
Cursus
Ingénieur de données en Python
40 h
Lors d'un entretien technique, les enquêteurs commenceront généralement par des questions simples, en se concentrant sur les bases du cadre et des concepts fondamentaux d'Airflow, avant de passer à des questions plus complexes et plus techniques.
Lorsque vous répondez à ces questions, veillez à ne pas vous contenter d'aborder les détails techniques, mais mentionnez également la manière dont cela pourrait s'intégrer dans un processus d'ingénierie des données et/ou de gestion des données de l'entreprise.
Réponse : Apache Airflow est un outil d'orchestration de données open-source qui permet aux praticiens des données de définir des pipelines de données de manière programmatique à l'aide de Python. Airflow est le plus souvent utilisé par les équipes d'ingénierie des données pour intégrer leur écosystème de données et extraire, transformer et charger les données.
Dites-m'en plus : Airflow est maintenu sous la licence logicielle Apache (d'où le préfixe "Apache").
Un outil d'orchestration des données offre des fonctionnalités permettant d'intégrer plusieurs sources et services dans un seul pipeline.
Ce qui distingue Airflow en tant qu'outil d'orchestration de données est son utilisation de Python pour définir les pipelines de données, ce qui offre un niveau d'extensibilité et de contrôle que les autres outils d'orchestration de données ne parviennent pas à offrir. Airflow dispose d'un certain nombre d'outils intégrés et soutenus par les fournisseurs pour intégrer la pile de données de n'importe quelle équipe, ainsi que la possibilité de concevoir votre propre pile.
Pour plus d'informations sur l'utilisation d'Airflow, consultez ce tutoriel de DataCamp : Premiers pas avec Apache Airflow. Si vous souhaitez plonger encore plus profondément dans le monde de l'orchestration des données avec Airflow, ce cours d'introduction à Airflow est le meilleur point de départ.
Réponse : Un DAG (directed-acyclic graph) est un ensemble de tâches et de relations entre ces tâches. Un DAG a un début et une fin clairs et ne comporte pas de "cycles" entre ces tâches. Lorsque vous utilisez Airflow, le terme "DAG" est couramment utilisé et peut être considéré comme un pipeline de données.
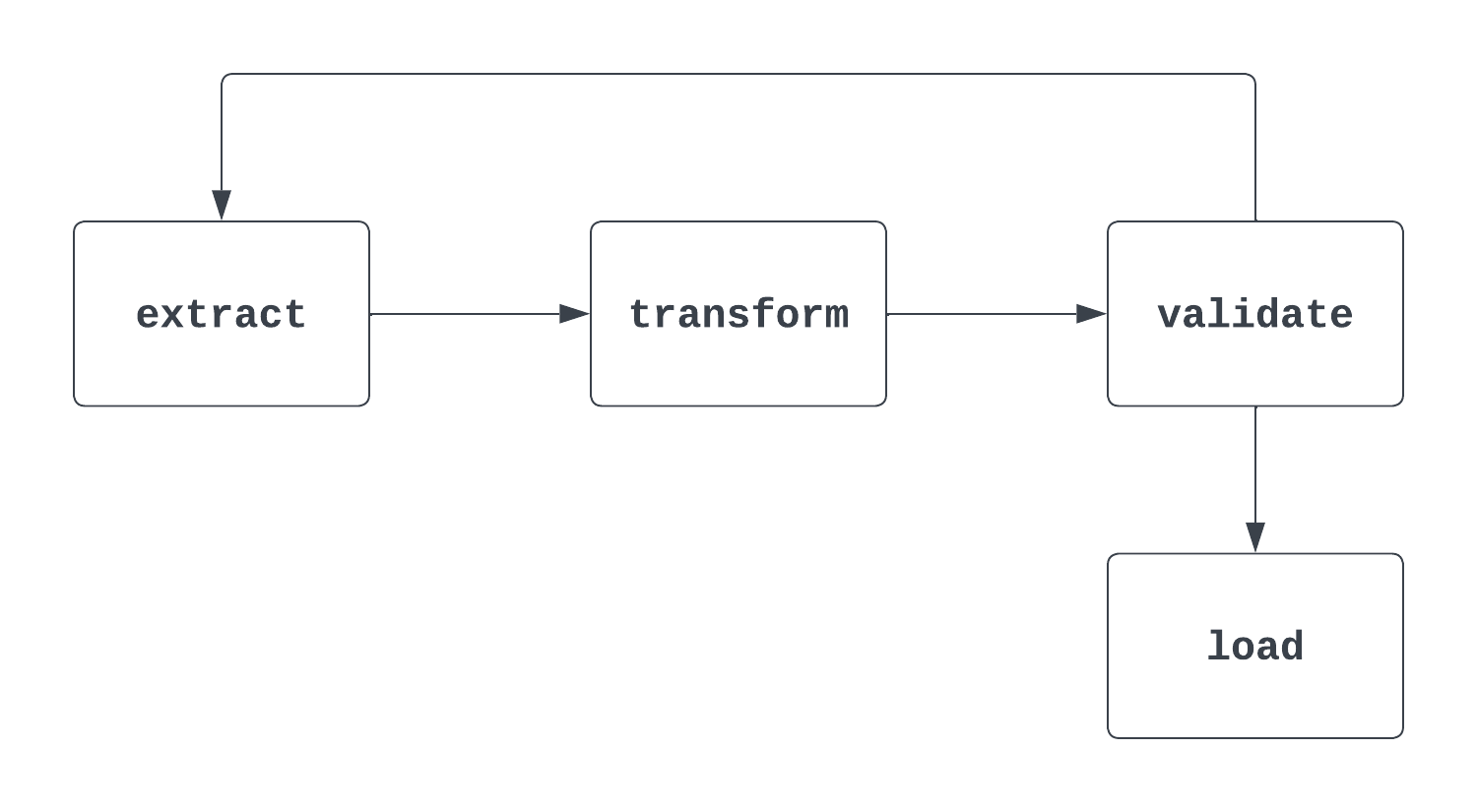
Dites-m'en plus : C'est une question délicate. Lorsqu'un interlocuteur pose cette question, il est important de répondre à la fois à la définition "mathématique" formelle d'un DAG et à la façon dont il est utilisé dans Airflow. Lorsque l'on réfléchit aux DAG, il est utile d'avoir un visuel. La première image ci-dessous est en fait un DAG. Il a un début et une fin clairs et ne comporte pas de cycles entre les tâches.

