
Program
AI Temelleri
10 sa
Yapay Zekâ (YZ) geliştirmesindeki ivme, bilgi işlem gereksinimlerinde kayda değer bir artış yaratarak güçlü donanım çözümlerine olan ihtiyacı artırdı. Grafik İşleme Birimleri (GPU’lar) ve Tensör İşleme Birimleri (TPU’lar) bu gereksinimleri karşılamada kilit teknolojiler olarak öne çıktı.
Başlangıçta grafik oluşturmaya yönelik tasarlanan GPU’lar, paralel işlem yetenekleri sayesinde YZ görevlerini verimli şekilde üstlenebilen çok yönlü işlemcilere dönüştü. Buna karşın Google tarafından geliştirilen TPU’lar, özellikle YZ hesaplamalarına optimize edilmiştir ve makine öğrenimi projeleri gibi görevlere özel, üstün performans sunar.
Bu yazıda GPU ve TPU’ları performans, maliyet, ekosistem ve daha pek çok ölçüte göre karşılaştıracağız. Ayrıca enerji verimlilikleri, çevresel etkileri ve kurumsal uygulamalardaki ölçeklenebilirliklerini de ele alacağız.
GPU’lar, başlangıçta bilgisayarlar ve oyun konsollarında görüntü ve grafik oluşturmaya yönelik geliştirilmiş özel işlemcilerdir. CPU’larda olduğu gibi işleri tek tek yapmak yerine, karmaşık problemleri birden fazla göreve ayırıp bunlar üzerinde eşzamanlı çalışırlar.
Paralel işlem gücü sayesinde yetenekleri grafik işlemenin çok ötesine geçmiş; YZ modellerinin geliştirilmesi gibi çeşitli bilgi işlem uygulamalarında vazgeçilmez bileşenler hâline gelmiştir.
Ama biraz geriye saralım.
GPU’lar ilk kez 1980’lerde grafik oluşturmayı hızlandıran özel donanımlar olarak sahneye çıktı. NVIDIA ve ATI (şimdi AMD’nin bir parçası) gibi şirketler bu alanda öncü rol oynadı. Ancak asıl yaygınlaşmaları 1990’ların sonu ve 2000’lerin başını buldu. Bunun nedeni, geliştiricilerin grafiğin ötesindeki görevler için paralel işlemden yararlanmasını sağlayan programlanabilir gölgelendiricilerin (shader) tanıtılmasıydı.
2000’lerde, grafik dışındaki genel amaçlı hesaplama görevleri için GPU’ların kullanımına yönelik araştırmalar arttı. NVIDIA’nın CUDA’sı (Compute Unified Device Architecture) ve AMD’nin Stream SDK’sı, geliştiricilerin GPU işlem gücünden bilimsel simülasyonlar, veri analizi ve daha fazlası için yararlanmasına olanak sağladı.
Ardından YZ ve derin öğrenme yükselişe geçti.
GPU’lar, büyük miktarda veriyi işleme ve hesaplamaları paralel yürütme yetenekleri sayesinde derin öğrenme modellerini eğitmek ve dağıtmak için vazgeçilmez araçlar olarak öne çıktı.
TensorFlow ve PyTorch gibi çerçeveler GPU hızlandırmasından yararlanır ve derin öğrenmeyi dünyanın dört bir yanındaki araştırmacı ve geliştiriciler için erişilebilir kılar.
Tensör İşleme Birimleri (TPU’lar), Google tarafından makine öğreniminin artan hesaplama gereksinimlerini karşılamak için öncülük edilen, uygulamaya özel tümleşik devrelerdir (ASIC).
Başlangıçta grafik işleme için oluşturulup sonradan YZ ihtiyaçlarına uyarlanan GPU’ların aksine TPU’lar, makine öğrenimi iş yüklerini hızlandırmak amacıyla özel olarak tasarlanmıştır.
Makine öğrenimi için tasarlandıklarından, TPU’lar derin öğrenme algoritmalarının temelini oluşturan tensör işlemlerine özel olarak mühendislenmiştir.
Özel mimarileri, sinir ağlarındaki temel işlem olan matris çarpımına optimize edildiği için, büyük veri hacimlerini işleme ve karmaşık sinir ağlarını verimli biçimde yürütmede mükemmeldir; bu da hızlı eğitim ve çıkarım (inference) süreleri sağlar.
