
Program
Data Engineer dalam Python
40 Hr
Dalam wawancara teknis, pewawancara biasanya mulai dari yang mudah, berfokus pada dasar-dasar kerangka kerja Airflow dan konsep intinya sebelum beralih ke pertanyaan yang lebih kompleks dan teknis.
Saat menjawab pertanyaan-pertanyaan ini, pastikan tidak hanya membahas detail teknis, tetapi juga kaitannya dengan alur kerja data engineering dan/atau data perusahaan.
Jawaban: Apache Airflow adalah alat orkestrasi data open-source yang memungkinkan praktisi data mendefinisikan pipeline data secara terprogram dengan bantuan Python. Airflow paling umum digunakan oleh tim data engineering untuk mengintegrasikan ekosistem data mereka serta mengekstrak, mentransformasi, dan memuat data.
Tell me more: Airflow dikelola di bawah lisensi perangkat lunak Apache (karena itu ada awalan “Apache”).
Alat orkestrasi data menyediakan fungsionalitas untuk memungkinkan berbagai sumber dan layanan diintegrasikan ke dalam satu pipeline.
Yang membedakan Airflow sebagai alat orkestrasi data adalah penggunaan Python untuk mendefinisikan pipeline data, yang memberikan tingkat ekstensi dan kontrol yang tidak ditawarkan alat orkestrasi data lain. Airflow memiliki banyak alat bawaan dan yang didukung penyedia untuk mengintegrasikan tumpukan data tim mana pun, serta kemampuan untuk merancang sendiri.
Untuk informasi lebih lanjut tentang memulai dengan Airflow, lihat tutorial DataCamp ini: Getting Started with Apache Airflow. Jika Anda ingin menyelami lebih dalam dunia orkestrasi data dengan Airflow, kursus Introduction to Airflow ini adalah tempat terbaik untuk memulai.
Jawaban: DAG, atau directed-acyclic graph, adalah kumpulan tugas dan relasi antar tugas tersebut. DAG memiliki awal dan akhir yang jelas dan tidak memiliki “siklus” di antara tugas-tugasnya. Saat menggunakan Airflow, istilah “DAG” umum digunakan, dan umumnya dapat dianggap sebagai sebuah pipeline data.
Tell me more: Ini pertanyaan yang rumit. Ketika pewawancara menanyakannya, penting untuk membahas baik definisi “matematis” formal dari DAG maupun cara penggunaannya di Airflow. Saat memikirkan DAG, akan membantu jika melihat visual. Gambar pertama di bawah ini adalah DAG. Ia memiliki awal dan akhir yang jelas serta tidak ada siklus antar tugas.

Proses kedua yang ditunjukkan di bawah BUKAN DAG. Meskipun ada tugas awal yang jelas, terdapat siklus antara tugas extract dan validate, yang membuat waktu pemicu tugas load menjadi tidak jelas.
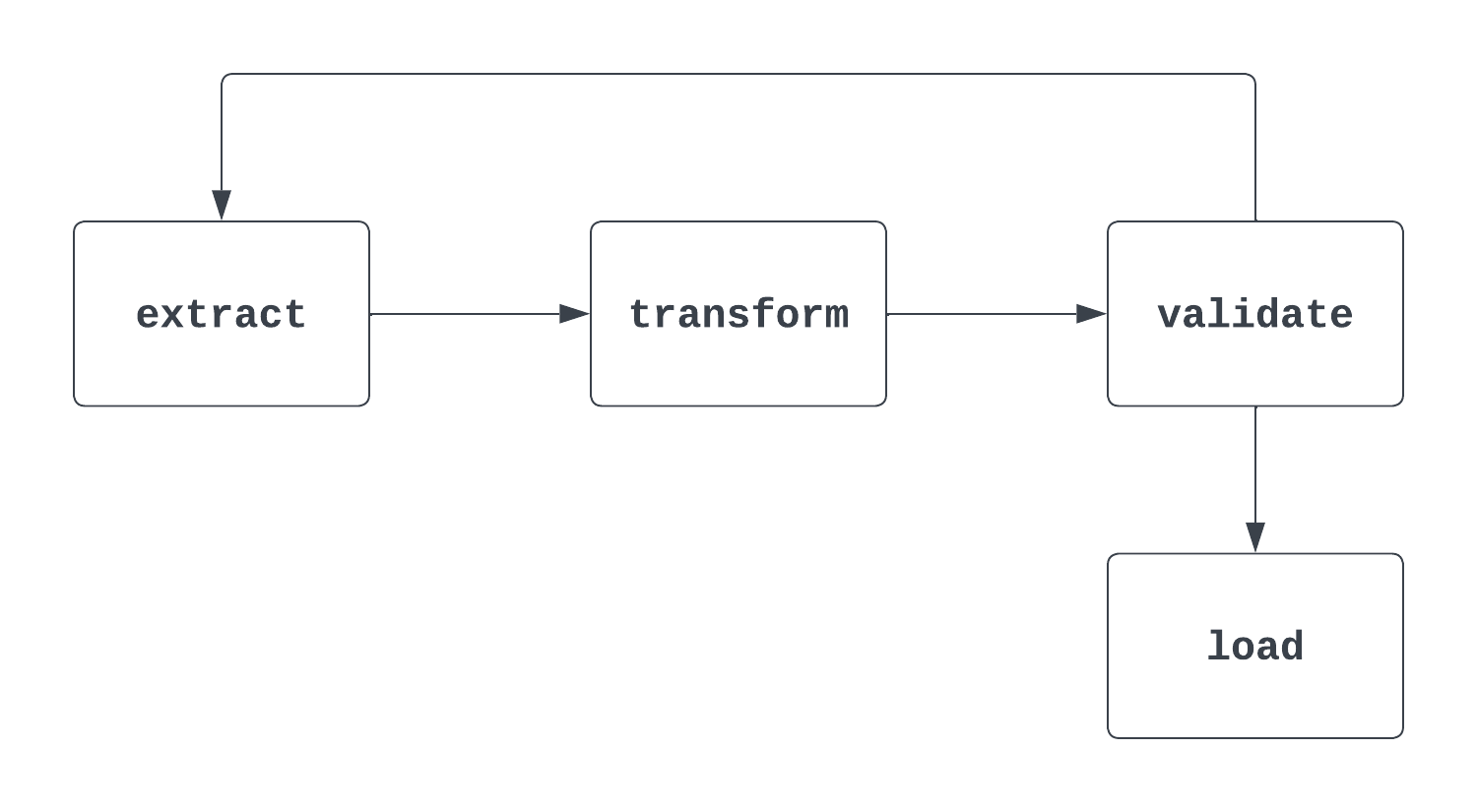
Jawaban: Untuk mendefinisikan DAG, harus disediakan ID, start date, dan schedule interval.
