
Leerpad
Data-engineer in Python
40 Hr
In een technisch gesprek beginnen interviewers meestal rustig, met de basis van Airflow’s framework en kernconcepten, om daarna op te bouwen naar complexere en technischer vragen.
Als je deze vragen beantwoordt, ga dan niet alleen in op technische details, maar benoem ook hoe dit aansluit op een data-engineering- en/of enterprise dataworkflow.
Antwoord: Apache Airflow is een open-source tool voor data-orkestratie waarmee dataprofessionals met Python programmatiche datapijplijnen kunnen definiëren. Airflow wordt het vaakst gebruikt door data-engineeringteams om hun data-ecosysteem te integreren en data te extraheren, transformeren en laden.
Vertel me meer: Airflow valt onder de Apache-softwarelicentie (vandaar het voorvoegsel “Apache”).
Een tool voor data-orkestratie biedt functionaliteit om meerdere bronnen en services in één pijplijn te integreren.
Wat Airflow onderscheidt als orkestratietool is het gebruik van Python om pijplijnen te definiëren, wat een mate van uitbreidbaarheid en controle biedt die andere tools niet hebben. Airflow heeft veel ingebouwde en provider-ondersteunde integraties voor elke datastack, en je kunt er ook zelf bouwen.
Meer weten over het starten met Airflow? Bekijk deze DataCamp-tutorial: Aan de slag met Apache Airflow. Wil je nog dieper duiken in data-orkestratie met Airflow, dan is deze cursus Introductie tot Airflow de beste plek om te beginnen.
Antwoord: Een DAG, of directed acyclic graph (gerichte acyclische graaf), is een verzameling taken en de relaties daartussen. Een DAG heeft een duidelijke start en einde en bevat geen “cycli” tussen taken. In Airflow wordt de term “DAG” vaak gebruikt en kun je die doorgaans zien als een datapijplijn.
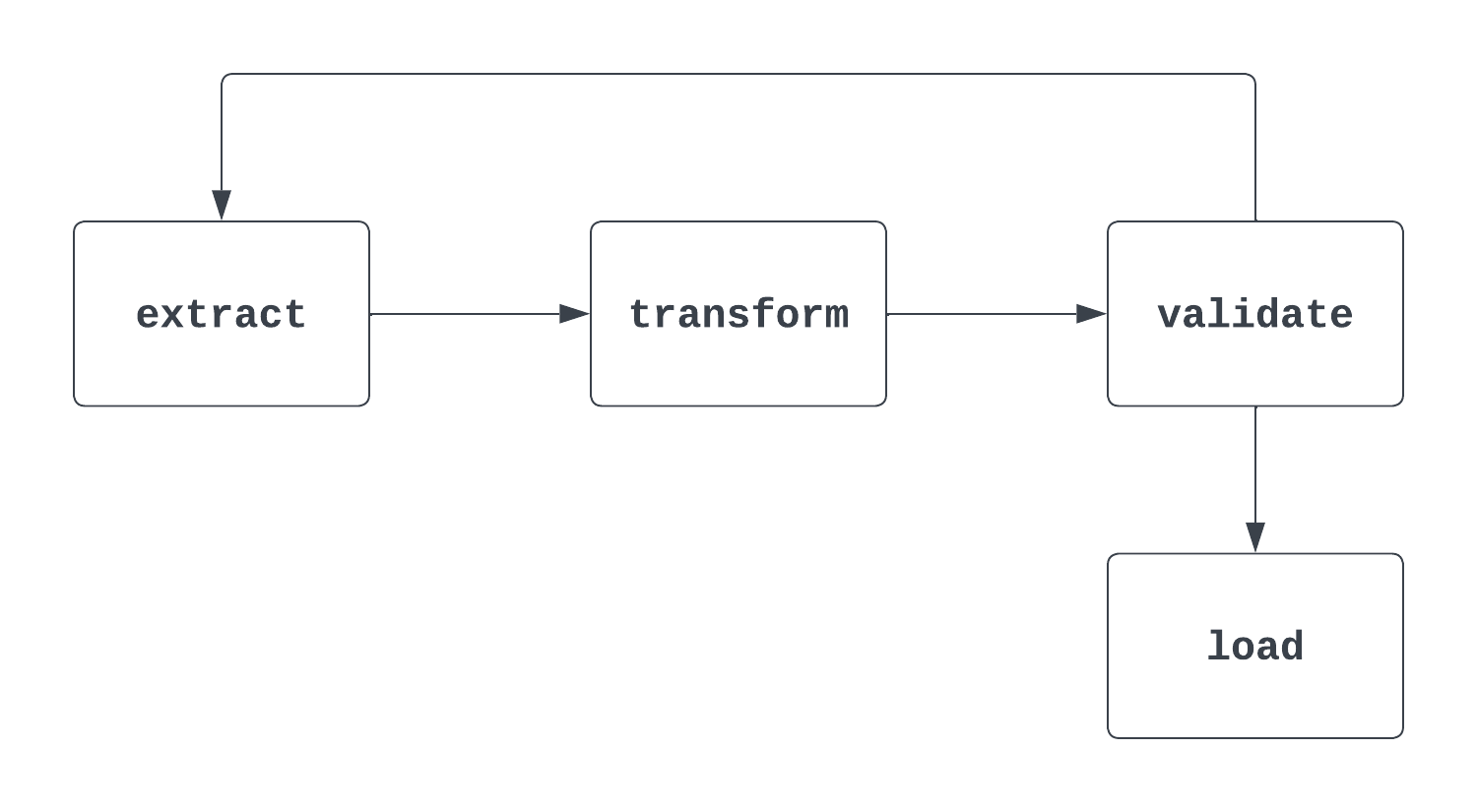
Vertel me meer: Dit is een lastige. Als een interviewer deze vraag stelt, is het belangrijk om zowel de formele, “wiskundige” definitie van een DAG te benoemen als de manier waarop het in Airflow wordt gebruikt. Een visual helpt. De eerste afbeelding hieronder is inderdaad een DAG. Er is een duidelijke start en einde en geen cycli tussen taken.

Het tweede proces hieronder is GEEN DAG. Hoewel er een duidelijke starttaak is, zit er een cyclus tussen de taken extract en validate, waardoor onduidelijk is wanneer de taak load getriggerd kan worden.
Antwoord: Om een DAG te definiëren, moet je een ID, startdatum en schema-interval opgeven.
Vertel me meer: De ID identificeert de DAG uniek en is meestal een korte string, zoals "sample_da." De startdatum is de datum en tijd van het eerste interval waarop een DAG wordt getriggerd.
