Curso
Machine Learning for Finance in Python
4 h
32.9K
As perguntas básicas têm a ver com terminologias, algoritmos e metodologias. Os entrevistadores fazem essas perguntas para avaliar o conhecimento técnico do candidato.
A aprendizagem semi-supervisionada é uma mistura de aprendizagem supervisionada e não supervisionada. O algoritmo é treinado com uma mistura de dados rotulados e não rotulados. Geralmente, é usado quando temos um conjunto de dados rotulados bem pequeno e um conjunto de dados não rotulados grande.
Em termos simples, o algoritmo não supervisionado é usado para criar clusters e, usando os dados rotulados existentes, rotular o resto dos dados não rotulados. Um algoritmo semi-supervisionado assume a suposição de continuidade, a suposição de agrupamento e a suposição de variedade.
Geralmente é usado para economizar o custo de aquisição de dados rotulados. Por exemplo, classificação de sequências de proteínas, reconhecimento automático de voz e carros autônomos.
Além do conjunto de dados, você precisa de um caso de uso comercial ou requisitos de aplicação. Você pode aplicar o aprendizado supervisionado e não supervisionado aos mesmos dados.
Em geral:
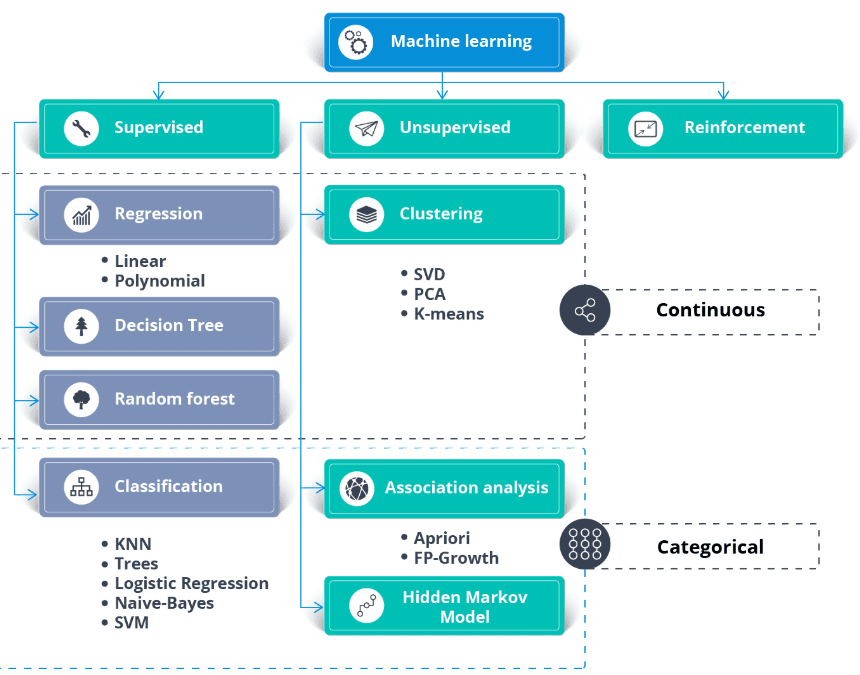
Imagem de thecleverprogrammer
Aprenda os fundamentos do machine learning fazendo nosso curso.
O K Nearest Neighbor (KNN) é um classificador de aprendizagem supervisionada. Ele usa a proximidade para classificar rótulos ou prever o agrupamento de pontos de dados individuais. Podemos usá-lo para regressão e classificação. O algoritmo KNN é não paramétrico, ou seja, não faz nenhuma suposição sobre como os dados estão distribuídos.