Tell me more: ID mengidentifikasi DAG secara unik dan biasanya berupa string pendek, seperti "sample_da." Start date adalah tanggal dan waktu interval pertama saat DAG akan dipicu.
Ini adalah timestamp, artinya tahun, bulan, hari, jam, dan menit ditentukan secara tepat. Schedule interval adalah seberapa sering DAG harus dijalankan. Ini bisa setiap minggu, setiap hari, setiap jam, atau sesuatu yang lebih kustom.
Pada contoh di sini, DAG didefinisikan menggunakan dag_id "sample_dag". Fungsi datetime dari pustaka datetime digunakan untuk menetapkan start_date 1 Januari 2024 pukul 09.00. DAG ini akan berjalan setiap hari (pukul 09.00), seperti yang ditetapkan oleh interval terjadwal @daily. Interval jadwal yang lebih kustom dapat diatur menggunakan ekspresi cron atau fungsi timedelta dari pustaka datetime.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Jawaban: Tugas Airflow adalah unit eksekusi terkecil dalam kerangka kerja Airflow. Sebuah tugas biasanya merangkum satu operasi dalam pipeline data (DAG). Tugas adalah blok pembangun untuk DAG, dan tugas dalam satu DAG memiliki relasi yang menentukan urutan eksekusinya. Tiga contoh tugas adalah:
Dalam pipeline ETL, relasinya adalah:
Tell me more: Tugas bisa sangat generik atau sangat kustom. Airflow menyediakan dua cara untuk mendefinisikan tugas: operator tradisional dan TaskFlow API (lebih lanjut nanti).
Salah satu keuntungan open-source adalah kontribusi dari komunitas yang lebih luas, yang terdiri tidak hanya dari kontributor individu tetapi juga pihak seperti AWS, Databricks, Snowflake, dan banyak lagi.
Kemungkinan besar, operator Airflow sudah tersedia untuk tugas yang ingin Anda definisikan. Jika belum, mudah untuk membuat sendiri. Beberapa contoh operator Airflow adalah SFTPToS3Operator, S3ToSnowflakeOperator, dan DatabricksRunNowOperator.
Jawaban: Ada empat komponen inti arsitektur Airflow: scheduler, executor, metadata database, dan webserver.
Tell me more: Scheduler memeriksa direktori DAG setiap menit dan memantau DAG serta tugas untuk mengidentifikasi tugas yang dapat dipicu. Executor adalah tempat tugas dijalankan. Tugas dapat dieksekusi secara lokal (di dalam scheduler) atau jarak jauh (di luar scheduler).
Executor adalah tempat berlangsungnya “pekerjaan” komputasional yang diperlukan setiap tugas. Metadata database berisi semua informasi tentang DAG dan tugas yang terkait dengan proyek Airflow yang Anda jalankan. Ini mencakup informasi seperti detail eksekusi historis, koneksi, variabel, dan banyak informasi lainnya.
Webserver memungkinkan UI Airflow dirender dan diinteraksikan saat mengembangkan, berinteraksi dengan, dan memelihara DAG.
Ini hanyalah gambaran singkat tentang komponen arsitektur inti Airflow.
Anda sudah menunjukkan bahwa Anda memahami dasar-dasar kerangka Airflow dan arsitekturnya. Sekarang saatnya menguji pengetahuan Anda dalam menulis DAG.
PythonOperator? Apa persyaratan untuk menggunakan operator ini? Kapan Anda ingin menggunakan PythonOperator?Jawaban: PythonOperator adalah fungsi yang memungkinkan sebuah fungsi Python dieksekusi sebagai tugas Airflow. Untuk menggunakan operator ini, sebuah fungsi Python harus diteruskan ke parameter python_callable. Salah satu contoh penggunaan operator ini adalah saat memanggil API untuk mengekstrak data.