Bu uzmanlaşmış optimizasyon, TPU’ları YZ uygulamaları için vazgeçilmez kılar ve makine öğrenimi araştırmaları ile dağıtımındaki ilerlemeleri hızlandırır.
TPU ve GPU’lar farklı avantajlar sunar ve farklı hesaplama görevlerine göre optimize edilmiştir. Her ikisi de makine öğrenimi iş yüklerini hızlandırabilse de mimarileri ve optimizasyonları, belirli göreve bağlı olarak performansta farklılıklara yol açar.
Öncelikle, hem GPU’lar hem de TPU’lar YZ görevlerinde performansı artırmak için tasarlanmış özel donanım hızlandırıcılarıdır; ancak hesaplama mimarileri farklıdır ve bu da belirli hesaplama türlerini ele almada verimlilik ve etkililiklerini önemli ölçüde etkiler.
GPU’lar, paralel işlem için tasarlanmış binlerce küçük ve verimli çekirdekten oluşur.
Bu mimari, birden fazla görevi aynı anda yürütmelerini sağlar; bu da onları grafik oluşturma ve derin öğrenme gibi paralelleştirilebilen görevlerde son derece etkili kılar.
GPU’lar, sinir ağı hesaplamalarında yaygın olan matris işlemlerinde özellikle ustadır. Büyük veri hacimlerini işleyip hesaplamaları paralel yürütme yetenekleri, devasa veri kümelerinin işlendiği ve karmaşık matematiksel işlemlerin yürütüldüğü YZ görevleri için onları son derece uygun hâle getirir.
Buna karşılık TPU’lar tensör işlemlerini önceliklendirir ve bu sayede hesaplamaları verimli biçimde gerçekleştirir. TPU’ların GPU’lar kadar çok çekirdeği olmayabilir; ancak uzmanlaşmış mimarileri, özellikle tensör işlemlerine yoğun şekilde dayanan belirli YZ görevlerinde GPU’ları geride bırakmalarını sağlar.
Öte yandan GPU’lar, paralel işlemden fayda sağlayan görevlerde üstün performans gösterir ve grafik oluşturma ile bilimsel simülasyonlar gibi YZ’nin ötesindeki çeşitli hesaplamalara da uygundur.
TPU’lar ise tensör işlemeye optimize edilmiştir; matris işlemlerini içeren derin öğrenme görevlerinde son derece verimlidir. YZ iş yükünün özel gereksinimlerine bağlı olarak daha iyi performans ve verimliliği GPU’lar da TPU’lar da sunabilir.
GPU’lar, derin öğrenme modellerinin eğitimi ve çıkarım işlemleri dâhil olmak üzere çeşitli YZ görevlerini ele almadaki çok yönlülükleriyle bilinir. Bunun nedeni, paralel işlemeye dayanan GPU mimarisinin pek çok YZ modelinde eğitim ve çıkarım hızını önemli ölçüde artırmasıdır. Örneğin, bir BERT modeliyle 128 dizinin işlenmesi V100 GPU’da 3,8 milisaniye sürerken TPU v3’te 1,7 milisaniye sürer.
Buna karşılık TPU’lar, sinir ağlarının kritik bileşenleri olan tensör işlemlerini hızlı ve verimli şekilde gerçekleştirmek üzere ince ayar yapılmıştır. Bu uzmanlaşma, özellikle Google tarafından optimize edilen, kapsamlı sinir ağı eğitimi ve karmaşık makine öğrenimi modelleri gibi belirli derin öğrenme görevlerinde TPU’ların GPU’ları geride bırakmasını sağlayabilir.
