Kursus
Machine Learning untuk Keuangan dengan Python
4 Hr
33K
Pertanyaan dasar terkait terminologi, algoritma, dan metodologi. Pewawancara menanyakan pertanyaan ini untuk menilai pengetahuan teknis kandidat.
Semi-supervised learning adalah perpaduan antara supervised dan unsupervised learning. Algoritma dilatih pada campuran data berlabel dan tidak berlabel. Umumnya digunakan ketika kita memiliki dataset berlabel yang sangat kecil dan dataset tidak berlabel yang besar.
Sederhananya, algoritma unsupervised digunakan untuk membuat klaster dan dengan menggunakan data berlabel yang sudah ada untuk memberi label pada sisa data yang tidak berlabel. Algoritma semi-supervised mengasumsikan continuity assumption, cluster assumption, dan manifold assumption.
Umumnya digunakan untuk menghemat biaya perolehan data berlabel. Misalnya, klasifikasi urutan protein, pengenalan ucapan otomatis, dan mobil tanpa pengemudi.
Selain dataset, Anda memerlukan use case bisnis atau kebutuhan aplikasi. Anda dapat menerapkan supervised dan unsupervised learning pada data yang sama.
Secara umum:
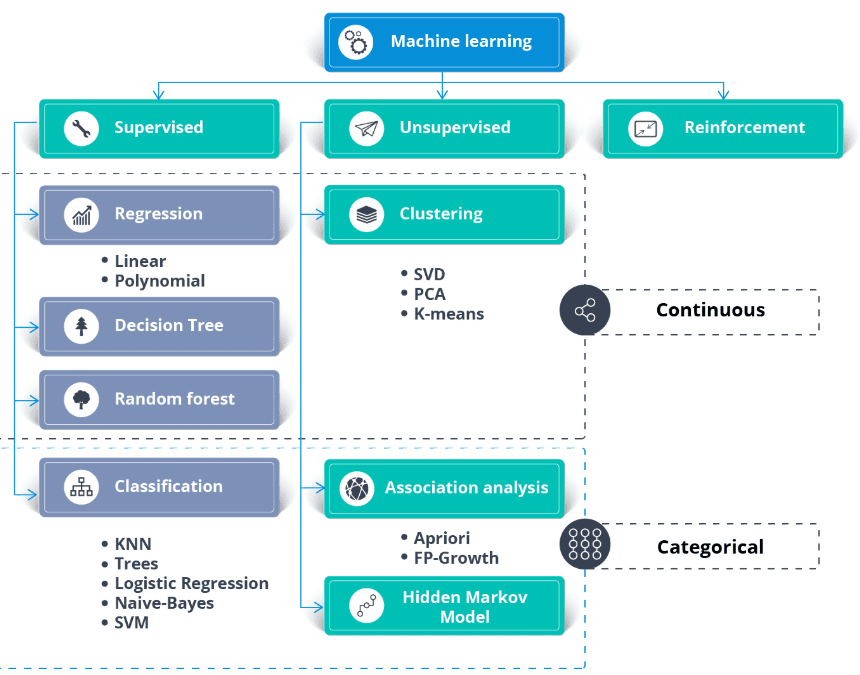
Gambar dari thecleverprogrammer
Pelajari dasar-dasar machine learning dengan mengikuti kursus kami.
K Nearest Neighbor (KNN) adalah pengklasifikasi supervised learning. Algoritma ini menggunakan kedekatan untuk mengklasifikasikan label atau memprediksi pengelompokan titik data individual. Kita dapat menggunakannya untuk regresi dan klasifikasi. Algoritma KNN bersifat non-parametrik, artinya tidak membuat asumsi dasar tentang distribusi data.
Pada pengklasifikasi KNN:
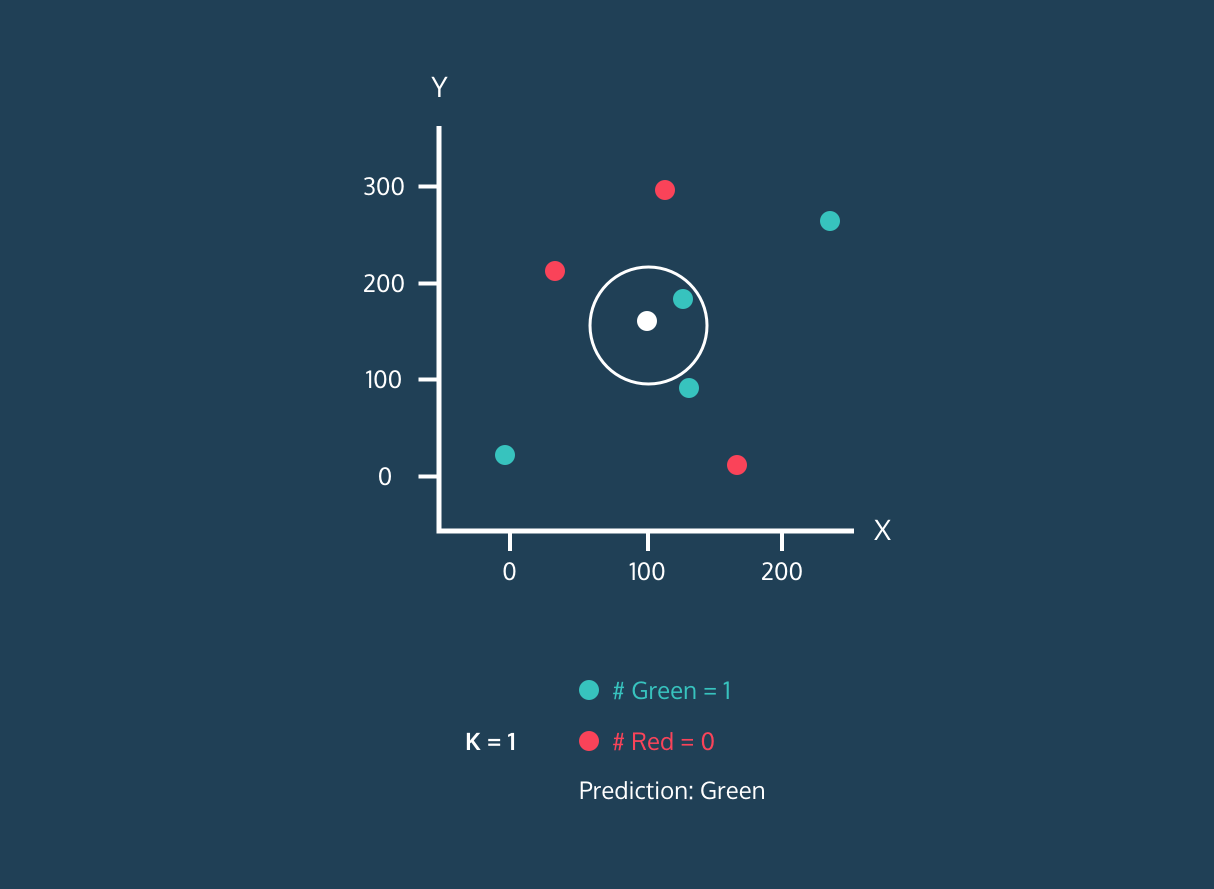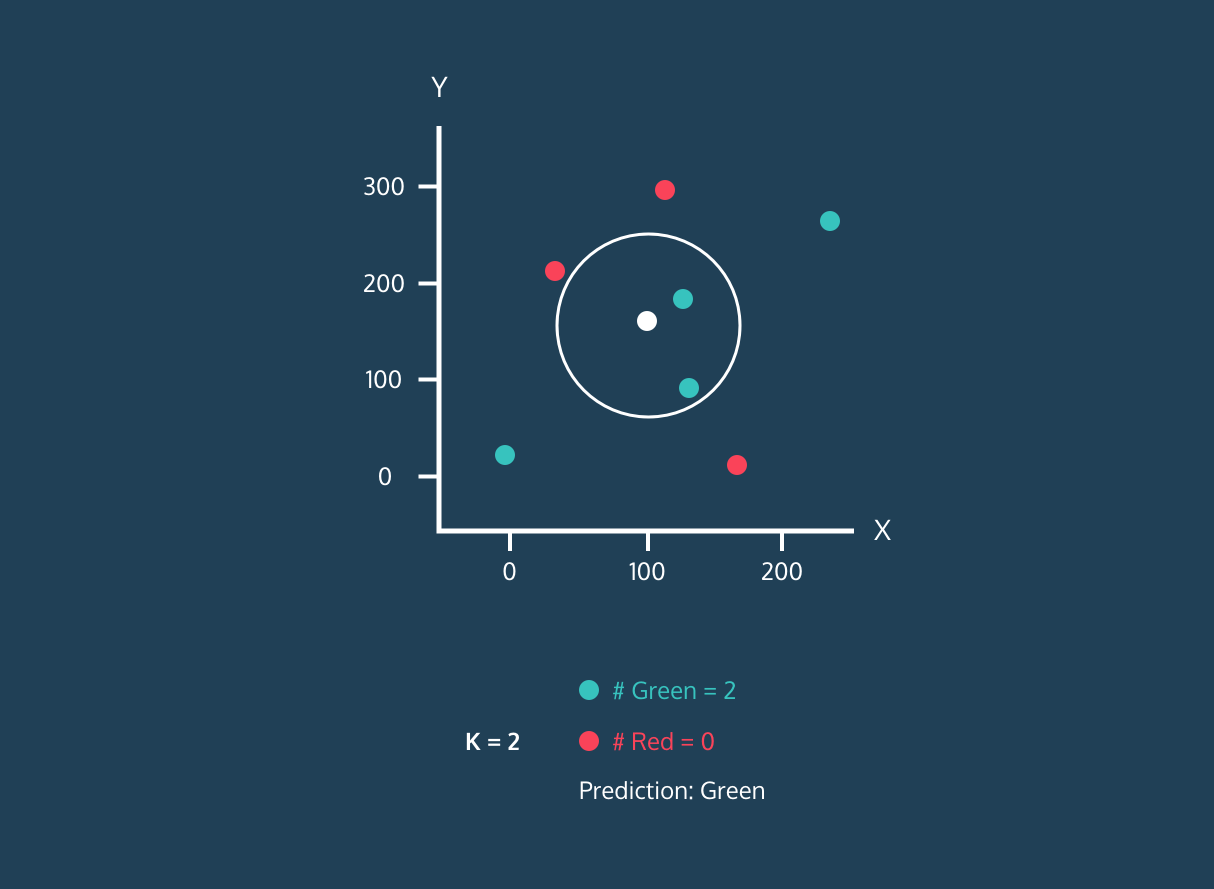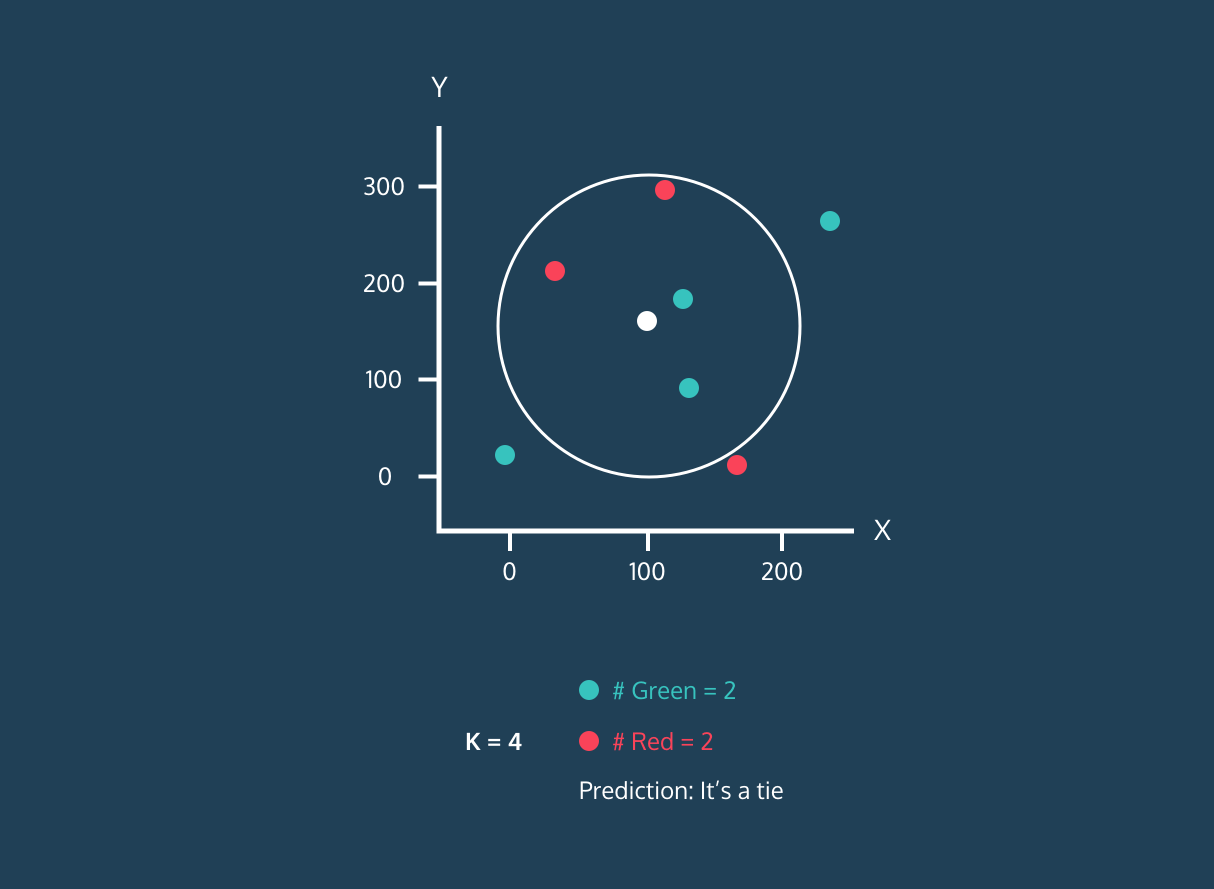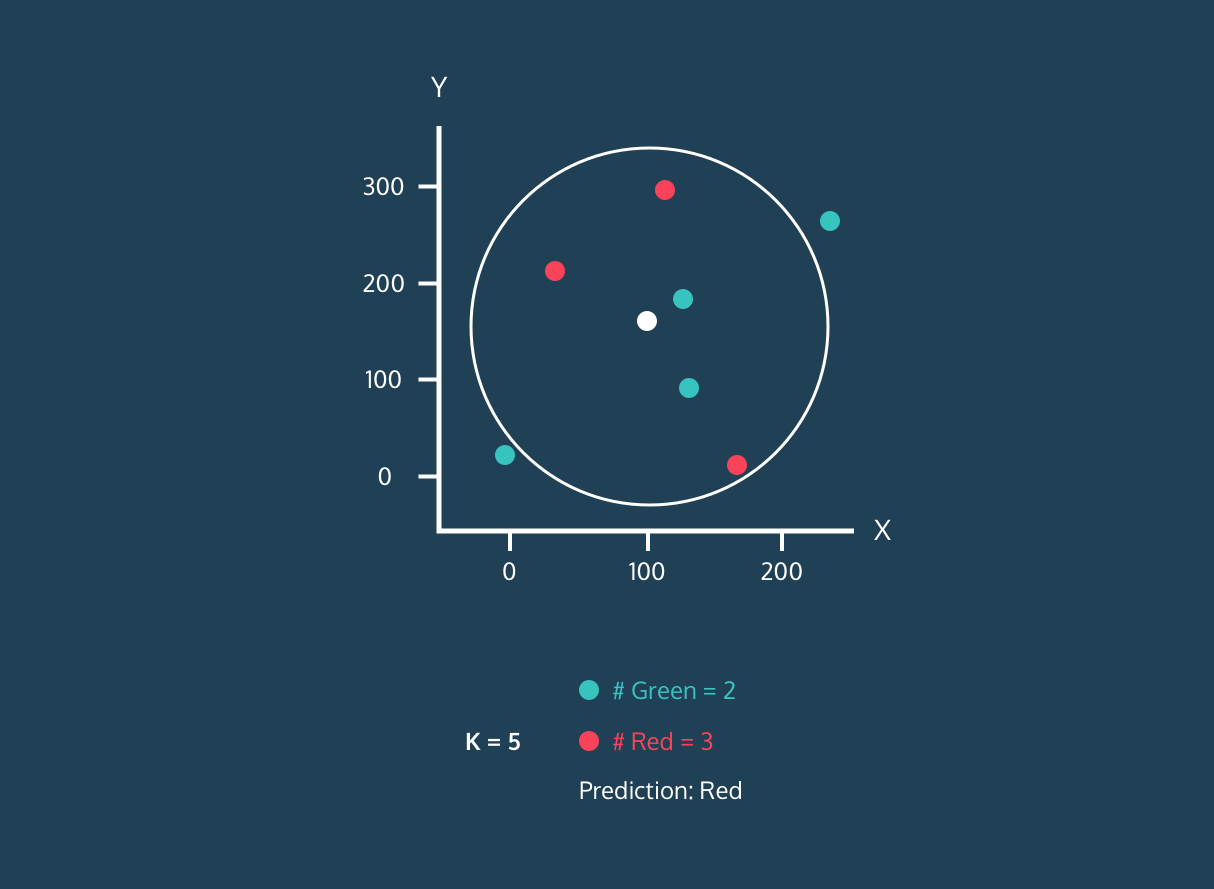
Gambar dari Codesigner's Dev Story
Pelajari semua tentang model klasifikasi dan regresi supervised learning dengan mengikuti kursus singkat.
Feature importance mengacu pada teknik yang memberikan skor pada fitur input berdasarkan seberapa bermanfaatnya fitur tersebut dalam memprediksi variabel target. Ini berperan penting untuk memahami struktur dasar data, perilaku model, dan membuat model lebih mudah diinterpretasikan.
Ada beberapa metode untuk menentukan feature importance:
Memahami feature importance sangat penting untuk optimasi model, mengurangi overfitting dengan menghapus fitur non-informatif, dan meningkatkan interpretabilitas model, terutama di domain di mana pemahaman proses pengambilan keputusan model itu krusial.
Overfitting terjadi ketika model berkinerja baik pada data pelatihan tetapi gagal melakukan generalisasi ke data yang belum pernah dilihat karena model menghafal data pelatihan alih-alih mempelajari pola dasarnya. Ini dapat dihindari dengan:
Confusion matrix adalah tabel yang digunakan untuk mengevaluasi kinerja model klasifikasi. Tabel ini menampilkan jumlah true positive, true negative, false positive, dan false negative. Berguna untuk menghitung metrik seperti akurasi, presisi, recall, dan skor F1.
Model Parametrik: Membuat asumsi tentang distribusi dasar data dan memiliki jumlah parameter tetap (misalnya, Linear Regression).
Model Non-Parametrik: Tidak membuat asumsi tentang distribusi data dan dapat beradaptasi dengan kompleksitas saat lebih banyak data ditambahkan (misalnya, K-Nearest Neighbors).