Le deuxième processus illustré ci-dessous n'est PAS un DAG. Si la tâche de démarrage est clairement définie, il existe un cycle entre les tâches d'extraction et de validation, ce qui ne permet pas de savoir à quel moment la tâche de chargement peut être déclenchée.
Réponse : Pour définir un DAG, vous devez fournir un identifiant, une date de début et un intervalle de planification.
Dites-m'en plus : L'ID identifie de manière unique le DAG et est généralement une chaîne courte, telle que "sample_da.". La date de début est la date et l'heure du premier intervalle auquel un DAG sera déclenché.
Il s'agit d'un horodatage, ce qui signifie que l'année, le mois, le jour, l'heure et les minutes sont spécifiés. L'intervalle de planification indique la fréquence à laquelle le DAG doit être exécuté. Cela peut être chaque semaine, chaque jour, chaque heure, ou quelque chose de plus personnalisé.
Dans cet exemple, le DAG a été défini à l'aide d'un site dag_id de "sample_dag". La fonction datetime de la bibliothèque datetime est utilisée pour fixer la date de début au 1er janvier 2024, à 9h00. Ce DAG s'exécutera tous les jours (à 9h00), comme indiqué par l'intervalle programmé @daily. Des intervalles plus personnalisés peuvent être définis à l'aide d'expressions cron ou de la fonction timedelta de la bibliothèque datetime.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Réponse : Les tâches Airflow sont la plus petite unité d'exécution dans le cadre d'Airflow. Une tâche encapsule généralement une opération unique dans un pipeline de données (DAG). Les tâches sont les éléments constitutifs des DAG, et les tâches au sein d'un DAG ont des relations entre elles qui déterminent l'ordre dans lequel elles sont exécutées. Voici trois exemples de tâches :
Dans un pipeline ETL, les relations seraient les suivantes :
Dites-m'en plus : Les tâches peuvent être très génériques ou très personnalisées. Airflow propose deux façons de définir ces tâches : les opérateurs traditionnels et l'API TaskFlow (nous y reviendrons).
L'un des avantages de l'open-source est la contribution de la communauté élargie, qui se compose non seulement de contributeurs individuels, mais aussi d'acteurs tels qu'AWS, Databricks, Snowflake, et bien d'autres encore.
Il y a de fortes chances qu'un opérateur Airflow ait déjà été conçu pour la tâche que vous souhaitez définir. Si ce n'est pas le cas, il est facile de créer le vôtre. Quelques exemples d'opérateurs Airflow sont SFTPToS3Operator, S3ToSnowflakeOperator, et DatabricksRunNowOperator.
Réponse : L'architecture d'Airflow est composée de quatre éléments principaux : le planificateur, l'exécuteur, la base de données de métadonnées et le serveur web.
Dites-m'en plus : L'ordonnanceur vérifie le répertoire des DAG toutes les minutes et surveille les DAG et les tâches afin d'identifier toute tâche pouvant être déclenchée. Un exécuteur est l'endroit où les tâches sont exécutées. Les tâches peuvent être exécutées localement (au sein de l'ordonnanceur) ou à distance (en dehors de l'ordonnanceur).
L'exécuteur est l'endroit où s'effectue le "travail" de calcul que chaque tâche requiert. La base de données de métadonnées contient toutes les informations sur les DAG et les tâches liées au projet Airflow que vous exécutez. Il s'agit d'informations telles que l'historique des détails d'exécution, les connexions, les variables et toute une série d'autres informations.
Le serveur web permet d'afficher l'interface utilisateur d'Airflow et d'interagir avec elle lors du développement, de l'interaction et de la maintenance des DAG.
Il ne s'agit là que d'un aperçu rapide des principaux composants architecturaux d'Airflow.
Vous avez clairement indiqué que vous connaissiez les bases du framework Airflow et de son architecture. Il est maintenant temps de tester vos connaissances en matière de création de DAG.