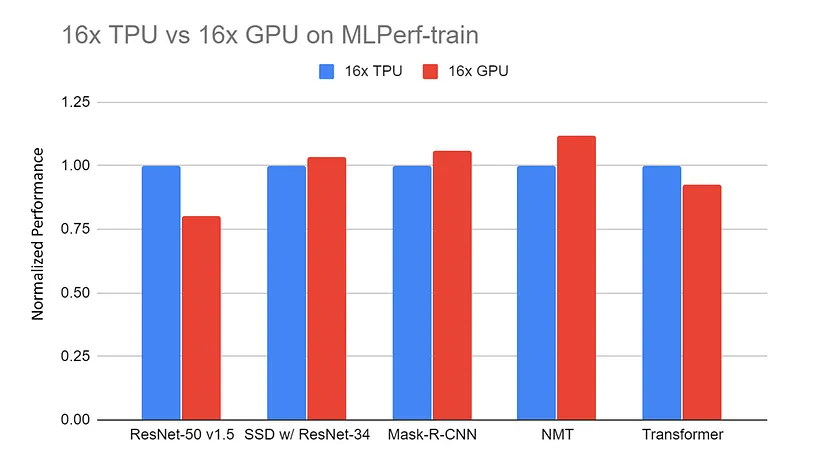
16x GPU sunucu (DGX-2H) ile 16x TPU v3 sunucu MLPerf-train kıyaslamalarında normalize edilmiş performans karşılaştırması. Veriler MLPerf web sitesinden alınmıştır. Tüm TPU sonuçları TensorFlow kullanır. Tüm GPU sonuçları Pytorch kullanır; ResNet ise MxNet kullanır |
Kaynak: TPU vs. GPU vs Cerebras vs. Graphcore: ML Donanımları Arasında Adil Bir Karşılaştırma, yazar: Mahmoud Khairy
Benzer görevlerde yapılan karşılaştırmalar, mimarilerine özel olarak uyarlanmış işlerde TPU’ların sıklıkla GPU’ları geride bıraktığını, daha hızlı eğitim süreleri ve daha etkili işlem sunduğunu gösterir.
Örneğin, CIFAR-10 veri kümesinde ResNet-50 modelini 10 epoch eğitmek, NVIDIA Tesla V100 GPU ile yaklaşık 40 dakika sürerken (epoch başına ortalama 4 dakika), Google Cloud TPU v3 ile aynı eğitim sadece 15 dakika sürer (epoch başına ortalama 1,5 dakika).
Bununla birlikte, GPU’lar uyarlanabilirlikleri ve topluluk tarafından yapılan kayda değer optimizasyon çalışmaları sayesinde daha geniş bir uygulama yelpazesinde rekabetçi performansını korur.
GPU ile TPU arasında seçim; bütçe, bilgi işlem ihtiyaçları ve erişilebilirliğe bağlıdır. Her seçenek farklı uygulamalar için özgün avantajlar sunar. Bu bölümde, GPU ve TPU’ların maliyet ve pazara erişim açısından nasıl karşılaştırıldığını göreceğiz.
Maliyet söz konusu olduğunda GPU’lar, TPU’lara kıyasla çok daha fazla esneklik sunar. Öncelikle TPU’lar tekil ürün olarak satılmaz; yalnızca Google Cloud Platform (GCP) gibi sağlayıcılar üzerinden bulut hizmeti olarak sunulurlar. Buna karşılık GPU’lar tekil olarak satın alınabilir.
Bir NVIDIA Tesla V100 GPU’nun yaklaşık maliyeti birim başına 8.000 – 10.000 ABD doları, bir NVIDIA A100 GPU birimi ise 10.000 – 15.000 ABD doları arasındadır. Ancak isteğe bağlı bulut fiyatlandırması seçeneğiniz de vardır.
NVIDIA Tesla V100 GPU kullanarak bir derin öğrenme modelini eğitmenin saatlik maliyeti yaklaşık 2,48 ABD doları; NVIDIA A100 için ise yaklaşık 2,93 ABD dolarıdır. Öte yandan Google Cloud TPU V3 saatte yaklaşık 4,50 ABD doları; Google Cloud TPU V4 ise yaklaşık 8,00 ABD dolarıdır.
Başka bir deyişle, TPU’lar GPU’lara göre çok daha az esnektir ve genellikle isteğe bağlı bulut bilişimde saatlik maliyetleri daha yüksektir. Ancak TPU’lar sıklıkla daha hızlı performans sunduğundan, büyük ölçekli makine öğrenimi görevleri için gereken toplam hesaplama süresini azaltabilir; bu da saatlik ücretler daha yüksek olsa bile toplam maliyet tasarrufu sağlayabilir.
Pazarda TPU ve GPU’ların bulunabilirliği büyük farklılıklar gösterir ve bu durum farklı sektörler ve bölgelerde benimsenmelerini etkiler…
Google tarafından geliştirilen TPU’lara, çoğunlukla bulut tabanlı YZ görevleri için Google Cloud Platform (GCP) üzerinden erişilir. Bu da esasen bilgi işlem ihtiyaçları için GCP’ye güvenen kişiler tarafından kullanıldıkları anlamına gelir; bu nedenle, teknoloji merkezleri veya internet altyapısının güçlü olduğu yerler gibi bulut bilişime ağırlık veren bölgeler ve sektörlerde daha popüler olabilirler.
