
Programma
Nozioni di base sull'intelligenza artificiale
10 h
L’ondata di sviluppo dell’Intelligenza Artificiale (AI) ha creato un notevole aumento della domanda di calcolo, rendendo necessarie soluzioni hardware robuste. Le Graphics Processing Units (GPU) e le Tensor Processing Units (TPU) sono emerse come tecnologie fondamentali per rispondere a queste esigenze.
Originariamente progettate per il rendering grafico, le GPU si sono evolute in processori versatili in grado di gestire con efficienza i compiti di AI grazie alle loro capacità di elaborazione in parallelo. Al contrario, le TPU, sviluppate da Google, sono ottimizzate specificamente per i calcoli di AI, offrendo prestazioni superiori su misura per attività come i progetti di machine learning.
In questo articolo parleremo di GPU vs TPU e confronteremo le due tecnologie in base a metriche come prestazioni, costo, ecosistema e altro ancora. Ti forniremo anche una panoramica della loro efficienza energetica, dell’impatto ambientale e della scalabilità nelle applicazioni enterprise.
Le GPU sono processori specializzati sviluppati inizialmente per il rendering di immagini e grafica in computer e console di gioco. Funzionano scomponendo problemi complessi in più attività e lavorando su di esse simultaneamente, invece che una alla volta come avviene nelle CPU.
Grazie alla loro potenza di elaborazione parallela, le loro capacità sono evolute ben oltre l’elaborazione grafica, diventando componenti essenziali in varie applicazioni di calcolo, come lo sviluppo di modelli di AI.
Ma facciamo un piccolo passo indietro.
Le GPU sono comparse negli anni ’80 come hardware specializzato per accelerare il rendering grafico. Aziende come NVIDIA e ATI (ora parte di AMD) hanno avuto un ruolo fondamentale nel loro sviluppo. Tuttavia, non hanno guadagnato popolarità di massa fino alla fine degli anni ’90 e ai primi anni 2000. La loro adozione è stata trainata dall’introduzione degli shader programmabili, che hanno permesso agli sviluppatori di sfruttare l’elaborazione parallela per compiti oltre la grafica.
Negli anni 2000, sempre più ricerche hanno esplorato le GPU per compiti di calcolo generico oltre la grafica. CUDA (Compute Unified Device Architecture) di NVIDIA e lo Stream SDK di AMD hanno permesso agli sviluppatori di sfruttare la potenza di calcolo delle GPU per simulazioni scientifiche, analisi dei dati e altro.
Poi è arrivata l’ascesa dell’AI e del deep learning.
Le GPU sono emerse come strumenti indispensabili per addestrare e distribuire modelli di deep learning grazie alla loro capacità di gestire enormi quantità di dati ed eseguire calcoli in parallelo.
Framework come TensorFlow e PyTorch utilizzano l’accelerazione GPU, rendendo il deep learning accessibile a ricercatori e sviluppatori in tutto il mondo.
Le Tensor Processing Units (TPU) sono un tipo di circuito integrato specifico per applicazioni (ASIC) introdotto da Google per rispondere alla crescente domanda di calcolo del machine learning.
A differenza delle GPU, inizialmente create per i compiti di elaborazione grafica e successivamente adattate alle esigenze dell’AI, le TPU sono state progettate specificamente per accelerare i carichi di lavoro di machine learning.
Poiché sono state pensate per il machine learning, le TPU sono ingegnerizzate specificamente per le operazioni sui tensori, fondamentali per gli algoritmi di deep learning.
Grazie alla loro architettura personalizzata ottimizzata per la moltiplicazione di matrici, un’operazione chiave nelle reti neurali, eccellono nell’elaborazione di grandi volumi di dati e nell’esecuzione efficiente di reti neurali complesse, consentendo tempi rapidi di training e inferenza.
Questa ottimizzazione specializzata rende le TPU indispensabili per le applicazioni di AI, favorendo i progressi nella ricerca e nella distribuzione del machine learning.
TPU e GPU offrono vantaggi distinti e sono ottimizzate per diversi compiti computazionali. Sebbene entrambe possano accelerare i carichi di lavoro di machine learning, le loro architetture e ottimizzazioni portano a variazioni di prestazioni a seconda del compito specifico.