PythonOperator? Quelles sont les conditions requises pour utiliser cet opérateur ? Quel est l'exemple d'une situation dans laquelle vous souhaiteriez utiliser la fonction PythonOperator?Réponse : Le site PythonOperator est une fonction qui permet d'exécuter une fonction Python en tant que tâche Airflow. Pour utiliser cet opérateur, une fonction Python doit être passée au paramètre python_callable. Un exemple où vous voudriez utiliser un opérateur Python est lorsque vous utilisez une API pour extraire des données.
Dites-m'en plus : Le PythonOperator est l'un des opérateurs les plus puissants proposés par Airflow. Il permet non seulement d'exécuter un code personnalisé dans un DAG, mais aussi d'écrire les résultats dans des XComs pour les utiliser dans des tâches en aval.
En passant un dictionnaire au paramètre op_kwargs, des arguments de type mot-clé peuvent être passés à l'appelable Python, ce qui permet une personnalisation encore plus poussée au moment de l'exécution. En plus de op_kwargs, il existe un certain nombre de paramètres supplémentaires qui permettent d'étendre la fonctionnalité de PythonOperator.
Vous trouverez ci-dessous un exemple d'appel de PythonOperator. En règle générale, la fonction Python transmise à python_callable est définie en dehors du fichier contenant la définition du DAG. Cependant, il a été inclus ici pour des raisons de verbosité.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Réponse : Il existe plusieurs façons de procéder. L'une des méthodes les plus courantes consiste à utiliser l'opérateur de décalage de bits >>. Une autre méthode consiste à utiliser la méthode .set_downstream() pour placer une tâche en aval d'une autre. La fonction chain est un autre outil utile pour définir des dépendances séquentielles entre les tâches. Voici trois exemples de cette démarche :
# task_1, task_2, task_3 instantiated above
# Using bit-shift operators
task_1 >> task_2 >> task_3
# Using .set_downstream()
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# Using chain
chain(task_1, task_2, task_3)
Dites-m'en plus : La définition des dépendances peut être simple, tandis que d'autres peuvent s'avérer très complexes ! Pour l'exécution séquentielle, il est courant d'utiliser les opérateurs de décalage de bits pour rendre le processus plus verbeux. Lorsque vous utilisez l'API TaskFlow, la définition des dépendances entre les tâches peut être légèrement différente.
S'il y a deux tâches dépendantes, on peut l'indiquer en passant un appel de fonction à une autre fonction, plutôt qu'en utilisant les techniques mentionnées ci-dessus. Vous pouvez en savoir plus sur les dépendances des tâches Airflow dans un autre article.
Réponse : Les groupes de tâches sont utilisés pour organiser les tâches ensemble au sein d'un DAG. Il est ainsi plus facile de regrouper des tâches similaires dans l'interface Airflow. Il peut être utile d'utiliser des groupes de tâches lors de l'extraction, de la transformation et du chargement de données appartenant à différentes équipes dans le même DAG.
Les groupes de tâches sont également couramment utilisés lorsqu'il s'agit d'entraîner plusieurs modèles ML ou d'interagir avec plusieurs systèmes sources (mais similaires) dans un seul DAG.
Lorsque vous utilisez des groupes de tâches dans Airflow, la vue graphique résultante peut ressembler à ceci :
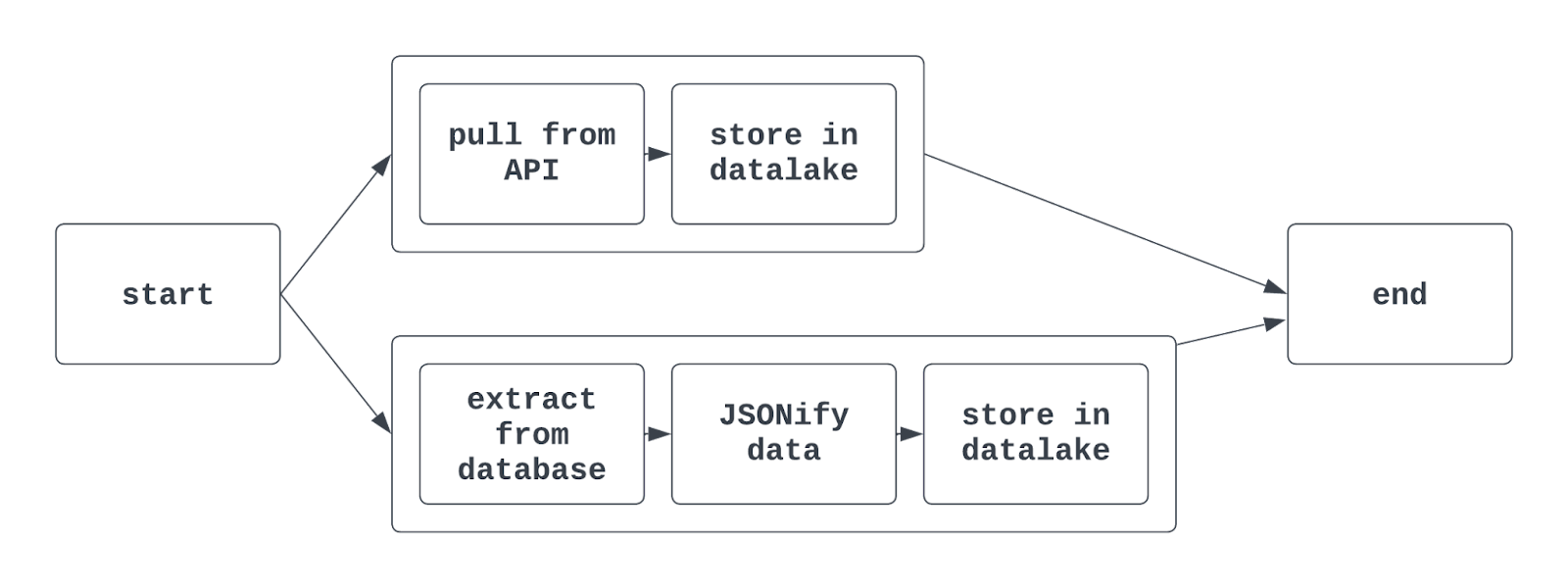
Dites-m'en plus : En utilisant la syntaxe traditionnelle d'Airflow, la fonction TaskGroup est utilisée pour créer des groupes de tâches. Les groupes de tâches peuvent être générés explicitement ou dynamiquement, mais doivent avoir des identifiants uniques (comme pour les DAG).
