
Programma
Ingegnere dei dati in Python
40 h
In un colloquio tecnico, di solito si parte in modo semplice, concentrandosi sulle basi del framework di Airflow e sui concetti chiave, per poi arrivare a domande più complesse e tecniche.
Quando rispondi a queste domande, non limitarti ai dettagli tecnici: spiega anche come si collegano a un flusso di lavoro di data engineering e/o a processi dati aziendali.
Risposta: Apache Airflow è uno strumento open-source di orchestrazione dei dati che consente ai professionisti dei dati di definire pipeline in modo programmatico utilizzando Python. Airflow è usato soprattutto dai team di data engineering per integrare il proprio ecosistema dati ed eseguire operazioni di estrazione, trasformazione e caricamento.
Dimmi di più: Airflow è mantenuto sotto licenza Apache (da qui il prefisso “Apache”).
Uno strumento di orchestrazione dei dati offre funzionalità per integrare più sorgenti e servizi in un’unica pipeline.
Ciò che distingue Airflow come strumento di orchestrazione è l’uso di Python per definire le pipeline, che garantisce un livello di estendibilità e controllo che altri strumenti non offrono. Airflow vanta numerosi strumenti integrati e supportati dai provider per integrare qualsiasi stack dati di team diversi, oltre alla possibilità di progettarne di propri.
Per ulteriori informazioni su come iniziare con Airflow, leggi questo tutorial di DataCamp: Introduzione ad Apache Airflow. Se vuoi approfondire ulteriormente il mondo dell’orchestrazione dei dati con Airflow, il corso Introduction to Airflow è il posto migliore da cui cominciare.
Risposta: Un DAG, o grafo aciclico diretto, è un insieme di task e delle relazioni tra questi task. Un DAG ha un inizio e una fine ben definiti e non contiene “cicli” tra i task. In Airflow, il termine “DAG” è usato comunemente e, in pratica, può essere considerato una pipeline di dati.
Dimmi di più: È una domanda insidiosa. Quando viene posta, è importante affrontare sia la definizione formale “matematica” di un DAG, sia come viene usato in Airflow. Per capire i DAG, aiuta molto una rappresentazione visiva. La prima immagine qui sotto è, di fatto, un DAG: ha un inizio e una fine chiari e nessun ciclo tra i task.

Il secondo processo mostrato sotto NON è un DAG. Pur avendo un task di avvio chiaro, esiste un ciclo tra i task extract e validate, il che rende incerto il momento in cui il task di load può essere attivato.
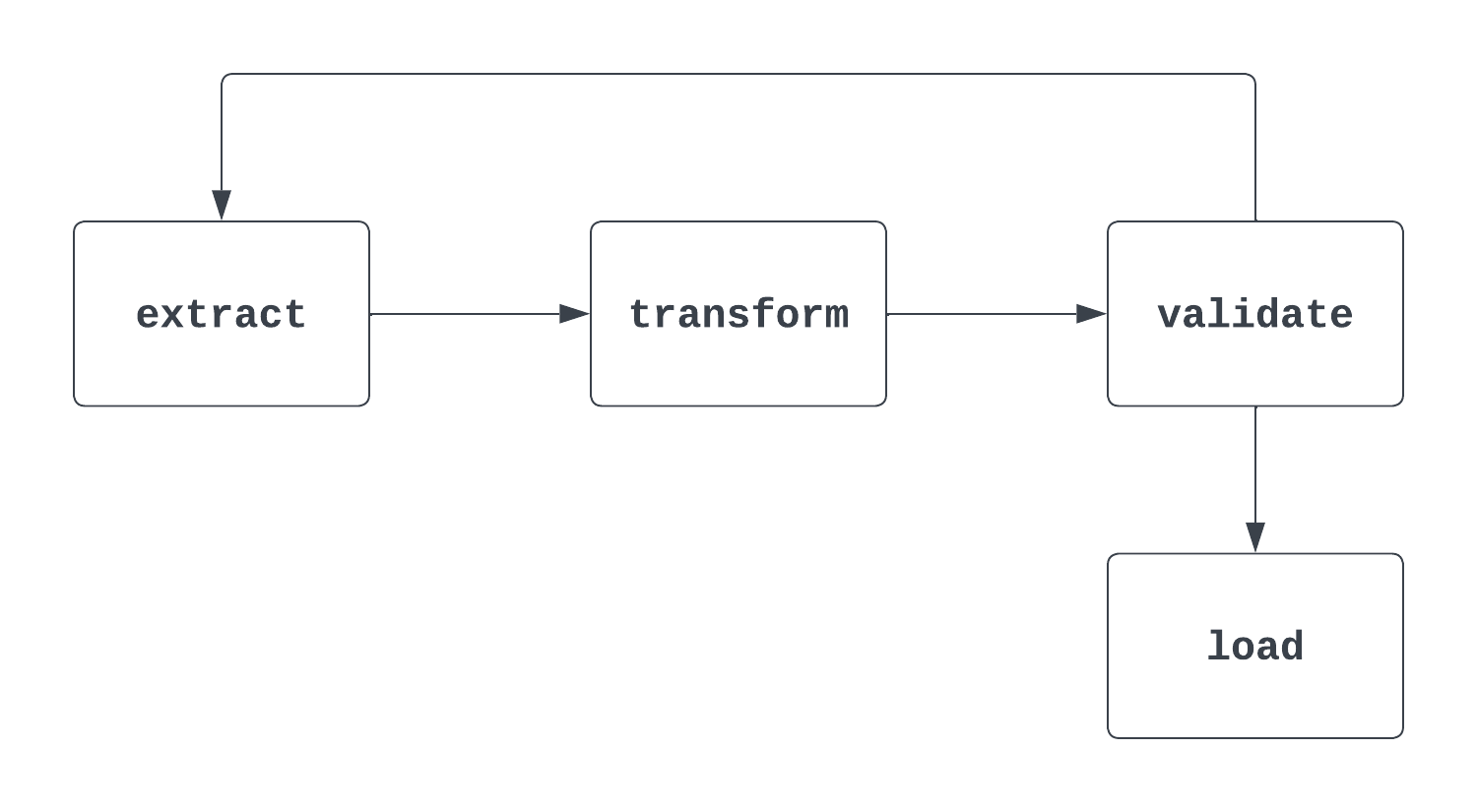
Risposta: Per definire un DAG è necessario fornire un ID, una data di inizio e un intervallo di pianificazione.