No classificador KNN:
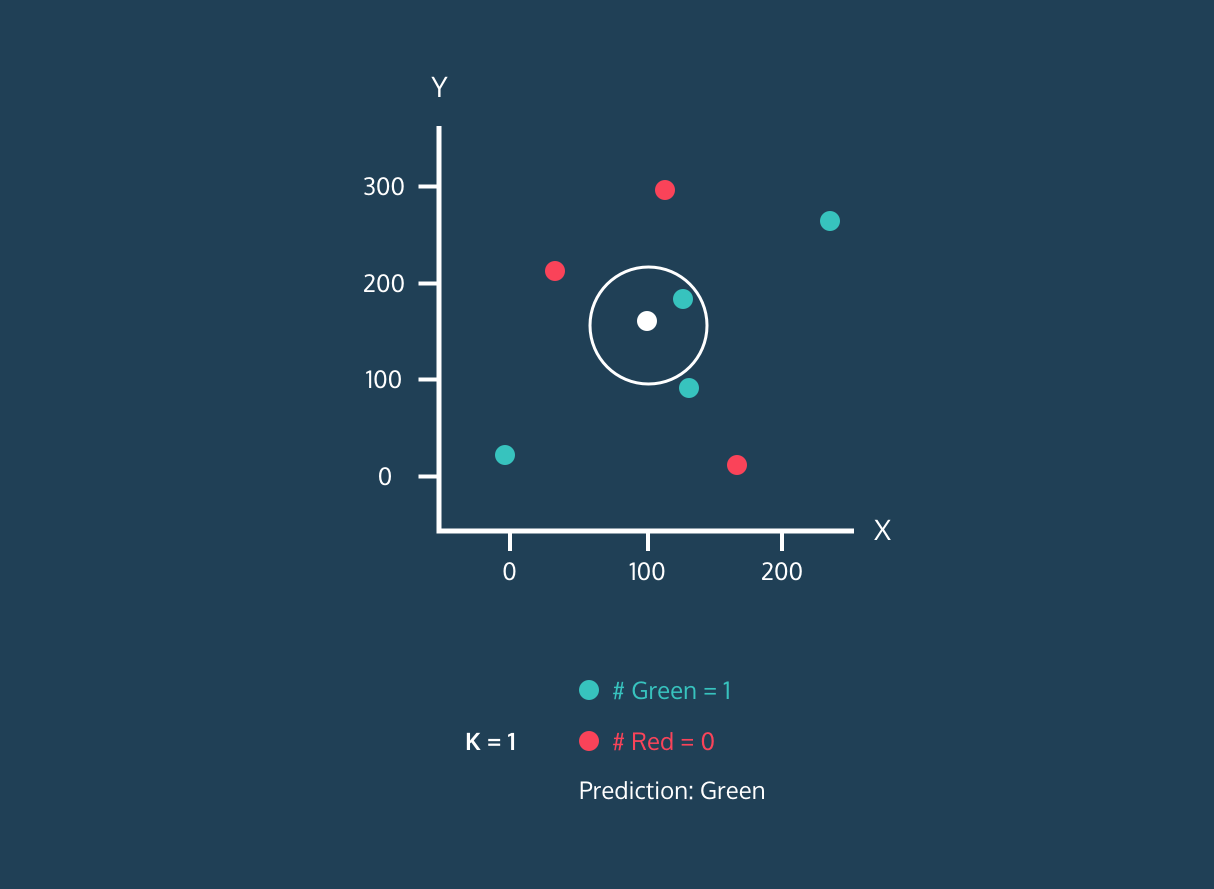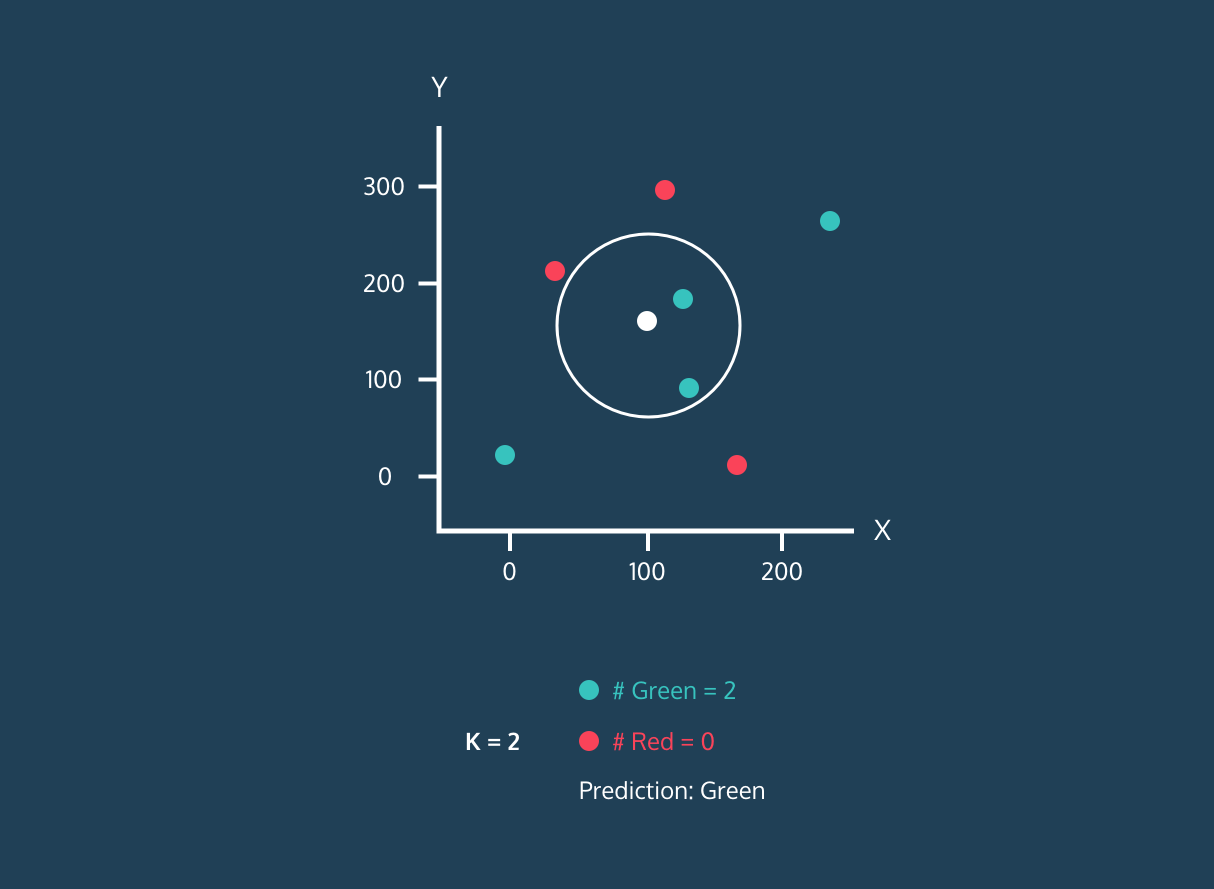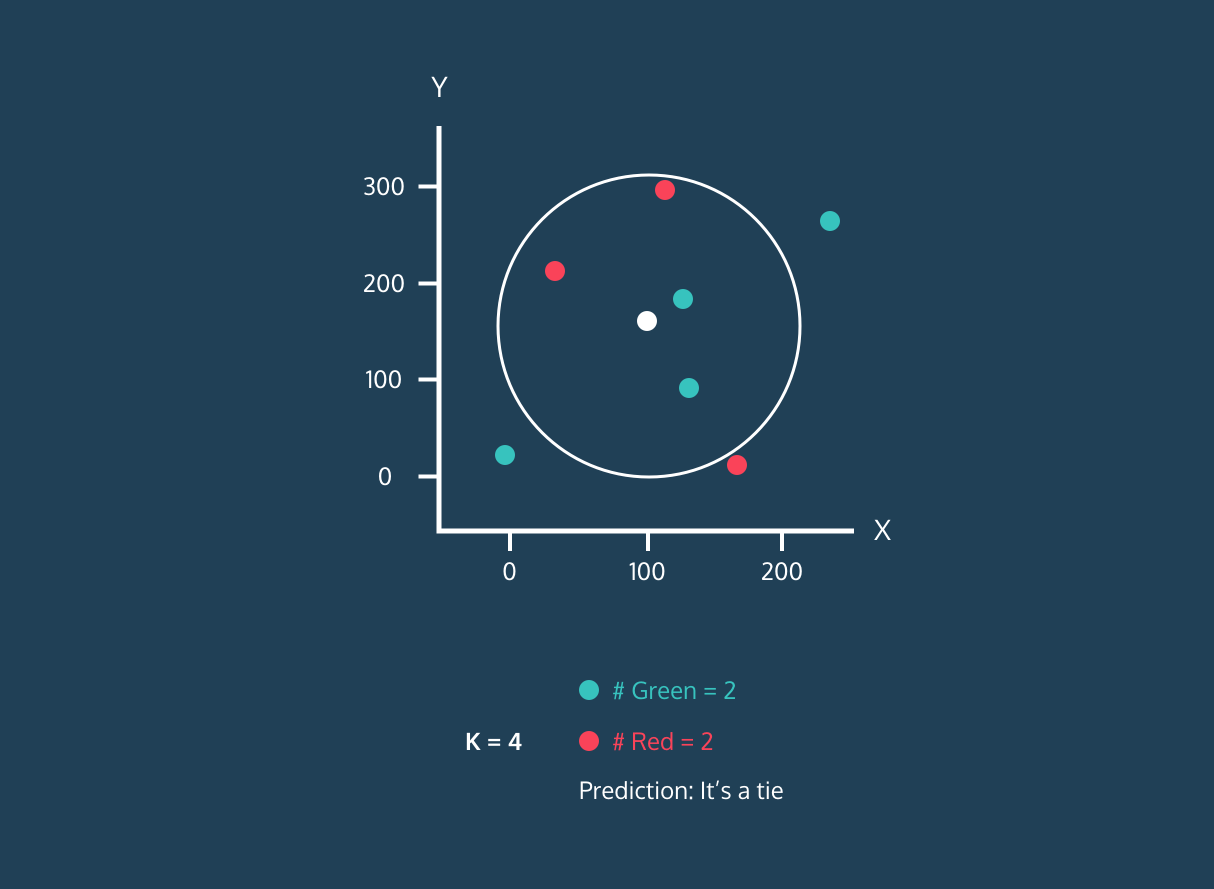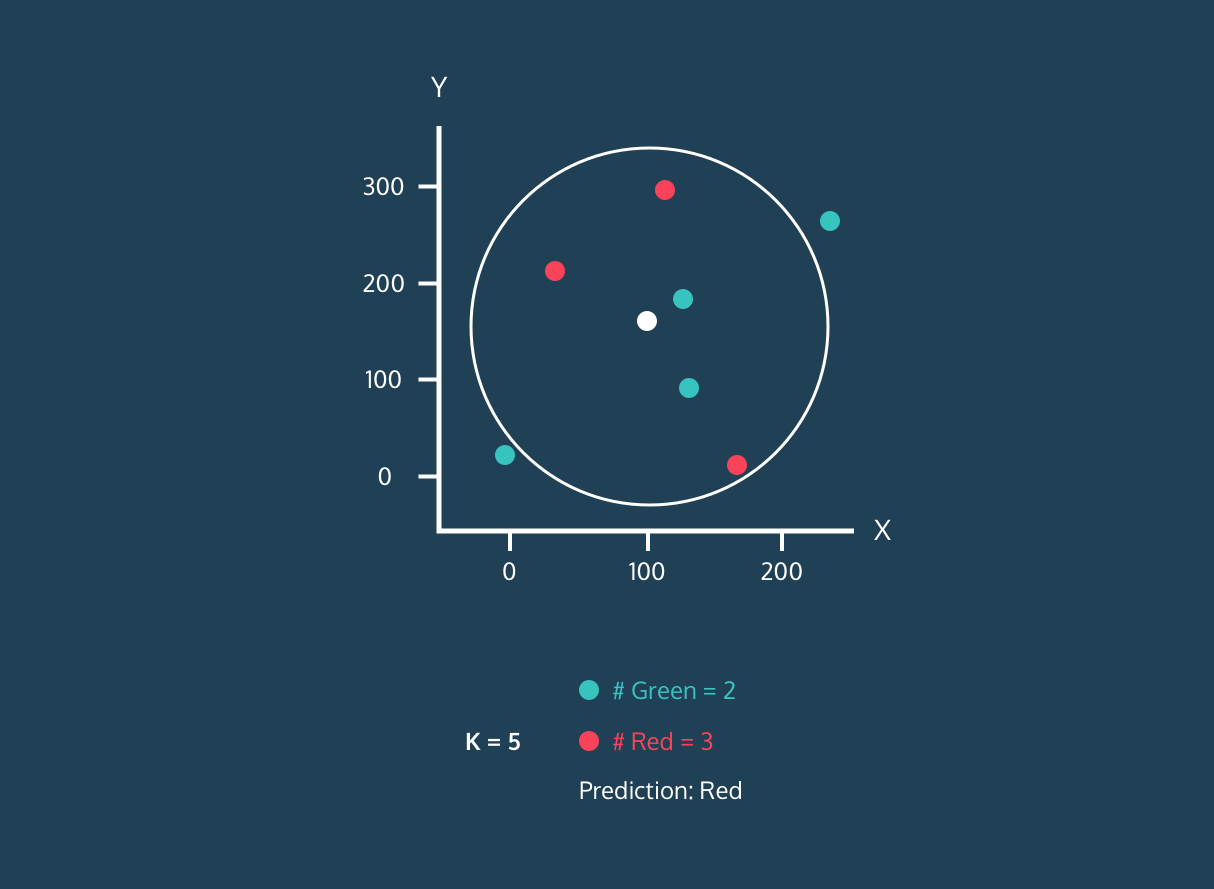
Imagem da história de desenvolvimento do Codesigner
Aprenda tudo sobre modelos de classificação e regressão de aprendizado supervisionado fazendo um curso rápido.
A importância dos recursos se refere a técnicas que atribuem uma pontuação aos recursos de entrada com base na sua utilidade para prever uma variável-alvo. Ele é super importante pra entender a estrutura dos dados, o comportamento do modelo e deixar o modelo mais fácil de entender.
Tem vários jeitos de ver qual é a importância de cada característica:
Entender a importância dos recursos é essencial para otimizar o modelo, reduzir o sobreajuste removendo recursos que não trazem informação e melhorar a interpretabilidade do modelo, principalmente em áreas onde entender o processo de decisão do modelo é superimportante.
O sobreajuste rola quando um modelo se sai bem nos dados de treinamento, mas não consegue generalizar para dados que não viu antes porque memorizou os dados de treinamento em vez de aprender os padrões por trás deles. Isso pode ser evitado:
Uma matriz de confusão é uma tabela usada para avaliar o desempenho de um modelo de classificação. Mostra o número de verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos. É útil para calcular métricas como exatidão, precisão, recall e pontuação F1.
Modelos paramétricos: Elas fazem suposições sobre a distribuição subjacente dos dados e têm um número fixo de parâmetros (por exemplo, regressão linear).