Bias-variance tradeoff mengacu pada keseimbangan antara kemampuan model untuk menangkap pola kompleks (bias rendah) dan sensitivitasnya terhadap fluktuasi pada data pelatihan (variance rendah). Model yang baik mencapai keseimbangan dengan meminimalkan bias dan variance untuk menghindari underfitting dan overfitting.
Sesi wawancara teknis lebih berfokus pada penilaian pengetahuan Anda tentang proses dan seberapa siap Anda menangani ketidakpastian. Hiring manager akan menanyakan pertanyaan wawancara machine learning tentang pemrosesan data, pelatihan dan validasi model, serta algoritma lanjutan.
Benar. Sebagian besar algoritma menggunakan jarak Euclidean antar titik data, dan jika nilai fitur sangat bervariasi, hasilnya akan sangat berbeda. Dalam banyak kasus, outlier menyebabkan model machine learning berkinerja lebih buruk pada dataset uji.
Kita juga menggunakan feature scaling untuk mengurangi waktu konvergensi. Gradient descent akan memerlukan waktu lebih lama untuk mencapai local minima ketika fitur tidak dinormalisasi.
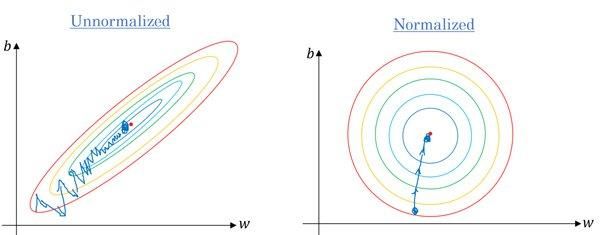
Gradien tanpa dan dengan penskalaan | Quora
Kemampuan feature engineering sangat diminati. Anda dapat mempelajari semuanya dengan mengikuti kursus DataCamp, seperti Feature Engineering for Machine Learning in Python.
Bias rendah terjadi ketika model memprediksi nilai yang mendekati nilai aktual. Model meniru dataset pelatihan. Model tidak memiliki generalisasi, artinya jika diuji pada data yang belum pernah dilihat, hasilnya akan buruk.