Dit is een tijdstempel, wat betekent dat jaar, maand, dag, uur en minuut exact zijn gespecificeerd. Het schema-interval bepaalt hoe vaak de DAG moet draaien. Dit kan wekelijks, dagelijks, elk uur of iets meer op maat zijn.
In dit voorbeeld is de DAG gedefinieerd met een dag_id van "sample_dag". De functie datetime uit de datetime-bibliotheek zet een start_date op 1 januari 2024 om 09:00 uur. Deze DAG draait dagelijks (om 09:00 uur), aangegeven door het schema-interval @daily. Meer aangepaste intervallen kun je instellen met cron-expressies of de functie timedelta uit de datetime-bibliotheek.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Antwoord: Airflow-taken zijn de kleinste uitvoereenheid in het Airflow-framework. Een taak omvat doorgaans één bewerking in een datapijplijn (DAG). Taken zijn de bouwstenen van DAGs, en taken binnen een DAG hebben onderlinge relaties die de uitvoervolgorde bepalen. Drie voorbeelden:
In een ETL-pijplijn zijn de relaties als volgt:
Vertel me meer: Taken kunnen heel generiek of juist erg maatwerk zijn. Airflow biedt twee manieren om taken te definiëren: traditionele operators en de TaskFlow API (daarover later meer).
Een voordeel van open source is de bijdrage van de bredere gemeenschap, niet alleen van individuele bijdragers maar ook van partijen als AWS, Databricks, Snowflake en nog veel meer.
De kans is groot dat er al een Airflow-operator is gebouwd voor de taak die jij wilt definiëren. Zo niet, dan is het eenvoudig om je eigen operator te maken. Enkele voorbeelden zijn de SFTPToS3Operator, S3ToSnowflakeOperator en DatabricksRunNowOperator.
Antwoord: Er zijn vier kernonderdelen: de scheduler, executor, metadatadatabase en de webserver.
Vertel me meer: De scheduler controleert elke minuut de DAG-map en monitort DAGs en taken om te bepalen welke taken getriggerd kunnen worden. Een executor is waar taken draaien. Taken kunnen lokaal (binnen de scheduler) of extern (buiten de scheduler) worden uitgevoerd.
De executor is waar het computationele “werk” van elke taak plaatsvindt. De metadatadatabase bevat alle informatie over de DAGs en taken van het Airflow-project dat je draait. Denk aan historische uitvoerdata, connections, variabelen en nog veel meer.
De webserver zorgt ervoor dat de Airflow-UI gerenderd en bedienbaar is tijdens het ontwikkelen, gebruiken en onderhouden van DAGs.
Dit is slechts een kort overzicht van de architecturale componenten van Airflow.