Tell me more: PythonOperator adalah salah satu operator paling kuat yang disediakan Airflow. Operator ini tidak hanya memungkinkan kode kustom dieksekusi dalam DAG, tetapi hasilnya juga dapat ditulis ke XComs untuk digunakan oleh tugas hilir.
Dengan meneruskan dictionary ke parameter op_kwargs, argumen kata kunci dapat diteruskan ke callable Python, memungkinkan kustomisasi lebih lanjut saat runtime. Selain op_kwargs, ada sejumlah parameter tambahan yang membantu memperluas fungsionalitas PythonOperator.
Berikut adalah contoh pemanggilan PythonOperator. Biasanya, fungsi Python yang diteruskan ke python_callable didefinisikan di luar berkas yang memuat definisi DAG. Namun, di sini disertakan demi kelengkapan.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Jawaban: Ada cukup banyak cara untuk melakukannya. Salah satu yang paling umum adalah menggunakan operator bit-shift >>. Cara lain adalah menggunakan metode .set_downstream() untuk menempatkan sebuah tugas di hilir tugas lain. Fungsi chain juga merupakan alat yang berguna untuk menetapkan dependensi berurutan antar tugas. Berikut tiga contohnya:
# task_1, task_2, task_3 sudah diinstansiasi di atas
# Menggunakan operator bit-shift
task_1 >> task_2 >> task_3
# Menggunakan .set_downstream()
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# Menggunakan chain
chain(task_1, task_2, task_3)
Tell me more: Penetapan dependensi bisa sederhana, namun ada juga yang cukup kompleks! Untuk eksekusi berurutan, umum menggunakan operator bit-shift agar lebih ringkas. Saat menggunakan TaskFlow API, penetapan dependensi antar tugas dapat terlihat sedikit berbeda.
Jika ada dua tugas yang saling bergantung, ini dapat dinyatakan dengan meneruskan pemanggilan fungsi ke fungsi lain, alih-alih menggunakan teknik yang disebutkan di atas. Anda dapat mempelajari lebih lanjut tentang dependensi tugas Airflow di artikel terpisah.
Jawaban: Task group digunakan untuk mengelompokkan tugas-tugas dalam sebuah DAG. Ini memudahkan untuk menandai tugas-tugas serupa bersama-sama di UI Airflow. Task group berguna saat mengekstrak, mentransformasi, dan memuat data yang berasal dari tim berbeda dalam satu DAG.
Task group juga umum digunakan saat melakukan hal seperti melatih beberapa model ML atau berinteraksi dengan beberapa sistem sumber yang mirip dalam satu DAG.
Saat menggunakan task group di Airflow, tampilan graph yang dihasilkan dapat terlihat seperti ini:
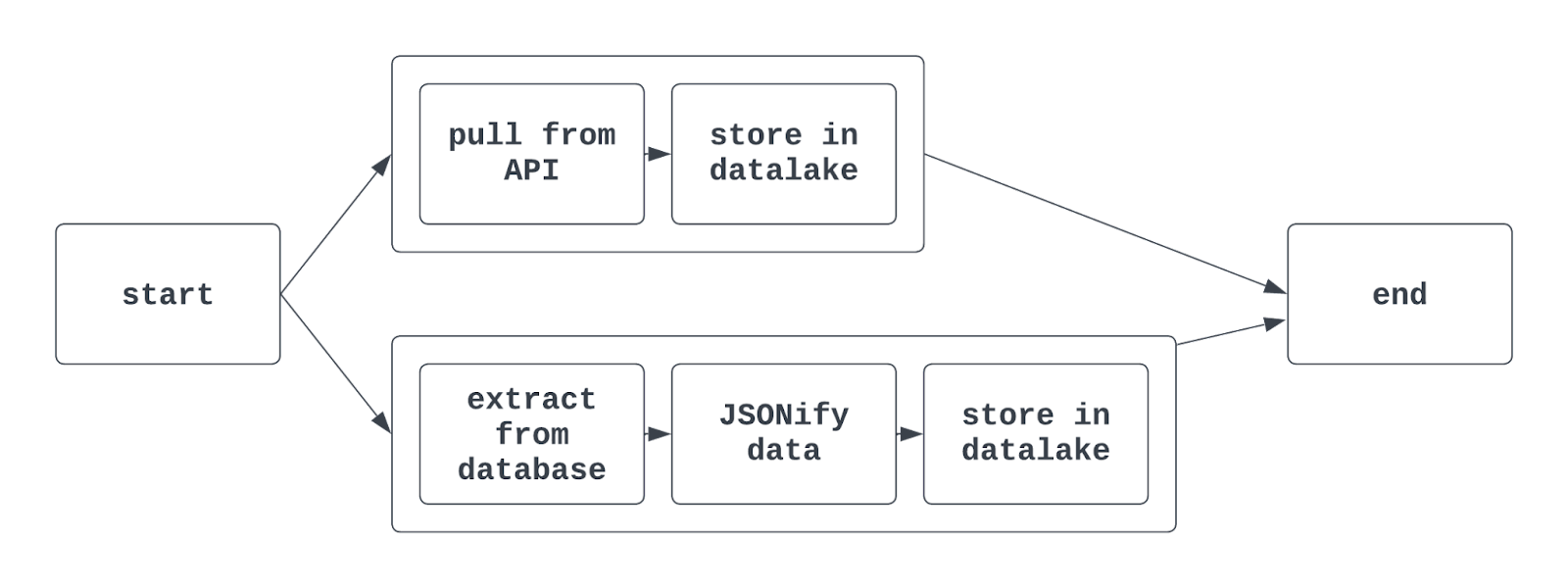
Tell me more: Menggunakan sintaks Airflow tradisional, fungsi TaskGroup digunakan untuk membuat task group. Task group dapat dibuat secara eksplisit atau dinamis tetapi harus memiliki ID unik (mirip dengan DAG).