Öte yandan GPU’lar NVIDIA, AMD ve Intel gibi şirketler tarafından üretilir ve hem tüketiciler hem de işletmeler için çeşitli seçeneklerle sunulur. Bu geniş erişilebilirlik, GPU’ları oyun, bilim, finans, sağlık ve üretim dâhil olmak üzere çok sayıda sektörde popüler bir tercih hâline getirir. GPU’lar şirket içinde (on-premises) veya bulutta kurulabilir; bu da kullanıcılara bilgi işlem kurulumlarında esneklik sağlar.
Sonuç olarak, teknoloji altyapısı veya bilgi işlem ihtiyaçları ne olursa olsun, farklı sektör ve bölgelerde GPU’ların kullanılması daha olasıdır. Genel olarak, TPU ve GPU’ların pazardaki erişilebilirliği benimsenme biçimlerini etkiler: TPU’lar bulut odaklı alan ve sektörlerde (ör. makine öğrenimi) daha yaygınken, GPU’lar farklı alan ve konumlarda geniş ölçüde kullanılır.
Google’ın TPU’ları, önde gelen açık kaynaklı makine öğrenimi çerçevesi olan TensorFlow ile sıkı şekilde tümleştirilmiştir. Yüksek performanslı sayısal hesaplama için bir başka kütüphane olan JAX de TPU’ları destekler ve verimli makine öğrenimi ile bilimsel hesaplamaya imkân tanır.
TPU’lar, TensorFlow ekosistemine sorunsuz şekilde entegredir; böylece TensorFlow kullanıcılarının TPU yeteneklerinden yararlanması kolaylaşır. Örneğin TensorFlow, TPU’lar için hesaplamaları optimize eden TensorFlow XLA (Accelerated Linear Algebra) derleyicisi gibi araçlar sunar.
Özetle TPU’lar, TensorFlow işlemlerini hızlandırmak üzere tasarlanmıştır ve eğitim ile çıkarım için optimize edilmiş performans sağlar. Ayrıca TensorFlow’un üst düzey API’lerini destekler; bu da modellerin TPU üzerinde çalıştırılması için taşınmasını ve optimize edilmesini kolaylaştırır.
Buna karşılık GPU’lar, çeşitli sektörler ve araştırma alanlarında yaygın şekilde benimsenmiştir ve farklı makine öğrenimi uygulamaları için popülerdir. Bu, GPU’ların daha fazla tümleşime sahip olduğu ve TensorFlow, PyTorch, Keras, MXNet ve Caffe dâhil olmak üzere daha geniş bir derin öğrenme çerçevesi yelpazesi tarafından desteklendiği anlamına gelir.
GPU’lar ayrıca CUDA, cuDNN ve RAPIDS gibi kapsamlı kütüphane ve araçlardan yararlanarak çok yönlülüklerini ve farklı makine öğrenimi ile veri bilimi iş akışlarına entegrasyon kolaylığını daha da artırır.
Topluluk desteği açısından GPU’lar; NVIDIA, AMD ve topluluk odaklı platformlar gibi çeşitli kaynaklardan geniş forumlar, eğitimler ve dokümantasyon içeren daha geniş bir ekosisteme sahiptir. Geliştiriciler, yardım almak, bilgi paylaşmak ve projelerde iş birliği yapmak için canlı çevrimiçi topluluklara, forumlara ve kullanıcı gruplarına erişebilir. Ayrıca GPU programlama, derin öğrenme çerçeveleri ve optimizasyon tekniklerini kapsayan çok sayıda eğitim, kurs ve dokümantasyon kaynağı mevcuttur.
TPU’lar için topluluk desteği ise daha çok Google ekosistemi etrafında merkezileşmiştir ve kaynaklar ağırlıklı olarak GCP dokümantasyonu, forumları ve destek kanalları üzerinden sunulur. Google, TPU’ların TensorFlow ile kullanımına özel olarak hazırlanmış kapsamlı dokümantasyon ve eğitimler sağlasa da, topluluk desteği daha geniş GPU ekosistemine kıyasla sınırlı olabilir. Yine de Google’ın resmî destek kanalları ve geliştirici kaynakları, YZ iş yükleri için TPU kullanan geliştiricilere değerli destek sunar.
