlow-API einhergeht. Weitere Informationen über die TaskFlow-API findest du in der Dokumentation.
Antwort: Idempotenz ist eine Eigenschaft eines Prozesses/einer Operation, die es ermöglicht, diesen Prozess mehrmals auszuführen, ohne das ursprüngliche Ergebnis zu verändern. Einfacher ausgedrückt: Wenn du eine DAG einmal oder zehnmal ausführst, sollten die Ergebnisse identisch sein.
Ein häufiger Arbeitsablauf, bei dem dies nicht der Fall ist, ist das Einfügen von Daten in strukturierte (SQL-)Datenbanken. Wenn Daten ohne eine Primärschlüsselerzwingung eingefügt werden und eine DAG mehrfach ausgeführt wird, führt diese DAG zu Duplikaten in der resultierenden Tabelle. Die Verwendung von Mustern wie "delete-insert" oder "upsert" hilft bei der Umsetzung von Idempotenz in Datenpipelines.
Erzähl mir mehr: Dieser Punkt ist zwar nicht ganz Airflow-spezifisch, sollte aber beim Entwurf und Aufbau von Datenpipelines unbedingt beachtet werden. Zum Glück gibt es in Airflow verschiedene Tools, die die Umsetzung von Idempotenz erleichtern. Der größte Teil dieser Logik muss jedoch von den Praktikern entworfen, entwickelt und getestet werden, die Airflow zur Implementierung ihrer Datenpipeline nutzen.
Bei eher technischen Positionen könnte ein Interviewer Fragen zur Verwaltung und Überwachung einer produktiven Airflow-Implementierung stellen, ähnlich der, die sie in ihrem Team betreiben. Diese Fragen sind etwas kniffliger und erfordern etwas mehr Vorbereitung vor einem Vorstellungsgespräch.
Antwort: Es gibt ein paar Möglichkeiten, eine DAG zu testen, nachdem sie geschrieben wurde. Am häufigsten wird eine DAG ausgeführt, um sicherzustellen, dass sie erfolgreich läuft. Dazu kannst du eine lokale Airflow-Umgebung einrichten und die DAG über die Airflow-Benutzeroberfläche auslösen.
Sobald die DAG ausgelöst wurde, kann sie überwacht werden, um ihre Leistung zu überprüfen (sowohl Erfolg/Misserfolg der DAG und der einzelnen Aufgaben als auch die Zeit und die Ressourcen, die für ihre Ausführung benötigt wurden).
Zusätzlich zum manuellen Testen der DAG über die Ausführung können DAGs auch einem Unit-Test unterzogen werden. Airflow stellt über die CLI Werkzeuge zur Verfügung, um Tests auszuführen, oder es kann ein Standard-Test-Runner verwendet werden. Diese Unit-Tests können sowohl für die DAG-Konfiguration und -Ausführung als auch für andere Komponenten eines Airflow-Projekts, wie Callables und Plugins, geschrieben werden.
Erzähl mir mehr: Das Testen von Airflow DAGs ist eine der wichtigsten Aufgaben eines Data Engineers. Wenn eine DAG nicht getestet wurde, ist sie nicht bereit, die Produktionsabläufe zu unterstützen.
Das Testen von Datenpipelines ist besonders knifflig: Es gibt Rand- und Eckfälle, die in anderen Entwicklungsszenarien nicht vorkommen. In einem eher technischen Gespräch (vor allem mit einem Lead/Senior Engineer) solltest du darauf hinweisen, wie wichtig es ist, eine DAG durchgängig zu testen und gleichzeitig Unit-Tests zu schreiben und die Ergebnisse zu dokumentieren.
Antwort: Niemand mag DAG-Ausfälle, aber sie mit Anstand zu behandeln, kann dich als Data Engineer auszeichnen. Zum Glück bietet Airflow eine Fülle von Tools, um DAG-Fehler zu erfassen, zu melden und zu beheben. Zunächst wird der Ausfall einer DAG in der Airflow-Benutzeroberfläche festgehalten. Der Status der DAG ändert sich auf "fehlgeschlagen" und in der Gitteransicht wird ein rotes Quadrat/Rechteck für diesen Lauf angezeigt. Dann können die Logs für diese Aufgabe manuell in der Benutzeroberfläche geparst werden.
In der Regel enthalten diese Protokolle die Ausnahme, die den Ausfall verursacht hat, und liefern dem Data Engineer Informationen für die weitere Triage.
Sobald das Problem identifiziert ist, kann der zugrunde liegende Code/die Konfiguration der DAG aktualisiert und die DAG erneut ausgeführt werden. Das kannst du tun, indem du den Status der DAG löschst und sie auf "aktiv" setzt.
