
Tracks
Kỹ sư dữ liệu trong Python
40 giờ
Trong phỏng vấn kỹ thuật, người phỏng vấn thường khởi động nhẹ, tập trung vào những kiến thức nền tảng về khung làm việc và các khái niệm cốt lõi của Airflow trước khi nâng dần độ phức tạp và kỹ thuật.
Khi trả lời, hãy đảm bảo không chỉ nói về chi tiết kỹ thuật mà còn liên hệ cách chúng gắn với quy trình kỹ thuật dữ liệu và/hoặc luồng dữ liệu doanh nghiệp.
Trả lời: Apache Airflow là một công cụ điều phối dữ liệu mã nguồn mở cho phép người làm dữ liệu định nghĩa các đường ống dữ liệu (pipeline) một cách lập trình bằng Python. Airflow thường được các nhóm kỹ thuật dữ liệu dùng để tích hợp hệ sinh thái dữ liệu của họ và thực hiện trích xuất, biến đổi, nạp dữ liệu.
Tìm hiểu thêm: Airflow được duy trì theo giấy phép phần mềm Apache (vì vậy có tiền tố “Apache”).
Một công cụ điều phối dữ liệu cung cấp chức năng cho phép tích hợp nhiều nguồn và dịch vụ vào một pipeline duy nhất.
Điểm khiến Airflow khác biệt là việc dùng Python để định nghĩa pipeline, mang lại mức độ mở rộng và kiểm soát mà các công cụ điều phối khác khó có được. Airflow có nhiều công cụ tích hợp sẵn và do nhà cung cấp hỗ trợ để kết nối mọi thành phần trong data stack của đội ngũ, đồng thời cho phép bạn tự thiết kế công cụ của mình.
Để tìm hiểu cách bắt đầu với Airflow, hãy xem hướng dẫn của DataCamp: Bắt đầu với Apache Airflow. Nếu muốn đào sâu hơn vào điều phối dữ liệu với Airflow, khóa Giới thiệu về Airflow là điểm khởi đầu tốt nhất.
Trả lời: DAG, hay đồ thị có hướng không chu trình, là một tập hợp các tác vụ và mối quan hệ giữa chúng. DAG có điểm bắt đầu và kết thúc rõ ràng và không có “vòng lặp” giữa các tác vụ. Khi dùng Airflow, thuật ngữ “DAG” rất phổ biến và thường có thể hiểu là một pipeline dữ liệu.
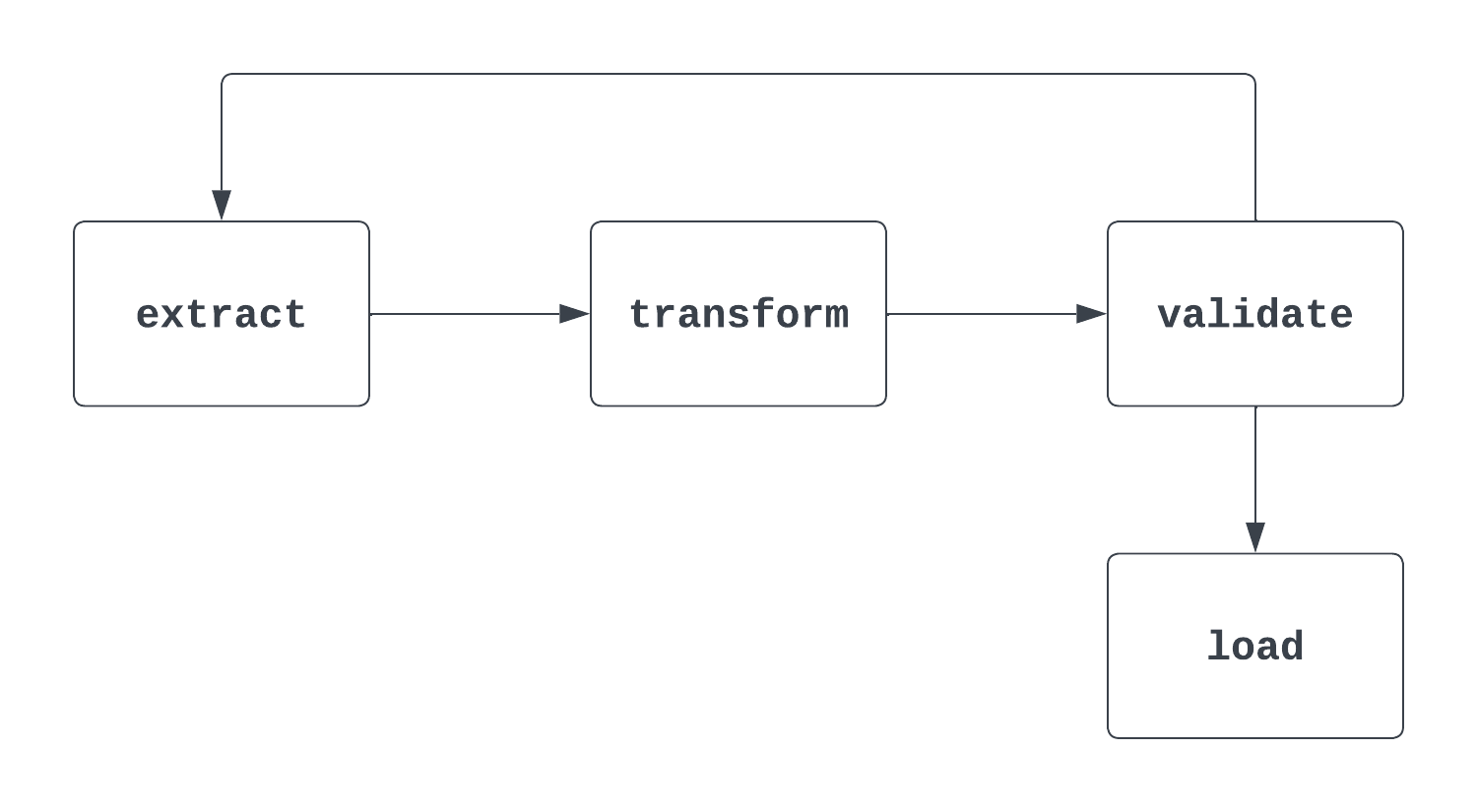
Tìm hiểu thêm: Đây là câu hỏi dễ gây nhầm lẫn. Khi được hỏi, bạn cần nêu cả định nghĩa “toán học” chính thống về DAG lẫn cách dùng trong Airflow. Khi nghĩ về DAG, xem hình minh họa sẽ hữu ích. Hình đầu tiên dưới đây là một DAG thực sự. Nó có điểm đầu cuối rõ ràng và không có chu trình giữa các tác vụ.

Quy trình thứ hai dưới đây KHÔNG phải là DAG. Dù có tác vụ bắt đầu rõ ràng, vẫn có vòng lặp giữa các tác vụ extract và validate, khiến thời điểm kích hoạt tác vụ load không rõ ràng.
