Courses
Machine Learning cho Tài chính bằng Python
4 giờ
33K
Các câu hỏi cơ bản liên quan đến thuật ngữ, thuật toán và phương pháp luận. Nhà tuyển dụng đặt những câu hỏi này để đánh giá kiến thức kỹ thuật của ứng viên.
Học bán giám sát là sự kết hợp giữa học có giám sát và không giám sát. Thuật toán được huấn luyện trên dữ liệu gồm cả có nhãn và không có nhãn. Thông thường, nó được sử dụng khi chúng ta có một bộ dữ liệu có nhãn rất nhỏ và một bộ dữ liệu không nhãn rất lớn.
Nói đơn giản, thuật toán không giám sát được dùng để tạo các cụm, và bằng cách sử dụng dữ liệu đã có nhãn để gán nhãn cho phần dữ liệu còn lại chưa có nhãn. Thuật toán bán giám sát giả định các giả thuyết về tính liên tục, giả thuyết cụm và giả thuyết đa tạp (manifold).
Thông thường nó được dùng để tiết kiệm chi phí thu thập dữ liệu có nhãn. Ví dụ: phân loại chuỗi protein, nhận dạng giọng nói tự động và xe tự lái.
Ngoài bộ dữ liệu, bạn cần một bài toán kinh doanh hoặc yêu cầu ứng dụng. Bạn có thể áp dụng cả học có giám sát và không giám sát cho cùng một dữ liệu.
Nhìn chung:
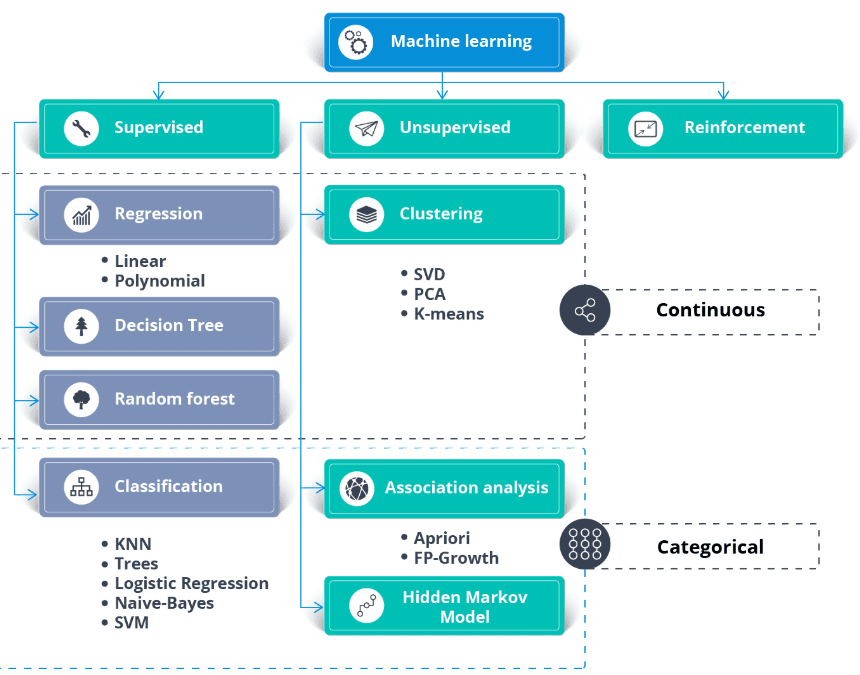
Hình ảnh từ thecleverprogrammer
Học các nguyên lý cơ bản của machine learning bằng cách tham gia khóa học của chúng tôi.
K Nearest Neighbor (KNN) là một bộ phân loại học có giám sát. Nó sử dụng độ gần để gán nhãn hoặc dự đoán nhóm của từng điểm dữ liệu. Chúng ta có thể dùng nó cho cả hồi quy và phân loại. Thuật toán KNN là phi tham số, nghĩa là nó không đưa ra giả định nền tảng về phân phối dữ liệu.
Trong bộ phân loại KNN:
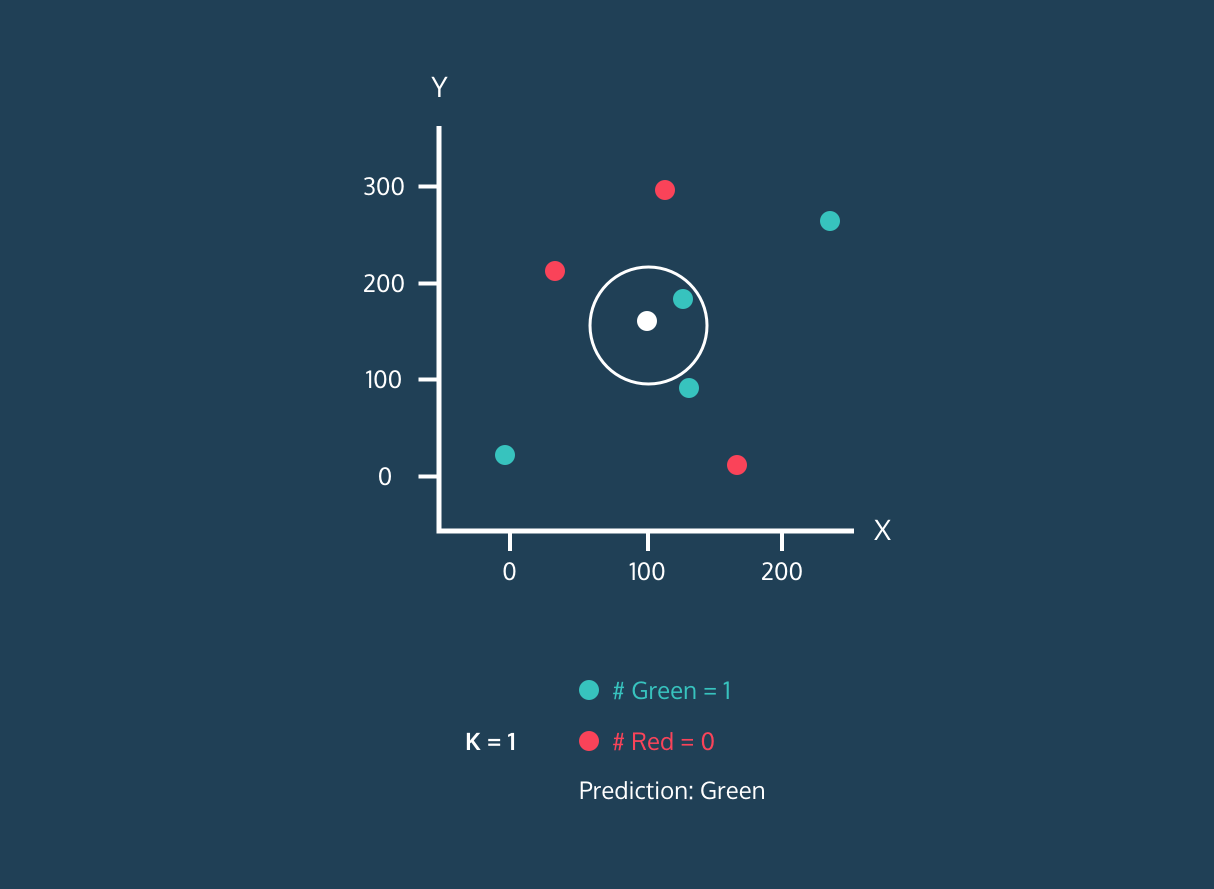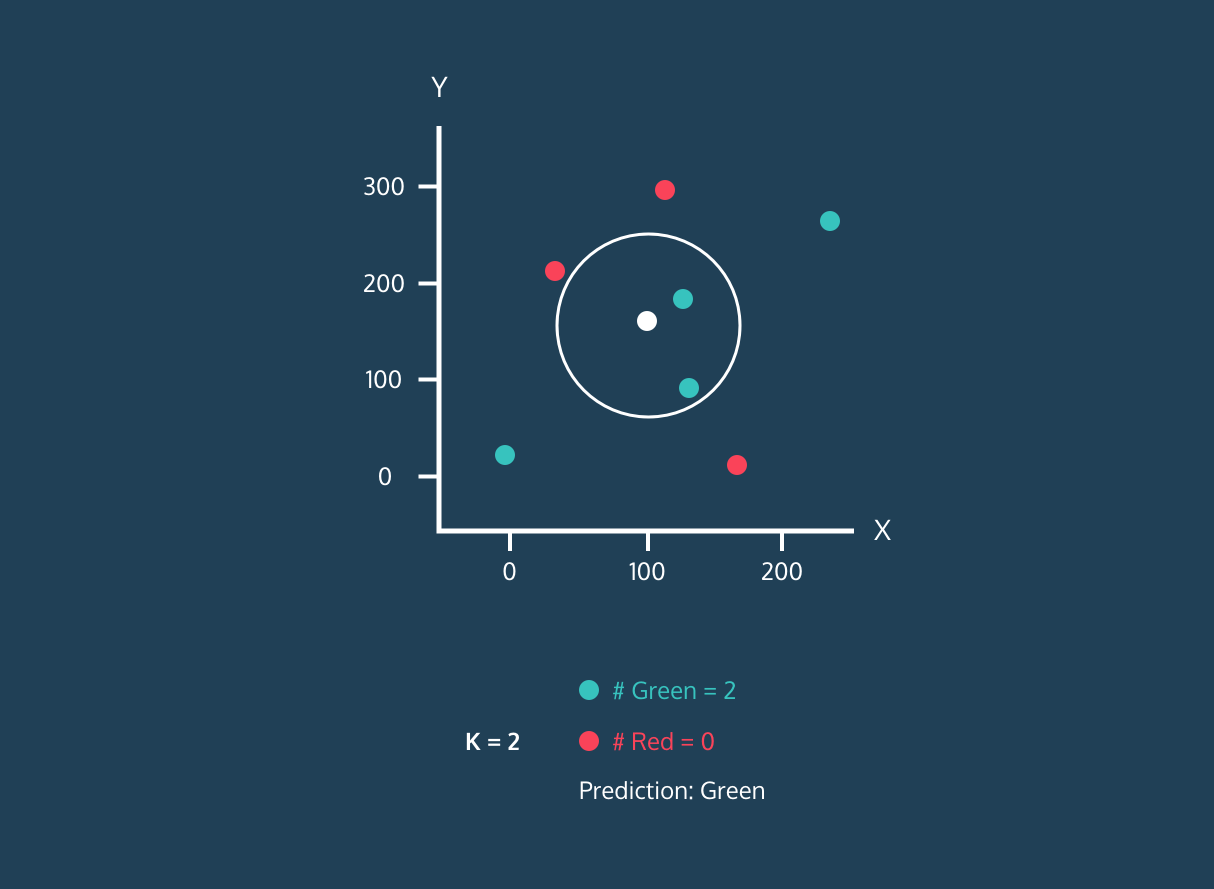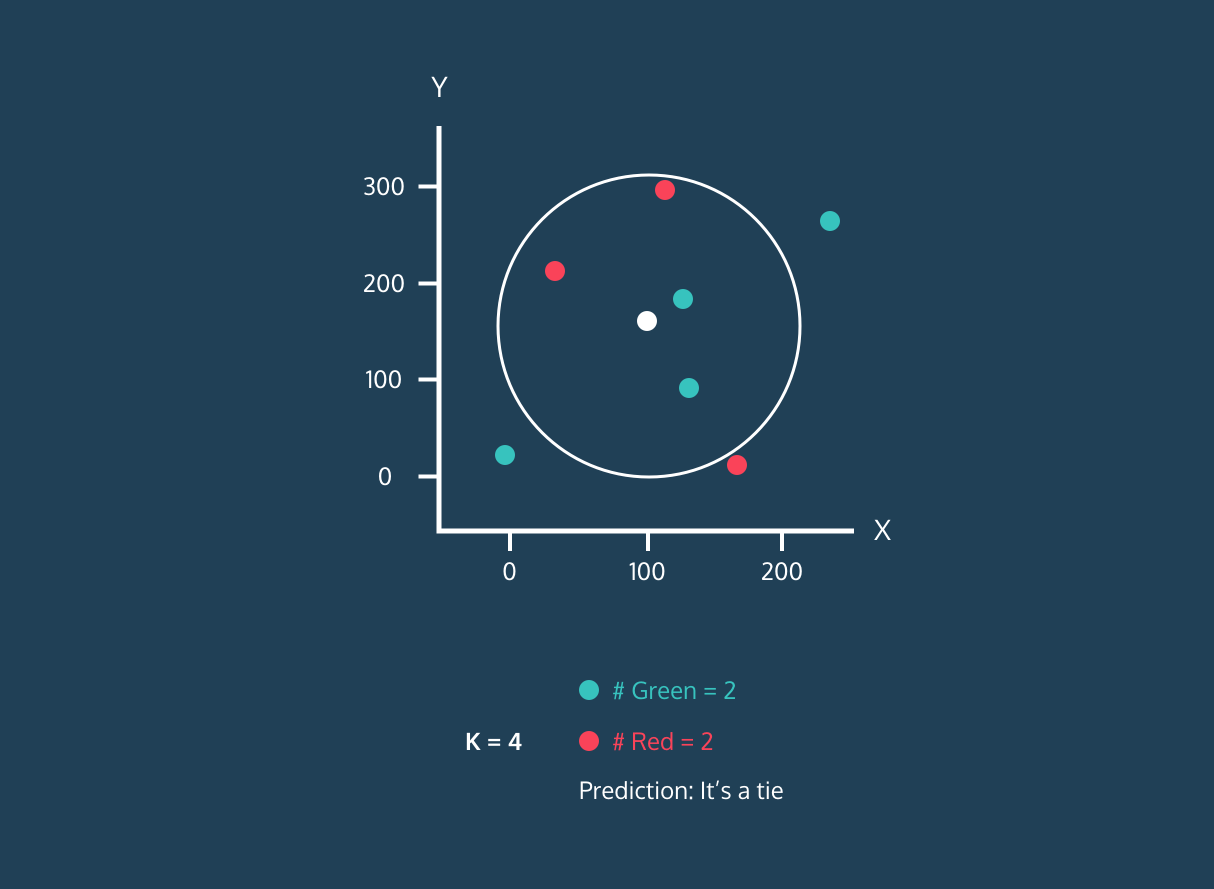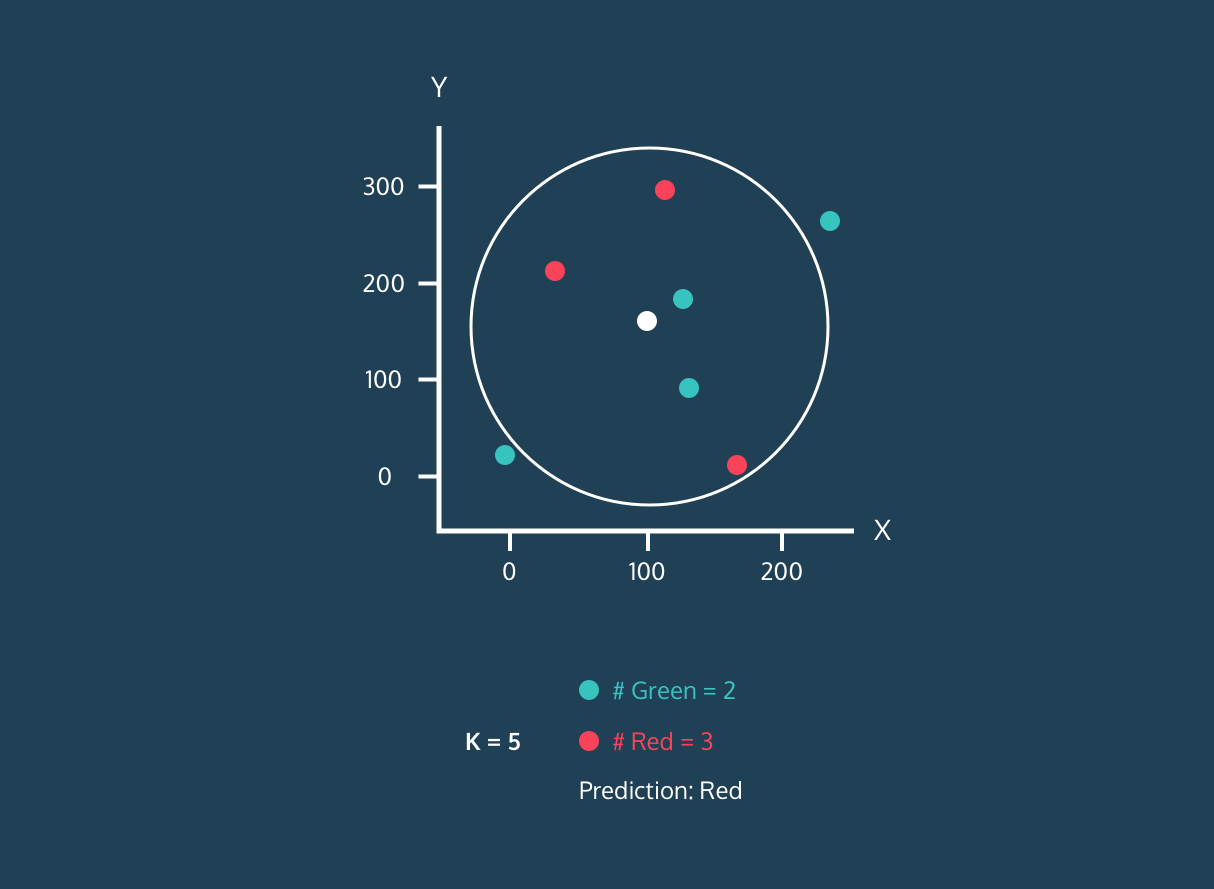
Hình ảnh từ Codesigner's Dev Story
Tìm hiểu mọi thứ về các mô hình phân loại và hồi quy trong học có giám sát qua một khóa học ngắn.
Feature importance đề cập đến các kỹ thuật gán điểm cho các đặc trưng đầu vào dựa trên mức độ hữu ích của chúng trong việc dự đoán biến mục tiêu. Nó đóng vai trò quan trọng trong việc hiểu cấu trúc nền tảng của dữ liệu, hành vi của mô hình và làm cho mô hình dễ diễn giải hơn.
Có một số phương pháp để xác định tầm quan trọng của đặc trưng:
Hiểu tầm quan trọng đặc trưng rất quan trọng để tối ưu mô hình, giảm overfitting bằng cách loại bỏ các đặc trưng không cung cấp thông tin, và cải thiện khả năng diễn giải của mô hình, đặc biệt trong các lĩnh vực yêu cầu hiểu quy trình ra quyết định của mô hình.
Overfitting xảy ra khi mô hình hoạt động tốt trên dữ liệu huấn luyện nhưng thất bại trong việc tổng quát hóa cho dữ liệu chưa thấy vì nó ghi nhớ dữ liệu huấn luyện thay vì học các mẫu nền tảng. Có thể tránh bằng cách:
Ma trận nhầm lẫn là bảng dùng để đánh giá hiệu suất của mô hình phân loại. Nó hiển thị số lượng dự đoán đúng dương, đúng âm, sai dương và sai âm. Hữu ích để tính các chỉ số như độ chính xác, độ chính xác (precision), độ bao phủ (recall) và điểm F1.
Mô hình tham số: Đưa ra giả định về phân phối nền tảng của dữ liệu và có số lượng tham số cố định (ví dụ, Hồi quy tuyến tính).