Wenn eine DAG regelmäßig ausfällt, aber bei einem erneuten Versuch funktioniert, kann es hilfreich sein, die Funktionen von Airflow retries und retry_delay zu nutzen. Diese beiden Parameter können verwendet werden, um eine Aufgabe bei Fehlschlag eine bestimmte Anzahl von Malen zu wiederholen, nachdem eine bestimmte Zeit gewartet wurde. Das kann z.B. nützlich sein, wenn du versuchst, eine Datei von einer SFTP-Site zu holen, die vielleicht erst spät ankommt.
Erzähl mir mehr: Damit eine DAG ausfällt, muss eine bestimmte Aufgabe fehlschlagen. Es ist wichtig, diese Aufgabe zu triagieren und nicht die gesamte DAG. Zusätzlich zu den Funktionen, die in der Benutzeroberfläche integriert sind, gibt es eine Menge anderer Tools zur Überwachung und Verwaltung der DAG-Leistung.
Callbacks bieten Dateningenieuren praktisch unbegrenzte Anpassungsmöglichkeiten bei der Handhabung von DAG-Erfolgen und -Fehlern. Mit Callbacks kann eine Funktion nach Wahl des DAG-Autors ausgeführt werden, wenn eine DAG erfolgreich ist oder fehlschlägt, indem die Parameter on_success_callback und on_failure_callback eines Operators verwendet werden. Diese Funktion kann eine Nachricht an ein Tool wie PagerDuty senden oder das Ergebnis in eine Datenbank schreiben, um später alarmiert zu werden. Das hilft, die Sichtbarkeit zu verbessern und den Triage-Prozess in Gang zu setzen, wenn ein Fehler auftritt.
Antwort: Eines der praktischsten Werkzeuge von Airflow sind die "Verbindungen". Verbindungen ermöglichen es einem DAG-Autor, Verbindungsinformationen (wie z. B. Host, Benutzername, Passwort usw.) zu speichern und darauf zuzugreifen, ohne diese Werte in den Code einbinden zu müssen.
Es gibt mehrere Möglichkeiten, Verbindungen zu speichern; die gängigste ist die Verwendung der Airflow-Benutzeroberfläche. Sobald eine Verbindung erstellt wurde, kann sie mit einem "Hook" direkt im Code aufgerufen werden. Die meisten traditionellen Operatoren, die eine Interaktion mit einem Quellsystem erfordern, haben jedoch ein conn_id (oder sehr ähnlich benanntes) Feld, das einen String aufnimmt und eine Verbindung zur gewünschten Quelle herstellt.
Airflow-Verbindungen tragen dazu bei, dass sensible Informationen sicher sind und das Speichern und Abrufen dieser Informationen ein Kinderspiel ist.
Erzähl mir mehr: Neben der Airflow-Benutzeroberfläche kann auch die CLI verwendet werden, um Verbindungen zu speichern und abzurufen. In einem Unternehmen ist es üblicher, ein benutzerdefiniertes "Geheimnisse-Backend" zu verwenden, um Verbindungsinformationen zu verwalten. Airflow bietet eine Reihe von Unterstützungsgeheimnissen für die Verwaltung von Verbindungen. Ein Unternehmen, das AWS nutzt, kann den Secrets Manager problemlos in Airflow integrieren, um Verbindungs- und sensible Daten zu speichern und abzurufen. Bei Bedarf können die Verbindungen auch in den Umgebungsvariablen eines Projekts definiert werden.
Antwort: Die Bereitstellung einer Airflow-Umgebung für den Einsatz in einer Produktionsumgebung kann schwierig sein. Cloud-Tools wie Azure und AWS bieten verwaltete Dienste für die Bereitstellung und Verwaltung einer Airflow-Implementierung. Diese Tools erfordern jedoch ein Cloud-Konto und können etwas teuer sein.
Eine gängige Alternative ist die Verwendung von Kubernetes für die Bereitstellung und den Betrieb einer Airflow-Produktionsumgebung. Dies ermöglicht die vollständige Kontrolle über die zugrundeliegenden Ressourcen, bringt aber die zusätzliche Verantwortung mit sich, diese Infrastruktur zu verwalten.
Abgesehen von Cloud-nativen und selbst entwickelten Kubernetes-Implementierungen ist Astronomer der beliebteste Managed Service Provider für Airflow in diesem Bereich.