Je hebt laten zien dat je de basis van het Airflow-framework en de architectuur kent. Tijd om je kennis van het schrijven van DAGs te testen.
PythonOperator? Welke vereisten zijn er om deze operator te gebruiken? Noem een voorbeeldsituatie waarin je de PythonOperator zou inzetten.Antwoord: De PythonOperator is een functie waarmee je een Python-functie als Airflow-taak kunt uitvoeren. Om deze operator te gebruiken, moet een Python-functie worden doorgegeven aan de parameter python_callable. Een voorbeeld is het aanroepen van een API om data te extraheren.
Vertel me meer: De PythonOperator is een van de krachtigste operators van Airflow. Je kunt er niet alleen maatwerkcode mee uitvoeren binnen een DAG, maar de resultaten kunnen ook naar XComs worden geschreven voor gebruik door downstream-taken.
Door een dictionary door te geven aan de parameter op_kwargs kun je keyword-argumenten meegeven aan de Python-callable, wat extra maatwerk tijdens runtime mogelijk maakt. Naast op_kwargs zijn er nog tal van parameters om de functionaliteit van de PythonOperator uit te breiden.
Hieronder staat een voorbeeld van een aanroep van de PythonOperator. Meestal staat de Python-functie die aan python_callable wordt doorgegeven buiten het bestand met de DAG-definitie. Voor de volledigheid is die hier opgenomen.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Antwoord: Er zijn meerdere manieren. Een van de meestgebruikte is de bitshift-operator >>. Een andere is de methode .set_downstream() om een taak downstream van een andere te plaatsen. De functie chain is ook handig om sequentiële afhankelijkheden te zetten. Drie voorbeelden:
# task_1, task_2, task_3 instantiated above
# Using bit-shift operators
task_1 >> task_2 >> task_3
# Using .set_downstream()
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# Using chain
chain(task_1, task_2, task_3)
Vertel me meer: Afhankelijkheden zetten kan simpel zijn, maar soms ook aardig complex! Voor sequentiële uitvoering is het gebruik van bitshift-operators gebruikelijk en duidelijk. Met de TaskFlow API ziet het zetten van afhankelijkheden er wat anders uit.
Als er twee afhankelijke taken zijn, kun je dat aangeven door een functieresultaat door te geven aan een andere functie, in plaats van de bovenstaande technieken te gebruiken. Meer over taakafhankelijkheden lees je in een apart artikel.
Antwoord: Task groups worden gebruikt om taken binnen een DAG te groeperen. Zo kun je vergelijkbare taken in de Airflow-UI overzichtelijk bij elkaar tonen. Handig als je in dezelfde DAG data voor verschillende teams extraheert, transformeert en laadt.
Task groups worden ook vaak gebruikt bij het trainen van meerdere ML-modellen of bij interactie met meerdere (maar vergelijkbare) bronsystemen binnen één DAG.
Met task groups in Airflow kan de graph view er bijvoorbeeld zo uitzien:
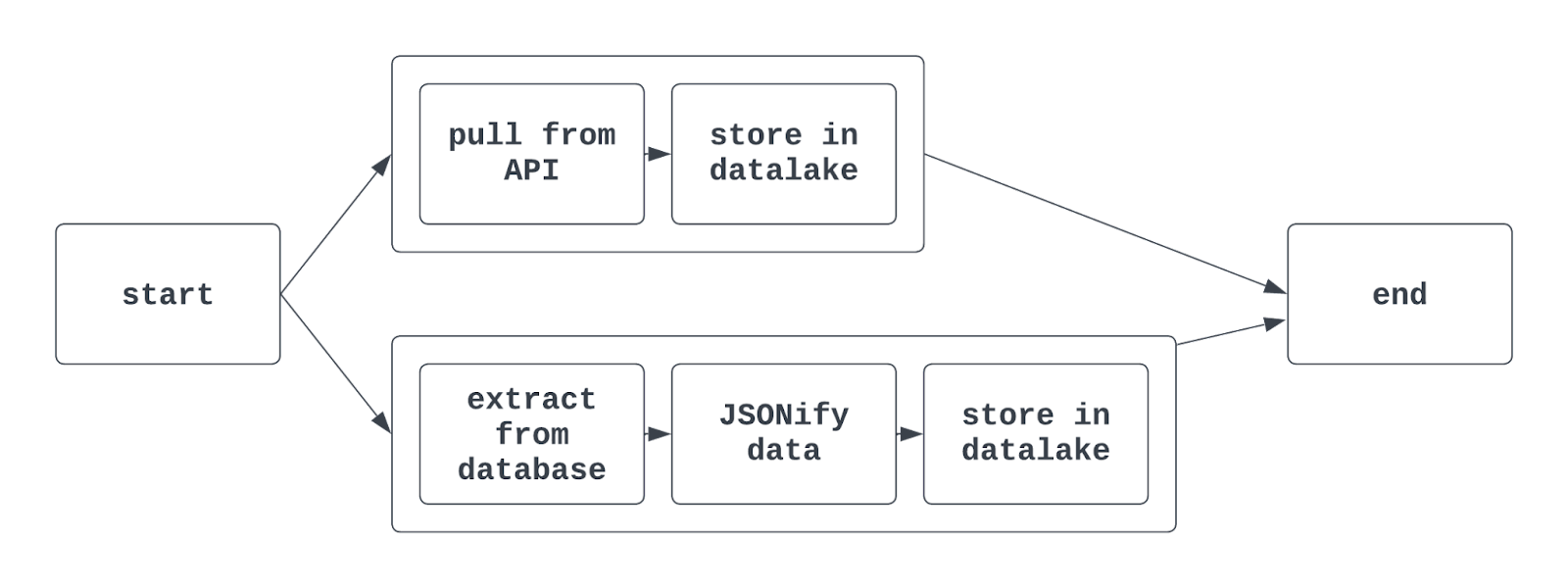
