
Leerpad
AI-basisprincipes
10 Hr
De opmars van Artificial Intelligence (AI) heeft geleid tot een duidelijke toename van de rekenvraag, waardoor de behoefte aan robuuste hardwareoplossingen groeit. Graphics Processing Units (GPU’s) en Tensor Processing Units (TPU’s) zijn naar voren gekomen als sleuteltechnologieën om aan deze vraag te voldoen.
GPU’s waren oorspronkelijk bedoeld voor het renderen van graphics, maar zijn uitgegroeid tot veelzijdige processors die AI-taken efficiënt aankunnen dankzij hun parallelle verwerkingscapaciteiten. TPU’s daarentegen, ontwikkeld door Google, zijn specifiek geoptimaliseerd voor AI-berekeningen en bieden superieure prestaties die zijn afgestemd op taken zoals machine learning-projecten.
In dit artikel bespreken we GPU’s versus TPU’s en vergelijken we beide technologieën op basis van onder meer prestaties, kosten en ecosysteem. We geven je ook een overzicht van hun energie-efficiëntie, milieueffect en schaalbaarheid in enterprise-toepassingen.
GPU’s zijn gespecialiseerde processors die in eerste instantie zijn ontwikkeld voor het renderen van beelden en graphics in computers en gameconsoles. Ze werken door complexe problemen op te delen in meerdere taken en die gelijktijdig uit te voeren, in plaats van één voor één zoals bij CPU’s.
Dankzij hun parallelle verwerkingskracht reiken hun mogelijkheden inmiddels veel verder dan alleen graphics. Ze zijn een essentieel onderdeel geworden in diverse computertoepassingen, zoals de ontwikkeling van AI-modellen.
Maar laten we even terugspoelen.
GPU’s verschenen in de jaren tachtig als gespecialiseerde hardware om graphicsrendering te versnellen. Bedrijven als NVIDIA en ATI (nu onderdeel van AMD) speelden een sleutelrol in hun ontwikkeling. Toch wonnen ze pas echt aan populariteit in de late jaren negentig en vroege jaren 2000. Dat kwam door de introductie van programmeerbare shaders, waardoor ontwikkelaars parallelle verwerking ook voor niet-graphicstaken konden benutten.
In de jaren 2000 werd meer onderzoek gedaan naar GPU’s voor algemene rekentaken buiten graphics. NVIDIA’s CUDA (Compute Unified Device Architecture) en AMD’s Stream SDK maakten het voor ontwikkelaars mogelijk om de rekenkracht van GPU’s in te zetten voor wetenschappelijke simulaties, data-analyse en meer.
Daarna kwam de opkomst van AI en deep learning.
GPU’s werden onmisbaar voor het trainen en uitrollen van deep learning-modellen dankzij hun vermogen om enorme hoeveelheden data te verwerken en berekeningen parallel uit te voeren.
Frameworks als TensorFlow en PyTorch maken gebruik van GPU-versnelling, waardoor deep learning toegankelijk is geworden voor onderzoekers en ontwikkelaars wereldwijd.
Tensor Processing Units (TPU’s) zijn een type application-specific integrated circuit (ASIC) dat door Google is ontwikkeld om te voldoen aan de groeiende rekenvraag van machine learning.
In tegenstelling tot GPU’s, die aanvankelijk voor graphics werden ontworpen en later zijn aangepast voor AI, zijn TPU’s specifiek ontwikkeld om machine learning-workloads te versnellen.
Omdat ze voor machine learning zijn ontworpen, zijn TPU’s specifiek afgestemd op tensor-bewerkingen, die fundamenteel zijn voor deep learning-algoritmes.
Dankzij een op maat gemaakte architectuur die is geoptimaliseerd voor matrixvermenigvuldiging, een kernbewerking in neurale netwerken, blinken TPU’s uit in het verwerken van grote hoeveelheden data en het efficiënt uitvoeren van complexe neurale netwerken, met snelle training en inferentie als resultaat.