Cependant, différents groupes de tâches dans le même DAG peuvent avoir des tâches avec le même task_id. La tâche sera alors identifiée de manière unique par la combinaison de l'ID du groupe de tâches et de l'ID de la tâche. Lorsque vous utilisez l'API TaskFlow, le décorateur @task_group peut également être utilisé pour créer un groupe de tâches.
Réponse : La génération dynamique de DAG est une technique pratique qui permet de créer plusieurs DAG à l'aide d'un seul "morceau" de code. L'extraction de données à partir de plusieurs sites est un exemple de l'utilité de la création dynamique de DAG. Si vous devez extraire, transformer et charger des données provenant de trois aéroports en utilisant la même logique, la génération dynamique de DAG permet de rationaliser ce processus.
Il y a plusieurs façons de procéder. L'une des solutions les plus simples consiste à utiliser une liste de métadonnées qui peut être parcourue en boucle. Ensuite, dans la boucle, un DAG peut être instancié. Il est important de se rappeler que chaque DAG doit avoir un identifiant unique. Le code pour ce faire pourrait ressembler à ceci :
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# Rest of the DAG definition
...
Ce code génère trois DAG, dont les ID sont atl_daily_etl, lax_daily_etl et jfk_daily_etl. En aval, les tâches pourraient être paramétrées en utilisant le même code d'aéroport pour s'assurer que chaque DAG s'exécute comme prévu.
Dites-m'en plus : La génération dynamique de DAG est une technique couramment utilisée dans les entreprises. Lorsque vous décidez de créer par programme des groupes de tâches dans un seul DAG ou de générer dynamiquement des DAG, il est important de penser aux relations entre les opérations.
Dans notre exemple ci-dessus, si un seul aéroport est à l'origine d'une exception, l'utilisation de groupes de tâches entraînerait l'échec de l'ensemble du DAG. Mais si les DAG sont générés dynamiquement, ce point de défaillance unique n'entraînera pas la défaillance des deux autres DAG.
Boucler sur un itérable Python n'est pas le seul moyen de générer dynamiquement des DAG - définir une fonction create_dag, utiliser des variables/connexions pour générer des DAG, ou tirer parti d'un fichier de configuration JSON sont des options couramment utilisées pour atteindre le même objectif. Des outils tiers tels que gusty et dag-factory fournissent des approches supplémentaires basées sur la configuration pour générer dynamiquement des DAG.
Comprendre et communiquer les bases de l'Airflow et du développement des DAG est souvent suffisant pour répondre aux attentes d'un poste de niveau junior dans le domaine des données. Mais la maîtrise d'Airflow ne se limite pas à l'écriture et à l'exécution de DAG.
Les questions et réponses ci-dessous vous aideront à montrer à votre interlocuteur une compréhension plus approfondie des fonctionnalités plus complexes d'Airflow, ce qui est généralement nécessaire pour les postes plus importants.
data_interval_start et data_interval_end, Quand un DAG est-il exécuté ?Réponse : Comme son nom l'indique, data_interval_start et data_interval_end sont les limites temporelles de l'exécution du DAG. Si un DAG est en cours de remplissage et que la durée d'exécution du DAG est supérieure à data_interval_end, le DAG sera immédiatement mis en file d'attente.
Cependant, pour une exécution "normale", un DAG ne s'exécutera pas tant que la durée d'exécution ne sera pas supérieure à **data_interval_end**.
Dites-m'en plus : Il s'agit d'un concept difficile, notamment en raison de la manière dont les séries de DAG sont étiquetées. Voici une bonne façon d'y réfléchir. Vous souhaitez extraire toutes les données relatives au 17 mars 2024 à partir d'une API.
Si l'intervalle de planification est quotidien, l'adresse data_interval_start pour cette exécution est 2024-03-17, 00:00:00 UTC, et l'adresse data_interval_end est 2024-03-18, 00:00:00 UTC. Il serait absurde d'exécuter ce DAG à 2024-03-17, 00:00:00 UTC, car aucune des données ne serait présente pour le 17 mars. Au lieu de cela, le DAG est exécuté à l'adresse data_interval_end le 2024-03-18, 00:00:00 UTC.