Vertel me meer: Met traditionele Airflow-syntax gebruik je de functie TaskGroup om task groups te maken. Task groups kunnen expliciet of dynamisch worden gegenereerd, maar moeten unieke IDs hebben (net als DAGs).
Verschillende task groups in dezelfde DAG mogen wel taken met dezelfde task_id hebben. De taak wordt dan uniek geïdentificeerd door de combinatie van task group ID en task ID. Met de TaskFlow API kun je ook de decorator @task_group gebruiken om een task group te maken.
Antwoord: Dynamisch DAGs genereren is een handige techniek om met één “stuk” code meerdere DAGs te maken. Data ophalen uit meerdere locaties is een goed voorbeeld. Als je data van drie luchthavens moet ETL’en met dezelfde logica, helpt dynamisch genereren om dit te stroomlijnen.
Er zijn verschillende manieren. Een van de eenvoudigste is een lijst met metadata waarover je loept. Binnen de lus instantieer je een DAG. Let erop dat elke DAG een unieke DAG ID heeft. De code kan er ongeveer zo uitzien:
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# Rest of the DAG definition
...
Deze code maakt drie DAGs met IDs atl_daily_etl, lax_daily_etl en jfk_daily_etl. Downstream kun je taken parametriseren met dezelfde luchthavencode zodat elke DAG werkt zoals bedoeld.
Vertel me meer: DAGs dynamisch genereren wordt vaak gebruikt in enterprise-omgevingen. Bij de keuze tussen programmatiche task groups in één DAG of dynamisch meerdere DAGs maken, moet je nadenken over de onderlinge afhankelijkheden.
In ons voorbeeld: als één luchthaven een exceptie veroorzaakt, leidt het gebruik van task groups tot falen van de hele DAG. Als je in plaats daarvan DAGs dynamisch genereert, zorgt dit ene probleem niet voor falen van de andere twee DAGs.
Itereren over een Python-iterable is niet de enige manier om DAGs dynamisch te maken: een functie create_dag definiëren, variabelen/connections gebruiken om DAGs te spawnen, of een JSON-configuratiebestand inzetten zijn gangbare opties. Externe tools zoals gusty en dag-factory bieden extra configuratiegedreven aanpakken.
De basis van Airflow en DAG-ontwikkeling begrijpen en uitleggen is vaak genoeg voor een juniorrol. Maar Airflow beheersen is meer dan DAGs schrijven en uitvoeren.
De onderstaande Q&A laat een interviewer zien dat je de complexere functionaliteit van Airflow begrijpt, wat meestal vereist is voor seniorrollen.
data_interval_start en data_interval_end, wanneer wordt een DAG uitgevoerd?Antwoord: Zoals de namen suggereren, zijn data_interval_start en data_interval_end de temporele grenzen van de DAG-run. Als een DAG wordt teruggevuld (backfilled) en het tijdstip van uitvoeren groter is dan data_interval_end, dan wordt de DAG direct in de wachtrij gezet om te draaien.
Bij “normale” uitvoering geldt echter: een DAG draait pas wanneer het uitvoertijdstip groter is dan de **data_interval_end**.
Vertel me meer: Dit is een lastig concept, zeker gezien de labels van DAG-runs. Zo kun je erover nadenken: je wilt alle data voor 17 maart 2024 uit een API halen.