Trả lời: Để định nghĩa DAG, phải cung cấp ID, ngày bắt đầu và khoảng lịch chạy.
Tìm hiểu thêm: ID nhận diện duy nhất DAG và thường là một chuỗi ngắn, như "sample_da." Ngày bắt đầu là ngày giờ của khoảng đầu tiên tại đó DAG sẽ được kích hoạt.
Đây là mốc thời gian, nghĩa là chỉ rõ năm, tháng, ngày, giờ và phút. Khoảng lịch chạy là tần suất DAG được thực thi: hàng tuần, hàng ngày, hàng giờ, hoặc tùy chỉnh hơn.
Trong ví dụ này, DAG được định nghĩa với dag_id là "sample_dag". Hàm datetime từ thư viện datetime được dùng để đặt start_date là 9:00 sáng ngày 1/1/2024. DAG này sẽ chạy hàng ngày (lúc 9:00), theo lịch @daily. Có thể đặt lịch tùy chỉnh hơn với cron expression hoặc hàm timedelta của thư viện datetime.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Trả lời: Tác vụ là đơn vị thực thi nhỏ nhất trong Airflow. Một tác vụ thường gói gọn một thao tác đơn lẻ trong một pipeline dữ liệu (DAG). Tác vụ là khối xây dựng của DAG, và các tác vụ trong DAG có quan hệ quy định thứ tự thực thi. Ba ví dụ:
Trong pipeline ETL, quan hệ sẽ là:
Tìm hiểu thêm: Tác vụ có thể rất tổng quát hoặc khá tùy biến. Airflow cung cấp hai cách định nghĩa: các operator truyền thống và TaskFlow API (sẽ nói sau).
Một lợi ích của mã nguồn mở là có đóng góp từ cộng đồng rộng lớn, không chỉ cá nhân mà còn các bên như AWS, Databricks, Snowflake, và nhiều nữa.
Nhiều khả năng đã có sẵn operator cho tác vụ bạn cần. Nếu chưa, bạn có thể dễ dàng tự tạo. Một vài ví dụ: SFTPToS3Operator, S3ToSnowflakeOperator, và DatabricksRunNowOperator.
Trả lời: Có bốn thành phần cốt lõi: scheduler (bộ lập lịch), executor (bộ thực thi), cơ sở dữ liệu metadata, và webserver.
Tìm hiểu thêm: Scheduler kiểm tra thư mục DAG mỗi phút và giám sát DAG và tác vụ để xác định tác vụ nào có thể kích hoạt. Executor là nơi tác vụ chạy. Tác vụ có thể chạy cục bộ (trong scheduler) hoặc từ xa (ngoài scheduler).
Executor là nơi diễn ra “công việc” tính toán mà mỗi tác vụ yêu cầu. Cơ sở dữ liệu metadata chứa mọi thông tin về DAG và tác vụ liên quan đến dự án Airflow bạn đang chạy, gồm lịch sử thực thi, kết nối, biến, và nhiều thông tin khác.
Webserver cho phép hiển thị và tương tác với giao diện Airflow khi phát triển, tương tác và bảo trì DAG.
Đây chỉ là tổng quan nhanh về các thành phần kiến trúc cốt lõi của Airflow.