Mô hình phi tham số: Không giả định phân phối dữ liệu và có thể thích nghi với độ phức tạp khi có thêm dữ liệu (ví dụ, K-Nearest Neighbors).
Đánh đổi bias-variance đề cập đến cân bằng giữa khả năng mô hình nắm bắt các mẫu phức tạp (bias thấp) và độ nhạy với biến động trong dữ liệu huấn luyện (variance thấp). Một mô hình tốt đạt cân bằng bằng cách giảm thiểu cả bias và variance để tránh underfitting và overfitting.
Phiên phỏng vấn kỹ thuật tập trung nhiều hơn vào việc đánh giá kiến thức của bạn về quy trình và mức độ bạn sẵn sàng xử lý sự bất định. Nhà tuyển dụng sẽ hỏi các câu hỏi về xử lý dữ liệu, huấn luyện và xác thực mô hình, cũng như các thuật toán nâng cao.
Đúng. Hầu hết thuật toán sử dụng khoảng cách Euclid giữa các điểm dữ liệu, và nếu giá trị đặc trưng khác biệt rất lớn, kết quả sẽ bị sai lệch đáng kể. Trong nhiều trường hợp, ngoại lệ (outliers) khiến mô hình machine learning hoạt động kém hơn trên tập kiểm tra.
Chúng ta cũng dùng chuẩn hóa đặc trưng để giảm thời gian hội tụ. Sẽ mất lâu hơn để gradient descent đạt cực tiểu cục bộ khi các đặc trưng không được chuẩn hóa.
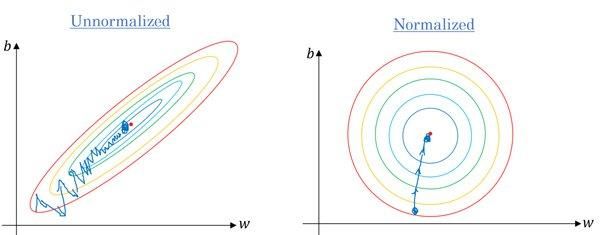
Gradient không và có chuẩn hóa | Quora
Kỹ năng kỹ thuật đặc trưng (feature engineering) đang rất được săn đón. Bạn có thể học mọi thứ về chủ đề này qua khóa học của DataCamp, như Feature Engineering for Machine Learning in Python.
Bias thấp xảy ra khi mô hình dự đoán gần với giá trị thực. Nó đang bắt chước tập huấn luyện. Mô hình không có khả năng tổng quát hóa, nghĩa là nếu kiểm tra trên dữ liệu chưa thấy, kết quả sẽ kém.