Modelos não paramétricos: Eles não fazem suposições sobre a distribuição dos dados e podem se adaptar à complexidade à medida que mais dados são adicionados (por exemplo, K-Nearest Neighbors).
O compromisso entre viés e variância é o equilíbrio entre a capacidade de um modelo de capturar padrões complexos (baixo viés) e sua sensibilidade às flutuações nos dados de treinamento (baixa variância). Um bom modelo consegue um equilíbrio minimizando tanto o viés quanto a variância para evitar o subajuste e o sobreajuste.
A entrevista técnica é mais pra ver o quanto você sabe sobre processos e como você lida com incertezas. O gerente de contratação vai fazer perguntas sobre machine learning relacionadas a processamento de dados, treinamento e validação de modelos e algoritmos avançados.
Sim. A maioria dos algoritmos usa a distância euclidiana entre pontos de dados e, se o valor da característica variar muito, os resultados serão bem diferentes. Na maioria dos casos, os outliers fazem com que os modelos de machine learning tenham um desempenho pior no conjunto de dados de teste.
Também usamos o dimensionamento de recursos para reduzir o tempo de convergência. Vai demorar mais tempo para o gradiente descendente chegar aos mínimos locais quando as características não estiverem normalizadas.
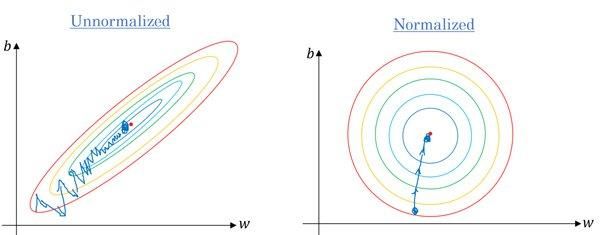
Gradiente sem e com escala | Quora
As habilidades de engenharia de recursos estão em alta demanda. Você pode aprender tudo sobre o assunto fazendo um curso do DataCamp, como Engenharia de Recursos para Machine Learning em Python.