Deze gerichte optimalisatie maakt TPU’s onmisbaar voor AI-toepassingen en stimuleert vooruitgang in machine learning-onderzoek en -implementatie.
TPU’s en GPU’s hebben elk hun voordelen en zijn geoptimaliseerd voor verschillende rekentaken. Hoewel beide machine learning-workloads kunnen versnellen, leiden hun architecturen en optimalisaties tot prestatieverschillen afhankelijk van de specifieke taak.
Om te beginnen: zowel GPU’s als TPU’s zijn gespecialiseerde hardwareversnellers die de prestaties bij AI-taken verbeteren, maar ze verschillen qua computationele architectuur. Dat heeft grote impact op hun efficiëntie en effectiviteit bij specifieke soorten berekeningen.
GPU’s bestaan uit duizenden kleine, efficiënte cores die zijn ontworpen voor parallelle verwerking.
Deze architectuur maakt het mogelijk om meerdere taken tegelijk uit te voeren, wat ze zeer geschikt maakt voor taken die te paralleliseren zijn, zoals graphicsrendering en deep learning.
GPU’s zijn bijzonder bedreven in matrixbewerkingen, die veel voorkomen in berekeningen voor neurale netwerken. Doordat ze grote hoeveelheden data aankunnen en berekeningen parallel uitvoeren, zijn ze ideaal voor AI-taken waarbij enorme datasets en complexe wiskundige operaties komen kijken.
TPU’s daarentegen geven prioriteit aan tensorbewerkingen, waardoor ze berekeningen efficiënt kunnen uitvoeren. Hoewel TPU’s mogelijk niet zoveel cores hebben als GPU’s, stelt hun gespecialiseerde architectuur ze in staat om GPU’s te overtreffen bij bepaalde AI-taken, vooral die welke zwaar leunen op tensoroperaties.
Daar staat tegenover dat GPU’s uitblinken in taken die profiteren van parallelle verwerking en geschikt zijn voor uiteenlopende berekeningen buiten AI, zoals graphicsrendering en wetenschappelijke simulaties.
TPU’s zijn juist geoptimaliseerd voor tensorverwerking, waardoor ze zeer efficiënt zijn voor deep learning-taken met matrixoperaties. Afhankelijk van de specifieke eisen van de AI-workload kunnen GPU’s of TPU’s de betere prestaties en efficiëntie bieden.
GPU’s staan bekend om hun veelzijdigheid bij uiteenlopende AI-taken, waaronder het trainen van deep learning-modellen en het uitvoeren van inferentie. Dat komt doordat de GPU-architectuur, die berust op parallelle verwerking, de trainings- en inferentiesnelheid bij talloze AI-modellen aanzienlijk verhoogt. Zo duurt het verwerken van een batch van 128 sequenties met een BERT-model 3,8 milliseconde op een V100 GPU, vergeleken met 1,7 milliseconde op een TPU v3.
TPU’s daarentegen zijn fijn-afgestemd op snelle en efficiënte tensorbewerkingen, cruciale componenten van neurale netwerken. Deze specialisatie stelt TPU’s vaak in staat om GPU’s te overtreffen bij specifieke deep learning-taken, met name die door Google zijn geoptimaliseerd, zoals grootschalige training van neurale netwerken en complexe machine learning-modellen.
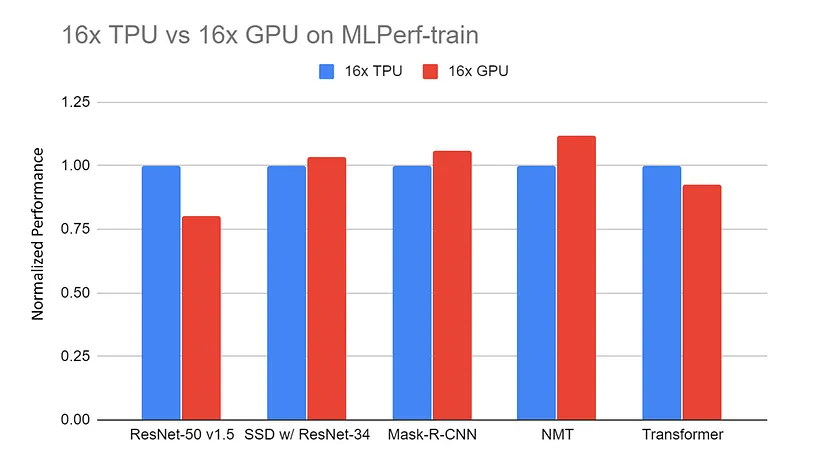
16x GPU-server (DGX-2H) vs 16x TPU v3-server, genormaliseerde prestaties op MLPerf-train-benchmarks. De data is verzameld van de MLPerf-website. Alle TPU-resultaten gebruiken TensorFlow. Alle GPU-resultaten gebruiken Pytorch, behalve ResNet dat MxNet gebruikt |
Bron: TPU vs. GPU vs Cerebras vs. Graphcore: A Fair Comparison between ML Hardware door Mahmoud Khairy
Vergelijkingen tussen TPU’s en GPU’s bij soortgelijke taken laten vaak zien dat TPU’s GPU’s overtreffen bij taken die specifiek op hun architectuur zijn toegesneden, met kortere trainingstijden en efficiëntere verwerking.
Zo duurt het trainen van een ResNet-50-model op de CIFAR-10-dataset gedurende 10 epochs met een NVIDIA Tesla V100 GPU ongeveer 40 minuten, gemiddeld 4 minuten per epoch. Met een Google Cloud TPU v3 duurt dezelfde training slechts 15 minuten, gemiddeld 1,5 minuut per epoch.
Toch blijven GPU’s competitieve prestaties leveren in een breder scala aan toepassingen dankzij hun flexibiliteit en de aanzienlijke optimalisatie-inspanningen vanuit de community.
De keuze tussen GPU en TPU hangt af van budget, rekenbehoeften en beschikbaarheid. Elke optie biedt unieke voordelen voor verschillende toepassingen. In dit onderdeel bekijken we hoe GPU’s en TPU’s zich verhouden qua kosten en marktbeschikbaarheid.
GPU’s bieden veel meer flexibiliteit dan TPU’s als het om kosten gaat. Om te beginnen: TPU’s worden niet los verkocht; ze zijn alleen als clouddienst beschikbaar via aanbieders zoals Google Cloud Platform (GCP). GPU’s daarentegen kun je afzonderlijk aanschaffen.
De geschatte kosten van een NVIDIA Tesla V100 GPU liggen tussen $8.000 en $10.000 per stuk, en een NVIDIA A100 GPU kost tussen $10.000 en $15.000 per stuk. Daarnaast is er de optie van on-demand cloudtarieven.
Het trainen van een deep learning-model met een NVIDIA Tesla V100 GPU kost je naar verwachting zo’n $2,48 per uur, en de NVIDIA A100 ongeveer $2,93. Aan de andere kant kost de Google Cloud TPU V3 rond de $4,50 per uur, en de Google Cloud TPU V4 ongeveer $8,00 per uur.
Met andere woorden: TPU’s zijn veel minder flexibel dan GPU’s en hebben over het algemeen hogere uurtarieven voor on-demand cloud computing dan GPU’s. Toch bieden TPU’s vaak snellere prestaties, wat de totale rekentijd voor grootschalige machine learning-taken kan verkorten en zo, ondanks het hogere uurtarief, mogelijk tot algehele kostenbesparingen leidt.
De beschikbaarheid van TPU’s en GPU’s op de markt verschilt sterk en beïnvloedt hun adoptie in verschillende sectoren en regio’s…
TPU’s, ontwikkeld door Google, zijn vooral toegankelijk via Google Cloud Platform (GCP) voor cloudgebaseerde AI-taken. Dat betekent dat ze voornamelijk worden gebruikt door mensen die voor hun rekencapaciteit op GCP vertrouwen, waardoor ze populairder kunnen zijn in regio’s en sectoren die sterk inzetten op cloud computing, zoals techhubs of plaatsen met goede internetverbindingen.
GPU’s daarentegen worden gemaakt door bedrijven als NVIDIA, AMD en Intel en zijn in allerlei varianten beschikbaar voor zowel consumenten als bedrijven. Die brede beschikbaarheid maakt GPU’s een populaire keuze in uiteenlopende sectoren, waaronder gaming, wetenschap, financiën, zorg en productie. GPU’s kunnen on-premises of in de cloud worden ingezet, wat gebruikers flexibiliteit geeft in hun rekeninfrastructuur.
Daardoor worden GPU’s waarschijnlijker ingezet in verschillende sectoren en regio’s, ongeacht hun techinfrastructuur of rekeneisen. Al met al beïnvloedt de marktbeschikbaarheid van TPU’s en GPU’s hoe ze worden geadopteerd: TPU’s komen vaker voor in cloudgerichte gebieden en sectoren (zoals machine learning), terwijl GPU’s breed worden gebruikt in uiteenlopende vakgebieden en locaties.
Google’s TPU’s zijn nauw geïntegreerd met TensorFlow, Google’s toonaangevende open-source machine learning-framework. JAX, een andere bibliotheek voor high-performance numerieke computing, ondersteunt eveneens TPU’s en maakt efficiënte machine learning en wetenschappelijke computing mogelijk.
TPU’s zijn naadloos ingebed in het TensorFlow-ecosysteem, waardoor TensorFlow-gebruikers eenvoudig de mogelijkheden van TPU’s kunnen benutten. Zo biedt TensorFlow tools zoals de TensorFlow XLA-compiler (Accelerated Linear Algebra), die berekeningen voor TPU’s optimaliseert.
Kortom, TPU’s zijn ontworpen om TensorFlow-bewerkingen te versnellen en geoptimaliseerde prestaties te bieden voor training en inferentie. Ze ondersteunen ook de high-level API’s van TensorFlow, waardoor het makkelijker wordt om modellen te migreren en te optimaliseren voor TPU-uitvoering.
GPU’s daarentegen zijn breed geadopteerd in uiteenlopende industrieën en onderzoeksvelden en daarom populair voor diverse machine learning-toepassingen. Dit betekent dat ze meer integraties hebben dan TPU’s en worden ondersteund door een breder scala aan deep learning-frameworks, waaronder TensorFlow, PyTorch, Keras, MXNet en Caffe.
GPU’s profiteren bovendien van uitgebreide bibliotheken en tools zoals CUDA, cuDNN en RAPIDS, wat hun veelzijdigheid en de makkelijke integratie in verschillende machine learning- en data science-workflows verder vergroot.
Wat communitysupport betreft, hebben GPU’s een breder ecosysteem met uitgebreide forums, tutorials en documentatie van bronnen zoals NVIDIA, AMD en communitygedreven platforms. Ontwikkelaars vinden levendige online communities, forums en gebruikersgroepen om hulp te vragen, kennis te delen en samen te werken aan projecten. Daarnaast zijn er tal van tutorials, cursussen en documentatie over GPU-programmering, deep learning-frameworks en optimalisatietechnieken.
De communitysupport voor TPU’s is centraler georganiseerd rond Google’s ecosysteem, met resources die vooral via GCP-documentatie, forums en supportkanalen beschikbaar zijn. Hoewel Google uitgebreide documentatie en tutorials biedt die specifiek zijn toegesneden op het gebruik van TPU’s met TensorFlow, kan de communitysupport beperkter zijn dan bij het bredere GPU-ecosysteem. Toch bieden de officiële supportkanalen en developersresources van Google waardevolle ondersteuning voor ontwikkelaars die TPU’s inzetten voor AI-workloads.