GPU ve TPU’ların enerji verimliliği, mimarilerine ve hedeflenen uygulamalara göre değişir. Genel olarak TPU’lar, özellikle Google Cloud TPU v3, üst düzey NVIDIA GPU’lara kıyasla belirgin biçimde daha enerji verimlidir.
Daha fazla bağlam için:
TPU’ların daha düşük güç tüketimi, özellikle büyük ölçekli makine öğrenimi dağıtımlarında, çok daha düşük işletme maliyetlerine ve artan enerji verimliliğine katkıda bulunabilir.
TPU ve GPU’lar, büyük ölçekli YZ işlemlerini yürütürken enerji verimliliğini artırmak için belirli optimizasyonlar uygular.
Yazının önceki kısımlarında belirtildiği gibi TPU mimarisi, sinir ağlarında yaygın olarak kullanılan tensör işlemlerini önceliklendirir ve bu sayede YZ görevlerinin minimum enerji tüketimiyle verimli şekilde yürütülmesini sağlar. TPU’lar ayrıca YZ hesaplamaları için optimize edilmiş özel bellek hiyerarşilerine sahiptir; bu da bellek erişim gecikmesini ve enerji yükünü azaltır.
Kantizasyon ve seyrekleştirme (sparsity) gibi tekniklerden yararlanarak aritmetik işlemleri optimize ederler; böylece doğruluktan ödün vermeden güç tüketimini en aza indirirler. Bu etkenler, TPU’ların enerji tasarrufu yaparken yüksek performans sunmasını sağlar.
Benzer şekilde GPU’lar da YZ işlemlerinde performansı artırmak için enerji verimli optimizasyonlar uygular. Modern GPU mimarileri, iş yükü taleplerine göre güç tüketimini ayarlamak için güç kapılama (power gating) ve dinamik voltaj/frekans ölçekleme (DVFS) gibi özellikleri içerir. Ayrıca hesaplama görevlerini birden fazla çekirdeğe dağıtmak için paralel işlem tekniklerini kullanırlar; bu da işlem başına enerjiyi en aza indirirken verimi en üst düzeye çıkarır.
GPU üreticileri, veri aktarımı sırasında enerji tüketimini azaltmak ve bellek erişim örüntülerini optimize etmek için enerji verimli bellek mimarileri ve önbellek hiyerarşileri geliştirir. Çekirdek birleştirme (kernel fusion) ve döngü açma (loop unrolling) gibi yazılım teknikleriyle birleştiğinde bu optimizasyonlar, GPU hızlandırmalı YZ iş yüklerinde enerji verimliliğini daha da artırır.
TPU ve GPU’lar, büyük YZ projeleri için ölçeklenebilirlik sunar; ancak bunu farklı şekilde gerçekleştirir. TPU’lar özellikle Google Cloud Platform (GCP) üzerinden bulut altyapısına sıkı şekilde entegredir ve YZ iş yükleri için ölçeklenebilir kaynaklar sunar. Kullanıcılar, hesaplama ihtiyaçlarına göre talep üzerine TPU’lara erişebilir; bu da büyük ölçekli YZ projelerini verimli şekilde yönetmek açısından kritiktir. Google, TPU üzerinde YZ modellerini dağıtmaya yönelik yönetilen hizmetler ve önceden yapılandırılmış ortamlar sağlar ve bulut altyapısına entegrasyon sürecini basitleştirir.
Öte yandan GPU’lar da büyük YZ projeleri için etkili şekilde ölçeklenir; Amazon Web Services (AWS) ve Microsoft Azure gibi sağlayıcıların sunduğu bulut ortamlarında kullanılabildikleri gibi şirket içinde de dağıtılabilirler. GPU’lar, daha yüksek hesaplama gücü için birden fazla GPU’nun paralel olarak devreye alınmasına olanak tanıyan esnek ölçekleme imkânı sunar.
Ayrıca GPU’lar, yüksek bellek bant genişliği ve paralel işlem yetenekleri sayesinde büyük veri kümelerini ele almakta mükemmeldir. Bu da çok büyük veri kümeleriyle uğraşan büyük ölçekli YZ projeleri için gerekli olan verimli veri işleme ve model eğitimini mümkün kılar.