Dimmi di più: L’ID identifica in modo univoco il DAG ed è in genere una stringa breve, come "sample_da." La data di inizio è la data e l’ora del primo intervallo in cui verrà attivato il DAG.
Si tratta di un timestamp, quindi specifica esattamente anno, mese, giorno, ora e minuti. L’intervallo di pianificazione indica la frequenza con cui il DAG deve essere eseguito: può essere settimanale, giornaliero, orario o qualcosa di più personalizzato.
In questo esempio, il DAG è definito con un dag_id pari a "sample_dag". La funzione datetime della libreria datetime imposta una start_date al 1° gennaio 2024, alle 9:00. Questo DAG verrà eseguito ogni giorno (alle 9:00), come indicato dall’intervallo @daily. Intervalli più personalizzati possono essere impostati con espressioni cron o con la funzione timedelta della libreria datetime.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Risposta: I task di Airflow sono la più piccola unità di esecuzione nel framework. Un task in genere incapsula una singola operazione in una pipeline (DAG). I task sono i mattoni di un DAG e all’interno di un DAG hanno relazioni che ne determinano l’ordine di esecuzione. Tre esempi di task sono:
In una pipeline ETL, le relazioni sarebbero:
Dimmi di più: I task possono essere molto generici o altamente personalizzati. Airflow fornisce due modi per definirli: gli operatori tradizionali e la TaskFlow API (ne parleremo più avanti).
Uno dei vantaggi dell’open source è il contributo della community, composta non solo da singoli contributor, ma anche da realtà come AWS, Databricks, Snowflake e molte altre.
È molto probabile che esista già un operatore di Airflow per il task che vuoi definire. In caso contrario, è semplice crearne uno tuo. Alcuni esempi di operatori sono SFTPToS3Operator, S3ToSnowflakeOperator e DatabricksRunNowOperator.
Risposta: I quattro componenti principali sono: scheduler, executor, database dei metadati e webserver.
Dimmi di più: Lo scheduler controlla ogni minuto la directory dei DAG e monitora DAG e task per identificare quelli avviabili. L’executor è dove vengono eseguiti i task. I task possono essere eseguiti in locale (all’interno dello scheduler) o in remoto (all’esterno).
Nell’executor avviene il “lavoro” computazionale richiesto da ciascun task. Il database dei metadati contiene tutte le informazioni su DAG e task legati al progetto Airflow in esecuzione: dettagli storici delle esecuzioni, connessioni, variabili e molto altro.
Il webserver consente di visualizzare e usare l’interfaccia di Airflow durante lo sviluppo, l’interazione e la manutenzione dei DAG.
Questa è solo una panoramica dei componenti architetturali di Airflow.