O viés baixo rola quando o modelo tá prevendo valores próximos do valor real. Está imitando o conjunto de dados de treinamento. O modelo não tem generalização, o que significa que, se for testado em dados não vistos, vai dar resultados ruins.
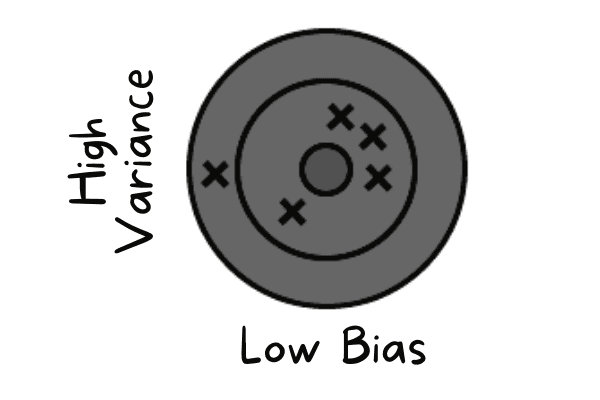
Baixo viés e alta variância | Autor
Para resolver esses problemas, vamos usar algoritmos de bagging, que dividem um conjunto de dados em subconjuntos usando amostragem aleatória. Depois, a gente gera conjuntos de modelos usando essas amostras com um único algoritmo. Depois disso, juntamos a previsão do modelo usando classificação por votação ou média.
Para alta variância, podemos usar técnicas de regularização. Isso penalizou coeficientes de modelo mais altos para diminuir a complexidade do modelo. Além disso, podemos escolher as principais características do gráfico de importância das características e treinar o modelo.
O desvio do modelo acontece quando o desempenho de um modelo piora com o tempo porque os dados do mundo real mudam em relação aos dados de treinamento. Existem dois tipos principais:
A validação cruzada é usada para avaliar o desempenho do modelo de forma robusta e evitar o sobreajuste. Geralmente, as técnicas de validação cruzada escolhem amostras aleatoriamente dos dados e as dividem em conjuntos de dados de treinamento e teste. O número de divisões é baseado no valor K.
Por exemplo, se K = 5, vai ter quatro dobras para o treinamento e uma para o teste. Ele vai repetir cinco vezes para medir o modelo executado em dobras separadas.
Não dá pra fazer isso com um conjunto de dados de séries temporais porque não faz sentido usar o valor do futuro pra prever o valor do passado. Tem uma dependência temporal entre as observações, e só dá pra dividir os dados numa direção, de forma que os valores do conjunto de dados de teste fiquem depois do conjunto de treinamento.
O diagrama mostra que a divisão em k partes dos dados da série temporal é unidirecional. Os pontos azuis são o conjunto de treinamento, o ponto vermelho é o conjunto de teste e o branco são dados não utilizados. Como dá pra ver em cada repetição, estamos avançando com o conjunto de treinamento, enquanto o conjunto de teste continua na frente do conjunto de treinamento, sem ser escolhido aleatoriamente.
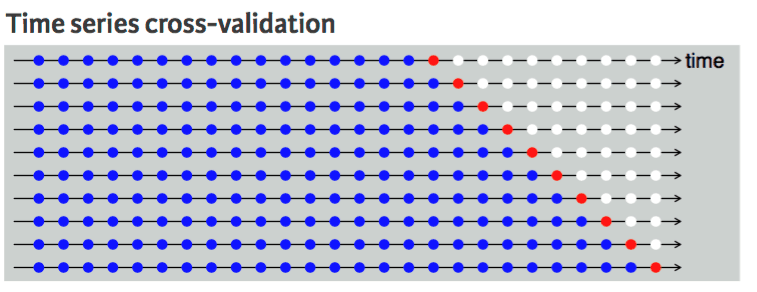
Validação cruzada de séries temporais | Guia de programação R para análise de negócios da UC
Aprenda sobre manipulação, análise, visualização e modelagem de dados de séries temporais fazendo o curso Séries temporais com Python.
A maioria das vagas de machine learning oferecidas no LinkedIn, Glassdoor e Indeed são específicas para cada função. Então, durante a entrevista, eles vão focar em perguntas específicas sobre a função. Para a função de engenheiro de visão computacional, o gerente de contratação vai se concentrar em questões relacionadas ao processamento de imagens.
Imagina uma imagem de 250 x 250 e uma primeira camada oculta totalmente conectada com 1000 unidades ocultas. Para essa imagem, as características de entrada são 250 X 250 X 3 = 187.500, e a matriz de pesos na primeira camada oculta será uma matriz dimensional de 187.500 X 1000. Esses números são enormes para armazenamento e computação, e para resolver esse problema, usamos operações de convolução.
Aprenda processamento de imagens fazendo um curso rápido de Processamento de Imagens em Python.
Se você não tiver dados suficientes para treinar uma rede neural convolucional, pode usar o aprendizado por transferência para treinar seu modelo e obter resultados de última geração. Você precisa de um modelo pré-treinado que tenha sido treinado em um conjunto de dados geral, mas maior. Depois disso, você vai ajustar tudo com dados mais recentes, treinando as últimas camadas dos modelos.
A aprendizagem por transferência permite que os cientistas de dados treinem modelos com menos dados, usando menos recursos, computação e armazenamento. Você pode encontrar facilmente modelos pré-treinados de código aberto para vários casos de uso, e a maioria deles tem uma licença comercial, o que significa que você pode usá-los para criar seu aplicativo.
