Kurs
Machine Learning for Finance in Python
4 Std.
32.9K
Grundlegende Fragen haben mit Terminologien, Algorithmen und Methoden zu tun. Die Interviewer stellen diese Fragen, um das Fachwissen des Bewerbers zu checken.
Halbüberwachtes Lernen ist eine Mischung aus überwachtem und unüberwachtem Lernen. Der Algorithmus wird mit einer Mischung aus beschrifteten und unbeschrifteten Daten trainiert. Normalerweise wird es benutzt, wenn wir einen ganz kleinen Datensatz mit Beschriftungen und einen großen Datensatz ohne Beschriftungen haben.
Einfach gesagt, wird der unüberwachte Algorithmus benutzt, um Cluster zu bilden und die restlichen unbeschrifteten Daten mit Hilfe der vorhandenen beschrifteten Daten zu beschriften. Ein halbüberwachter Algorithmus geht von der Kontinuitätsannahme, der Clusterannahme und der Mannigfaltigkeitsannahme aus.
Es wird meistens benutzt, um die Kosten für gekennzeichnete Daten zu sparen. Zum Beispiel die Klassifizierung von Proteinsequenzen, automatische Spracherkennung und selbstfahrende Autos.
Neben dem Datensatz brauchst du einen Anwendungsfall für dein Unternehmen oder Anwendungsanforderungen. Du kannst überwachtes und unüberwachtes Lernen auf dieselben Daten anwenden.
Im Allgemeinen:
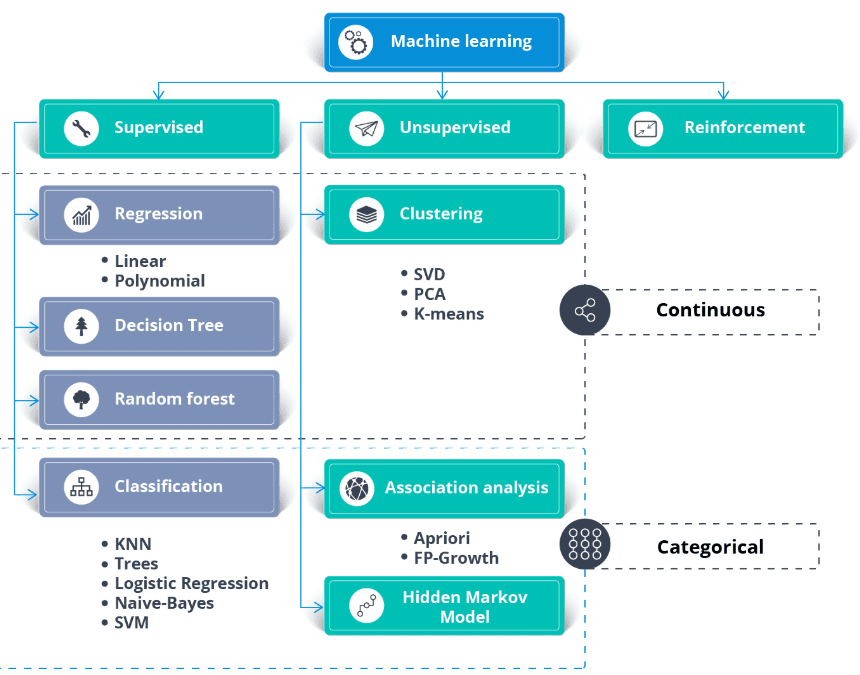
Bild von thecleverprogrammer
Lerne die Grundlagen des maschinellen Lernens in unserem Kurs.
Der K Nearest Neighbor (KNN) ist ein Klassifikator für überwachtes Lernen. Es nutzt die Nähe, um Labels zu sortieren oder die Gruppierung einzelner Datenpunkte vorherzusagen. Wir können es für Regression und Klassifizierung nutzen. Der KNN-Algorithmus ist nicht parametrisch, was bedeutet, dass er keine grundlegenden Annahmen zur Datenverteilung trifft.
Im KNN-Klassifikator:
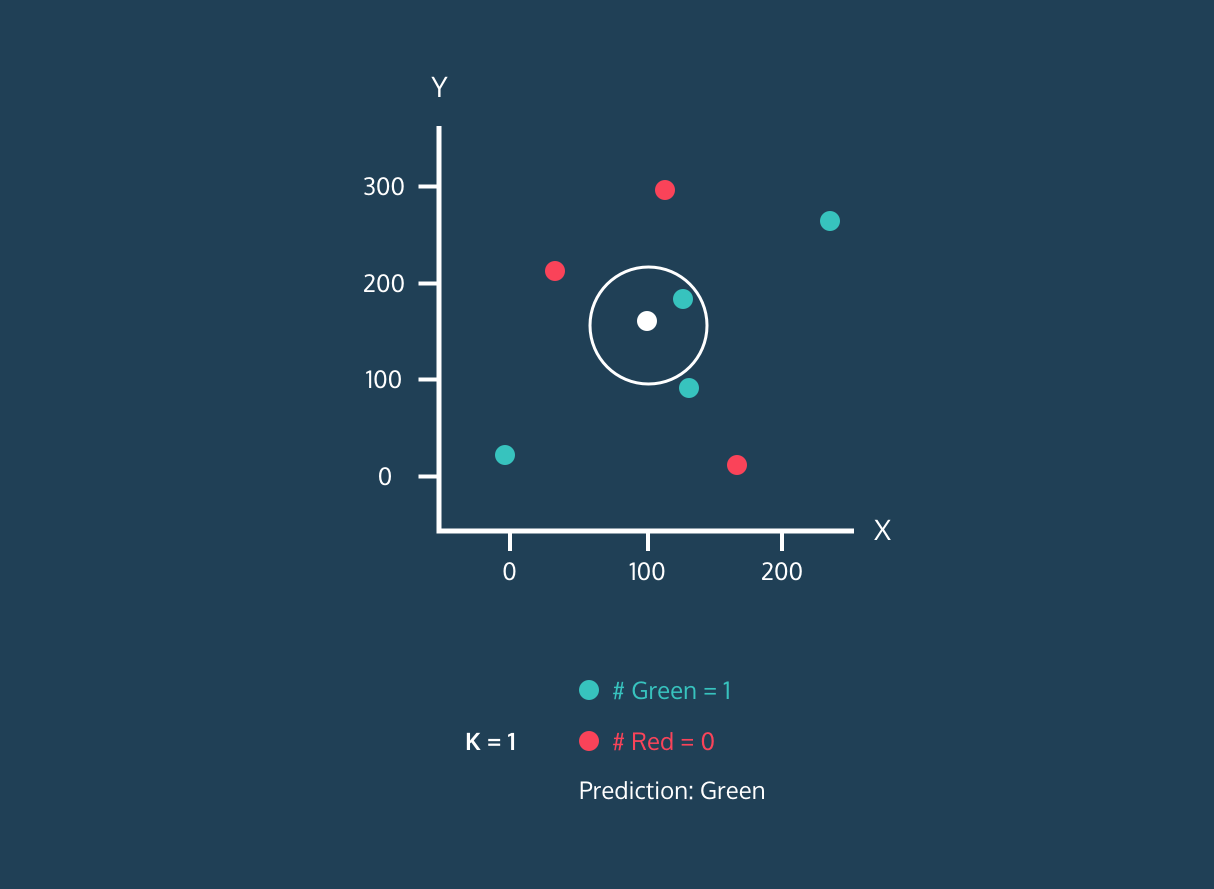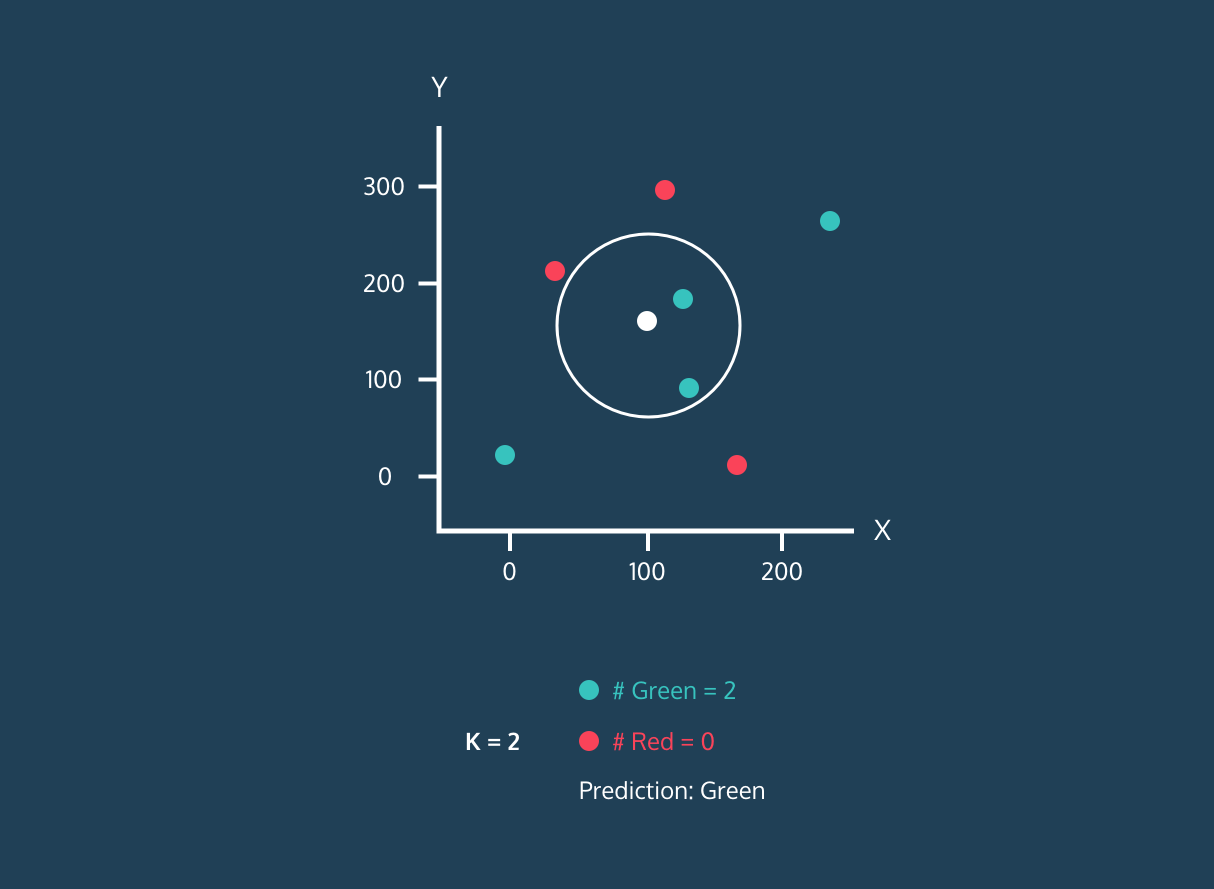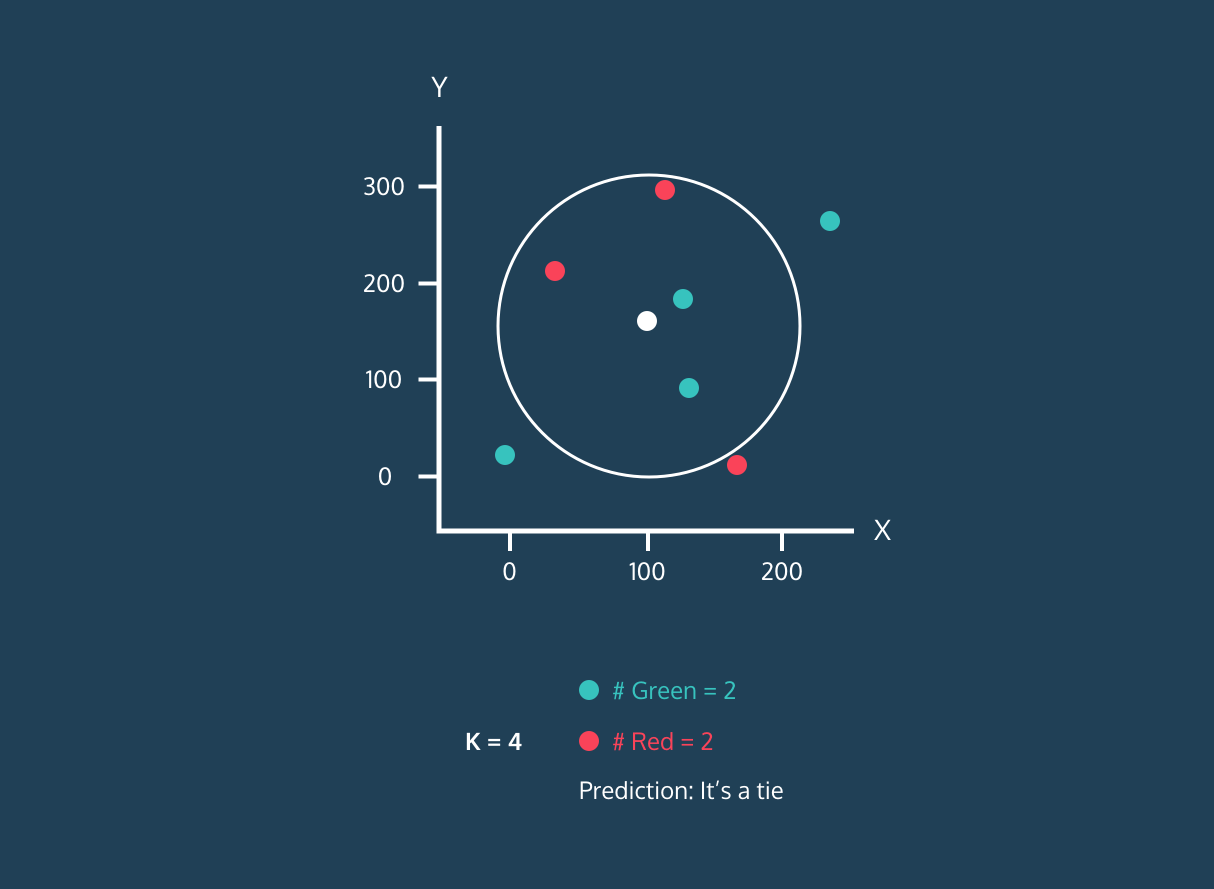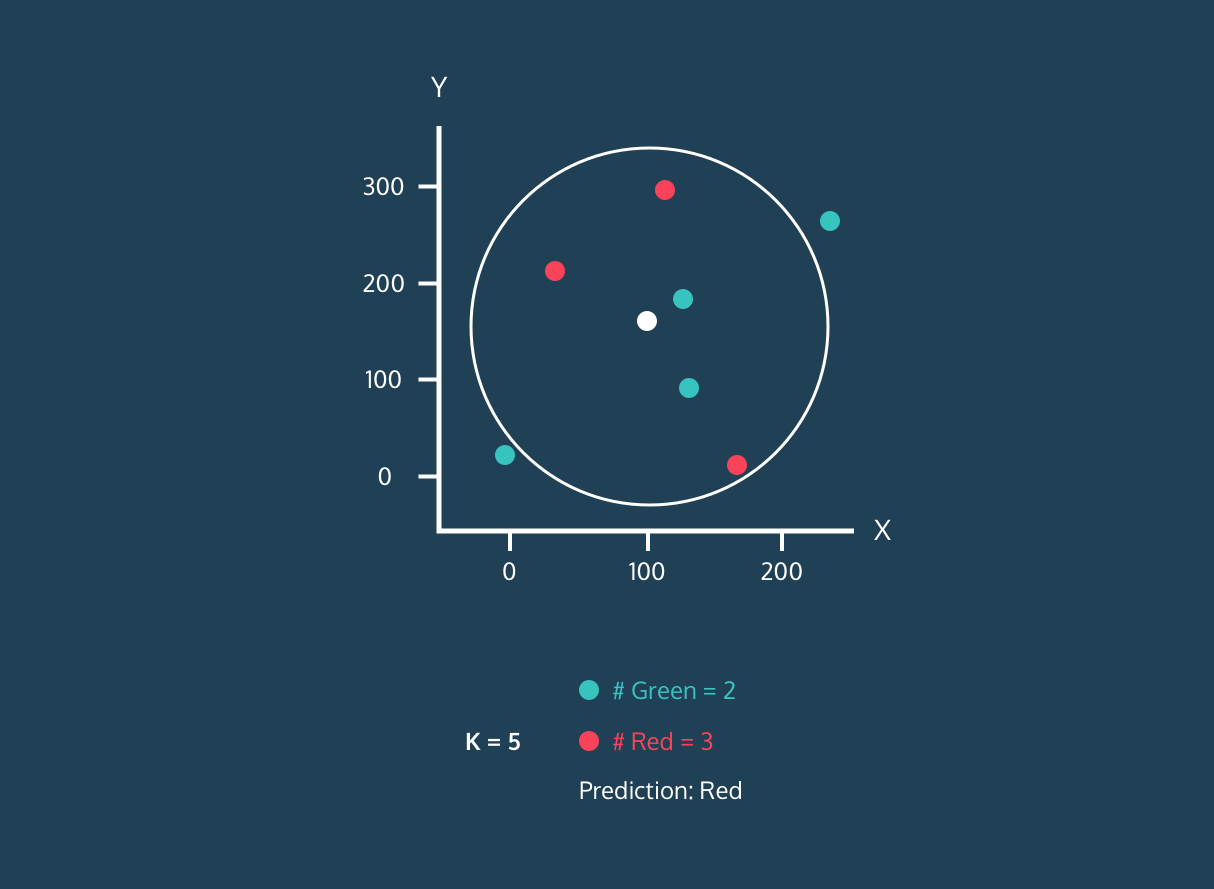
Bild aus der Entwicklergeschichte von Codesigner
Lerne in einem kurzen Kurs alles über überwachte Lernklassifikations- und Regressionsmodelle.
Die Merkmalsbedeutung ist eine Technik, bei der Eingabemerkmalen eine Punktzahl gegeben wird, je nachdem, wie gut sie eine Zielvariable vorhersagen können. Es ist echt wichtig, um die Struktur der Daten und das Verhalten des Modells zu verstehen und das Modell besser zu verstehen.
Es gibt ein paar Methoden, um die Wichtigkeit von Merkmalen zu bestimmen:
Das Verständnis der Merkmalsbedeutung ist super wichtig für die Modelloptimierung, weil es Überanpassung durch das Entfernen nicht informativer Merkmale reduziert und die Interpretierbarkeit des Modells verbessert, vor allem in Bereichen, in denen es entscheidend ist, den Entscheidungsprozess des Modells zu verstehen.
Überanpassung passiert, wenn ein Modell bei Trainingsdaten gut läuft, aber bei unbekannten Daten nicht funktioniert, weil es sich die Trainingsdaten gemerkt hat, anstatt die zugrunde liegenden Muster zu lernen. Das kann man vermeiden, indem man:
Eine Verwechslungsmatrix ist eine Tabelle, mit der man die Leistung eines Klassifizierungsmodells checkt. Es zeigt die Anzahl der echten positiven, echten negativen, falschen positiven und falschen negativen Ergebnisse. Es ist praktisch, um Metriken wie Genauigkeit, Präzision, Recall und F1-Score zu berechnen.
Parametrische Modelle: Diese machen Annahmen über die zugrunde liegende Verteilung der Daten und haben eine feste Anzahl von Parametern (z. B. lineare Regression).
Nichtparametrische Modelle: Die machen keine Annahmen über die Datenverteilung und können sich an die Komplexität anpassen, wenn mehr Daten dazukommen (z. B. K-Nearest Neighbors).