Bạn đã chứng tỏ mình nắm vững nền tảng khung Airflow và kiến trúc của nó. Giờ là lúc kiểm tra kiến thức viết DAG.
PythonOperator là gì? Yêu cầu để dùng operator này? Ví dụ khi nào bạn muốn dùng PythonOperator?Trả lời: PythonOperator cho phép thực thi một hàm Python như một tác vụ Airflow. Để dùng operator này, phải truyền một hàm Python vào tham số python_callable. Một ví dụ là khi gọi một API để trích xuất dữ liệu.
Tìm hiểu thêm: PythonOperator là một trong những operator mạnh mẽ nhất của Airflow. Nó cho phép chạy mã tùy biến trong DAG, và kết quả có thể ghi vào XCom để tác vụ hạ lưu dùng.
Bằng cách truyền một dictionary vào tham số op_kwargs, có thể truyền đối số theo tên vào callable Python, cho phép tinh chỉnh hơn khi chạy. Ngoài op_kwargs, còn nhiều tham số khác mở rộng chức năng của PythonOperator.
Dưới đây là ví dụ gọi PythonOperator. Thông thường hàm Python truyền vào python_callable được định nghĩa ngoài tệp chứa DAG, nhưng ở đây được đưa vào cho đầy đủ.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Trả lời: Có khá nhiều cách. Phổ biến là dùng toán tử dịch bit >>. Cách khác là dùng phương thức .set_downstream() để đặt một tác vụ ở hạ lưu của tác vụ khác. Hàm chain cũng hữu ích để đặt phụ thuộc tuần tự. Ba ví dụ:
# task_1, task_2, task_3 đã được khởi tạo ở trên
# Dùng toán tử dịch bit
task_1 >> task_2 >> task_3
# Dùng .set_downstream()
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# Dùng chain
chain(task_1, task_2, task_3)
Tìm hiểu thêm: Đặt phụ thuộc có thể đơn giản hoặc khá phức tạp! Với thực thi tuần tự, thường dùng toán tử dịch bit cho ngắn gọn. Khi dùng TaskFlow API, cách đặt phụ thuộc có thể khác đôi chút.
Nếu có hai tác vụ phụ thuộc, có thể biểu đạt bằng cách truyền lời gọi hàm này vào hàm kia, thay vì dùng các kỹ thuật kể trên. Bạn có thể tìm hiểu thêm về phụ thuộc giữa tác vụ của Airflow trong một bài viết riêng.
Trả lời: Task group dùng để nhóm các tác vụ trong một DAG. Điều này giúp dễ nhận biết các tác vụ tương tự nhau trong giao diện Airflow. Sẽ hữu ích khi nhóm tác vụ trích xuất, biến đổi, nạp dữ liệu thuộc các đội khác nhau trong cùng một DAG.
Task group cũng thường dùng khi huấn luyện nhiều mô hình ML hoặc tương tác với nhiều hệ thống nguồn (nhưng tương tự) trong một DAG.
Khi dùng task group trong Airflow, chế độ xem đồ thị có thể trông như sau:
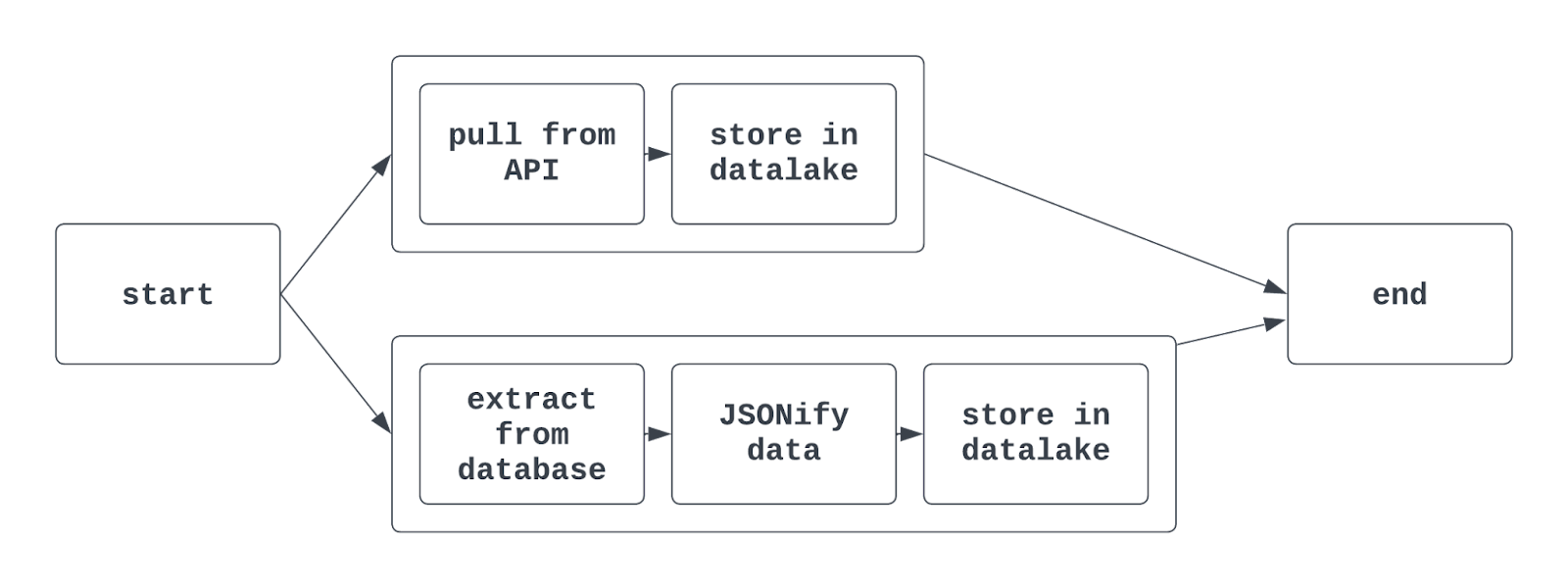
Tìm hiểu thêm: Với cú pháp Airflow truyền thống, hàm TaskGroup được dùng để tạo task group. Task group có thể được tạo rõ ràng hoặc động nhưng phải có ID duy nhất (tương tự DAG).
