Kurs
Python ile Finans için Machine Learning
4 sa
33K
Temel sorular terminoloji, algoritmalar ve yöntemlerle ilgilidir. Mülakatçılar, adayın teknik bilgisini değerlendirmek için bu soruları sorar.
Yarı denetimli öğrenme, denetimli ve denetimsiz öğrenmenin bir harmanıdır. Algoritma, etiketli ve etiketsiz verilerin bir karışımı üzerinde eğitilir. Genellikle, çok küçük bir etiketli veri kümesi ve büyük bir etiketsiz veri kümesi olduğunda kullanılır.
Basitçe söylemek gerekirse, denetimsiz algoritma kümeler oluşturur ve mevcut etiketli veriler kullanılarak geri kalan etiketsiz veriler etiketlenir. Yarı denetimli bir algoritma süreklilik varsayımı, küme varsayımı ve manifold varsayımı yapar.
Genellikle etiketli veri edinme maliyetini düşürmek için kullanılır. Örneğin, protein dizisi sınıflandırma, otomatik konuşma tanıma ve otonom araçlar.
Veri kümesine ek olarak, bir iş kullanım durumu veya uygulama gereksinimleri gerekir. Aynı veriye denetimli ve denetimsiz öğrenme uygulayabilirsiniz.
Genel olarak:
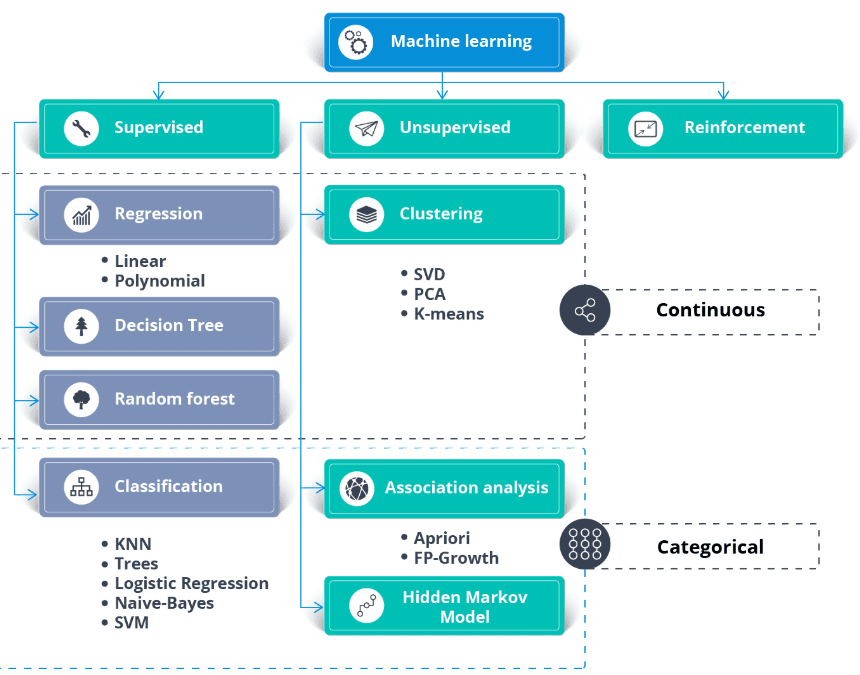
Görsel: thecleverprogrammer
Kursumuzu alarak makine öğrenimi temellerini öğrenin.
K En Yakın Komşu (KNN), denetimli bir öğrenme sınıflandırıcısıdır. Etiketleri sınıflandırmak veya tek tek veri noktalarının gruplandırmasını tahmin etmek için yakınlığı kullanır. Regresyon ve sınıflandırma için kullanılabilir. KNN algoritması parametrik olmayan bir yapıya sahiptir; yani veri dağılımı hakkında örtük bir varsayımda bulunmaz.
KNN sınıflandırıcısında:
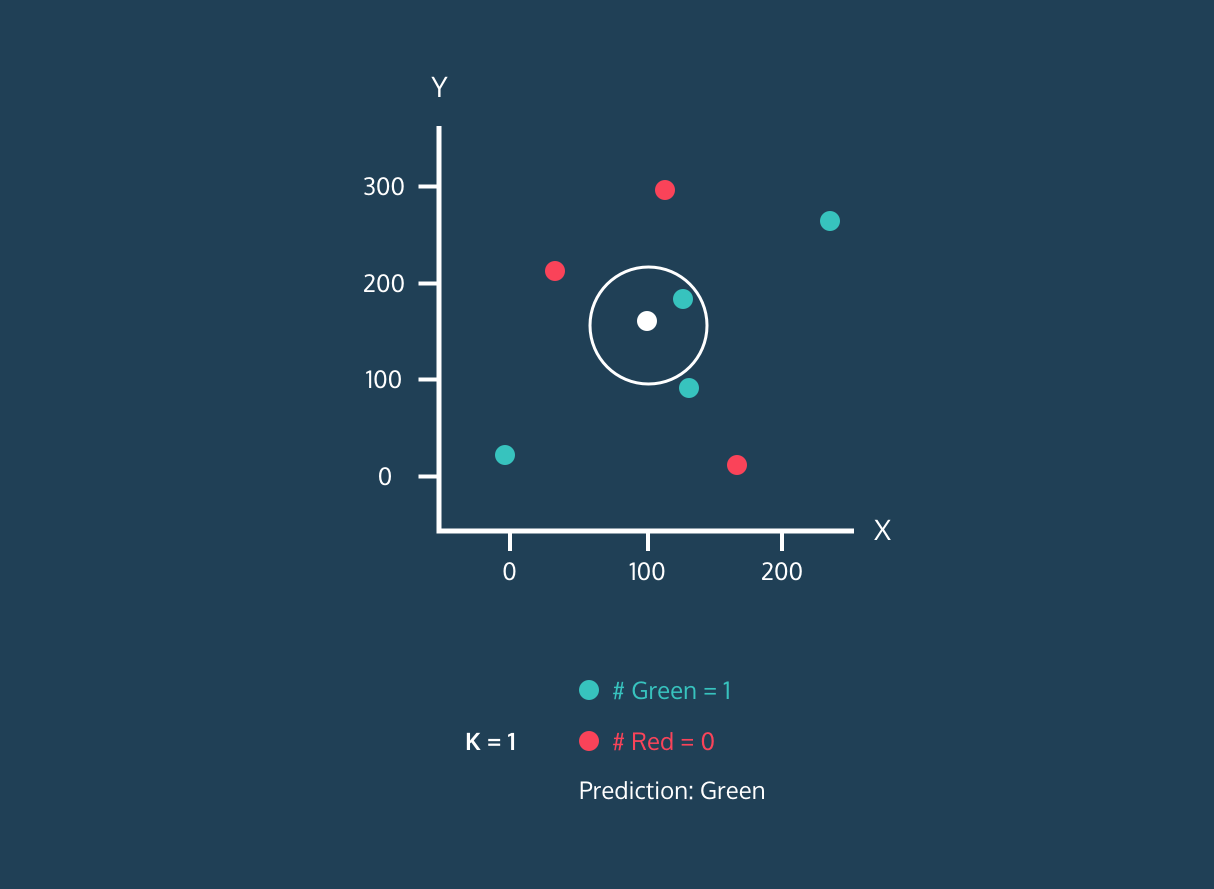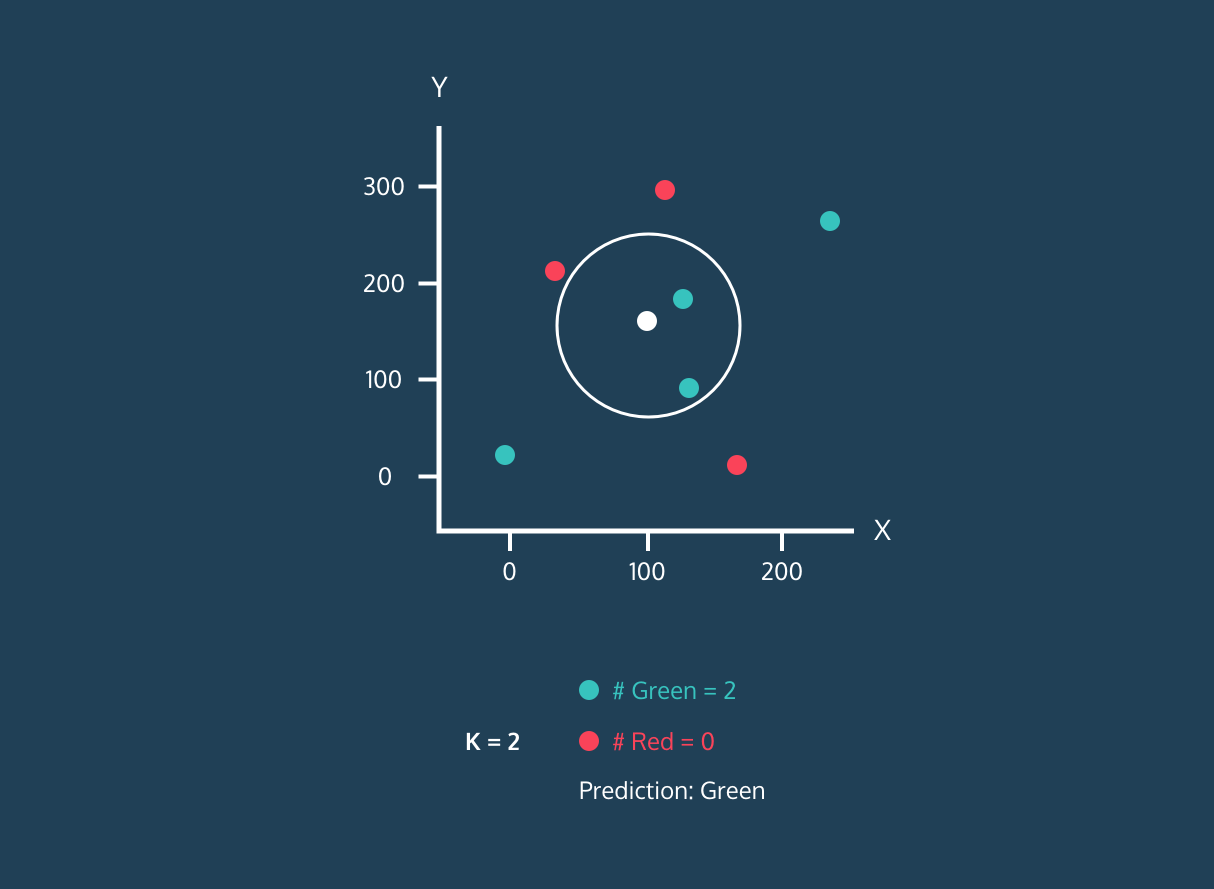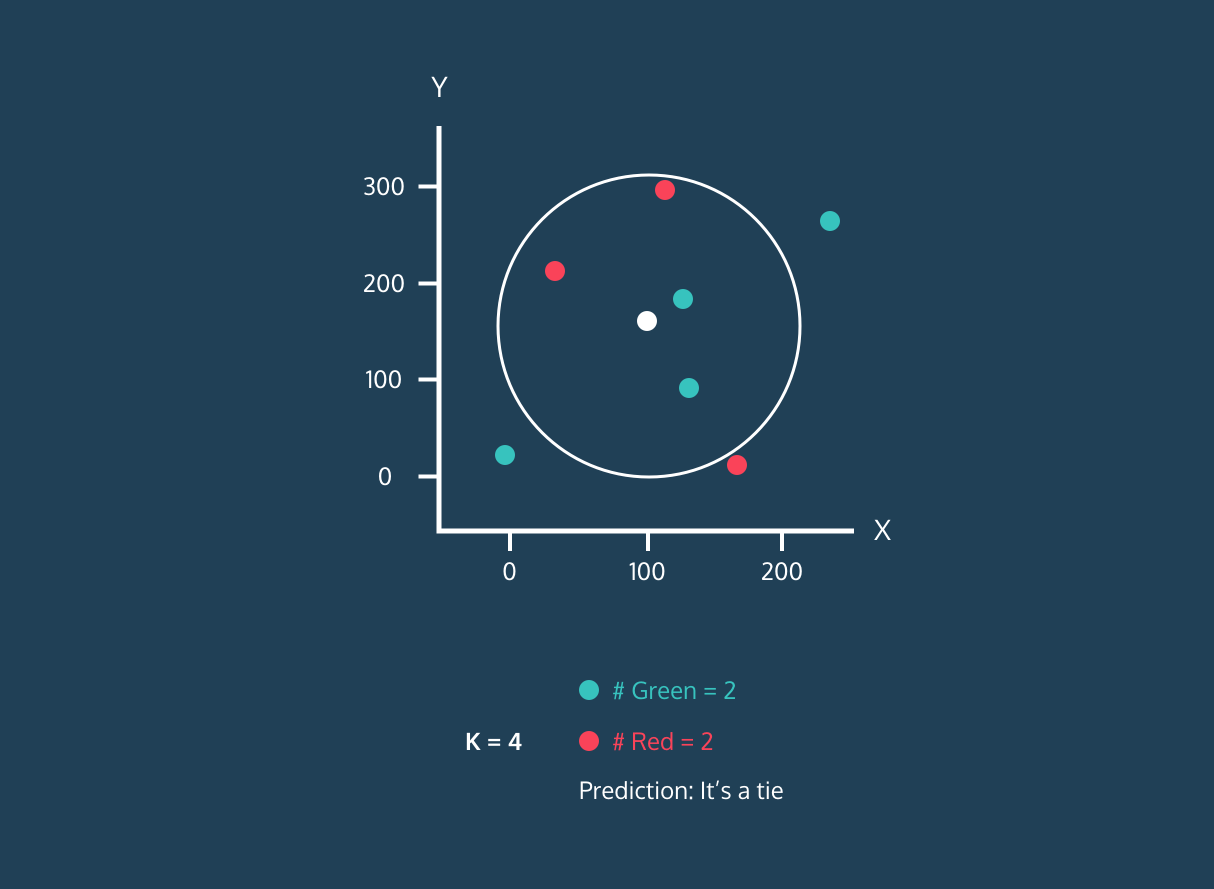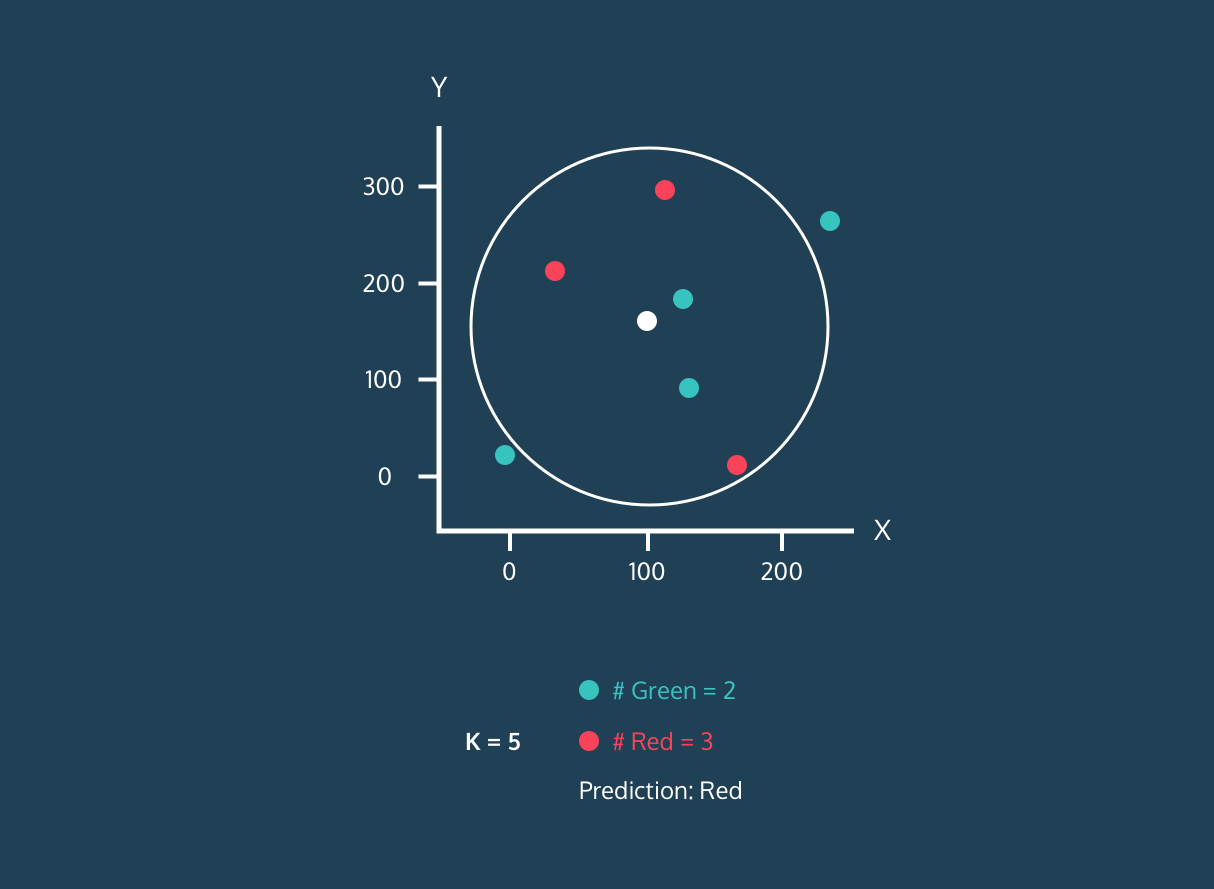
Görsel: Codesigner's Dev Story
Kısa bir kurs alarak denetimli öğrenme sınıflandırma ve regresyon modelleri hakkında her şeyi öğrenin.
Özellik önemi, hedef değişkeni tahmin etmede ne kadar faydalı olduklarına göre girdi özelliklerine bir puan atayan teknikleri ifade eder. Verinin temel yapısını, modelin davranışını anlamada ve modeli daha yorumlanabilir hale getirmede kritik bir rol oynar.
Özellik önemini belirlemek için çeşitli yöntemler vardır:
Özellik önemini anlamak, modeli optimize etmek, bilgi taşımayan özellikleri çıkararak aşırı uyum riskini azaltmak ve özellikle modelin karar sürecini anlamanın kritik olduğu alanlarda modelin yorumlanabilirliğini artırmak için çok önemlidir.
Aşırı uyum, bir model eğitim verisinde iyi performans gösterip, altta yatan örüntüleri öğrenmek yerine eğitim verisini ezberlediği için görülmemiş veriye genelleyemediğinde ortaya çıkar. Şunlarla önlenebilir:
Karmaşıklık matrisi, bir sınıflandırma modelinin performansını değerlendirmek için kullanılan bir tablodur. Doğru pozitif, doğru negatif, yanlış pozitif ve yanlış negatif sayılarını gösterir. Doğruluk, kesinlik (precision), duyarlılık (recall) ve F1 skoru gibi metriklerin hesaplanması için kullanışlıdır.
Parametrik Modeller: Verinin temel dağılımı hakkında varsayımlar yapar ve sabit sayıda parametreye sahiptir (ör. Doğrusal Regresyon).
Parametrik Olmayan Modeller: Veri dağılımı hakkında varsayım yapmaz ve daha fazla veri eklendikçe karmaşıklığa uyum sağlayabilir (ör. K-En Yakın Komşu).