Der Bias-Varianz-Kompromiss ist die Balance zwischen der Fähigkeit eines Modells, komplexe Muster zu erfassen (geringer Bias), und seiner Empfindlichkeit gegenüber Schwankungen in den Trainingsdaten (geringe Varianz). Ein gutes Modell schafft ein Gleichgewicht, indem es sowohl Verzerrungen als auch Abweichungen minimiert, um Unteranpassung und Überanpassung zu vermeiden.
Im technischen Vorstellungsgespräch geht's mehr darum, dein Wissen über Prozesse zu checken und zu sehen, wie gut du mit Unsicherheiten umgehen kannst. Der Personalchef wird Fragen zum Thema maschinelles Lernen stellen, die sich um Datenverarbeitung, Modelltraining und -validierung sowie fortgeschrittene Algorithmen drehen.
Ja. Die meisten Algorithmen nutzen die euklidische Distanz zwischen Datenpunkten, und wenn der Merkmalswert stark variiert, fallen die Ergebnisse ziemlich unterschiedlich aus. Meistens sorgen Ausreißer dafür, dass Machine-Learning-Modelle beim Testdatensatz schlechter abschneiden.
Wir nutzen auch Feature-Skalierung, um die Konvergenzzeit zu verkürzen. Wenn die Merkmale nicht normalisiert sind, dauert es länger, bis der Gradientenabstieg lokale Minima erreicht.
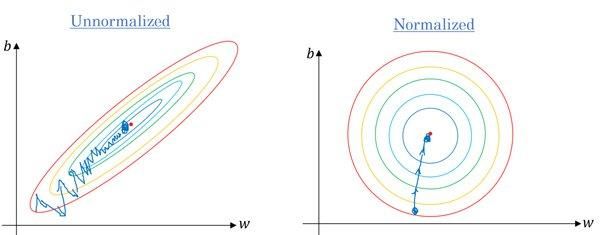
Gradient ohne und mit Skalierung | Quora
Feature-Engineering-Fähigkeiten sind echt gefragt. Du kannst alles über das Thema lernen, indem du einen DataCamp-Kurs machst, zum Beispiel „Feature Engineering für maschinelles Lernen in Python”.
Eine geringe Verzerrung tritt auf, wenn das Modell Werte vorhersagt, die nahe am tatsächlichen Wert liegen. Es ahmt den Trainingsdatensatz nach. Das Modell hat keine Generalisierung, was heißt, dass es bei Tests mit unbekannten Daten schlechte Ergebnisse liefert.