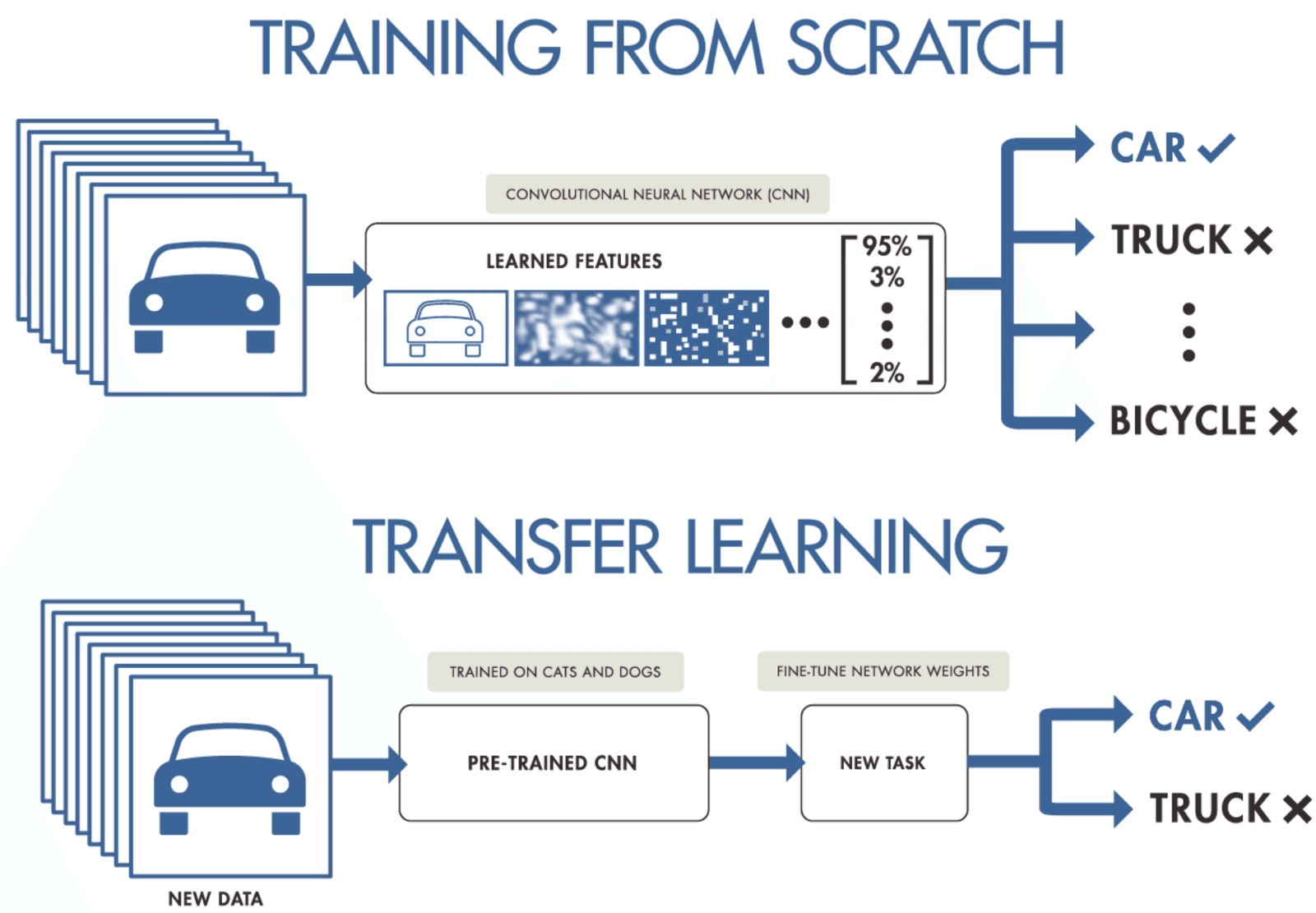
Aprendizado por transferência por Purnasai Gudikandula
O YOLO é um algoritmo de detecção de objetos baseado em redes neurais convolucionais e pode fornecer resultados em tempo real. O algoritmo YOLO precisa de uma única passagem pela CNN para reconhecer o objeto. Ele prevê várias probabilidades de classe e caixas de limite.
O modelo foi treinado para detectar vários objetos, e as empresas estão usando o aprendizado por transferência para ajustá-lo em novos dados para aplicações modernas, como direção autônoma, preservação da vida selvagem e segurança.
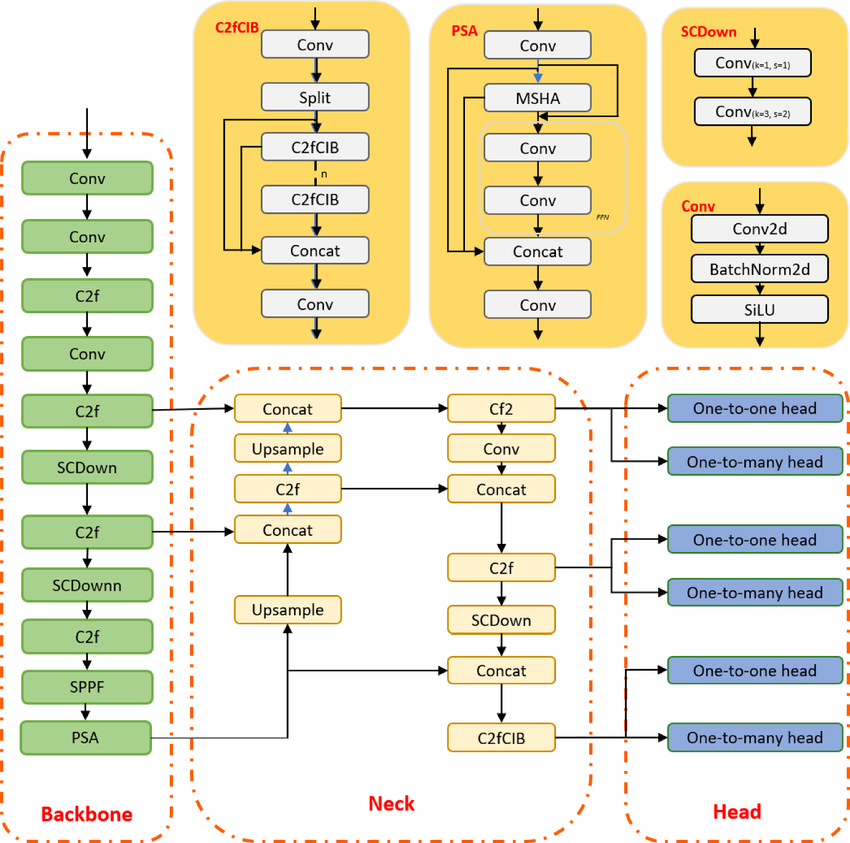
Arquitetura do modelo YOLOv10 | researchgate
O Processamento de Linguagem Natural (NLP) é uma das bases das aplicações modernas de IA. Espere perguntas que ligam a teoria linguística com a prática, testando sua habilidade de processar, analisar e extrair significado de dados de texto não estruturados usando tanto técnicas clássicas quanto abordagens modernas de aprendizado profundo.
A análise sintática, também conhecida como análise de sintaxe ou parsing, é uma análise de texto que nos mostra o significado lógico por trás de uma frase ou parte de uma frase. Ele foca na relação entre as palavras e a estrutura gramatical das frases. Também dá pra dizer que é o processo de analisar a linguagem natural usando regras gramaticais.
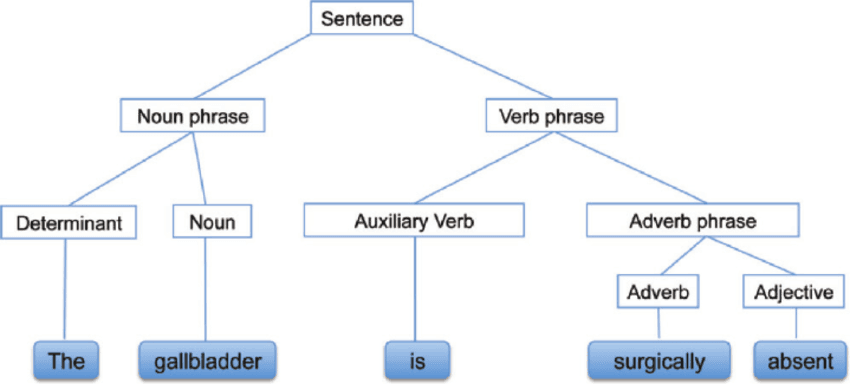
Análise sintática | researchgate
A derivação morfológica e a lematização são técnicas de normalização usadas para minimizar a variação estrutural das palavras em uma frase.