Hai dimostrato di conoscere le basi del framework e dell’architettura di Airflow. Ora è il momento di mettere alla prova le tue competenze nella scrittura dei DAG.
PythonOperator? Quali sono i requisiti per usarlo? Fai un esempio di quando useresti il PythonOperator.Risposta: Il PythonOperator consente di eseguire una funzione Python come task di Airflow. Per usarlo, è necessario passare una funzione Python al parametro python_callable. Un esempio d’uso è la chiamata a un’API per estrarre dati.
Dimmi di più: Il PythonOperator è tra gli operatori più potenti offerti da Airflow. Oltre a permettere l’esecuzione di codice personalizzato in un DAG, consente di scrivere i risultati negli XCom per l’uso da parte dei task a valle.
Passando un dizionario al parametro op_kwargs, si possono passare argomenti con nome alla funzione Python, consentendo ulteriore personalizzazione a runtime. Oltre a op_kwargs, esistono vari altri parametri che estendono le funzionalità del PythonOperator.
Di seguito un esempio di chiamata al PythonOperator. In genere, la funzione Python passata a python_callable è definita fuori dal file con la definizione del DAG. Tuttavia, qui è inclusa per completezza.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Risposta: Ci sono vari modi. Uno dei più comuni è usare l’operatore di bit-shift >>. Un altro è il metodo .set_downstream() per impostare un task a valle di un altro. La funzione chain è un ulteriore strumento utile per definire dipendenze sequenziali. Ecco tre esempi:
# task_1, task_2, task_3 istanziati sopra
# Usando gli operatori di bit-shift
task_1 >> task_2 >> task_3
# Usando .set_downstream()
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# Usando chain
chain(task_1, task_2, task_3)
Dimmi di più: Impostare le dipendenze può essere semplice, ma anche diventare piuttosto complesso! Per un’esecuzione sequenziale, è comune usare gli operatori di bit-shift per una sintassi più espressiva. Con la TaskFlow API, l’impostazione delle dipendenze può apparire un po’ diversa.
Se ci sono due task dipendenti, lo si può indicare passando la chiamata a una funzione come argomento di un’altra funzione, invece di usare le tecniche sopra. Puoi approfondire le dipendenze tra task in un articolo dedicato.
Risposta: I task group servono a raggruppare task correlati all’interno di un DAG. Questo facilita la visualizzazione di task simili nella UI di Airflow. Possono essere utili, ad esempio, quando si estraggono, trasformano e caricano dati appartenenti a team diversi nello stesso DAG.
I task group sono comunemente usati anche per attività come l’addestramento di più modelli di ML o l’interazione con più sistemi sorgente simili in un unico DAG.
Usando i task group in Airflow, la vista del grafo può apparire così:
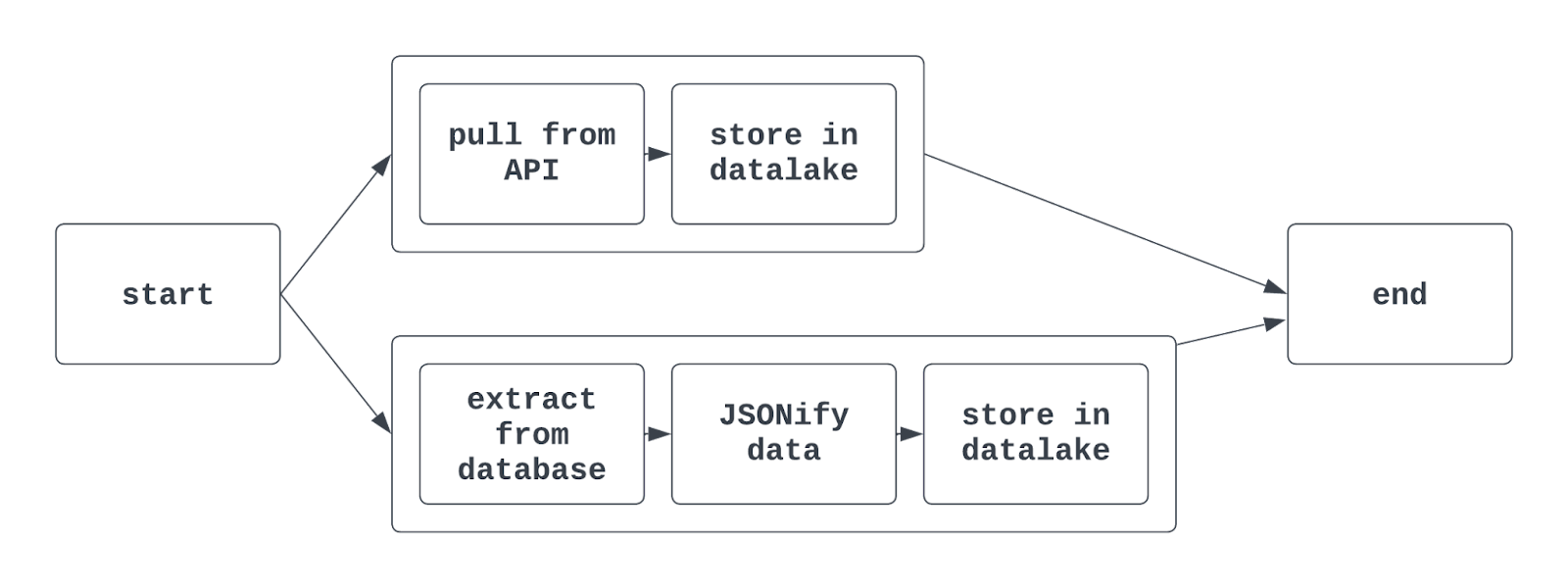
Dimmi di più: Con la sintassi tradizionale di Airflow si usa la funzione TaskGroup per creare task group. Possono essere generati in modo esplicito o dinamico, ma devono avere ID univoci (simili ai DAG).
