
Cursus
Principes fondamentaux de l'IA
10 h
L'essor du développement de l'intelligence artificielle (IA) a entraîné une augmentation notable de la demande en matière de calcul, d'où la nécessité de disposer de solutions matérielles robustes. Les unités de traitement graphique (GPU) et les unités de traitement tensoriel (TPU) sont devenues des technologies essentielles pour répondre à ces demandes.
Conçus à l'origine pour le rendu graphique, les GPU sont devenus des processeurs polyvalents capables de traiter efficacement des tâches d'intelligence artificielle grâce à leurs capacités de traitement parallèle. En revanche, les TPU, développées par Google, sont spécifiquement optimisées pour les calculs d'IA et offrent des performances supérieures adaptées à des tâches telles que les projets d'apprentissage automatique.
Dans cet article, nous allons discuter des GPU et des TPU et comparer les deux technologies sur la base d'indicateurs tels que les performances, le coût, l'écosystème, etc. Nous vous donnerons également un aperçu de leur efficacité énergétique, de leur impact sur l'environnement et de leur évolutivité dans les applications d'entreprise.
Les GPU sont des processeurs spécialisés initialement développés pour le rendu des images et des graphiques dans les ordinateurs et les consoles de jeu. Ils fonctionnent en décomposant les problèmes complexes en plusieurs tâches et en les traitant simultanément plutôt qu'une par une, comme c'est le cas dans les unités centrales de traitement.
Grâce à leur puissance de traitement parallèle, leurs capacités ont considérablement évolué au-delà du traitement graphique, devenant des composants à part entière dans diverses applications informatiques, telles que le développement de modèles d'intelligence artificielle.
Mais revenons un peu en arrière.
Les GPU sont apparus pour la première fois dans les années 1980 en tant que matériel spécialisé pour accélérer le rendu graphique. Des sociétés comme NVIDIA et ATI (qui fait aujourd'hui partie d'AMD) ont joué un rôle essentiel dans leur développement. Cependant, ce n'est qu'à la fin des années 1990 et au début des années 2000 qu'ils ont gagné en popularité auprès du grand public. Leur adoption est due à l'introduction des nuanceurs programmables, qui permettent aux développeurs d'exploiter le traitement parallèle pour des tâches autres que le graphisme.
Dans les années 2000, la recherche a davantage exploré les GPU pour des tâches informatiques générales au-delà du graphisme. Le CUDA (Compute Unified Device Architecture) de NVIDIA et le SDK Stream d'AMD ont permis aux développeurs d'exploiter la puissance de traitement du GPU pour les simulations scientifiques, l'analyse des données, etc.
C'est alors qu'est apparue l'IA et l'apprentissage profond.
Les GPU se sont imposés comme des outils indispensables pour l'entraînement et le déploiement de modèles d'apprentissage profond en raison de leur capacité à traiter des quantités massives de données et à effectuer des calculs en parallèle.
Des frameworks comme TensorFlow et PyTorch utilisent l'accélération GPU, rendant l'apprentissage profond accessible aux chercheurs et aux développeurs du monde entier.
Les unités de traitement tensoriel (TPU) sont un type de circuit intégré spécifique à une application (ASIC) mis au point par Google pour répondre aux exigences croissantes en matière de calcul dans le domaine de l'apprentissage automatique.
Contrairement aux GPU, qui ont été initialement créés pour les tâches de traitement graphique puis modifiés pour répondre aux exigences de l'IA, les TPU ont été conçues spécifiquement pour accélérer les charges de travail liées à l'apprentissage automatique.
Conçues pour l'apprentissage automatique, les TPU sont spécialement conçues pour les opérations tensorielles, qui sont fondamentales pour les algorithmes d'apprentissage profond.
Grâce à leur architecture personnalisée optimisée pour la multiplication matricielle, une opération clé dans les réseaux neuronaux, ils excellent dans le traitement de grands volumes de données et dans l'exécution efficace de réseaux neuronaux complexes, permettant des temps d'apprentissage et d'inférence rapides.
