Cours
Machine Learning for Finance in Python
4 h
32.9K
Les questions fondamentales concernent la terminologie, les algorithmes et les méthodologies. Les examinateurs posent ces questions afin d'évaluer les connaissances techniques du candidat.
L'apprentissage semi-supervisé est une combinaison d'apprentissage supervisé et non supervisé. L'algorithme est entraîné à partir d'un mélange de données étiquetées et non étiquetées. En général, cette méthode est utilisée lorsque nous disposons d'un ensemble de données étiquetées très restreint et d'un ensemble de données non étiquetées volumineux.
En termes simples, l'algorithme non supervisé est utilisé pour créer des clusters et, à partir des données étiquetées existantes, étiqueter le reste des données non étiquetées. Un algorithme semi-supervisé repose sur les hypothèses de continuité, de regroupement et de variété.
Il est généralement utilisé pour réduire les coûts liés à l'acquisition de données étiquetées. Par exemple, la classification des séquences protéiques, la reconnaissance vocale automatique et les véhicules autonomes.
Outre l'ensemble de données, il est nécessaire de disposer d'un cas d'utilisation commerciale ou d'exigences applicatives. Il est possible d'appliquer l'apprentissage supervisé et non supervisé aux mêmes données.
En général :
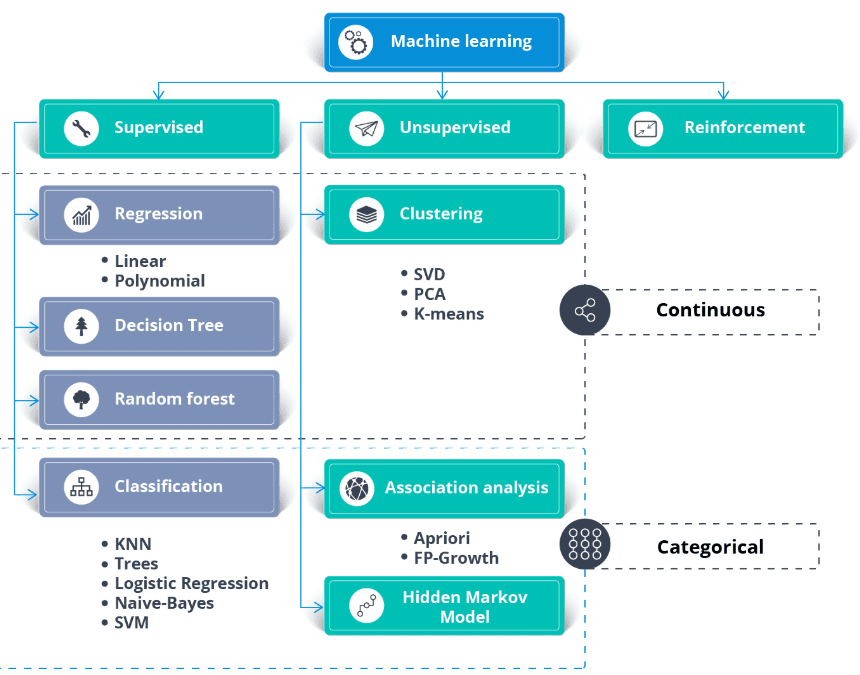
Image provenant de thecleverprogrammer
Veuillez suivre notre cours pour acquérir les bases de l'apprentissage automatique.
Le K Nearest Neighbor (KNN) est un classificateur d'apprentissage supervisé. Il utilise la proximité pour classer les étiquettes ou prédire le regroupement de points de données individuels. Nous pouvons l'utiliser pour la régression et la classification. L'algorithme KNN est non paramétrique, ce qui signifie qu'il ne repose pas sur une hypothèse sous-jacente concernant la distribution des données.
Dans le classificateur KNN :
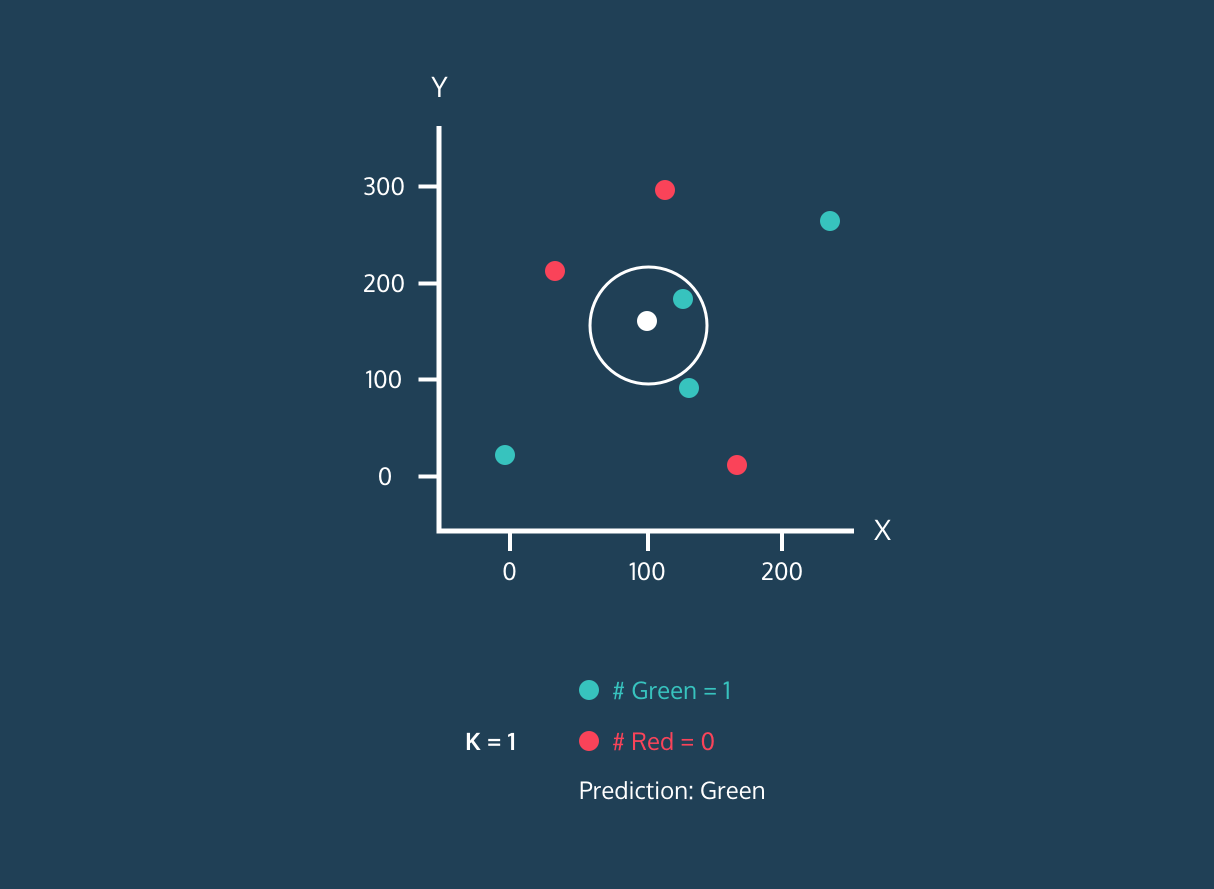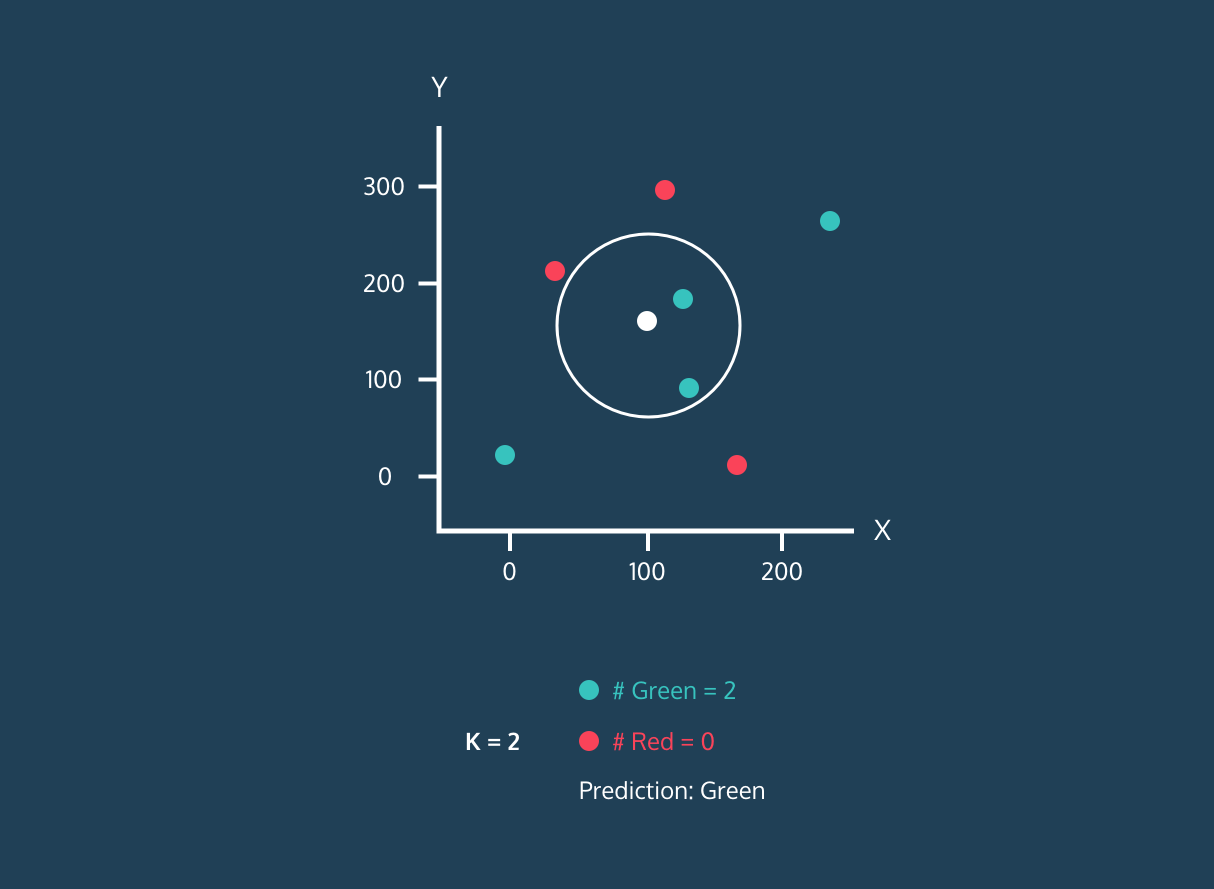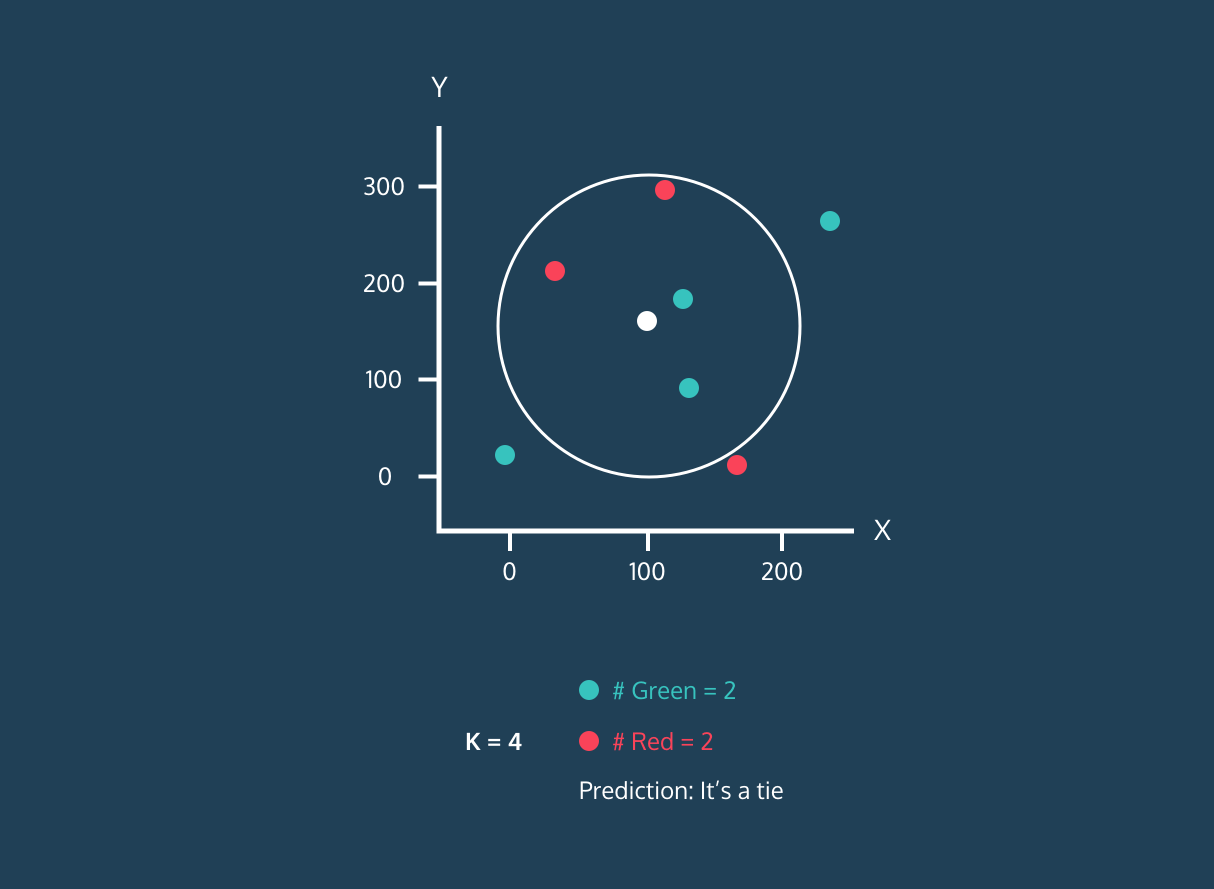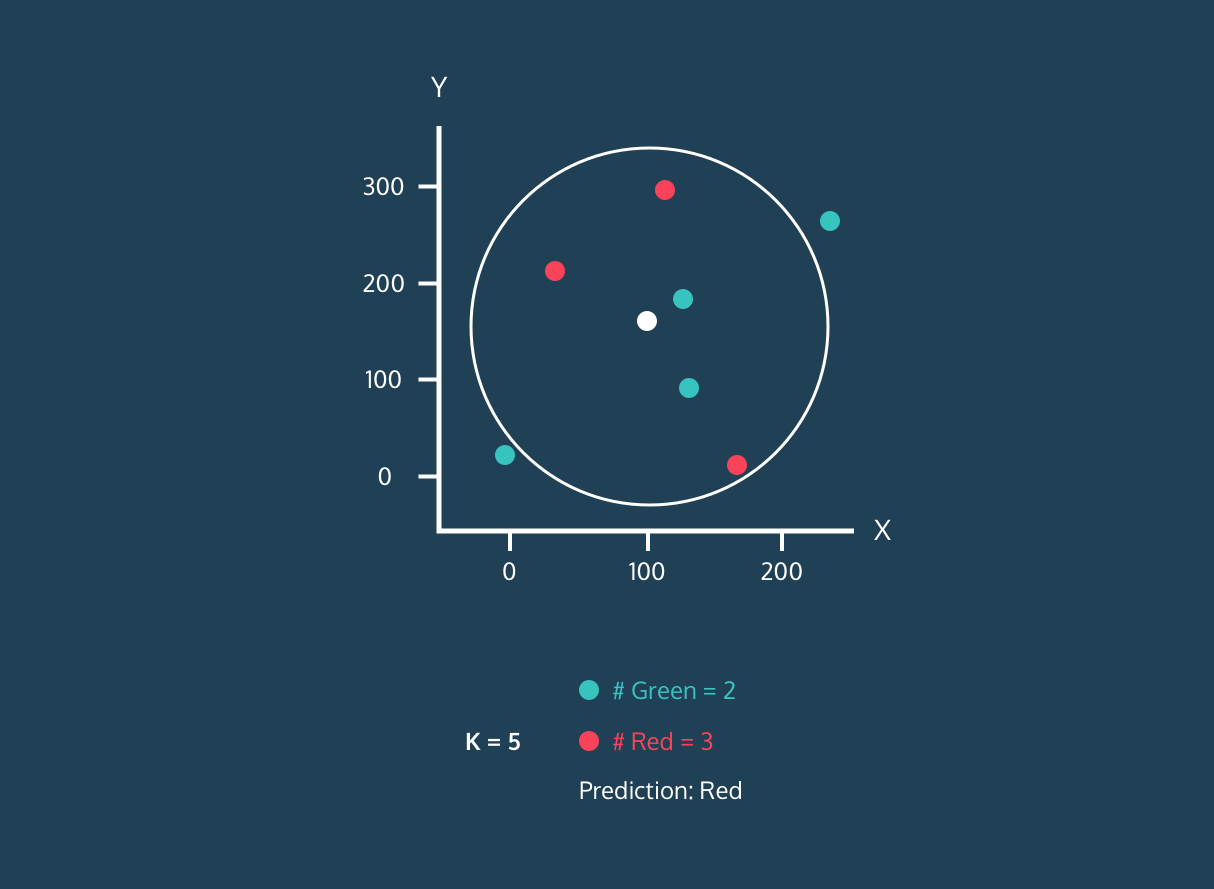
