Cursus
Machine Learning for Finance in Python
4 Hr
33K
Basisvragen hebben betrekking op terminologie, algoritmen en methodologieën. Interviewers stellen deze vragen om de technische kennis van de kandidaat te beoordelen.
Semi-supervised learning is een mix van supervised en unsupervised learning. Het algoritme wordt getraind op een combinatie van gelabelde en ongelabelde data. Het wordt meestal gebruikt wanneer we een heel kleine gelabelde dataset en een grote ongelabelde dataset hebben.
Eenvoudig gezegd: het unsupervised algoritme wordt gebruikt om clusters te maken en met behulp van bestaande gelabelde data labelen we de rest van de ongelabelde data. Een semi-supervised algoritme gaat uit van de continuïteitsaanname, clusteraanname en manifoldaanname.
Het wordt doorgaans gebruikt om de kosten van het verzamelen van gelabelde data te besparen. Bijvoorbeeld bij classificatie van eiwitsequenties, automatische spraakherkenning en zelfrijdende auto's.
Naast de dataset heb je een zakelijke usecase of applicatie-eisen nodig. Je kunt supervised en unsupervised learning op dezelfde data toepassen.
In het algemeen:
Afbeelding van thecleverprogrammer
Leer de basisprincipes van machine learning met onze cursus.
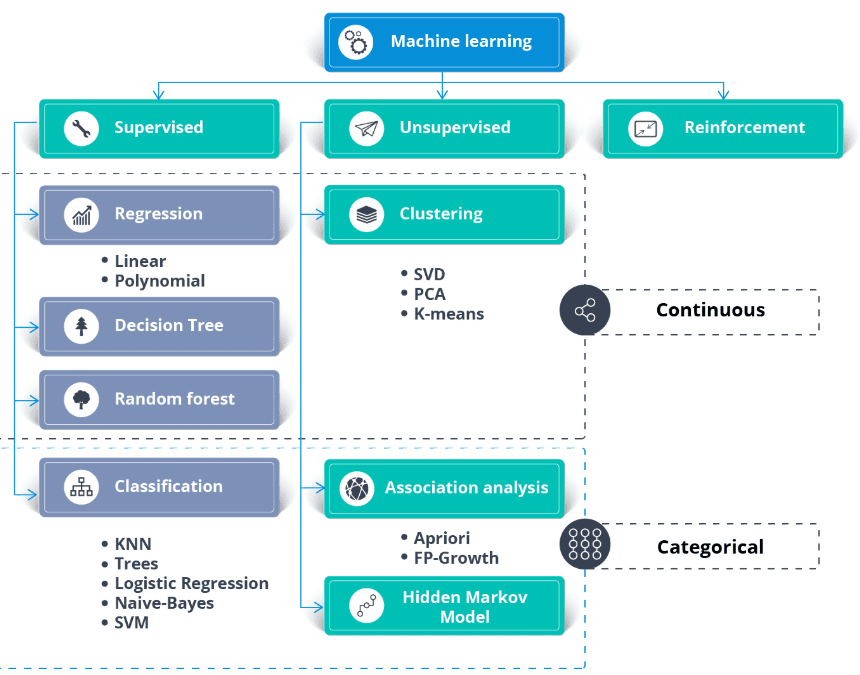
De K Nearest Neighbor (KNN) is een supervised learning-classificator. Het gebruikt nabijheid om labels te classificeren of de groepering van individuele datapunten te voorspellen. We kunnen het gebruiken voor regressie en classificatie. Het KNN-algoritme is niet-parametrisch, wat betekent dat het geen aannames doet over de onderliggende dataverdeling.