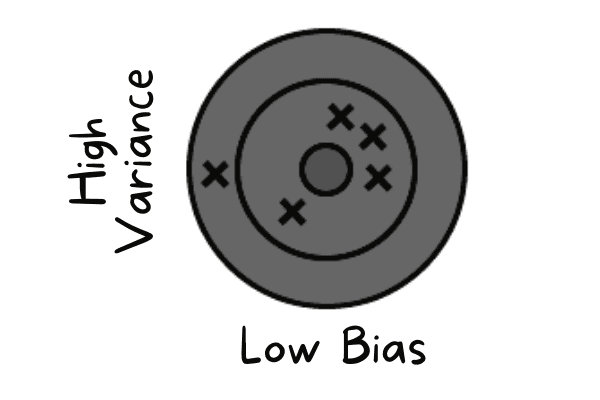
Bias thấp và variance cao | Tác giả
Để khắc phục, chúng ta dùng các thuật toán bagging vì chúng chia bộ dữ liệu thành các tập con bằng lấy mẫu ngẫu nhiên. Sau đó, tạo các bộ mô hình từ các mẫu này với một thuật toán duy nhất. Cuối cùng, kết hợp dự đoán của mô hình bằng bỏ phiếu (voting) hoặc trung bình.
Với variance cao, có thể dùng kỹ thuật regularization. Nó phạt các hệ số lớn của mô hình để giảm độ phức tạp. Ngoài ra, ta có thể chọn các đặc trưng hàng đầu từ biểu đồ tầm quan trọng đặc trưng và huấn luyện lại mô hình.
Model drift xảy ra khi hiệu suất mô hình suy giảm theo thời gian vì dữ liệu thực tế thay đổi so với dữ liệu huấn luyện. Có hai loại chính:
Cross-validation được dùng để đánh giá hiệu suất mô hình một cách vững chắc và ngăn overfitting. Thông thường, các kỹ thuật cross-validation chọn mẫu ngẫu nhiên từ dữ liệu và chia thành tập huấn luyện và kiểm tra. Số lần chia dựa trên giá trị K.
Ví dụ, nếu K = 5, sẽ có bốn fold cho huấn luyện và một cho kiểm tra. Quá trình lặp lại năm lần để đo hiệu suất mô hình trên các fold riêng biệt.
Ta không thể làm vậy với dữ liệu chuỗi thời gian vì không hợp lý khi dùng giá trị tương lai để dự báo quá khứ. Có phụ thuộc theo thời gian giữa các quan sát, và ta chỉ có thể chia dữ liệu theo một chiều sao cho các giá trị của tập kiểm tra nằm sau tập huấn luyện.
Sơ đồ cho thấy chia k-fold trong chuỗi thời gian là một chiều. Các điểm xanh là tập huấn luyện, đỏ là tập kiểm tra, và trắng là dữ liệu không dùng. Có thể thấy mỗi lần lặp, ta tiến dần về phía trước với tập huấn luyện trong khi tập kiểm tra luôn nằm phía trước, không được chọn ngẫu nhiên.
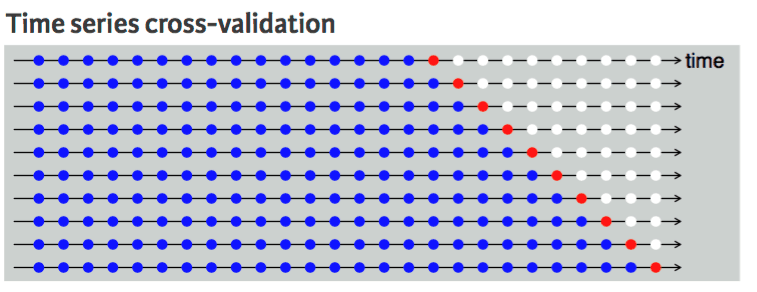
Cross validation chuỗi thời gian | UC Business Analytics R Programming Guide
Tìm hiểu thao tác, phân tích, trực quan hóa và mô hình hóa dữ liệu chuỗi thời gian bằng cách tham gia Time Series with Python.
Hầu hết các công việc machine learning trên LinkedIn, Glassdoor và Indeed đều theo vai trò cụ thể. Vì vậy, trong phỏng vấn, họ sẽ tập trung vào các câu hỏi theo vai trò. Với vai trò kỹ sư thị giác máy tính, nhà tuyển dụng sẽ tập trung vào các câu hỏi xử lý ảnh.
Hãy hình dung một ảnh 250 X 250 và một lớp ẩn fully-connected đầu tiên với 1000 đơn vị ẩn. Với ảnh này, số đặc trưng đầu vào là 250 X 250 X 3 = 187.500, và ma trận trọng số ở lớp ẩn đầu tiên sẽ là ma trận kích thước 187.500 X 1000. Những con số này rất lớn cho lưu trữ và tính toán, và để khắc phục, chúng ta dùng các phép tích chập (convolution).
Học xử lý ảnh qua khóa học ngắn Image Processing in Python
Nếu bạn không có đủ dữ liệu để huấn luyện mạng nơ-ron tích chập, bạn có thể dùng học chuyển giao (transfer learning) để huấn luyện mô hình và đạt kết quả hiện đại. Bạn cần một mô hình tiền huấn luyện trên một bộ dữ liệu tổng quát nhưng lớn hơn. Sau đó, bạn tinh chỉnh nó trên dữ liệu mới bằng cách huấn luyện các lớp cuối của mô hình.
Học chuyển giao cho phép nhà khoa học dữ liệu huấn luyện mô hình trên dữ liệu nhỏ hơn với ít tài nguyên, tính toán và lưu trữ hơn. Bạn có thể dễ dàng tìm các mô hình tiền huấn luyện mã nguồn mở cho nhiều trường hợp sử dụng, và hầu hết có giấy phép thương mại, nghĩa là bạn có thể dùng để tạo ứng dụng của mình.