Tuttavia, task group diversi nello stesso DAG possono contenere task con lo stesso task_id. In quel caso, il task viene identificato univocamente dalla combinazione dell’ID del task group e del task. Con la TaskFlow API, si può usare anche il decorator @task_group per creare un task group.
Risposta: La generazione dinamica di DAG è una tecnica utile per creare più DAG da un unico “blocco” di codice. Un esempio è l’estrazione di dati da più sedi: in questo caso, la creazione dinamica è molto pratica. Se devi estrarre, trasformare e caricare dati da tre aeroporti usando la stessa logica, generare i DAG dinamicamente semplifica il processo.
Ci sono vari modi per farlo. Uno dei più semplici consiste nell’usare un elenco di metadati da iterare. All’interno del ciclo, si istanzia un DAG. È importante ricordare che ogni DAG deve avere un ID univoco. Il codice potrebbe essere simile a questo:
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# Rest of the DAG definition
...
Questo codice genererebbe tre DAG, con ID atl_daily_etl, lax_daily_etl e jfk_daily_etl. A valle, i task potrebbero essere parametrici usando lo stesso codice aeroporto per assicurare che ogni DAG si comporti come previsto.
Dimmi di più: La generazione dinamica dei DAG è usata spesso in ambito enterprise. Quando si sceglie tra la creazione programmatica di task group in un singolo DAG o la generazione dinamica di più DAG, è importante considerare le relazioni tra le operazioni.
Nell’esempio sopra, se un singolo aeroporto causasse un’eccezione, l’uso dei task group porterebbe al fallimento dell’intero DAG. Generando invece i DAG dinamicamente, questo singolo punto di errore non farebbe fallire gli altri due DAG.
Iterare su un iterabile Python non è l’unico modo per generare dinamicamente i DAG: definire una funzione create_dag, usare variabili/connessioni per creare DAG o sfruttare un file di configurazione JSON sono opzioni comuni per raggiungere lo stesso obiettivo. Strumenti di terze parti come gusty e dag-factory offrono ulteriori approcci basati su configurazione.
Comprendere e saper spiegare le basi di Airflow e lo sviluppo dei DAG spesso basta per soddisfare le aspettative di un ruolo junior. Ma padroneggiare Airflow significa andare oltre la semplice scrittura ed esecuzione di DAG.
Le domande e risposte seguenti ti aiuteranno a mostrare una comprensione più profonda delle funzionalità complesse di Airflow, tipiche dei ruoli più senior.
data_interval_start e un data_interval_end, quando viene eseguito un DAG?Risposta: Come suggerisce il nome, data_interval_start e data_interval_end sono i limiti temporali dell’esecuzione del DAG. Se un DAG è in backfill e l’ora corrente è maggiore di data_interval_end, il DAG verrà messo subito in coda per l’esecuzione.
Tuttavia, in esecuzione “normale”, un DAG non verrà eseguito finché l’ora di esecuzione non supera il **data_interval_end**.
Dimmi di più: È un concetto difficile, anche per come sono etichettate le esecuzioni dei DAG. Ecco un buon modo per pensarci. Vuoi recuperare tutti i dati del 17 marzo 2024 da un’API.