Réponse : Le paramètre catchup est défini lors de l'instanciation d'un DAG. catchup prend la valeur True ou False, et par défaut True s'il n'est pas spécifié. Si True, toutes les exécutions de DAG entre la date de début et le moment où le statut du DAG a été modifié pour la première fois en actif seront exécutées.
Supposons que la date de démarrage d'un DAG soit fixée au 1er janvier 2024, avec un intervalle de programmation quotidien et catchup=True. Si la date actuelle est le 15 avril 2024, lorsque ce DAG est activé pour la première fois, l'exécution du DAG avec data_interval_start le 1er janvier 2024 sera exécutée, suivie de l'exécution du DAG pour le 2 janvier 2024 (et ainsi de suite).
Cette opération se poursuivra jusqu'à ce que le DAG soit "rattrapé" et qu'il reprenne son comportement normal. C'est ce qu'on appelle le "remblayage". Le remblayage peut se faire assez rapidement. Si votre exécution DAG ne prend que quelques minutes, quelques mois d'exécutions DAG historiques peuvent être exécutés en quelques heures seulement.
Si False, aucune exécution historique de DAG ne sera exécutée, et la première exécution commencera à la fin de l'intervalle pendant lequel l'état DAG a été défini comme étant en cours d'exécution.
Dites-m'en plus : L'une des fonctionnalités les plus puissantes d'Airflow est la possibilité d'effectuer des remplissages de DAG sans modification significative du code ni effort manuel. Supposons que vous travailliez sur une intégration pour extraire toutes les transactions d'une API pour l'année écoulée.
Une fois que vous avez construit votre DAG, il vous suffit de définir la date de début souhaitée et catchup=True, et il est facile de récupérer ces données historiques.
Si vous ne souhaitez pas remplir votre DAG lorsqu'il est activé pour la première fois, ne vous inquiétez pas ! Il existe un certain nombre d'autres moyens de déclencher systématiquement des remblais. Cela peut être fait avec l'API Airflow et le CLI Airflow (et Astro).
Réponse : Les XComs (pour cross-communications) sont une fonctionnalité plus nuancée d'Airflow qui permet de stocker et d'extraire des messages entre les tâches.
Les XComs sont stockés dans des paires clé-valeur et peuvent être lus et écrits de plusieurs manières. Lorsque vous utilisez PythonOperator, les méthodes .xcom_push() et .xcom_pull() peuvent être utilisées dans l'objet appelable pour "pousser" et "tirer" des données de XComs. Les XComs sont utilisés pour stocker de petites quantités de données, telles que des noms de fichiers ou un indicateur booléen.
Dites-m'en plus : Outre l'utilisation des sites .xcom_push() et .xcom_pull(), il existe un certain nombre d'autres moyens d'écrire et de lire des données à partir de XComs. Lorsque vous utilisez PythonOperator, le fait de passer True aux paramètres do_xcom_push écrit la valeur renvoyée par l'appelant dans XComs.
Cela ne se limite pas à PythonOperator; tout opérateur qui renvoie une valeur peut voir cette valeur écrite dans XComs à l'aide du paramètre do_xcom_push. En coulisses, l'API TaskFlow utilise également les XComs pour partager des données entre les tâches (nous y reviendrons).
Pour plus d'informations sur les XComs, consultez le blog du légendaire Airflow, Marc Lamberti.
Réponse : L'API TaskFlow offre une nouvelle façon d'écrire des DAG d'une manière plus intuitive, plus "Python". Plutôt que d'utiliser des opérateurs traditionnels, les fonctions Python sont décorées avec le décorateur @task, et peuvent déduire des dépendances entre les tâches sans les définir explicitement.
Une tâche rédigée à l'aide de l'API TaskFlow peut ressembler à ceci :
import random
...
@task
def get_temperature():
# Pull a temperature, return the value
temperature = random.randint(0, 100)
return temperature
…
Avec l'API TaskFlow, il est facile de partager des données entre les tâches. Plutôt que d'utiliser directement les XComs, la valeur de retour d'une tâche (fonction) peut être transmise directement à une autre tâche en tant qu'argument. Tout au long de ce processus, les XComs sont toujours utilisés en coulisses, ce qui signifie que de grandes quantités de données ne peuvent pas être partagées entre les tâches, même en utilisant l'API TaskFlow.
Dites-m'en plus : L'API TaskFlow s'inscrit dans la volonté d'Airflow de faciliter l'écriture de DAG, ce qui permet au framework de séduire un public plus large de data scientists et d'analystes. Si l'API TaskFlow ne répond pas aux besoins des équipes d'ingénierie des données qui cherchent à intégrer un écosystème de données dans le cloud, elle est particulièrement utile (et intuitive) pour les tâches ETL de base.
L'API TaskFlow et les opérateurs traditionnels peuvent être utilisés dans le même DAG, offrant l'intégrabilité des opérateurs traditionnels avec la facilité d'utilisation de l'API TaskFlow. Pour plus d'informations sur l'API TaskFlow, consultez la documentation.
Réponse : L'idempotence est une propriété d'un processus/opération qui permet à ce processus d'être exécuté plusieurs fois sans changer le résultat initial. Plus simplement, si vous exécutez un DAG une fois, ou si vous l'exécutez dix fois, les résultats devraient être identiques.