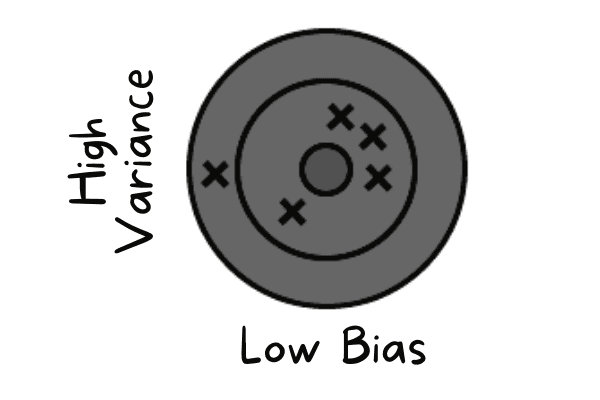
Bias rendah dan variance tinggi | Penulis
Untuk memperbaiki masalah ini, kita akan menggunakan algoritma bagging karena membagi dataset menjadi subset menggunakan pengambilan sampel acak. Lalu, kita menghasilkan kumpulan model menggunakan sampel ini dengan satu algoritma. Setelah itu, kita menggabungkan prediksi model menggunakan voting classification atau perataan (averaging).
Untuk variance tinggi, kita dapat menggunakan teknik regularisasi. Teknik ini memberikan penalti pada koefisien model yang lebih tinggi untuk menurunkan kompleksitas model. Selain itu, kita dapat memilih fitur teratas dari grafik feature importance dan melatih model.
Model drift terjadi ketika kinerja model menurun seiring waktu karena data dunia nyata berubah dibandingkan dengan data pelatihan. Ada dua jenis utama:
Cross-validation digunakan untuk mengevaluasi kinerja model secara andal dan mencegah overfitting. Umumnya, teknik cross-validation memilih sampel secara acak dari data dan membaginya menjadi train dan test set. Jumlah pembagian didasarkan pada nilai K.
Misalnya, jika K = 5, akan ada empat fold untuk train dan satu untuk test. Ini akan diulang lima kali untuk mengukur kinerja model pada fold terpisah.
Kita tidak dapat melakukannya pada dataset deret waktu karena tidak masuk akal menggunakan nilai dari masa depan untuk memprediksi nilai masa lalu. Ada ketergantungan temporal antarobservasi, dan kita hanya bisa membagi data ke satu arah sehingga nilai pada dataset uji berada setelah set pelatihan.
Diagram menunjukkan bahwa pembagian k-fold data deret waktu bersifat searah. Titik biru adalah training set, titik merah adalah test set, dan putih adalah data yang tidak digunakan. Seperti yang dapat kita amati, pada setiap iterasi, kita bergerak maju dengan training set sementara test set tetap di depan training set, bukan dipilih secara acak.
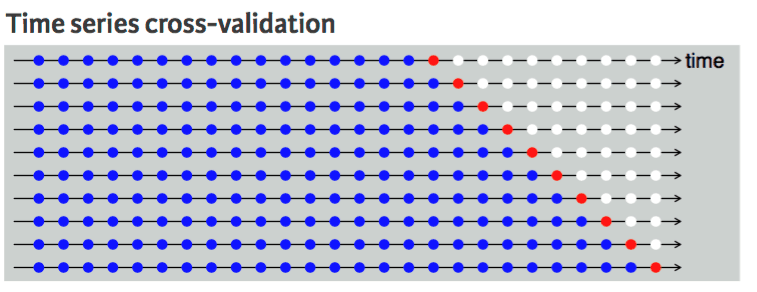
Cross validation deret waktu | UC Business Analytics R Programming Guide
Pelajari manipulasi, analisis, visualisasi, dan pemodelan data deret waktu dengan mengikuti Time Series with Python.
Kebanyakan pekerjaan machine learning yang ditawarkan di LinkedIn, Glassdoor, dan Indeed bersifat spesifik peran. Karena itu, selama wawancara, mereka akan fokus pada pertanyaan yang spesifik peran. Untuk peran rekayasa computer vision, hiring manager akan fokus pada pertanyaan pemrosesan citra.
Bayangkan sebuah gambar 250 X 250 dan lapisan tersembunyi pertama yang sepenuhnya terhubung dengan 1000 unit tersembunyi. Untuk gambar ini, fitur input adalah 250 X 250 X 3 = 187.500, dan matriks bobot pada lapisan tersembunyi pertama akan berukuran 187.500 X 1000. Angka-angka ini sangat besar untuk penyimpanan dan komputasi, dan untuk mengatasi masalah ini, kita menggunakan operasi konvolusi.
Pelajari pemrosesan citra dengan mengikuti kursus singkat Image Processing in Python
Jika Anda tidak memiliki cukup data untuk melatih convolutional neural network, Anda dapat menggunakan transfer learning untuk melatih model dan mendapatkan hasil mutakhir. Anda memerlukan model pra-latih yang dilatih pada dataset yang lebih besar namun umum. Setelah itu, Anda akan fine-tune pada data yang lebih baru dengan melatih lapisan terakhir dari model.
Transfer learning memungkinkan data scientist melatih model pada data yang lebih kecil dengan menggunakan sumber daya, komputasi, dan penyimpanan yang lebih sedikit. Anda dapat dengan mudah menemukan model pra-latih open-source untuk berbagai use case, dan sebagian besar memiliki lisensi komersial yang berarti Anda dapat menggunakannya untuk membuat aplikasi Anda.