Image tirée de l'histoire du développement de Codesigner
Découvrez tout ce qu'il faut savoir sur les modèles de classification et de régression par apprentissage supervisé en suivant un cours de courte durée.
L'importance des caractéristiques fait référence aux techniques qui attribuent une note aux caractéristiques d'entrée en fonction de leur utilité pour prédire une variable cible. Il joue un rôle essentiel dans la compréhension de la structure sous-jacente des données, du comportement du modèle et dans l'amélioration de l'interprétabilité du modèle.
Il existe plusieurs méthodes pour déterminer l'importance des caractéristiques :
Il est essentiel de comprendre l'importance des caractéristiques pour optimiser les modèles, réduire le surajustement en supprimant les caractéristiques non informatives et améliorer l'interprétabilité des modèles, en particulier dans les domaines où il est crucial de comprendre le processus décisionnel du modèle.
Le surajustement se produit lorsqu'un modèle fonctionne bien sur les données d'apprentissage, mais ne parvient pas à généraliser à des données inconnues, car il a mémorisé les données d'apprentissage au lieu d'apprendre les modèles sous-jacents. Il est possible de l'éviter en :
Une matrice de confusion est un tableau utilisé pour évaluer la performance d'un modèle de classification. Il indique le nombre de vrais positifs, de vrais négatifs, de faux positifs et de faux négatifs. Il est utile pour calculer des mesures telles que l'exactitude, la précision, le rappel et le score F1.
Modèles paramétriques : Ces modèles émettent des hypothèses sur la distribution sous-jacente des données et ont un nombre fixe de paramètres (par exemple, la régression linéaire).
Modèles non paramétriques : Ces méthodes ne font aucune hypothèse sur la distribution des données et peuvent s'adapter à la complexité à mesure que de nouvelles données sont ajoutées (par exemple, K-Nearest Neighbors).