L'insertion de données dans des bases de données structurées (SQL) est un cas courant où ce n'est pas le cas. Si des données sont insérées sans application d'une clé primaire et qu'un DAG est exécuté plusieurs fois, ce DAG provoquera des doublons dans le tableau résultant. L'utilisation de modèles tels que la suppression-insertion ou l'"upsert" permet de mettre en œuvre l'idempotence dans les pipelines de données.
Dites-m'en plus : Celle-ci n'est pas tout à fait spécifique à Airflow, mais il est essentiel de la garder à l'esprit lors de la conception et de la construction de pipelines de données. Heureusement, Airflow fournit plusieurs outils pour faciliter la mise en œuvre de l'idempotence. Cependant, la plupart de cette logique devra être conçue, développée et testée par le praticien qui utilise Airflow pour mettre en œuvre son pipeline de données.
Pour les postes plus techniques, un intervieweur pourrait poser des questions sur la gestion et la surveillance d'un déploiement Airflow de niveau production, similaire à celui qu'il pourrait exécuter dans son équipe. Ces questions sont un peu plus délicates et nécessitent un peu plus de préparation avant l'entretien.
Réponse : Il existe plusieurs façons de tester un DAG après son écriture. La méthode la plus courante consiste à exécuter un DAG pour s'assurer qu'il fonctionne correctement. Vous pouvez le faire en créant un environnement Airflow local et en utilisant l'interface utilisateur Airflow pour déclencher le DAG.
Une fois que le DAG a été déclenché, il peut être contrôlé pour valider ses performances (succès/échec du DAG et des tâches individuelles, ainsi que le temps et les ressources nécessaires à son exécution).
Outre le test manuel du DAG via l'exécution, les DAG peuvent faire l'objet d'un test unitaire. Airflow fournit des outils via le CLI pour exécuter les tests, ou un programme de test standard peut être utilisé. Ces tests unitaires peuvent être écrits à la fois sur la configuration et l'exécution du DAG ainsi que sur d'autres composants d'un projet Airflow, comme les callables et les plugins.
Dites-m'en plus : Tester les DAG Airflow est l'une des tâches les plus importantes d'un ingénieur des données. Si un DAG n'a pas été testé, il n'est pas prêt à prendre en charge les flux de production.
Les tests de pipelines de données sont particulièrement délicats ; il existe des cas limites et des cas particuliers que l'on ne retrouve généralement pas dans d'autres scénarios de développement. Lors d'un entretien plus technique (en particulier pour un ingénieur principal), assurez-vous de communiquer l'importance de tester un DAG de bout en bout en même temps que d'écrire des tests unitaires et de documenter les résultats de chacun d'entre eux.
Réponse : Personne n'aime les pannes de DAG, mais les gérer avec élégance peut vous distinguer en tant qu'ingénieur des données. Heureusement, Airflow offre une pléthore d'outils pour capturer, alerter et remédier aux défaillances des DAG. Tout d'abord, la défaillance d'un DAG est capturée dans l'interface utilisateur Airflow. L'état du DAG passe à "failed" (échec) et la grille affiche un carré/rectangle rouge pour cette exécution. Ensuite, les journaux de cette tâche peuvent être analysés manuellement dans l'interface utilisateur.
En général, ces journaux indiquent l'exception à l'origine de la défaillance et fournissent à l'ingénieur des données des informations qui lui permettent d'effectuer un triage plus approfondi.
Une fois le problème identifié, le code/la configuration sous-jacente du DAG peut être mis à jour et le DAG peut être réexécuté. Pour ce faire, il suffit d'effacer l'état du DAG et de le rendre "actif".
Si un DAG échoue régulièrement mais fonctionne lorsqu'il est réessayé, il peut être utile d'utiliser les fonctionnalités retries et retry_delay d'Airflow. Ces deux paramètres peuvent être utilisés pour réessayer une tâche en cas d'échec un certain nombre de fois après avoir attendu un certain temps. Cela peut s'avérer utile dans des scénarios tels que l'extraction d'un fichier à partir d'un site SFTP qui peut être en retard dans l'atterrissage.
Dites-m'en plus : Pour qu'un DAG échoue, il faut qu'une tâche spécifique échoue. Il est important de trier cette tâche plutôt que l'ensemble du DAG. Outre les fonctionnalités intégrées à l'interface utilisateur, il existe des tonnes d'autres outils pour surveiller et gérer les performances des DAG.
Les rappels offrent aux ingénieurs de données une personnalisation pratiquement illimitée de la gestion des succès et des échecs des DAG. Grâce aux rappels, une fonction choisie par l'auteur du DAG peut être exécutée lorsqu'un DAG réussit ou échoue en utilisant les paramètres on_success_callback et on_failure_callback d'un opérateur. Cette fonction peut envoyer un message à un outil tel que PagerDuty ou écrire le résultat dans une base de données pour être alerté ultérieurement. Cela permet d'améliorer la visibilité et de lancer le processus de triage lorsqu'une défaillance se produit.
Réponse : L'un des outils les plus pratiques d'Airflow est celui des "connexions". Les connexions permettent à l'auteur d'un DAG de stocker et d'accéder aux informations de connexion (telles que l'hôte, le nom d'utilisateur, le mot de passe, etc.