Namun, task group yang berbeda dalam DAG yang sama dapat memiliki tugas dengan task_id yang sama. Tugas tersebut kemudian diidentifikasi secara unik oleh kombinasi ID task group dan task ID. Saat memanfaatkan TaskFlow API, dekorator @task_group juga dapat digunakan untuk membuat task group.
Jawaban: Pembuatan DAG secara dinamis adalah teknik praktis untuk membuat banyak DAG menggunakan satu “potongan” kode. Menarik data dari beberapa lokasi adalah salah satu contoh betapa bergunanya pembuatan DAG secara dinamis. Jika Anda perlu mengekstrak, mentransformasi, dan memuat data dari tiga bandara menggunakan logika yang sama, pembuatan DAG secara dinamis membantu merampingkan proses ini.
Ada beberapa cara untuk melakukannya. Salah satu yang termudah adalah menggunakan daftar metadata yang dapat di-loop. Kemudian, di dalam loop, sebuah DAG dapat diinstansiasi. Penting diingat bahwa setiap DAG harus memiliki ID DAG yang unik. Kode untuk melakukannya mungkin terlihat seperti ini:
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# Sisa definisi DAG
...
Kode ini akan menghasilkan tiga DAG, dengan DAG ID atl_daily_etl, lax_daily_etl, dan jfk_daily_etl. Di hilir, tugas dapat diparameterkan menggunakan kode bandara yang sama untuk memastikan setiap DAG dieksekusi sesuai harapan.
Tell me more: Pembuatan DAG secara dinamis adalah teknik yang umum digunakan di lingkungan perusahaan. Saat memutuskan antara membuat task group secara terprogram dalam satu DAG, atau membuat DAG secara dinamis, penting untuk memikirkan relasi antar operasi.
Pada contoh di atas, jika satu bandara menyebabkan pengecualian, penggunaan task group akan menyebabkan seluruh DAG gagal. Namun, jika DAG dibuat secara dinamis, satu titik kegagalan ini tidak akan menyebabkan dua DAG lainnya gagal.
Melakukan loop atas iterable Python bukan satu-satunya cara untuk membuat DAG secara dinamis — mendefinisikan fungsi create_dag, menggunakan variabel/koneksi untuk memunculkan DAG, atau memanfaatkan file konfigurasi JSON adalah opsi umum untuk mencapai tujuan yang sama. Alat pihak ketiga seperti gusty dan dag-factory menyediakan pendekatan berbasis konfigurasi tambahan untuk membuat DAG secara dinamis.
Memahami dan mengomunikasikan dasar-dasar Airflow dan pengembangan DAG sering kali cukup untuk memenuhi ekspektasi pada posisi data tingkat junior. Namun menguasai Airflow berarti lebih dari sekadar menulis dan menjalankan DAG.
Pertanyaan dan jawaban di bawah ini akan membantu menunjukkan kepada pewawancara pemahaman yang lebih mendalam tentang fungsionalitas Airflow yang lebih kompleks, yang biasanya diperlukan untuk peran yang lebih senior.
data_interval_start dan data_interval_end, kapan sebuah DAG dieksekusi?Jawaban: Sesuai namanya, data_interval_start dan data_interval_end adalah batas temporal untuk run DAG. Jika sebuah DAG sedang di-backfill, dan waktu pelaksanaan DAG lebih besar daripada data_interval_end, maka DAG akan segera diantrekan untuk dijalankan.
Namun, untuk eksekusi “normal”, sebuah DAG tidak akan berjalan hingga waktu pelaksanaannya lebih besar dari **data_interval_end**.
Tell me more: Ini konsep yang sulit, terutama dengan cara penamaan run DAG. Begini cara berpikir yang baik. Anda ingin menarik semua data untuk 17 Maret 2024 dari sebuah API.
Jika interval jadwalnya harian, data_interval_start untuk run ini adalah 2024-03-17, 00:00:00 UTC, dan data_interval_end-nya adalah 2024-03-18, 00:00:00 UTC. Tidak masuk akal menjalankan DAG ini pada 2024-03-17, 00:00:00 UTC, karena tidak ada data untuk 17 Maret yang tersedia. Sebaliknya, DAG dieksekusi pada data_interval_end 2024-03-18, 00:00:00 UTC.
Jawaban: Parameter catchup didefinisikan saat DAG diinstansiasi. catchup menerima nilai True atau False, dengan default True jika tidak ditentukan. Jika True, semua run DAG antara start date dan waktu status DAG pertama kali diubah menjadi aktif akan dijalankan.