In de KNN-classificator:
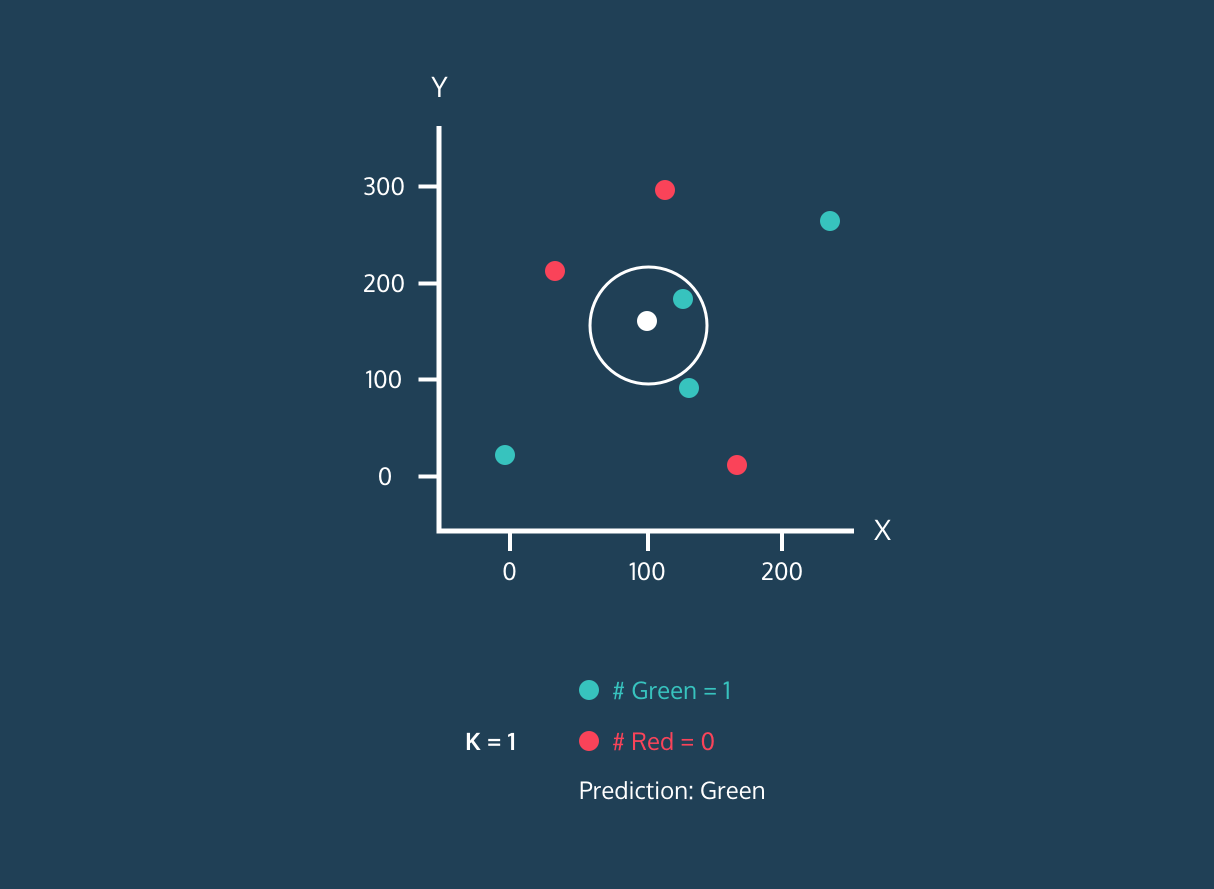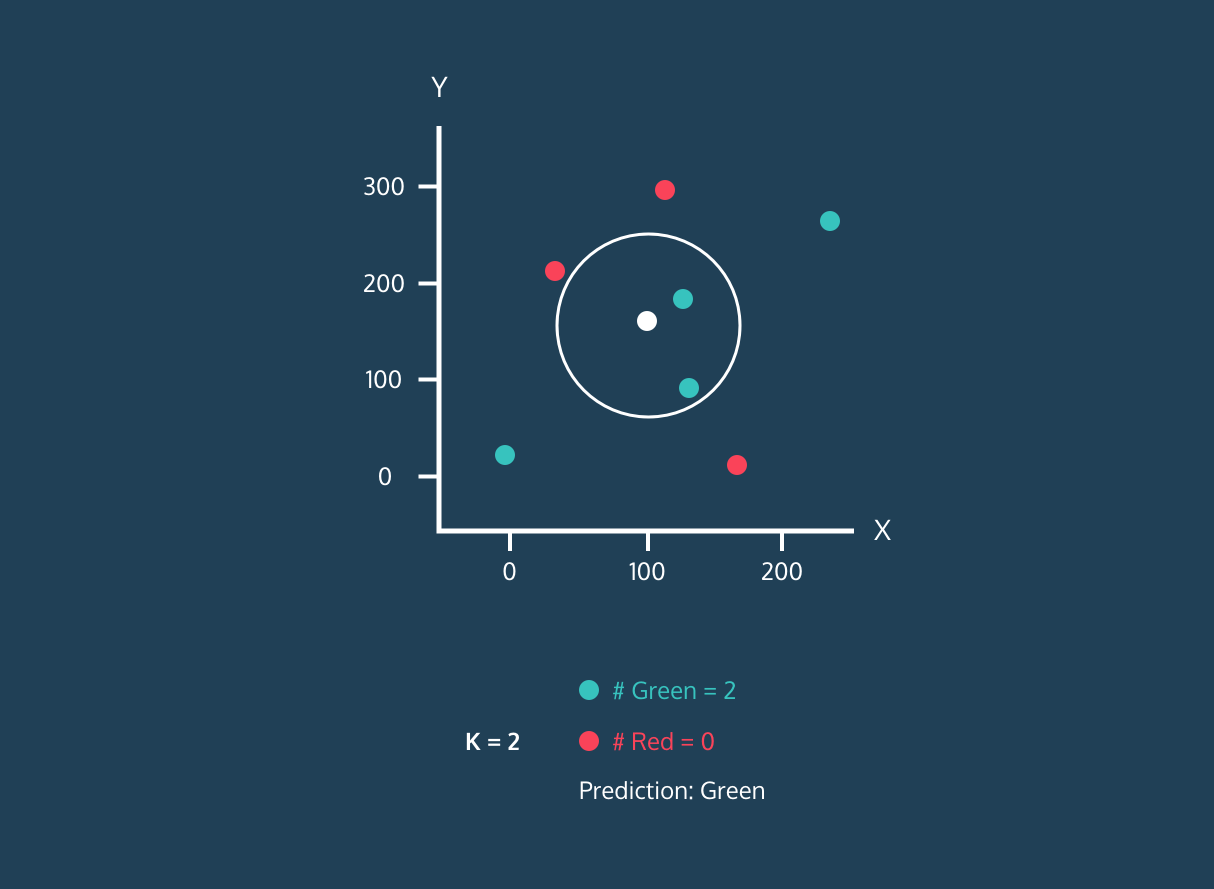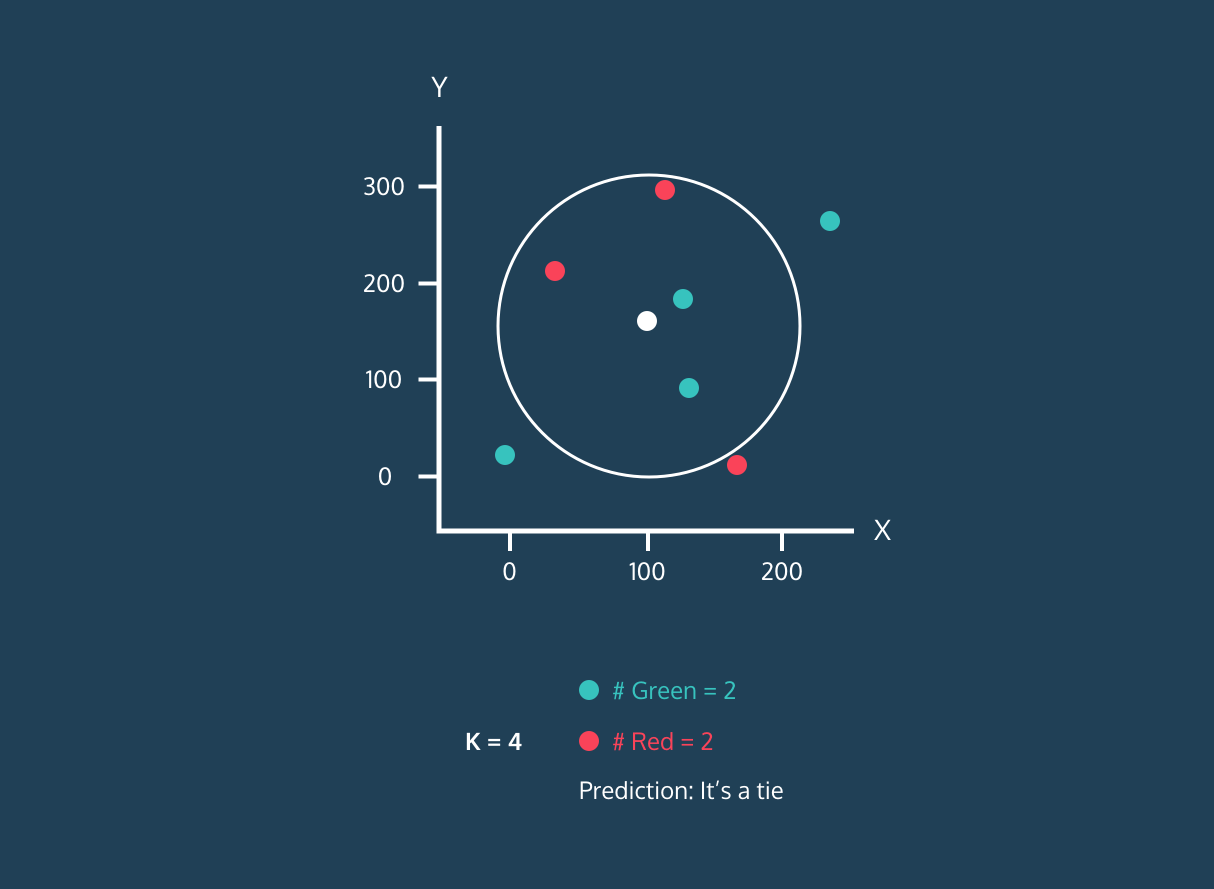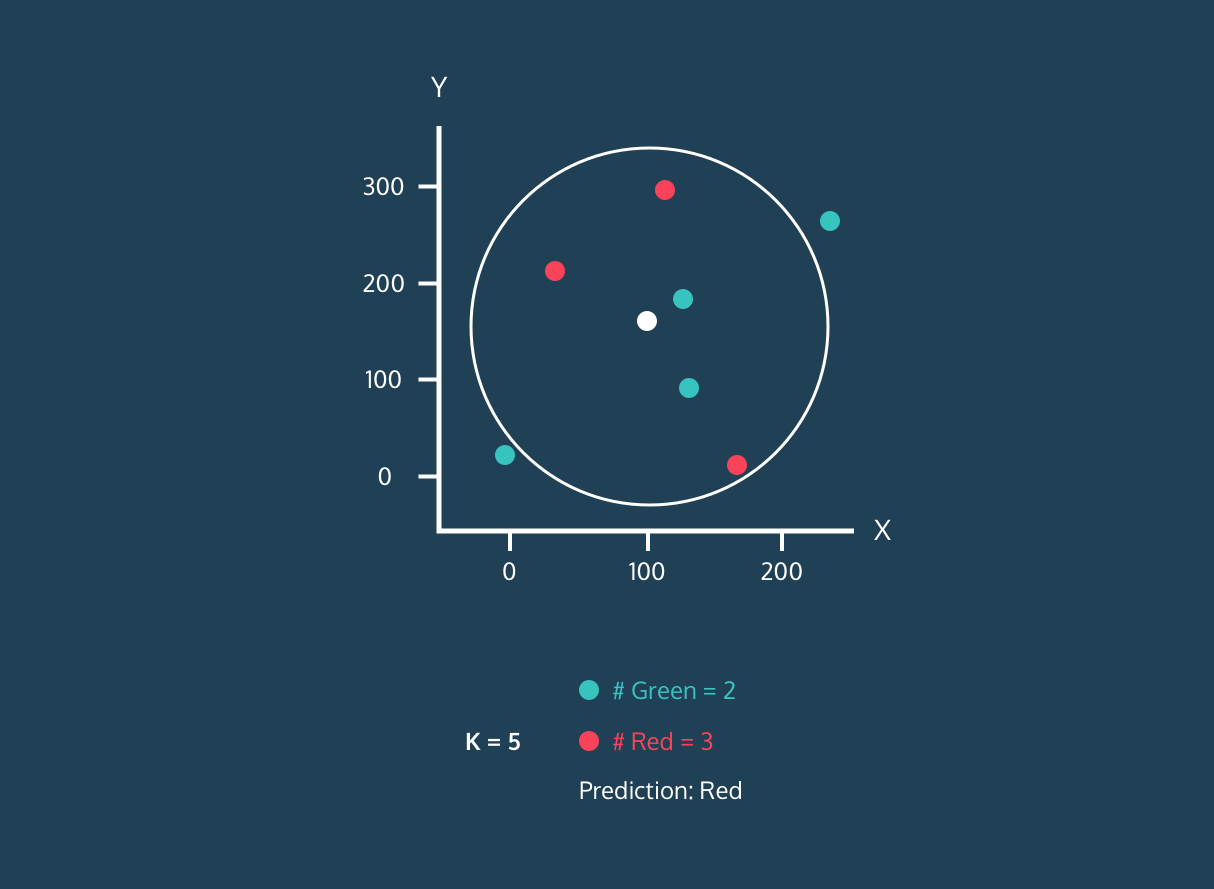
Afbeelding van Codesigner's Dev Story
Leer alles over supervised learning-classificatie- en regressiemodellen met een korte cursus.
Feature importance verwijst naar technieken die een score toekennen aan inputfeatures op basis van hoe nuttig ze zijn bij het voorspellen van een doelvariabele. Het speelt een cruciale rol bij het begrijpen van de onderliggende datastructuur, het gedrag van het model en het beter interpreteerbaar maken van het model.
Er zijn verschillende methoden om feature importance te bepalen:
Het begrijpen van feature importance is essentieel voor modeloptimalisatie, het verminderen van overfitting door niet-informatieve features te verwijderen en het verbeteren van de interpretatie van het model, vooral in domeinen waar inzicht in het beslissingsproces van het model cruciaal is.
Overfitting treedt op wanneer een model goed presteert op trainingsdata, maar niet generaliseert naar onzichtbare data omdat het de trainingsdata heeft gememoriseerd in plaats van de onderliggende patronen te leren. Je kunt het voorkomen door:
Een confusion matrix is een tabel die wordt gebruikt om de prestaties van een classificatiemodel te evalueren. Hij toont het aantal true positives, true negatives, false positives en false negatives. Hij is nuttig voor het berekenen van metrics zoals accuracy, precision, recall en F1-score.