Önyargı-varyans dengesi, bir modelin karmaşık örüntüleri yakalama yeteneği (düşük önyargı) ile eğitim verisindeki dalgalanmalara duyarlılığı (düşük varyans) arasındaki dengeyi ifade eder. İyi bir model, hem önyargıyı hem varyansı en aza indirerek aşırı ve yetersiz uyumu önleyecek bir denge sağlar.
Teknik mülakat oturumu, süreçler hakkındaki bilginizi ve belirsizlikle başa çıkma becerinizi değerlendirmeye yöneliktir. İşe alım uzmanı, veri işleme, model eğitimi ve doğrulama ile ileri algoritmalar hakkında makine öğrenimi mülakat soruları soracaktır.
Evet. Algoritmaların çoğu, veri noktaları arasındaki Öklid uzaklığını kullanır ve özellik değeri çok farklılık gösterirse sonuçlar oldukça farklı olur. Çoğu durumda aykırı değerler, makine öğrenimi modellerinin test veri kümesinde daha kötü performans göstermesine neden olur.
Ayrıca, yakınsama süresini azaltmak için özellik ölçeklendirme yaparız. Özellikler normalize edilmediğinde, gradyan inişinin yerel minimuma ulaşması daha uzun sürer.
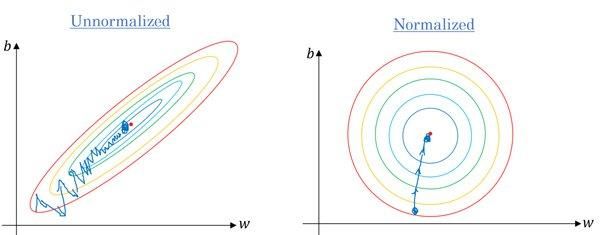
Ölçekleme olmadan ve ölçekleme ile gradyan | Quora
Özellik mühendisliği becerileri yüksek talep görüyor. Python ile Makine Öğrenimi için Özellik Mühendisliği gibi bir DataCamp kursu alarak konu hakkında her şeyi öğrenebilirsiniz.
Düşük önyargı, modelin gerçek değere yakın tahminler yaptığı durumlarda görülür. Eğitim veri setini taklit eder. Modelin genelleme yeteneği yoktur; yani model görülmemiş veride test edildiğinde zayıf sonuç verir.