Il y a plusieurs façons de stocker les connexions, la plus courante étant d'utiliser l'interface utilisateur d'Airflow. Une fois qu'une connexion a été créée, il est possible d'y accéder directement dans le code à l'aide d'un "crochet". Cependant, la plupart des opérateurs traditionnels nécessitant une interaction avec un système source disposent d'un champ conn_id (ou d'un nom très similaire) qui prend une chaîne et crée une connexion avec la source souhaitée.
Les connexions de flux d'air permettent de sécuriser les informations sensibles et facilitent le stockage et la récupération de ces informations.
Dites-m'en plus : En plus de l'interface utilisateur Airflow, le CLI peut être utilisé pour stocker et récupérer des connexions. Dans une entreprise, il est plus courant d'utiliser un "backend secrets" personnalisé pour gérer les informations de connexion. Airflow fournit un certain nombre de secrets de support pour gérer les connexions. Une entreprise utilisant AWS peut facilement intégrer Secrets Manager à Airflow pour stocker et récupérer des informations de connexion et des informations sensibles. Si nécessaire, les connexions peuvent également être définies dans les variables d'environnement d'un projet.
Réponse : Le déploiement d'un environnement Airflow dans un environnement de production peut s'avérer difficile. Les outils cloud tels qu'Azure et AWS fournissent des services gérés pour déployer et gérer un déploiement Airflow. Toutefois, ces outils nécessitent un compte cloud et peuvent être quelque peu onéreux.
Une alternative courante consiste à utiliser Kubernetes pour déployer et exécuter un environnement Airflow de production. Cela permet un contrôle total des ressources sous-jacentes, mais s'accompagne de la responsabilité supplémentaire de la gestion de cette infrastructure.
Si l'on regarde en dehors des déploiements Kubernetes cloud-native et homegrown, Astronomer est le fournisseur de services gérés d'Airflow le plus populaire dans l'espace.
Ils fournissent un certain nombre d'outils open-source (CLI, SDK, beaucoup de documentation) en plus de leur offre PaaS "Astro" pour rendre le développement et le déploiement d'Airflow aussi facile que possible. Avec Astro, l'allocation des ressources, le contrôle de l'accès à la plateforme et les mises à niveau Airflow en place sont pris en charge de manière native, ce qui permet de se concentrer à nouveau sur le développement du pipeline.
Bien que les questions basées sur des scénarios ne soient pas trop techniques, elles font partie des questions les plus importantes lors d'un entretien Airflow. Fournir des réponses détaillées et bien pensées démontre une grande compétence non seulement avec Airflow mais aussi avec l'architecture des données et les principes de conception.
Réponse : C'est très amusant ! Avec une telle question, le monde est à portée de main. La chose la plus importante est la suivante : lorsque vous parcourez le processus, assurez-vous de choisir des outils et des processus dans le pipeline de données patrimoniales que vous connaissez bien. Cela démontre votre expertise et rendra votre réponse à votre question plus éclairée.
C'est l'occasion idéale de montrer vos compétences en matière de gestion de projet et de leadership. Mentionnez comment vous allez structurer le projet, interagir avec les parties prenantes et les autres ingénieurs, et documenter/communiquer les processus. Cela montre que vous mettez l'accent sur la valeur ajoutée et que vous facilitez la vie de votre équipe.
Si une entreprise dispose d'un certain outil dans sa pile (par exemple, Google BigQuery), il peut être judicieux de discuter de la manière dont vous pouvez remanier ce processus pour passer d'un outil comme Postgres à BigQuery. Cela permet de montrer la sensibilisation et la connaissance non seulement d'Airflow mais aussi d'autres composants de l'infrastructure d'une entreprise.
Réponse : Pour concevoir ce DAG, vous devrez d'abord utiliser l'API pour extraire des données. Pour ce faire, vous pouvez utiliser le site PythonOperator et une fonction d'appel personnalisée. Dans cet appel, vous voudrez également persister les données vers un emplacement de stockage dans le cloud, tel qu'AWS S3.
Une fois que ces données ont été persistées, vous pouvez tirer parti d'un opérateur préconstruit, tel que S3ToSnowflakeOperator, pour charger les données de S3 dans un entrepôt de données Snowflake. Enfin, un travail DBT peut être exécuté pour transformer ces données à l'aide du site DbtCloudRunJobOperator.
Vous devrez planifier l'exécution de ce DAG à l'intervalle souhaité et le configurer de manière à ce qu'il gère les défaillances avec élégance (mais avec visibilité). Consultez le diagramme ci-dessous !