Se l’intervallo è giornaliero, il data_interval_start per questa esecuzione è 2024-03-17 00:00:00 UTC e il data_interval_end è 2024-03-18 00:00:00 UTC. Non avrebbe senso eseguire il DAG alle 2024-03-17 00:00:00 UTC, perché i dati del 17 marzo non sarebbero ancora completi. Il DAG viene quindi eseguito al data_interval_end del 2024-03-18 00:00:00 UTC.
Risposta: Il parametro catchup viene definito quando si istanzia un DAG. catchup accetta True o False e il valore predefinito è True. Se è True, verranno eseguite tutte le esecuzioni del DAG tra la data di inizio e il momento in cui lo stato del DAG è stato impostato per la prima volta su attivo.
Supponiamo che la data di inizio di un DAG sia il 1° gennaio 2024, con intervallo giornaliero e catchup=True. Se la data corrente è il 15 aprile 2024, quando il DAG viene attivato per la prima volta, verrà eseguita l’esecuzione con data_interval_start del 1° gennaio 2024, seguita da quella del 2 gennaio 2024 (e così via).
Questo continuerà finché il DAG non sarà “in pari”, per poi riprendere il comportamento normale. Questo è noto come “backfilling”. Il backfill può essere molto rapido: se un’esecuzione impiega pochi minuti, mesi di esecuzioni storiche possono completarsi in poche ore.
Se è False, non verrà eseguita alcuna esecuzione storica e la prima esecuzione partirà alla fine dell’intervallo durante il quale lo stato del DAG è stato impostato su attivo.
Dimmi di più: Poter fare backfill senza modifiche significative al codice o sforzi manuali è una delle funzionalità più potenti di Airflow. Mettiamo che tu stia creando un’integrazione per recuperare tutte le transazioni di un’API dell’ultimo anno.
Una volta costruito il DAG, ti basta impostare la data di inizio desiderata e catchup=True per recuperare facilmente questi dati storici.
Se non vuoi eseguire il backfill quando attivi per la prima volta il DAG, nessun problema! Esistono vari modi per attivare backfill in modo sistematico, tramite l’API di Airflow e la CLI di Airflow (e Astro).
Risposta: Gli XCom (cross-communications) sono una funzionalità avanzata di Airflow che consente di memorizzare e recuperare messaggi tra i task.
Gli XCom sono memorizzati come coppie chiave-valore e possono essere letti e scritti in diversi modi. Con il PythonOperator, i metodi .xcom_push() e .xcom_pull() possono essere utilizzati all’interno della funzione per “spingere” e “recuperare” dati dagli XCom. Gli XCom sono usati per memorizzare quantità ridotte di dati, come nomi di file o flag booleani.
Dimmi di più: Oltre a .xcom_push() e .xcom_pull(), ci sono altri modi per scrivere e leggere dati dagli XCom. Con il PythonOperator, impostare a True il parametro do_xcom_push fa sì che il valore restituito dalla funzione venga scritto negli XCom.
Non è limitato al PythonOperator: qualsiasi operatore che restituisce un valore può scriverlo negli XCom tramite il parametro do_xcom_push. Dietro le quinte, anche la TaskFlow API usa gli XCom per condividere dati tra i task (lo vedremo tra poco).
Per approfondire gli XCom, dai un’occhiata a questo ottimo articolo del grande Marc Lamberti.
Risposta: La TaskFlow API offre un nuovo modo, più intuitivo e “pythonic”, di scrivere DAG. Invece degli operatori tradizionali, si decorano le funzioni Python con il decorator @task, e si possono dedurre le dipendenze tra task senza doverle definire esplicitamente.
Un task scritto con la TaskFlow API può apparire così:
import random
...
@task
def get_temperature():
# Pull a temperature, return the value
temperature = random.randint(0, 100)
return temperature
…
Con la TaskFlow API è facile condividere dati tra i task. Invece di usare direttamente gli XCom, il valore restituito da un task (funzione) può essere passato come argomento a un altro task. In questo processo, gli XCom sono comunque usati dietro le quinte, quindi non è possibile condividere grandi quantità di dati tra task neppure con la TaskFlow API.
Dimmi di più: La TaskFlow API fa parte dello sforzo di Airflow per semplificare la scrittura dei DAG, rendendo il framework più accessibile a data scientist e analyst. Pur non coprendo tutte le esigenze dei team di Data Engineering che devono integrare ecosistemi cloud complessi, è particolarmente utile (e intuitiva) per task ETL di base.
La TaskFlow API e gli operatori tradizionali possono coesistere nello stesso DAG, coniugando l’integrabilità degli operatori classici con la facilità d’uso della TaskFlow API. Per maggiori dettagli, consulta la documentazione.