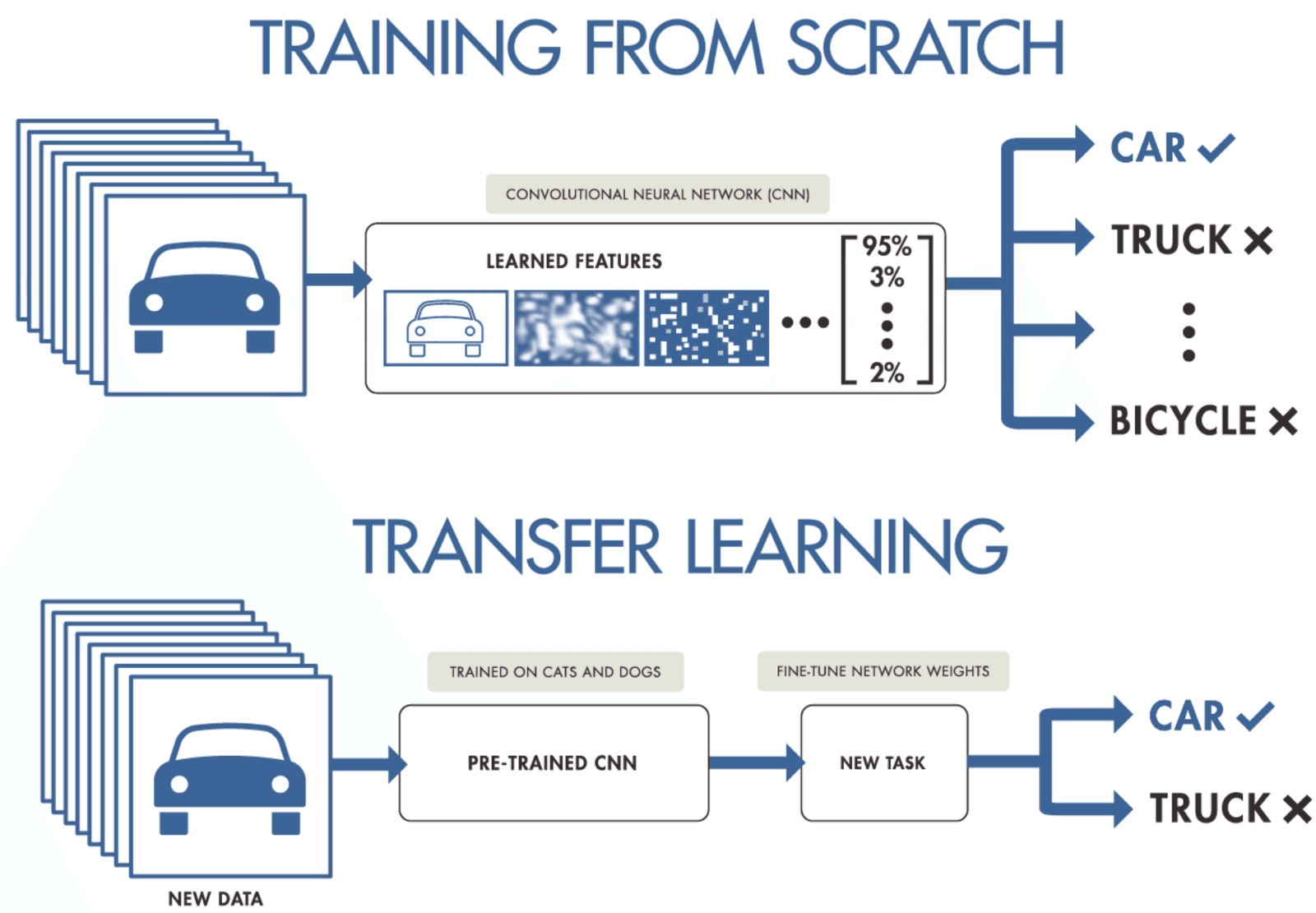
Transfer Learning oleh purnasai gudikandula
YOLO adalah algoritma deteksi objek berbasis convolutional neural network, dan dapat memberikan hasil secara real-time. Algoritma YOLO memerlukan satu kali forward pass melalui CNN untuk mengenali objek. Algoritma ini memprediksi berbagai probabilitas kelas dan bounding box sekaligus.
Model dilatih untuk mendeteksi berbagai objek, dan perusahaan menggunakan transfer learning untuk melakukan fine-tuning pada data baru untuk aplikasi modern seperti mengemudi otonom, pelestarian satwa liar, dan keamanan.
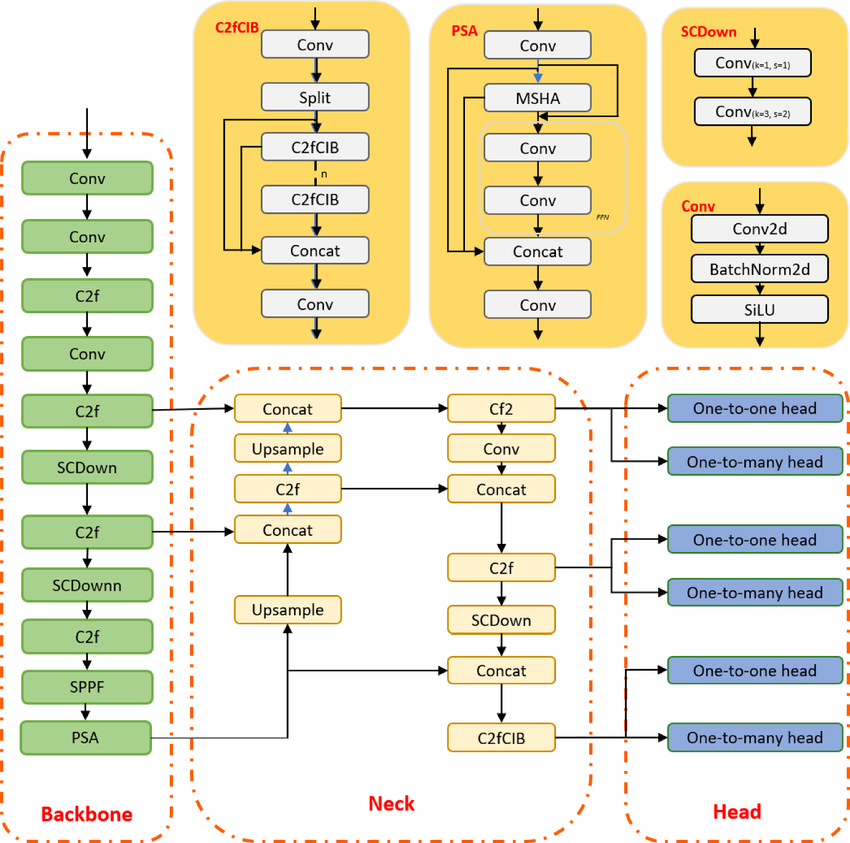
Arsitektur model YOLOv10 | researchgate
Natural Language Processing (NLP) adalah salah satu fondasi aplikasi AI modern. Harapkan pertanyaan yang menjembatani teori linguistik dan implementasi praktis, menguji kemampuan Anda memroses, menganalisis, dan mengekstrak makna dari data teks tidak terstruktur menggunakan teknik klasik dan pendekatan deep learning modern.
Syntactic Analysis, juga dikenal sebagai analisis sintaksis atau parsing, adalah analisis teks yang memberi tahu kita makna logis di balik kalimat atau bagian dari kalimat. Analisis ini berfokus pada hubungan antar kata dan struktur gramatikal kalimat. Anda juga dapat menyebutnya sebagai pemrosesan bahasa alami menggunakan kaidah tata bahasa.
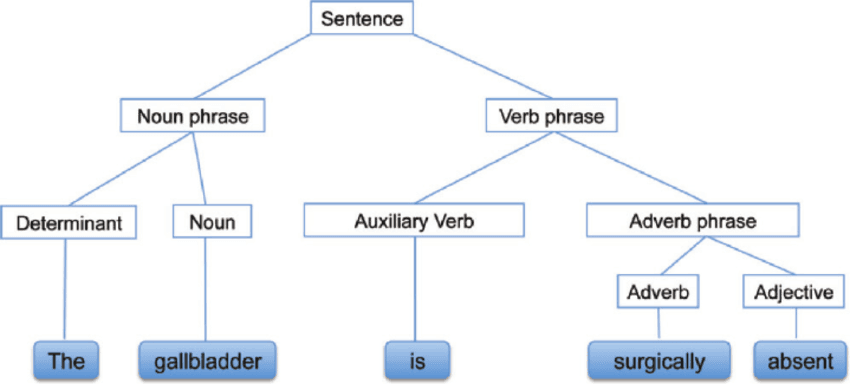
Syntactic Analysis | researchgate
Stemming dan lemmatization adalah teknik normalisasi yang digunakan untuk meminimalkan variasi struktural kata dalam sebuah kalimat.