Le compromis biais-variance fait référence à l'équilibre entre la capacité d'un modèle à saisir des schémas complexes (faible biais) et sa sensibilité aux fluctuations dans les données d'apprentissage (faible variance). Un modèle performant atteint un équilibre en minimisant à la fois le biais et la variance afin d'éviter le sous-ajustement et le surajustement.
La session d'entretien technique vise davantage à évaluer vos connaissances des processus et votre capacité à gérer l'incertitude. Le responsable du recrutement posera des questions relatives à l'apprentissage automatique concernant le traitement des données, la formation et la validation des modèles, ainsi que les algorithmes avancés.
Oui. La plupart des algorithmes utilisent la distance euclidienne entre les points de données, et si la valeur des caractéristiques varie considérablement, les résultats seront très différents. Dans la plupart des cas, les valeurs aberrantes entraînent une baisse des performances des modèles d'apprentissage automatique sur l'ensemble de données de test.
Nous utilisons également la mise à l'échelle des caractéristiques afin de réduire le temps de convergence. Il faudra plus de temps à la descente de gradient pour atteindre les minima locaux lorsque les caractéristiques ne sont pas normalisées.
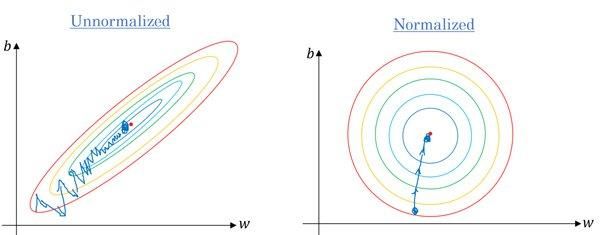
Gradient sans et avec mise à l'échelle | Quora
Les compétences en ingénierie des caractéristiques sont très recherchées. Vous pouvez acquérir toutes les connaissances nécessaires sur le sujet en suivant un cours DataCamp, tel que « Feature Engineering for Machine Learning in Python » (Ingénierie des fonctionnalités pour l'apprentissage automatique en Python).
Un biais faible se produit lorsque le modèle prédit des valeurs proches de la valeur réelle. Il reproduit l'ensemble de données d'entraînement. Le modèle ne dispose d'aucune généralisation, ce qui signifie que s'il est testé sur des données non observées, il produira des résultats peu satisfaisants.