Misalnya start date DAG ditetapkan pada 1 Januari 2024, dengan interval jadwal harian dan catchup=True. Jika tanggal saat ini adalah 15 April 2024 saat DAG ini pertama kali diaktifkan, run DAG dengan data_interval_start 1 Januari 2024 akan dieksekusi, diikuti run DAG untuk 2 Januari 2024 (dan seterusnya).
Ini akan berlanjut hingga DAG “terkejar”, lalu akan kembali ke perilaku normal. Ini dikenal sebagai “backfilling”. Backfilling mungkin terjadi cukup cepat. Jika run DAG Anda hanya memerlukan beberapa menit, beberapa bulan run historis dapat dieksekusi hanya dalam beberapa jam.
Jika False, tidak ada run DAG historis yang akan dieksekusi, dan run pertama akan dimulai pada akhir interval saat status DAG diatur untuk berjalan.
Tell me more: Kemampuan melakukan backfill run DAG tanpa perubahan kode yang signifikan atau upaya manual adalah salah satu fitur terkuat Airflow. Misalnya, Anda sedang mengerjakan integrasi untuk menarik semua transaksi dari sebuah API selama setahun terakhir.
Setelah Anda membangun DAG, yang perlu dilakukan hanyalah menetapkan start date yang diinginkan dan catchup=True, dan mudah untuk mengambil data historis ini.
Jika Anda tidak ingin melakukan backfill DAG saat pertama kali mengaktifkannya, jangan khawatir! Ada sejumlah cara lain untuk memicu backfill secara sistematis. Ini dapat dilakukan dengan API Airflow dan Airflow (serta Astro CLI).
Jawaban: XCom (singkatan dari cross-communications) adalah fitur Airflow yang lebih mendalam yang memungkinkan pesan disimpan dan diambil antar tugas.
XCom disimpan dalam pasangan key-value, dan dapat dibaca serta ditulis dengan berbagai cara. Saat menggunakan PythonOperator, metode .xcom_push() dan .xcom_pull() dapat digunakan di dalam callable untuk “mendorong” dan “menarik” data dari XCom. XCom digunakan untuk menyimpan data dalam jumlah kecil, seperti nama file atau flag boolean.
Tell me more: Selain menggunakan .xcom_push() dan .xcom_pull(), ada sejumlah cara lain untuk menulis dan membaca data dari XCom. Saat menggunakan PythonOperator, meneruskan True ke parameter do_xcom_push akan menulis nilai yang dikembalikan oleh callable ke XCom.
Ini tidak terbatas pada PythonOperator; operator apa pun yang mengembalikan nilai dapat menuliskan nilai tersebut ke XCom dengan bantuan parameter do_xcom_push. Di balik layar, TaskFlow API juga menggunakan XCom untuk berbagi data antar tugas (kita akan melihat ini selanjutnya).
Untuk informasi lebih lanjut tentang XCom, lihat blog hebat oleh legenda Airflow sendiri, Marc Lamberti.
Jawaban: TaskFlow API menawarkan cara baru untuk menulis DAG dengan lebih intuitif dan “Pythonic”. Alih-alih menggunakan operator tradisional, fungsi Python didekorasi dengan dekorator @task, dan dapat menyimpulkan dependensi antar tugas tanpa mendefinisikannya secara eksplisit.
Tugas yang ditulis menggunakan TaskFlow API mungkin terlihat seperti ini:
import random
...
@task
def get_temperature():
# Ambil suhu, kembalikan nilainya
temperature = random.randint(0, 100)
return temperature
…
Dengan TaskFlow API, mudah untuk berbagi data antar tugas. Alih-alih langsung menggunakan XCom, nilai kembalian dari satu tugas (fungsi) dapat diteruskan langsung ke tugas lain sebagai argumen. Sepanjang proses ini, XCom tetap digunakan di balik layar, yang berarti sejumlah besar data tidak dapat dibagikan antar tugas bahkan saat menggunakan TaskFlow API.
Tell me more: TaskFlow API adalah bagian dari upaya Airflow untuk mempermudah penulisan DAG, membantu kerangka kerja ini menarik bagi audiens yang lebih luas seperti data scientist dan analis. Meskipun TaskFlow API tidak selalu memenuhi kebutuhan tim Data Engineering yang ingin mengintegrasikan ekosistem data cloud, API ini sangat berguna (dan intuitif) untuk tugas ETL dasar.
TaskFlow API dan operator tradisional dapat digunakan dalam DAG yang sama, menyediakan kemampuan integrasi operator tradisional dengan kemudahan penggunaan yang ditawarkan TaskFlow API. Untuk informasi lebih lanjut tentang TaskFlow API, lihat dokumentasi.
Jawaban: Idempoten adalah sifat suatu proses/operasi yang memungkinkan proses tersebut dilakukan berkali-kali tanpa mengubah hasil awal. Sederhananya, jika Anda menjalankan sebuah DAG sekali, atau menjalankannya sepuluh kali, hasilnya harus identik.
Salah satu alur kerja umum yang tidak demikian adalah saat menyisipkan data ke database terstruktur (SQL). Jika data disisipkan tanpa penegakan primary key dan DAG dijalankan berkali-kali, DAG ini akan menyebabkan duplikasi pada tabel hasil. Menggunakan pola seperti delete-insert atau “upsert” membantu menerapkan idempoten dalam pipeline data.
