Corso
Machine Learning for Finance in Python
4 h
33K
Le domande base riguardano terminologia, algoritmi e metodologie. Gli intervistatori le usano per valutare le conoscenze tecniche del candidato.
L'apprendimento semi-supervisionato è una via di mezzo tra apprendimento supervisionato e non supervisionato. L'algoritmo viene addestrato su un mix di dati etichettati e non etichettati. In genere si usa quando abbiamo un dataset etichettato molto piccolo e un dataset non etichettato molto grande.
In parole semplici, l'algoritmo non supervisionato viene usato per creare cluster e, usando i dati etichettati esistenti, per etichettare il resto dei dati non etichettati. Un algoritmo semi-supervisionato assume l'ipotesi di continuità, l'ipotesi di cluster e l'ipotesi di varietà (manifold).
In genere serve a ridurre i costi di acquisizione dei dati etichettati. Per esempio, classificazione di sequenze proteiche, riconoscimento vocale automatico e auto a guida autonoma.
Oltre al dataset, ti servono un caso d'uso aziendale o dei requisiti applicativi. Puoi applicare apprendimento supervisionato e non supervisionato agli stessi dati.
In generale:
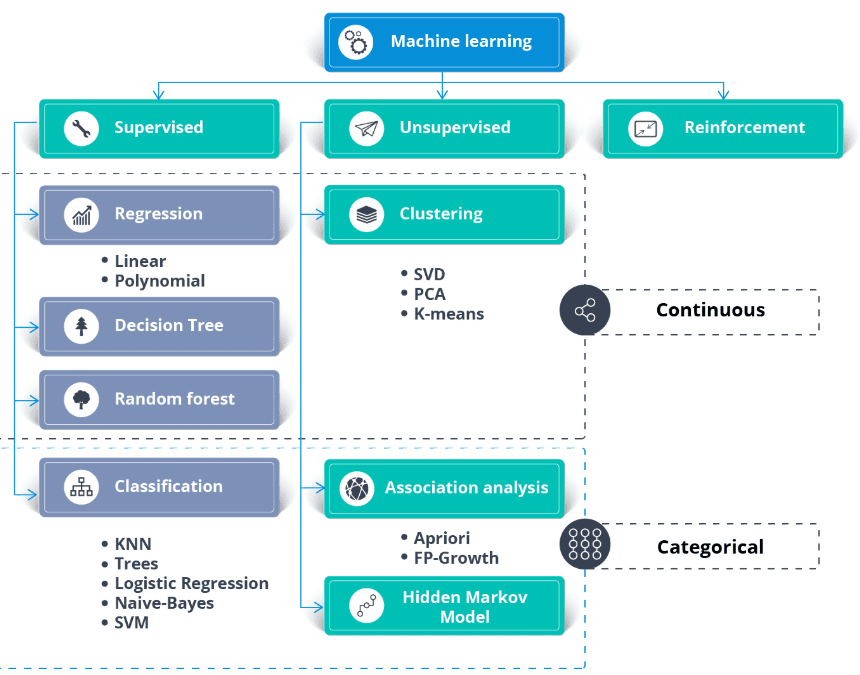
Immagine da thecleverprogrammer
Impara le basi del machine learning seguendo il nostro corso.
Il K Nearest Neighbor (KNN) è un classificatore di apprendimento supervisionato. Usa la prossimità per classificare etichette o prevedere il raggruppamento di singoli punti dati. Possiamo usarlo per regressione e classificazione. L'algoritmo KNN è non parametrico, cioè non fa assunzioni sulla distribuzione dei dati.
Nel classificatore KNN:
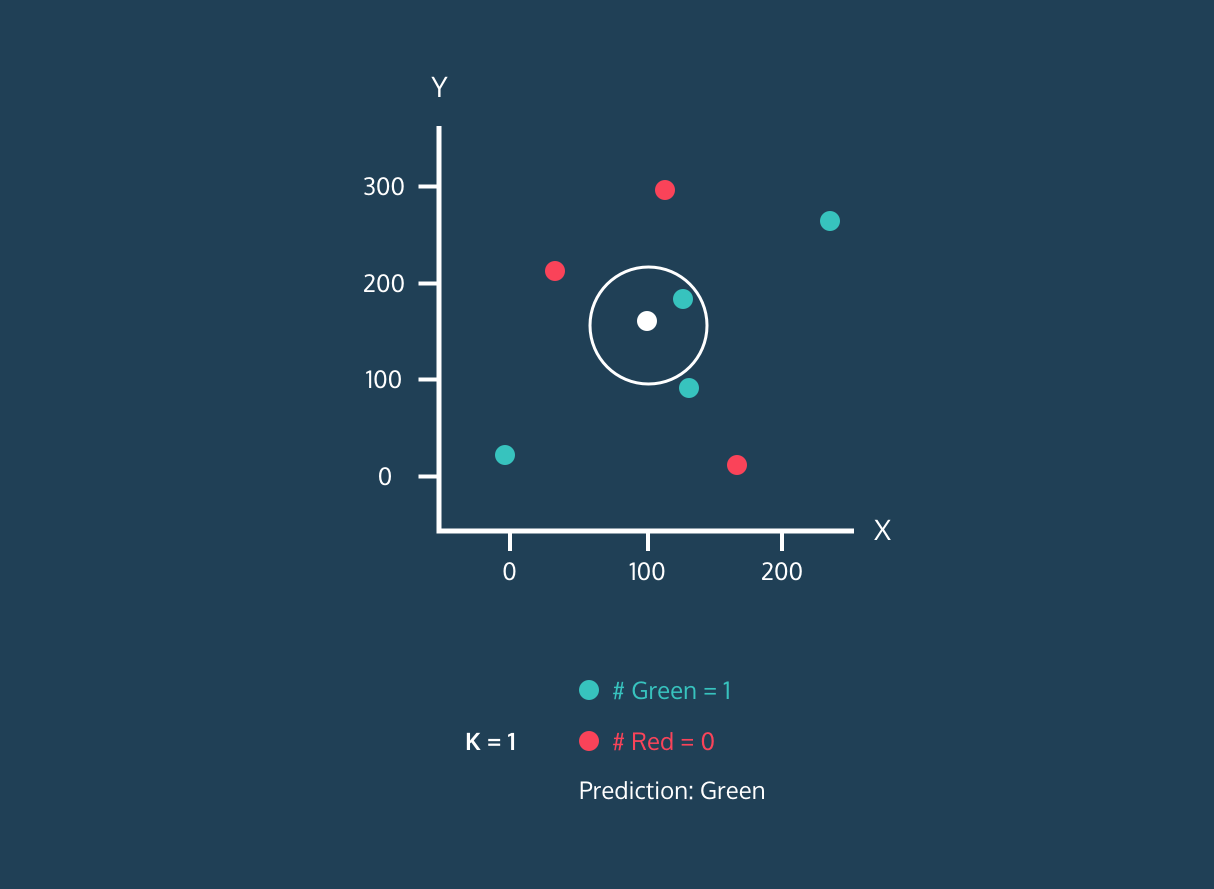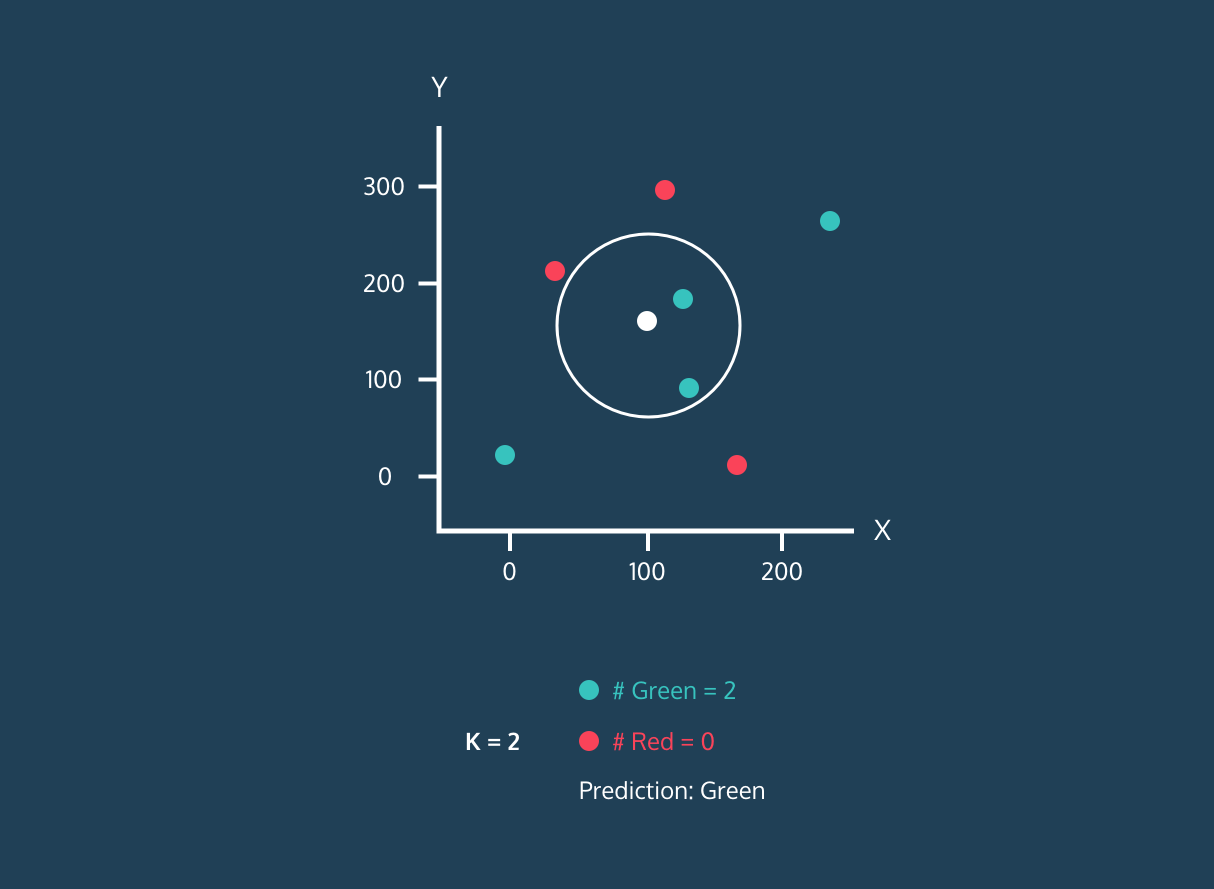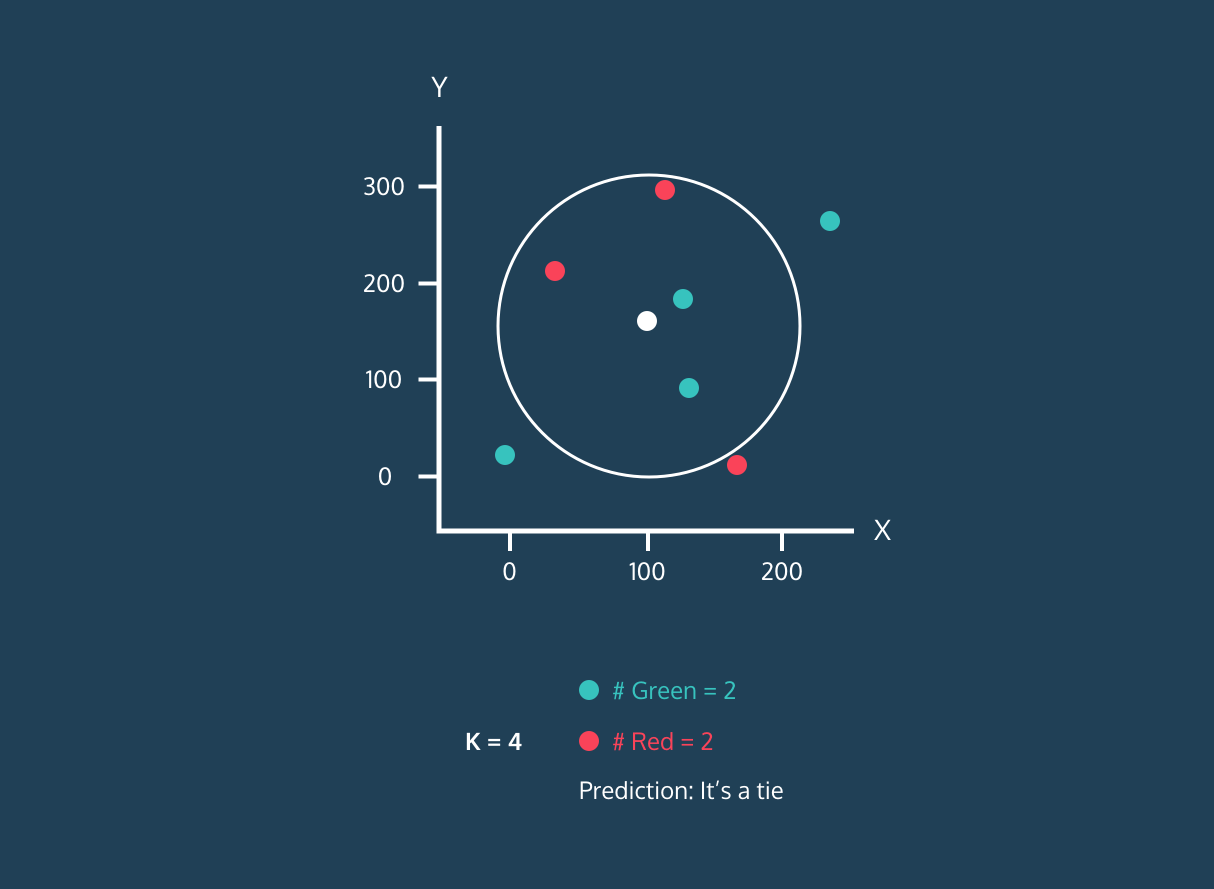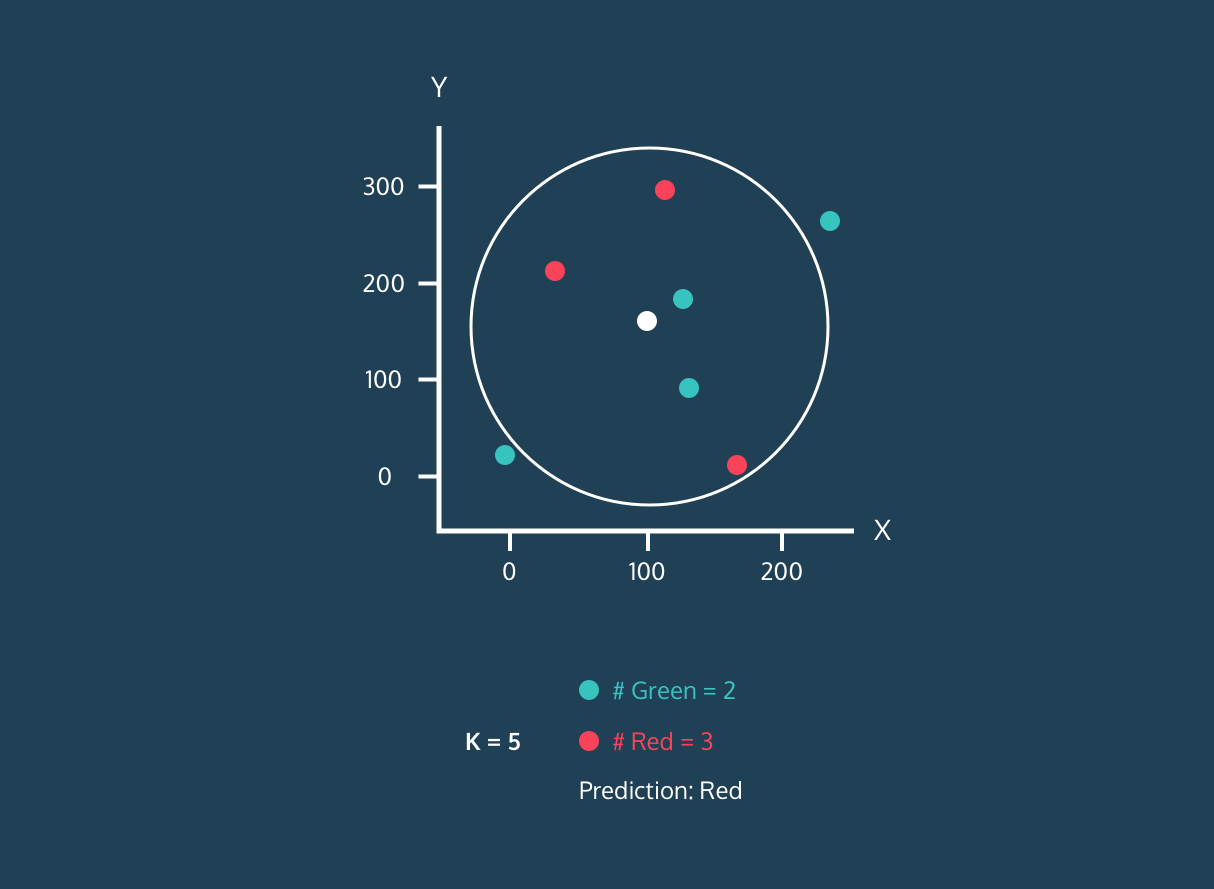
Immagine da Codesigner's Dev Story
Scopri tutto su modelli di classificazione e regressione supervisionata con un corso breve.
Per importanza delle feature si intendono tecniche che assegnano un punteggio alle variabili in input in base a quanto sono utili nel prevedere la variabile target. Ha un ruolo fondamentale per comprendere la struttura sottostante dei dati, il comportamento del modello e per rendere il modello più interpretabile.
Esistono diversi metodi per determinarla:
Capire l'importanza delle feature è cruciale per ottimizzare il modello, ridurre l'overfitting rimuovendo le variabili non informative e migliorare l'interpretabilità, soprattutto in ambiti in cui comprendere il processo decisionale del modello è fondamentale.
L'overfitting si verifica quando un modello va bene sui dati di training ma non generalizza ai dati non visti perché ha memorizzato i dati di training invece di apprenderne i pattern sottostanti. Si può evitare:
La matrice di confusione è una tabella usata per valutare le prestazioni di un modello di classificazione. Mostra i conteggi di veri positivi, veri negativi, falsi positivi e falsi negativi. È utile per calcolare metriche come accuratezza, precisione, richiamo e F1 score.
Modelli parametrici: Fanno ipotesi sulla distribuzione sottostante dei dati e hanno un numero fisso di parametri (ad es. Regressione Lineare).
Modelli non parametrici: Non fanno ipotesi sulla distribuzione dei dati e possono adattarsi alla complessità man mano che si aggiungono dati (ad es. K-Nearest Neighbors).
Il trade-off bias-varianza riguarda l'equilibrio tra la capacità di un modello di catturare pattern complessi (basso bias) e la sua sensibilità alle fluttuazioni nei dati di training (bassa varianza). Un buon modello trova un equilibrio minimizzando sia bias sia varianza, evitando underfitting e overfitting.
La sessione tecnica serve soprattutto a valutare la tua conoscenza dei processi e quanto sei preparato a gestire l'incertezza. Il responsabile delle assunzioni porrà domande su data processing, addestramento e validazione dei modelli e algoritmi avanzati.
Sì. La maggior parte degli algoritmi usa la distanza euclidea tra i punti dati, e se il valore delle feature varia molto, i risultati saranno molto diversi. Nella maggior parte dei casi, gli outlier fanno peggiorare le prestazioni dei modelli sul dataset di test.
Usiamo anche il feature scaling per ridurre il tempo di convergenza. Il gradiente discendente impiegherà più tempo a raggiungere i minimi locali quando le feature non sono normalizzate.
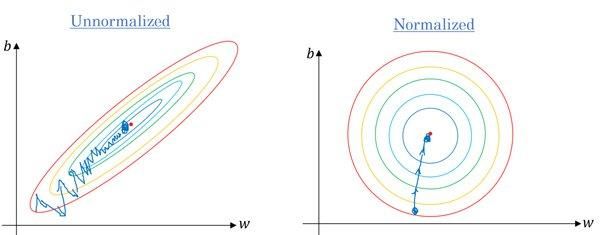
Gradiente senza e con scaling | Quora
Le competenze di feature engineering sono molto richieste. Puoi imparare tutto sull'argomento con un corso DataCamp, ad esempio Feature Engineering for Machine Learning in Python.
Il basso bias si verifica quando il modello predice valori vicini a quelli reali. Sta imitando il dataset di training. Il modello non generalizza, il che significa che, se testato su dati non visti, darà risultati scadenti.
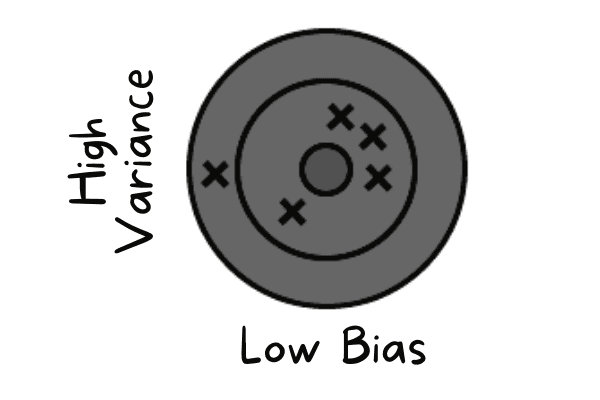
Basso bias e alta varianza | Autore
Per risolvere questi problemi, useremo algoritmi di bagging, poiché dividono un set di dati in sottoinsiemi usando campionamento randomizzato. Poi generiamo insiemi di modelli usando questi campioni con un singolo algoritmo. Successivamente, combiniamo le predizioni dei modelli con voting (classificazione) o media (regressione).
Per l'alta varianza, possiamo usare tecniche di regolarizzazione. Penalizzano coefficienti elevati per ridurre la complessità del modello. Inoltre, possiamo selezionare le feature principali dal grafico di importanza e addestrare il modello.
Il model drift si verifica quando le prestazioni di un modello peggiorano nel tempo perché i dati reali cambiano rispetto a quelli di training. Esistono due tipi principali:
La cross-validation si usa per valutare in modo robusto le prestazioni del modello e prevenire l'overfitting. In genere, le tecniche di cross-validation selezionano casualmente campioni dai dati e li dividono in train e test. Il numero di suddivisioni dipende dal valore di K.
Per esempio, se K = 5, ci saranno quattro fold per il train e uno per il test. Si ripete cinque volte per misurare le prestazioni del modello su fold separati.
Non possiamo farlo con un dataset di serie temporali perché non ha senso usare valori dal futuro per prevedere il passato. Esiste una dipendenza temporale tra le osservazioni, e possiamo dividere i dati solo in un'unica direzione, in modo che i valori del test set vengano dopo il training set.
Il diagramma mostra che lo split k-fold per serie temporali è unidirezionale. I punti blu sono il training set, il rosso è il test set e il bianco sono dati non usati. Come si vede, a ogni iterazione ci spostiamo in avanti con il training set, mentre il test set rimane davanti, non selezionato casualmente.
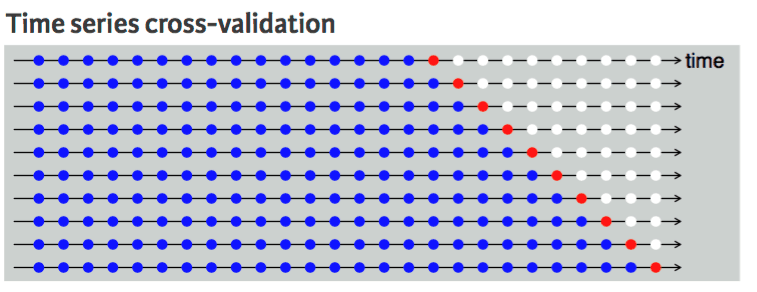
Cross validation per serie temporali | UC Business Analytics R Programming Guide
Impara la manipolazione, l'analisi, la visualizzazione e il modeling dei dati di serie temporali seguendo Time Series with Python.
La maggior parte dei lavori di machine learning pubblicati su LinkedIn, Glassdoor e Indeed sono specifici per il ruolo. Di conseguenza, durante il colloquio si concentreranno su domande specifiche. Per il ruolo di computer vision engineer, il responsabile delle assunzioni si focalizzerà su domande di image processing.
Immagina un'immagine 250 X 250 e un primo livello nascosto completamente connesso con 1000 unità. Per questa immagine, le feature in input sono 250 X 250 X 3 = 187.500, e la matrice dei pesi al primo livello nascosto sarà una matrice di dimensione 187.500 X 1000. Questi numeri sono enormi per archiviazione e calcolo; per affrontare il problema usiamo le operazioni di convoluzione.
Impara l'image processing con un breve corso Image Processing in Python
Se non hai abbastanza dati per addestrare una CNN, puoi usare il transfer learning per addestrare il modello e ottenere risultati allo stato dell'arte. Ti serve un modello pre-addestrato su un dataset generale ma più ampio. Dopodiché, lo affinerai sui nuovi dati addestrando gli ultimi layer del modello.
Il transfer learning consente ai data scientist di addestrare modelli su pochi dati usando meno risorse, calcolo e storage. Puoi trovare facilmente modelli open-source pre-addestrati per vari casi d'uso; la maggior parte ha licenza commerciale, cioè puoi usarli per creare la tua applicazione.
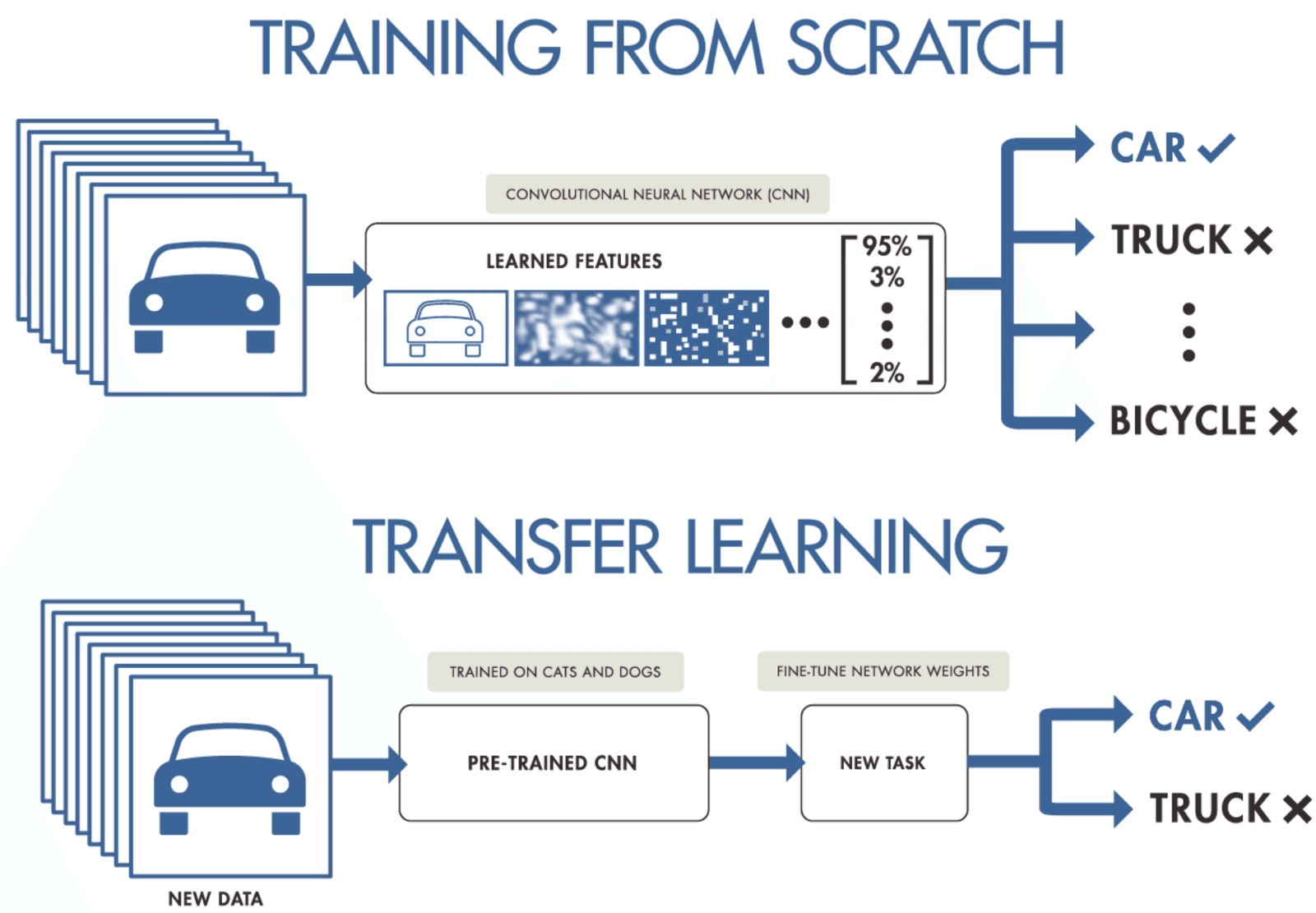
Transfer Learning di purnasai gudikandula
YOLO è un algoritmo di object detection basato su reti neurali convoluzionali, in grado di fornire risultati in tempo reale. L'algoritmo YOLO richiede un'unica passata forward attraverso la CNN per riconoscere l'oggetto. Predice sia le probabilità delle varie classi sia i bounding box.
Il modello è stato addestrato per rilevare vari oggetti e le aziende usano il transfer learning per affinarlo su nuovi dati per applicazioni moderne come guida autonoma, tutela della fauna selvatica e sicurezza.
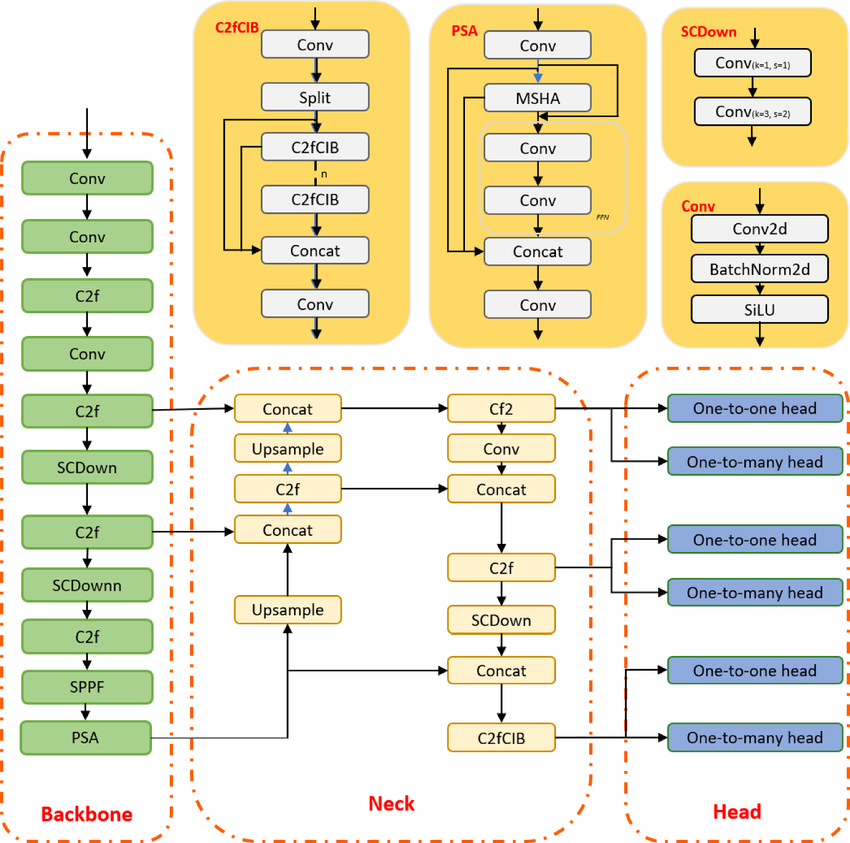
Architettura del modello YOLOv10 | researchgate
Il Natural Language Processing (NLP) è una delle basi delle moderne applicazioni di AI. Aspettati domande che collegano la teoria linguistica all'implementazione pratica, mettendo alla prova la tua capacità di elaborare, analizzare ed estrarre significato da testo non strutturato usando tecniche classiche e approcci di deep learning moderni.
L'Analisi Sintattica, nota anche come Syntax analysis o Parsing, è un'analisi del testo che ci restituisce il significato logico dietro una frase o parte di essa. Si concentra sulla relazione tra le parole e sulla struttura grammaticale delle frasi. In altre parole, è l'elaborazione del linguaggio naturale usando regole grammaticali.
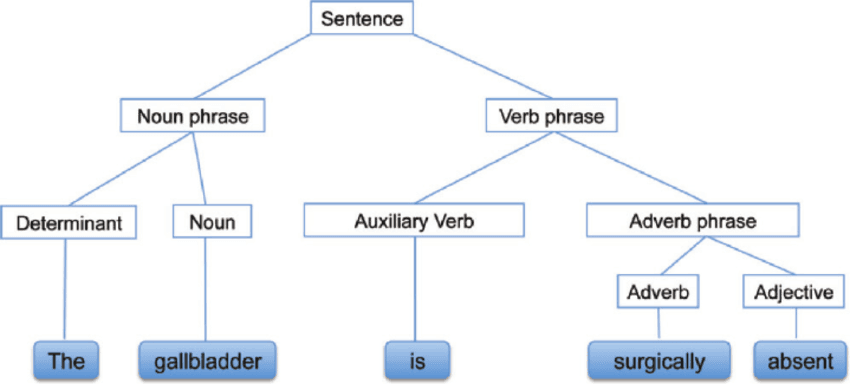
Analisi Sintattica | researchgate
Stemming e lemmatization sono tecniche di normalizzazione usate per minimizzare la variazione strutturale delle parole in una frase.
Lo stemming rimuove gli affissi aggiunti alla parola e la lascia nella forma base. Per esempio, Changing diventa Chang.
È ampiamente usato dai motori di ricerca per ottimizzare lo storage. Invece di memorizzare tutte le forme delle parole, memorizza solo gli stem.
La lemmatization converte la parola nella sua forma lemma. L'output è la parola radice, non lo stem. Dopo la lemmatization otteniamo una parola valida che ha significato. Per esempio, Changing diventa Change.

Stemming vs. Lemmatization | Autore
Ottimizzare grandi transformer richiede di affrontare i colli di bottiglia sia di banda di memoria sia di calcolo:
Impara le basi dell'NLP completando il percorso di competenze Natural Language Processing in Python .
Poiché gli LLM dominano l'attuale panorama dell'AI, gli intervistatori danno priorità a candidati che sanno come distribuirli in modo efficace. Questa sezione si concentra su alcune delle maggiori sfide ingegneristiche pratiche del 2026.
La context window di un LLM è la quantità massima di testo (misurata in token) che il modello può considerare in una singola generazione, e limita direttamente quanta "memoria di lavoro" il modello ha a disposizione.
Anche se diventano comuni context window ampie, prestazioni e costi non scalano linearmente: prompt lunghi aumentano la latenza e possono comunque portare a problemi di affidabilità quando l'informazione rilevante è sepolta nel mezzo del contesto.
In un colloquio, risponderei spiegando strategie pratiche per attività su documenti lunghi:
Le allucinazioni si verificano quando un LLM genera informazioni plausibili ma fattualmente errate. Nel 2026, la mitigazione richiede un approccio multilivello:
È una classica domanda di "trade-off". La decisione dipende dall'aggiornamento dei dati e dalla specificità del dominio:
La questione è approfondita nel nostro blog su RAG vs Fine-Tuning.
Il Reinforcement Learning (RL) affronta problemi in cui un agente impara interagendo con un ambiente invece che da dataset statici. Preparati a spiegare come funziona l'RL e a illustrare concetti chiave come le policy.
Il reinforcement learning usa tentativi ed errori per raggiungere obiettivi. È un algoritmo orientato all'obiettivo e impara dall'ambiente compiendo le mosse corrette per massimizzare la ricompensa cumulativa.
In un tipico reinforcement learning:
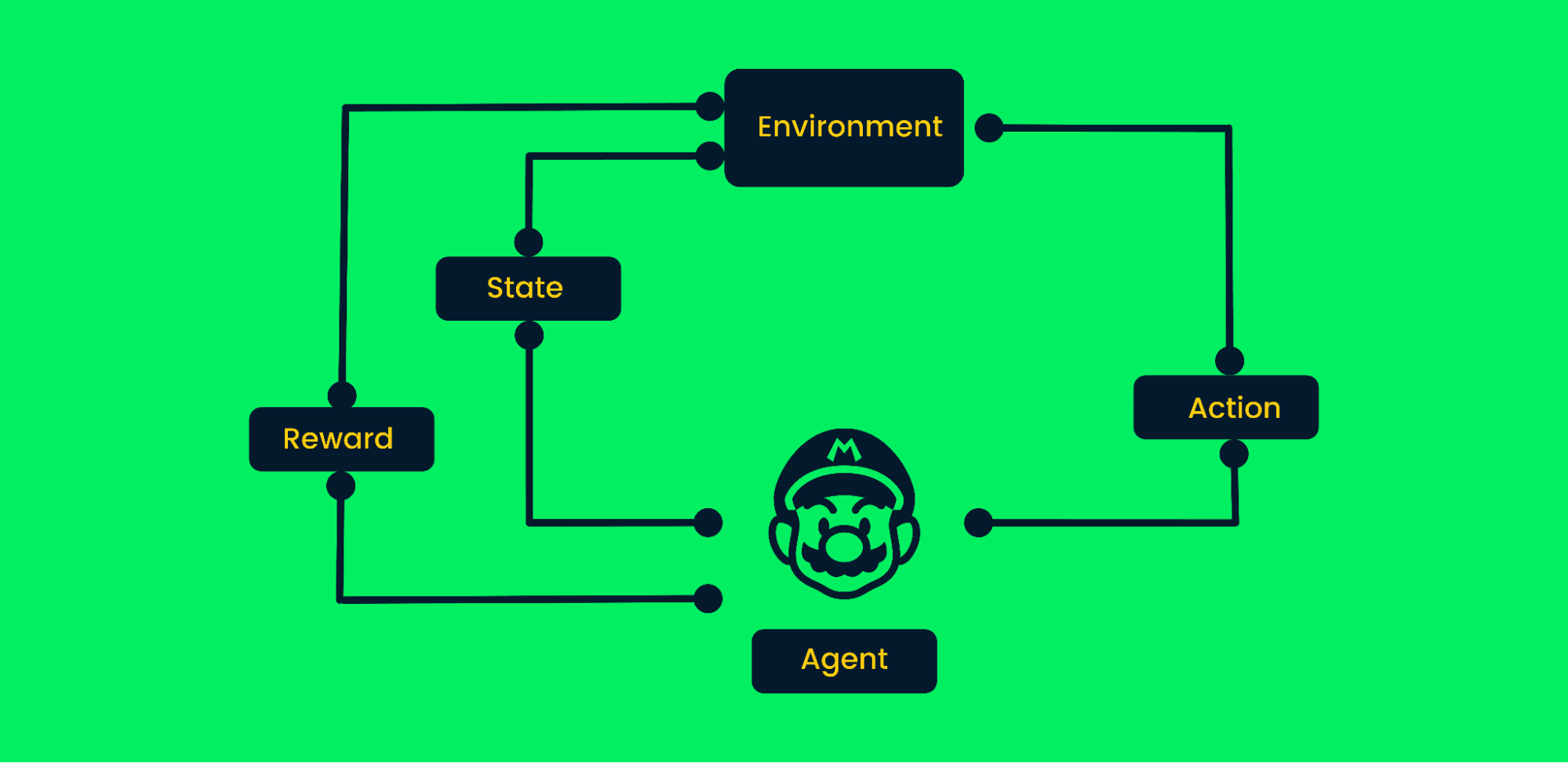
Framework di Reinforcement Learning | Autore
Gli algoritmi On-Policy valutano e migliorano la stessa policy con cui agiscono e che aggiornano. In altre parole, la policy usata per l'aggiornamento e quella usata per agire sono le stesse.
Target Policy == Behavior Policy
Gli algoritmi On-Policy includono Sarsa, Monte Carlo On-Policy, Value Iteration e Policy Iteration
Gli algoritmi Off-Policy sono completamente diversi, poiché la policy aggiornata è diversa dalla behavior policy. Per esempio, nel Q-learning l'agente apprende una policy ottimale con l'aiuto di una greedy policy e agisce usando altre policy.
Target Policy != Behavior Policy
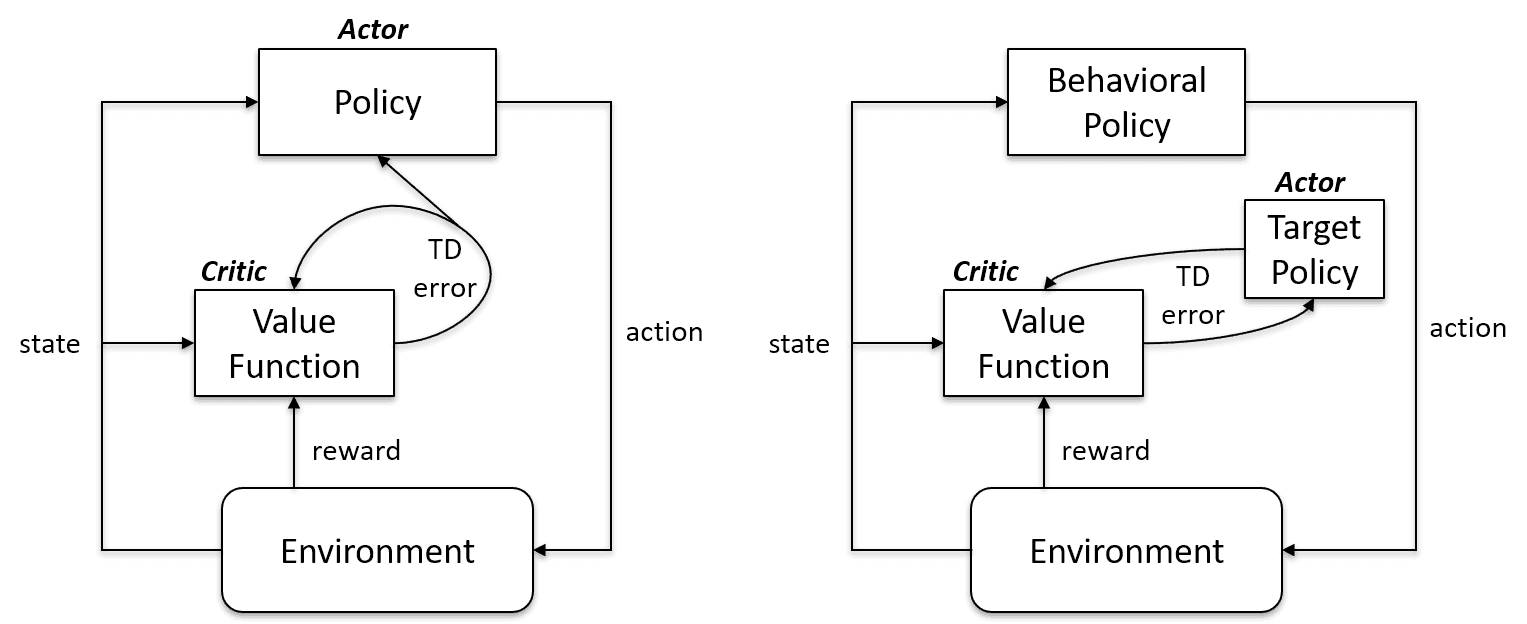
Caso On-policy vs. Off-policy | Artificial Intelligence Stack Exchange
Il Q learning semplice è ottimo. Risolve il problema su piccola scala, ma su larga scala fallisce.
Immagina che l'ambiente abbia 1000 stati e 1000 azioni per stato. Servirebbe una tabella Q con milioni di celle. Il gioco degli scacchi o del Go richiederebbe una tabella ancora più grande. È qui che entra in gioco il Deep Q-learning.
Usa una rete neurale per approssimare la funzione di valore Q. La rete neurale riceve gli stati in input e restituisce i Q-value di tutte le azioni possibili.
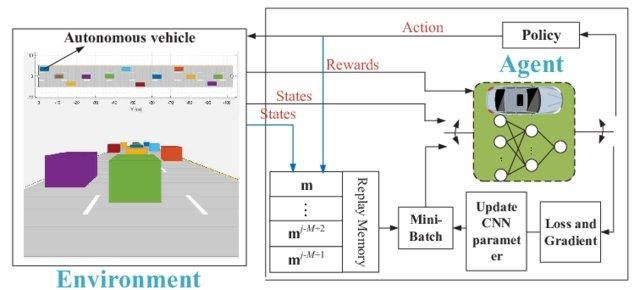
Deep Q-network per guida autonoma | researchgate
Di seguito abbiamo elencato alcune possibili domande che l'intervistatore potrebbe porti in alcune delle principali aziende tech:
Le receiver operating characteristics (ROC) mostrano il trade-off tra sensibilità e specificità.
La curva è tracciata usando il tasso di falsi positivi (FP/(TN + FP)) e il tasso di veri positivi (TP/(TP + FN))
L'area sotto la curva (AUC) indica le prestazioni del modello. Se l'area sotto la ROC è 0,5, allora il nostro modello è completamente casuale. Un modello con AUC vicino a 1 è migliore.
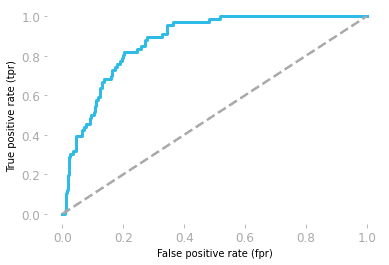
Curva ROC di Hadrien Jean
A differenza della classificazione (dove una risposta è giusta o sbagliata), GenAI spesso richiede valutazione umana o framework "LLM-as-a-Judge":
Per la riduzione della dimensionalità possiamo usare metodi di selezione o di estrazione delle feature.
La selezione delle feature è il processo di scelta delle variabili ottimali ed eliminazione di quelle irrilevanti. Usiamo metodi Filter, Wrapper ed Embedded per analizzare l'importanza delle feature e rimuovere quelle meno importanti per migliorare le prestazioni del modello.
L'estrazione delle feature trasforma uno spazio a molte dimensioni in uno con meno dimensioni. Durante il processo non si perde informazione e si usano meno risorse per elaborare i dati. Le tecniche più comuni di estrazione sono Linear Discriminant Analysis (LDA), Kernel PCA e Quadratic Discriminant Analysis.
Nel caso di un classificatore di spam, un modello di regressione logistica restituirà una probabilità. Possiamo usare tale probabilità, ad esempio 0,8999, oppure convertirla in classe (Spam/Non Spam) usando una soglia.
Di solito la soglia di un classificatore è 0,5, ma in alcuni casi va ottimizzata per migliorare l'accuratezza. La soglia 0,5 significa che, se la probabilità è pari o superiore a 0,5, è spam; se inferiore, non è spam.
Per trovare la soglia, possiamo usare le curve Precision-Recall e ROC, la grid search o modificare manualmente il valore per ottenere una CV migliore.
Diventa un machine learning engineer professionista completando il percorso Machine Learning Scientist with Python.
La regressione lineare è usata per comprendere la relazione tra feature (X) e target (y). Prima di addestrare il modello, dobbiamo soddisfare alcune assunzioni:
Nota: i residui nella regressione lineare sono la differenza tra valori reali e predetti.
Durante i colloqui di coding ti verranno poste domande di machine learning, ma in alcuni casi valuteranno le tue competenze Python con domande generali di programmazione. Diventa un esperto programmatore Python seguendo il percorso Python Programmer.
Creare una funzione per i bigrammi è piuttosto semplice. Devi usare due cicli con la funzione zip.
zip per creare la combinazione della parola precedente e di quella successivaÈ piuttosto semplice se scomponi il problema e usi zip.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Risultati:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]La funzione di attivazione è una trasformazione non lineare nelle reti neurali. Passiamo l'input attraverso la funzione di attivazione prima di inviarlo allo strato successivo.
Il valore di input netto può essere qualsiasi cosa tra -inf e +inf, e il neurone non sa come limitare i valori, risultando incapace di decidere il pattern di attivazione. La funzione di attivazione decide se un neurone debba attivarsi o meno per limitare i valori netti in input.
Tipi più comuni di funzioni di attivazione:
La risposta dipende da te. Ma prima di rispondere, devi considerare quale obiettivo di business vuoi raggiungere per definire una metrica di prestazione e come acquisirai i dati.
In un tipico system design di machine learning, noi:
Assicurati di concentrarti sul design più che sulla teoria o sull'architettura del modello. Parla dell'inferenza del modello e di come migliorarla aumenterà i ricavi complessivi.
Fornisci anche una panoramica del perché hai scelto una certa metodologia rispetto a un'altra.
Scopri di più su come costruire sistemi di raccomandazione seguendo un corso su DataCamp.
Risolvere sfide di programmazione e lavorare sulle tue abilità in Python aumenterà le possibilità di superare la fase di coding interview.
Prima di metterti a risolvere il problema, capisci bene la domanda. Devi semplicemente creare una funzione booleana che restituisca True se, spostando le lettere nella stringa B, ottieni la stringa A.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueL'ensemble learning combina gli insight di più modelli di machine learning per migliorare accuratezza e metriche di prestazione.
Metodi di ensemble semplici:
Metodi di ensemble avanzati:
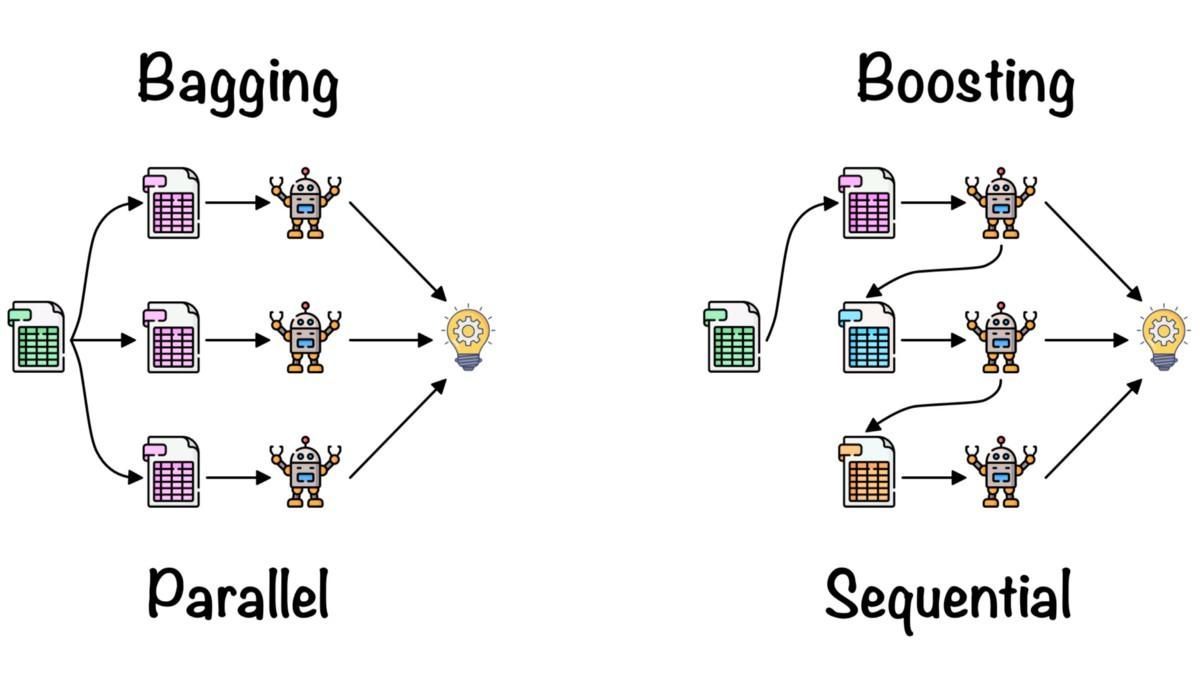
Bagging e Boosting di Fernando López
Scopri di più su averaging, bagging, stacking e boosting completando il corso Ensemble Methods in Python.
Concludendo la nostra esplorazione delle domande essenziali di colloquio sul machine learning, è evidente che per avere successo servono un mix di conoscenze teoriche, competenze pratiche e consapevolezza delle ultime tendenze e tecnologie del settore. Dalla comprensione di concetti base come l'apprendimento semi-supervisionato e la scelta degli algoritmi, fino ad affrontare le complessità di algoritmi specifici come KNN e le sfide legate al ruolo in NLP, computer vision o reinforcement learning, l'ambito è vasto.
Che tu sia un principiante che vuole entrare nel settore o un professionista esperto che punta a fare un salto avanti, apprendimento continuo ed esercizio sono la chiave. DataCamp offre un percorso completo Machine Learning Scientist with Python che fornisce un modo strutturato e approfondito per migliorare le tue competenze.
Corsi di Machine Learning
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