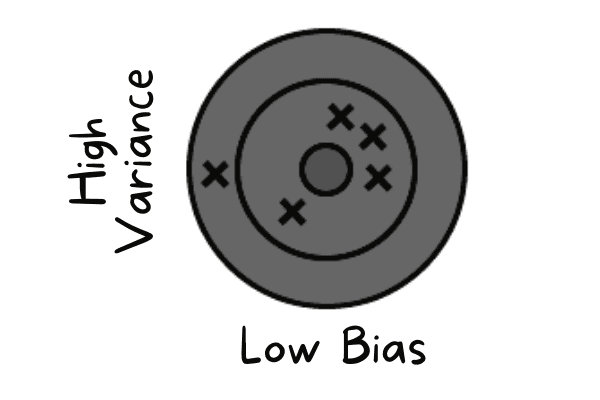
Faible biais et variance élevée | Auteur
Pour résoudre ces problèmes, nous utiliserons des algorithmes de bagging, car ils divisent un ensemble de données en sous-ensembles à l'aide d'un échantillonnage aléatoire. Ensuite, nous générons des ensembles de modèles à partir de ces échantillons à l'aide d'un algorithme unique. Ensuite, nous combinons les prédictions du modèle à l'aide d'une classification par vote ou d'une moyenne.
Pour une variance élevée, nous pouvons recourir à des techniques de régularisation. Il a pénalisé les coefficients de modèle plus élevés afin de réduire la complexité du modèle. De plus, nous pouvons sélectionner les caractéristiques les plus importantes à partir du graphique d'importance des caractéristiques et entraîner le modèle.
La dérive du modèle se produit lorsque les performances d'un modèle se dégradent au fil du temps en raison de l'évolution des données réelles par rapport aux données d'apprentissage. Il existe deux types principaux :
La validation croisée est utilisée pour évaluer de manière fiable les performances d'un modèle et éviter le surajustement. En règle générale, les techniques de validation croisée sélectionnent de manière aléatoire des échantillons à partir des données et les divisent en ensembles de données d'apprentissage et de test. Le nombre de divisions est basé sur la valeur K.
Par exemple, si K = 5, il y aura quatre plis pour l'apprentissage et un pour le test. Il sera répété cinq fois afin d'évaluer le modèle sur des plis distincts.
Nous ne pouvons pas procéder ainsi avec un ensemble de données chronologiques, car il n'est pas pertinent d'utiliser une valeur future pour prévoir une valeur passée. Il existe une dépendance temporelle entre les observations, et nous ne pouvons diviser les données que dans un seul sens, de sorte que les valeurs de l'ensemble de données de test se trouvent après l'ensemble d'apprentissage.
Le diagramme montre que la division en k parties des données chronologiques est unidirectionnelle. Les points bleus représentent l'ensemble d'apprentissage, le point rouge représente l'ensemble de test et les points blancs représentent les données non utilisées. Comme nous pouvons l'observer à chaque itération, nous progressons avec l'ensemble d'apprentissage tandis que l'ensemble de test reste en amont de l'ensemble d'apprentissage, sans être sélectionné de manière aléatoire.
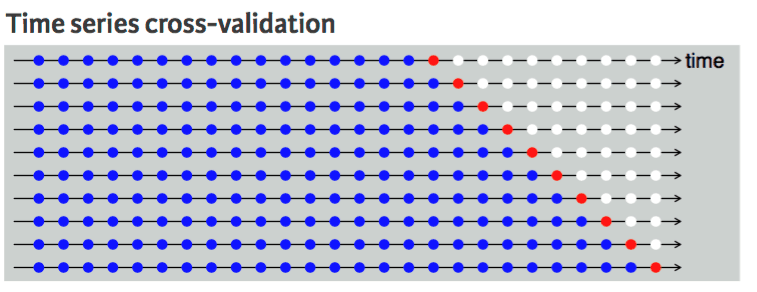
Validation croisée des séries chronologiques | Guide de programmation R pour l'analyse commerciale à l'université de Californie
Découvrez la manipulation, l'analyse, la visualisation et la modélisation des données chronologiques en suivant le cours « Time Series with Python » (Séries chronologiques avec Python).
La plupart des offres d'emploi dans le domaine de l'apprentissage automatique publiées sur LinkedIn, Glassdoor et Indeed sont spécifiques à un poste. Par conséquent, au cours de l'entretien, ils se concentreront sur des questions spécifiques au poste. Pour le poste d'ingénieur en vision par ordinateur, le responsable du recrutement se concentrera sur les questions relatives au traitement d'images.
Veuillez envisager une image de 250 x 250 et une première couche cachée entièrement connectée avec 1 000 unités cachées. Pour cette image, les caractéristiques d'entrée sont 250 X 250 X 3 = 187 500, et la matrice de poids au premier niveau caché sera une matrice de dimension 187 500 X 1000. Ces chiffres sont considérables en termes de stockage et de calcul. Pour remédier à ce problème, nous utilisons des opérations de convolution.
Apprenez le traitement d'images en suivant un cours abrégé sur le traitement d'images en Python.
Si vous ne disposez pas de suffisamment de données pour entraîner un réseau neuronal convolutif, vous pouvez recourir à l'apprentissage par transfert pour entraîner votre modèle et obtenir des résultats de pointe. Il est nécessaire de disposer d'un modèle pré-entraîné qui a été formé sur un ensemble de données général mais plus vaste. Par la suite, vous l'affinerez à l'aide de données plus récentes en entraînant les dernières couches des modèles.
L'apprentissage par transfert permet aux scientifiques des données de former des modèles à partir de données plus restreintes en utilisant moins de ressources, de puissance de calcul et de stockage. Vous pouvez facilement trouver des modèles open source pré-entraînés pour divers cas d'utilisation, et la plupart d'entre eux disposent d'une licence commerciale, ce qui signifie que vous pouvez les utiliser pour créer votre application.