A derivação tira os afixos que foram adicionados à palavra e deixa ela na forma básica. Por exemplo, mudar para Chang.
É muito usado pelos mecanismos de busca pra otimizar o armazenamento. Em vez de guardar todas as formas das palavras, ele só guarda os radicais.
A lematização transforma a palavra na sua forma lematizada. O resultado é a raiz da palavra, em vez do radical. Depois da lematização, a gente consegue a palavra válida que tem algum significado. Por exemplo, Mudar para mudar.

Derivação vs. Lematização | Autor
Otimizar grandes transformadores exige resolver os gargalos de largura de banda de memória e computação:
Aprenda o básico de PNL completando o programa de Processamento de Linguagem Natural em Python .
Como os LLMs dominam o cenário atual da IA, os entrevistadores priorizam os candidatos que entendem como usá-los de forma eficaz. Essa seção fala sobre alguns dos maiores desafios práticos de engenharia de 2026.
A janela de contexto de um LLM é a quantidade máxima de texto (medida em tokens) que o modelo pode considerar de uma vez só ao gerar uma resposta, e isso limita diretamente a quantidade de “memória de trabalho” que o modelo tem efetivamente.
Mesmo com as janelas de contexto grandes ficando mais comuns, o desempenho e o custo não aumentam de forma linear: prompts longos aumentam a latência e ainda podem causar problemas de confiabilidade quando as informações relevantes estão bem no meio do contexto.
Nas entrevistas, eu respondia explicando estratégias práticas para tarefas de documentos longos:
As alucinações acontecem quando um LLM gera informações que parecem certas, mas que na verdade estão erradas. Em 2026, a mitigação precisa de uma abordagem em várias camadas:
Essa é uma clássica questão de “compromisso”. A decisão depende da atualidade dos dados e da especificidade do domínio:
A questão é discutida com mais detalhes em nosso blog sobre RAG vs. Ajuste fino.
A Aprendizagem por Reforço (RL) lida com problemas em que um agente aprende interagindo com um ambiente, em vez de aprender a partir de conjuntos de dados estáticos. Esteja pronto pra falar sobre como o RL funciona e explicar conceitos básicos, tipo políticas.
O aprendizado por reforço usa tentativa e erro para alcançar objetivos. É um algoritmo focado em objetivos e aprende com o ambiente, tomando as medidas certas para maximizar a recompensa acumulada.
No aprendizado por reforço típico:
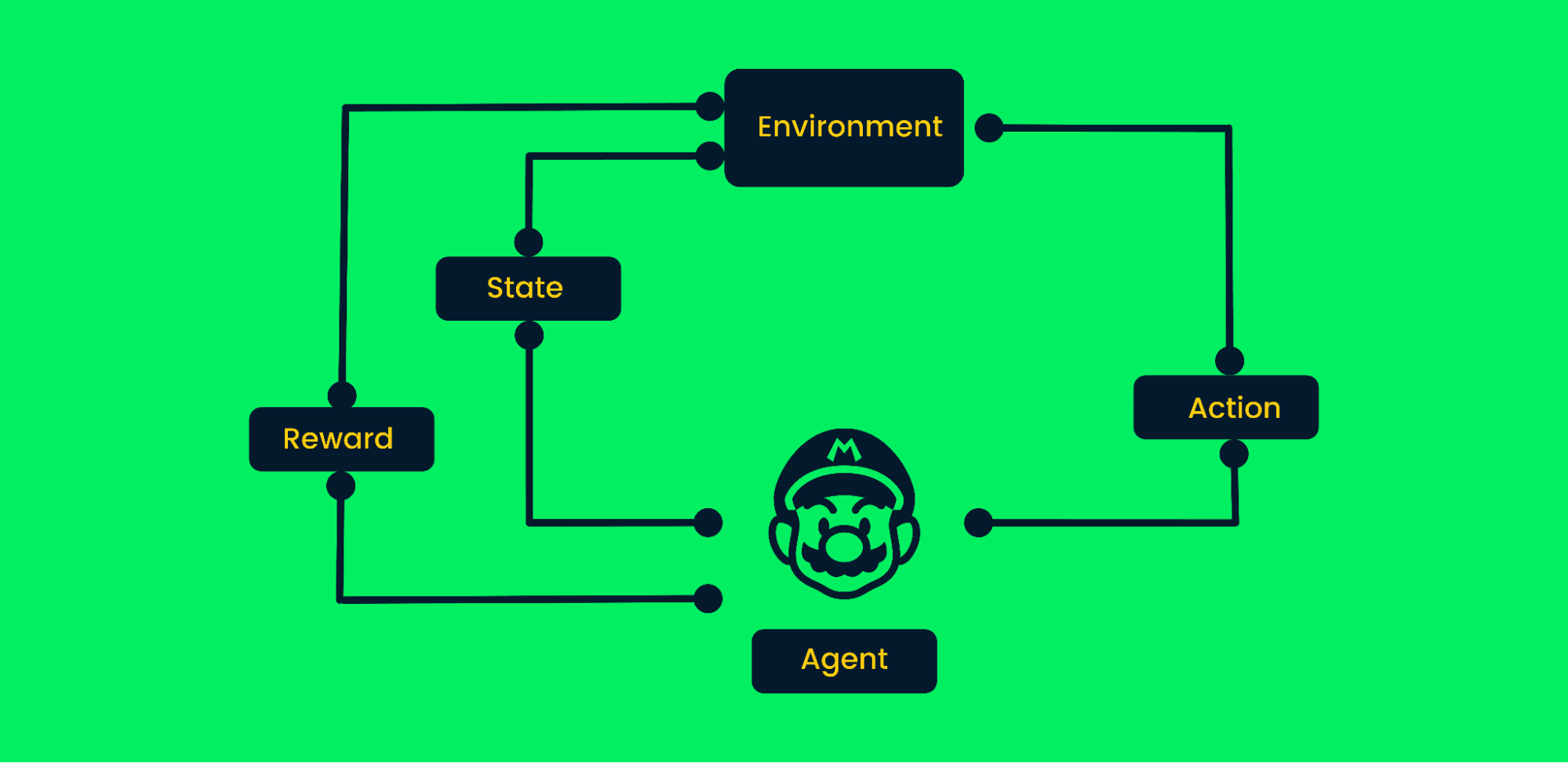
Estrutura de Aprendizado por Reforço | Autor
Os algoritmos de aprendizagem On-Policy avaliam e melhoram a mesma política para agir e atualizá-la. Ou seja, a política que usamos para atualizar e a política que usamos para agir são a mesma coisa.