Risposta: L’idempotenza è la proprietà di un processo/operazione per cui può essere eseguito più volte senza cambiare il risultato iniziale. In parole povere, se esegui un DAG una volta o dieci volte, il risultato dovrebbe essere identico.
Un caso comune in cui ciò non accade è l’inserimento di dati in database strutturati (SQL). Se si inseriscono dati senza vincolo di chiave primaria e un DAG viene eseguito più volte, nella tabella risultante si genereranno duplicati. Pattern come delete-insert o “upsert” aiutano a implementare l’idempotenza nelle pipeline.
Dimmi di più: Non è un concetto strettamente specifico di Airflow, ma è essenziale nella progettazione delle pipeline. Airflow fornisce vari strumenti per facilitarne l’implementazione, ma gran parte di questa logica deve essere progettata, sviluppata e testata da chi realizza la pipeline.
Per ruoli più tecnici, potrebbero arrivare domande sulla gestione e il monitoraggio di una distribuzione di Airflow a livello produttivo, simile a quella in uso nel loro team. Queste domande sono più impegnative e richiedono maggiore preparazione.
Risposta: Ci sono diversi modi per testare un DAG. Il più comune è eseguirlo per verificarne il successo. Si può avviare un ambiente Airflow locale e usare la UI per attivare il DAG.
Una volta avviato, si può monitorare l’esecuzione per verificarne le prestazioni (successo/fallimento del DAG e dei singoli task, oltre al tempo e alle risorse impiegate).
Oltre al test manuale tramite esecuzione, i DAG possono essere testati con unit test. Airflow fornisce strumenti via CLI per eseguire test, oppure si può usare un test runner standard. Gli unit test possono riguardare sia configurazione ed esecuzione del DAG, sia altri componenti del progetto, come funzioni richiamabili e plugin.
Dimmi di più: Testare i DAG è una delle attività più importanti per un Data Engineer. Se un DAG non è stato testato, non è pronto per supportare workflow di produzione.
Testare pipeline di dati è particolarmente complesso: ci sono edge e corner case meno comuni in altri contesti di sviluppo. In un colloquio più tecnico (soprattutto per ruoli Lead/Senior), sottolinea l’importanza di test end-to-end insieme agli unit test e alla documentazione dei risultati.
Risposta: Nessuno ama i fallimenti dei DAG, ma gestirli con metodo può distinguerti come Data Engineer. Fortunatamente, Airflow offre molti strumenti per catturare, notificare e risolvere i fallimenti. Per prima cosa, il fallimento è visibile nella UI di Airflow: lo stato del DAG diventa “failed” e nella grid view compare un riquadro rosso per quell’esecuzione. Quindi, si possono analizzare manualmente i log nella UI.
Di solito, i log riportano l’eccezione che ha causato il fallimento e forniscono informazioni utili per l’analisi.
Identificato il problema, si aggiornano codice/configurazione sottostanti del DAG e si riesegue. Questo si può fare azzerando lo stato del DAG e reimpostandolo su “active”.
Se un DAG fallisce spesso ma funziona ai retry, può essere utile usare i parametri retries e retry_delay di Airflow. Consentono di ritentare un task al fallimento per un numero definito di volte dopo un certo intervallo. È utile, per esempio, quando si tenta di prelevare un file da un sito SFTP che potrebbe arrivare in ritardo.
Dimmi di più: Perché un DAG fallisca, deve fallire un task specifico. È importante analizzare quel task e non l’intero DAG. Oltre alle funzionalità della UI, esistono molti altri strumenti per monitorare e gestire le prestazioni dei DAG.
I callback offrono una personalizzazione pressoché illimitata nella gestione dei successi e dei fallimenti. Con i callback, si può eseguire una funzione scelta dall’autore del DAG quando un DAG ha successo o fallisce, usando i parametri on_success_callback e on_failure_callback di un operatore. Questa funzione può inviare un messaggio a uno strumento come PagerDuty o scrivere l’esito in un database da cui generare allerte. Ciò migliora la visibilità e accelera l’analisi quando si verifica un fallimento.
Risposta: Una delle funzionalità più utili di Airflow sono le “connessioni”. Le connessioni consentono all’autore del DAG di memorizzare e recuperare informazioni di connessione (host, username, password, ecc.) senza doverle inserire hardcoded nel codice.
Ci sono vari modi per memorizzare le connessioni; il più comune è tramite la UI di Airflow. Una volta creata, una connessione può essere richiamata in codice con un “hook”. Tuttavia, la maggior parte degli operatori tradizionali che interagiscono con sistemi sorgente ha un campo conn_id (o molto simile) che accetta una stringa e crea la connessione alla sorgente desiderata.