Als het schema-interval dagelijks is, dan is de data_interval_start voor deze run 2024-03-17 00:00:00 UTC en de data_interval_end 2024-03-18 00:00:00 UTC. Het is niet logisch om deze DAG te draaien op 2024-03-17 00:00:00 UTC, want de data voor 17 maart is dan nog niet compleet. In plaats daarvan draait de DAG op de data_interval_end van 2024-03-18 00:00:00 UTC.
Antwoord: De parameter catchup wordt gedefinieerd bij het instantiëren van een DAG. catchup is True of False, en is standaard True als je niets opgeeft. Als True, worden alle DAG-runs tussen de startdatum en het moment waarop de status van de DAG voor het eerst op actief is gezet uitgevoerd.
Stel: de startdatum is 1 januari 2024, met een dagelijks schema en catchup=True. Als de huidige datum 15 april 2024 is wanneer deze DAG voor het eerst wordt geactiveerd, wordt de run met data_interval_start 1 januari 2024 uitgevoerd, gevolgd door 2 januari 2024 (enzovoort).
Dit gaat door totdat de DAG is “bijgewerkt”, waarna normaal gedrag hervat wordt. Dit heet “backfilling”. Backfilling kan snel gaan. Als je DAG-run maar een paar minuten duurt, kan je in enkele uren een paar maanden aan historische runs uitvoeren.
Als False, worden geen historische runs uitgevoerd en begint de eerste run aan het einde van het interval waarin de status van de DAG op actief is gezet.
Vertel me meer: Het kunnen terugvullen van runs zonder grote codewijzigingen of handwerk is een van de krachtigste features van Airflow. Stel dat je een integratie bouwt om alle transacties van het afgelopen jaar uit een API te halen.
Zodra je DAG klaar is, hoef je alleen je gewenste startdatum te zetten en catchup=True, en je haalt eenvoudig de historische data op.
Wil je niet backfillen bij de eerste activatie? Geen probleem. Er zijn meerdere manieren om systematisch backfills te triggeren. Dat kan met de Airflow API en de Airflow- (en Astro-) CLI.
Antwoord: XComs (cross-communications) zijn een geavanceerdere feature van Airflow waarmee berichten tussen taken kunnen worden opgeslagen en opgehaald.
XComs worden opgeslagen als key-valueparen en zijn op meerdere manieren te lezen en te schrijven. Met de PythonOperator kun je binnen de callable de methoden .xcom_push() en .xcom_pull() gebruiken om data naar/uit XComs te schrijven/lezen. XComs zijn bedoeld voor kleine hoeveelheden data, zoals bestandsnamen of een boolean.
Vertel me meer: Naast .xcom_push() en .xcom_pull() zijn er meer manieren om met XComs te werken. Bij de PythonOperator schrijft het meegeven van True aan de parameter do_xcom_push de returnwaarde van de callable naar XComs.
Dit beperkt zich niet tot de PythonOperator; elke operator die een waarde retourneert kan die waarde naar XComs schrijven met de parameter do_xcom_push. Onder de motorkap gebruikt de TaskFlow API ook XComs om data tussen taken te delen (daar kijken we zo naar).
Voor meer informatie over XComs, bekijk deze uitstekende blog van Airflow-legende Marc Lamberti.
Antwoord: De TaskFlow API biedt een nieuwe manier om DAGs te schrijven op een meer intuïtieve, “Pythonic” manier. In plaats van traditionele operators worden Python-functies gedecoreerd met @task, en kunnen afhankelijkheden tussen taken worden afgeleid zonder ze expliciet te definiëren.
Een taak geschreven met de TaskFlow API kan er zo uitzien:
import random
...
@task
def get_temperature():
# Pull a temperature, return the value
temperature = random.randint(0, 100)
return temperature
…
Met de TaskFlow API is data delen tussen taken eenvoudig. In plaats van direct XComs te gebruiken, kan de returnwaarde van de ene taak (functie) rechtstreeks als argument aan een andere taak worden meegegeven. Daarbij worden XComs nog steeds achter de schermen gebruikt, wat betekent dat je ook met de TaskFlow API geen grote hoeveelheden data tussen taken kunt delen.
Vertel me meer: De TaskFlow API maakt onderdeel uit van Airflow’s inzet om het schrijven van DAGs eenvoudiger te maken, zodat het framework aantrekkelijker is voor data scientists en analisten. Hoewel de TaskFlow API niet altijd voldoet aan de behoeften van data-engineeringteams die een cloud-ecosysteem integreren, is hij vooral handig (en intuïtief) voor basis-ETL-taken.
De TaskFlow API en traditionele operators kunnen in dezelfde DAG worden gebruikt, zodat je zowel integratiemogelijkheden als gebruiksgemak hebt. Meer over de TaskFlow API vind je in de documentatie.