Tuy nhiên, các task group khác nhau trong cùng DAG có thể chứa tác vụ có cùng task_id. Khi đó, tác vụ sẽ được nhận diện duy nhất bằng cặp ID task group và task ID. Khi dùng TaskFlow API, decorator @task_group cũng có thể dùng để tạo task group.
Trả lời: Tạo DAG động là kỹ thuật hữu ích để tạo nhiều DAG từ một “khối” mã. Lấy dữ liệu từ nhiều địa điểm là ví dụ điển hình. Nếu bạn cần ETL từ ba sân bay với cùng logic, tạo DAG động giúp đơn giản hóa quy trình.
Có nhiều cách làm. Dễ nhất là dùng một danh sách metadata để lặp qua, rồi trong vòng lặp khởi tạo một DAG. Hãy nhớ mỗi DAG phải có ID duy nhất. Mã có thể như sau:
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# Phần định nghĩa DAG còn lại
...
Đoạn mã này sẽ tạo ra ba DAG với ID atl_daily_etl, lax_daily_etl và jfk_daily_etl. Ở hạ lưu, có thể tham số hóa các tác vụ bằng cùng mã sân bay để đảm bảo mỗi DAG chạy đúng như mong đợi.
Tìm hiểu thêm: Tạo DAG động thường được dùng trong môi trường doanh nghiệp. Khi cân nhắc giữa việc tạo nhóm tác vụ bằng mã trong một DAG hay tạo DAG động, hãy nghĩ về mối quan hệ giữa các thao tác.
Trong ví dụ trên, nếu một sân bay gây ra ngoại lệ, dùng task group sẽ khiến cả DAG thất bại. Nhưng nếu thay vào đó tạo DAG động, điểm lỗi đơn lẻ này sẽ không khiến hai DAG còn lại thất bại.
Lặp qua iterable Python không phải cách duy nhất để tạo DAG động—định nghĩa hàm create_dag, dùng biến/kết nối để sinh DAG, hoặc tận dụng tệp cấu hình JSON cũng là các lựa chọn phổ biến. Công cụ bên thứ ba như gusty và dag-factory cung cấp cách tiếp cận dựa trên cấu hình để tạo DAG động.
Hiểu và truyền đạt những điều cơ bản về Airflow và phát triển DAG thường đủ cho vị trí cấp junior. Nhưng làm chủ Airflow còn hơn cả viết và chạy DAG.
Những câu hỏi và trả lời dưới đây sẽ giúp bạn thể hiện hiểu biết sâu hơn về các chức năng phức tạp của Airflow, thường cần cho vai trò cấp cao hơn.
data_interval_start và data_interval_end, khi nào một DAG được thực thi?Trả lời: Đúng như tên gọi, data_interval_start và data_interval_end là ranh giới thời gian cho lần chạy DAG. Nếu DAG đang được backfill và thời điểm chạy lớn hơn data_interval_end, DAG sẽ lập tức được đưa vào hàng đợi để chạy.
Tuy nhiên, với thực thi “bình thường”, Một DAG sẽ chỉ chạy khi thời điểm thực thi lớn hơn **data_interval_end**.
Tìm hiểu thêm: Khái niệm này khó, nhất là với cách gán nhãn lần chạy DAG. Hãy nghĩ thế này: bạn muốn lấy toàn bộ dữ liệu ngày 17/03/2024 từ một API.
Nếu lịch là hàng ngày, data_interval_start cho lần chạy này là 2024-03-17 00:00:00 UTC, và data_interval_end là 2024-03-18 00:00:00 UTC. Không hợp lý nếu chạy DAG lúc 2024-03-17 00:00:00 UTC vì dữ liệu ngày 17 chưa có đầy đủ. Thay vào đó, DAG được thực thi tại data_interval_end là 2024-03-18 00:00:00 UTC.
