
Lernpfad
Grundlagen der KI
10 Std.
Die rasante Entwicklung der Künstlichen Intelligenz (KI) hat zu einem deutlichen Anstieg der Computeranforderungen geführt, was den Bedarf an robusten Hardwarelösungen erhöht. Graphics Processing Units (GPUs) und Tensor Processing Units (TPUs) haben sich als Schlüsseltechnologien zur Erfüllung dieser Anforderungen herausgestellt.
Ursprünglich für das Rendering von Grafiken entwickelt, haben sich die GPUs zu vielseitigen Prozessoren entwickelt, die dank ihrer parallelen Verarbeitungsfähigkeiten auch KI-Aufgaben effizient erledigen können. Im Gegensatz dazu sind die von Google entwickelten TPUs speziell für KI-Berechnungen optimiert und bieten eine überlegene Leistung, die auf Aufgaben wie maschinelle Lernprojekte zugeschnitten ist.
In diesem Artikel werden wir über GPUs und TPUs sprechen und die beiden Technologien anhand von Kriterien wie Leistung, Kosten, Ökosystem und mehr vergleichen. Außerdem geben wir dir einen Überblick über ihre Energieeffizienz, Umweltverträglichkeit und Skalierbarkeit in Unternehmensanwendungen.
GPUs sind spezialisierte Prozessoren, die ursprünglich für das Rendern von Bildern und Grafiken in Computern und Spielkonsolen entwickelt wurden. Sie funktionieren, indem sie komplexe Probleme in mehrere Aufgaben aufteilen und diese gleichzeitig bearbeiten, anstatt eine nach der anderen, wie es bei CPUs der Fall ist.
Aufgrund ihrer parallelen Rechenleistung haben sich ihre Fähigkeiten über die Grafikverarbeitung hinaus deutlich weiterentwickelt und sind zu integralen Bestandteilen verschiedener Computeranwendungen geworden, z. B. bei der Entwicklung von KI-Modellen.
Aber lass uns ein bisschen zurückspulen.
GPUs kamen in den 1980er Jahren als spezielle Hardware zur Beschleunigung des Grafik-Renderings auf den Markt. Unternehmen wie NVIDIA und ATI (jetzt Teil von AMD) spielten eine entscheidende Rolle bei ihrer Entwicklung. Aber erst in den späten 1990er und frühen 2000er Jahren wurden sie im Mainstream populär. Die Einführung programmierbarer Shader ermöglichte es Entwicklern, die Parallelverarbeitung auch für andere Aufgaben als die Grafik zu nutzen.
In den 2000er Jahren wurden GPUs verstärkt für allgemeine Rechenaufgaben jenseits der Grafik erforscht. NVIDIAs CUDA (Compute Unified Device Architecture) und AMDs Stream SDK ermöglichen es Entwicklern, die Rechenleistung von Grafikprozessoren für wissenschaftliche Simulationen, Datenanalysen und vieles mehr zu nutzen.
Dann kam der Aufstieg der KI und des Deep Learning.
Grafikprozessoren haben sich als unverzichtbare Werkzeuge für das Training und den Einsatz von Deep Learning-Modellen erwiesen, da sie große Datenmengen verarbeiten und Berechnungen parallel durchführen können.
Frameworks wie TensorFlow und PyTorch nutzen die GPU-Beschleunigung und machen Deep Learning für Forscher und Entwickler weltweit zugänglich.
Tensor Processing Units (TPUs) sind eine Art anwendungsspezifischer integrierter Schaltungen (ASICs), die von Google entwickelt wurden, um den wachsenden Rechenanforderungen des maschinellen Lernens gerecht zu werden.
Im Gegensatz zu GPUs, die ursprünglich für Grafikverarbeitungsaufgaben entwickelt und später an die Anforderungen der KI angepasst wurden, wurden TPUs speziell für die Beschleunigung von maschinellen Lernprozessen entwickelt.
Da sie für maschinelles Lernen entwickelt wurden, sind TPUs speziell für Tensor-Operationen ausgelegt, die für Deep-Learning-Algorithmen grundlegend sind.
Dank ihrer maßgeschneiderten Architektur, die für die Matrixmultiplikation, eine Schlüsseloperation in neuronalen Netzen, optimiert ist, können sie große Datenmengen verarbeiten und komplexe neuronale Netze effizient ausführen, was schnelle Trainings- und Inferenzzeiten ermöglicht.
Diese spezielle Optimierung macht TPUs für KI-Anwendungen unverzichtbar und treibt die Forschung und den Einsatz von maschinellem Lernen voran.
TPUs und GPUs bieten unterschiedliche Vorteile und sind für verschiedene Berechnungsaufgaben optimiert. Beide können zwar maschinelles Lernen beschleunigen, aber ihre Architekturen und Optimierungen führen je nach Aufgabe zu unterschiedlichen Leistungen.
Zunächst einmal sind sowohl GPUs als auch TPUs spezialisierte Hardware-Beschleuniger, die die Leistung bei KI-Aufgaben steigern sollen. Sie unterscheiden sich jedoch in ihrer Rechenarchitektur, was sich erheblich auf ihre Effizienz und Effektivität bei der Bewältigung bestimmter Arten von Berechnungen auswirkt.
GPUs bestehen aus Tausenden von kleinen, effizienten Kernen, die für die parallele Verarbeitung entwickelt wurden.
Diese Architektur ermöglicht es ihnen, mehrere Aufgaben gleichzeitig auszuführen, was sie sehr effektiv für Aufgaben macht, die parallelisiert werden können, wie z.B. Grafikrendering und Deep Learning.
GPUs sind besonders geschickt bei Matrixoperationen, die bei der Berechnung von neuronalen Netzen häufig vorkommen. Durch ihre Fähigkeit, große Datenmengen zu verarbeiten und Berechnungen parallel auszuführen, eignen sie sich gut für KI-Aufgaben, bei denen große Datenmengen verarbeitet und komplexe mathematische Operationen ausgeführt werden müssen.
Im Gegensatz dazu priorisieren TPUs Tensor-Operationen, so dass sie Berechnungen effizient durchführen können. TPUs haben zwar nicht so viele Kerne wie GPUs, aber ihre spezielle Architektur ermöglicht es ihnen, GPUs bei bestimmten Arten von KI-Aufgaben zu übertreffen, insbesondere bei solchen, die stark auf Tensor-Operationen angewiesen sind.
Dennoch sind GPUs hervorragend für Aufgaben geeignet, die von paralleler Verarbeitung profitieren, wie z.B. Grafikrendering und wissenschaftliche Simulationen.
Auf der anderen Seite sind TPUs für die Tensor-Verarbeitung optimiert, was sie für Deep Learning-Aufgaben, die Matrixoperationen beinhalten, sehr effizient macht. Je nach den spezifischen Anforderungen der KI-Arbeitslast bieten entweder GPUs oder TPUs eine bessere Leistung und Effizienz.
Grafikprozessoren sind für ihre Vielseitigkeit bei der Bewältigung verschiedener KI-Aufgaben bekannt, darunter das Trainieren von Deep-Learning-Modellen und die Durchführung von Inferenzoperationen. Das liegt daran, dass die GPU-Architektur, die auf paralleler Verarbeitung beruht, die Trainings- und Inferenzgeschwindigkeit für zahlreiche KI-Modelle erheblich steigert. Die Verarbeitung eines Stapels von 128 Sequenzen mit einem BERT-Modell dauert zum Beispiel 3,8 Millisekunden auf einer V100 GPU im Vergleich zu 1,7 Millisekunden auf einer TPU v3.
Umgekehrt sind TPUs auf schnelle und effiziente Tensor-Operationen abgestimmt, die für neuronale Netze entscheidend sind. Dank dieser Spezialisierung sind TPUs bei bestimmten Deep-Learning-Aufgaben oft leistungsfähiger als GPUs, insbesondere bei den von Google optimierten Aufgaben wie dem Training umfangreicher neuronaler Netzwerke und komplexer Machine-Learning-Modelle.
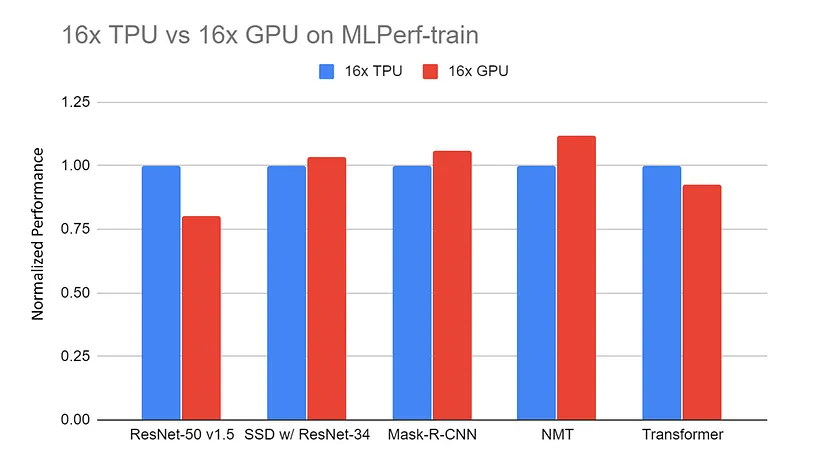
16x GPU Server (DGX-2H) vs. 16x TPU v3 Server normalisierte Leistung bei MLPerf-train Benchmarks. Die Daten werden von der MLPerf-Website gesammelt. Alle TPU-Ergebnisse werden mit TensorFlow erzielt. Alle GPU-Ergebnisse verwenden Pytorch, außer ResNet, das MxNet | verwendet.
Quelle: TPU vs. GPU vs. Cerebras vs. Graphcore: Ein fairer Vergleich zwischen ML-Hardware von Mahmoud Khairy
Vergleiche zwischen TPUs und GPUs bei ähnlichen Aufgaben zeigen häufig, dass TPUs den GPUs bei Aufgaben, die speziell auf ihre Architektur zugeschnitten sind, überlegen sind und kürzere Trainingszeiten und eine effektivere Verarbeitung bieten.
So dauert das Training eines ResNet-50-Modells auf dem CIFAR-10-Datensatz für 10 Epochen mit einem NVIDIA Tesla V100 Grafikprozessor etwa 40 Minuten, durchschnittlich 4 Minuten pro Epoche. Im Gegensatz dazu dauert das gleiche Training mit einer Google Cloud TPU v3 nur 15 Minuten, im Durchschnitt 1,5 Minuten pro Epoche.
Nichtsdestotrotz sind GPUs aufgrund ihrer Anpassungsfähigkeit und der beträchtlichen Optimierungsanstrengungen der Community in einem breiteren Spektrum von Anwendungen wettbewerbsfähig.
Die Entscheidung zwischen GPU und TPU hängt vom Budget, dem Rechenbedarf und der Verfügbarkeit ab. Jede Option bietet einzigartige Vorteile für verschiedene Anwendungen. In diesem Abschnitt werden wir sehen, wie GPUs und TPUs in Bezug auf Kosten und Marktzugänglichkeit im Vergleich stehen.
GPUs bieten viel mehr Flexibilität als TPUs, wenn es um die Kosten geht. Zunächst einmal werden TPUs nicht einzeln verkauft; sie sind nur als Cloud-Service über Anbieter wie Google Cloud Platform (GCP) erhältlich. Im Gegensatz dazu können GPUs einzeln gekauft werden.
Die ungefähren Kosten für einen NVIDIA Tesla V100 Grafikprozessor liegen zwischen 8.000 und 10.000 US-Dollar pro Einheit, und eine NVIDIA A100 Grafikprozessoreinheit kostet zwischen 10.000 und 15.000 US-Dollar. Du hast aber auch die Möglichkeit, die Cloud auf Abruf zu nutzen.
Wenn du den NVIDIA Tesla V100 Grafikprozessor zum Trainieren eines Deep Learning-Modells verwendest, kostet dich das wahrscheinlich etwa 2,48 Dollar pro Stunde, und der NVIDIA A100 würde etwa 2,93 Dollar kosten. Die Google Cloud TPU V3 würde dagegen etwa 4,50 $ pro Stunde kosten und die Google Cloud TPU V4 kostet ungefähr 8,00 $ pro Stunde.
Mit anderen Worten: TPUs sind viel weniger flexibel als GPUs und haben in der Regel höhere Stundenkosten für On-Demand-Cloud-Computing als GPUs. TPUs bieten jedoch oft eine schnellere Leistung, die die gesamte Rechenzeit für umfangreiche maschinelle Lernaufgaben reduzieren kann, was trotz der höheren Stundensätze zu Kosteneinsparungen führen kann.
Die Verfügbarkeit von TPUs und GPUs auf dem Markt ist sehr unterschiedlich, was sich auf ihre Akzeptanz in verschiedenen Branchen und Regionen auswirkt...
TPUs, die von Google entwickelt wurden, sind hauptsächlich über die Google Cloud Platform (GCP) für cloudbasierte KI-Aufgaben zugänglich. Das bedeutet, dass sie vor allem von Menschen genutzt werden, die auf GCP angewiesen sind, was sie in Gegenden und Branchen, in denen Cloud Computing eine große Rolle spielt, wie z.B. in Tech-Hubs oder an Orten mit starken Internetverbindungen, beliebter macht.
Mittlerweile werden Grafikprozessoren von Unternehmen wie NVIDIA, AMD und Intel hergestellt und sind in verschiedenen Varianten für Verbraucher und Unternehmen erhältlich. Diese größere Verfügbarkeit macht GPUs zu einer beliebten Wahl in verschiedenen Branchen, darunter Spiele, Wissenschaft, Finanzen, Gesundheitswesen und Produktion. GPUs können sowohl vor Ort als auch in der Cloud eingesetzt werden, was den Nutzern mehr Flexibilität bei der Einrichtung ihrer Rechenleistung bietet.
Folglich ist es wahrscheinlicher, dass GPUs in verschiedenen Branchen und Regionen eingesetzt werden, unabhängig von ihrer technischen Infrastruktur oder ihrem Bedarf an Rechenleistung. Insgesamt beeinflusst die Marktverfügbarkeit von TPUs und GPUs, wie sie eingesetzt werden. TPUs sind eher in Cloud-fokussierten Bereichen und Sektoren (z. B. maschinelles Lernen) verbreitet, während GPUs in verschiedenen Bereichen und an verschiedenen Orten eingesetzt werden.
Die TPUs von Google sind eng mit TensorFlow integriert, dem führenden Open-Source-Framework für maschinelles Lernen. JAX, eine weitere Bibliothek für numerische Hochleistungsberechnungen, unterstützt ebenfalls TPUs und ermöglicht effizientes maschinelles Lernen und wissenschaftliche Berechnungen.
TPUs sind nahtlos in das TensorFlow-Ökosystem integriert, so dass es für TensorFlow-Nutzer einfach ist, TPU-Fähigkeiten zu nutzen. TensorFlow bietet zum Beispiel Tools wie den TensorFlow XLA (Accelerated Linear Algebra) Compiler, der Berechnungen für TPUs optimiert.
TPUs wurden entwickelt, um TensorFlow-Operationen zu beschleunigen und die Leistung für Training und Inferenz zu optimieren. Sie unterstützen auch die High-Level-APIs von TensorFlow, was es einfacher macht, Modelle für die TPU-Ausführung zu migrieren und zu optimieren.
Im Gegensatz dazu sind GPUs in verschiedenen Branchen und Forschungsbereichen weit verbreitet, was sie für verschiedene Anwendungen des maschinellen Lernens beliebt macht. Das bedeutet, dass sie mehr Integrationen haben als GPUs und von einer breiteren Palette von Deep-Learning-Frameworks unterstützt werden, darunter TensorFlow, PyTorch, Keras, MXNet und Caffe.
GPUs profitieren außerdem von umfangreichen Bibliotheken und Tools wie CUDA, cuDNN und RAPIDS, was ihre Vielseitigkeit und die einfache Integration in verschiedene Workflows für maschinelles Lernen und Data Science weiter erhöht.
Was die Unterstützung durch die Community angeht, so haben GPUs ein breiteres Ökosystem mit umfangreichen Foren, Tutorials und Dokumentationen, die von verschiedenen Quellen wie NVIDIA, AMD und von der Community betriebenen Plattformen bereitgestellt werden. Entwickler können auf lebendige Online-Communities, Foren und Benutzergruppen zugreifen, um Hilfe zu suchen, Wissen auszutauschen und gemeinsam an Projekten zu arbeiten. Darüber hinaus gibt es zahlreiche Tutorials, Kurse und Dokumentationsressourcen zur GPU-Programmierung, zu Deep-Learning-Frameworks und Optimierungstechniken.
Die Unterstützung der Community für TPUs ist stärker auf das Google-Ökosystem ausgerichtet. Ressourcen sind hauptsächlich über die GCP-Dokumentation, Foren und Support-Kanäle verfügbar. Google stellt zwar eine umfassende Dokumentation und Tutorials zur Verfügung, die speziell auf die Verwendung von TPUs mit TensorFlow zugeschnitten sind, aber die Unterstützung durch die Community ist möglicherweise begrenzter als im breiteren GPU-Ökosystem. Die offiziellen Supportkanäle und Entwicklerressourcen von Google bieten Entwicklern, die TPUs für KI-Workloads nutzen, jedoch weiterhin wertvolle Unterstützung.
Die Energieeffizienz von GPUs und TPUs variiert je nach Architektur und Anwendungsbereich. Im Allgemeinen sind TPUs energieeffizienter als GPUs, insbesondere die Google Cloud TPU v3, die deutlich energieeffizienter ist als die High-End-GPUs von NVIDIA.
Für mehr Kontext:
Der geringere Stromverbrauch der TPUs kann zu deutlich niedrigeren Betriebskosten und einer höheren Energieeffizienz beitragen, insbesondere bei groß angelegten maschinellen Lernanwendungen.
TPUs und GPUs nutzen spezielle Optimierungen, um die Energieeffizienz bei umfangreichen KI-Operationen zu verbessern.
Wie bereits erwähnt, ist die TPU-Architektur so konzipiert, dass sie Tensor-Operationen, die häufig in neuronalen Netzen verwendet werden, priorisiert und so die effiziente Ausführung von KI-Aufgaben bei minimalem Energieverbrauch ermöglicht. TPUs verfügen außerdem über benutzerdefinierte Speicherhierarchien, die für KI-Berechnungen optimiert sind und die Speicherzugriffslatenz und den Energieaufwand reduzieren.
Sie nutzen Techniken wie Quantisierung und Sparsamkeit, um arithmetische Operationen zu optimieren und den Stromverbrauch zu minimieren, ohne die Genauigkeit zu beeinträchtigen. Diese Faktoren ermöglichen es TPUs, hohe Leistungen zu erbringen und gleichzeitig Energie zu sparen.
Ebenso implementieren GPUs energieeffiziente Optimierungen, um die Leistung bei KI-Operationen zu verbessern. Moderne GPU-Architekturen verfügen über Funktionen wie Power Gating und Dynamic Voltage and Frequency Scaling (DVFS), um den Stromverbrauch an die Arbeitslast anzupassen. Sie nutzen außerdem parallele Verarbeitungstechniken, um Rechenaufgaben auf mehrere Kerne zu verteilen und so den Durchsatz zu maximieren und gleichzeitig den Energieverbrauch pro Vorgang zu minimieren.
GPU-Hersteller entwickeln energieeffiziente Speicherarchitekturen und Cache-Hierarchien, um die Speicherzugriffsmuster zu optimieren und den Energieverbrauch bei Datenübertragungen zu senken. Diese Optimierungen, kombiniert mit Softwaretechniken wie Kernel Fusion und Loop Unrolling, verbessern die Energieeffizienz von GPU-beschleunigten KI-Workloads weiter.
TPUs und GPUs bieten beide Skalierbarkeit für große KI-Projekte, aber sie gehen unterschiedlich vor. TPUs sind eng in die Cloud-Infrastruktur integriert, insbesondere über die Google Cloud Platform (GCP), die skalierbare Ressourcen für KI-Workloads bietet. Die Nutzer können nach Bedarf auf TPUs zugreifen und diese je nach Rechenbedarf vergrößern oder verkleinern, was für die effiziente Durchführung großer KI-Projekte entscheidend ist. Google bietet Managed Services und vorkonfigurierte Umgebungen für den Einsatz von KI-Modellen auf TPUs an und vereinfacht so den Integrationsprozess in die Cloud-Infrastruktur.
Andererseits skalieren GPUs auch effektiv für große KI-Projekte, mit Optionen für den Einsatz vor Ort oder die Nutzung in Cloud-Umgebungen, die von Anbietern wie Amazon Web Services (AWS) und Microsoft Azure angeboten werden. GPUs bieten Flexibilität bei der Skalierung und ermöglichen es den Nutzern, mehrere GPUs parallel einzusetzen, um die Rechenleistung zu erhöhen.
Außerdem eignen sich GPUs dank ihrer hohen Speicherbandbreite und parallelen Verarbeitung hervorragend für die Verarbeitung großer Datenmengen. Dies ermöglicht eine effiziente Datenverarbeitung und ein effizientes Modelltraining, was für große KI-Projekte mit riesigen Datensätzen unerlässlich ist.
Insgesamt bieten sowohl TPUs als auch GPUs Skalierbarkeit für große KI-Projekte, wobei TPUs eng in die Cloud-Infrastruktur integriert sind und GPUs Flexibilität für den Einsatz vor Ort oder in der Cloud bieten. Ihre Fähigkeit, große Datenmengen zu verarbeiten und Rechenressourcen zu skalieren, macht sie für die Bewältigung komplexer KI-Aufgaben im großen Maßstab unschätzbar.
| Feature | GPUs | TPUs |
|---|---|---|
| Computergestützte Architektur | Tausende von kleinen, effizienten Kernen für die parallele Verarbeitung | Priorisierung von Tensor-Operationen, spezialisierte Architektur |
| Leistung | Vielseitig, ausgezeichnet in verschiedenen KI-Aufgaben, einschließlich Deep Learning und Inferenz | Optimiert für Tensor-Operationen, oft leistungsfähiger als GPUs bei bestimmten Deep Learning-Aufgaben |
| Geschwindigkeit und Effizienz | Z.B. 128 Sequenzen mit dem BERT-Modell: 3,8 ms auf der V100 GPU | Z.B. 128 Sequenzen mit dem BERT-Modell: 1,7 ms auf TPU v3 |
| Benchmarks | ResNet-50 auf CIFAR-10: 40 Minuten für 10 Epochen (4 Minuten/Epoche) auf Tesla V100 GPU | ResNet-50 auf CIFAR-10: 15 Minuten für 10 Epochen (1,5 Minuten/Epoche) auf Google Cloud TPU v3 |
| Kosten | NVIDIA Tesla V100: $8.000 - $10.000/Einheit, $2,48/Stunde; NVIDIA A100: $10.000 - $15.000/Einheit, $2,93/Stunde | Google Cloud TPU v3: $4,50/Stunde; TPU v4: $8,00/Stunde |
| Verfügbarkeit | Weit verbreitet von mehreren Anbietern (NVIDIA, AMD, Intel), für Verbraucher und Unternehmen | Hauptsächlich über die Google Cloud Platform (GCP) zugänglich |
| Ökosystem und Entwicklungswerkzeuge | Unterstützt von vielen Frameworks (TensorFlow, PyTorch, Keras, MXNet, Caffe), umfangreichen Bibliotheken (CUDA, cuDNN, RAPIDS) | Integriert mit TensorFlow, unterstützt JAX, optimiert durch TensorFlow XLA Compiler |
| Unterstützung und Ressourcen der Gemeinschaft | Breites Ökosystem mit umfangreichen Foren, Tutorials und Dokumentationen von NVIDIA, AMD und den Communities | Zentralisiert um das Google-Ökosystem mit GCP-Dokumentation, Foren und Support-Kanälen |
| Energie-Effizienz | NVIDIA Tesla V100: 250 watts; NVIDIA A100: 400 Watt | Google Cloud TPU v3: 120-150 watts; TPU v4: 200-250 Watt |
| Optimierung für KI-Aufgaben | Energieeffiziente Optimierungen (Power Gating, DVFS, Parallelverarbeitung, Kernel-Fusion) | Individuelle Speicherhierarchien, Quantisierung und Sparsamkeit für effiziente KI-Berechnungen |
| Skalierbarkeit in Unternehmensanwendungen | Skalierbar für große KI-Projekte, vor Ort oder in der Cloud (AWS, Azure), hohe Speicherbandbreite, parallele Verarbeitung | Enge Integration in die Cloud-Infrastruktur (GCP), Skalierbarkeit nach Bedarf, Managed Services für den Einsatz von KI-Modellen |
Wähle GPUs, wenn:
Wähle TPUs, wenn:
GPUs und TPUs sind spezielle Hardware-Beschleuniger, die in KI-Anwendungen eingesetzt werden. Ursprünglich für das Rendering von Grafiken entwickelt, zeichnen sich GPUs durch parallele Verarbeitung aus und wurden für KI-Aufgaben adaptiert, wodurch sie in verschiedenen Branchen vielseitig einsetzbar sind. TPUs hingegen werden von Google speziell für KI-Workloads entwickelt und priorisieren Tensor-Operationen, wie sie in neuronalen Netzwerken üblich sind.
Dieser Artikel vergleicht GPU- und TPU-Technologien anhand ihrer Leistung, Kosten und Verfügbarkeit, ihres Ökosystems und ihrer Entwicklung, ihrer Energieeffizienz und Umweltverträglichkeit sowie ihrer Skalierbarkeit in KI-Anwendungen. Um dein Wissen über TPUs und GPUs zu erweitern, schau dir einige dieser Ressourcen an, um dein Wissen zu erweitern:
Erlerne KI-Fähigkeiten mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