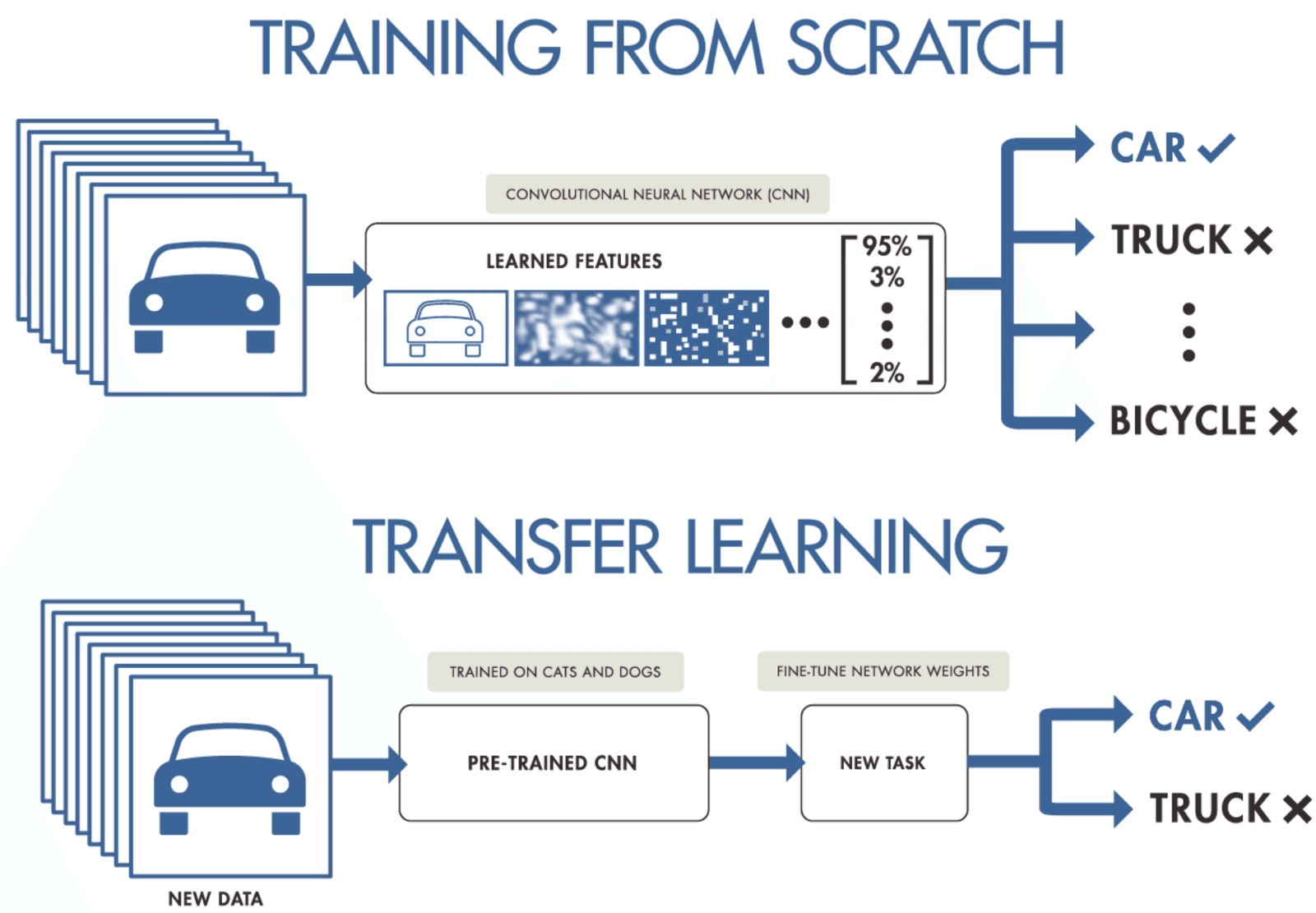
Transfer Learning bởi purnasai gudikandula
YOLO là một thuật toán phát hiện vật thể dựa trên mạng nơ-ron tích chập, có thể cho kết quả theo thời gian thực. Thuật toán YOLO chỉ cần một lần lan truyền xuôi qua CNN để nhận diện vật thể. Nó dự đoán cả xác suất của nhiều lớp và các hộp biên.
Mô hình được huấn luyện để phát hiện nhiều vật thể, và các công ty đang dùng học chuyển giao để tinh chỉnh nó trên dữ liệu mới cho các ứng dụng hiện đại như lái xe tự hành, bảo tồn động vật hoang dã và an ninh.
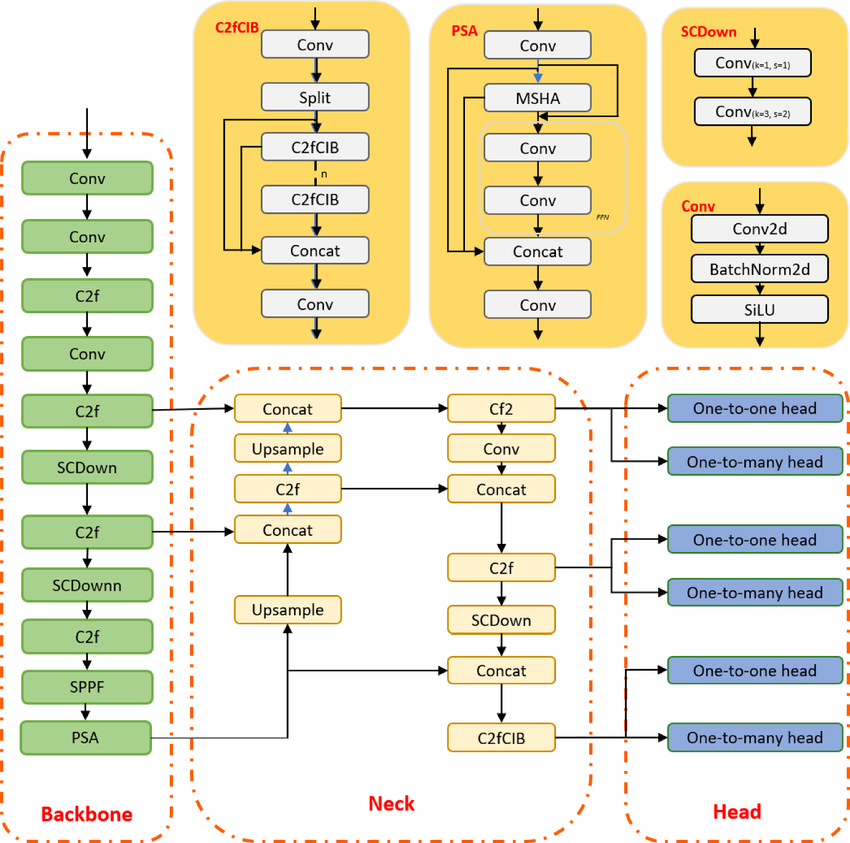
Kiến trúc mô hình YOLOv10 | researchgate
Xử lý ngôn ngữ tự nhiên (NLP) là một trong những nền tảng của các ứng dụng AI hiện đại. Hãy kỳ vọng những câu hỏi nối liền lý thuyết ngôn ngữ học và triển khai thực tiễn, kiểm tra khả năng xử lý, phân tích và trích xuất ý nghĩa từ dữ liệu văn bản phi cấu trúc bằng cả kỹ thuật cổ điển và phương pháp học sâu hiện đại.
Phân tích cú pháp, còn gọi là phân tích cú pháp hoặc Parsing, là phân tích văn bản giúp ta hiểu nghĩa logic đằng sau câu hoặc một phần câu. Nó tập trung vào mối quan hệ giữa các từ và cấu trúc ngữ pháp của câu. Bạn cũng có thể hiểu đó là việc xử lý ngôn ngữ tự nhiên bằng cách sử dụng các quy tắc ngữ pháp.
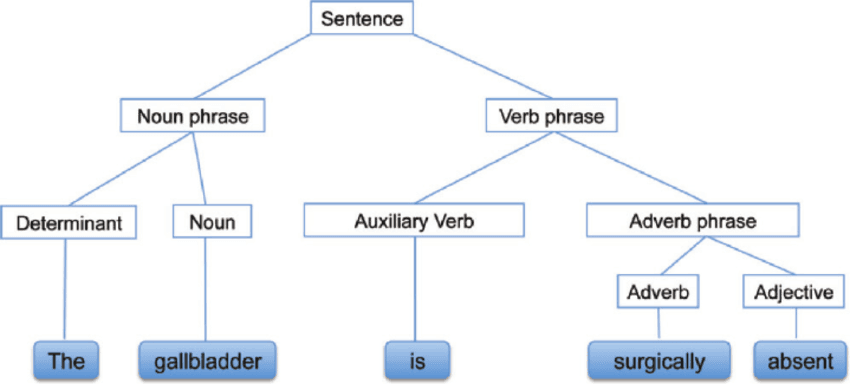
Phân tích cú pháp | researchgate
Stemming và lemmatization là các kỹ thuật chuẩn hóa dùng để giảm thiểu sự biến đổi về hình thái của từ trong câu.