Trả lời: Tham số catchup được đặt khi khởi tạo DAG. catchup nhận giá trị True hoặc False, mặc định là True nếu không chỉ định. Nếu True, mọi lần chạy DAG giữa ngày bắt đầu và thời điểm DAG được bật hoạt động lần đầu sẽ được chạy.
Giả sử DAG có ngày bắt đầu 1/1/2024, lịch hàng ngày và catchup=True. Nếu ngày hiện tại là 15/4/2024 khi DAG lần đầu được bật, lần chạy có data_interval_start là 1/1/2024 sẽ được thực thi, tiếp theo là lần chạy cho 2/1/2024 (v.v.).
Điều này tiếp diễn đến khi DAG “bắt kịp”, rồi tiếp tục hành vi bình thường. Đây gọi là “backfilling”. Backfill có thể diễn ra rất nhanh. Nếu mỗi lần chạy chỉ mất vài phút, vài tháng lịch sử có thể được thực thi trong vài giờ.
Nếu False, sẽ không chạy lịch sử, và lần chạy đầu tiên sẽ bắt đầu ở cuối khoảng mà tại đó DAG được bật chạy.
Tìm hiểu thêm: Khả năng backfill mà không cần thay đổi mã lớn hay thao tác thủ công là tính năng mạnh của Airflow. Giả sử bạn đang xây tích hợp để lấy mọi giao dịch từ API trong năm qua.
Sau khi xây xong DAG, bạn chỉ cần đặt ngày bắt đầu mong muốn và catchup=True là có thể dễ dàng lấy dữ liệu lịch sử.
Nếu bạn không muốn backfill khi vừa bật DAG, đừng lo! Có nhiều cách khác để kích hoạt backfill một cách hệ thống. Có thể làm qua Airflow API và Airflow (và Astro CLI).
Trả lời: XCom (viết tắt của cross-communications) là tính năng tinh vi cho phép lưu và truy xuất thông điệp giữa các tác vụ.
XCom được lưu dưới dạng cặp khóa-giá trị và có thể đọc/ghi theo nhiều cách. Khi dùng PythonOperator, các phương thức .xcom_push() và .xcom_pull() có thể dùng trong callable để “đẩy” và “kéo” dữ liệu từ XCom. XCom dùng để lưu lượng dữ liệu nhỏ, như tên tệp hoặc cờ boolean.
Tìm hiểu thêm: Ngoài .xcom_push() và .xcom_pull(), còn nhiều cách khác để ghi/đọc XCom. Khi dùng PythonOperator, truyền True vào tham số do_xcom_push sẽ ghi giá trị trả về của callable vào XCom.
Không chỉ giới hạn ở PythonOperator; bất kỳ operator nào trả về giá trị đều có thể ghi giá trị đó vào XCom với do_xcom_push. Ở hậu trường, TaskFlow API cũng dùng XCom để chia sẻ dữ liệu giữa tác vụ (chúng ta sẽ xem ngay sau).
Để biết thêm về XCom, hãy xem bài viết tuyệt vời của chính huyền thoại Airflow, Marc Lamberti.
Trả lời: TaskFlow API cung cấp cách viết DAG mới, trực quan và “Pythonic” hơn. Thay vì dùng operator truyền thống, các hàm Python được trang trí bằng @task và có thể suy luận phụ thuộc giữa các tác vụ mà không cần định nghĩa tường minh.
Một tác vụ viết bằng TaskFlow API có thể như sau:
import random
...
@task
def get_temperature():
# Lấy nhiệt độ, trả về giá trị
temperature = random.randint(0, 100)
return temperature
…
Với TaskFlow API, việc chia sẻ dữ liệu giữa tác vụ rất dễ. Thay vì dùng XCom trực tiếp, giá trị trả về của tác vụ này (hàm) có thể truyền thẳng làm đối số cho tác vụ khác. Trong suốt quá trình, XCom vẫn được dùng ở hậu trường, nghĩa là không thể chia sẻ lượng dữ liệu lớn giữa các tác vụ ngay cả khi dùng TaskFlow API.
Tìm hiểu thêm: TaskFlow API là một phần trong nỗ lực của Airflow nhằm làm cho việc viết DAG dễ hơn, giúp framework hấp dẫn với nhiều nhà khoa học dữ liệu và nhà phân tích. Dù TaskFlow API không đáp ứng mọi nhu cầu của đội Kỹ thuật Dữ liệu khi tích hợp hệ sinh thái dữ liệu đám mây, nó đặc biệt hữu ích (và trực quan) cho các tác vụ ETL cơ bản.
TaskFlow API và operator truyền thống có thể dùng chung trong một DAG, vừa tận dụng khả năng tích hợp của operator truyền thống vừa có sự dễ dùng của TaskFlow API. Để tìm hiểu thêm, xem tài liệu.
Trả lời: Idempotency (tính bất biến theo số lần thực thi) là thuộc tính của một quy trình/thao tác cho phép thực hiện nhiều lần mà không thay đổi kết quả ban đầu. Nói đơn giản, bạn chạy DAG một lần hay mười lần thì kết quả phải giống hệt.