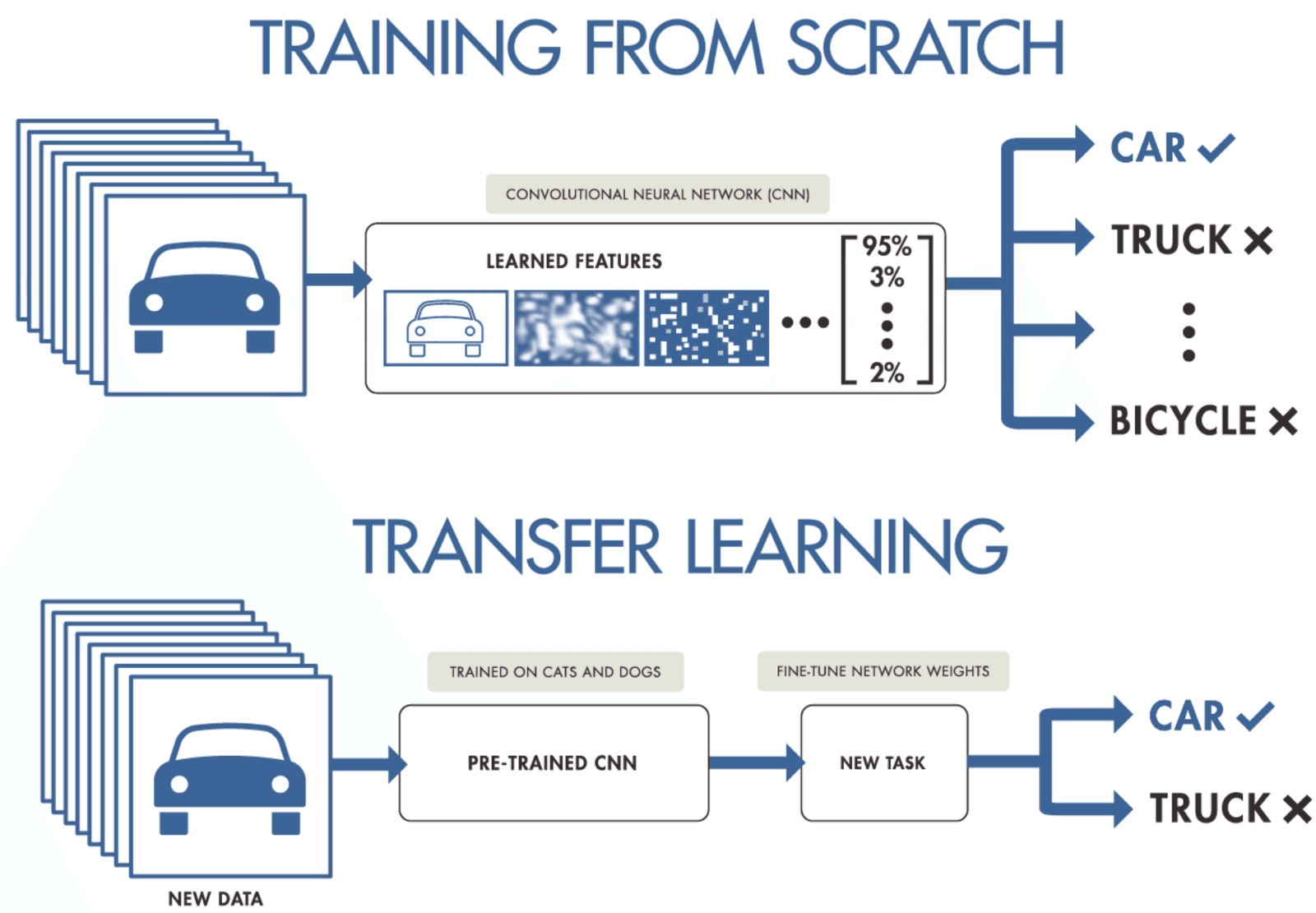
Apprentissage par transfert par Purnasai Gudikandula
YOLO est un algorithme de détection d'objets basé sur des réseaux neuronaux convolutifs, capable de fournir des résultats en temps réel. L'algorithme YOLO nécessite un seul passage en avant à travers le CNN pour reconnaître l'objet. Il prédit à la fois diverses probabilités de classe et des boîtes limites.
Le modèle a été formé pour détecter divers objets, et les entreprises utilisent l'apprentissage par transfert pour l'ajuster à de nouvelles données pour des applications modernes telles que la conduite autonome, la préservation de la faune sauvage et la sécurité.
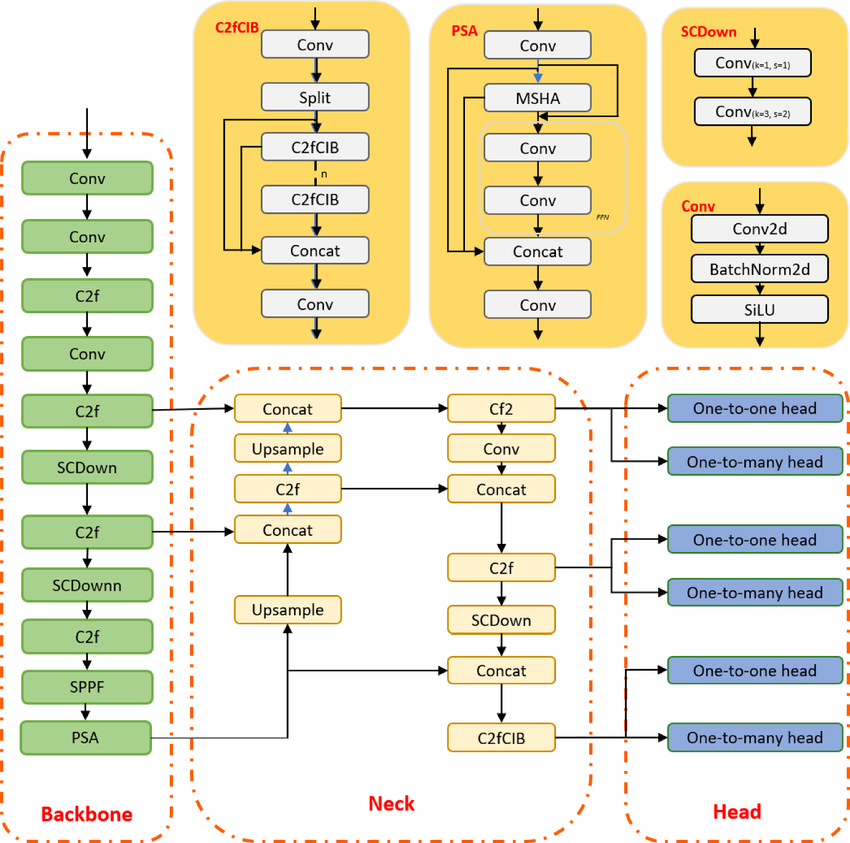
Architecture du modèle YOLOv10 | researchgate
Le traitement du langage naturel (NLP) constitue l'un des fondements des applications modernes de l'intelligence artificielle. Préparez-vous à des questions qui font le lien entre la théorie linguistique et la mise en œuvre pratique, et qui évaluent votre capacité à traiter, analyser et extraire du sens à partir de données textuelles non structurées à l'aide de techniques classiques et d'approches modernes d'apprentissage profond.
L'analyse syntaxique, également appelée analyse de la syntaxe ou parsing, est une analyse de texte qui nous permet de comprendre la signification logique d'une phrase ou d'une partie de phrase. Il se concentre sur la relation entre les mots et la structure grammaticale des phrases. On peut également dire qu'il s'agit du traitement consistant à analyser le langage naturel à l'aide de règles grammaticales.
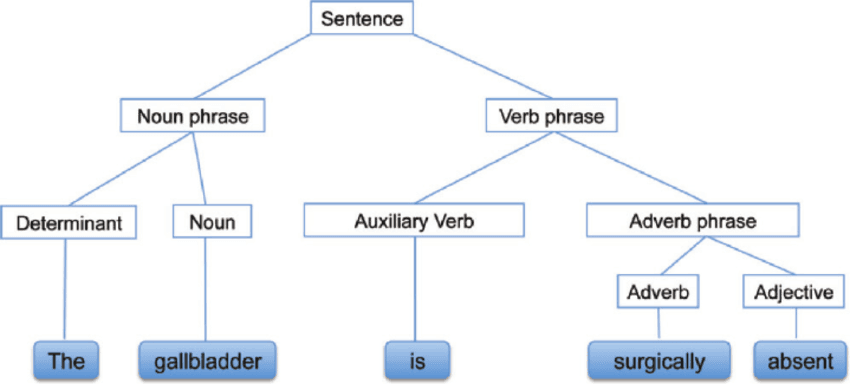
Analyse syntaxique | researchgate
La lemmatisation est une technique de normalisation utilisée pour minimiser la variation structurelle des mots dans une phrase.