Stemming menghapus imbuhan yang ditambahkan pada kata dan meninggalkannya dalam bentuk dasar. Misalnya, Changing menjadi Chang.
Teknik ini banyak digunakan oleh mesin telusur untuk optimasi penyimpanan. Alih-alih menyimpan semua bentuk kata, mesin hanya menyimpan stem-nya.
Lemmatization mengonversi kata ke bentuk lemma-nya. Hasilnya adalah kata akar alih-alih kata stem. Setelah lemmatization, kita mendapatkan kata yang valid dan bermakna. Misalnya, Changing menjadi Change.

Stemming vs. Lemmatization | Penulis
Mengoptimalkan transformer besar memerlukan penanganan bottleneck bandwidth memori dan komputasi:
Pelajari dasar-dasar NLP dengan menyelesaikan jalur keterampilan Natural Language Processing in Python .
Seiring LLM mendominasi lanskap AI saat ini, pewawancara memprioritaskan kandidat yang memahami cara menerapkannya secara efektif. Bagian ini berfokus pada beberapa tantangan rekayasa praktis terbesar di tahun 2026.
Context window LLM adalah jumlah maksimum teks (diukur dalam token) yang dapat dipertimbangkan model sekaligus saat menghasilkan respons, dan secara langsung membatasi seberapa banyak "memori kerja" yang dimiliki model secara efektif.
Bahkan saat context window besar menjadi lebih umum, kinerja dan biaya tidak berskala secara linear: prompt panjang meningkatkan latensi dan masih dapat menyebabkan masalah keandalan ketika informasi yang relevan terkubur di tengah konteks.
Dalam wawancara, saya akan menjawab dengan menjelaskan strategi praktis untuk tugas dokumen panjang:
Halusinasi terjadi ketika LLM menghasilkan informasi yang masuk akal namun secara faktual salah. Pada 2026, mitigasinya memerlukan pendekatan berlapis:
Ini adalah pertanyaan "trade-off" klasik. Keputusannya bergantung pada kebaruan data dan kekhususan domain:
Pertanyaan ini dibahas lebih detail di blog kami tentang RAG vs Fine-Tuning.
Reinforcement Learning (RL) menangani masalah di mana agen belajar dengan berinteraksi dengan lingkungan alih-alih dari dataset statis. Bersiaplah untuk membahas cara kerja RL dan menjelaskan konsep inti seperti kebijakan (policies).
Reinforcement learning menggunakan coba-coba untuk mencapai tujuan. Ini adalah algoritma berorientasi tujuan dan belajar dari lingkungan dengan mengambil langkah yang benar untuk memaksimalkan reward kumulatif.
Dalam reinforcement learning tipikal:
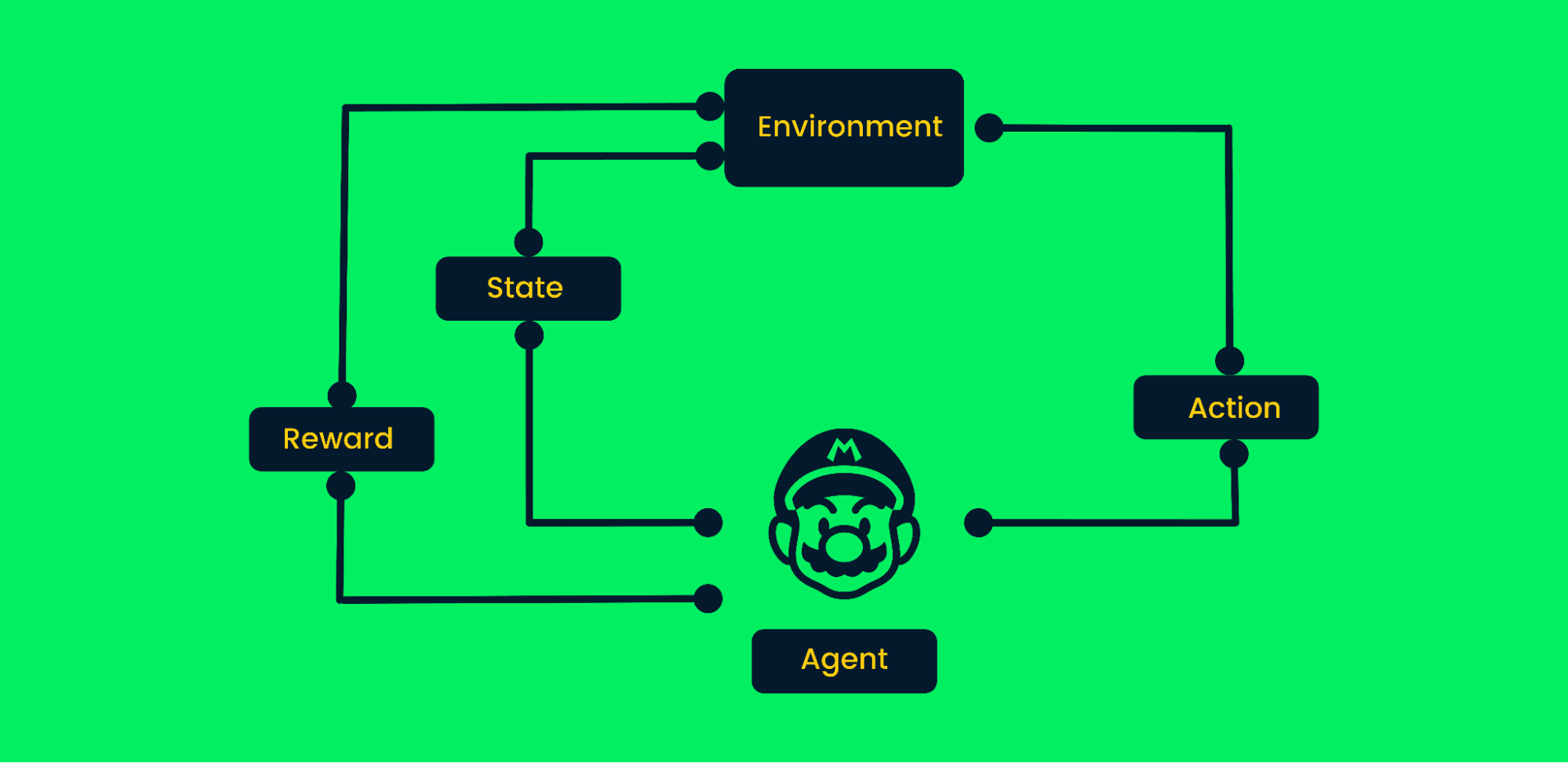
Kerangka Reinforcement Learning | Penulis
Algoritma On-Policy mengevaluasi dan meningkatkan kebijakan yang sama untuk bertindak dan memperbaruinya. Dengan kata lain, kebijakan yang digunakan untuk pembaruan dan kebijakan yang digunakan untuk bertindak adalah sama.