Antwoord: Idempotentie is een eigenschap van een proces/bewerking waardoor dit meerdere keren kan worden uitgevoerd zonder het initiële resultaat te veranderen. Simpeler: of je een DAG één of tien keer draait, de resultaten moeten identiek zijn.
Een veelvoorkomend patroon waar dit misgaat, is het invoegen van data in gestructureerde (SQL-)databases. Als je data inbrengt zonder primaire-sleutelhandhaving en je draait de DAG meerdere keren, dan krijg je duplicaten in de tabel. Patronen zoals delete-insert of “upsert” helpen idempotentie te realiseren.
Vertel me meer: Dit is niet specifiek voor Airflow, maar wel essentieel bij het ontwerpen en bouwen van datapijplijnen. Gelukkig biedt Airflow diverse tools om idempotentie makkelijker te maken. Toch zal het grootste deel van deze logica door de gebruiker van Airflow moeten worden ontworpen, ontwikkeld en getest.
Voor technischere rollen kan een interviewer vragen stellen over het beheer en de monitoring van een productieklare Airflow-omgeving, vergelijkbaar met wat hun team draait. Deze vragen zijn wat lastiger en vergen extra voorbereiding.
Antwoord: Er zijn een paar manieren om een DAG te testen nadat hij is geschreven. De meest gangbare is de DAG uitvoeren om te controleren of hij succesvol draait. Dit kan door lokaal een Airflow-omgeving op te starten en via de UI de DAG te triggeren.
Zodra de DAG is getriggerd, kun je de uitvoering monitoren om de performance te valideren (succes/falen van de DAG en individuele taken, plus de tijd en resources die nodig waren).
Naast handmatig testen via uitvoering kun je ook unittests schrijven. Airflow biedt CLI-tools om tests uit te voeren, of je gebruikt een standaard testrunner. Deze unittests kunnen zowel de configuratie en uitvoering van DAGs dekken als andere componenten van een Airflow-project, zoals callables en plugins.
Vertel me meer: Het testen van Airflow-DAGs is een van de belangrijkste taken van een Data Engineer. Zonder tests is een DAG niet klaar voor productie.
Datapijplijnen testen is extra lastig; er zijn rand- en hoekgevallen die je in andere ontwikkelsituaties minder ziet. Benoem in een technisch gesprek (zeker als Lead/Senior Engineer) het belang van end-to-end testen naast unittests, en het documenteren van de resultaten daarvan.
Antwoord: Niemand houdt van falende DAGs, maar er netjes mee omgaan onderscheidt je als Data Engineer. Gelukkig biedt Airflow talloze tools om falen vast te leggen, te alarmeren en op te lossen. Eerst wordt de mislukking vastgelegd in de UI. De status van de DAG verandert naar “failed” en in grid view zie je een rood blok voor deze run. Vervolgens kun je in de UI handmatig de logs van deze taak doorspitten.
Meestal zie je daar de exceptie die het falen veroorzaakte, plus info om verder te triëren.
Zodra het probleem is gevonden, kun je de onderliggende code/configuratie aanpassen en de DAG opnieuw draaien. Dat kan door de status van de DAG te clearen en hem op “active” te zetten.
Als een DAG regelmatig faalt maar het bij een retry wel goed gaat, is het handig om retries en retry_delay in te zetten. Met deze twee parameters kun je een taak bij falen een opgegeven aantal keren opnieuw proberen met een bepaalde wachttijd. Handig als je bijvoorbeeld een bestand van een SFTP-site probeert te halen dat soms later beschikbaar is.
Vertel me meer: Voor een DAG om te falen, moet een specifieke taak falen. Richt je triage op die taak, niet op de hele DAG. Naast de functionaliteit in de UI zijn er nog tal van andere tools om performance te monitoren en beheren.
Callbacks bieden vrijwel onbeperkte maatwerkopties voor het afhandelen van successen en mislukkingen. Met callbacks kun je een zelfgekozen functie uitvoeren wanneer een DAG slaagt of faalt via de parameters on_success_callback en on_failure_callback van een operator. Die functie kan bijvoorbeeld een bericht sturen naar een tool als PagerDuty of het resultaat naar een database schrijven om later op te alarmeren. Dit vergroot de zichtbaarheid en versnelt de triage bij een failure.
Antwoord: Een van de handigste tools van Airflow zijn “connections”. Hiermee kan een DAG-auteur verbindingsinformatie (zoals host, gebruikersnaam, wachtwoord, etc.) opslaan en gebruiken zonder deze in code te hardcoden.