Cette optimisation spécialisée rend les TPU indispensables pour les applications d'IA, favorisant les avancées dans la recherche et le déploiement de l'apprentissage automatique.
Les TPU et les GPU offrent des avantages distincts et sont optimisés pour des tâches de calcul différentes. Bien qu'ils puissent tous deux accélérer les charges de travail d'apprentissage automatique, leurs architectures et leurs optimisations entraînent des variations de performances en fonction de la tâche spécifique.
Tout d'abord, les GPU et les TPU sont des accélérateurs matériels spécialisés conçus pour améliorer les performances des tâches d'intelligence artificielle, mais ils diffèrent par leurs architectures de calcul, ce qui a un impact significatif sur leur efficacité et leur efficience dans le traitement de types de calculs spécifiques.
Les GPU sont constitués de milliers de petits cœurs efficaces conçus pour le traitement parallèle.
Cette architecture leur permet d'exécuter plusieurs tâches simultanément, ce qui les rend très efficaces pour les tâches pouvant être parallélisées, telles que le rendu graphique et l'apprentissage profond.
Les GPU sont particulièrement compétents pour les opérations matricielles, qui sont courantes dans les calculs de réseaux neuronaux. Leur capacité à traiter de grands volumes de données et à exécuter des calculs en parallèle les rend bien adaptés aux tâches d'IA qui impliquent le traitement d'ensembles massifs de données et l'exécution d'opérations mathématiques complexes.
En revanche, les TPU donnent la priorité aux opérations tensorielles, ce qui leur permet d'effectuer des calculs de manière efficace. Bien que les TPU n'aient pas autant de cœurs que les GPU, leur architecture spécialisée leur permet de surpasser les GPU dans certains types de tâches d'intelligence artificielle, en particulier celles qui reposent fortement sur des opérations tensorielles.
Cela dit, les GPU excellent dans les tâches qui bénéficient d'un traitement parallèle et sont bien adaptés à divers calculs au-delà de l'IA, tels que le rendu graphique et les simulations scientifiques.
D'autre part, les TPU sont optimisées pour le traitement des tenseurs, ce qui les rend très efficaces pour les tâches d'apprentissage en profondeur qui impliquent des opérations matricielles. En fonction des exigences spécifiques de la charge de travail de l'IA, les GPU ou les TPU peuvent offrir de meilleures performances et une plus grande efficacité.
Les GPU sont connus pour leur polyvalence dans le traitement de diverses tâches d'IA, y compris l'entraînement de modèles d'apprentissage profond et l'exécution d'opérations d'inférence. En effet, l'architecture GPU, qui repose sur le traitement parallèle, augmente considérablement la vitesse de formation et d'inférence pour de nombreux modèles d'IA. Par exemple, le traitement d'un lot de 128 séquences avec un modèle BERT prend 3,8 millisecondes sur un GPU V100 contre 1,7 millisecondes sur une TPU v3.
À l'inverse, les TPU sont parfaitement adaptées aux opérations tensorielles rapides et efficaces, qui sont des composantes essentielles des réseaux neuronaux. Cette spécialisation permet souvent aux TPU de surpasser les GPU dans des tâches spécifiques d'apprentissage profond, en particulier celles optimisées par Google, comme l'entraînement de réseaux neuronaux étendus et les modèles complexes d'apprentissage automatique.