Target Policy == Behavior Policy
Algoritma on-policy adalah Sarsa, Monte Carlo for On-Policy, Value Iteration, dan Policy Iteration
Algoritma Off-Policy Learning sangat berbeda karena kebijakan yang diperbarui berbeda dari behavior policy. Misalnya, pada Q-learning, agen belajar dari kebijakan optimal dengan bantuan kebijakan greedy dan mengambil tindakan menggunakan kebijakan lain.
Target Policy != Behavior Policy
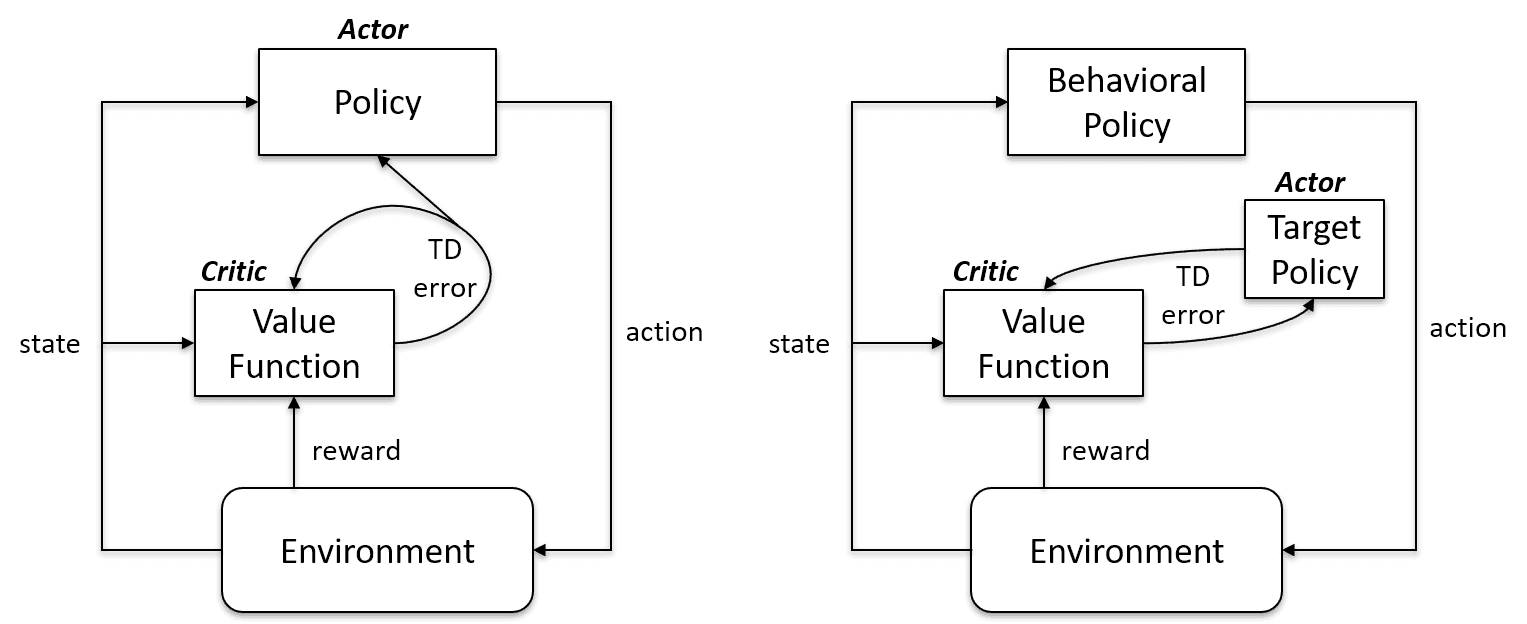
Kasus on-policy vs. off-policy | Artificial Intelligence Stack Exchange
Q learning sederhana sangat baik. Ini menyelesaikan masalah dalam skala kecil, tetapi gagal pada skala besar.
Bayangkan jika lingkungan memiliki 1000 state dan 1000 aksi per state. Kita akan memerlukan tabel Q dengan jutaan sel. Permainan catur dan Go akan memerlukan tabel yang jauh lebih besar. Di sinilah Deep Q-learning menjadi solusi.
Ia memanfaatkan neural network untuk mengaproksimasi fungsi nilai Q. Neural network menerima state sebagai input dan menghasilkan nilai Q untuk semua aksi yang mungkin.
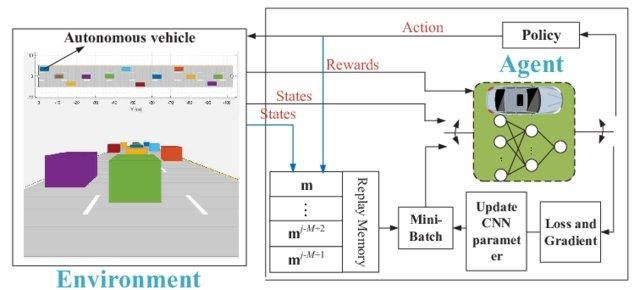
Deep Q-network untuk mengemudi otonom | researchgate
Di bawah ini, kami merangkum beberapa pertanyaan potensial yang mungkin diajukan pewawancara kepada Anda di beberapa perusahaan teknologi teratas:
Receiver operating characteristics (ROC) menunjukkan trade-off antara sensitivitas dan spesifisitas.
Kurva diplot menggunakan False positive rate (FP/(TN + FP)) dan true positive rate (TP/(TP + FN))
Luas di bawah kurva (AUC) menunjukkan kinerja model. Jika area di bawah kurva ROC adalah 0,5, maka model kita benar-benar acak. Model dengan AUC mendekati 1 adalah model yang lebih baik.
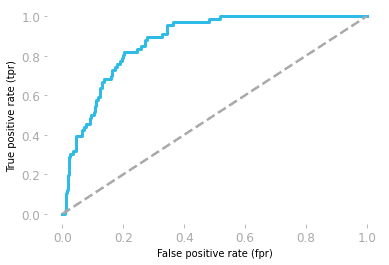
Kurva ROC oleh Hadrien Jean
Tidak seperti klasifikasi (di mana jawaban benar atau salah), GenAI sering memerlukan evaluasi manusia atau kerangka "LLM-as-a-Judge":
Untuk pengurangan dimensi, kita dapat menggunakan metode seleksi fitur atau ekstraksi fitur.
Feature selection adalah proses memilih fitur optimal dan membuang fitur yang tidak relevan. Kita menggunakan metode Filter, Wrapper, dan Embedded untuk menganalisis feature importance dan menghapus fitur yang kurang penting guna meningkatkan kinerja model.
Feature extraction mentransformasikan ruang berdimensi banyak menjadi dimensi yang lebih sedikit. Tidak ada informasi yang hilang selama proses, dan menggunakan lebih sedikit sumber daya untuk memproses data. Teknik ekstraksi yang paling umum adalah Linear Discriminant Analysis (LDA), Kernel PCA, dan Quadratic Discriminant Analysis.
Pada kasus pengklasifikasi spam, model logistic regression akan mengembalikan probabilitas. Kita bisa menggunakan probabilitas 0,8999 atau mengonversinya menjadi kelas (Spam/Bukan Spam) menggunakan threshold.