Zusätzlich zu ihrem PaaS-Angebot "Astro" stellen sie eine Reihe von Open-Source-Tools (CLI, SDK, umfangreiche Dokumentation) zur Verfügung, um die Entwicklung und Bereitstellung von Airflow so reibungslos wie möglich zu gestalten. Mit Astro werden die Ressourcenzuweisung, die Kontrolle des Plattformzugriffs und Airflow-Upgrades direkt vor Ort unterstützt, so dass der Fokus wieder auf der Pipeline-Entwicklung liegt.
Obwohl szenariobasierte Fragen nicht übermäßig technisch sind, gehören sie zu den wichtigsten Fragen in einem Airflow-Interview. Detaillierte und gut durchdachte Antworten zeigen, dass du nicht nur mit Airflow, sondern auch mit Datenarchitektur und Designprinzipien vertraut bist.
Antwort: Das ist eine lustige Sache! Mit einer Frage wie dieser liegt dir die Welt zu Füßen. Das Wichtigste ist, dass du beim Durchlaufen des Prozesses darauf achtest, Werkzeuge und Prozesse in der Legacy Data Pipeline zu wählen, mit denen du vertraut bist. Das zeigt dein Fachwissen und macht deine Antwort auf deine Frage fundierter.
Das ist die perfekte Gelegenheit, um auch deine Projektmanagement- und Führungsqualitäten unter Beweis zu stellen. Erkläre, wie du das Projekt strukturieren, mit Stakeholdern und anderen Ingenieuren interagieren und Prozesse dokumentieren/kommunizieren würdest. Das zeigt, dass du Wert darauf legst, deinem Team einen Mehrwert zu bieten und ihm das Leben zu erleichtern.
Wenn ein Unternehmen ein bestimmtes Tool in seinem Stack hat (z.B. Google BigQuery), könnte es sinnvoll sein, darüber zu sprechen, wie du diesen Prozess so umgestalten kannst, dass er von Postgres auf BigQuery umgestellt wird. Das zeigt, dass du nicht nur Airflow, sondern auch andere Komponenten der Unternehmensinfrastruktur kennst.
Antwort: Um diese DAG zu erstellen, musst du zunächst die API nutzen, um Daten zu extrahieren. Dies kann mit der PythonOperator und einem benutzerdefinierten Callable geschehen. In diesem Callable musst du die Daten auch in einem Cloud-Speicher wie AWS S3 speichern.
Sobald diese Daten gespeichert sind, kannst du einen vorgefertigten Operator wie S3ToSnowflakeOperator nutzen, um Daten aus S3 in ein Snowflake Data Warehouse zu laden. Schließlich kann ein DBT-Job ausgeführt werden, um diese Daten mit Hilfe der DbtCloudRunJobOperator umzuwandeln.
Du solltest diese DAG so einplanen, dass sie in den gewünschten Intervallen läuft und so konfigurieren, dass sie Ausfälle elegant (aber sichtbar) behandelt. Schau dir das Diagramm unten an!
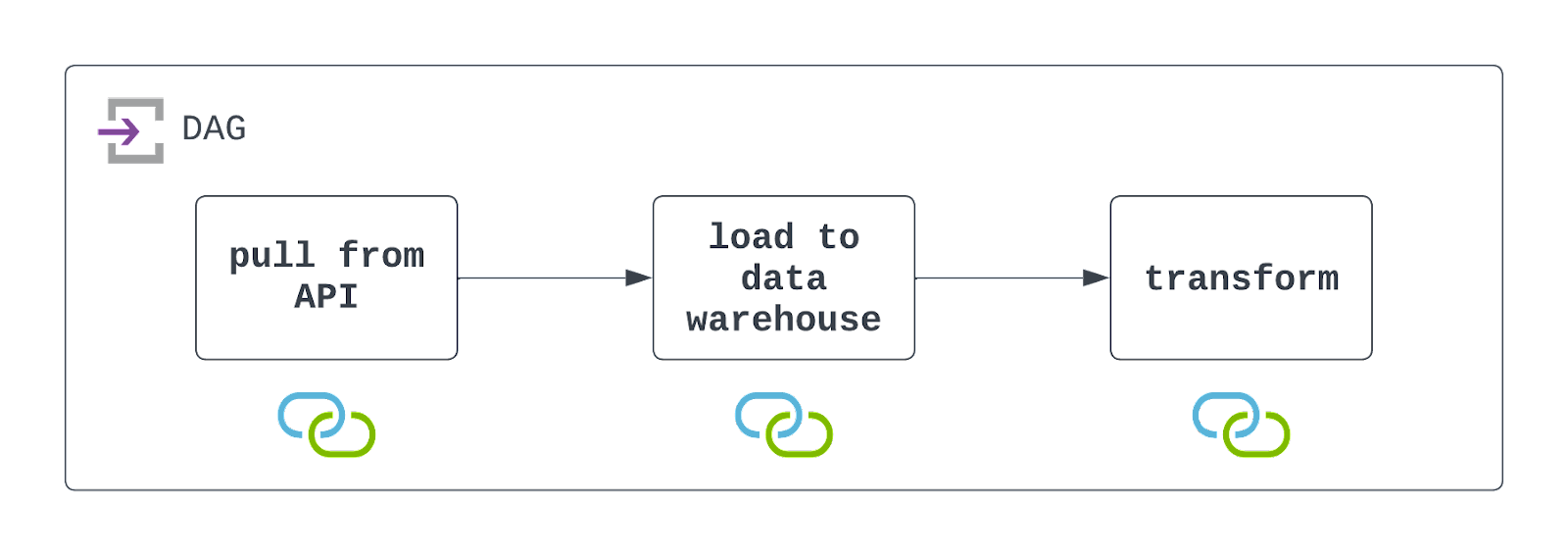
Es ist wichtig zu wissen, dass Airflow sowohl mit dem Dateisystem eines Cloud-Speichers als auch mit einem Data Warehouse interagiert. Damit diese DAG erfolgreich ausgeführt werden kann, müssen diese Ressourcen vorhanden sein, und es müssen Verbindungen definiert und genutzt werden. Diese sind durch die Symbole unter jeder Aufgabe im obigen Architekturdiagramm gekennzeichnet.