Parametrische modellen: Deze doen aannames over de onderliggende dataverdeling en hebben een vast aantal parameters (bijv. lineaire regressie).
Niet-parametrische modellen: Deze doen geen aannames over de dataverdeling en kunnen zich aanpassen aan complexiteit naarmate er meer data bijkomt (bijv. K-Nearest Neighbors).
De bias-variance trade-off verwijst naar de balans tussen het vermogen van een model om complexe patronen te vangen (lage bias) en zijn gevoeligheid voor fluctuaties in de trainingsdata (lage variantie). Een goed model bereikt een balans door zowel bias als variantie te minimaliseren om underfitting en overfitting te vermijden.
Het technische interview gaat meer over het beoordelen van je kennis van processen en hoe goed je bent toegerust om met onzekerheid om te gaan. De hiring manager zal vragen stellen over dataverwerking, modeltraining en -validatie en geavanceerde algoritmen.
Ja. De meeste algoritmen gebruiken de euclidische afstand tussen datapunten, en als de featurewaarden sterk variëren, zullen de resultaten behoorlijk verschillen. In de meeste gevallen zorgen uitschieters ervoor dat machine-learningmodellen slechter presteren op de testdataset.
We gebruiken ook feature scaling om de convergentietijd te verkorten. Het duurt langer voor gradient descent om lokale minima te bereiken wanneer features niet genormaliseerd zijn.
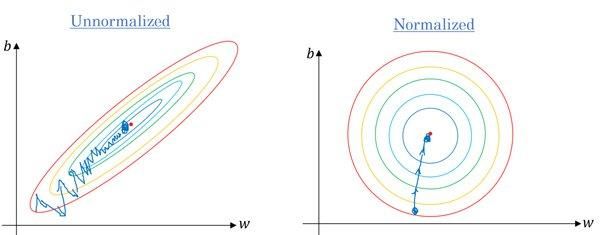
Gradiënt zonder en met schaling | Quora
Vaardigheden in feature engineering zijn zeer gewild. Je kunt alles over het onderwerp leren met een DataCamp-cursus, zoals Feature Engineering for Machine Learning in Python.