La dérivation supprime les affixes ajoutés au mot et le laisse sous sa forme de base. Par exemple, passer de « Changing » à « Chang ».
Il est largement utilisé par les moteurs de recherche pour optimiser le stockage. Au lieu de stocker toutes les formes des mots, il stocke uniquement les racines.
La lemmatisation transforme le mot en sa forme lemmatisée. Le résultat est le mot racine plutôt que le mot de base. Après la lemmatisation, nous obtenons le mot valide qui a un sens. Par exemple, Changer pour évoluer.

Stemming vs. Lemmatisation | Auteur
L'optimisation des grands transformateurs nécessite de prendre en compte à la fois la bande passante mémoire et les goulots d'étranglement informatiques :
Apprenez les bases du TALN en suivant le cursus « Traitement automatique du langage naturel en Python ».
Les modèles d'apprentissage profond (LLM) occupant une place prépondérante dans le paysage actuel de l'intelligence artificielle, les recruteurs privilégient les candidats qui maîtrisent leur déploiement efficace. Cette section se concentre sur certains des plus grands défis techniques pratiques de 2026.
La fenêtre contextuelle d'un LLM correspond à la quantité maximale de texte (mesurée en tokens) que le modèle peut prendre en compte à un moment donné lors de la génération d'une réponse, et elle limite directement la quantité de « mémoire de travail » dont dispose effectivement le modèle.
Même si les fenêtres contextuelles de grande taille deviennent plus courantes, les performances et les coûts n'évoluent pas de manière linéaire : les invites longues augmentent la latence et peuvent encore entraîner des problèmes de fiabilité lorsque les informations pertinentes sont enfouies au cœur du contexte.
Lors des entretiens, je répondais en expliquant des stratégies pratiques pour les tâches impliquant des documents longs :
Les hallucinations surviennent lorsqu'un LLM génère des informations plausibles mais factuellement incorrectes. En 2026, l'atténuation nécessite une approche à plusieurs niveaux :
Il s'agit d'une question classique de compromis. La décision dépend de la fraîcheur des données et de la spécificité du domaine :
Cette question est abordée plus en détail dans notre blog consacré à la comparaison entre RAG et Fine-Tuning.
L'apprentissage par renforcement (RL) traite des problèmes dans lesquels un agent apprend en interagissant avec un environnement plutôt qu'à partir d'ensembles de données statiques. Soyez prêt à discuter du fonctionnement de RL et à expliquer des concepts fondamentaux tels que les politiques.
L'apprentissage par renforcement utilise la méthode d'essais et d'erreurs pour atteindre des objectifs. Il s'agit d'un algorithme orienté vers les objectifs qui apprend de l'environnement en prenant les mesures appropriées pour maximiser la récompense cumulative.
Dans l'apprentissage par renforcement classique :
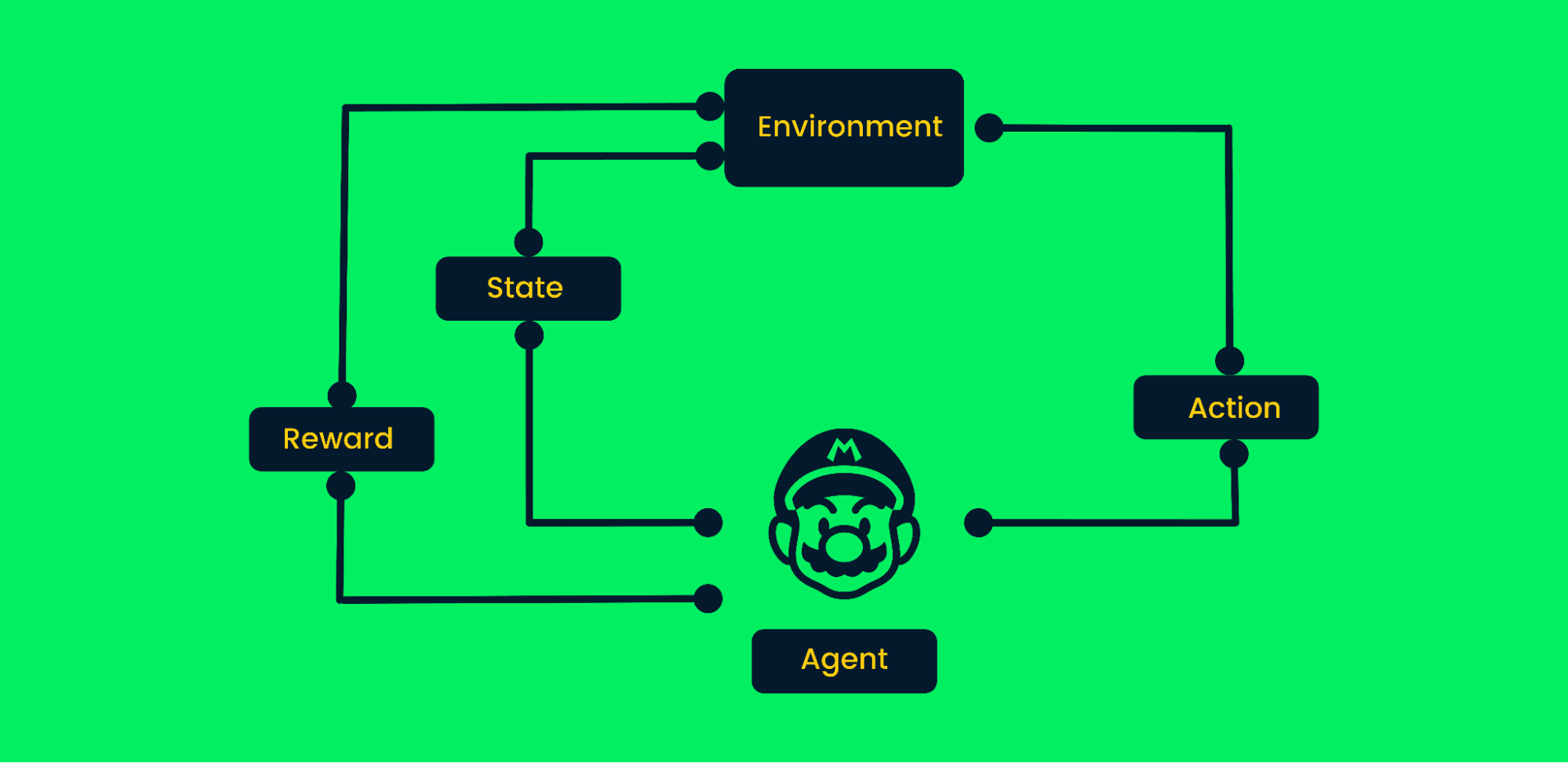
Cadre d'apprentissage par renforcement | Auteur
Les algorithmes d'apprentissage sur politique évaluent et améliorent la même politique pour agir et la mettre à jour. En d'autres termes, la politique utilisée pour la mise à jour et celle utilisée pour prendre des mesures sont identiques.
Politique cible == Politique comportementale
Les algorithmes on-policy sont Sarsa, Monte Carlo for On-Policy, Value Iteration et Policy Iteration.