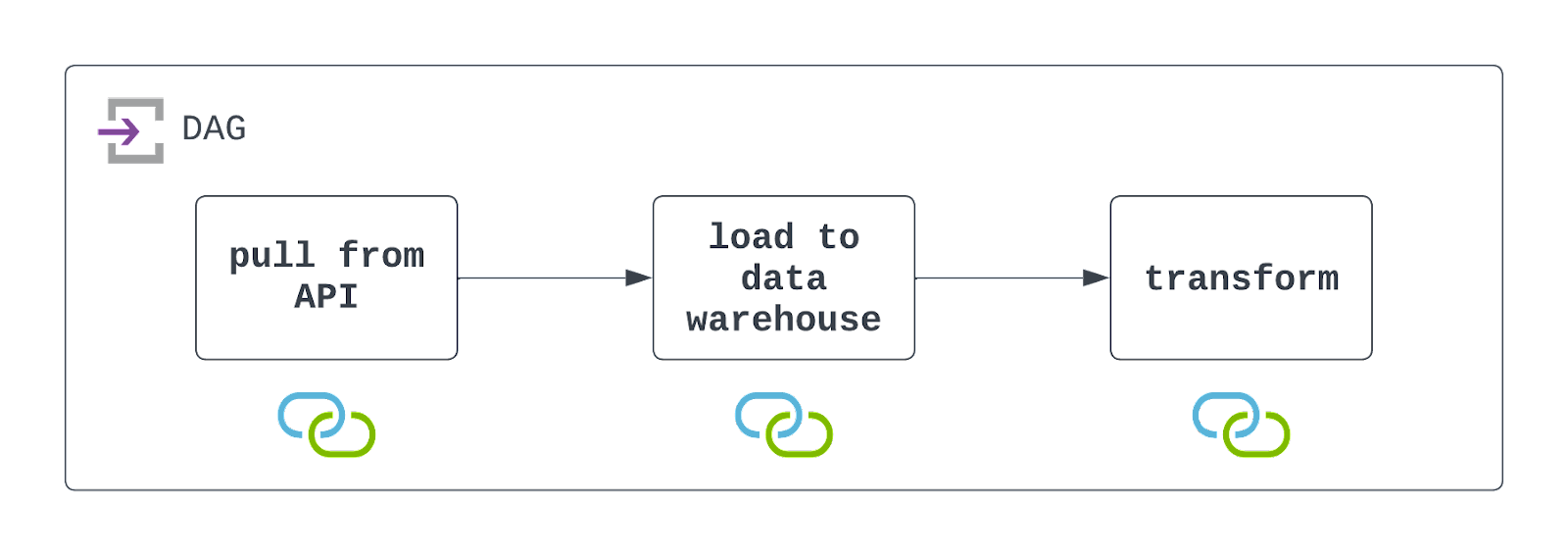
Il est important de garder à l'esprit qu'Airflow interagit à la fois avec un système de fichiers de stockage dans le cloud et avec un entrepôt de données. Pour que ce DAG s'exécute avec succès, ces ressources doivent exister et des connexions doivent être définies et utilisées. Elles sont indiquées par les icônes situées sous chaque tâche dans le diagramme d'architecture ci-dessus.
Dites-m'en plus : Voici quelques-unes des questions d'entretien les plus courantes concernant Airflow, qui se concentrent davantage sur la conception et l'implémentation de DAG de haut niveau, plutôt que sur des détails techniques minutieux. Face à ces questions, il est important de garder quelques éléments à l'esprit :
DbtCloudRunJobOperator, mentionnez cet outil, mais ne vous sentez pas obligé d'en dire plus (sauf si on vous le demande).Réponse : L'extensibilité d'Airflow et sa popularité croissante dans la communauté des données en ont fait un outil de choix pour bien plus que les ingénieurs de données. Les Data Scientists et les ingénieurs en Machine Learning utilisent Airflow pour entraîner (et réentraîner) leurs modèles, ainsi que pour réaliser une suite complète de MLOps. Les ingénieurs en IA commencent même à utiliser Airflow pour gérer et mettre à l'échelle leurs modèles d'IA générative, avec de nouvelles intégrations pour des outils tels que OpenAI, OpenSearch et Pinecone.
Dites-m'en plus : Les créateurs de l'Airflow n'avaient peut-être pas envisagé de prospérer en dehors des circuits traditionnels d'ingénierie des données. Cependant, en tirant parti de Python et des philosophies open-source, Airflow s'est développé pour répondre aux besoins d'un espace de données/AI en évolution rapide. Lorsque des tâches programmatiques doivent être planifiées et exécutées, Airflow est peut-être le meilleur outil pour ce travail !
Beau travail ! Vous avez fait le tour de la question. Les questions ci-dessus sont difficiles, mais elles reflètent la plupart des questions posées lors d'entretiens techniques sur le thème de l'écoulement de l'air.
En plus des questions ci-dessus, l'une des meilleures façons de se préparer à un entretien avec Airflow est de construire vos propres pipelines de données à l'aide d'Airflow.
Trouvez un ensemble de données qui vous intéresse et commencez à construire votre pipeline ETL (ou ELT) à partir de zéro. Entraînez-vous à utiliser l'API TaskFlow et les opérateurs traditionnels. Stockez des informations sensibles en utilisant des connexions Airflow. Essayez de signaler les défaillances à l'aide de rappels, et testez votre DAG avec des tests unitaires et de bout en bout. Plus important encore, documentez et partagez le travail que vous avez effectué.
Un projet comme celui-ci permet de montrer non seulement la compétence dans le domaine de l'Airflow mais aussi la passion et le désir d'apprendre et de se développer. Si vous avez encore besoin d'une introduction à certains des principes de base, vous pouvez consulter notre cours Introduction à Airflow en Python, notre comparaison Airflow vs Prefect, et notre tutoriel Getting Started with Apache Airflow.
Bonne chance et bon codage !
Poursuivez votre parcours en ingénierie des données dès aujourd'hui !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Samuel Shaibu