De energie-efficiëntie van GPU’s en TPU’s verschilt op basis van hun architecturen en beoogde toepassingen. Over het algemeen zijn TPU’s energiezuiniger dan GPU’s, met name de Google Cloud TPU v3, die aanzienlijk zuiniger is dan de high-end NVIDIA GPU’s.
Ter illustratie:
Het lagere stroomverbruik van TPU’s kan zorgen voor veel lagere operationele kosten en een hogere energie-efficiëntie, zeker bij grootschalige machine learning-implementaties.
TPU’s en GPU’s passen specifieke optimalisaties toe om energie-efficiëntie te verbeteren bij grootschalige AI-bewerkingen.
Zoals eerder vermeld is de TPU-architectuur ontworpen om tensorbewerkingen die veel voorkomen in neurale netwerken te prioriteren, zodat AI-taken efficiënt kunnen worden uitgevoerd met minimaal energieverbruik. TPU’s hebben ook aangepaste geheugenniveaus die zijn geoptimaliseerd voor AI-berekeningen, wat de geheugen-toegangslatentie en energie-overhead vermindert.
Ze benutten technieken zoals kwantisatie en sparsity om rekenkundige operaties te optimaliseren, waardoor het stroomverbruik daalt zonder aan nauwkeurigheid in te boeten. Deze factoren stellen TPU’s in staat hoge prestaties te leveren en toch zuinig met energie om te gaan.
Similarly, GPU’s implementeren energiezuinige optimalisaties om de prestaties bij AI-bewerkingen te verbeteren. Moderne GPU-architecturen bevatten functies als power gating en dynamische spannings- en frequentieschaling (DVFS) om het stroomverbruik aan te passen aan de werkbelasting. Ze gebruiken ook parallelle verwerkingstechnieken om rekenwerk te verdelen over meerdere cores, waardoor de throughput wordt gemaximaliseerd en het energieverbruik per operatie wordt geminimaliseerd.
GPU-fabrikanten ontwikkelen energiezuinige geheugenarchitecturen en cachehiërarchieën om geheugen-toegangspatronen te optimaliseren en het energieverbruik tijdens datatransfers te verlagen. Deze optimalisaties, in combinatie met softwaretechnieken zoals kernel fusion en loop unrolling, verhogen de energie-efficiëntie van GPU-versnelde AI-workloads verder.
Zowel TPU’s als GPU’s bieden schaalbaarheid voor grote AI-projecten, maar ze pakken dat anders aan. TPU’s zijn nauw geïntegreerd in cloudinfrastructuur, met name via Google Cloud Platform (GCP), en bieden schaalbare resources voor AI-workloads. Gebruikers kunnen TPU’s on-demand inzetten en op- of afschalen naar gelang de rekenbehoefte, wat cruciaal is voor het efficiënt afhandelen van grootschalige AI-projecten. Google levert beheerde services en vooraf geconfigureerde omgevingen voor het uitrollen van AI-modellen op TPU’s, wat de integratie in cloudinfrastructuur vereenvoudigt.
GPU’s schalen op hun beurt ook effectief voor grote AI-projecten, met opties voor on-premises implementatie of inzet in cloudomgevingen van aanbieders zoals Amazon Web Services (AWS) en Microsoft Azure. GPU’s bieden flexibiliteit in opschalen en maken het mogelijk om meerdere GPU’s parallel in te zetten voor extra rekenkracht.
Bovendien zijn GPU’s sterk in het verwerken van grote datasets dankzij hun hoge geheugendoorvoer en parallelle verwerkingscapaciteiten. Dit maakt efficiënte dataverwerking en modeltraining mogelijk, essentieel voor grootschalige AI-projecten met enorme datasets.