Les algorithmes d'apprentissage hors politique sont totalement différents, car la politique mise à jour diffère de la politique comportementale. Par exemple, dans l'apprentissage Q, l'agent apprend à partir d'une politique optimale à l'aide d'une politique avide et agit en utilisant d'autres politiques.
Politique cible ≠ Politique comportementale
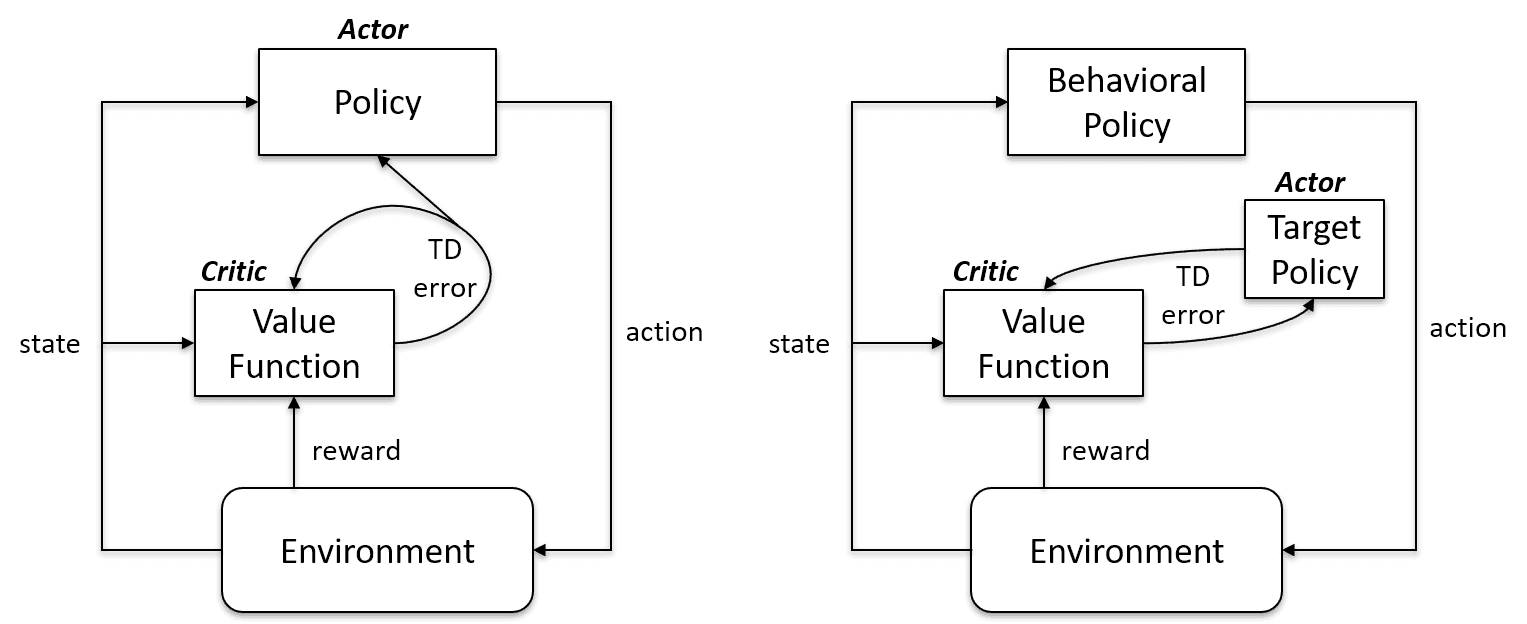
Conforme à la politique vs. Cas hors politique | Artificial Intelligence Stack Exchange
L'apprentissage simple par Q est remarquable. Cela résout le problème à petite échelle, mais à plus grande échelle, cela ne fonctionne pas.
Considérons que l'environnement comporte 1 000 états et 1 000 actions par état. Nous aurons besoin d'un tableau Q contenant des millions de cellules. Le jeu d'échecs et le jeu de go nécessitent un tableau encore plus grand. C'est là que l'apprentissage profond Q intervient.
Il utilise un réseau neuronal pour estimer la fonction de valeur Q. La recette des réseaux neuronaux indique en entrée et en sortie la valeur Q de toutes les actions possibles.
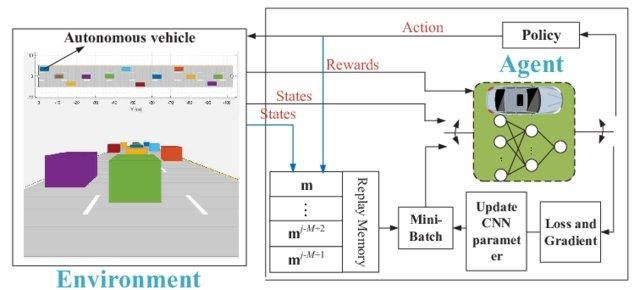
Réseau Q profond pour la conduite autonome | researchgate
Ci-dessous, nous avons répertorié quelques questions que le recruteur pourrait vous poser dans certaines des plus grandes entreprises technologiques :
Les caractéristiques de fonctionnement du récepteur (ROC) illustrent le compromis entre la sensibilité et la spécificité.
Le graphique est réalisé à l'aide du taux de faux positifs (FP/(TN + FP)) et du taux de vrais positifs (TP/(TP + FN)).
L'aire sous la courbe (AUC) indique la performance du modèle. Si l'aire sous la courbe ROC est égale à 0,5, cela signifie que notre modèle est entièrement aléatoire. Le modèle dont l'AUC est proche de 1 est le modèle le plus performant.
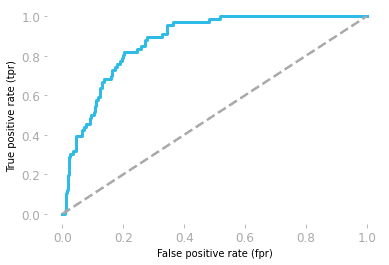
Courbe ROC par Hadrien Jean
Contrairement à la classification (où une réponse est correcte ou incorrecte), l'IA générative nécessite souvent une évaluation humaine ou des cadres « LLM-as-a-Judge » :
Pour la réduction de dimensionnalité, nous pouvons recourir à des méthodes de sélection ou d'extraction de caractéristiques.
La sélection des caractéristiques est un processus qui consiste à choisir les caractéristiques optimales et à éliminer celles qui ne sont pas pertinentes. Nous utilisons les méthodes Filter, Wrapper et Embedded pour analyser l'importance des caractéristiques et supprimer celles qui sont moins importantes afin d'améliorer les performances du modèle.
L'extraction de caractéristiques transforme l'espace à plusieurs dimensions en un espace à moins de dimensions. Aucune information n'est perdue au cours du processus, et celui-ci utilise moins de ressources pour traiter les données. Les techniques d'extraction les plus courantes sont l'analyse discriminante linéaire (LDA), l'ACP à noyau et l'analyse discriminante quadratique.
Dans le cas d'un classificateur de spam, un modèle de régression logistique renverra la probabilité. Nous utilisons soit la probabilité de 0,8999, soit nous la convertissons en classe (spam/non spam) à l'aide d'un seuil.
Généralement, le seuil d'un classificateur est de 0,5, mais dans certains cas, il est nécessaire de l'ajuster pour améliorer la précision. Le seuil de 0,5 signifie que si la probabilité est égale ou supérieure à 0,5, il s'agit de spam, et si elle est inférieure, il ne s'agit pas de spam.