Tell me more: Ini tidak sepenuhnya spesifik Airflow, namun sangat penting untuk diingat saat merancang dan membangun pipeline data. Untungnya, Airflow menyediakan beberapa alat untuk mempermudah penerapan idempoten. Namun, sebagian besar logika ini perlu dirancang, dikembangkan, dan diuji oleh praktisi yang memanfaatkan Airflow untuk mengimplementasikan pipeline datanya.
Untuk peran yang lebih teknis, pewawancara mungkin mengajukan pertanyaan tentang mengelola dan memantau deployment Airflow tingkat produksi, mirip dengan yang mungkin mereka jalankan di tim mereka. Pertanyaan-pertanyaan ini sedikit lebih rumit dan memerlukan lebih banyak persiapan sebelum wawancara.
Jawaban: Ada beberapa cara untuk menguji DAG setelah ditulis. Yang paling umum adalah mengeksekusi DAG untuk memastikan bahwa ia berjalan dengan sukses. Ini dapat dilakukan dengan menyalakan lingkungan Airflow lokal dan menggunakan UI Airflow untuk memicu DAG.
Setelah DAG dipicu, ia dapat dipantau untuk memvalidasi performanya (baik keberhasilan/kegagalan DAG dan tugas individual, maupun waktu dan sumber daya yang diperlukan untuk menjalankannya).
Selain menguji DAG secara manual melalui eksekusi, DAG juga dapat diuji unit. Airflow menyediakan alat melalui CLI untuk menjalankan pengujian, atau Anda dapat menggunakan test runner standar. Pengujian unit ini dapat ditulis terhadap konfigurasi dan eksekusi DAG serta terhadap komponen lain dari proyek Airflow, seperti callable dan plugin.
Tell me more: Menguji DAG Airflow adalah salah satu hal terpenting yang dilakukan Data Engineer. Jika DAG belum diuji, ia belum siap mendukung workflow produksi.
Menguji pipeline data sangat rumit; ada kasus tepi dan sudut yang biasanya tidak ditemukan dalam skenario pengembangan lain. Dalam wawancara yang lebih teknis (terutama untuk Lead/Senior Engineer), pastikan untuk mengomunikasikan pentingnya menguji DAG end-to-end bersamaan dengan menulis pengujian unit dan mendokumentasikan hasil masing-masing.
Jawaban: Tidak ada yang menyukai kegagalan DAG, tetapi menanganinya dengan baik dapat membedakan Anda sebagai Data Engineer. Untungnya, Airflow menawarkan banyak alat untuk menangkap, memberi peringatan, dan memperbaiki kegagalan DAG. Pertama, kegagalan DAG ditangkap di UI Airflow. Status DAG akan berubah menjadi “failed,” dan tampilan grid akan menampilkan kotak/persegi panjang merah untuk run tersebut. Kemudian, log untuk tugas ini dapat diparsing secara manual di UI.
Biasanya, log ini akan memberikan pengecualian yang menyebabkan kegagalan dan memberikan informasi kepada Data Engineer untuk triase lebih lanjut.
Setelah masalah diidentifikasi, kode/konfigurasi yang mendasari DAG dapat diperbarui, dan DAG dapat dijalankan ulang. Ini dapat dilakukan dengan menghapus status DAG dan mengaturnya menjadi “active.”
Jika sebuah DAG sering gagal namun berhasil saat dicoba ulang, akan berguna menggunakan fungsionalitas retries dan retry_delay Airflow. Kedua parameter ini dapat digunakan untuk mencoba ulang tugas yang gagal sejumlah kali tertentu setelah menunggu periode waktu tertentu. Ini mungkin berguna pada skenario seperti mencoba menarik file dari situs SFTP yang mungkin terlambat mendarat.
Tell me more: Agar sebuah DAG gagal, sebuah tugas spesifik harus gagal. Penting untuk men-triase tugas ini alih-alih seluruh DAG. Selain fungsionalitas yang ada di UI, ada banyak alat lain untuk memantau dan mengelola performa DAG.
Callback menawarkan kustomisasi nyaris tak terbatas bagi Data Engineer saat menangani keberhasilan dan kegagalan DAG. Dengan callback, sebuah fungsi pilihan penulis DAG dapat dieksekusi ketika DAG berhasil atau gagal menggunakan parameter on_success_callback dan on_failure_callback dari sebuah operator. Fungsi ini dapat mengirim pesan ke alat seperti PagerDuty atau menulis hasil ke database untuk kemudian diberi peringatan. Ini membantu meningkatkan visibilitas dan mempercepat proses triase saat kegagalan terjadi.
Jawaban: Salah satu alat paling praktis di Airflow adalah “connections.” Connections memungkinkan penulis DAG menyimpan dan mengakses informasi koneksi (seperti host, username, password, dll.) tanpa harus menanamkan nilai-nilai ini ke dalam kode.
Ada beberapa cara untuk menyimpan connections; yang paling umum adalah menggunakan UI Airflow. Setelah sebuah connection dibuat, ia dapat diakses langsung di kode menggunakan “hook.” Namun, sebagian besar operator tradisional yang memerlukan interaksi dengan sistem sumber memiliki field conn_id (atau nama yang sangat mirip) yang menerima string dan membuat koneksi ke sumber yang diinginkan.