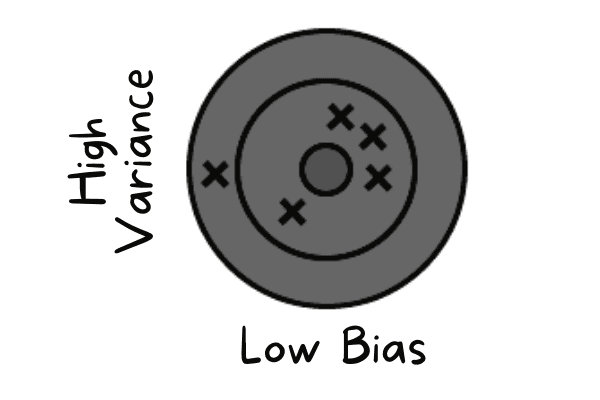
Düşük önyargı ve yüksek varyans | Yazar
Bu sorunları gidermek için, veri setini rastgele örnekleme ile alt kümelere bölen torbalama (bagging) algoritmalarını kullanırız. Ardından, bu örneklerle tek bir algoritma kullanarak model setleri üretiriz. Sonrasında, model tahminlerini oylama sınıflandırması veya ortalama alma ile birleştiririz.
Yüksek varyans için düzenlileştirme teknikleri kullanabiliriz. Daha yüksek model katsayılarını cezalandırarak model karmaşıklığını düşürür. Ayrıca, özellik önem grafiğinden en iyi özellikleri seçip modeli yeniden eğitebiliriz.
Model sürüklenmesi, gerçek dünya verileri eğitim verileriyle karşılaştırıldığında değiştiği için bir modelin performansının zamanla bozulmasıdır. İki ana türü vardır:
Çapraz doğrulama, model performansını sağlam bir şekilde değerlendirmek ve aşırı uyumu önlemek için kullanılır. Genel olarak çapraz doğrulama teknikleri, verilerden rastgele örnekler seçip bunları eğitim ve test veri setlerine böler. Bölme sayısı K değerine bağlıdır.
Örneğin K = 5 ise, eğitim için dört, test için bir kat vardır. Modelin ayrı katlardaki performansını ölçmek için bu işlem beş kez tekrarlanır.
Bunu zaman serisi veri kümesiyle yapamayız çünkü gelecekteki bir değeri kullanarak geçmişin değerini tahmin etmek mantıklı değildir. Gözlemler arasında zamansal bir bağımlılık vardır ve verileri yalnızca tek yönde bölebiliriz; böylece test veri setinin değerleri, eğitim setinin sonrasında kalır.
Şema, zaman serisi verilerinde k katlı bölmenin tek yönlü olduğunu gösterir. Mavi noktalar eğitim setidir, kırmızı nokta test setidir, beyaz ise kullanılmayan veridir. Her yinelemede eğitim setiyle ileriye doğru hareket ederken, test setinin eğitim setinin önünde kaldığını ve rastgele seçilmediğini gözlemleyebiliriz.
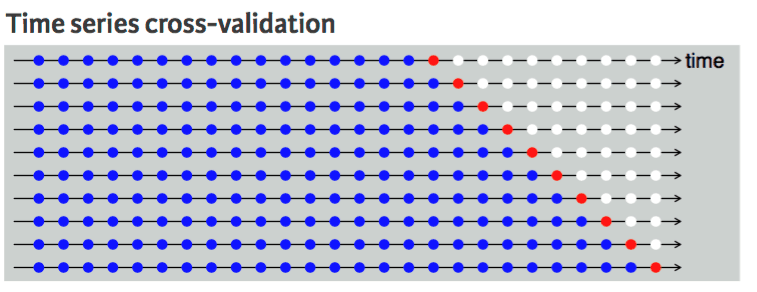
Zaman serisi çapraz doğrulama | UC Business Analytics R Programlama Rehberi
Python ile Zaman Serileri alarak zaman serisi veri manipülasyonu, analizi, görselleştirme ve modelleme hakkında bilgi edinin.
LinkedIn, Glassdoor ve Indeed'de sunulan makine öğrenimi işlerinin çoğu role özeldir. Bu nedenle mülakatta role özel sorulara odaklanılır. Bilgisayarlı görü mühendisliği rolü için işe alım uzmanı görüntü işleme sorularına yoğunlaşacaktır.
250 X 250 boyutunda bir görsel ve 1000 gizli birime sahip tam bağlı bir ilk gizli katman hayal edin. Bu görsel için girdi özellikleri 250 X 250 X 3 = 187.500'dür ve ilk gizli katmandaki ağırlık matrisi 187.500 X 1000 boyutlu olacaktır. Bu sayılar depolama ve hesaplama açısından çok büyüktür ve bu sorunu çözmek için evrişim (convolution) işlemlerini kullanırız.
Kısa bir Python ile Görüntü İşleme kursu alarak görüntü işlemeyi öğrenin
Bir evrişimli sinir ağını eğitmek için yeterli veriniz yoksa, transfer öğrenimi kullanarak modelinizi eğitebilir ve son teknoloji sonuçlar elde edebilirsiniz. Daha genel ancak daha büyük bir veri kümesi üzerinde eğitilmiş önceden eğitilmiş bir modele ihtiyacınız vardır. Sonrasında, modelin son katmanlarını eğiterek yeni veriler üzerinde ince ayar yaparsınız.
Transfer öğrenimi, veri bilimcilerin daha az kaynak, hesaplama ve depolama kullanarak küçük veriler üzerinde model eğitmesini sağlar. Çeşitli kullanım durumları için açık kaynaklı önceden eğitilmiş modelleri kolayca bulabilirsiniz ve çoğu ticari lisansa sahiptir; bu da onları uygulamanızı oluşturmak için kullanabileceğiniz anlamına gelir.
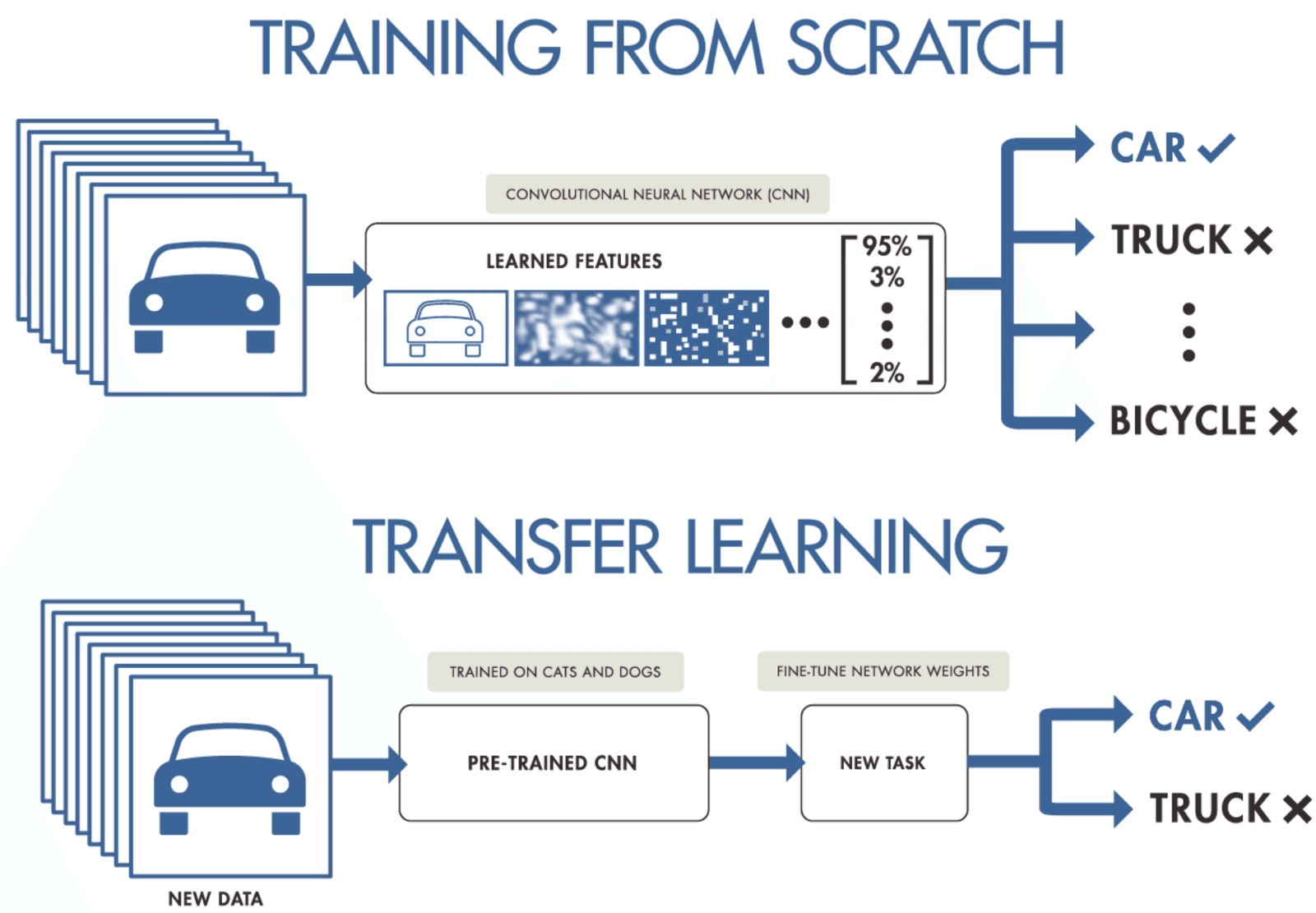
Transfer Öğrenimi, purnasai gudikandula
YOLO, evrişimli sinir ağlarına dayalı bir nesne tespiti algoritmasıdır ve gerçek zamanlı sonuçlar sağlayabilir. YOLO algoritması, nesneyi tanımak için CNN üzerinden tek bir ileri geçiş gerektirir. Hem çeşitli sınıf olasılıklarını hem de sınırlayıcı kutuları tahmin eder.
Model, çeşitli nesneleri tespit etmek üzere eğitilmiştir ve şirketler, otonom sürüş, yaban hayatını koruma ve güvenlik gibi modern uygulamalar için yeni veriler üzerinde ince ayar yapmak amacıyla transfer öğrenimini kullanmaktadır.
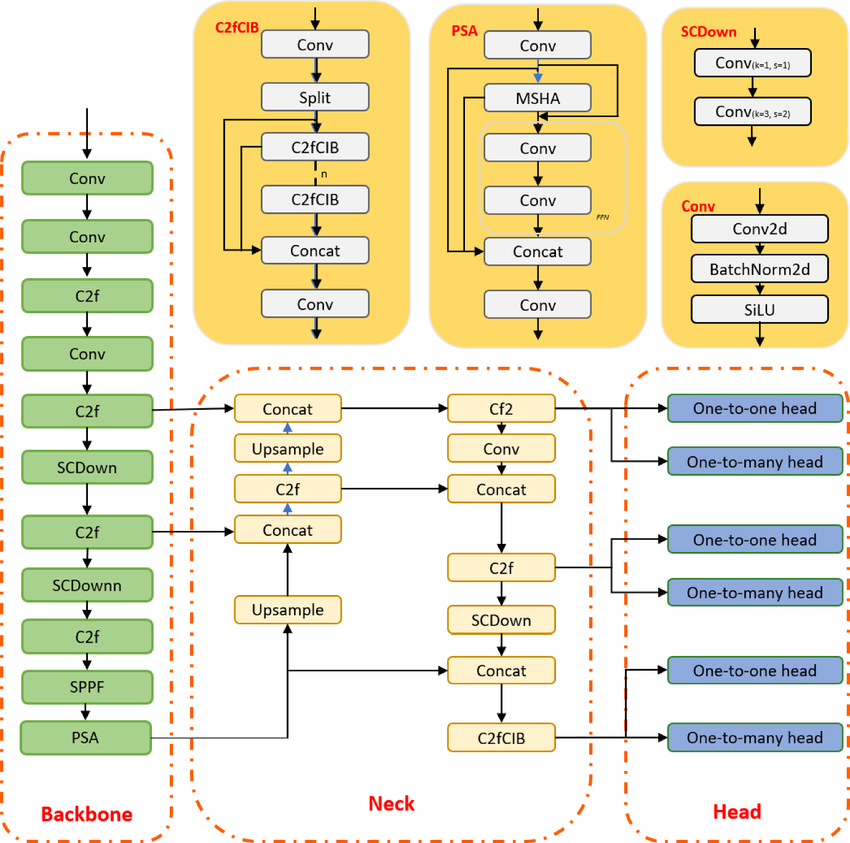
YOLOv10 model mimarisi | researchgate
Doğal Dil İşleme (NLP), modern yapay zekâ uygulamalarının temel taşlarından biridir. Mülakatlarda, dilbilim kuramıyla pratik uygulama arasındaki köprüyü kurmanızı, klasik teknikler ile modern derin öğrenme yaklaşımlarını kullanarak yapılandırılmamış metin verisini işleme, analiz etme ve anlam çıkarma becerinizi sınayan sorular bekleyin.
Sözdizimsel Analiz, diğer adıyla sözdizimi analizi veya Ayrıştırma (Parsing), bir cümlenin ya da cümlenin bir bölümünün arkasındaki mantıksal anlamı ortaya koyan metin analizidir. Sözcükler arasındaki ilişkilere ve cümlelerin dilbilgisel yapısına odaklanır. Doğal dili dilbilgisel kurallarla analiz etme süreci olarak da ifade edilebilir.
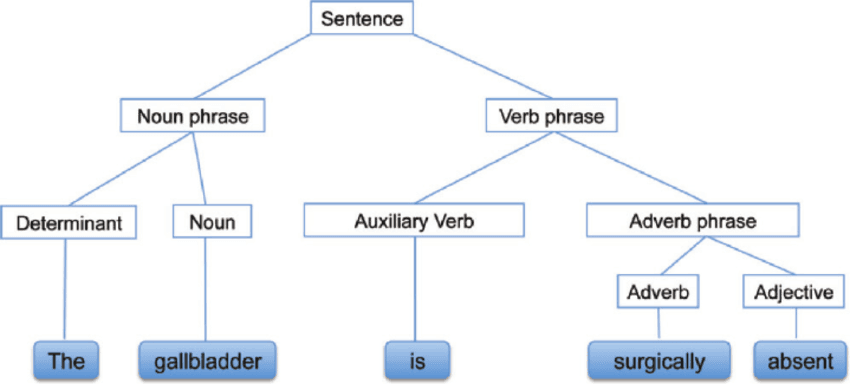
Sözdizimsel Analiz | researchgate
Gövdeleme ve sözlükleme, bir cümledeki sözcüklerin yapısal çeşitliliğini en aza indirmek için kullanılan bir normalleştirme tekniğidir.
Gövdeleme, sözcüğe eklenen ekleri kaldırır ve onu kök hâline getirir. Örneğin, Changing → Chang.
Arama motorları tarafından depolama optimizasyonu için yaygın olarak kullanılır. Sözcüklerin tüm biçimlerini depolamak yerine yalnızca gövdeleri depolar.
Sözlükleme, sözcüğü lemma biçimine dönüştürür. Çıktı, gövde yerine kök (sözlükte yer alan) sözcüktür. Sözlüklemeden sonra anlamlı geçerli bir sözcük elde ederiz. Örneğin, Changing → Change.

Gövdeleme vs. Sözlükleme | Yazar
Büyük dönüştürücüleri optimize etmek, hem bellek bant genişliği hem de hesaplama darboğazlarını ele almayı gerektirir:
Python ile Doğal Dil İşleme yetkinlik yolunu tamamlayarak NLP temellerini öğrenin.
LLM'ler günümüz yapay zekâ dünyasına hâkim oldukça, mülakatçılar onları etkili şekilde devreye almayı bilen adaylara öncelik veriyor. Bu bölüm, 2026'nın en büyük pratik mühendislik zorluklarına odaklanır.
Bir LLM'in bağlam penceresi, modelin bir yanıt üretirken bir seferde dikkate alabileceği metnin (belirteç cinsinden) azami miktarıdır ve modelin etkili "çalışma belleğini" doğrudan sınırlar.
Büyük bağlam pencereleri yaygınlaşsa bile performans ve maliyet doğrusal ölçeklenmez: uzun istemler gecikmeyi artırır ve ilgili bilgi bağlamın ortalarında gömülü kaldığında hâlâ güvenilirlik sorunlarına yol açabilir.
Mülakatlarda, uzun belge görevleri için pratik stratejileri açıklayarak yanıt veririm:
Halüsinasyonlar, bir LLM'in makul görünen ancak gerçek dışı bilgiler üretmesiyle ortaya çıkar. 2026'da azaltım çok katmanlı bir yaklaşım gerektirir:
Bu klasik bir "denge" sorusudur. Karar, verinin güncelliği ve alan özgüllüğüne bağlıdır:
Soru, RAG vs Fine-Tuning blogumuzda daha ayrıntılı tartışılmaktadır.
Pekiştirmeli Öğrenme (RL), bir ajanın sabit veri kümeleri yerine bir çevreyle etkileşerek öğrendiği problemleri ele alır. RL'nin nasıl çalıştığını tartışmaya ve politika (policy) gibi temel kavramları açıklamaya hazır olun.
Pekiştirmeli öğrenme, hedeflere deneme-yanılma yoluyla ulaşır. Hedef odaklı bir algoritmadır ve toplam ödülü maksimize etmek için doğru adımları atarak çevreden öğrenir.
Tipik pekiştirmeli öğrenmede:
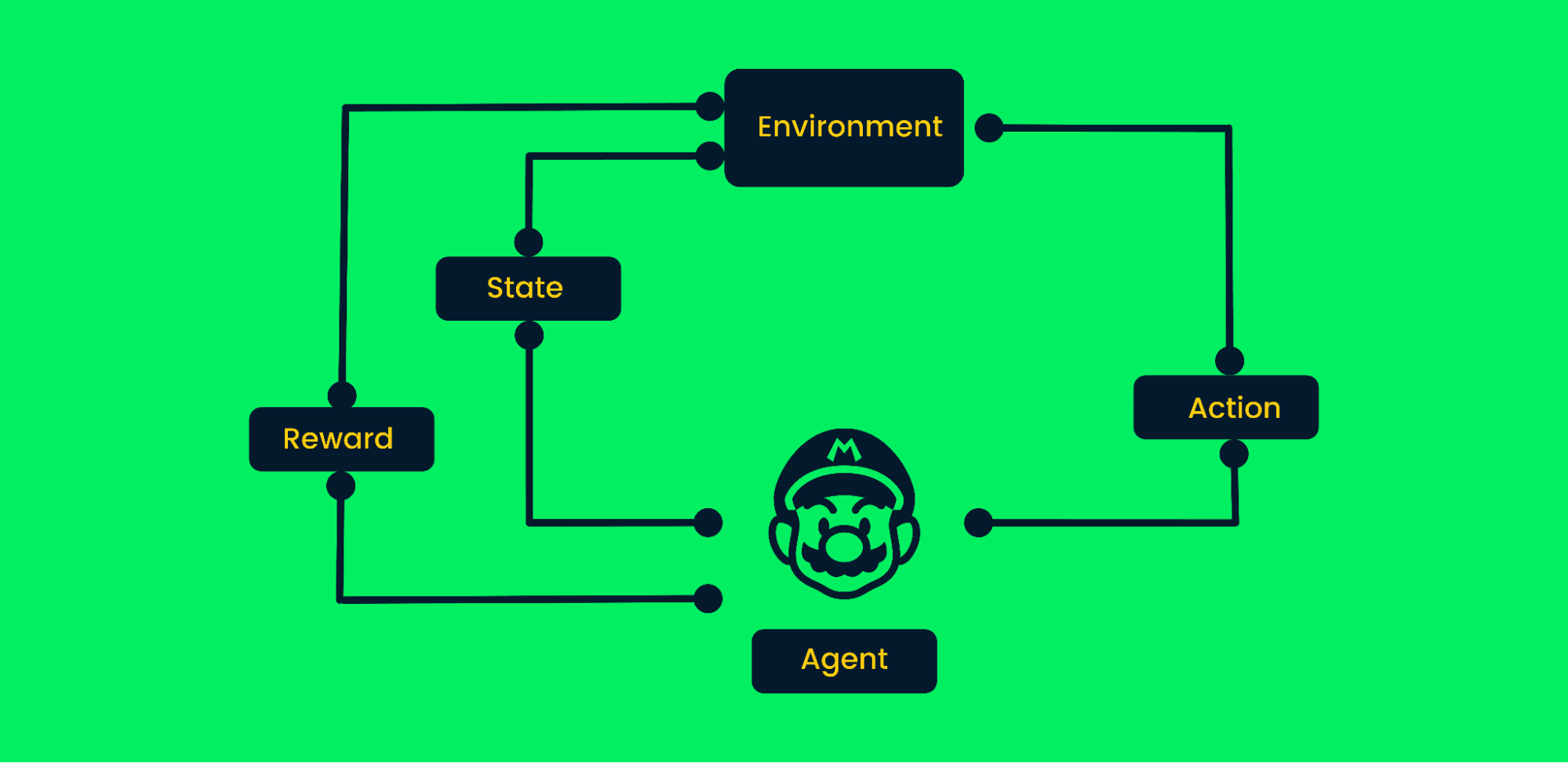
Pekiştirmeli Öğrenme Çerçevesi | Yazar
On-Policy öğrenme algoritmaları, aynı politikayı hem eyleme dökmek hem de güncellemek üzere değerlendirir ve iyileştirir. Başka bir deyişle, güncelleme için kullanılan politika ile eylem almak için kullanılan politika aynıdır.
Hedef Politika == Davranış Politikası
On-policy algoritmalara Sarsa, On-Policy için Monte Carlo, Değer Yineleme (Value Iteration) ve Politika Yineleme (Policy Iteration) örnek verilebilir
Off-Policy Öğrenme algoritmaları ise tamamen farklıdır; güncellenen politika, davranış politikasından farklıdır. Örneğin Q-öğrenmede, ajan, açgözlü (greedy) bir politikanın yardımıyla optimal bir politikadan öğrenir ve eylemi diğer politikaları kullanarak alır.
Hedef Politika != Davranış Politikası
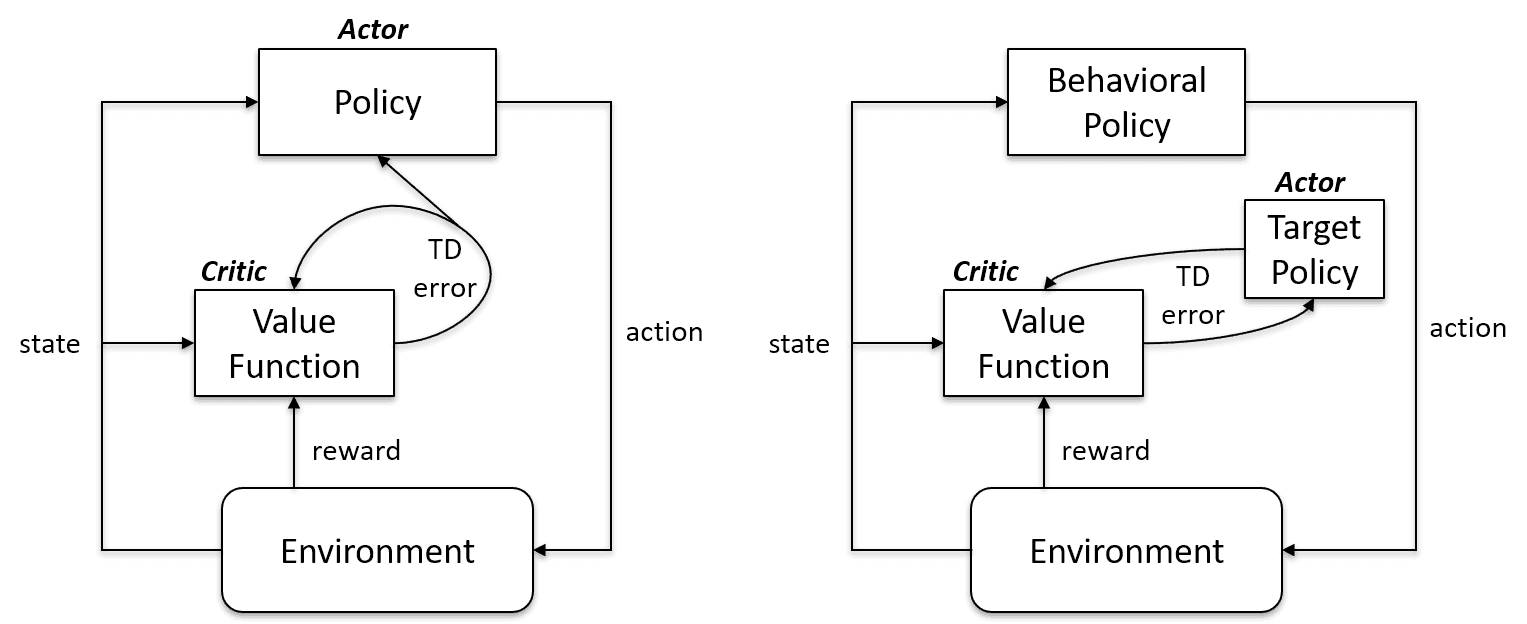
On-policy vs. Off-policy durumu | Artificial Intelligence Stack Exchange
Basit Q öğrenme harikadır. Küçük ölçekte sorunu çözer, ancak büyük ölçekte başarısız olur.
Çevrenin 1000 durumu ve durum başına 1000 eylemi olduğunu hayal edin. Milyonlarca hücrelik bir Q tablosuna ihtiyaç duyarız. Satranç ve Go oyunları daha da büyük tablolar gerektirir. İşte bu noktada Derin Q-öğrenme imdada yetişir.
Q değer fonksiyonunu yaklaştırmak için bir sinir ağı kullanır. Sinir ağı, durumları girdi olarak alır ve tüm olası eylemlerin Q-değerlerini çıktı olarak verir.
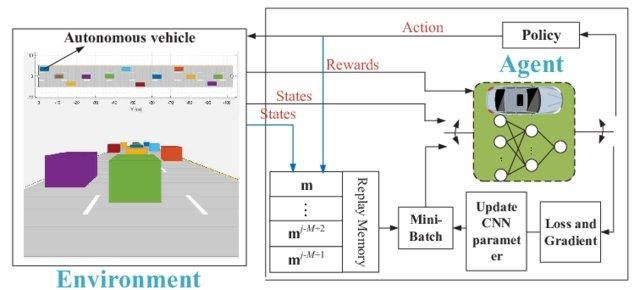
Otonom sürüş için Derin Q-ağı | researchgate
Aşağıda, en iyi teknoloji şirketlerindeki mülakatlarda size sorulabilecek bazı olası soruları özetledik:
Alıcı işletim karakteristikleri (ROC), duyarlılık ve özgüllük arasındaki dengeyi gösterir.
Eğri, Yanlış pozitif oranı (FP/(TN + FP)) ve doğru pozitif oranı (TP/(TP + FN)) kullanılarak çizilir
ROC eğrisi altındaki alan (AUC), model performansını gösterir. ROC eğrisi altındaki alan 0,5 ise modelimiz tamamen rastgele demektir. AUC'si 1'e yakın olan model daha iyidir.
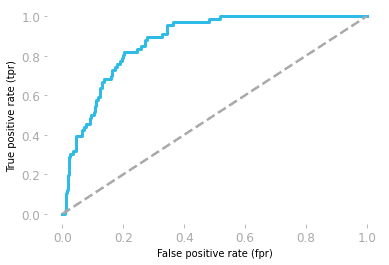
ROC eğrisi, Hadrien Jean
Sınıflandırmanın (cevabın doğru ya da yanlış olduğu) aksine, GenAI çoğunlukla insan değerlendirmesi veya "Hakem Olarak LLM" çerçeveleri gerektirir:
Boyut indirgeme için özellik seçimi veya özellik çıkarımı yöntemlerini kullanabiliriz.
Özellik seçimi, en uygun özellikleri seçme ve ilgisiz özellikleri eleme sürecidir. Filtre, Sarmalayıcı (Wrapper) ve Gömülü (Embedded) yöntemleri kullanarak özellik önemini analiz eder ve daha az önemli özellikleri kaldırarak model performansını iyileştiririz.
Özellik çıkarımı, çok boyutlu uzayı daha az boyuta dönüştürür. Süreç sırasında bilgi kaybı olmaz ve veriyi işlemek için daha az kaynak kullanır. En yaygın çıkarım teknikleri Doğrusal Ayrım Analizi (LDA), Çekirdek PCA ve Kuadratik Ayrım Analizi'dir.
Bir spam sınıflandırıcı örneğinde, lojistik regresyon modeli olasılık döndürecektir. 0,8999 olasılığını kullanabilir veya bir eşik değeriyle sınıfa (Spam/Spam Değil) dönüştürebiliriz.
Genellikle sınıflandırıcının eşiği 0,5'tir; ancak bazı durumlarda doğruluğu artırmak için bunu ince ayarlamak gerekir. 0,5 eşiği, olasılık 0,5'e eşit veya daha yüksekse spam, daha düşükse spam değil olduğu anlamına gelir.