Biasanya, threshold pengklasifikasi adalah 0,5, tetapi dalam beberapa kasus, kita perlu melakukan fine-tuning untuk meningkatkan akurasi. Threshold 0,5 berarti jika probabilitas sama dengan atau di atas 0,5, maka itu spam, dan jika lebih rendah, maka bukan spam.
Untuk menemukan threshold, kita dapat menggunakan Precision-Recall curve dan ROC curve, grid search, serta dengan mengubah nilai secara manual untuk mendapatkan CV yang lebih baik.
Jadilah machine learning engineer profesional dengan menyelesaikan jalur karier Machine Learning Scientist with Python.
Linear regression digunakan untuk memahami hubungan antara fitur (X) dan target (y). Sebelum kita melatih model, kita perlu memenuhi beberapa asumsi:
Catatan: residual dalam linear regression adalah selisih antara nilai aktual dan nilai prediksi.
Selama wawancara coding, Anda akan ditanya tentang masalah machine learning, tetapi dalam beberapa kasus, mereka akan menilai keterampilan Python Anda dengan menanyakan pertanyaan coding umum. Jadilah programmer Python ahli dengan mengikuti jalur karier Python Programmer.
Membuat fungsi bigram cukup mudah. Anda perlu menggunakan dua loop dengan fungsi zip.
zip untuk membuat kombinasi kata sebelumnya dan kata berikutnyaIni cukup mudah jika Anda memecah masalah dan menggunakan fungsi zip.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Hasil:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]Fungsi aktivasi adalah transformasi non-linear dalam neural network. Kita melewatkan input melalui fungsi aktivasi sebelum meneruskannya ke lapisan berikutnya.
Nilai input bersih dapat berada di antara -inf hingga +inf, dan neuron tidak tahu cara membatasi nilai, sehingga tidak dapat menentukan pola firing. Fungsi aktivasi memutuskan apakah neuron harus diaktifkan atau tidak untuk membatasi nilai input bersih.
Jenis fungsi aktivasi yang paling umum:
Jawabannya sepenuhnya terserah Anda. Namun sebelum menjawab, Anda perlu mempertimbangkan tujuan bisnis yang ingin dicapai untuk menetapkan metrik kinerja dan bagaimana Anda akan memperoleh data.
Dalam desain sistem machine learning yang tipikal, kita:
Anda perlu memastikan fokus pada desain alih-alih teori atau arsitektur model. Pastikan untuk membahas inferensi model dan bagaimana peningkatannya akan meningkatkan pendapatan secara keseluruhan.
Juga, berikan gambaran mengapa Anda memilih metodologi tertentu dibandingkan yang lain.
Pelajari lebih lanjut tentang membangun sistem rekomendasi dengan mengikuti kursus di DataCamp.
Menyelesaikan tantangan coding dan mengasah keterampilan Python Anda akan meningkatkan peluang melewati tahap wawancara coding.
Sebelum terjun menyelesaikan masalah, Anda perlu memahami pertanyaannya. Anda cukup membuat fungsi boolean yang akan mengembalikan True jika dengan menggeser alfabet dalam String B, Anda mendapatkan String A.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueEnsemble learning digunakan untuk menggabungkan wawasan dari beberapa model machine learning guna meningkatkan akurasi dan metrik kinerja.
Metode ensemble sederhana:
Metode ensemble lanjutan:
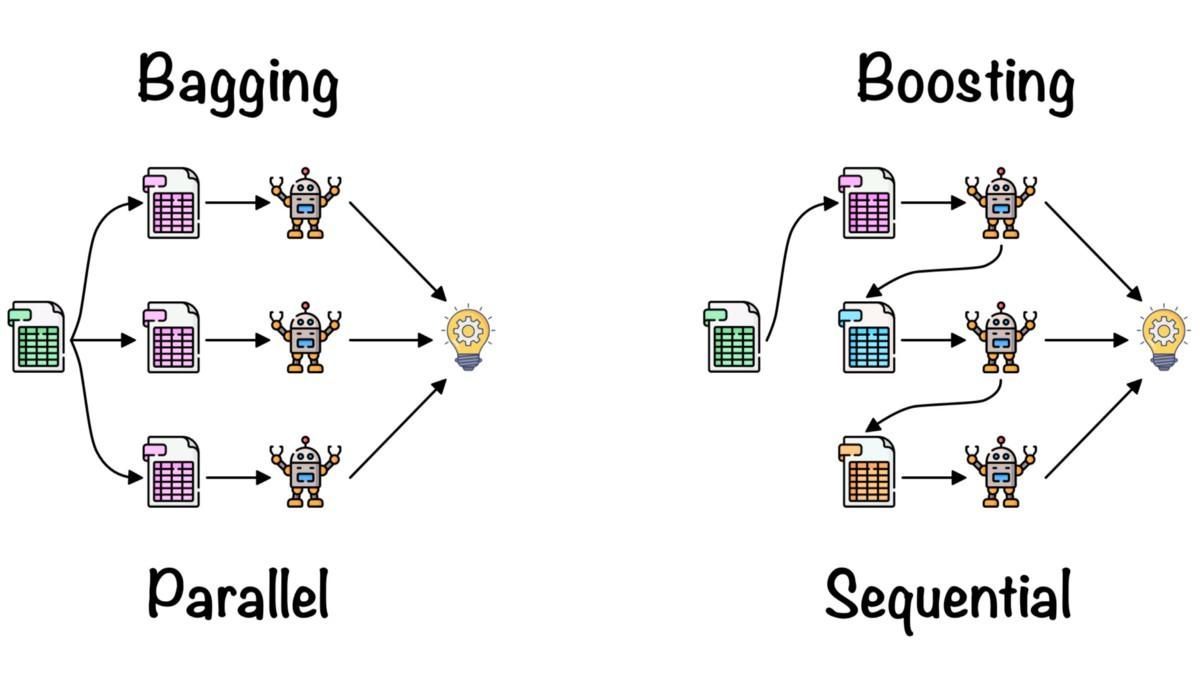
Bagging dan Boosting oleh Fernando López
Pelajari lebih lanjut tentang averaging, bagging, stacking, dan boosting dengan menyelesaikan kursus Ensemble Methods in Python.
Menutup penjelajahan kita atas pertanyaan wawancara machine learning yang esensial, jelas bahwa keberhasilan dalam wawancara jenis ini memerlukan perpaduan pengetahuan teoretis, keterampilan praktis, dan pemahaman akan tren serta teknologi terbaru di bidang ini. Dari memahami konsep dasar seperti pembelajaran semi-supervised dan pemilihan algoritma, hingga menyelami kompleksitas algoritma spesifik seperti KNN, serta menghadapi tantangan spesifik peran di NLP, computer vision, atau reinforcement learning, cakupannya luas.
Baik Anda pemula yang ingin masuk ke bidang ini maupun praktisi berpengalaman yang ingin melangkah lebih jauh, pembelajaran dan latihan berkelanjutan adalah kuncinya. DataCamp menawarkan jalur komprehensif Machine Learning Scientist with Python yang menyediakan cara terstruktur dan mendalam untuk meningkatkan keterampilan Anda.
Kursus Machine Learning
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