Một quy trình phổ biến không đạt điều này là khi chèn dữ liệu vào cơ sở dữ liệu có cấu trúc (SQL). Nếu chèn dữ liệu mà không cưỡng bức khóa chính và DAG chạy nhiều lần, bảng kết quả sẽ có bản ghi trùng. Dùng các mẫu như xóa-rồi-chèn (delete-insert) hoặc “upsert” giúp hiện thực hóa tính idempotent trong pipeline dữ liệu.
Tìm hiểu thêm: Điều này không hoàn toàn đặc thù Airflow, nhưng rất quan trọng khi thiết kế và xây dựng pipeline. May mắn là Airflow cung cấp vài công cụ giúp việc này dễ hơn. Tuy nhiên, phần lớn logic vẫn cần được người dùng Airflow thiết kế, phát triển và kiểm thử.
Với vai trò kỹ thuật hơn, người phỏng vấn có thể hỏi về quản lý và giám sát triển khai Airflow ở cấp sản xuất, tương tự môi trường đội ngũ của họ. Những câu hỏi này khó hơn và cần chuẩn bị kỹ.
Trả lời: Có vài cách kiểm thử DAG sau khi viết xong. Phổ biến nhất là thực thi DAG để đảm bảo chạy thành công. Có thể khởi chạy môi trường Airflow cục bộ và dùng giao diện Airflow để kích hoạt DAG.
Sau khi kích hoạt, bạn có thể giám sát để xác nhận hiệu năng (thành công/thất bại của DAG và từng tác vụ, cùng thời gian và tài nguyên sử dụng).
Ngoài thử nghiệm thủ công qua thực thi, có thể viết unit test cho DAG. Airflow cung cấp công cụ qua CLI để chạy test, hoặc dùng test runner tiêu chuẩn. Unit test có thể viết cho cấu hình và thực thi DAG, cũng như các thành phần khác của dự án Airflow như callable và plugin.
Tìm hiểu thêm: Kiểm thử DAG là một trong những việc quan trọng nhất của Kỹ sư Dữ liệu. Nếu DAG chưa được kiểm thử, nó chưa sẵn sàng cho sản xuất.
Kiểm thử pipeline dữ liệu đặc biệt khó; có nhiều trường hợp rìa và góc cạnh không thường gặp ở bối cảnh phát triển khác. Trong phỏng vấn kỹ thuật hơn (nhất là Lead/Senior), hãy nhấn mạnh tầm quan trọng của việc kiểm thử end-to-end song song với viết unit test và ghi lại kết quả.
Trả lời: Không ai thích DAG thất bại, nhưng xử lý khéo léo sẽ giúp bạn nổi bật. May mắn là Airflow có nhiều công cụ để ghi nhận, cảnh báo và khắc phục. Trước hết, trạng thái thất bại của DAG được hiển thị trong giao diện. Trạng thái DAG chuyển sang “failed” và ở grid view sẽ có ô đỏ cho lần chạy này. Sau đó, có thể xem log tác vụ trong UI.
Thông thường, log sẽ cung cấp ngoại lệ gây lỗi và thông tin để kỹ sư dữ liệu tiếp tục phân tích.
Khi xác định được vấn đề, có thể cập nhật mã/cấu hình của DAG và chạy lại. Điều này thực hiện bằng cách xóa trạng thái DAG và bật “active”.
Nếu DAG thường xuyên thất bại nhưng chạy lại thì thành công, có thể dùng chức năng retries và retry_delay. Hai tham số này cho phép thử lại tác vụ khi thất bại một số lần nhất định sau khi chờ một khoảng thời gian. Hữu ích khi, ví dụ, cố tải tệp từ SFTP có thể đến muộn.
Tìm hiểu thêm: Để DAG thất bại, phải có tác vụ cụ thể thất bại. Cần phân tích tác vụ đó chứ không phải cả DAG. Ngoài chức năng có sẵn trong UI, còn rất nhiều công cụ khác để giám sát và quản lý hiệu năng DAG.
Callbacks cho phép tùy biến gần như không giới hạn khi xử lý thành công/thất bại. Với callbacks, có thể thực thi hàm do tác giả DAG chọn khi DAG thành công hay thất bại thông qua tham số on_success_callback và on_failure_callback của operator. Hàm này có thể gửi thông điệp đến công cụ như PagerDuty hoặc ghi kết quả vào cơ sở dữ liệu để cảnh báo sau. Điều này giúp tăng khả năng quan sát và khởi động nhanh quá trình phân tích khi có lỗi.
Trả lời: Một trong những công cụ tiện lợi nhất của Airflow là “connections”. Connections cho phép tác giả DAG lưu và truy cập thông tin kết nối (như host, username, password, v.v.) mà không phải hardcode vào mã.
Có vài cách lưu connections; phổ biến là qua giao diện Airflow. Khi tạo xong, có thể truy cập trực tiếp trong mã bằng “hook”. Tuy nhiên, hầu hết operator truyền thống cần tương tác với nguồn đều có trường conn_id (hoặc tên tương tự) nhận một chuỗi để tạo kết nối đến nguồn mong muốn.
Connections giúp giữ an toàn thông tin nhạy cảm và khiến việc lưu/truy xuất trở nên dễ dàng.