Eşiği bulmak için Kesinlik-Duyarlılık (Precision-Recall) eğrileri ve ROC eğrileri, ızgara araması ve daha iyi ÇD (çapraz doğrulama) değeri elde etmek için değeri elle değiştirerek yöntemleri kullanabiliriz.
Python ile Makine Öğrenimi Bilimcisi kariyer yolunu tamamlayarak profesyonel bir makine öğrenimi mühendisi olun.
Doğrusal regresyon, özellikler (X) ile hedef (y) arasındaki ilişkiyi anlamak için kullanılır. Modeli eğitmeden önce birkaç varsayımı sağlamamız gerekir:
Not: Doğrusal regresyonda artıklar, gerçek ve tahmin edilen değerler arasındaki farktır.
Kodlama mülakatlarında sizden makine öğrenimi sorunları istenecektir, ancak bazı durumlarda genel Python soruları sorarak Python becerilerinizi de değerlendirirler. Python Programcısı kariyer yolunu alarak uzman bir Python programcısı olun.
Bir bigram fonksiyonu oluşturmak oldukça kolaydır. zip fonksiyonuyla iki döngü kullanmanız gerekir.
zip kullanarak önceki sözcük ve sonraki sözcüğün kombinasyonunu oluşturmaProblemi parçalara ayırıp zip fonksiyonlarını kullanırsanız oldukça kolaydır.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Sonuçlar:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]Aktivasyon fonksiyonu, sinir ağlarında doğrusal olmayan bir dönüşümdür. Girdiyi bir sonraki katmana geçirmeden önce aktivasyon fonksiyonundan geçiririz.
Net giriş değeri -sonsuz ile +sonsuz arasında olabilir ve nöron bu değerleri sınırlamayı bilmediği için ateşleme desenine karar veremez. Aktivasyon fonksiyonu, nöronun etkinleşip etkinleşmeyeceğine karar vererek net giriş değerlerini sınırlar.
En yaygın Aktivasyon Fonksiyonları:
Cevap tamamen size bağlı. Ancak yanıtlamadan önce, bir performans metriği belirlemek için hangi iş hedefini gerçekleştirmek istediğinizi ve veriyi nasıl edineceğinizi düşünmeniz gerekir.
Tipik bir makine öğrenimi sistem tasarımında:
Teoriden veya model mimarisinden ziyade tasarıma odaklandığınızdan emin olun. Model çıkarımından bahsedin ve bunu iyileştirmenin toplam geliri nasıl artıracağını anlatın.
Ayrıca, neden belirli bir yöntemi diğerine tercih ettiğinize dair genel bir bakış verin.
DataCamp'te bir kurs alarak öneri sistemleri oluşturma hakkında daha fazla bilgi edinin.
Kodlama zorluklarını çözmek ve Python becerileriniz üzerinde çalışmak, kodlama mülakatı aşamasını geçme şansınızı artıracaktır.
Bir problemi çözmeye başlamadan önce soruyu anlamanız gerekir. Basitçe, B stringindeki harfleri kaydırarak A string'ini elde edip edemeyeceğinizi True döndüren bir boolean fonksiyon oluşturmanız gerekir.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueTopluluk öğrenme, doğruluk ve performans metriklerini iyileştirmek için birden fazla makine öğrenimi modelinin içgörülerini birleştirmede kullanılır.
Basit topluluk yöntemleri:
İleri topluluk yöntemleri:
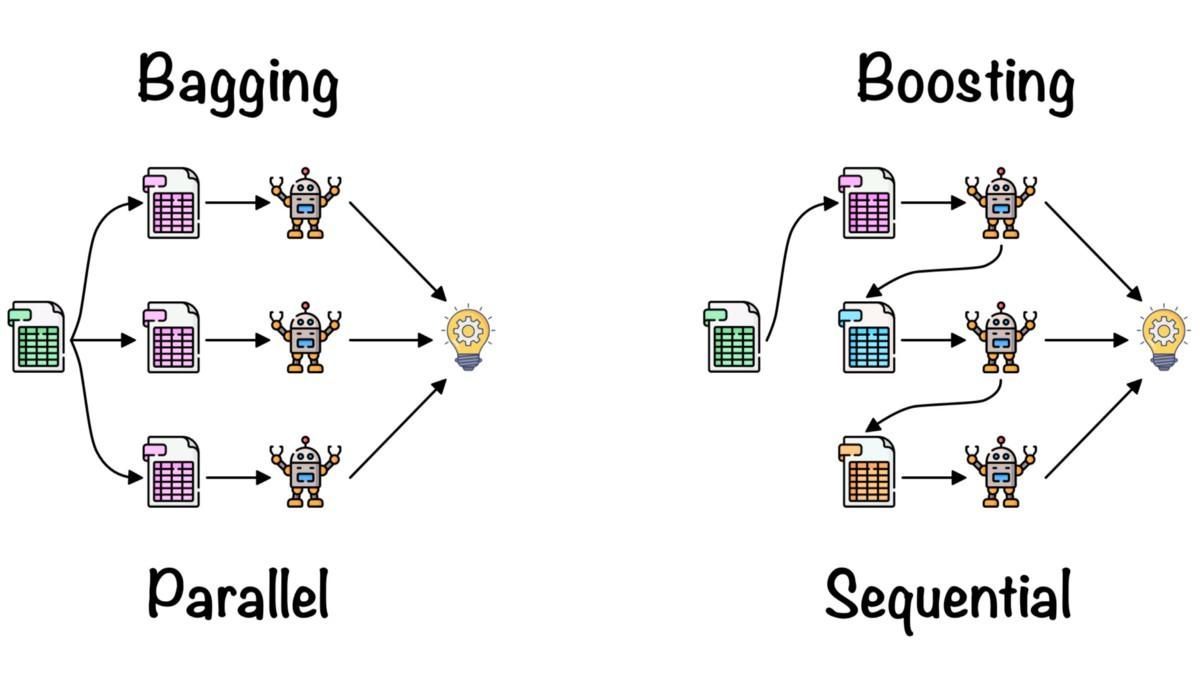
Torbalama ve Artırma, Fernando López
Averajlama, torbalama, istifleme (stacking) ve artırma hakkında daha fazla bilgi edinmek için Python'da Topluluk Yöntemleri kursunu tamamlayın.
Temel makine öğrenimi mülakat sorularını incelememizi tamamlarken, bu tür mülakatlarda başarılı olmanın, kuramsal bilgi, pratik beceriler ve alandaki en son trendler ile teknolojilerden haberdar olmanın bir bileşimini gerektirdiği açıktır. Yarı denetimli öğrenme ve algoritma seçimi gibi temel kavramları anlamaktan, KNN gibi belirli algoritmaların karmaşıklıklarına dalmaya ve NLP, bilgisayarlı görü veya pekiştirmeli öğrenme gibi role özgü zorluklarla başa çıkmaya kadar kapsam geniştir.
İster alana girmeyi hedefleyen bir başlangıç, ister daha da ilerlemeyi amaçlayan deneyimli bir uygulayıcı olun, sürekli öğrenme ve pratik yapmak anahtardır. DataCamp, becerilerinizi yapılandırılmış ve derinlemesine geliştirmenin bir yolu olan kapsamlı Python ile Makine Öğrenimi Bilimcisi yolunu sunar.
Makine Öğrenimi Kursları
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