Stemming loại bỏ các phụ tố gắn vào từ và để lại dạng gốc. Ví dụ, Changing thành Chang.
Nó được công cụ tìm kiếm dùng rộng rãi để tối ưu lưu trữ. Thay vì lưu tất cả các dạng của từ, chỉ lưu phần gốc (stem).
Lemmatization chuyển từ về dạng lemma. Kết quả là từ gốc (root word) thay vì stem. Sau lemmatization, ta nhận được từ hợp lệ có nghĩa. Ví dụ, Changing thành Change.

Stemming vs. Lemmatization | Tác giả
Tối ưu các mô hình transformer lớn đòi hỏi xử lý cả nút thắt băng thông bộ nhớ và tính toán:
Học các kiến thức cơ bản về NLP bằng cách hoàn thành lộ trình kỹ năng Natural Language Processing in Python .
Khi LLM thống trị bức tranh AI hiện tại, nhà tuyển dụng ưu tiên các ứng viên hiểu cách triển khai hiệu quả. Phần này tập trung vào một số thách thức kỹ thuật thực tiễn lớn nhất của năm 2026.
Cửa sổ ngữ cảnh của LLM là lượng văn bản tối đa (tính bằng token) mà mô hình có thể xem xét tại một thời điểm khi tạo phản hồi, và nó trực tiếp giới hạn lượng "bộ nhớ làm việc" mà mô hình thực sự có.
Ngay cả khi cửa sổ ngữ cảnh lớn trở nên phổ biến, hiệu suất và chi phí không tỉ lệ tuyến tính: prompt dài làm tăng độ trễ và vẫn có thể dẫn đến vấn đề độ tin cậy khi thông tin liên quan bị chôn sâu ở giữa ngữ cảnh.
Trong phỏng vấn, tôi sẽ trả lời bằng cách giải thích các chiến lược thực tiễn cho các tác vụ tài liệu dài:
Ảo giác xảy ra khi LLM tạo ra thông tin có vẻ hợp lý nhưng sai sự thật. Năm 2026, giảm thiểu đòi hỏi cách tiếp cận nhiều lớp:
Đây là câu hỏi về "đánh đổi" kinh điển. Quyết định phụ thuộc vào độ cập nhật dữ liệu và tính chuyên biệt miền:
Câu hỏi này được bàn luận chi tiết hơn trong blog của chúng tôi về RAG vs Fine-Tuning.
Reinforcement Learning (RL) giải quyết các bài toán nơi tác tử học bằng cách tương tác với môi trường thay vì từ các bộ dữ liệu tĩnh. Hãy sẵn sàng thảo luận cách RL hoạt động và giải thích các khái niệm cốt lõi như chính sách (policy).
Học tăng cường sử dụng thử và sai để đạt mục tiêu. Đây là thuật toán định hướng mục tiêu và học từ môi trường bằng cách thực hiện các bước đúng nhằm tối đa hóa phần thưởng tích lũy.
Trong học tăng cường điển hình:
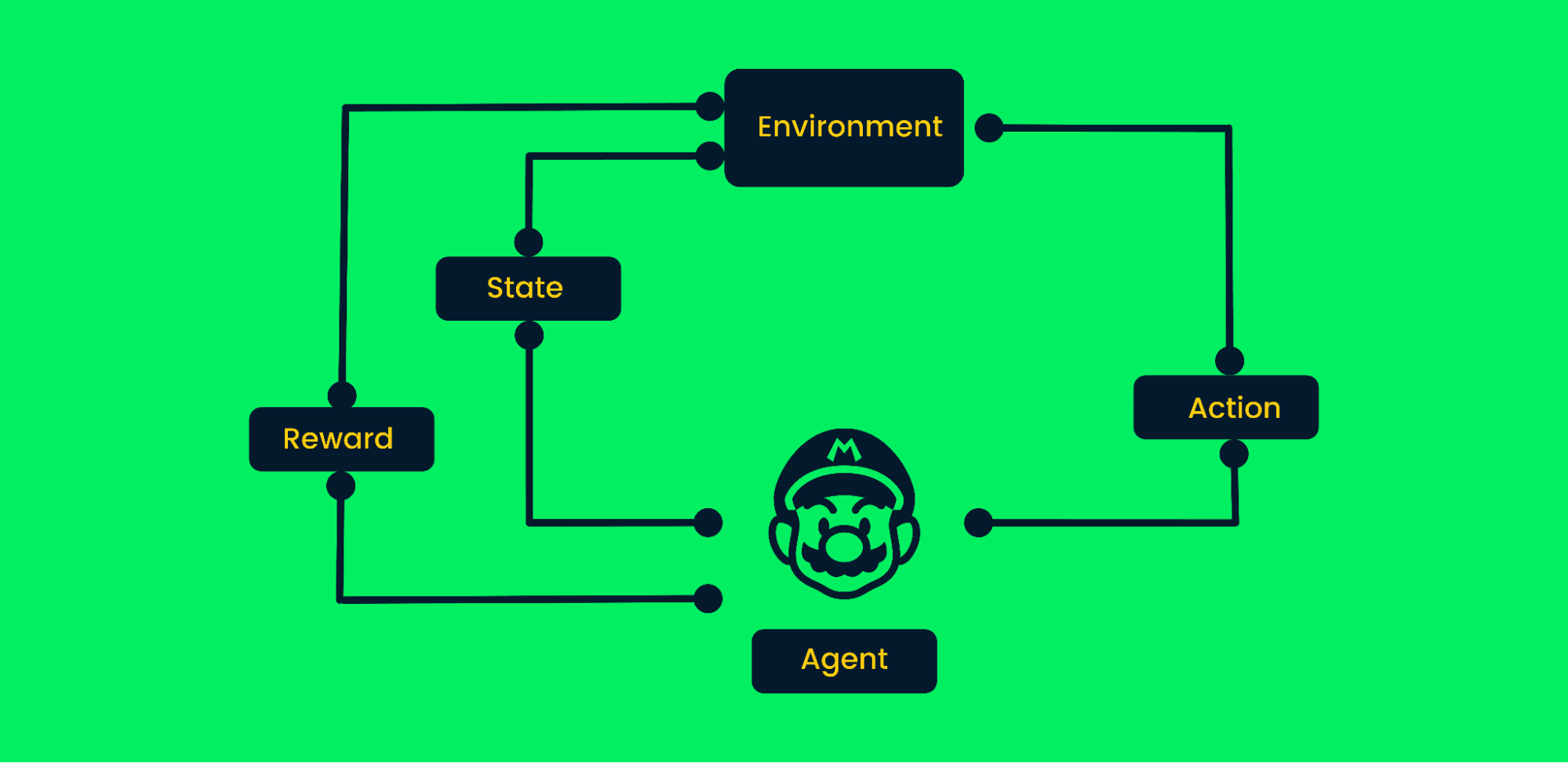
Khung Reinforcement Learning | Tác giả
Thuật toán On-Policy đánh giá và cải thiện cùng một chính sách để hành động và cập nhật nó. Nói cách khác, chính sách dùng để cập nhật và chính sách dùng để hành động là như nhau.