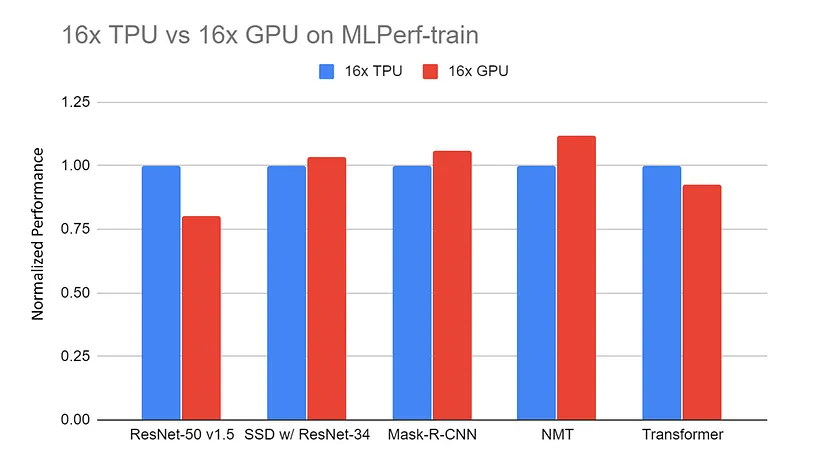
Performance normalisée du serveur 16x GPU (DGX-2H) par rapport au serveur 16x TPU v3 sur les benchmarks MLPerf-train. Les données sont collectées sur le site web de MLPerf. Tous les résultats de la TPU utilisent TensorFlow. Tous les résultats obtenus avec le GPU utilisent Pytorch, sauf ResNet qui utilise MxNet.
Source : TPU vs. GPU vs Cerebras vs. Graphcore : Une comparaison équitable entre le matériel de ML par Mahmoud Khairy
Les comparaisons entre les TPU et les GPU dans des tâches similaires révèlent souvent que les TPU surpassent les GPU dans des tâches spécifiquement adaptées à leur architecture, offrant des durées d'apprentissage plus rapides et un traitement plus efficace.
Par exemple, l'entraînement d'un modèle ResNet-50 sur l'ensemble de données CIFAR-10 pendant 10 époques à l'aide d'un GPU NVIDIA Tesla V100 prend environ 40 minutes, soit une moyenne de 4 minutes par époque. En revanche, en utilisant une TPU v3 de Google Cloud, le même entraînement ne prend que 15 minutes, avec une moyenne de 1,5 minute par époch.
Néanmoins, les GPU conservent des performances compétitives dans un plus large spectre d'applications grâce à leur adaptabilité et aux efforts considérables d'optimisation entrepris par la communauté.
Le choix entre GPU et TPU dépend du budget, des besoins informatiques et de la disponibilité. Chaque option offre des avantages uniques pour différentes applications. Dans cette section, nous verrons comment les GPU et les TPU se comparent en termes de coût et d'accessibilité au marché.
Les GPU offrent beaucoup plus de flexibilité que les TPU en ce qui concerne les coûts. Pour commencer, les TPU ne sont pas vendues individuellement ; elles ne sont disponibles que sous la forme d'un service cloud par l'intermédiaire de fournisseurs tels que Google Cloud Platform (GCP). En revanche, les GPU peuvent être achetés individuellement.
Le coût approximatif d'un GPU NVIDIA Tesla V100 se situe entre 8 000 et 10 000 dollars par unité, et celui d'un GPU NVIDIA A100 entre 10 000 et 15 000 dollars. Mais vous pouvez également opter pour une tarification du cloud à la demande.
L'utilisation du GPU NVIDIA Tesla V100 pour entraîner un modèle d'apprentissage profond devrait vous coûter environ 2,48 $ par heure, et le NVIDIA A100 environ 2,93 $. En revanche, la Google Cloud TPU V3 coûterait environ 4,50 dollars par heure, et la Google Cloud TPU V4 environ 8 dollars par heure.
En d'autres termes, les TPU sont beaucoup moins flexibles que les GPU et leurs coûts horaires pour le cloud computing à la demande sont généralement plus élevés que ceux des GPU. Cependant, les TPU offrent souvent des performances plus rapides, ce qui peut réduire le temps de calcul total requis pour les tâches d'apprentissage automatique à grande échelle, ce qui peut conduire à des économies globales malgré des taux horaires plus élevés.
La disponibilité des TPU et des GPU sur le marché varie considérablement, ce qui influence leur adoption dans différentes industries et régions...
Les TPU, développées par Google, sont principalement accessibles via la Google Cloud Platform (GCP) pour les tâches d'IA basées sur le cloud. Cela signifie qu'ils sont principalement utilisés par des personnes qui comptent sur GCP pour leurs besoins informatiques, ce qui pourrait les rendre plus populaires dans les zones et les industries qui misent beaucoup sur le cloud computing, comme les centres technologiques ou les endroits dotés de connexions internet solides.
Les GPU sont fabriqués par des sociétés telles que NVIDIA, AMD et Intel, et sont disponibles en différentes options pour les particuliers et les entreprises. Cette plus grande disponibilité fait des GPU un choix populaire dans divers secteurs, notamment les jeux, la science, la finance, les soins de santé et la fabrication. Les GPU peuvent être installés sur site ou dans le cloud, ce qui offre aux utilisateurs une certaine flexibilité dans leur configuration informatique.
Par conséquent, les GPU sont plus susceptibles d'être utilisés dans différentes industries et régions, indépendamment de leur infrastructure technologique ou de leurs besoins informatiques. Globalement, la disponibilité des TPU et des GPU sur le marché influe sur leur adoption. Les TPU sont plus courantes dans les domaines et secteurs axés sur le cloud (par exemple, l'apprentissage automatique), tandis que les GPU sont largement utilisés dans différents domaines et lieux.
Les TPU de Google sont étroitement intégrées à TensorFlow, son principal cadre d'apprentissage machine open-source. JAX, une autre bibliothèque pour le calcul numérique à haute performance, prend également en charge les TPU, ce qui permet un apprentissage automatique et un calcul scientifique efficaces.
Les TPU sont intégrées de manière transparente dans l'écosystème TensorFlow, ce qui permet aux utilisateurs de TensorFlow d'exploiter facilement les capacités des TPU. Par exemple, TensorFlow propose des outils tels que le compilateur TensorFlow XLA (Accelerated Linear Algebra), qui optimise les calculs pour les TPU.
Par essence, les TPU sont conçues pour accélérer les opérations TensorFlow, offrant des performances optimisées pour la formation et l'inférence. Ils prennent également en charge les API de haut niveau de TensorFlow, ce qui facilite la migration et l'optimisation des modèles pour l'exécution sur TPU.
En revanche, les GPU sont largement adoptés dans divers secteurs et domaines de recherche, ce qui les rend populaires pour diverses applications d'apprentissage automatique. Cela signifie qu'ils disposent de plus d'intégrations que les GPU et qu'ils sont pris en charge par un plus grand nombre de frameworks d'apprentissage profond, notamment TensorFlow, PyTorch, Keras, MXNet et Caffe.
Les GPU bénéficient également de bibliothèques et d'outils complets tels que CUDA, cuDNN et RAPIDS, ce qui améliore encore leur polyvalence et leur facilité d'intégration dans divers flux de travail d'apprentissage automatique et de science des données.
En ce qui concerne le soutien de la communauté, les GPU disposent d'un écosystème plus large avec des forums, des tutoriels et de la documentation disponibles auprès de diverses sources telles que NVIDIA, AMD et des plates-formes communautaires. Les développeurs peuvent accéder à des communautés en ligne, des forums et des groupes d'utilisateurs dynamiques pour demander de l'aide, partager leurs connaissances et collaborer à des projets. En outre, de nombreux tutoriels, cours et ressources documentaires couvrent la programmation GPU, les cadres d'apprentissage profond et les techniques d'optimisation.
Le soutien de la communauté pour les TPU est plus centralisé autour de l'écosystème de Google, avec des ressources principalement disponibles dans la documentation GCP, les forums et les canaux d'assistance. Bien que Google fournisse une documentation complète et des tutoriels spécialement conçus pour l'utilisation des TPU avec TensorFlow, le soutien de la communauté peut être plus limité que celui de l'écosystème GPU au sens large. Cependant, les canaux d'assistance officiels de Google et les ressources pour les développeurs offrent toujours une aide précieuse aux développeurs qui utilisent les TPU pour les charges de travail d'intelligence artificielle.
L'efficacité énergétique des GPU et des TPU varie en fonction de leurs architectures et des applications auxquelles elles sont destinées. En général, les TPU sont plus économes en énergie que les GPU, notamment la Google Cloud TPU v3, qui est nettement plus économe en énergie que les GPU NVIDIA haut de gamme.
Pour plus de détails :
La faible consommation d'énergie des TPU peut contribuer à réduire considérablement les coûts d'exploitation et à améliorer l'efficacité énergétique, en particulier dans les déploiements d'apprentissage automatique à grande échelle.
Les TPU et les GPU utilisent des optimisations spécifiques pour améliorer l'efficacité énergétique lors de l'exécution d'opérations d'IA à grande échelle.
Comme indiqué plus haut dans l'article, l'architecture de la TPU est conçue pour donner la priorité aux opérations tensorielles couramment utilisées dans les réseaux neuronaux, ce qui permet l'exécution efficace de tâches d'intelligence artificielle avec une consommation d'énergie minimale. Les TPU sont également dotées de hiérarchies de mémoire personnalisées optimisées pour les calculs d'IA, réduisant la latence d'accès à la mémoire et la consommation d'énergie.
Ils exploitent des techniques telles que la quantification et l'éparpillement pour optimiser les opérations arithmétiques, en minimisant la consommation d'énergie sans sacrifier la précision. Ces facteurs permettent aux TPU de fournir des performances élevées tout en conservant l'énergie.
De la même manière, les GPU mettent en œuvre des optimisations écoénergétiques pour améliorer les performances des opérations d'IA. Les architectures modernes de GPU intègrent des fonctions telles que le power gating et le dynamic voltage and frequency scaling (DVFS) pour ajuster la consommation d'énergie en fonction des exigences de la charge de travail. Ils utilisent également des techniques de traitement parallèle pour répartir les tâches de calcul sur plusieurs cœurs, maximisant ainsi le débit tout en minimisant l'énergie par opération.
Les fabricants de GPU développent des architectures de mémoire et des hiérarchies de cache économes en énergie afin d'optimiser les schémas d'accès à la mémoire et de réduire la consommation d'énergie lors des transferts de données. Ces optimisations, associées à des techniques logicielles telles que la fusion des noyaux et le déroulement des boucles, améliorent encore l'efficacité énergétique des charges de travail d'IA accélérées par le GPU.
Les TPU et les GPU offrent tous deux une évolutivité pour les grands projets d'IA, mais ils l'abordent différemment. Les TPU sont étroitement intégrées à l'infrastructure cloud, notamment par le biais de Google Cloud Platform (GCP), offrant des ressources évolutives pour les charges de travail d'IA. Les utilisateurs peuvent accéder aux TPU à la demande, en les augmentant ou en les réduisant en fonction des besoins de calcul, ce qui est essentiel pour traiter efficacement les projets d'IA à grande échelle. Google propose des services gérés et des environnements préconfigurés pour déployer des modèles d'IA sur des TPU, ce qui simplifie le processus d'intégration dans l'infrastructure cloud.
D'autre part, les GPU s'adaptent aussi efficacement aux grands projets d'IA, avec des options de déploiement sur site ou d'utilisation dans des environnements cloud proposés par des fournisseurs comme Amazon Web Services (AWS) et Microsoft Azure. Les GPU offrent une grande souplesse d'évolution, permettant aux utilisateurs de déployer plusieurs GPU en parallèle pour augmenter la puissance de calcul.
En outre, les GPU excellent dans le traitement de grands ensembles de données grâce à leur grande largeur de bande de mémoire et à leurs capacités de traitement parallèle. Cela permet un traitement efficace des données et la formation de modèles, ce qui est essentiel pour les projets d'IA à grande échelle qui traitent de vastes ensembles de données.