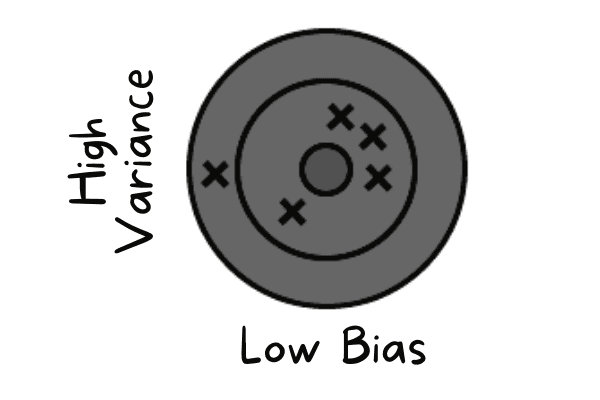
Geringe Verzerrung und hohe Varianz | Autor
Um diese Probleme zu lösen, werden wir Bagging-Algorithmen verwenden, da diese einen Datensatz mithilfe von zufälligen Stichproben in Teilmengen aufteilen. Dann machen wir mit diesen Beispielen und einem einzigen Algorithmus mehrere Modelle. Danach kombinieren wir die Modellvorhersagen mit Hilfe von Voting-Klassifizierung oder Mittelwertbildung.
Bei hoher Varianz können wir Regularisierungstechniken einsetzen. Es hat höhere Modellkoeffizienten bestraft, um die Komplexität des Modells zu verringern. Außerdem können wir die wichtigsten Merkmale aus dem Diagramm zur Merkmalsbedeutung auswählen und das Modell trainieren.
Modelldrift passiert, wenn die Leistung eines Modells mit der Zeit schlechter wird, weil sich die Daten aus der echten Welt im Vergleich zu den Trainingsdaten ändern. Es gibt zwei Haupttypen:
Kreuzvalidierung wird benutzt, um die Leistung von Modellen zuverlässig zu checken und eine Überanpassung zu vermeiden. Normalerweise nehmen Kreuzvalidierungstechniken zufällig Proben aus den Daten und teilen sie in Trainings- und Testdatensätze auf. Die Anzahl der Teilungen hängt vom K-Wert ab.
Wenn zum Beispiel K = 5 ist, gibt's vier Faltungen für den Zug und eine für den Test. Es wird fünfmal wiederholt, um das Modell zu messen, das auf separaten Faltungen durchgeführt wurde.
Mit einem Zeitreihendatensatz geht das nicht, weil es keinen Sinn macht, den Wert aus der Zukunft zu nehmen, um den Wert aus der Vergangenheit vorherzusagen. Es gibt eine zeitliche Abhängigkeit zwischen den Beobachtungen, und wir können die Daten nur in eine Richtung aufteilen, sodass die Werte des Testdatensatzes nach dem Trainingssatz kommen.
Das Diagramm zeigt, dass die k-fache Aufteilung der Zeitreihendaten nur in eine Richtung geht. Die blauen Punkte sind das Trainingsset, der rote Punkt ist das Testsatz und die weißen Punkte sind nicht verwendete Daten. Wie wir bei jeder Iteration sehen können, kommen wir mit dem Trainingssatz voran, während der Testsatz vor dem Trainingssatz bleibt und nicht zufällig ausgewählt wird.
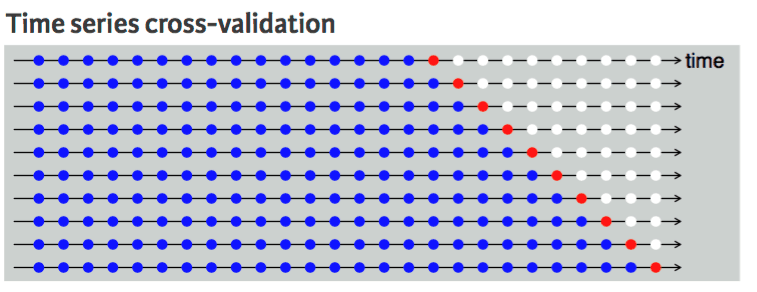
Zeitreihen-Kreuzvalidierung | UC Business Analytics R-Programmierhandbuch
Lerne mit dem Kurs „Zeitreihen mit Python“ alles über die Datenbearbeitung, Analyse, Visualisierung und Modellierung von Zeitreihendaten.
Die meisten Jobs im Bereich maschinelles Lernen, die auf LinkedIn, Glassdoor und Indeed angeboten werden, sind auf bestimmte Aufgaben zugeschnitten. Deshalb werden sie sich im Vorstellungsgespräch auf Fragen konzentrieren, die speziell mit der Stelle zu tun haben. Für die Stelle im Bereich Computer Vision Engineering wird sich der Personalverantwortliche auf Fragen zur Bildverarbeitung konzentrieren.
Stell dir ein Bild mit den Maßen 250 x 250 und eine komplett verbundene versteckte erste Schicht mit 1000 versteckten Einheiten vor. Für dieses Bild sind die Eingabefunktionen 250 x 250 x 3 = 187.500, und die Gewichtungsmatrix in der ersten versteckten Schicht ist eine Matrix mit den Maßen 187.500 x 1000. Diese Zahlen sind für die Speicherung und Berechnung echt riesig. Um dieses Problem zu lösen, nutzen wir Faltungsoperationen.
Lerne Bildverarbeitung mit einem kurzen Kurs zu Bildverarbeitung in Python.
Wenn du nicht genug Daten hast, um ein Convolutional Neural Network zu trainieren, kannst du Transfer Learning nutzen, um dein Modell zu trainieren und topmoderne Ergebnisse zu erzielen. Du brauchst ein vortrainiertes Modell, das mit einem allgemeinen, aber größeren Datensatz trainiert wurde. Danach optimierst du es anhand neuerer Daten, indem du die letzten Schichten der Modelle trainierst.
Mit Transferlernen können Datenwissenschaftler Modelle mit weniger Daten trainieren, indem sie weniger Ressourcen, Rechenleistung und Speicherplatz brauchen. Du kannst ganz einfach vorab trainierte Open-Source-Modelle für verschiedene Anwendungsfälle finden, und die meisten davon haben eine kommerzielle Lizenz, was bedeutet, dass du sie für die Erstellung deiner Anwendung nutzen kannst.