Target Policy == Behavior Policy
Các thuật toán on-policy gồm Sarsa, Monte Carlo for On-Policy, Value Iteration và Policy Iteration
Thuật toán Off-Policy hoàn toàn khác vì chính sách được cập nhật khác với chính sách hành vi. Ví dụ, trong Q-learning, tác tử học từ một chính sách tối ưu với sự hỗ trợ của chính sách tham lam (greedy) và thực hiện hành động bằng các chính sách khác.
Target Policy != Behavior Policy
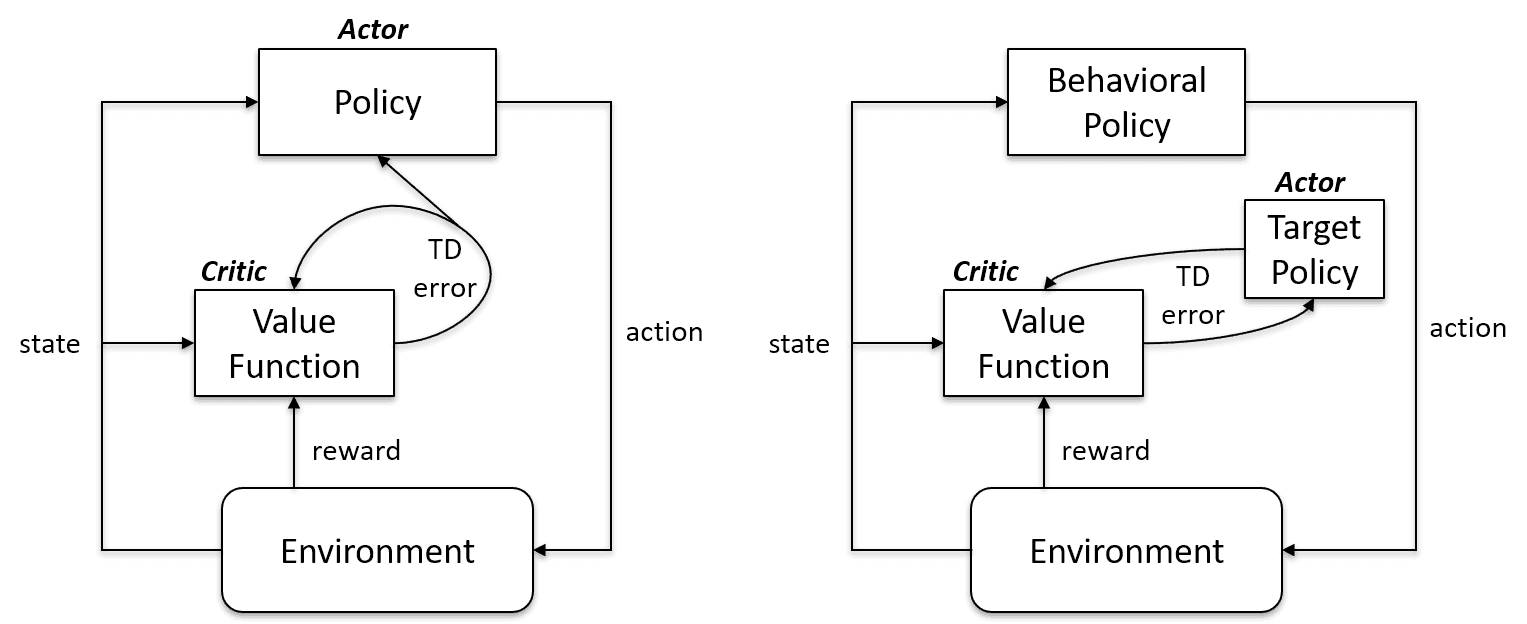
On-policy vs. Off-policy | Artificial Intelligence Stack Exchange
Q-learning đơn giản rất tốt. Nó giải quyết bài toán ở quy mô nhỏ, nhưng ở quy mô lớn thì thất bại.
Hãy tưởng tượng môi trường có 1000 trạng thái và 1000 hành động mỗi trạng thái. Chúng ta sẽ cần một bảng Q có hàng triệu ô. Trò chơi cờ vua và cờ vây còn cần bảng lớn hơn nữa. Đây là lúc Deep Q-learning ra tay cứu nguy.
Nó sử dụng mạng nơ-ron để xấp xỉ hàm giá trị Q. Mạng nơ-ron nhận trạng thái làm đầu vào và xuất ra Q-value của tất cả hành động khả dĩ.
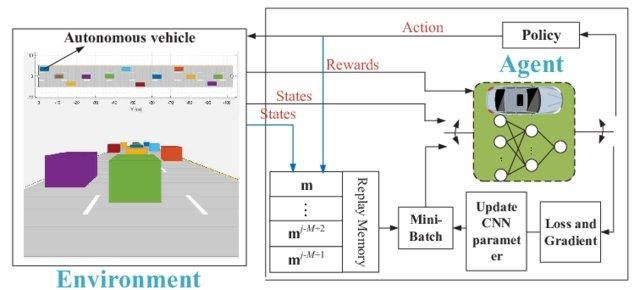
Mạng Q sâu cho lái xe tự động | researchgate
Dưới đây, chúng tôi đã liệt kê một số câu hỏi tiềm năng mà nhà phỏng vấn có thể hỏi bạn tại các công ty công nghệ hàng đầu:
Đường đặc trưng hoạt động của bộ thu (ROC) thể hiện sự đánh đổi giữa độ nhạy (sensitivity) và độ đặc hiệu (specificity).
Đường cong được vẽ bằng tỷ lệ sai dương (FP/(TN + FP)) và tỷ lệ đúng dương (TP/(TP + FN))
Diện tích dưới đường cong (AUC) thể hiện hiệu suất mô hình. Nếu AUC bằng 0,5, mô hình là hoàn toàn ngẫu nhiên. Mô hình có AUC gần 1 là mô hình tốt hơn.
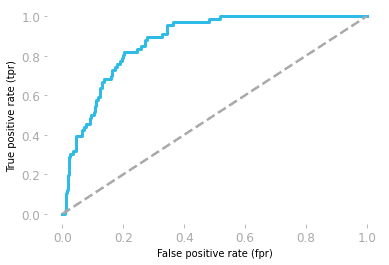
Đường cong ROC bởi Hadrien Jean
Không giống phân loại (nơi câu trả lời đúng hoặc sai), GenAI thường cần đánh giá của con người hoặc khuôn khổ "LLM-as-a-Judge":
Để giảm chiều dữ liệu, ta có thể dùng chọn đặc trưng (feature selection) hoặc trích xuất đặc trưng (feature extraction).
Feature selection là quá trình chọn các đặc trưng tối ưu và loại bỏ các đặc trưng không liên quan. Ta dùng các phương pháp Filter, Wrapper và Embedded để phân tích tầm quan trọng đặc trưng và loại bỏ các đặc trưng kém quan trọng nhằm cải thiện hiệu suất mô hình.
Feature extraction biến đổi không gian nhiều chiều thành ít chiều hơn. Không mất thông tin trong quá trình và dùng ít tài nguyên hơn để xử lý dữ liệu. Các kỹ thuật trích xuất phổ biến nhất là Phân tích biệt tuyến tính (LDA), Kernel PCA và Phân tích biệt bậc hai.
Trong trường hợp bộ phân loại spam, mô hình hồi quy logistic sẽ trả về xác suất. Chúng ta có thể dùng trực tiếp xác suất như 0,8999 hoặc chuyển thành lớp (Spam/Không Spam) bằng ngưỡng.