Tìm hiểu thêm: Ngoài giao diện Airflow, có thể dùng CLI để lưu và truy xuất connections. Trong doanh nghiệp, thường dùng “secrets backend” tùy biến để quản lý thông tin kết nối. Airflow hỗ trợ nhiều secrets backend để quản lý connections. Công ty dùng AWS có thể dễ dàng tích hợp Secrets Manager với Airflow để lưu và truy xuất thông tin kết nối và nhạy cảm. Nếu cần, connections cũng có thể được định nghĩa trong biến môi trường của dự án.
Trả lời: Triển khai Airflow cho môi trường sản xuất có thể khó. Các công cụ đám mây như Azure và AWS cung cấp dịch vụ quản lý để triển khai và vận hành Airflow. Tuy nhiên, chúng yêu cầu tài khoản đám mây và có thể tốn kém.
Một lựa chọn phổ biến là dùng Kubernetes để triển khai và chạy Airflow sản xuất. Cách này cho phép kiểm soát hoàn toàn tài nguyên bên dưới nhưng đi kèm trách nhiệm quản trị hạ tầng.
Ngoài triển khai thuần đám mây và Kubernetes tự quản, Astronomer là nhà cung cấp dịch vụ Airflow được quản lý phổ biến nhất hiện nay.
Họ cung cấp nhiều công cụ mã nguồn mở (CLI, SDK, tài liệu phong phú) bên cạnh dịch vụ PaaS “Astro” để việc phát triển và triển khai Airflow trơn tru nhất. Với Astro, phân bổ tài nguyên, kiểm soát truy cập nền tảng và nâng cấp Airflow tại chỗ được hỗ trợ sẵn, giúp bạn tập trung vào phát triển pipeline.
Dù không quá kỹ thuật, các câu hỏi theo kịch bản lại là những câu quan trọng nhất trong phỏng vấn Airflow. Trả lời chi tiết và thấu đáo cho thấy năng lực sâu không chỉ với Airflow mà còn với kiến trúc và nguyên tắc thiết kế dữ liệu.
Trả lời: Đây là câu thú vị! Với dạng câu hỏi này, bạn có rất nhiều lựa chọn. Điều quan trọng nhất là: khi mô tả quy trình, hãy chọn các công cụ và quy trình trong pipeline kế thừa mà bạn quen thuộc. Điều này thể hiện chuyên môn của bạn và giúp câu trả lời thuyết phục hơn.
Đây cũng là dịp để thể hiện kỹ năng quản lý dự án và lãnh đạo. Hãy nói bạn sẽ cấu trúc dự án ra sao, tương tác với bên liên quan và kỹ sư khác thế nào, và cách bạn ghi chép/giao tiếp quy trình. Điều này cho thấy bạn coi trọng giá trị đem lại và giúp cuộc sống của đội nhóm dễ dàng hơn.
Nếu công ty có công cụ cụ thể trong stack (ví dụ Google BigQuery), có thể hợp lý khi nói về cách bạn tái cấu trúc để chuyển từ Postgres sang BigQuery. Điều này thể hiện bạn không chỉ hiểu Airflow mà còn nắm các thành phần khác trong hạ tầng của công ty.
Trả lời: Để thiết kế DAG này, trước tiên bạn cần gọi API để trích xuất dữ liệu. Có thể dùng PythonOperator và một callable tự viết. Trong callable đó, bạn cũng nên lưu dữ liệu vào vị trí lưu trữ đám mây như AWS S3.
Sau khi lưu, bạn có thể dùng operator dựng sẵn như S3ToSnowflakeOperator để nạp dữ liệu từ S3 vào kho dữ liệu Snowflake. Cuối cùng, chạy một job DBT để biến đổi dữ liệu bằng DbtCloudRunJobOperator.
Bạn sẽ cần lập lịch DAG này chạy theo khoảng mong muốn và cấu hình để xử lý lỗi một cách nhã nhặn (nhưng vẫn có khả năng quan sát). Xem sơ đồ bên dưới!