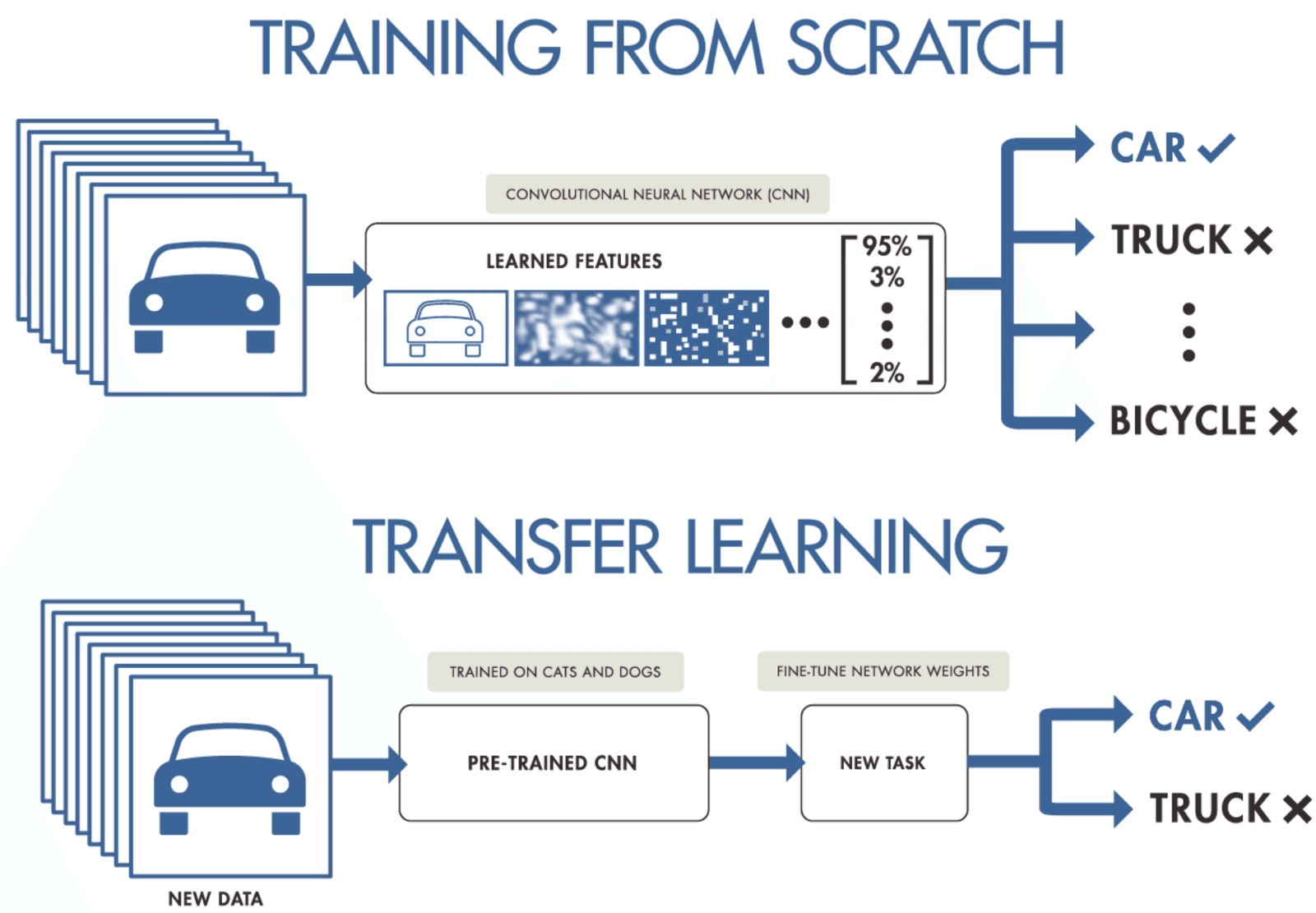
Transferlernen von Purnasai Gudikandula
YOLO ist ein Algorithmus zur Objekterkennung, der auf Faltungsneuronalen Netzen basiert und Ergebnisse in Echtzeit liefern kann. Der YOLO-Algorithmus braucht nur einen einzigen Durchlauf durch das CNN, um das Objekt zu erkennen. Es sagt sowohl verschiedene Klassenwahrscheinlichkeiten als auch Begrenzungsrahmen voraus.
Das Modell wurde trainiert, um verschiedene Objekte zu erkennen, und Firmen nutzen Transferlernen, um es für neue Daten für moderne Anwendungen wie autonomes Fahren, Naturschutz und Sicherheit zu optimieren.
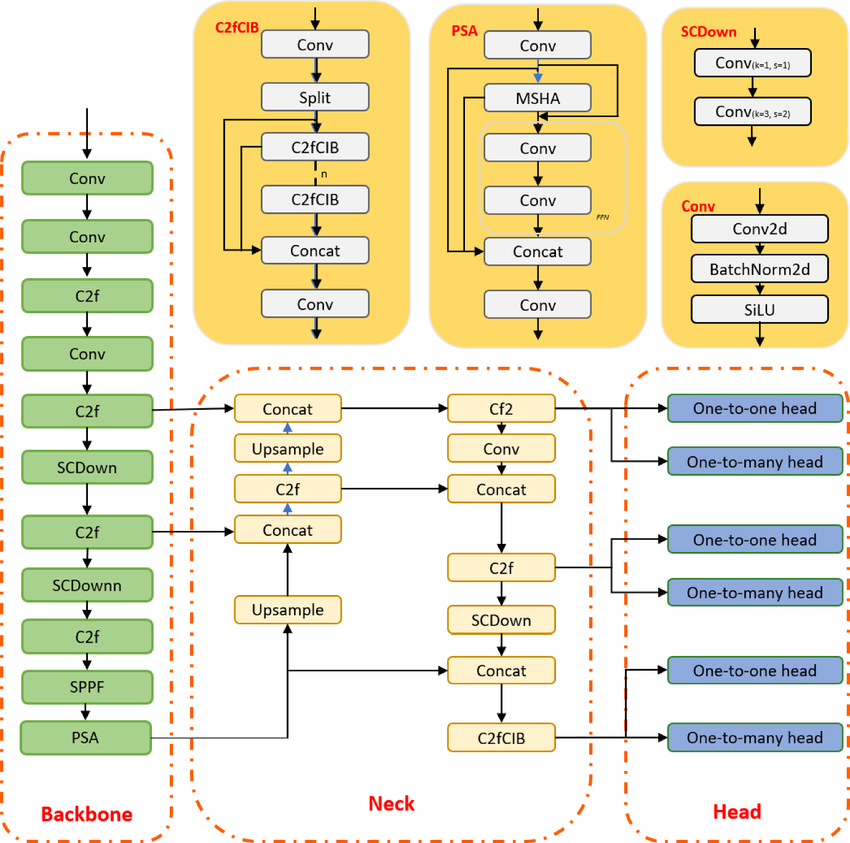
YOLOv10-Modellarchitektur | researchgate
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) ist eine der Grundlagen moderner KI-Anwendungen. Mach dich auf Fragen gefasst, die die Lücke zwischen Sprachtheorie und praktischer Umsetzung schließen und deine Fähigkeit testen, unstrukturierte Textdaten sowohl mit klassischen Techniken als auch mit modernen Deep-Learning-Ansätzen zu verarbeiten, zu analysieren und ihnen Bedeutung zu entnehmen.
Die syntaktische Analyse, auch bekannt als Syntaxanalyse oder Parsing, ist eine Textanalyse, die uns die logische Bedeutung hinter einem Satz oder einem Teil davon erklärt. Es geht um die Beziehung zwischen Wörtern und der grammatikalischen Struktur von Sätzen. Man kann auch sagen, dass es die Verarbeitung der Analyse der natürlichen Sprache mithilfe grammatikalischer Regeln ist.
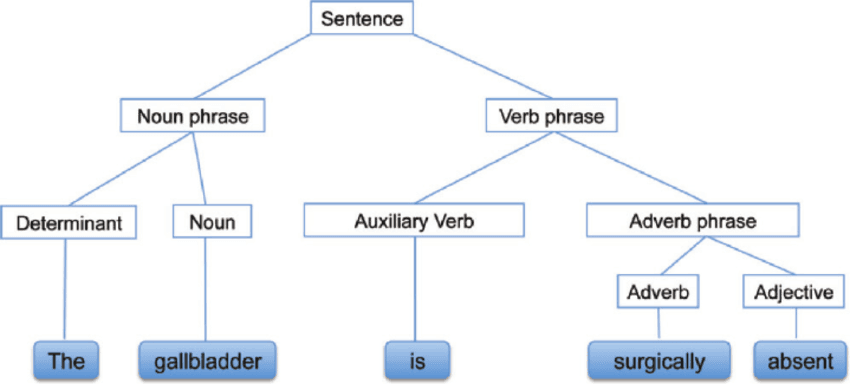
Syntaxanalyse | researchgate
Stemming und Lemmatisierung sind Techniken, die Wörter in einem Satz standardisieren, um strukturelle Unterschiede zu minimieren.