Erzähl mir mehr: Dies sind einige der häufigsten Airflow-Interview-Fragen, die sich eher auf den Entwurf und die Implementierung von DAGs auf hoher Ebene als auf technische Details konzentrieren. Bei diesen Fragen ist es wichtig, dass du ein paar Dinge im Hinterkopf behältst:
DbtCloudRunJobOperator verwenden möchtest, erwähne dieses Tool, aber gehe nicht weiter darauf ein (außer du wirst gefragt).Antwort: Die Erweiterbarkeit von Airflow und seine wachsende Beliebtheit in der Daten-Community haben es nicht nur für Dateningenieure zu einem beliebten Tool gemacht. Data Scientists und Machine Learning Engineers nutzen Airflow, um ihre Modelle zu trainieren (und wieder zu trainieren) und eine ganze Reihe von MLOps durchzuführen. KI-Ingenieure beginnen sogar, Airflow für die Verwaltung und Skalierung ihrer generativen KI-Modelle zu nutzen, mit neuen Integrationen für Tools wie OpenAI, OpenSearch und Pinecone.
Erzähl mir mehr: Der Erfolg außerhalb der traditionellen Datenentwicklungspipelines war vielleicht nicht das, was sich die Erfinder von Airflow vorgestellt haben. Durch die Nutzung von Python und der Open-Source-Philosophie ist Airflow jedoch gewachsen, um den Anforderungen eines sich schnell entwickelnden Daten- und KI-Bereichs gerecht zu werden. Wenn programmatische Aufgaben geplant und ausgeführt werden müssen, ist Airflow vielleicht das beste Werkzeug für diese Aufgabe!
Gute Arbeit! Du hast es geschafft, durch die Mangel gedreht zu werden. Die obigen Fragen sind anspruchsvoll, erfassen aber einen Großteil der Fragen, die in technischen Vorstellungsgesprächen rund um Airflow gestellt werden.
Eine der besten Möglichkeiten, sich auf ein Airflow-Interview vorzubereiten, ist es, deine eigenen Datenpipelines mit Airflow zu erstellen und die obigen Fragen aufzufrischen.
Finde einen Datensatz, der dich interessiert, und beginne damit, deine ETL- (oder ELT-) Pipeline von Grund auf aufzubauen. Übe den Umgang mit der TaskFlow-API und traditionellen Operatoren. Speichere sensible Informationen über Airflow-Verbindungen. Versuche dich an der Meldung von Fehlern mithilfe von Rückrufen und teste deine DAG mit Unit-Tests und End-to-End. Am wichtigsten ist, dass du deine Arbeit dokumentierst und mit anderen teilst.
Ein Projekt wie dieses zeigt nicht nur, dass du Airflow beherrschst, sondern auch, dass du mit Leidenschaft lernst und wachsen willst. Wenn du noch eine Einführung in einige der Grundprinzipien brauchst, kannst du dir unseren Kurs Einführung in Airflow in Python, unseren Vergleich zwischen Airflow und Prefect und unser Tutorial Erste Schritte mit Apache Airflow ansehen.
Viel Glück und viel Spaß beim Codieren!
Setze deine Data Engineering-Reise heute fort!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Matt Crabtree
14 Min.
Tutorial
Laiba Siddiqui