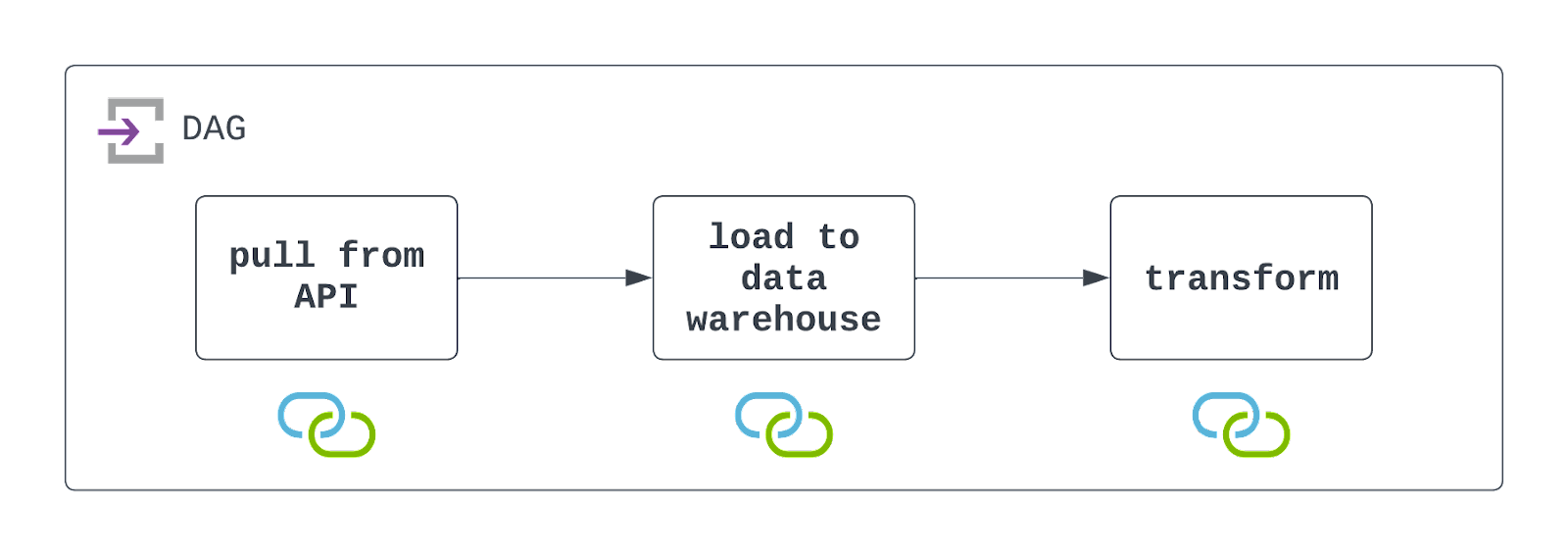
Cần lưu ý rằng Airflow đang tương tác với cả hệ thống tệp lưu trữ đám mây và kho dữ liệu. Để DAG chạy thành công, các tài nguyên này phải tồn tại và connections phải được định nghĩa và sử dụng. Điều này được biểu thị bằng các biểu tượng dưới mỗi tác vụ trong sơ đồ kiến trúc ở trên.
Tìm hiểu thêm: Đây là vài câu hỏi phỏng vấn Airflow phổ biến nhất, tập trung nhiều hơn vào thiết kế và triển khai DAG ở mức cao thay vì chi tiết kỹ thuật nhỏ nhặt. Với các câu này, cần nhớ:
DbtCloudRunJobOperator, hãy nêu tên công cụ, không cần giải thích thêm (trừ khi được hỏi).Trả lời: Tính linh hoạt và mức độ phổ biến ngày càng tăng của Airflow khiến nó trở thành công cụ ưa chuộng không chỉ với Kỹ sư Dữ liệu. Nhà khoa học dữ liệu và Kỹ sư Machine Learning dùng Airflow để huấn luyện (và tái huấn luyện) mô hình, cũng như thực hiện đầy đủ bộ MLOps. Kỹ sư AI thậm chí bắt đầu dùng Airflow để quản lý và mở rộng mô hình tạo sinh của họ, với các tích hợp mới cho OpenAI, OpenSearch và Pinecone.
Tìm hiểu thêm: Việc phát triển ngoài các pipeline kỹ thuật dữ liệu truyền thống có thể không phải điều những người tạo ra Airflow ban đầu hình dung. Tuy nhiên, nhờ tận dụng Python và triết lý mã nguồn mở, Airflow đã phát triển để đáp ứng nhu cầu của lĩnh vực dữ liệu/AI đang thay đổi nhanh chóng. Khi cần lập lịch và thực thi tác vụ theo lập trình, Airflow có thể là công cụ tốt nhất cho công việc!
Làm tốt lắm! Bạn đã vượt qua một chặng khó. Các câu hỏi trên tuy thử thách nhưng bao quát phần lớn nội dung thường được hỏi trong các phỏng vấn kỹ thuật xoay quanh Airflow.
Bên cạnh việc ôn lại các câu hỏi trên, một trong những cách tốt nhất để chuẩn bị cho phỏng vấn Airflow là tự xây pipeline dữ liệu bằng Airflow.
Hãy tìm một bộ dữ liệu bạn hứng thú và bắt đầu xây pipeline ETL (hoặc ELT) từ con số 0. Luyện tập dùng TaskFlow API và operator truyền thống. Lưu thông tin nhạy cảm bằng connections của Airflow. Thử báo cáo lỗi bằng callbacks và kiểm thử DAG bằng unit test và end-to-end. Quan trọng nhất, hãy ghi chép và chia sẻ công việc bạn đã làm.
Một dự án như vậy không chỉ thể hiện năng lực với Airflow mà còn niềm đam mê và khát khao học hỏi, phát triển. Nếu bạn vẫn cần phần mở đầu về một số nguyên tắc cơ bản, hãy xem khóa Introduction to Airflow in Python, bài so sánh Airflow vs Prefect, và hướng dẫn Bắt đầu với Apache Airflow.
Chúc bạn may mắn và code vui vẻ!
Tiếp tục hành trình Data Engineering của bạn ngay hôm nay!
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút