Programa
Fundamentos da IA
10 h
O surto de desenvolvimento da inteligência artificial (IA) criou um aumento notável nas demandas de computação, impulsionando a necessidade de soluções robustas de hardware. As unidades de processamento gráfico (GPUs) e as unidades de processamento de tensor (TPUs) surgiram como tecnologias essenciais para atender a essas demandas.
Originalmente projetadas para renderização de gráficos, as GPUs evoluíram para processadores versáteis capazes de lidar com tarefas de IA de forma eficiente devido aos seus recursos de processamento paralelo. Por outro lado, as TPUs, desenvolvidas pelo Google, são otimizadas especificamente para cálculos de IA, oferecendo desempenho superior adaptado para tarefas como projetos de machine learning.
Neste artigo, falaremos sobre GPUs e TPUs e compararemos as duas tecnologias com base em métricas como desempenho, custo, ecossistema e muito mais. Também apresentaremos a você um resumo da eficiência energética, do impacto ambiental e da escalabilidade em aplicativos corporativos.
As GPUs são processadores especializados desenvolvidos inicialmente para renderizar imagens e gráficos em computadores e consoles de jogos. Eles funcionam dividindo problemas complexos em várias tarefas e trabalhando nelas simultaneamente, em vez de uma a uma, como ocorre nas CPUs.
Devido ao seu poder de processamento paralelo, seus recursos evoluíram significativamente além do processamento gráfico, tornando-se componentes integrais em vários aplicativos de computação, como o desenvolvimento de modelos de IA.
Mas vamos voltar um pouco no tempo.
As GPUs entraram em cena pela primeira vez na década de 1980 como hardware especializado para acelerar a renderização de gráficos. Empresas como a NVIDIA e a ATI (agora parte da AMD) desempenharam papéis fundamentais em seu desenvolvimento. No entanto, eles não ganharam popularidade até o final dos anos 1990 e início dos anos 2000. Sua adoção se deveu à introdução de shaders programáveis, permitindo que os desenvolvedores aproveitassem o processamento paralelo para tarefas além dos gráficos.
Nos anos 2000, mais pesquisas exploraram as GPUs para tarefas de computação de uso geral além dos gráficos. A CUDA (Compute Unified Device Architecture) da NVIDIA e o Stream SDK da AMD permitiram que os desenvolvedores aproveitassem o poder de processamento da GPU para simulações científicas, análise de dados e muito mais.
Depois veio o surgimento da IA e da aprendizagem profunda.
As GPUs surgiram como ferramentas indispensáveis para o treinamento e a implantação de modelos de aprendizagem profunda devido à sua capacidade de lidar com grandes quantidades de dados e realizar cálculos em paralelo.
Estruturas como TensorFlow e PyTorch utilizam aceleração de GPU, tornando a aprendizagem profunda acessível a pesquisadores e desenvolvedores em todo o mundo.
As unidades de processamento de tensor (TPUs) são um tipo de circuito integrado específico de aplicativo (ASIC) criado pelo Google para atender às crescentes demandas computacionais de machine learning.
Em contraste com as GPUs, que foram inicialmente criadas para tarefas de processamento gráfico e posteriormente modificadas para atender às demandas de IA, as TPUs foram projetadas especificamente para acelerar as cargas de trabalho de machine learning.
Como foram projetadas para machine learning, as TPUs são desenvolvidas especificamente para operações de tensor, que são fundamentais para os algoritmos de aprendizagem profunda.
Devido à sua arquitetura personalizada otimizada para a multiplicação de matrizes, uma operação essencial em redes neurais, eles se destacam no processamento de grandes volumes de dados e na execução eficiente de redes neurais complexas, permitindo tempos rápidos de treinamento e inferência.
Essa otimização especializada torna as TPUs indispensáveis para aplicativos de IA, impulsionando os avanços na pesquisa e na implementação do machine learning.
As TPUs e GPUs oferecem vantagens distintas e são otimizadas para diferentes tarefas de computação. Embora ambos possam acelerar as cargas de trabalho de machine learning, suas arquiteturas e otimizações levam a variações no desempenho, dependendo da tarefa específica.
Para começar, tanto as GPUs quanto as TPUs são aceleradores de hardware especializados projetados para aprimorar o desempenho em tarefas de IA, mas diferem em suas arquiteturas computacionais, o que afeta significativamente sua eficiência e eficácia no tratamento de tipos específicos de cálculos.
As GPUs consistem em milhares de núcleos pequenos e eficientes projetados para processamento paralelo.
Essa arquitetura permite que eles executem várias tarefas simultaneamente, o que os torna altamente eficazes para tarefas que podem ser paralelizadas, como renderização de gráficos e aprendizagem profunda.
As GPUs são particularmente hábeis em operações de matriz, que são predominantes em cálculos de redes neurais. Sua capacidade de lidar com grandes volumes de dados e executar cálculos em paralelo os torna adequados para tarefas de IA que envolvem o processamento de grandes conjuntos de dados e a execução de operações matemáticas complexas.
Por outro lado, as TPUs priorizam as operações de tensor, o que lhes permite realizar cálculos de forma eficiente. Embora as TPUs possam não ter tantos núcleos quanto as GPUs, sua arquitetura especializada permite que elas superem as GPUs em determinados tipos de tarefas de IA, especialmente aquelas que dependem muito de operações de tensor.
Dito isso, as GPUs são excelentes em tarefas que se beneficiam do processamento paralelo e são adequadas para vários cálculos além da IA, como renderização de gráficos e simulações científicas.
Por outro lado, as TPUs são otimizadas para o processamento de tensores, o que as torna altamente eficientes para tarefas de aprendizagem profunda que envolvem operações de matriz. Dependendo dos requisitos específicos da carga de trabalho de IA, as GPUs ou TPUs podem oferecer melhor desempenho e eficiência.
As GPUs são conhecidas por sua versatilidade em lidar com várias tarefas de IA, incluindo o treinamento de modelos de aprendizagem profunda e a realização de operações de inferência. Isso ocorre porque a arquitetura da GPU, que se baseia no processamento paralelo, aumenta significativamente a velocidade de treinamento e inferência em vários modelos de IA. Por exemplo, o processamento de um lote de 128 sequências com um modelo BERT leva 3,8 milissegundos em uma GPU V100 em comparação com 1,7 milissegundos em uma TPU v3.
Por outro lado, as TPUs são ajustadas com precisão para operações tensoras rápidas e eficientes, componentes essenciais das redes neurais. Essa especialização geralmente permite que as TPUs superem as GPUs em tarefas específicas de aprendizagem profunda, especialmente aquelas otimizadas pelo Google, como treinamento extensivo de redes neurais e modelos complexos de machine learning.
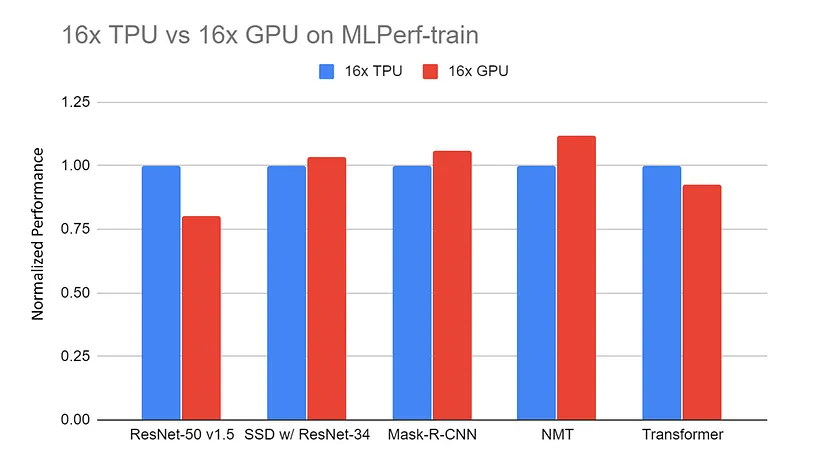
Desempenho normalizado do servidor de GPU 16x (DGX-2H) vs. servidor TPU v3 16x em benchmarks de treinamento MLPerf. Os dados são coletados no site do MLPerf. Todos os resultados da TPU estão usando o TensorFlow. Todos os resultados da GPU estão usando o Pytorch, exceto o ResNet que está usando o MxNet |.
Fonte: TPU vs. GPU vs. Cerebras vs. Graphcore: Uma comparação justa entre hardware de ML por Mahmoud Khairy
As comparações entre TPUs e GPUs em tarefas semelhantes frequentemente revelam que as TPUs superam as GPUs em tarefas especificamente adaptadas à sua arquitetura, proporcionando durações de treinamento mais rápidas e processamento mais eficaz.
Por exemplo, o treinamento de um modelo ResNet-50 no conjunto de dados CIFAR-10 para 10 épocas usando uma GPU NVIDIA Tesla V100 leva aproximadamente 40 minutos, com uma média de 4 minutos por época. Por outro lado, usando uma TPU v3 do Google Cloud, o mesmo treinamento leva apenas 15 minutos, com uma média de 1,5 minuto por época.
No entanto, as GPUs mantêm um desempenho competitivo em um espectro mais amplo de aplicativos devido à sua adaptabilidade e aos consideráveis esforços de otimização realizados pela comunidade.
A escolha entre GPU e TPU depende do orçamento, das necessidades de computação e da disponibilidade. Cada opção oferece vantagens exclusivas para diferentes aplicações. Nesta seção, veremos como as GPUs e TPUs se comparam em termos de custo e acessibilidade ao mercado.
As GPUs oferecem muito mais flexibilidade do que as TPUs quando se trata de custos. Para começar, as TPUs não são vendidas individualmente; elas só estão disponíveis como um serviço de nuvem por meio de provedores como o Google Cloud Platform (GCP). Por outro lado, as GPUs podem ser adquiridas individualmente.
O custo aproximado de uma GPU NVIDIA Tesla V100 está entre US$ 8.000 e US$ 10.000 por unidade, e uma unidade de GPU NVIDIA A100 está entre US$ 10.000 e US$ 15.000. Mas você também tem a opção de preços de nuvem sob demanda.
Usar a GPU NVIDIA Tesla V100 para treinar um modelo de aprendizagem profunda provavelmente custará a você cerca de US$ 2,48 por hora, e a NVIDIA A100 custaria cerca de US$ 2,93. Por outro lado, o Google Cloud TPU V3 custaria cerca de US$ 4,50 por hora, e o Google Cloud TPU V4 custaria aproximadamente US$ 8,00 por hora.
Em outras palavras, as TPUs são muito menos flexíveis do que as GPUs e, em geral, têm custos mais altos por hora para computação em nuvem sob demanda do que as GPUs. No entanto, as TPUs geralmente oferecem desempenho mais rápido, o que pode reduzir o tempo total de computação necessário para tarefas de machine learning em grande escala, o que pode levar a uma economia geral de custos, apesar das taxas horárias mais altas.
A disponibilidade de TPUs e GPUs no mercado varia muito, influenciando sua adoção em diferentes setores e regiões...
As TPUs, desenvolvidas pelo Google, são acessíveis principalmente por meio do Google Cloud Platform (GCP) para tarefas de IA baseadas em nuvem. Isso significa que eles são usados principalmente por pessoas que dependem do GCP para suas necessidades de computação, o que pode torná-los mais populares em áreas e setores que utilizam muito a computação em nuvem, como centros de tecnologia ou locais com fortes conexões de Internet.
Enquanto isso, as GPUs são fabricadas por empresas como NVIDIA, AMD e Intel, e estão disponíveis em várias opções para consumidores e empresas. Essa disponibilidade mais ampla torna as GPUs uma escolha popular em vários setores, incluindo jogos, ciência, finanças, saúde e manufatura. As GPUs podem ser configuradas no local ou na nuvem, oferecendo aos usuários flexibilidade em sua configuração de computação.
Consequentemente, é mais provável que as GPUs sejam usadas em diferentes setores e regiões, independentemente de suas necessidades de infraestrutura tecnológica ou de computação. De modo geral, a disponibilidade de TPUs e GPUs no mercado influencia a forma como elas são adotadas. As TPUs são mais comuns em áreas e setores voltados para a nuvem (por exemplo, machine learning), enquanto as GPUs são amplamente usadas em diferentes campos e locais.
As TPUs do Google são totalmente integradas ao TensorFlow, sua principal estrutura de machine learning de código aberto. JAX, outra biblioteca para computação numérica de alto desempenho, também suporta TPUs, permitindo machine learning eficiente e computação científica.
As TPUs são perfeitamente integradas ao ecossistema do TensorFlow, o que torna simples para os usuários do TensorFlow aproveitarem os recursos da TPU. Por exemplo, o TensorFlow oferece ferramentas como o compilador TensorFlow XLA (Accelerated Linear Algebra), que otimiza os cálculos para TPUs.
Em essência, as TPUs são projetadas para acelerar as operações do TensorFlow, fornecendo desempenho otimizado para treinamento e inferência. Eles também são compatíveis com as APIs de alto nível do TensorFlow, facilitando a migração e a otimização de modelos para execução em TPU.
Por outro lado, as GPUs são amplamente adotadas em vários setores e campos de pesquisa, o que as torna populares para diversas aplicações de machine learning. Isso significa que elas têm mais integrações do que as GPUs e são compatíveis com uma variedade maior de estruturas de aprendizagem profunda, incluindo TensorFlow, PyTorch, Keras, MXNet e Caffe.
As GPUs também se beneficiam de extensas bibliotecas e ferramentas como CUDA, cuDNN e RAPIDS, aumentando ainda mais sua versatilidade e facilidade de integração em vários fluxos de trabalho de machine learning e ciência de dados.
Com relação ao suporte da comunidade, as GPUs têm um ecossistema mais amplo, com fóruns, tutoriais e documentação abrangentes disponíveis em várias fontes, como NVIDIA, AMD e plataformas voltadas para a comunidade. Os desenvolvedores podem acessar comunidades on-line, fóruns e grupos de usuários vibrantes para buscar ajuda, compartilhar conhecimento e colaborar em projetos. Além disso, vários tutoriais, cursos e recursos de documentação abrangem programação de GPU, estruturas de aprendizagem profunda e técnicas de otimização.
O suporte da comunidade para TPUs é mais centralizado no ecossistema do Google, com recursos disponíveis principalmente na documentação, nos fóruns e nos canais de suporte do GCP. Embora o Google forneça documentação abrangente e tutoriais especificamente adaptados para o uso de TPUs com o TensorFlow, o suporte da comunidade pode ser mais limitado do que o ecossistema de GPU mais amplo. No entanto, os canais de suporte oficiais do Google e os recursos para desenvolvedores ainda oferecem assistência valiosa aos desenvolvedores que utilizam TPUs para cargas de trabalho de IA.
A eficiência energética das GPUs e TPUs varia de acordo com suas arquiteturas e aplicações pretendidas. Em geral, as TPUs são mais eficientes em termos de energia do que as GPUs, especialmente a Google Cloud TPU v3, que é significativamente mais eficiente em termos de energia do que as GPUs NVIDIA de ponta.
Para obter mais contexto:
O menor consumo de energia das TPUs pode contribuir para que você tenha custos operacionais muito mais baixos e maior eficiência energética, especialmente em implementações de machine learning em grande escala.
As TPUs e GPUs empregam otimizações específicas para aumentar a eficiência energética ao realizar operações de IA em grande escala.
Conforme mencionado anteriormente no artigo, a arquitetura da TPU foi projetada para priorizar operações de tensor comumente usadas em redes neurais, permitindo a execução eficiente de tarefas de IA com consumo mínimo de energia. As TPUs também apresentam hierarquias de memória personalizadas otimizadas para cálculos de IA, reduzindo a latência de acesso à memória e a sobrecarga de energia.
Eles utilizam técnicas como quantização e esparsidade para otimizar as operações aritméticas, minimizando o consumo de energia sem sacrificar a precisão. Esses fatores permitem que as TPUs ofereçam alto desempenho e, ao mesmo tempo, conservem energia.
Da mesma forma, as GPUs implementam otimizações com eficiência energética para melhorar o desempenho em operações de IA. As arquiteturas modernas de GPUs incorporam recursos como o controle de energia e o dimensionamento dinâmico de tensão e frequência (DVFS) para ajustar o consumo de energia com base nas demandas de carga de trabalho. Eles também utilizam técnicas de processamento paralelo para distribuir tarefas computacionais em vários núcleos, maximizando o rendimento e minimizando a energia por operação.
Os fabricantes de GPUs desenvolvem arquiteturas de memória e hierarquias de cache com eficiência energética para otimizar os padrões de acesso à memória e reduzir o consumo de energia durante as transferências de dados. Essas otimizações, combinadas com técnicas de software, como fusão de kernel e desenrolamento de loop, aumentam ainda mais a eficiência energética em cargas de trabalho de IA aceleradas por GPU.
Tanto as TPUs quanto as GPUs oferecem escalabilidade para grandes projetos de IA, mas com abordagens diferentes. As TPUs são totalmente integradas à infraestrutura de nuvem, especialmente por meio do Google Cloud Platform (GCP), oferecendo recursos dimensionáveis para cargas de trabalho de IA. Os usuários podem acessar TPUs sob demanda, aumentando ou diminuindo a escala com base nas necessidades computacionais, o que é crucial para lidar com projetos de IA em grande escala de forma eficiente. O Google fornece serviços gerenciados e ambientes pré-configurados para a implantação de modelos de IA em TPUs, simplificando o processo de integração na infraestrutura de nuvem.
Por outro lado, as GPUs também são dimensionadas de forma eficaz para grandes projetos de IA, com opções para implantação no local ou utilização em ambientes de nuvem oferecidos por provedores como Amazon Web Services (AWS) e Microsoft Azure. As GPUs oferecem flexibilidade no dimensionamento, permitindo que os usuários implementem várias GPUs em paralelo para aumentar a capacidade de computação.
Além disso, as GPUs são excelentes para lidar com grandes conjuntos de dados graças à sua alta largura de banda de memória e aos recursos de processamento paralelo. Isso permite o processamento eficiente de dados e o treinamento de modelos, o que é essencial para projetos de IA em grande escala que lidam com vastos conjuntos de dados.
De modo geral, tanto as TPUs quanto as GPUs oferecem escalabilidade para grandes projetos de IA, com as TPUs totalmente integradas à infraestrutura de nuvem e as GPUs oferecendo flexibilidade para implantação no local ou baseada na nuvem. Sua capacidade de lidar com grandes conjuntos de dados e dimensionar recursos computacionais os torna inestimáveis para lidar com tarefas complexas de IA em escala.
| Recurso | GPUs | TPUs |
|---|---|---|
| Arquitetura computacional | Milhares de núcleos pequenos e eficientes para processamento paralelo | Priorizar operações de tensor, arquitetura especializada |
| Desempenho | Versátil, excelente em várias tarefas de IA, incluindo aprendizagem profunda e inferência | Otimizado para operações de tensor, geralmente supera o desempenho das GPUs em tarefas específicas de aprendizagem profunda |
| Velocidade e eficiência | Por exemplo, 128 sequências com o modelo BERT: 3,8 ms na GPU V100 | Por exemplo, 128 sequências com o modelo BERT: 1,7 ms na TPU v3 |
| Padrões de referência | ResNet-50 no CIFAR-10: 40 minutos para 10 épocas (4 minutos/época) na GPU Tesla V100 | ResNet-50 no CIFAR-10: 15 minutos para 10 épocas (1,5 minutos/época) no Google Cloud TPU v3 |
| Custo | NVIDIA Tesla V100: US$ 8.000 - US$ 10.000/unidade, US$ 2,48/hora; NVIDIA A100: US$ 10.000 - US$ 15.000/unidade, US$ 2,93/hora | Google Cloud TPU v3: US$ 4,50/hora; TPU v4: US$ 8,00/hora |
| Disponibilidade | Amplamente disponível em vários fornecedores (NVIDIA, AMD, Intel), para consumidores e empresas | Principalmente acessível por meio do Google Cloud Platform (GCP) |
| Ecossistema e ferramentas de desenvolvimento | Suportado por muitas estruturas (TensorFlow, PyTorch, Keras, MXNet, Caffe), bibliotecas extensas (CUDA, cuDNN, RAPIDS) | Integrado ao TensorFlow, compatível com JAX, otimizado pelo compilador XLA do TensorFlow |
| Suporte e recursos da comunidade | Amplo ecossistema com fóruns, tutoriais e documentação abrangentes da NVIDIA, AMD e comunidades | Centralizado no ecossistema do Google com documentação, fóruns e canais de suporte do GCP |
| Eficiência energética | NVIDIA Tesla V100: 250 watts; NVIDIA A100: 400 watts | Google Cloud TPU v3: 120-150 watts; TPU v4: 200-250 watts |
| Otimização para tarefas de IA | Otimizações com eficiência energética (controle de energia, DVFS, processamento paralelo, fusão de kernel) | Hierarquias de memória personalizadas, quantização e esparsidade para computação eficiente de IA |
| Escalabilidade em aplicativos corporativos | Escalável para grandes projetos de IA, no local ou na nuvem (AWS, Azure), alta largura de banda de memória, processamento paralelo | Totalmente integrado à infraestrutura de nuvem (GCP), escalabilidade sob demanda, serviços gerenciados para implantação de modelos de IA |
Escolha GPUs quando:
Escolha TPUs quando:
GPUs e TPUs são aceleradores de hardware especializados usados em aplicativos de IA. Originalmente desenvolvidas para renderização de gráficos, as GPUs são excelentes em processamento paralelo e foram adaptadas para tarefas de IA, oferecendo versatilidade em vários setores. As TPUs, por outro lado, são personalizadas pelo Google especificamente para cargas de trabalho de IA, priorizando operações de tensor comumente encontradas em redes neurais.
Este artigo comparou as tecnologias de GPU e TPU com base em seu desempenho, custo e disponibilidade, ecossistema e desenvolvimento, eficiência energética e impacto ambiental e escalabilidade em aplicativos de IA. Para continuar aprendendo sobre TPUs e GPUs, confira alguns desses recursos e continue aprendendo:
Aprenda habilidades de IA com o DataCamp
Programa
Curso
Curso
blog
Bhavishya Pandit
7 min
blog
Javier Canales Luna
9 min
blog
Hesam Sheikh Hassani
12 min
blog
Bhavishya Pandit
9 min
Tutorial
Josep Ferrer
Tutorial
Arunn Thevapalan