Lage bias treedt op wanneer het model waarden voorspelt die dicht bij de werkelijke waarde liggen. Het imiteert de trainingsdataset. Het model heeft geen generalisatie, wat betekent dat het bij testen op onzichtbare data slecht zal presteren.
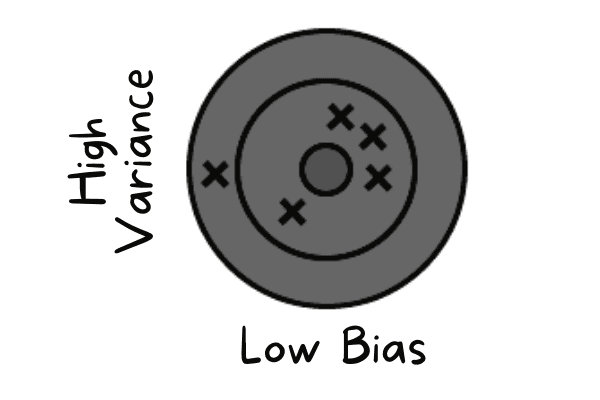
Lage bias en hoge variantie | Auteur
Om deze problemen op te lossen, gebruiken we bagging-algoritmen, omdat die een dataset opdelen in subsets met gerandomiseerde sampling. Vervolgens genereren we sets modellen met behulp van deze samples met één enkel algoritme. Daarna combineren we de modelvoorspellingen met voting-classificatie of middelen.
Voor hoge variantie kunnen we regularisatietechnieken gebruiken. Die bestraffen hogere modelcoëfficiënten om de modelcomplexiteit te verlagen. Verder kunnen we de topfeatures selecteren uit de feature-importancegrafiek en het model daarmee trainen.
Model drift treedt op wanneer de prestaties van een model in de loop van de tijd achteruitgaan omdat de data in de echte wereld verandert ten opzichte van de trainingsdata. Er zijn twee hoofdtypen:
Cross-validatie wordt gebruikt om de modelprestatie robuust te evalueren en overfitting te voorkomen. In het algemeen kiezen cross-validatietechnieken willekeurig samples uit de data en splitsen die in train- en testsets. Het aantal splits is gebaseerd op de K-waarde.
Bijvoorbeeld, als K = 5, zijn er vier folds voor training en één voor testen. Dit wordt vijf keer herhaald om te meten hoe het model op afzonderlijke folds presteerde.
Dit kan niet bij een tijdreeksdataset, omdat het niet logisch is om een waarde uit de toekomst te gebruiken om een waarde uit het verleden te voorspellen. Er is temporele afhankelijkheid tussen observaties, en we kunnen de data slechts in één richting splitsen zodat de waarden in de testdataset na de trainingsset liggen.
Het diagram toont dat k-fold-splitsing voor tijdreeksen unidirectioneel is. De blauwe punten zijn de trainingsset, het rode punt is de testset en wit is ongebruikte data. We zien dat we bij elke iteratie vooruit schuiven met de trainingsset, terwijl de testset vóór de trainingsset blijft en niet willekeurig is geselecteerd.
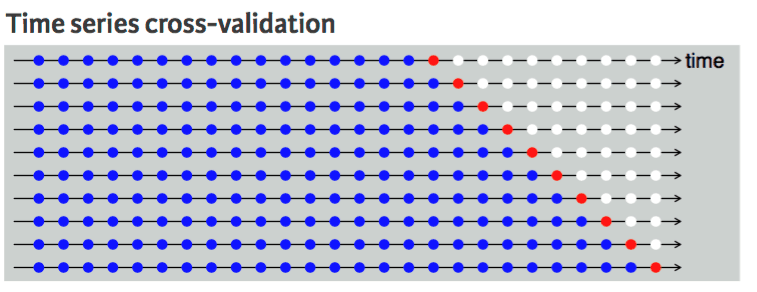
Cross-validatie voor tijdreeksen | UC Business Analytics R Programming Guide
Leer over manipulatie, analyse, visualisatie en modellering van tijdreeksdata met Time Series with Python.
De meeste machine-learningbanen op LinkedIn, Glassdoor en Indeed zijn rolspecifiek. Tijdens het gesprek ligt de focus dan ook op rolspecifieke vragen. Voor de rol van computer vision engineer zal de hiring manager focussen op vragen over beeldverwerking.
Stel je een afbeelding voor van 250 X 250 en een volledig verbonden eerste verborgen laag met 1000 verborgen units. Voor deze afbeelding zijn de inputfeatures 250 X 250 X 3 = 187.500, en de gewichtenmatrix in de eerste verborgen laag is een matrix van 187.500 X 1000. Deze aantallen zijn enorm voor opslag en berekening, en om dit probleem te bestrijden gebruiken we convolutieoperaties.
Leer beeldverwerking met een korte cursus Image Processing in Python
Als je niet genoeg data hebt om een convolutioneel neuraal netwerk te trainen, kun je transfer learning gebruiken om je model te trainen en resultaten op state-of-the-art-niveau te behalen. Je hebt een voorgetraind model nodig dat is getraind op een algemene maar grotere dataset. Daarna finetune je het op nieuwere data door de laatste lagen van de modellen te trainen.
Transfer learning stelt data scientists in staat om modellen op kleinere data te trainen met minder resources, rekenkracht en opslag. Je vindt eenvoudig open-source voorgetrainde modellen voor diverse usecases, en de meeste hebben een commerciële licentie, wat betekent dat je ze kunt gebruiken om je applicatie te bouwen.