Dans l'ensemble, les TPU et les GPU offrent tous deux une évolutivité pour les grands projets d'IA, les TPU étant étroitement intégrées à l'infrastructure cloud et les GPU offrant une certaine flexibilité pour un déploiement sur site ou dans le cloud. Leur capacité à traiter de grands ensembles de données et à mettre à l'échelle les ressources informatiques les rend inestimables pour s'attaquer à des tâches d'IA complexes à grande échelle.
| Fonctionnalité | GPU | TPU |
|---|---|---|
| Architecture informatique | Des milliers de petits cœurs efficaces pour le traitement parallèle | Priorité aux opérations tensorielles, architecture spécialisée |
| Performance | Polyvalent, vous excellez dans diverses tâches liées à l'IA, y compris l'apprentissage profond et l'inférence. | Optimisés pour les opérations tensorielles, ils sont souvent plus performants que les GPU dans des tâches spécifiques d'apprentissage profond. |
| Vitesse et efficacité | Par exemple, 128 séquences avec le modèle BERT : 3,8 ms sur le GPU V100 | Par exemple, 128 séquences avec le modèle BERT : 1,7 ms sur TPU v3 |
| Points de repère | ResNet-50 sur CIFAR-10 : 40 minutes pour 10 époques (4 minutes/époque) sur le GPU Tesla V100 | ResNet-50 sur CIFAR-10 : 15 minutes pour 10 époques (1,5 minute/époque) sur Google Cloud TPU v3 |
| Coût | NVIDIA Tesla V100 : 8 000 - 10 000 $/unité, 2,48 $/heure ; NVIDIA A100 : 10 000 - 15 000 $/unité, 2,93 $/heure. | Google Cloud TPU v3 : 4,50 $/heure ; TPU v4 : 8,00 $/heure |
| Disponibilité | Largement disponible auprès de plusieurs fournisseurs (NVIDIA, AMD, Intel), pour les particuliers et les entreprises. | Principalement accessible par l'intermédiaire de Google Cloud Platform (GCP). |
| Écosystème et outils de développement | Supporté par de nombreux frameworks (TensorFlow, PyTorch, Keras, MXNet, Caffe), des bibliothèques étendues (CUDA, cuDNN, RAPIDS). | Intégré à TensorFlow, supporte JAX, optimisé par le compilateur TensorFlow XLA |
| Soutien et ressources communautaires | Vaste écosystème avec des forums, des tutoriels et de la documentation de NVIDIA, AMD et des communautés. | Centralisé autour de l'écosystème de Google avec la documentation GCP, les forums et les canaux d'assistance. |
| Efficacité énergétique | NVIDIA Tesla V100 : 250 watts ; NVIDIA A100 : 400 watts | Google Cloud TPU v3 : 120-150 watts ; TPU v4 : 200-250 watts |
| Optimisation des tâches d'IA | Optimisation de l'efficacité énergétique (power gating, DVFS, traitement parallèle, fusion de noyaux) | Hiérarchies de mémoire, quantification et densité personnalisées pour un calcul efficace de l'IA |
| Évolutivité des applications d'entreprise | Évolutif pour les grands projets d'IA, sur site ou dans le cloud (AWS, Azure), bande passante mémoire élevée, traitement parallèle. | Intégration étroite à l'infrastructure cloud (GCP), évolutivité à la demande, services gérés pour le déploiement de modèles d'IA. |
Choisissez les GPU lorsque :
Choisissez les TPU lorsque :
Les GPU et TPU sont des accélérateurs matériels spécialisés utilisés dans les applications d'intelligence artificielle. Développés à l'origine pour le rendu graphique, les GPU excellent dans le traitement parallèle et ont été adaptés aux tâches d'intelligence artificielle, offrant ainsi une grande polyvalence dans divers secteurs d'activité. Les TPU, en revanche, sont conçues par Google spécifiquement pour les charges de travail liées à l'intelligence artificielle, en donnant la priorité aux opérations de tenseur que l'on trouve couramment dans les réseaux neuronaux.
Cet article compare les technologies GPU et TPU en fonction de leurs performances, de leur coût et de leur disponibilité, de leur écosystème et de leur développement, de leur efficacité énergétique et de leur impact sur l'environnement, ainsi que de leur évolutivité dans les applications d'intelligence artificielle. Pour poursuivre votre apprentissage sur les TPU et les GPU, consultez certaines de ces ressources :
Maîtrisez l'IA avec DataCamp
Cursus
Cours
Cours
blog
blog
Lynn Heidmann
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Sejal Jaiswal