Kortom, zowel TPU’s als GPU’s bieden schaalbaarheid voor grote AI-projecten: TPU’s zijn strak verweven met cloudinfrastructuur, terwijl GPU’s flexibiliteit bieden voor on-premises of cloudgebaseerde inzet. Hun vermogen om grote datasets te verwerken en rekenresources op te schalen maakt ze van onschatbare waarde voor complexe AI-taken op schaal.
| Kenmerk | GPU’s | TPU’s |
|---|---|---|
| Computationele architectuur | Duizenden kleine, efficiënte cores voor parallelle verwerking | Prioriteren tensorbewerkingen, gespecialiseerde architectuur |
| Prestaties | Veelzijdig, uitstekend in diverse AI-taken, waaronder deep learning en inferentie | Geoptimaliseerd voor tensorbewerkingen, presteren vaak beter dan GPU’s bij specifieke deep learning-taken |
| Snelheid en efficiëntie | Bijv. 128 sequenties met BERT-model: 3,8 ms op V100 GPU | Bijv. 128 sequenties met BERT-model: 1,7 ms op TPU v3 |
| Benchmarks | ResNet-50 op CIFAR-10: 40 minuten voor 10 epochs (4 minuten/epoch) op Tesla V100 GPU | ResNet-50 op CIFAR-10: 15 minuten voor 10 epochs (1,5 minuut/epoch) op Google Cloud TPU v3 |
| Kosten | NVIDIA Tesla V100: $8.000–$10.000/stuk, $2,48/uur; NVIDIA A100: $10.000–$15.000/stuk, $2,93/uur | Google Cloud TPU v3: $4,50/uur; TPU v4: $8,00/uur |
| Beschikbaarheid | Breed beschikbaar bij meerdere leveranciers (NVIDIA, AMD, Intel), voor consumenten en bedrijven | Vooral toegankelijk via Google Cloud Platform (GCP) |
| Ecosysteem en ontwikkeltools | Ondersteund door veel frameworks (TensorFlow, PyTorch, Keras, MXNet, Caffe), uitgebreide bibliotheken (CUDA, cuDNN, RAPIDS) | Geïntegreerd met TensorFlow, ondersteunt JAX, geoptimaliseerd door de TensorFlow XLA-compiler |
| Communitysupport en resources | Breed ecosysteem met uitgebreide forums, tutorials en documentatie van NVIDIA, AMD en communities | Gecentraliseerd rond Google’s ecosysteem met GCP-documentatie, forums en supportkanalen |
| Energie-efficiëntie | NVIDIA Tesla V100: 250 watt; NVIDIA A100: 400 watt | Google Cloud TPU v3: 120–150 watt; TPU v4: 200–250 watt |
| Optimalisatie voor AI-taken | Energiezuinige optimalisaties (power gating, DVFS, parallelle verwerking, kernel fusion) | Aangepaste geheugenhiërarchieën, kwantisatie en sparsity voor efficiënte AI-berekening |
| Schaalbaarheid in enterprise-toepassingen | Schaalbaar voor grote AI-projecten, on-premises of in de cloud (AWS, Azure), hoge geheugendoorvoer, parallelle verwerking | Nauw geïntegreerd in cloudinfrastructuur (GCP), on-demand schaalbaarheid, beheerde services voor het uitrollen van AI-modellen |
Kies GPU’s wanneer:
Kies TPU’s wanneer:
GPU’s en TPU’s zijn gespecialiseerde hardwareversnellers die worden gebruikt in AI-toepassingen. GPU’s zijn oorspronkelijk ontwikkeld voor graphicsrendering, blinken uit in parallelle verwerking en zijn aangepast voor AI-taken, met veelzijdige inzetbaarheid in verschillende sectoren. TPU’s daarentegen zijn door Google op maat gebouwd voor AI-workloads en geven prioriteit aan tensorbewerkingen die veel voorkomen in neurale netwerken.
In dit artikel hebben we GPU- en TPU-technologieën vergeleken op basis van prestaties, kosten en beschikbaarheid, ecosysteem en ontwikkeling, energie-efficiëntie en milieueffect, en schaalbaarheid in AI-toepassingen. Wil je meer leren over TPU’s en GPU’s? Bekijk dan deze resources om verder te gaan:
Leer AI-vaardigheden met DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