Le connessioni di Airflow aiutano a mantenere al sicuro le informazioni sensibili e rendono semplice salvarle e recuperarle.
Dimmi di più: Oltre alla UI, si può usare la CLI per salvare e recuperare connessioni. In ambito enterprise, è più comune usare un “secrets backend” personalizzato per gestire le connessioni. Airflow supporta diversi secrets backend. Un’azienda su AWS può integrare facilmente Secrets Manager con Airflow per memorizzare e recuperare connessioni e informazioni sensibili. Se necessario, le connessioni possono anche essere definite come variabili d’ambiente del progetto.
Risposta: Distribuire un ambiente Airflow di livello produttivo può essere complesso. Strumenti cloud come Azure e AWS offrono servizi gestiti per distribuire e gestire Airflow, ma richiedono un account cloud e possono avere costi non trascurabili.
Un’alternativa diffusa è usare Kubernetes per distribuire ed eseguire Airflow in produzione. Questo consente il pieno controllo delle risorse sottostanti, ma implica anche la responsabilità di gestire quell’infrastruttura.
Al di fuori dei servizi cloud nativi e delle distribuzioni Kubernetes in house, Astronomer è il provider gestito di Airflow più popolare sul mercato.
Offrono numerosi strumenti open-source (CLI, SDK, ampia documentazione) oltre alla loro offerta PaaS “Astro”, per rendere lo sviluppo e il deployment di Airflow il più fluidi possibile. Con Astro, allocazione delle risorse, controllo degli accessi alla piattaforma e aggiornamenti in-place di Airflow sono supportati nativamente, riportando l’attenzione sullo sviluppo delle pipeline.
Sebbene non siano eccessivamente tecniche, le domande basate su scenari sono tra le più importanti in un colloquio su Airflow. Fornire risposte dettagliate e ben ragionate dimostra padronanza non solo di Airflow, ma anche di principi di architettura e progettazione dei dati.
Risposta: Questa è stimolante! Con una domanda del genere, hai molte possibilità. La cosa più importante è: mentre descrivi il processo, scegli strumenti e processi della pipeline legacy che conosci bene. Questo dimostra competenza e rende la tua risposta più solida.
È l’occasione perfetta per mostrare anche capacità di project management e leadership. Spiega come struttureresti il progetto, come interagirai con stakeholder e altri ingegneri e come documenterai/comunicherai i processi. Dimostra attenzione al valore e alla semplificazione del lavoro del tuo team.
Se un’azienda ha un certo strumento nello stack (ad esempio Google BigQuery), potrebbe avere senso parlare di come rifattorizzare il processo passando, per esempio, da Postgres a BigQuery. Questo mostra consapevolezza e conoscenza non solo di Airflow, ma anche degli altri componenti dell’infrastruttura aziendale.
Risposta: Per progettare questo DAG, dovrai prima chiamare l’API per estrarre i dati. Puoi farlo con il PythonOperator e una funzione personalizzata. All’interno della funzione, conviene anche salvare i dati in un’area di storage cloud, come AWS S3.
Una volta persistiti i dati, puoi usare un operatore già pronto, come S3ToSnowflakeOperator, per caricare i dati da S3 in un data warehouse Snowflake. Infine, puoi eseguire un job DBT per trasformare i dati usando DbtCloudRunJobOperator.
Dovrai pianificare il DAG all’intervallo desiderato e configurarlo per gestire i fallimenti in modo elegante (ma con visibilità). Dai un’occhiata al diagramma qui sotto!