Er zijn meerdere manieren om connections op te slaan; de meest voorkomende is via de UI. Zodra een connection is aangemaakt, kun je die in code benaderen met een “hook”. De meeste traditionele operators die met een bronsysteem praten, hebben echter een veld conn_id (of iets vergelijkbaars) dat een string aanneemt en de verbinding opzet.
Airflow-connections helpen gevoelige informatie veilig te houden en maken het opslaan en ophalen ervan eenvoudig.
Vertel me meer: Naast de UI kun je via de CLI connections opslaan en ophalen. In enterprise-omgevingen is het gangbaarder om een eigen “secrets backend” te gebruiken voor connection-informatie. Airflow ondersteunt meerdere secrets backends. Een bedrijf dat AWS gebruikt, kan eenvoudig Secrets Manager integreren om connections en gevoelige info op te slaan en op te halen. Indien nodig kunnen connections ook via omgevingsvariabelen worden gedefinieerd.
Antwoord: Het deployen van een productieklare Airflow-omgeving kan lastig zijn. Cloudtools zoals Azure en AWS bieden beheerde services om Airflow te deployen en beheren. Deze vereisen echter een cloudaccount en kunnen wat prijzig zijn.
Een veelgebruikt alternatief is Kubernetes om een productie-Airflow-omgeving te draaien. Dit geeft volledige controle over de onderliggende resources, maar brengt ook de verantwoordelijkheid voor het beheer van die infrastructuur met zich mee.
Buiten cloud-native en eigen Kubernetes-deployments is Astronomer de populairste managed service provider voor Airflow.
Ze bieden veel open-sourcetools (CLI, SDK, uitgebreide documentatie) naast hun “Astro”-PaaS om ontwikkeling en deployment zo soepel mogelijk te maken. Met Astro zijn resource-allocatie, toegangsbeheer en in-place Airflow-upgrades standaard ondersteund, zodat je je weer kunt richten op het bouwen van pijplijnen.
Hoewel scenario-vragen niet overdreven technisch zijn, behoren ze tot de belangrijkste vragen in een Airflow-gesprek. Door doordachte, gedetailleerde antwoorden te geven, laat je zien dat je niet alleen Airflow beheerst, maar ook principes van data-architectuur en -ontwerp.
Antwoord: Leuke vraag! Bij zo’n vraag kun je veel kanten op. Het belangrijkste is dit: kies in je uitleg voor tools en processen uit de legacy-pijplijn waarmee jij bekend bent. Dat toont je expertise en maakt je antwoord beter onderbouwd.
Dit is ook hét moment om je projectmanagement- en leiderschapsvaardigheden te laten zien. Vertel hoe je het project zou structureren, met stakeholders en engineers samenwerkt, en processen documenteert/communiceert. Dat laat zien dat je waarde levert en het werk van je team makkelijker maakt.
Als een bedrijf een bepaalde tool gebruikt (zeg Google BigQuery), kan het logisch zijn om te bespreken hoe je van bijvoorbeeld Postgres kunt migreren naar BigQuery. Daarmee toon je niet alleen kennis van Airflow, maar ook van andere onderdelen van de infrastructuur.
Antwoord: Om deze DAG te ontwerpen, moet je eerst de API aanroepen om data te extraheren. Dat kan met de PythonOperator en een eigen callable. Binnen die callable wil je de data ook opslaan in cloudopslag, zoals AWS S3.
Zodra de data is opgeslagen, kun je een kant-en-klare operator gebruiken, zoals de S3ToSnowflakeOperator, om data van S3 naar een Snowflake-datawarehouse te laden. Tot slot kun je een DBT-job draaien om de data te transformeren met de DbtCloudRunJobOperator.
Plan deze DAG op het gewenste interval en configureer hem om falen netjes af te handelen (met zichtbaarheid). Bekijk onderstaand diagram!