Stemming schmeißt die an das Wort angehängten Affixe raus und lässt es in seiner Grundform stehen. Zum Beispiel: Von „Changing“ zu „Chang“.
Es wird von Suchmaschinen oft für die Speicheroptimierung genutzt. Anstatt alle Formen der Wörter zu speichern, werden nur die Wortstämme gespeichert.
Die Lemmatisierung macht das Wort zu seiner Grundform. Die Ausgabe ist das Stammwort statt des Wortstamms. Nach der Lemmatisierung kriegen wir das richtige Wort, das was bedeutet. Zum Beispiel: Veränderung, um zu verändern.

Stemming vs. Lemmatisierung | Autor
Um große Transformatoren zu optimieren, muss man sich sowohl mit Speicherbandbreite als auch mit Rechenengpässen beschäftigen:
Lerne die Grundlagen von NLP, indem du den Lernpfad „Natural Language Processing in Python ” machst.
Da LLMs die aktuelle KI-Landschaft dominieren, suchen die Leute, die Vorstellungsgespräche führen, vor allem nach Leuten, die wissen, wie man sie effektiv einsetzt. Dieser Abschnitt geht auf einige der größten praktischen technischen Herausforderungen des Jahres 2026 ein.
Das Kontextfenster eines LLM ist die maximale Textmenge (gemessen in Tokens), die das Modell bei der Generierung einer Antwort gleichzeitig berücksichtigen kann, und es begrenzt direkt, wie viel „Arbeitsspeicher“ das Modell effektiv hat.
Auch wenn große Kontextfenster immer häufiger werden, steigen Leistung und Kosten nicht linear: Lange Eingabeaufforderungen erhöhen die Latenz und können immer noch zu Problemen mit der Zuverlässigkeit führen, wenn die relevanten Infos tief im Kontext vergraben sind.
In Interviews würde ich mit praktischen Strategien antworten praktische Strategien für Aufgaben mit langen Dokumenten:
Halluzinationen treten auf, wenn ein LLM plausible, aber sachlich falsche Infos generiert. Im Jahr 2026 braucht es für den Klimaschutz einen mehrschichtigen Ansatz:
Das ist echt eine typische „Entweder-oder“-Frage. Die Entscheidung hängt davon ab, wie aktuell die Daten sind und wie spezifisch die Domain ist:
Die Frage wird in unserem Blogbeitrag „RAG vs. Fine-Tuning“ genauer besprochen.
Reinforcement Learning (RL) geht Probleme an, bei denen ein Agent durch Interaktion mit einer Umgebung lernt und nicht durch statische Datensätze. Sei bereit, darüber zu reden, wie RL funktioniert, und wichtige Sachen wie Richtlinien zu erklären.
Beim Reinforcement Learning geht's darum, durch Ausprobieren ans Ziel zu kommen. Es ist ein zielorientierter Algorithmus, der aus der Umgebung lernt, indem er die richtigen Schritte macht, um die kumulative Belohnung zu maximieren.
Beim typischen Reinforcement Learning:
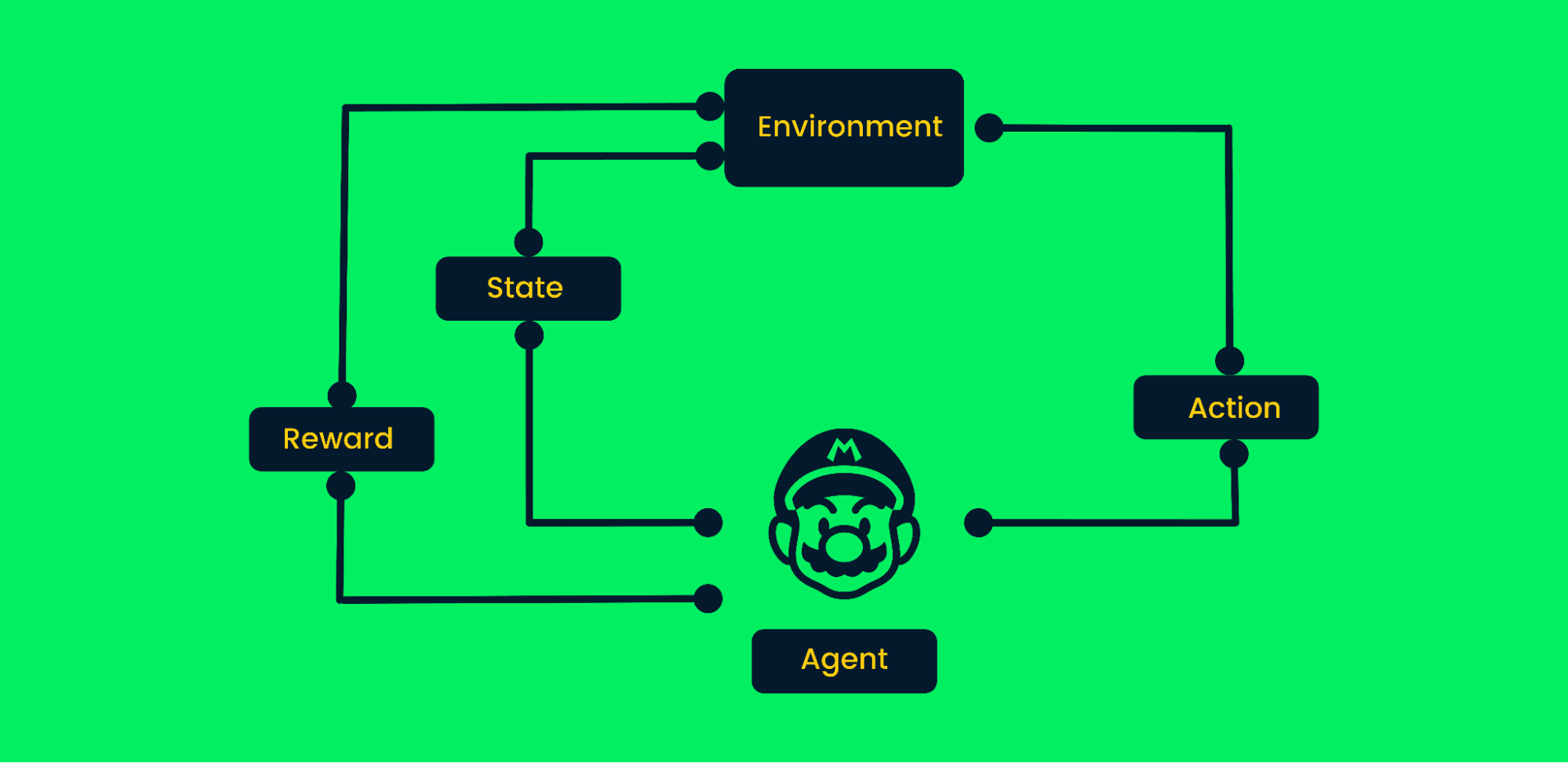
Framework für verstärktes Lernen | Autor
On-Policy-Lernalgorithmen checken und verbessern dieselbe Vorgehensweise, um sie anzuwenden und zu aktualisieren. Also, die Richtlinie, die für die Aktualisierung benutzt wird, und die, die für Maßnahmen benutzt wird, sind die gleichen.
Zielpolitik == Verhaltenspolitik
On-Policy-Algorithmen sind Sarsa, Monte Carlo für On-Policy, Value Iteration und Policy Iteration.
Off-Policy-Lernalgorithmen sind total anders, weil die aktualisierte Richtlinie anders ist als die Verhaltensrichtlinie. Zum Beispiel lernt der Agent beim Q-Lernen mit Hilfe einer gierigen Strategie aus einer optimalen Strategie und macht dann mit anderen Strategien weiter.