Política de metas == Política de comportamento
Os algoritmos on-policy são Sarsa, Monte Carlo para On-Policy, Iteração de Valor e Iteração de Política.
Os algoritmos de aprendizagem fora da política são completamente diferentes, pois a política atualizada é diferente da política de comportamento. Por exemplo, no aprendizado Q, o agente aprende com uma política ideal com a ajuda de uma política gananciosa e age usando outras políticas.
Política de metas != Política de comportamento
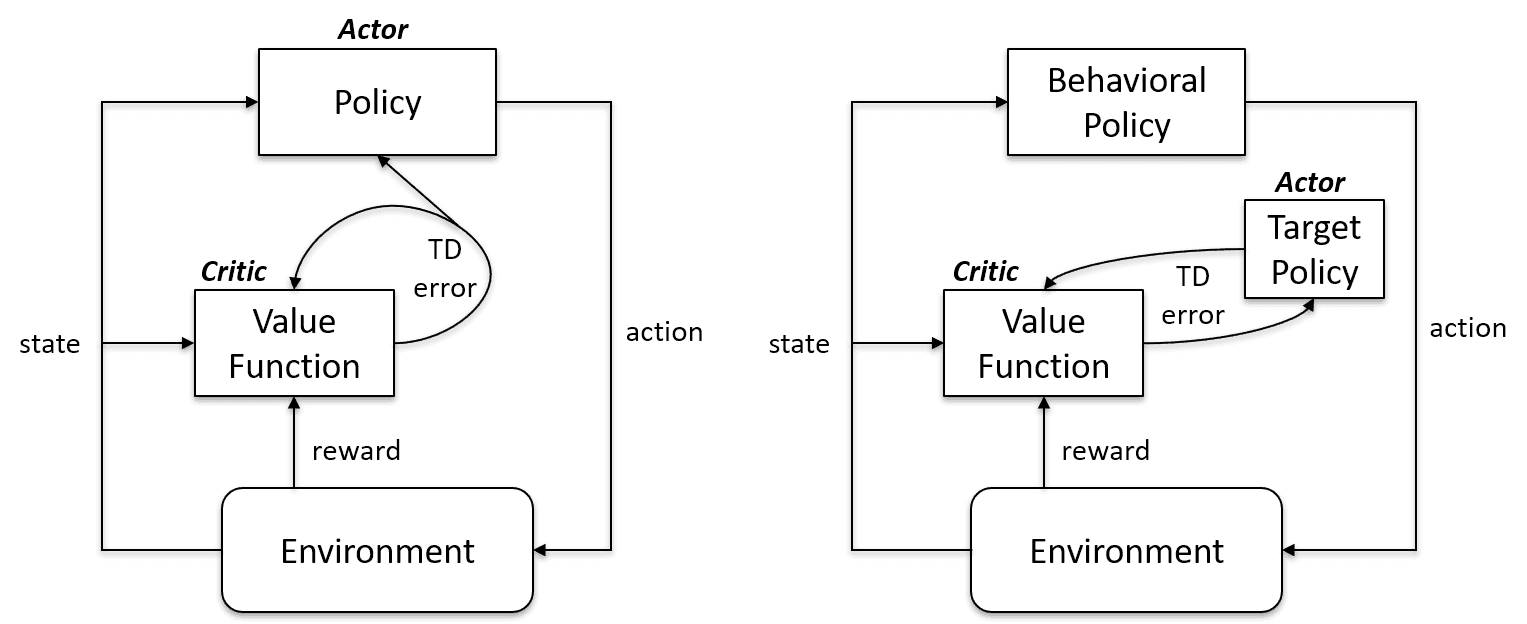
Na política vs. Caso fora da política | Artificial Intelligence Stack Exchange
O aprendizado simples Q é ótimo. Resolve o problema em menor escala, mas em maior escala, não funciona.
Imagina se o ambiente tem 1000 estados e 1000 ações por estado. Vamos precisar de uma tabela Q com milhões de células. O jogo de xadrez e Go vai precisar de uma tabela ainda maior. É aí que o Deep Q-learning entra em cena.
Ele usa uma rede neural pra aproximar a função do valor Q. A receita das redes neurais define como entrada e saída o valor Q de todas as ações possíveis.
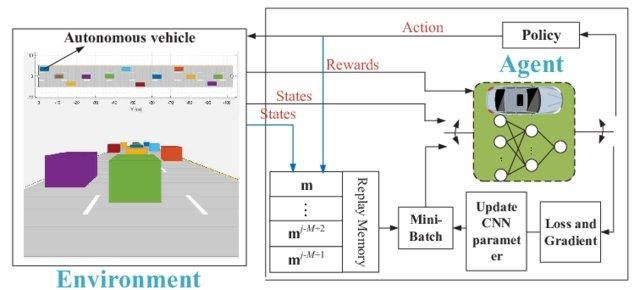
Rede Q profunda para direção autônoma | researchgate
Abaixo, listamos algumas perguntas que o entrevistador pode fazer em algumas das principais empresas de tecnologia:
As características operacionais do receptor (ROC) mostram o equilíbrio entre sensibilidade e especificidade.
A curva é traçada usando a taxa de falsos positivos (FP/(TN + FP)) e a taxa de verdadeiros positivos (TP/(TP + FN)).
A área sob a curva (AUC) mostra o desempenho do modelo. Se a área sob a curva ROC for 0,5, então nosso modelo é completamente aleatório. O modelo com AUC próximo a 1 é o melhor modelo.
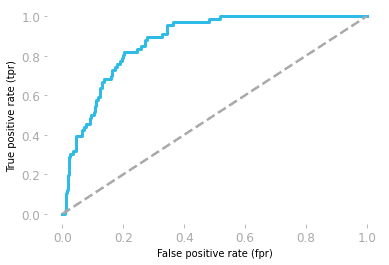
Curva ROC por Hadrien Jean
Diferente da classificação (onde uma resposta é certa ou errada), a GenAI geralmente precisa de uma avaliação humana ou de estruturas do tipo “LLM como juiz”:
Para reduzir a dimensionalidade, dá pra usar métodos de seleção ou extração de características.
A seleção de características é um processo de escolher as características ideais e descartar as que não são relevantes. Usamos métodos de filtro, wrapper e incorporados para analisar a importância dos recursos e remover os menos importantes para melhorar o desempenho do modelo.
A extração de características transforma o espaço com várias dimensões em menos dimensões. Nenhuma informação é perdida durante o processo, e ele usa menos recursos para processar os dados. As técnicas de extração mais comuns são a análise discriminante linear (LDA), a PCA do kernel e a análise discriminante quadrática.
No caso de um classificador de spam, um modelo de regressão logística vai mostrar a probabilidade. Usamos a probabilidade de 0,8999 ou convertemos em classe (Spam/Não Spam) usando um limite.
Normalmente, o limite de um classificador é 0,5, mas, em alguns casos, precisamos ajustá-lo para melhorar a precisão. O limite de 0,5 quer dizer que, se a probabilidade for igual ou maior que 0,5, é spam, e se for menor, não é spam.
Para encontrar o limite, podemos usar curvas de precisão-recall e curvas ROC, pesquisa em grade e alterar manualmente o valor para obter um CV melhor.
Torne-se um engenheiro profissional de machine learning ao concluir o programa de Cientista de Machine Learning com Python.
A regressão linear é usada pra entender a relação entre as características (X) e o alvo (y). Antes de treinarmos o modelo, precisamos atender a algumas premissas:
Observação: os resíduos na regressão linear são a diferença entre os valores reais e os valores previstos.
Durante as entrevistas de programação, vão te perguntar sobre problemas de machine learning, mas, às vezes, vão avaliar suas habilidades em Python com perguntas gerais sobre programação. Torne-se um programador Python experiente seguindo o programa de Programador Python.
Criar uma função bigram é bem fácil. Você precisa usar dois loops com a função zip.
zip para criar uma combinação da palavra anterior e da palavra seguinteÉ bem fácil se você dividir o problema e usar funções zip.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Resultados:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]A função de ativação é uma transformação não linear em redes neurais. Passamos a entrada pela função de ativação antes de mandá-la para a próxima camada.
O valor líquido de entrada pode ser qualquer coisa entre -inf e +inf, e o neurônio não sabe como limitar os valores, sendo assim incapaz de decidir o padrão de disparo. A função de ativação decide se um neurônio deve ser ativado ou não para limitar os valores de entrada da rede.
Tipos mais comuns de funções de ativação:
A resposta depende totalmente de você. Mas, antes de responder, você precisa pensar em qual meta de negócios quer atingir para definir uma métrica de desempenho e como vai conseguir os dados.
Em um projeto típico de sistema de machine learning, nós:
Você precisa se certificar de que está focando no design, e não na teoria ou na arquitetura do modelo. Não esqueça de falar sobre a inferência do modelo e como melhorá-la vai aumentar as receitas gerais.
Além disso, explique por que você escolheu uma determinada metodologia em vez de outra.
Aprenda mais sobre como criar sistemas de recomendação fazendo um curso no DataCamp.
Resolver desafios de programação e trabalhar suas habilidades em Python vai aumentar suas chances de passar na etapa da entrevista de programação.
Antes de começar a resolver um problema, você precisa entender a questão. Você só precisa criar uma função booleana que vai retornar Verdadeiro se, ao mudar as letras na String B, você conseguir a String A.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueO aprendizado conjunto é usado pra juntar as ideias de vários modelos de machine learning e melhorar a precisão e as métricas de desempenho.
Métodos simples de conjunto:
Métodos avançados de conjunto:
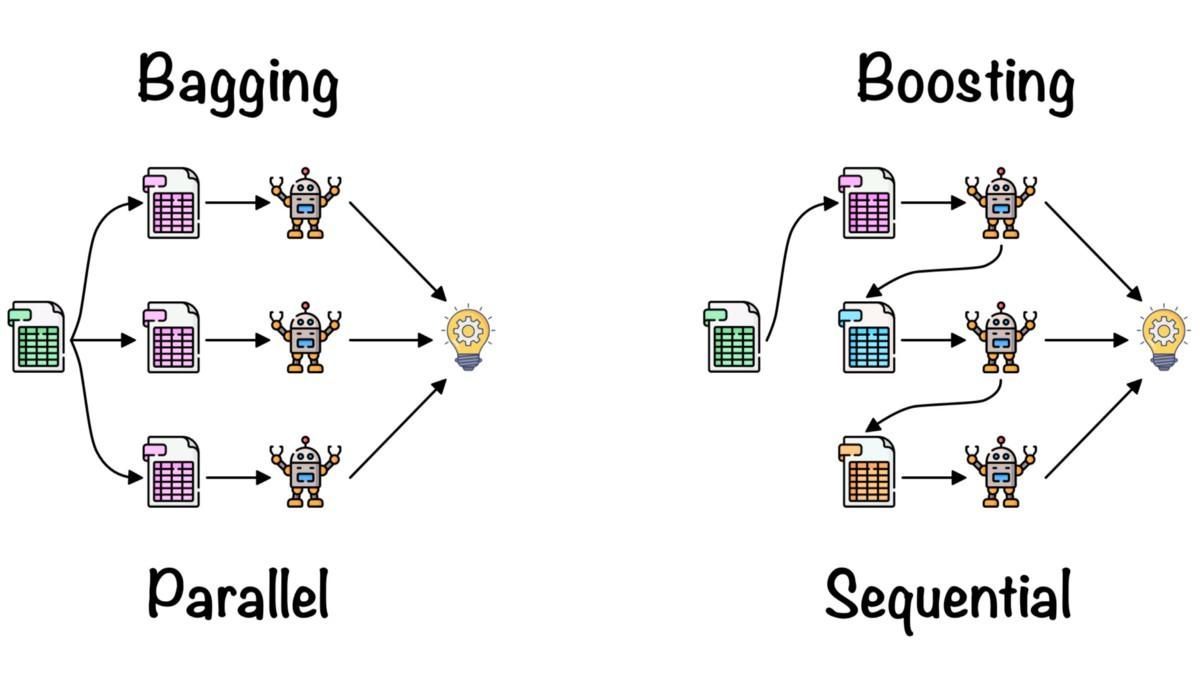
Bagging e Boosting por Fernando López
Saiba mais sobre média, agrupamento, empilhamento e reforço fazendo o curso Métodos Ensemble em Python.
Ao concluirmos nossa exploração das perguntas essenciais para entrevistas sobre machine learning, fica claro que, para se dar bem nessas entrevistas, é preciso ter uma mistura de conhecimento teórico, habilidades práticas e estar por dentro das últimas tendências e tecnologias da área. Desde entender conceitos básicos como aprendizado semi-supervisionado e seleção de algoritmos, até mergulhar nas complexidades de algoritmos específicos como KNN, e lidar com desafios específicos em NLP, visão computacional ou aprendizado por reforço, o escopo é enorme.
Seja você um novato querendo entrar na área ou um profissional experiente querendo avançar ainda mais, o aprendizado e a prática contínuos são essenciais. DataCamp oferece um programa completo de Cientista de Machine Learning com Python que te ajuda a melhorar suas habilidades de um jeito estruturado e detalhado.
Cursos de Machine Learning
Curso
Curso
blog
Hesam Sheikh Hassani
15 min
blog
Tim Lu
9 min
blog
Matt Crabtree
10 min
blog
Natassha Selvaraj
11 min
blog
Zoumana Keita
12 min