Airflow connections membantu menjaga informasi sensitif tetap aman dan memudahkan penyimpanan serta pengambilannya.
Tell me more: Selain menggunakan UI Airflow, CLI dapat digunakan untuk menyimpan dan mengambil connections. Di lingkungan perusahaan, lebih umum menggunakan “secrets backend” kustom untuk mengelola informasi koneksi. Airflow menyediakan sejumlah secrets backend yang didukung untuk mengelola connections. Perusahaan yang menggunakan AWS dapat dengan mudah mengintegrasikan Secrets Manager dengan Airflow untuk menyimpan dan mengambil informasi koneksi dan data sensitif. Jika diperlukan, connections juga dapat didefinisikan dalam variabel lingkungan proyek.
Jawaban: Melakukan deployment lingkungan Airflow agar berjalan di lingkungan tingkat produksi bisa jadi sulit. Alat cloud seperti Azure dan AWS menyediakan layanan terkelola untuk melakukan deployment dan mengelola Airflow. Namun, alat-alat ini memerlukan akun cloud dan mungkin cukup mahal.
Alternatif umum adalah menggunakan Kubernetes untuk melakukan deployment dan menjalankan lingkungan Airflow produksi. Ini memungkinkan kontrol penuh atas sumber daya yang mendasarinya namun disertai tanggung jawab tambahan untuk mengelola infrastruktur tersebut.
Di luar deployment cloud-native dan Kubernetes buatan sendiri, Astronomer adalah penyedia layanan terkelola Airflow paling populer di bidang ini.
Mereka menyediakan berbagai tooling open-source (CLI, SDK, banyak dokumentasi) selain penawaran PaaS “Astro” mereka untuk membuat pengembangan dan deployment Airflow semulus mungkin. Dengan Astro, alokasi sumber daya, kontrol akses platform, dan upgrade Airflow di tempat didukung secara native, sehingga fokus kembali pada pengembangan pipeline.
Meskipun pertanyaan berbasis skenario tidak terlalu teknis, ini adalah beberapa pertanyaan terpenting dalam wawancara Airflow. Memberikan jawaban yang terperinci dan matang menunjukkan kompetensi mendalam tidak hanya pada Airflow tetapi juga pada prinsip arsitektur dan desain data.
Jawaban: Ini yang menyenangkan! Dengan pertanyaan seperti ini, dunia ada di ujung jari Anda. Hal terpenting adalah ini — saat menjelaskan prosesnya, pastikan untuk memilih alat dan proses dalam pipeline data warisan yang Anda kenal. Ini menunjukkan keahlian Anda dan akan membuat jawaban Anda lebih berbobot.
Ini juga kesempatan sempurna untuk memamerkan keterampilan manajemen proyek dan kepemimpinan Anda. Sebutkan bagaimana Anda akan menyusun proyek, berinteraksi dengan pemangku kepentingan dan engineer lain, serta mendokumentasikan/mengomunikasikan proses. Ini menunjukkan penekanan pada pemberian nilai dan memudahkan pekerjaan tim Anda.
Jika sebuah perusahaan memiliki alat tertentu dalam stack mereka (misalnya Google BigQuery), akan masuk akal untuk membahas bagaimana Anda dapat merombak proses ini untuk beralih dari sesuatu seperti Postgres ke BigQuery. Ini membantu menunjukkan kesadaran dan pengetahuan tidak hanya tentang Airflow tetapi juga komponen lain dari infrastruktur perusahaan.
Jawaban: Untuk merancang DAG ini, Anda terlebih dahulu perlu memanggil API untuk mengekstrak data. Ini dapat dilakukan menggunakan PythonOperator dan callable kustom. Di dalam callable tersebut, Anda juga ingin menyimpan data ke lokasi penyimpanan cloud, seperti AWS S3.
Setelah data ini disimpan, Anda dapat memanfaatkan operator yang sudah tersedia, seperti S3ToSnowflakeOperator, untuk memuat data dari S3 ke gudang data Snowflake. Terakhir, pekerjaan DBT dapat dijalankan untuk mentransformasi data ini menggunakan DbtCloudRunJobOperator.
Anda perlu menjadwalkan DAG ini agar berjalan pada interval yang diinginkan dan mengonfigurasinya untuk menangani kegagalan secara elegan (namun tetap terlihat). Lihat diagram di bawah!