Thông thường, ngưỡng của bộ phân loại là 0,5, nhưng trong một số trường hợp, cần tinh chỉnh để cải thiện độ chính xác. Ngưỡng 0,5 nghĩa là nếu xác suất bằng hoặc lớn hơn 0,5 thì là spam, còn thấp hơn thì không phải spam.
Để tìm ngưỡng, ta có thể dùng đường cong Precision-Recall và ROC, grid search, và thay đổi thủ công để có CV tốt hơn.
Trở thành kỹ sư machine learning chuyên nghiệp bằng cách hoàn thành lộ trình nghề nghiệp Machine Learning Scientist with Python.
Hồi quy tuyến tính được dùng để hiểu mối quan hệ giữa đặc trưng (X) và mục tiêu (y). Trước khi huấn luyện mô hình, ta cần thỏa một vài giả định:
Lưu ý: phần dư trong hồi quy tuyến tính là chênh lệch giữa giá trị thực và dự đoán.
Trong các buổi phỏng vấn code, bạn sẽ được hỏi về các bài toán machine learning, nhưng đôi khi họ sẽ đánh giá kỹ năng Python bằng những câu hỏi lập trình chung. Trở thành lập trình viên Python xuất sắc bằng cách tham gia lộ trình nghề nghiệp Python Programmer.
Tạo một hàm bigram khá đơn giản. Bạn cần dùng hai vòng lặp với hàm zip.
zip để tạo tổ hợp từ trước và từ sauRất dễ nếu bạn chia nhỏ bài toán và dùng zip.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Kết quả:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]Hàm kích hoạt là một phép biến đổi phi tuyến trong mạng nơ-ron. Chúng ta đưa đầu vào qua hàm kích hoạt trước khi truyền tới lớp tiếp theo.
Giá trị đầu vào thuần có thể nằm từ -vô cực đến +vô cực, và neuron không biết cách chặn giá trị, do đó không thể quyết định mẫu kích hoạt. Hàm kích hoạt quyết định neuron có nên được kích hoạt hay không để chặn các giá trị đầu vào thuần.
Các loại hàm kích hoạt phổ biến:
Câu trả lời hoàn toàn tùy bạn. Nhưng trước khi trả lời, bạn cần cân nhắc mục tiêu kinh doanh muốn đạt để đặt ra chỉ số hiệu suất và cách bạn sẽ thu thập dữ liệu.
Trong thiết kế hệ thống machine learning điển hình, chúng ta:
Bạn cần đảm bảo tập trung vào thiết kế hơn là lý thuyết hoặc kiến trúc mô hình. Hãy nói về suy luận mô hình (inference) và cách cải thiện nó sẽ tăng doanh thu tổng thể.
Đồng thời, đưa ra tổng quan vì sao bạn chọn phương pháp này thay vì phương pháp khác.
Tìm hiểu thêm về xây dựng hệ thống gợi ý bằng cách tham gia một khóa học trên DataCamp.
Giải bài toán lập trình và rèn kỹ năng Python sẽ cải thiện cơ hội vượt qua vòng phỏng vấn code.
Trước khi lao vào giải, bạn cần hiểu đề bài. Bạn chỉ cần tạo một hàm boolean trả về True nếu bằng cách dịch chuyển các ký tự trong Chuỗi B, bạn nhận được Chuỗi A.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueEnsemble learning được dùng để kết hợp hiểu biết của nhiều mô hình machine learning nhằm cải thiện độ chính xác và các chỉ số hiệu suất.
Các phương pháp ensemble đơn giản:
Các phương pháp ensemble nâng cao:
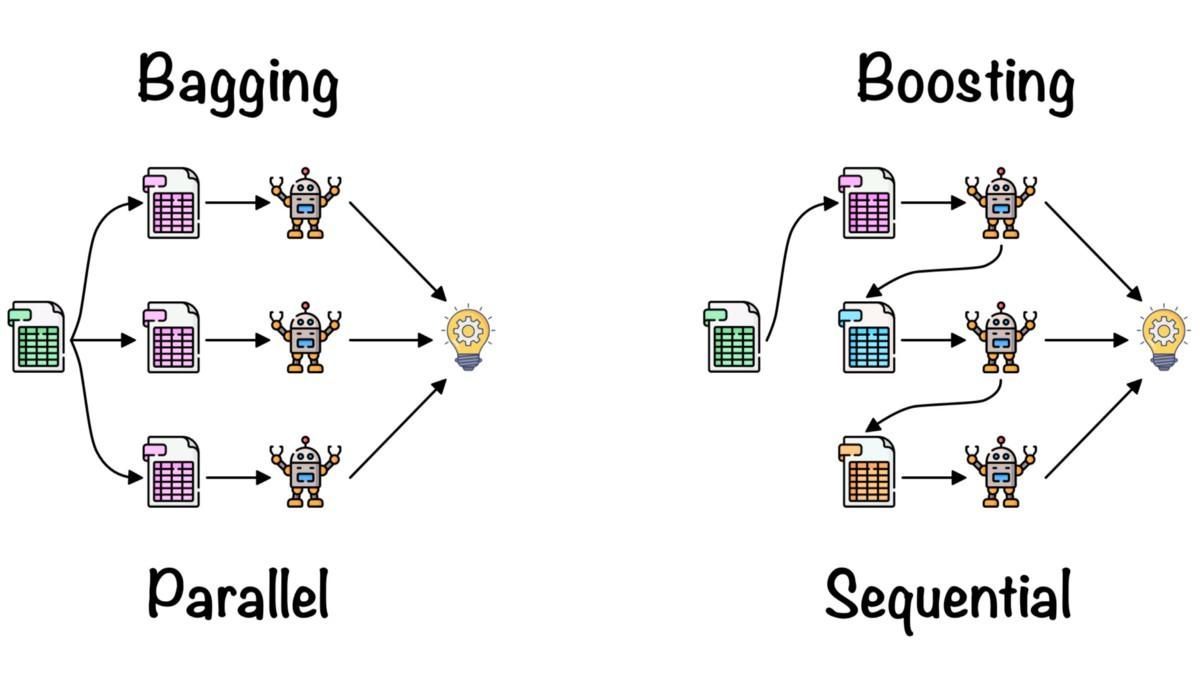
Bagging và Boosting bởi Fernando López
Tìm hiểu thêm về averaging, bagging, stacking và boosting bằng cách hoàn thành khóa học Ensemble Methods in Python.
Khi kết thúc hành trình khám phá các câu hỏi phỏng vấn machine learning thiết yếu, có thể thấy để thành công trong các buổi phỏng vấn này cần sự kết hợp giữa kiến thức lý thuyết, kỹ năng thực hành và sự cập nhật về xu hướng, công nghệ mới nhất trong lĩnh vực. Từ việc hiểu các khái niệm cơ bản như học bán giám sát và lựa chọn thuật toán, đến đào sâu vào độ phức tạp của các thuật toán cụ thể như KNN, và giải quyết các thách thức theo vai trò trong NLP, thị giác máy tính hay học tăng cường, phạm vi là rất rộng.
Dù bạn là người mới muốn bước vào lĩnh vực hay là người đã có kinh nghiệm muốn tiến xa hơn, học tập và luyện tập liên tục là chìa khóa. DataCamp cung cấp lộ trình toàn diện Machine Learning Scientist with Python giúp bạn nâng cao kỹ năng theo cách có cấu trúc và chuyên sâu.
Khóa học Machine Learning
Courses
Courses
blogs
Matt Crabtree
10 phút