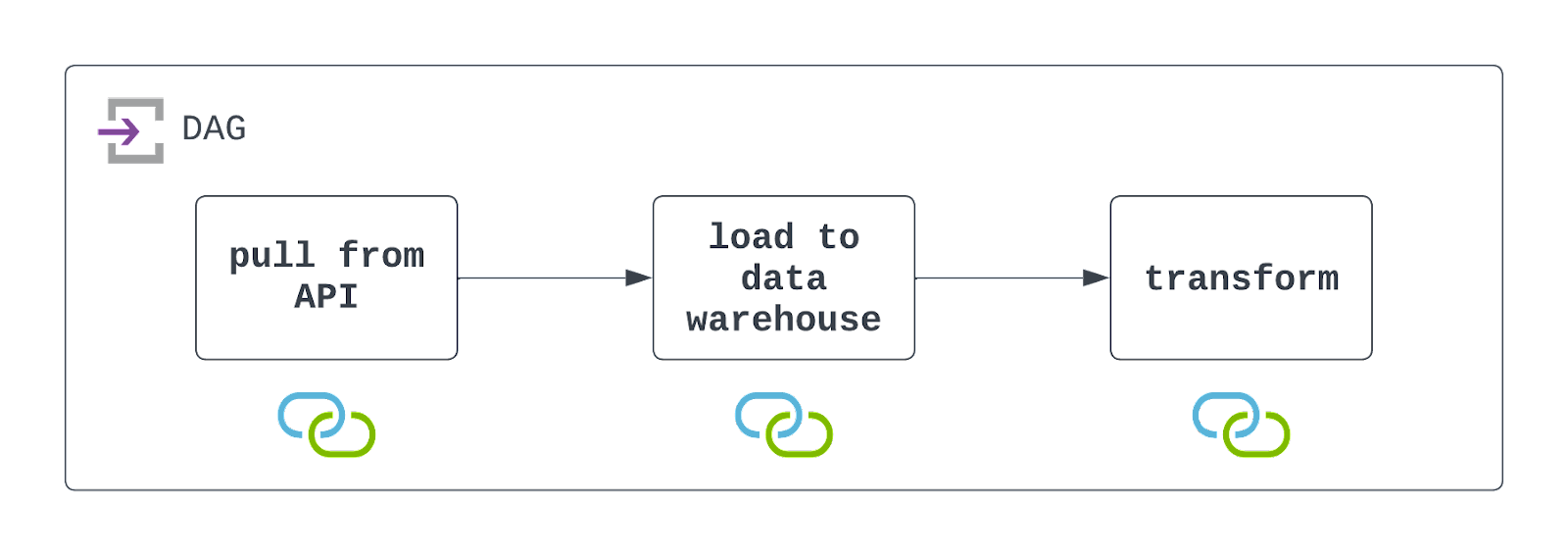
Onthoud dat Airflow hier met zowel cloudopslag als een datawarehouse praat. Voor succesvolle uitvoering moeten deze resources bestaan en moeten connections gedefinieerd en gebruikt worden. Die zie je terug onder de taken in het diagram.
Vertel me meer: Dit zijn enkele van de meest voorkomende Airflow-sollicitatievragen, met focus op hoog-over ontwerp en implementatie van een DAG, in plaats van de kleinste technische details. Houd bij dit soort vragen rekening met het volgende:
DbtCloudRunJobOperator wilt gebruiken, noem die dan, maar licht het niet verder toe (tenzij ernaar gevraagd).Antwoord: Dankzij de uitbreidbaarheid en populariteit van Airflow is het een go-to tool geworden voor meer dan alleen Data Engineers. Data Scientists en Machine Learning Engineers gebruiken Airflow om hun modellen te trainen (en hertrainen) en voor een volledige suite aan MLOps. AI Engineers zetten Airflow zelfs in om generatieve AI-modellen te beheren en op te schalen, met nieuwe integraties voor tools als OpenAI, OpenSearch en Pinecone.
Vertel me meer: Succes buiten traditionele data-engineeringpijplijnen was misschien niet wat de oorspronkelijke makers voor ogen hadden. Maar door Python en open-sourcefilosofie te omarmen, is Airflow meegegroeid met de snel evoluerende data-/AI-wereld. Wanneer programmatiche taken gepland en uitgevoerd moeten worden, is Airflow vaak de beste tool voor de klus!
Goed gedaan! Je bent erdoorheen. De bovenstaande vragen zijn uitdagend, maar dekken veel van wat er in technische Airflow-gesprekken wordt gevraagd.
Naast het doornemen van de vragen hierboven is een van de beste manieren om je voor te bereiden op een Airflow-gesprek het bouwen van je eigen datapijplijnen met Airflow.
Zoek een dataset die je interessant vindt en bouw je ETL- (of ELT-)pijplijn from scratch. Oefen met de TaskFlow API en traditionele operators. Sla gevoelige informatie op met Airflow-connections. Probeer fouten te rapporteren met callbacks en test je DAG met unittests en end-to-end. Het belangrijkst: documenteer en deel wat je hebt gedaan.
Zo’n project toont niet alleen je Airflow-vaardigheid, maar ook je passie en leergierigheid. Heb je nog een opfrisser nodig van de basisprincipes, bekijk dan onze cursus Introduction to Airflow in Python, onze vergelijking Airflow vs Prefect en onze tutorial Aan de slag met Apache Airflow.
Veel succes en happy coding!
Zet vandaag je volgende stap in data engineering!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