Özetle, hem TPU’lar hem de GPU’lar büyük YZ projeleri için ölçeklenebilirlik sunar; TPU’lar bulut altyapısına sıkı şekilde entegreyken, GPU’lar şirket içi veya bulut tabanlı dağıtım için esneklik sağlar. Büyük veri kümelerini ele alma ve hesaplama kaynaklarını ölçekleme yetenekleri, karmaşık YZ görevlerini büyük ölçekte çözmede onları vazgeçilmez kılar.
| Özellik | GPU’lar | TPU’lar |
|---|---|---|
| Hesaplama Mimarisi | Paralel işlem için binlerce küçük ve verimli çekirdek | Tensör işlemlerini önceliklendirir, uzmanlaşmış mimari |
| Performans | Çok yönlüdür; derin öğrenme ve çıkarım dâhil çeşitli YZ görevlerinde üstündür | Tensör işlemleri için optimize edilmiştir; belirli derin öğrenme görevlerinde sıklıkla GPU’ları geride bırakır |
| Hız ve Verimlilik | Örn., BERT ile 128 dizi: V100 GPU’da 3,8 ms | Örn., BERT ile 128 dizi: TPU v3’te 1,7 ms |
| Kıyaslamalar | ResNet-50, CIFAR-10: Tesla V100 GPU’da 10 epoch için 40 dakika (epoch başına 4 dakika) | ResNet-50, CIFAR-10: Google Cloud TPU v3’te 10 epoch için 15 dakika (epoch başına 1,5 dakika) |
| Maliyet | NVIDIA Tesla V100: 8.000 - 10.000 $/birim, 2,48 $/saat; NVIDIA A100: 10.000 - 15.000 $/birim, 2,93 $/saat | Google Cloud TPU v3: 4,50 $/saat; TPU v4: 8,00 $/saat |
| Erişilebilirlik | Birden çok satıcıdan (NVIDIA, AMD, Intel) geniş ölçekte, tüketici ve işletmeler için mevcut | Esasen Google Cloud Platform (GCP) üzerinden erişilebilir |
| Ekosistem ve Geliştirme Araçları | Birçok çerçeve tarafından desteklenir (TensorFlow, PyTorch, Keras, MXNet, Caffe); kapsamlı kütüphaneler (CUDA, cuDNN, RAPIDS) | TensorFlow ile entegredir, JAX’i destekler, TensorFlow XLA derleyicisiyle optimize edilir |
| Topluluk Desteği ve Kaynaklar | NVIDIA, AMD ve topluluklardan geniş forumlar, eğitimler ve dokümantasyon içeren yaygın ekosistem | Google ekosistemi etrafında merkezileşmiştir; GCP dokümantasyonu, forumları ve destek kanalları |
| Enerji Verimliliği | NVIDIA Tesla V100: 250 watt; NVIDIA A100: 400 watt | Google Cloud TPU v3: 120-150 watt; TPU v4: 200-250 watt |
| YZ Görevleri için Optimizasyon | Enerji verimli optimizasyonlar (güç kapılama, DVFS, paralel işlem, çekirdek birleştirme) | Özel bellek hiyerarşileri, kantizasyon ve seyrekleştirme ile verimli YZ hesaplaması |
| Kurumsal Uygulamalarda Ölçeklenebilirlik | Büyük YZ projeleri için ölçeklenebilir; şirket içi veya bulut (AWS, Azure); yüksek bellek bant genişliği, paralel işlem | Bulut altyapısına (GCP) sıkı entegrasyon; isteğe bağlı ölçeklenebilirlik; YZ modellerini dağıtmak için yönetilen hizmetler |
Şu durumlarda GPU’ları seçin:
Şu durumlarda TPU’ları seçin:
GPU ve TPU’lar, YZ uygulamalarında kullanılan özel donanım hızlandırıcılarıdır. Başlangıçta grafik oluşturmaya yönelik geliştirilen GPU’lar, paralel işlemde üstün olup YZ görevlerine uyarlanmış, çeşitli sektörlerde çok yönlülük sunar. TPU’lar ise Google tarafından YZ iş yükleri için özel olarak üretilmiş olup sinir ağlarında yaygın olan tensör işlemlerini önceliklendirir.
Bu makale, GPU ve TPU teknolojilerini performans, maliyet ve erişilebilirlik, ekosistem ve geliştirme, enerji verimliliği ve çevresel etki ile YZ uygulamalarındaki ölçeklenebilirlik açısından karşılaştırdı. TPU ve GPU’lar hakkında öğrenmeye devam etmek için aşağıdaki kaynaklara göz atın:
DataCamp ile YZ Becerileri Öğrenin
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