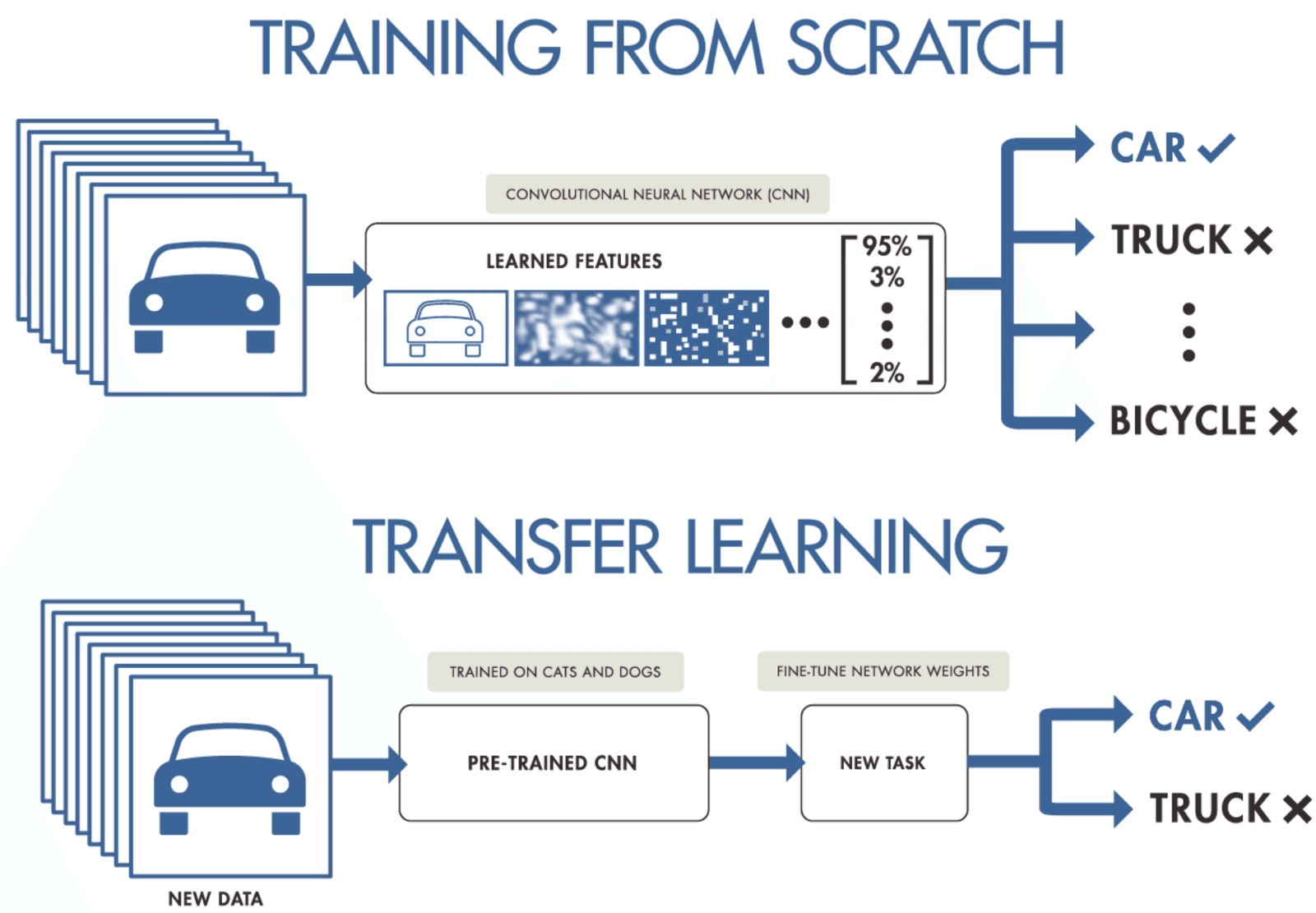
Transfer learning door purnasai gudikandula
YOLO is een objectdetectie-algoritme op basis van convolutionele neurale netwerken en kan realtime resultaten leveren. Het YOLO-algoritme vereist één forward pass door een CNN om het object te herkennen. Het voorspelt zowel verschillende klassewaarschijnlijkheden als begrenzingsvakken.
Het model is getraind om verschillende objecten te detecteren, en bedrijven gebruiken transfer learning om het te finetunen op nieuwe data voor moderne toepassingen zoals autonoom rijden, natuurbehoud en beveiliging.
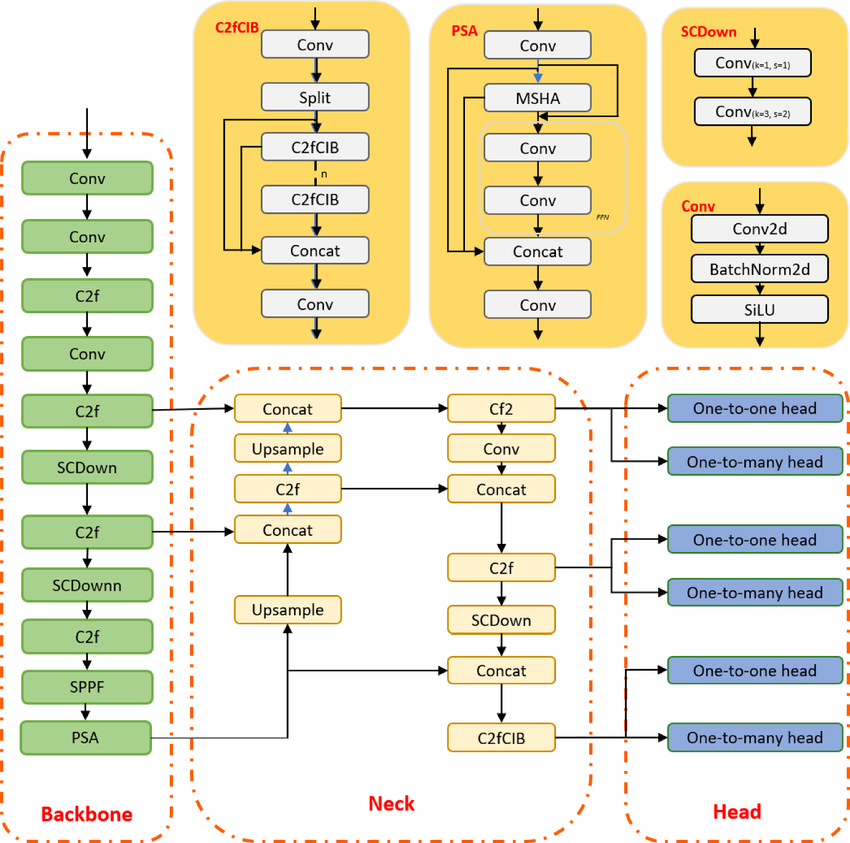
YOLOv10-modelarchitectuur | researchgate
Natural Language Processing (NLP) is een van de pijlers van moderne AI-toepassingen. Verwacht vragen die de kloof overbruggen tussen taalkundige theorie en praktische implementatie, waarbij je vermogen wordt getest om ongestructureerde tekstdata te verwerken, analyseren en er betekenis uit te halen met zowel klassieke technieken als moderne deep-learningbenaderingen.
Syntactische analyse, ook wel syntaxanalyse of parsing genoemd, is een tekstanalyse die ons de logische betekenis achter de zin of een deel van de zin geeft. Ze richt zich op de relatie tussen woorden en de grammaticale structuur van zinnen. Je kunt ook zeggen dat het het verwerken van natuurlijke taal is met behulp van grammaticale regels.
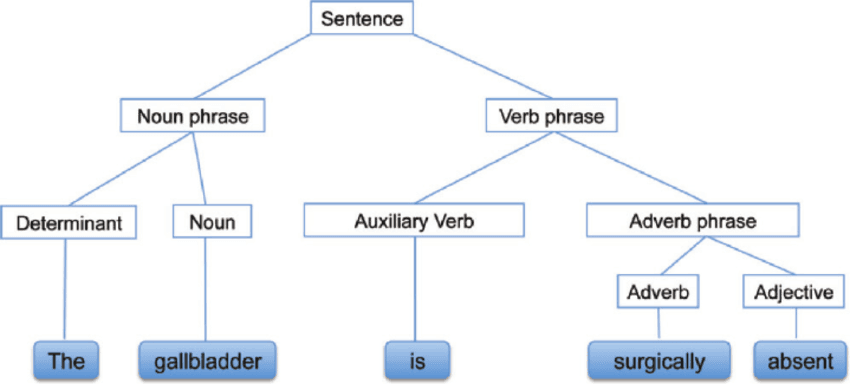
Syntactische analyse | researchgate
Stemming en lemmatisering zijn normalisatietechnieken die worden gebruikt om de structurele variatie van woorden in een zin te minimaliseren.