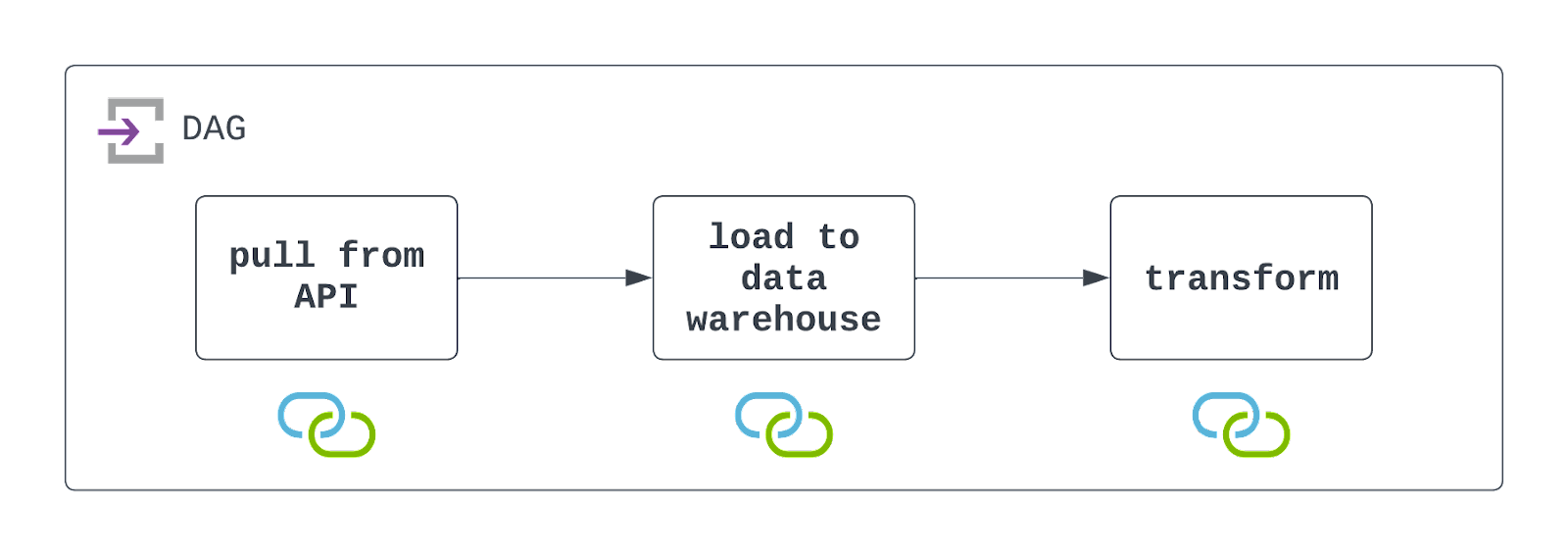
Perlu diingat bahwa Airflow berinteraksi dengan sistem file penyimpanan cloud serta gudang data. Agar DAG ini berhasil dieksekusi, sumber daya tersebut harus ada, dan connections harus didefinisikan serta digunakan. Ini ditandai oleh ikon di bawah setiap tugas pada diagram arsitektur di atas.
Tell me more: Ini adalah beberapa pertanyaan wawancara Airflow yang paling umum, lebih berfokus pada desain dan implementasi DAG tingkat tinggi, daripada detail teknis yang rinci. Untuk pertanyaan-pertanyaan seperti ini, penting untuk mengingat beberapa hal:
DbtCloudRunJobOperator, sebutkan alat ini, tetapi tidak perlu mengelaborasi lebih jauh (kecuali diminta).Jawaban: Ekstensibilitas Airflow dan popularitasnya yang kian meningkat di komunitas data menjadikannya alat andalan bukan hanya bagi Data Engineer. Data Scientist dan Machine Learning Engineer menggunakan Airflow untuk melatih (dan melatih ulang) model mereka, serta melakukan rangkaian lengkap MLOps. AI Engineer bahkan mulai menggunakan Airflow untuk mengelola dan menskalakan model AI generatif mereka, dengan integrasi baru untuk alat seperti OpenAI, OpenSearch, dan Pinecone.
Tell me more: Berkembang di luar pipeline data engineering tradisional mungkin bukan sesuatu yang dibayangkan pencipta awal Airflow. Namun, dengan memanfaatkan Python dan filosofi open-source, Airflow telah tumbuh untuk memenuhi kebutuhan ruang data/AI yang berkembang pesat. Ketika tugas-tugas terprogram perlu dijadwalkan dan dieksekusi, Airflow bisa jadi alat terbaik untuk pekerjaan itu!
Kerja bagus! Anda sudah melewatinya. Pertanyaan-pertanyaan di atas menantang namun mencakup banyak hal yang ditanyakan dalam wawancara teknis yang berfokus pada Airflow.
Selain mengulang pertanyaan-pertanyaan di atas, salah satu cara terbaik untuk mempersiapkan wawancara Airflow adalah membangun pipeline data Anda sendiri menggunakan Airflow.
Temukan dataset yang menarik bagi Anda, dan mulai bangun pipeline ETL (atau ELT) dari nol. Berlatihlah menggunakan TaskFlow API dan operator tradisional. Simpan informasi sensitif menggunakan Airflow connections. Cobalah pelaporan kegagalan menggunakan callback, dan uji DAG Anda dengan unit test dan end-to-end. Yang terpenting, dokumentasikan dan bagikan pekerjaan yang Anda lakukan.
Sebuah proyek seperti ini membantu menunjukkan tidak hanya kompetensi pada Airflow, tetapi juga hasrat dan keinginan untuk belajar dan berkembang. Jika Anda masih memerlukan pengantar tentang beberapa prinsip dasar, Anda dapat melihat kursus Introduction to Airflow in Python, perbandingan Airflow vs Prefect, dan tutorial Getting Started with Apache Airflow kami.
Semoga sukses, dan selamat ngoding!
Lanjutkan Perjalanan Data Engineering Anda Hari Ini!
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
