
Program
Dasar-Dasar Kecerdasan Buatan
10 Hr
Lonjakan pengembangan Kecerdasan Buatan (AI) telah menciptakan peningkatan kebutuhan komputasi yang signifikan, mendorong kebutuhan akan solusi perangkat keras yang andal. Graphics Processing Unit (GPU) dan Tensor Processing Unit (TPU) muncul sebagai teknologi kunci untuk memenuhi kebutuhan tersebut.
Awalnya dirancang untuk melakukan rendering grafis, GPU berevolusi menjadi prosesor serbaguna yang mampu menangani tugas AI secara efisien berkat kemampuan pemrosesan paralelnya. Sebaliknya, TPU, yang dikembangkan oleh Google, dioptimalkan khusus untuk komputasi AI, menawarkan performa unggul yang disesuaikan untuk tugas seperti proyek machine learning.
Dalam artikel ini, kami akan membahas perbandingan GPU vs TPU dan membandingkan kedua teknologi berdasarkan metrik seperti performa, biaya, ekosistem, dan lainnya. Kami juga akan mengulas efisiensi energi, dampak lingkungan, dan skalabilitasnya dalam aplikasi enterprise.
GPU adalah prosesor khusus yang awalnya dikembangkan untuk merender gambar dan grafis di komputer dan konsol gim. GPU bekerja dengan memecah masalah kompleks menjadi beberapa tugas dan mengerjakannya secara bersamaan alih-alih satu per satu seperti pada CPU.
Berkat kekuatan pemrosesan paralel, kemampuannya telah berkembang jauh melampaui pemrosesan grafis, menjadi komponen penting dalam berbagai aplikasi komputasi, seperti pengembangan model AI.
Namun mari kita mundur sedikit.
GPU pertama kali muncul pada 1980-an sebagai perangkat keras khusus untuk mempercepat rendering grafis. Perusahaan seperti NVIDIA dan ATI (kini bagian dari AMD) berperan penting dalam pengembangannya. Namun, GPU baru meraih popularitas arus utama pada akhir 1990-an dan awal 2000-an. Adopsinya didorong oleh hadirnya programmable shader, yang memungkinkan pengembang memanfaatkan pemrosesan paralel untuk tugas di luar grafis.
Pada 2000-an, lebih banyak penelitian mengeksplorasi GPU untuk tugas komputasi umum di luar grafis. CUDA (Compute Unified Device Architecture) dari NVIDIA dan Stream SDK dari AMD memungkinkan pengembang memanfaatkan daya pemrosesan GPU untuk simulasi ilmiah, analisis data, dan lainnya.
Lalu muncullah gelombang AI dan deep learning.
GPU menjadi alat yang tak tergantikan untuk melatih dan menerapkan model deep learning karena kemampuannya menangani data berukuran masif dan melakukan komputasi secara paralel.
Kerangka kerja seperti TensorFlow dan PyTorch memanfaatkan akselerasi GPU, membuat deep learning dapat diakses oleh peneliti dan pengembang di seluruh dunia.
Tensor Processing Unit (TPU) adalah jenis application-specific integrated circuit (ASIC) yang dipelopori oleh Google untuk menjawab meningkatnya kebutuhan komputasi dalam machine learning.
Berbeda dengan GPU, yang awalnya dibuat untuk tugas pemrosesan grafis dan kemudian dimodifikasi untuk memenuhi kebutuhan AI, TPU dirancang khusus untuk mempercepat beban kerja machine learning.
Karena dirancang untuk machine learning, TPU direkayasa khusus untuk operasi tensor, yang merupakan dasar dari algoritme deep learning.
Berkat arsitektur khusus yang dioptimalkan untuk perkalian matriks, operasi kunci dalam jaringan saraf, TPU unggul dalam memproses data berukuran besar dan mengeksekusi jaringan saraf kompleks secara efisien, sehingga memungkinkan waktu pelatihan dan inferensi yang cepat.
Optimasi khusus ini membuat TPU tak tergantikan untuk aplikasi AI, mendorong kemajuan dalam riset dan penerapan machine learning.
TPU dan GPU menawarkan keunggulan berbeda dan dioptimalkan untuk tugas komputasi yang berbeda. Meski keduanya dapat mempercepat beban kerja machine learning, arsitektur dan optimasinya menghasilkan variasi performa bergantung pada tugas spesifiknya.
Sebagai permulaan, baik GPU maupun TPU adalah akselerator perangkat keras khusus yang dirancang untuk meningkatkan performa dalam tugas AI, tetapi keduanya berbeda dalam arsitektur komputasional, yang berdampak signifikan pada efisiensi dan efektivitas dalam menangani jenis komputasi tertentu.
GPU terdiri dari ribuan inti kecil yang efisien yang dirancang untuk pemrosesan paralel.
Arsitektur ini memungkinkan eksekusi banyak tugas secara bersamaan, menjadikannya sangat efektif untuk tugas yang dapat diparalelkan, seperti rendering grafis dan deep learning.
GPU sangat piawai dalam operasi matriks, yang banyak ditemukan pada komputasi jaringan saraf. Kemampuannya menangani volume data besar dan mengeksekusi komputasi secara paralel membuatnya cocok untuk tugas AI yang melibatkan pemrosesan dataset masif dan operasi matematis kompleks.
Sebaliknya, TPU memprioritaskan operasi tensor, sehingga memungkinkan komputasi dilakukan secara efisien. Walau TPU mungkin tidak memiliki sebanyak inti seperti GPU, arsitektur khususnya memungkinkan TPU mengungguli GPU pada jenis tugas AI tertentu, terutama yang sangat bergantung pada operasi tensor.
Meski demikian, GPU unggul pada tugas yang diuntungkan dari pemrosesan paralel dan cocok untuk berbagai komputasi di luar AI, seperti rendering grafis dan simulasi ilmiah.
Di sisi lain, TPU dioptimalkan untuk pemrosesan tensor, menjadikannya sangat efisien untuk tugas deep learning yang melibatkan operasi matriks. Bergantung pada kebutuhan spesifik beban kerja AI, baik GPU maupun TPU dapat menawarkan performa dan efisiensi yang lebih baik.
GPU dikenal karena keserbagunaannya dalam menangani berbagai tugas AI, termasuk pelatihan model deep learning dan melakukan operasi inferensi. Ini karena arsitektur GPU yang mengandalkan pemrosesan paralel, secara signifikan meningkatkan kecepatan pelatihan dan inferensi di banyak model AI. Sebagai contoh, memproses batch berisi 128 urutan dengan model BERT membutuhkan 3,8 milidetik pada GPU V100 dibandingkan 1,7 milidetik pada TPU v3.
Sebaliknya, TPU disetel secara cermat untuk operasi tensor yang cepat dan efisien, komponen krusial dari jaringan saraf. Spesialisasi ini sering kali memungkinkan TPU mengungguli GPU dalam tugas deep learning tertentu, khususnya yang dioptimalkan oleh Google, seperti pelatihan jaringan saraf berskala besar dan model machine learning yang kompleks.
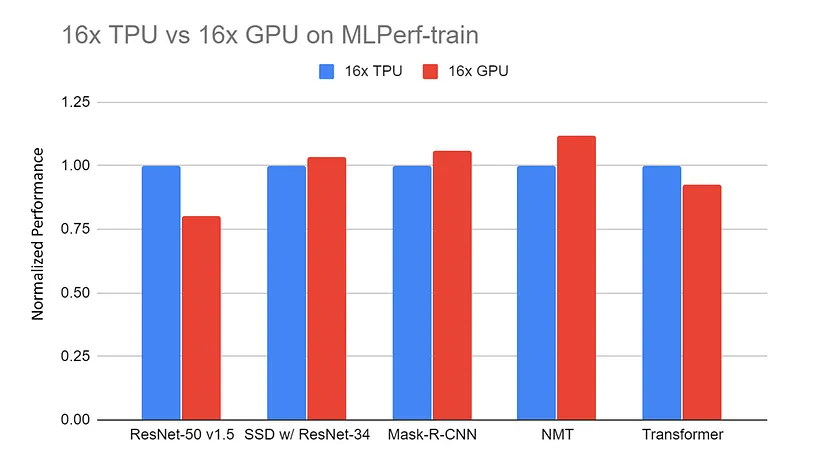
Performa ternormalisasi server 16x GPU (DGX-2H) vs server 16x TPU v3 pada benchmark MLPerf-train. Data diambil dari situs MLPerf. Semua hasil TPU menggunakan TensorFlow. Semua hasil GPU menggunakan Pytorch, kecuali ResNet menggunakan MxNet |
Sumber: TPU vs. GPU vs Cerebras vs. Graphcore: A Fair Comparison between ML Hardware oleh Mahmoud Khairy
Perbandingan antara TPU dan GPU pada tugas serupa kerap menunjukkan TPU mengungguli GPU dalam tugas yang secara khusus disesuaikan dengan arsitekturnya, memberikan durasi pelatihan yang lebih cepat dan pemrosesan yang lebih efektif.
Sebagai contoh, melatih model ResNet-50 pada dataset CIFAR-10 selama 10 epoch menggunakan GPU NVIDIA Tesla V100 memakan waktu sekitar 40 menit, rata-rata 4 menit per epoch. Sebaliknya, menggunakan Google Cloud TPU v3, pelatihan yang sama hanya memakan waktu 15 menit, rata-rata 1,5 menit per epoch.
Kendati demikian, GPU tetap mempertahankan performa yang kompetitif di spektrum aplikasi yang lebih luas berkat adaptabilitasnya dan upaya optimasi besar dari komunitas.
Pilihan antara GPU dan TPU bergantung pada anggaran, kebutuhan komputasi, dan ketersediaan. Masing-masing menawarkan keunggulan unik untuk aplikasi berbeda. Pada bagian ini, kita akan melihat bagaimana GPU dan TPU dibandingkan dalam hal biaya dan aksesibilitas pasar.
GPU menawarkan fleksibilitas yang jauh lebih besar daripada TPU dalam hal biaya. Untuk awal, TPU tidak dijual secara individual; TPU hanya tersedia sebagai layanan cloud melalui penyedia seperti Google Cloud Platform (GCP). Sebaliknya, GPU dapat dibeli secara individual.
Perkiraan biaya satu unit GPU NVIDIA Tesla V100 berada di kisaran $8.000 hingga $10.000, dan satu unit GPU NVIDIA A100 berkisar antara $10.000 hingga $15.000. Namun Anda juga memiliki opsi harga on-demand di cloud.
Menggunakan GPU NVIDIA Tesla V100 untuk melatih model deep learning kemungkinan akan menelan biaya sekitar $2,48 per jam, dan NVIDIA A100 sekitar $2,93. Di sisi lain, Google Cloud TPU V3 akan berharga sekitar $4,50 per jam, dan Google Cloud TPU V4 kira-kira $8,00 per jam.
Dengan kata lain, TPU jauh kurang fleksibel daripada GPU dan umumnya memiliki biaya per jam yang lebih tinggi untuk komputasi cloud on-demand dibandingkan GPU. Namun, TPU sering menawarkan performa yang lebih cepat, yang dapat mengurangi total waktu komputasi yang dibutuhkan untuk tugas machine learning berskala besar, sehingga berpotensi menghasilkan penghematan biaya keseluruhan meskipun tarif per jamnya lebih tinggi.
Ketersediaan TPU dan GPU di pasar sangat bervariasi, memengaruhi adopsinya di berbagai industri dan wilayah…
TPU, yang dikembangkan oleh Google, terutama dapat diakses melalui Google Cloud Platform (GCP) untuk tugas AI berbasis cloud. Ini berarti TPU terutama digunakan oleh pihak yang mengandalkan GCP untuk kebutuhan komputasinya, yang mungkin membuatnya lebih populer di area dan industri yang berfokus pada komputasi cloud, seperti pusat teknologi atau wilayah dengan koneksi internet yang kuat.
Sementara itu, GPU diproduksi oleh perusahaan seperti NVIDIA, AMD, dan Intel, dan tersedia dalam berbagai opsi untuk konsumen maupun bisnis. Ketersediaan yang lebih luas ini membuat GPU menjadi pilihan populer di berbagai industri, termasuk gim, sains, keuangan, kesehatan, dan manufaktur. GPU dapat disiapkan di lingkungan on-premises atau di cloud, memberi pengguna fleksibilitas dalam penataan komputasi.
Akibatnya, GPU lebih mungkin digunakan di berbagai industri dan wilayah, terlepas dari infrastruktur teknologi atau kebutuhan komputasinya. Secara keseluruhan, ketersediaan pasar TPU dan GPU memengaruhi bagaimana keduanya diadopsi. TPU lebih umum di area dan sektor yang berfokus pada cloud (misalnya, machine learning), sedangkan GPU digunakan secara luas di berbagai bidang dan lokasi.
TPU Google terintegrasi erat dengan TensorFlow, kerangka kerja machine learning open-source andalannya. JAX, pustaka lain untuk komputasi numerik berkinerja tinggi, juga mendukung TPU, memungkinkan machine learning dan komputasi ilmiah yang efisien.
TPU terintegrasi mulus ke dalam ekosistem TensorFlow, sehingga pengguna TensorFlow mudah memanfaatkan kapabilitas TPU. Misalnya, TensorFlow menawarkan alat seperti kompilator TensorFlow XLA (Accelerated Linear Algebra) yang mengoptimalkan komputasi untuk TPU.
Intinya, TPU dirancang untuk mempercepat operasi TensorFlow, memberikan performa yang dioptimalkan untuk pelatihan dan inferensi. TPU juga mendukung API tingkat tinggi TensorFlow, sehingga memudahkan migrasi dan optimasi model untuk eksekusi di TPU.
Sebaliknya, GPU diadopsi secara luas di berbagai industri dan bidang riset, menjadikannya populer untuk beragam aplikasi machine learning. Ini berarti GPU memiliki lebih banyak integrasi dan didukung oleh beragam kerangka kerja deep learning, termasuk TensorFlow, PyTorch, Keras, MXNet, dan Caffe.
GPU juga diuntungkan oleh pustaka dan alat yang ekstensif seperti CUDA, cuDNN, dan RAPIDS, yang semakin meningkatkan keserbagunaan dan kemudahan integrasinya ke berbagai alur kerja machine learning dan data science.
Dalam hal dukungan komunitas, GPU memiliki ekosistem yang lebih luas dengan forum, tutorial, dan dokumentasi ekstensif yang tersedia dari berbagai sumber seperti NVIDIA, AMD, dan platform berbasis komunitas. Pengembang dapat mengakses komunitas online yang dinamis, forum, dan grup pengguna untuk mencari bantuan, berbagi pengetahuan, dan berkolaborasi dalam proyek. Selain itu, banyak tutorial, kursus, dan sumber dokumentasi yang membahas pemrograman GPU, kerangka kerja deep learning, dan teknik optimasi.
Dukungan komunitas untuk TPU lebih terpusat di ekosistem Google, dengan sumber daya yang terutama tersedia melalui dokumentasi GCP, forum, dan saluran dukungan. Walaupun Google menyediakan dokumentasi dan tutorial komprehensif yang secara khusus disesuaikan untuk penggunaan TPU dengan TensorFlow, dukungan komunitasnya mungkin lebih terbatas dibandingkan ekosistem GPU yang lebih luas. Namun, saluran dukungan resmi Google dan sumber daya pengembang tetap menawarkan bantuan berharga bagi pengembang yang memanfaatkan TPU untuk beban kerja AI.
Efisiensi energi GPU dan TPU bervariasi berdasarkan arsitektur dan aplikasi yang dituju. Secara umum, TPU lebih hemat energi daripada GPU, khususnya Google Cloud TPU v3, yang secara signifikan lebih hemat daya dibandingkan GPU NVIDIA kelas atas.
Untuk konteks lebih lanjut:
Konsumsi daya TPU yang lebih rendah dapat berkontribusi pada biaya operasional yang jauh lebih rendah dan peningkatan efisiensi energi, terutama dalam penerapan machine learning berskala besar.
TPU dan GPU menerapkan optimasi khusus untuk meningkatkan efisiensi energi saat menjalankan operasi AI berskala besar.
Seperti disebutkan sebelumnya dalam artikel, arsitektur TPU dirancang untuk memprioritaskan operasi tensor yang umum digunakan dalam jaringan saraf, memungkinkan eksekusi tugas AI secara efisien dengan konsumsi energi minimal. TPU juga menampilkan hierarki memori khusus yang dioptimalkan untuk komputasi AI, mengurangi latensi akses memori dan beban energi.
TPU memanfaatkan teknik seperti kuantisasi dan sparsity untuk mengoptimalkan operasi aritmetika, meminimalkan konsumsi daya tanpa mengorbankan akurasi. Faktor-faktor ini memungkinkan TPU memberikan performa tinggi sekaligus menghemat energi.
Demikian pula, GPU menerapkan optimasi hemat energi untuk meningkatkan performa dalam operasi AI. Arsitektur GPU modern menggabungkan fitur seperti power gating dan dynamic voltage and frequency scaling (DVFS) untuk menyesuaikan konsumsi daya berdasarkan beban kerja. GPU juga memanfaatkan teknik pemrosesan paralel untuk mendistribusikan tugas komputasi ke banyak inti, memaksimalkan throughput sambil meminimalkan energi per operasi.
Produsen GPU mengembangkan arsitektur memori dan hierarki cache yang hemat energi untuk mengoptimalkan pola akses memori dan mengurangi konsumsi energi selama transfer data. Optimasi ini, dipadukan dengan teknik perangkat lunak seperti kernel fusion dan loop unrolling, semakin meningkatkan efisiensi energi dalam beban kerja AI yang dipercepat GPU.
TPU dan GPU sama-sama menawarkan skalabilitas untuk proyek AI berskala besar, tetapi pendekatannya berbeda. TPU terintegrasi erat ke dalam infrastruktur cloud, khususnya melalui Google Cloud Platform (GCP), menawarkan sumber daya yang dapat diskalakan untuk beban kerja AI. Pengguna dapat mengakses TPU sesuai permintaan, melakukan scale up atau down berdasarkan kebutuhan komputasi, yang krusial untuk menangani proyek AI skala besar secara efisien. Google menyediakan layanan terkelola dan lingkungan prakonfigurasi untuk menerapkan model AI di TPU, menyederhanakan proses integrasi ke infrastruktur cloud.
Di sisi lain, GPU juga dapat diskalakan secara efektif untuk proyek AI besar, dengan opsi penerapan on-premises atau pemanfaatan di lingkungan cloud yang ditawarkan oleh penyedia seperti Amazon Web Services (AWS) dan Microsoft Azure. GPU menawarkan fleksibilitas dalam skalabilitas, memungkinkan pengguna menerapkan banyak GPU secara paralel untuk meningkatkan daya komputasi.
Selain itu, GPU unggul dalam menangani dataset besar berkat bandwidth memori tinggi dan kemampuan pemrosesan paralel. Hal ini memungkinkan pemrosesan data dan pelatihan model yang efisien, yang penting untuk proyek AI berskala besar yang menangani dataset masif.