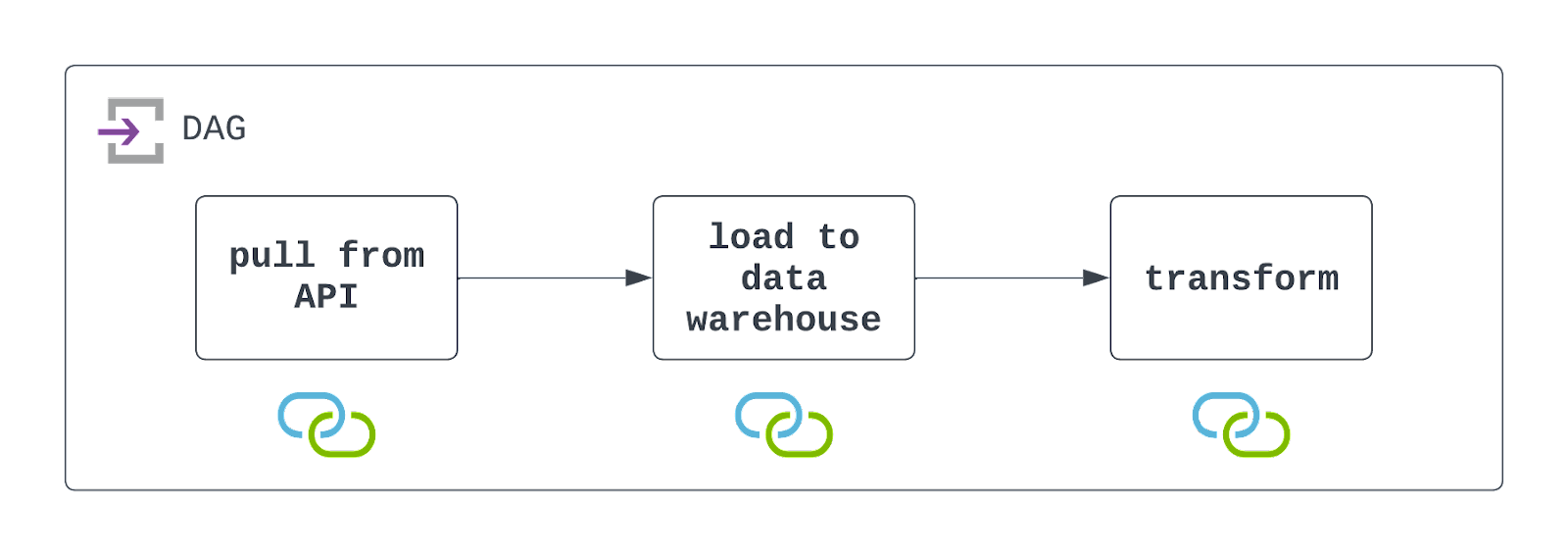
È importante ricordare che Airflow interagisce sia con un file system di storage cloud sia con un data warehouse. Perché il DAG venga eseguito con successo, queste risorse devono esistere e le connessioni vanno definite e usate. Nel diagramma architetturale sopra, ciò è indicato dalle icone sotto ciascun task.
Dimmi di più: Queste sono tra le domande più comuni nei colloqui su Airflow, più focalizzate sul design e l’implementazione ad alto livello dei DAG che sui dettagli tecnici minuti. Tieni a mente alcune cose:
DbtCloudRunJobOperator, menzionalo senza dilungarti (a meno che non ti venga chiesto).Risposta: L’estendibilità di Airflow e la sua crescente popolarità nella community lo hanno reso uno strumento di riferimento non solo per i Data Engineer. Data Scientist e Machine Learning Engineer usano Airflow per addestrare (e ri-addestrare) i loro modelli e per svolgere un set completo di attività MLOps. Anche gli AI Engineer stanno iniziando a utilizzare Airflow per gestire e scalare modelli di generative AI, con nuove integrazioni per strumenti come OpenAI, OpenSearch e Pinecone.
Dimmi di più: Emergere al di fuori delle pipeline tradizionali di data engineering forse non era tra le previsioni dei creatori iniziali di Airflow. Tuttavia, grazie a Python e alla filosofia open source, Airflow è cresciuto per rispondere alle esigenze di un panorama dati/AI in rapida evoluzione. Quando occorre pianificare ed eseguire task programmabili, Airflow potrebbe essere lo strumento migliore!
Ottimo lavoro! Sei arrivato in fondo. Le domande sopra sono impegnative, ma coprono gran parte di ciò che viene chiesto nei colloqui tecnici incentrati su Airflow.
Oltre a ripassare le domande sopra, uno dei modi migliori per prepararti a un colloquio su Airflow è costruire pipeline di dati con Airflow in prima persona.
Trova un dataset che ti interessa e inizia a costruire da zero la tua pipeline ETL (o ELT). Esercitati con la TaskFlow API e con gli operatori tradizionali. Conserva le informazioni sensibili con le connessioni di Airflow. Prova a gestire le segnalazioni di fallimento con i callback e testa il DAG con unit test e prove end-to-end. Soprattutto, documenta e condividi il lavoro svolto.
Un progetto del genere dimostra non solo competenza su Airflow, ma anche passione e desiderio di imparare e crescere. Se ti serve ancora un ripasso dei principi di base, dai un’occhiata al nostro corso Introduction to Airflow in Python, al nostro confronto Airflow vs Prefect e al nostro tutorial Getting Started with Apache Airflow.
In bocca al lupo e buon coding!
Continua oggi il tuo percorso in Data Engineering!
Programma
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min