Zielpolitik ≠ Verhaltenspolitik
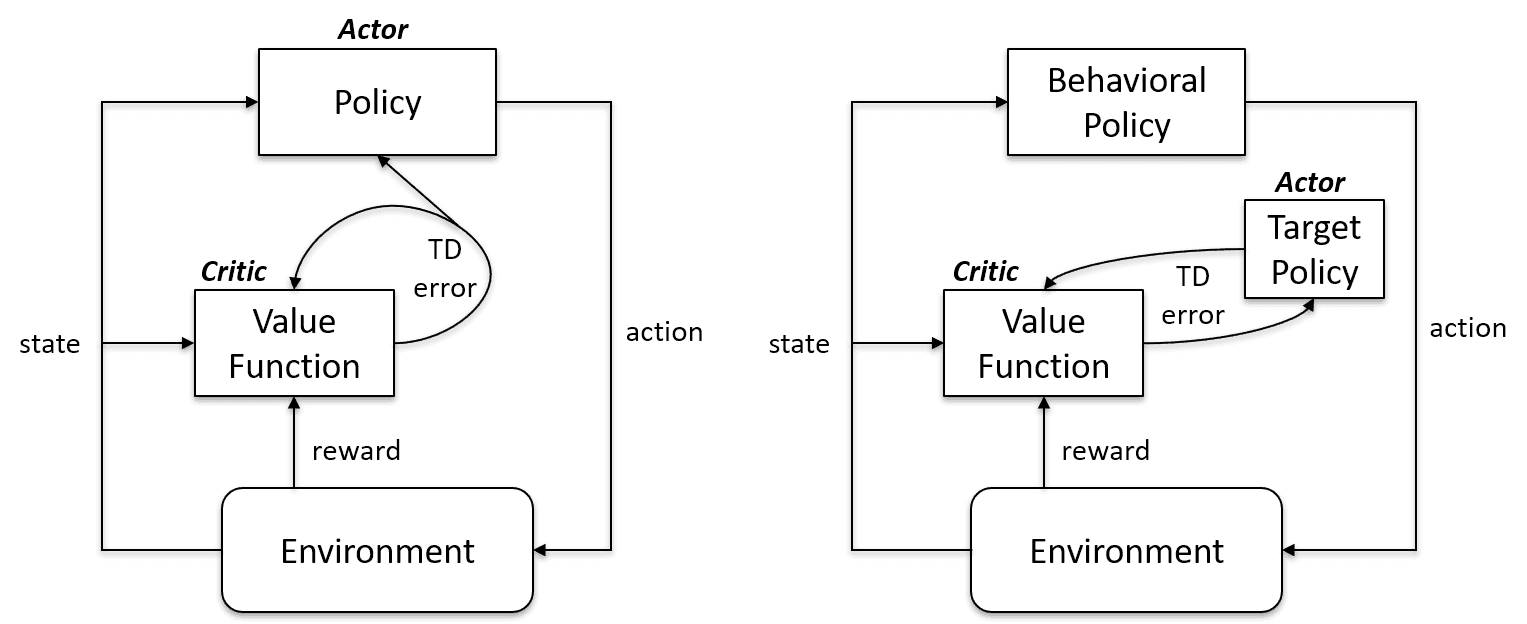
On-Policy vs. Fall außerhalb der Richtlinie | Künstliche Intelligenz Stack Exchange
Einfaches Q-Lernen ist echt super. Es löst das Problem im kleinen Rahmen, aber im großen Rahmen klappt es nicht.
Stell dir vor, die Umgebung hätte 1000 Zustände und 1000 Aktionen pro Zustand. Wir brauchen eine Q-Tabelle mit Millionen von Zellen. Für Schach und Go braucht man einen noch größeren Tisch. Hier kommt Deep Q-Learning ins Spiel.
Es nutzt ein neuronales Netzwerk, um die Q-Wert-Funktion zu schätzen. Das Rezept für neuronale Netze gibt als Input den Q-Wert aller möglichen Aktionen an und gibt ihn auch als Output wieder.
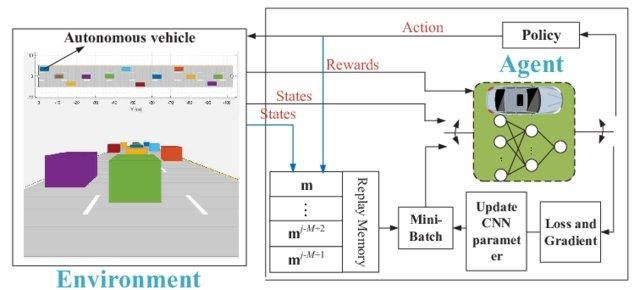
Deep Q-Netzwerk für autonomes Fahren | researchgate
Hier sind ein paar Fragen, die dir der Interviewer bei einigen der besten Tech-Firmen stellen könnte:
Die Empfänger-Operationscharakteristik (ROC) zeigt den Kompromiss zwischen Sensitivität und Spezifität.
Die Kurve wird anhand der Falsch-Positiv-Rate (FP/(TN + FP)) und der Echt-Positiv-Rate (TP/(TP + FN)) gezeichnet.
Die Fläche unter der Kurve (AUC) zeigt, wie gut das Modell funktioniert. Wenn die Fläche unter der ROC-Kurve 0,5 ist, dann ist unser Modell komplett zufällig. Das Modell mit einem AUC-Wert nahe 1 ist das bessere Modell.
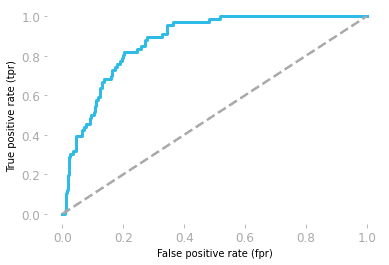
ROC-Kurve von Hadrien Jean
Anders als bei der Klassifizierung (wo eine Antwort richtig oder falsch ist) braucht man bei GenAI oft menschliche Bewertung oder „LLM-as-a-Judge”-Frameworks:
Zur Reduzierung der Dimensionalität können wir Methoden zur Merkmalsauswahl oder Merkmalsextraktion nutzen.
Die Merkmalsauswahl ist ein Prozess, bei dem man die besten Merkmale aussucht und die unwichtigen weglässt. Wir nutzen Filter-, Wrapper- und Embedded-Methoden, um die Wichtigkeit von Merkmalen zu analysieren und weniger wichtige Merkmale zu entfernen, um die Modellleistung zu verbessern.
Die Merkmalsextraktion verwandelt den Raum mit mehreren Dimensionen in einen Raum mit weniger Dimensionen. Dabei gehen keine Infos verloren und es werden weniger Ressourcen für die Datenverarbeitung gebraucht. Die gängigsten Extraktionstechniken sind die lineare Diskriminanzanalyse (LDA), die Kernel-PCA und die quadratische Diskriminanzanalyse.
Bei einem Spam-Klassifikator gibt ein logistisches Regressionsmodell die Wahrscheinlichkeit zurück. Wir nehmen entweder die Wahrscheinlichkeit von 0,8999 oder wandeln sie mithilfe eines Schwellenwerts in eine Klasse (Spam/Kein Spam) um.
Normalerweise ist der Schwellenwert eines Klassifikators 0,5, aber manchmal muss man ihn anpassen, um die Genauigkeit zu verbessern. Der Schwellenwert von 0,5 heißt: Wenn die Wahrscheinlichkeit bei 0,5 oder höher liegt, ist es Spam, und wenn sie niedriger ist, ist es kein Spam.
Um den Schwellenwert zu finden, können wir Präzisions-Recall-Kurven und ROC-Kurven, Rastersuche und die manuelle Änderung des Werts verwenden, um einen besseren CV zu bekommen.
Mach dich zum Profi im Bereich maschinelles Lernen, indem du den Lernpfad „Machine Learning Scientist with Python“ abschließt.
Lineare Regression hilft dabei, die Beziehung zwischen Merkmalen (X) und Ziel (y) zu verstehen. Bevor wir das Modell trainieren, müssen wir ein paar Voraussetzungen erfüllen:
Hey, die Residuen in der linearen Regression sind die Differenz zwischen den tatsächlichen und den vorhergesagten Werten.
Bei Programmier-Interviews wirst du zu Themen rund um maschinelles Lernen befragt, aber manchmal checken sie auch deine Python-Kenntnisse, indem sie dir allgemeine Programmierfragen stellen. Werde ein Python-Programmierprofi, indem du den Lernpfad „Python-Programmierer“ einschlägst.
Eine Bigramm-Funktion zu erstellen ist echt einfach. Du musst zwei Schleifen mit der Zip-Funktion verwenden.
zip “ kannst du das vorherige und das nächste Wort verbinden.Es ist ziemlich einfach, wenn du das Problem aufteilst und Zip-Funktionen benutzt.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Ergebnisse:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]Die Aktivierungsfunktion ist eine nichtlineare Transformation in neuronalen Netzen. Wir lassen die Eingabe durch die Aktivierungsfunktion laufen, bevor wir sie an die nächste Schicht weitergeben.
Der Netzeingangswert kann zwischen -inf und +inf liegen, und das Neuron weiß nicht, wie es die Werte begrenzen soll, sodass es das Auslösemuster nicht bestimmen kann. Die Aktivierungsfunktion entscheidet, ob ein Neuron aktiviert wird oder nicht, um die Netzeingangswerte zu begrenzen.
Die häufigsten Arten von Aktivierungsfunktionen:
Die Antwort liegt ganz bei dir. Bevor du antwortest, solltest du dir überlegen, welches Geschäftsziel du erreichen willst, um eine Leistungskennzahl festzulegen, und wie du die Daten sammeln willst.
Bei einem typischen Design für maschinelles Lernen machen wir Folgendes:
Du solltest dich auf das Design konzentrieren und nicht so sehr auf die Theorie oder die Modellarchitektur. Sag unbedingt, wie die Modellinferenz funktioniert und wie man sie verbessern kann, um die Gesamteinnahmen zu steigern.
Gib auch einen Überblick darüber, warum du eine bestimmte Methode der anderen vorgezogen hast.
Lerne mehr über das Erstellen von Empfehlungssystemen, indem du einen Kurs bei DataCamp machst.
Wenn du Programmieraufgaben löst und deine Python-Kenntnisse verbesserst, hast du bessere Chancen, die Programmier-Interviewphase zu meistern.
Bevor du dich an die Lösung eines Problems machst, musst du die Frage verstehen. Du musst einfach eine boolesche Funktion erstellen, die „True“ zurückgibt, wenn du durch Verschieben der Buchstaben in String B den String A bekommst.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueBeim Ensemble Learning werden die Erkenntnisse aus mehreren Machine-Learning-Modellen zusammengebracht, um die Genauigkeit und die Leistungskennzahlen zu verbessern.
Einfache Ensemble-Methoden:
Fortgeschrittene Ensemble-Methoden:
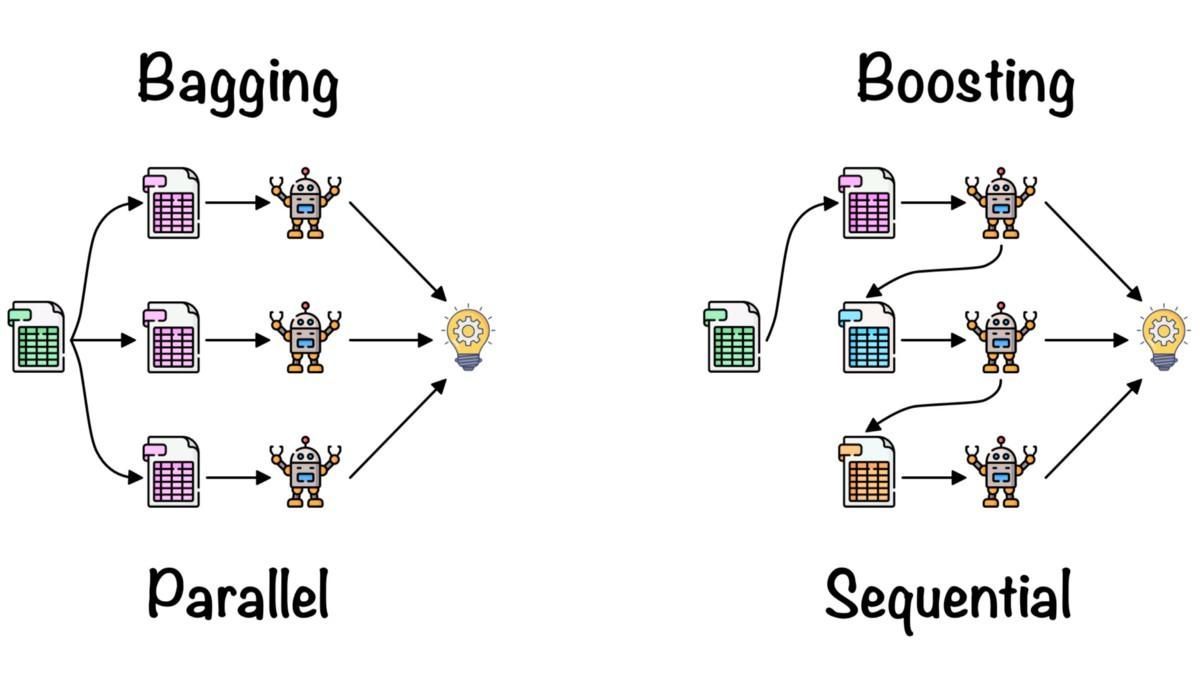
Verpacken und Verstärken von Fernando López
Lerne mehr über Mittelwertbildung, Bagging, Stacking und Boosting, indem du den Kurs „Ensemble-Methoden in Python” machst.
Zum Abschluss unserer Reihe über wichtige Fragen im Vorstellungsgespräch zum Thema maschinelles Lernen ist klar, dass man für den Erfolg in solchen Gesprächen eine Mischung aus theoretischem Wissen, praktischen Fähigkeiten und einem Bewusstsein für die neuesten Trends und Technologien in diesem Bereich braucht. Von den grundlegenden Konzepten wie halbüberwachtem Lernen und Algorithmusauswahl bis hin zur Auseinandersetzung mit der Komplexität bestimmter Algorithmen wie KNN und der Bewältigung rollenspezifischer Herausforderungen in den Bereichen NLP, Computer Vision oder Reinforcement Learning ist das Spektrum riesig.
Egal, ob du ein Anfänger bist, der in diesem Bereich durchstarten will, oder ein erfahrener Profi, der sich weiterentwickeln möchte – kontinuierliches Lernen und Üben sind der Schlüssel zum Erfolg. DataCamp hat einen coolen Lernpfad für Machine Learning Scientist mit Python, der dir eine strukturierte und gründliche Möglichkeit bietet, deine Fähigkeiten zu verbessern.
Kurse zum maschinellen Lernen
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