Secara keseluruhan, baik TPU maupun GPU menawarkan skalabilitas untuk proyek AI besar, dengan TPU terintegrasi erat ke infrastruktur cloud dan GPU memberikan fleksibilitas untuk penerapan on-premises atau berbasis cloud. Kemampuan keduanya dalam menangani dataset besar dan menskalakan sumber daya komputasi menjadikannya tak ternilai untuk menangani tugas AI kompleks dalam skala besar.
| Fitur | GPU | TPU |
|---|---|---|
| Arsitektur Komputasional | Ribuan inti kecil yang efisien untuk pemrosesan paralel | Memprioritaskan operasi tensor, arsitektur khusus |
| Performa | Serbaguna, unggul dalam berbagai tugas AI, termasuk deep learning dan inferensi | Dioptimalkan untuk operasi tensor, sering mengungguli GPU pada tugas deep learning tertentu |
| Kecepatan dan Efisiensi | Mis., 128 urutan dengan model BERT: 3,8 ms pada GPU V100 | Mis., 128 urutan dengan model BERT: 1,7 ms pada TPU v3 |
| Benchmark | ResNet-50 pada CIFAR-10: 40 menit untuk 10 epoch (4 menit/epoch) pada Tesla V100 GPU | ResNet-50 pada CIFAR-10: 15 menit untuk 10 epoch (1,5 menit/epoch) pada Google Cloud TPU v3 |
| Biaya | NVIDIA Tesla V100: $8.000 - $10.000/unit, $2,48/jam; NVIDIA A100: $10.000 - $15.000/unit, $2,93/jam | Google Cloud TPU v3: $4,50/jam; TPU v4: $8,00/jam |
| Ketersediaan | Tersedia luas dari banyak vendor (NVIDIA, AMD, Intel), untuk konsumen dan bisnis | Utamanya dapat diakses melalui Google Cloud Platform (GCP) |
| Ekosistem dan Alat Pengembangan | Didukung banyak kerangka kerja (TensorFlow, PyTorch, Keras, MXNet, Caffe), pustaka ekstensif (CUDA, cuDNN, RAPIDS) | Terintegrasi dengan TensorFlow, mendukung JAX, dioptimalkan oleh kompilator TensorFlow XLA |
| Dukungan Komunitas dan Sumber Daya | Ekosistem luas dengan forum, tutorial, dan dokumentasi ekstensif dari NVIDIA, AMD, dan komunitas | Tersentralisasi di ekosistem Google dengan dokumentasi, forum, dan saluran dukungan GCP |
| Efisiensi Energi | NVIDIA Tesla V100: 250 watt; NVIDIA A100: 400 watt | Google Cloud TPU v3: 120-150 watt; TPU v4: 200-250 watt |
| Optimasi untuk Tugas AI | Optimasi hemat energi (power gating, DVFS, pemrosesan paralel, kernel fusion) | Hierarki memori khusus, kuantisasi, dan sparsity untuk komputasi AI yang efisien |
| Skalabilitas dalam Aplikasi Enterprise | Dapat diskalakan untuk proyek AI besar, on-premises atau cloud (AWS, Azure), bandwidth memori tinggi, pemrosesan paralel | Terintegrasi erat ke infrastruktur cloud (GCP), skalabilitas on-demand, layanan terkelola untuk menerapkan model AI |
Pilih GPU saat:
Pilih TPU saat:
GPU dan TPU adalah akselerator perangkat keras khusus yang digunakan dalam aplikasi AI. Awalnya dikembangkan untuk rendering grafis, GPU unggul dalam pemrosesan paralel dan telah diadaptasi untuk tugas AI, menawarkan keserbagunaan di berbagai industri. Sebaliknya, TPU dibuat khusus oleh Google untuk beban kerja AI, memprioritaskan operasi tensor yang umum ditemukan pada jaringan saraf.
Artikel ini membandingkan teknologi GPU dan TPU berdasarkan performa, biaya dan ketersediaan, ekosistem dan pengembangan, efisiensi energi dan dampak lingkungan, serta skalabilitas dalam aplikasi AI. Untuk melanjutkan pembelajaran tentang TPU dan GPU, lihat beberapa sumber berikut untuk memperdalam pengetahuan Anda:
Pelajari Keterampilan AI dengan DataCamp
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