Pour déterminer le seuil, nous pouvons utiliser les courbes de précision-rappel et les courbes ROC, effectuer une recherche par grille et modifier manuellement la valeur afin d'obtenir un meilleur CV.
Devenez un ingénieur professionnel en apprentissage automatique en suivant le cursus « Machine Learning Scientist with Python » (Scientifique en apprentissage automatique avec Python).
La régression linéaire est utilisée pour comprendre la relation entre les caractéristiques (X) et la cible (y). Avant de procéder à l'entraînement du modèle, il est nécessaire de respecter certaines conditions préalables :
Remarque : les résidus dans la régression linéaire correspondent à la différence entre les valeurs réelles et les valeurs prédites.
Au cours des entretiens de codage, on vous posera des questions sur les problèmes liés à l'apprentissage automatique, mais dans certains cas, on évaluera vos compétences en Python en vous posant des questions générales sur le codage. Devenez un programmeur Python expert en suivant le cursus Programmeur Python.
Créer une fonction bigramme est relativement simple. Il est nécessaire d'utiliser deux boucles avec la fonction zip.
zip pour créer une combinaison du mot précédent et du mot suivantIl est relativement simple de résoudre ce problème en le décomposant et en utilisant les fonctions zip.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Résultats :
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]La fonction d'activation est une transformation non linéaire dans les réseaux neuronaux. Nous transmettons l'entrée à la fonction d'activation avant de la transmettre à la couche suivante.
La valeur d'entrée nette peut être comprise entre -inf et +inf, et le neurone ne sait pas comment limiter les valeurs, ce qui l'empêche de déterminer le modèle de déclenchement. La fonction d'activation détermine si un neurone doit être activé ou non afin de limiter les valeurs d'entrée du réseau.
Types les plus courants de fonctions d'activation :
La réponse dépend entièrement de vous. Cependant, avant de répondre, il est nécessaire de déterminer l'objectif commercial que vous souhaitez atteindre afin de définir un indicateur de performance et la manière dont vous allez acquérir les données.
Dans une conception classique de système d'apprentissage automatique, nous :
Il est important de vous concentrer sur la conception plutôt que sur la théorie ou l'architecture du modèle. Veuillez aborder le sujet de l'inférence des modèles et expliquer comment son amélioration augmentera les revenus globaux.
Veuillez également expliquer pourquoi vous avez choisi une méthodologie plutôt qu'une autre.
Pour en savoir plus sur la création de systèmes de recommandation, nous vous invitons à suivre un cours sur DataCamp.
Résoudre des défis de codage et perfectionner vos compétences en Python augmentera vos chances de réussir l'étape de l'entretien de codage.
Avant de vous lancer dans la résolution d'un problème, il est nécessaire de bien comprendre la question. Il vous suffit de créer une fonction booléenne qui renverra True si, en décalant les lettres de la chaîne B, vous obtenez la chaîne A.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueL'apprentissage d'ensemble est utilisé pour combiner les informations issues de plusieurs modèles d'apprentissage automatique afin d'améliorer la précision et les indicateurs de performance.
Méthodes d'ensemble simples :
Méthodes d'ensemble avancées :
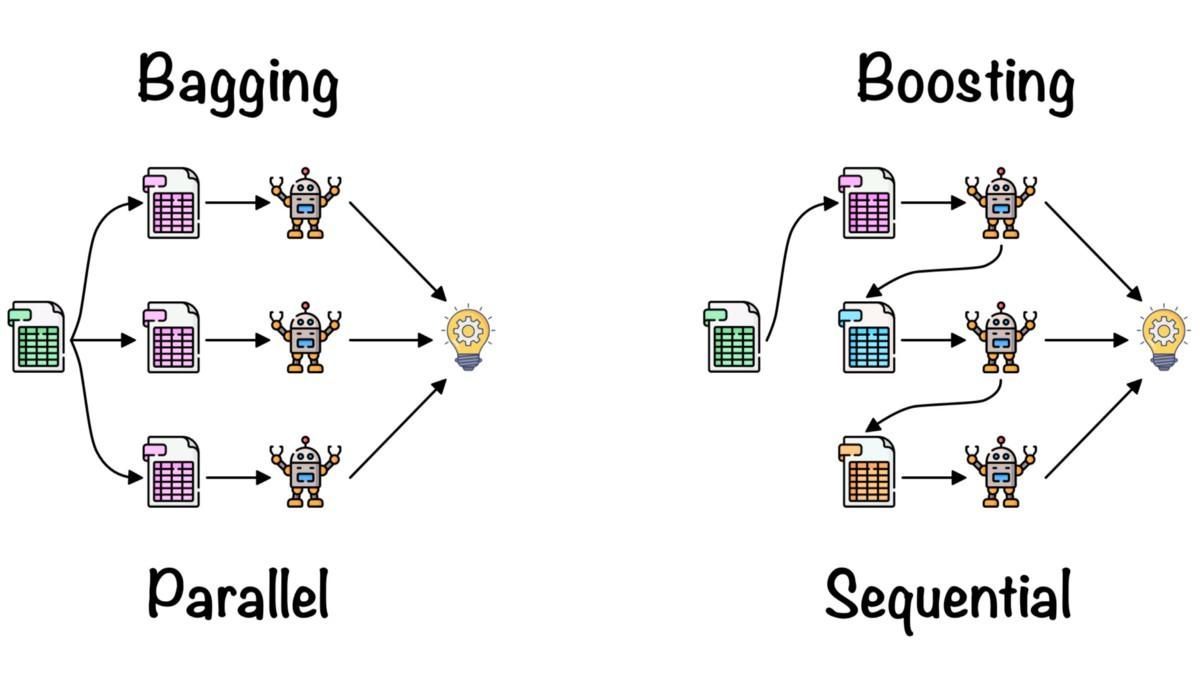
Emballage et optimisation par Fernando López
Pour en savoir plus sur le calcul de la moyenne, le bagging, le stacking et le boosting, veuillez suivre le cours Méthodes d'ensemble en Python.
Alors que nous terminons notre exploration des questions essentielles à poser lors d'un entretien d'embauche dans le domaine du machine learning, il apparaît clairement que pour réussir un tel entretien, il est nécessaire de posséder à la fois des connaissances théoriques, des compétences pratiques et une bonne connaissance des dernières tendances et technologies dans ce domaine. De la compréhension des concepts de base tels que l'apprentissage semi-supervisé et la sélection d'algorithmes, à l'étude approfondie de la complexité d'algorithmes spécifiques tels que KNN, en passant par la maîtrise des défis spécifiques à chaque rôle dans le domaine du traitement automatique du langage naturel, de la vision par ordinateur ou de l'apprentissage par renforcement, le champ d'application est vaste.
Que vous soyez débutant et souhaitiez vous lancer dans ce domaine ou praticien expérimenté cherchant à progresser, l'apprentissage et la pratique continus sont essentiels. DataCamp propose un cursus complet intitulé « Machine Learning Scientist with Python » (Scientifique en apprentissage automatique avec Python) qui vous permet d'améliorer vos compétences de manière structurée et approfondie.
Cours sur l'apprentissage automatique
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
blog
Kurtis Pykes
15 min
blog
Lynn Heidmann
Tutoriel