Stemming verwijdert de affixen die aan het woord zijn toegevoegd en laat het in stamvorm achter. Bijvoorbeeld: Changing naar Chang.
Het wordt veel gebruikt door zoekmachines voor opslagoptimalisatie. In plaats van alle vormen van de woorden op te slaan, slaan ze alleen de stammen op.
Lemmatisering zet het woord om naar zijn lemma. De output is het grondwoord in plaats van het stamwoord. Na lemmatisering krijgen we een geldig woord dat betekenis heeft. Bijvoorbeeld: Changing naar Change.

Stemming vs. lemmatisering | Auteur
Het optimaliseren van grote transformers vereist het aanpakken van zowel geheugenbandbreedte- als rekenknelpunten:
Leer de basis van NLP door de skill track Natural Language Processing in Python te voltooien.
Nu LLM's het huidige AI-landschap domineren, geven interviewers de voorkeur aan kandidaten die begrijpen hoe ze deze effectief inzetten. Deze sectie focust op enkele van de grootste praktische engineeringuitdagingen van 2026.
Een contextvenster van een LLM is de maximale hoeveelheid tekst (gemeten in tokens) die het model in één keer kan meenemen bij het genereren van een antwoord, en het beperkt direct hoeveel “werkgeheugen” het model effectief heeft.
Zelfs nu grote contextvensters vaker voorkomen, schalen prestatie en kosten niet lineair: lange prompts verhogen de latency en kunnen nog steeds tot betrouwbaarheidsproblemen leiden wanneer de relevante informatie diep in het midden van de context begraven ligt.
In interviews zou ik praktische strategieën uitleggen voor taken met lange documenten:
Hallucinaties treden op wanneer een LLM aannemelijk maar feitelijk onjuiste informatie genereert. In 2026 is mitigatie gelaagd:
Dit is een klassiek "trade-off"-vraagstuk. De beslissing hangt af van actualiteit van data en domeinspecificiteit:
De vraag wordt uitgebreider besproken in onze blog over RAG vs fine-tuning.
Reinforcement learning (RL) pakt problemen aan waarbij een agent leert door te interageren met een omgeving in plaats van uit statische datasets. Wees voorbereid om uit te leggen hoe RL werkt en kernconcepten zoals policies te bespreken.
Reinforcement learning gebruikt trial-and-error om doelen te bereiken. Het is een doelgericht algoritme en leert van de omgeving door de juiste stappen te zetten om de cumulatieve beloning te maximaliseren.
In een typisch reinforcement learning-proces:
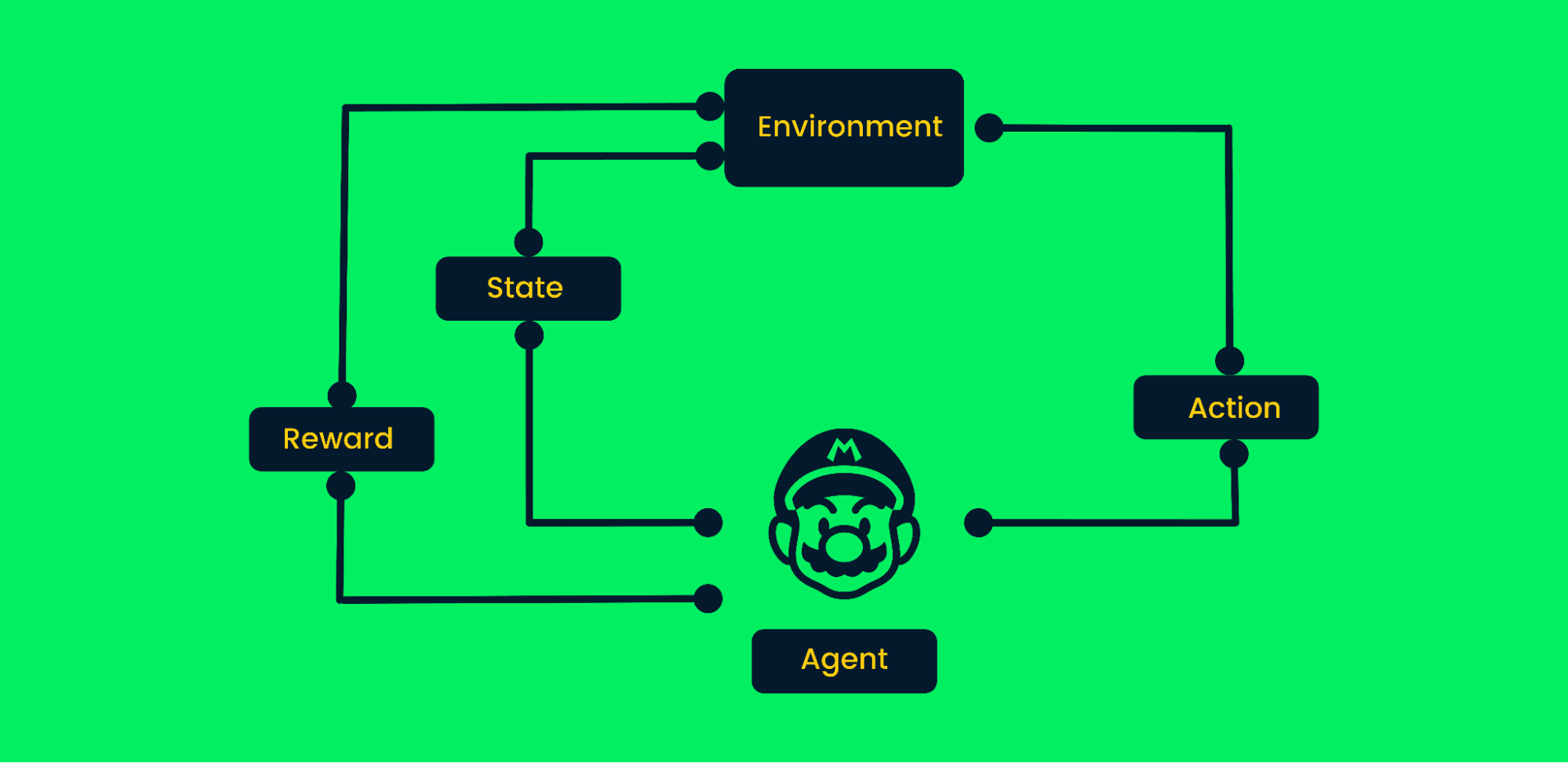
Reinforcement learning-framework | Auteur
On-policy-leeralgoritmen evalueren en verbeteren hetzelfde beleid om te handelen en bij te werken. Met andere woorden: het beleid dat wordt gebruikt voor het updaten en het beleid dat wordt gebruikt om te handelen zijn hetzelfde.
Target policy == Behavior policy
On-policy-algoritmen zijn Sarsa, Monte Carlo voor on-policy, value iteration en policy iteration
Off-policy-leeralgoritmen zijn volledig anders, omdat het geüpdatete beleid verschilt van het behavior policy. In Q-learning bijvoorbeeld leert de agent van een optimaal beleid met behulp van een greedy policy en onderneemt acties met andere policies.
Target policy != Behavior policy
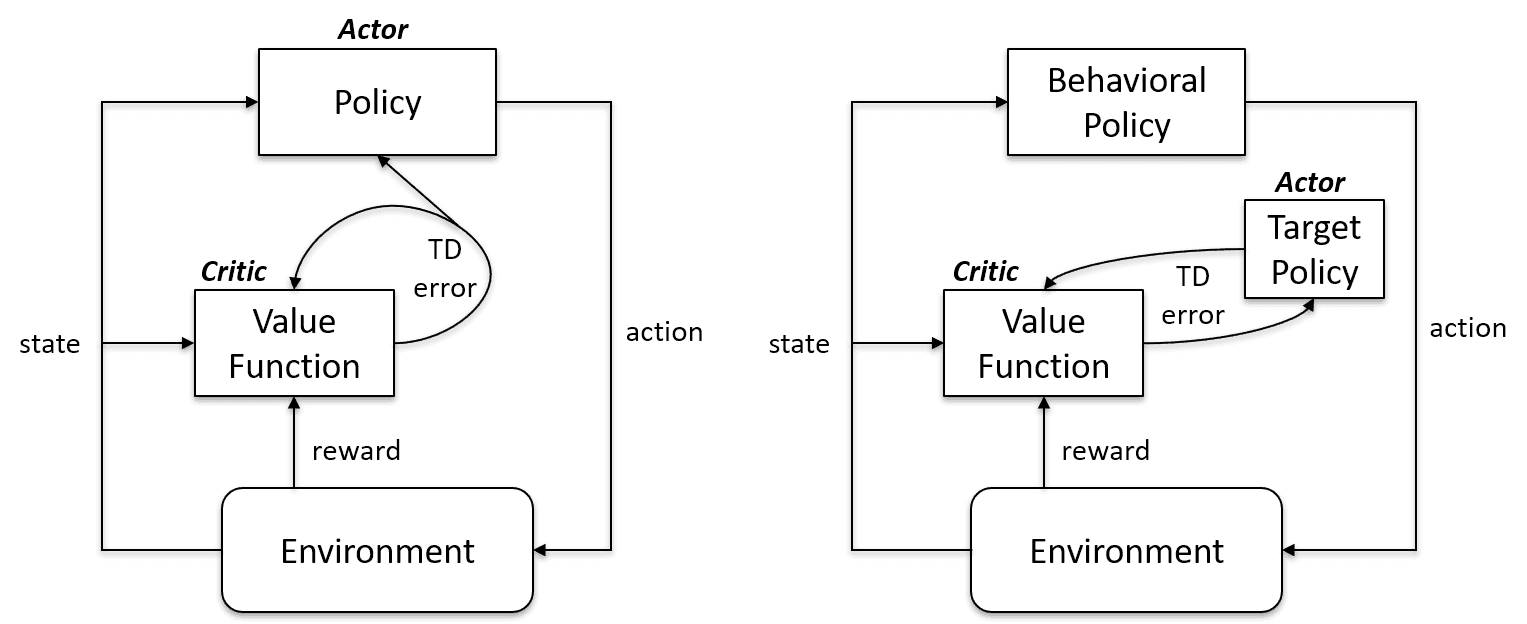
On-policy vs. off-policy | Artificial Intelligence Stack Exchange
Eenvoudig Q-learning is prima. Het lost het probleem op kleinere schaal op, maar faalt op grote schaal.
Stel dat de omgeving 1000 toestanden en 1000 acties per toestand heeft. We hebben dan een Q-tabel van miljoenen cellen nodig. Het spel schaken en Go vereisen een nog grotere tabel. Hier komt deep Q-learning te hulp.
Het gebruikt een neuraal netwerk om de Q-waardefunctie te benaderen. De neurale netwerken nemen toestanden als input en geven de Q-waarde van alle mogelijke acties als output.
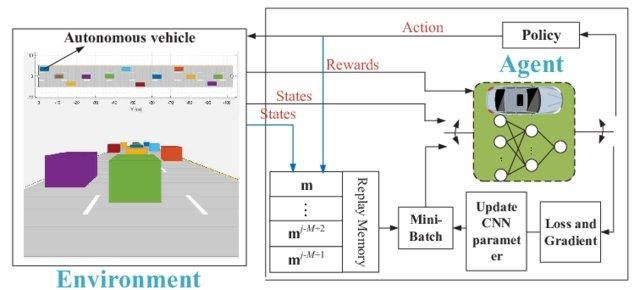
Deep Q-netwerk voor autonoom rijden | researchgate
Hieronder hebben we enkele mogelijke vragen uiteengezet die de interviewer je kan stellen bij enkele van de grootste techbedrijven:
Receiver operating characteristics (ROC) tonen de trade-off tussen sensitiviteit en specificiteit.
De curve wordt uitgezet met de false positive rate (FP/(TN + FP)) en true positive rate (TP/(TP + FN))
Het gebied onder de curve (AUC) toont de modelprestatie. Als het gebied onder de ROC-curve 0,5 is, is ons model volledig willekeurig. Een model met AUC dicht bij 1 is beter.
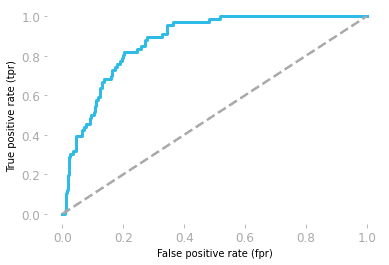
ROC-curve door Hadrien Jean
In tegenstelling tot classificatie (waar een antwoord goed of fout is), vereist GenAI vaak menselijke evaluatie of "LLM-as-a-Judge"-frameworks:
Voor dimensionale reductie kunnen we featureselectie of feature-extractiemethoden gebruiken.
Featureselectie is het proces van het kiezen van optimale features en het verwijderen van irrelevante features. We gebruiken filter-, wrapper- en embedded-methoden om feature-importance te analyseren en minder belangrijke features te verwijderen om de modelprestatie te verbeteren.
Feature-extractie transformeert de ruimte met meerdere dimensies naar minder dimensies. Er gaat geen informatie verloren tijdens dit proces en het gebruikt minder resources om de data te verwerken. De meest gangbare extractietechnieken zijn lineaire discriminantanalyse (LDA), kernel-PCA en quadratische discriminantanalyse.
In het geval van een spamclassificator geeft een logistische regressie een waarschijnlijkheid terug. We gebruiken ofwel de waarschijnlijkheid van 0,8999 of we zetten die om in een klasse (Spam/Geen spam) met behulp van een drempel.
Meestal is de drempel van een classificator 0,5, maar in sommige gevallen moeten we deze fijn afstellen om de nauwkeurigheid te verbeteren. De drempel van 0,5 betekent dat als de waarschijnlijkheid gelijk is aan of groter is dan 0,5, het spam is, en als deze lager is, het geen spam is.
Om de drempel te vinden, kunnen we precision-recall-curves en ROC-curves gebruiken, grid search en handmatig de waarde aanpassen om een betere CV te krijgen.
Word een professionele machine learning engineer door de Machine Learning Scientist with Python-carrièreroute te voltooien.
Lineaire regressie wordt gebruikt om de relatie tussen features (X) en doel (y) te begrijpen. Voordat we het model trainen, moeten we aan een paar aannames voldoen:
Let op: de residuen in lineaire regressie zijn het verschil tussen werkelijke en voorspelde waarden.
Tijdens codeerinterviews krijg je vragen over machine learning, maar in sommige gevallen beoordelen ze je Python-vaardigheden met algemene codeervragen. Word een expert Python-programmeur met de Python Programmer-carrièreroute.
Een bigramfunctie maken is vrij eenvoudig. Je hebt twee lussen nodig met de zip-functie.
zip gebruiken om een combinatie te maken van het vorige woord en het volgende woordHet is vrij eenvoudig als je het probleem opdeelt en zip gebruikt.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Resultaten:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]De activatiefunctie is een niet-lineaire transformatie in neurale netwerken. We voeren de input door de activatiefunctie voordat we deze naar de volgende laag sturen.
De netto-invoerwaarde kan variëren van -inf tot +inf, en het neuron weet niet hoe hij de waarden moet begrenzen en kan daardoor het vuurgepatroon niet bepalen. De activatiefunctie bepaalt of een neuron moet worden geactiveerd om de netto-invoerwaarden te begrenzen.
Meest voorkomende typen activatiefuncties:
Het antwoord is helemaal aan jou. Maar voordat je antwoordt, moet je bedenken welk zakelijk doel je wilt bereiken om een prestatiemetric te kiezen en hoe je de data gaat verzamelen.
In een typisch machine-learning-systeemontwerp:
Je moet ervoor zorgen dat je de focus legt op het ontwerp in plaats van op theorie of modelarchitectuur. Zorg dat je praat over modelinference en hoe het verbeteren daarvan de totale opbrengsten verhoogt.
Geef ook een overzicht van waarom je een bepaalde methodologie boven een andere hebt gekozen.
Leer meer over het bouwen van recommendsystemen met een DataCamp-cursus.
Het oplossen van codeeruitdagingen en werken aan je Python-vaardigheden vergroot je kans om de codeerfase van het interview te halen.
Voordat je begint met oplossen, moet je de vraag begrijpen. Je moet simpelweg een booleaanse functie maken die True retourneert als je door de letters in string B te verschuiven string A krijgt.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueEnsemble learning wordt gebruikt om de inzichten van meerdere machine-learningmodellen te combineren om de nauwkeurigheid en prestatiemetrics te verbeteren.
Eenvoudige ensemblemethoden:
Geavanceerde ensemblemethoden:
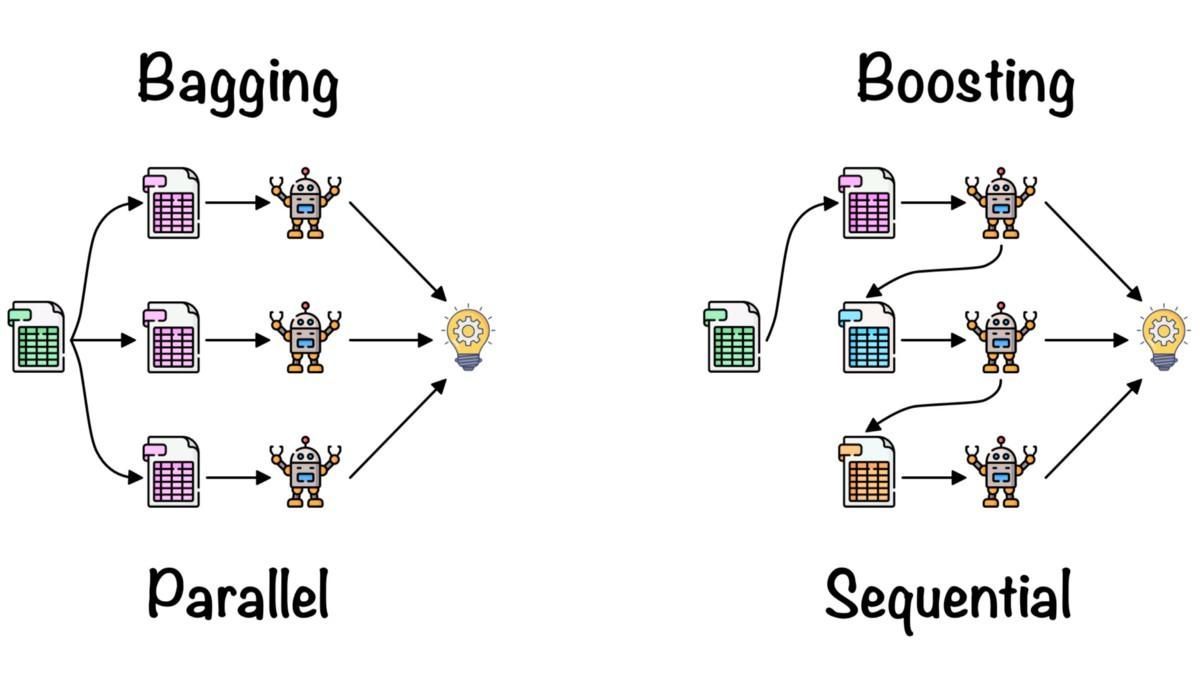
Bagging en boosting door Fernando López
Leer meer over middelen, bagging, stacking en boosting met de cursus Ensemble Methods in Python.
Nu we onze verkenning van essentiële vragen voor sollicitaties over machine learning afronden, is het duidelijk dat succes in zulke gesprekken een mix vereist van theoretische kennis, praktische vaardigheden en bewustzijn van de nieuwste trends en technologieën in het veld. Van het begrijpen van basisconcepten zoals semi-supervised learning en algoritmekeuze, tot het verdiepen in de complexiteit van specifieke algoritmen zoals KNN, en het aangaan van rolspecifieke uitdagingen in NLP, computer vision of reinforcement learning: de reikwijdte is groot.
Of je nu een beginner bent die het veld wil betreden of een ervaren professional die verder wil groeien, continu leren en oefenen is de sleutel. DataCamp biedt een uitgebreide Machine Learning Scientist with Python-route die een gestructureerde en diepgaande manier biedt om je vaardigheden te verbeteren.
Cursussen over machine learning
Cursus
Cursus
blog
Adel Nehme
15 min