Per cominciare, sia le GPU sia le TPU sono acceleratori hardware specializzati progettati per migliorare le prestazioni nei compiti di AI, ma differiscono nelle architetture computazionali, differenze che incidono notevolmente sulla loro efficienza ed efficacia nella gestione di specifici tipi di calcolo.
Le GPU sono composte da migliaia di core piccoli ed efficienti progettati per l’elaborazione parallela.
Questa architettura consente di eseguire più attività contemporaneamente, rendendole molto efficaci per compiti parallelizzabili, come il rendering grafico e il deep learning.
Le GPU sono particolarmente abili nelle operazioni su matrici, molto diffuse nei calcoli delle reti neurali. La capacità di gestire grandi volumi di dati ed eseguire calcoli in parallelo le rende adatte ai compiti di AI che prevedono l’elaborazione di dataset massicci e l’esecuzione di operazioni matematiche complesse.
Al contrario, le TPU danno priorità alle operazioni sui tensori, consentendo di eseguire i calcoli in modo efficiente. Pur non avendo tante core quanto le GPU, la loro architettura specializzata permette di superare le GPU in alcuni tipi di compiti di AI, soprattutto quelli che si basano fortemente sulle operazioni sui tensori.
Detto questo, le GPU eccellono nei compiti che beneficiano dell’elaborazione parallela e sono adatte a vari calcoli oltre l’AI, come il rendering grafico e le simulazioni scientifiche.
Le TPU, invece, sono ottimizzate per l’elaborazione dei tensori, risultando altamente efficienti per i compiti di deep learning che coinvolgono operazioni su matrici. A seconda dei requisiti specifici del carico di lavoro di AI, potrebbero offrire prestazioni ed efficienza migliori le GPU o le TPU.
Le GPU sono note per la loro versatilità nel gestire vari compiti di AI, tra cui l’addestramento di modelli di deep learning e le operazioni di inferenza. Questo perché l’architettura delle GPU, che si basa sull’elaborazione parallela, incrementa sensibilmente la velocità di training e inferenza in numerosi modelli di AI. Per esempio, elaborare un batch di 128 sequenze con un modello BERT richiede 3,8 millisecondi su una GPU V100 rispetto a 1,7 millisecondi su una TPU v3.
Le TPU, invece, sono finemente ottimizzate per operazioni rapide ed efficienti sui tensori, componenti cruciali delle reti neurali. Questa specializzazione consente spesso alle TPU di superare le GPU in specifici compiti di deep learning, in particolare quelli ottimizzati da Google, come l’addestramento di grandi reti neurali e modelli di machine learning complessi.
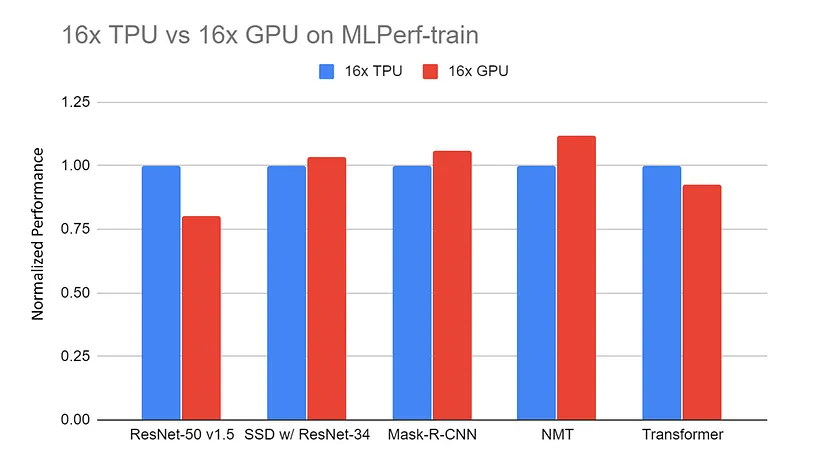
Prestazioni normalizzate di server con 16x GPU (DGX-2H) vs server con 16x TPU v3 sui benchmark MLPerf-train. I dati sono raccolti dal sito MLPerf. Tutti i risultati TPU usano TensorFlow. Tutti i risultati GPU usano Pytorch, tranne ResNet che usa MxNet |
Fonte: TPU vs. GPU vs Cerebras vs. Graphcore: A Fair Comparison between ML Hardware di Mahmoud Khairy
I confronti tra TPU e GPU su compiti simili mostrano spesso che le TPU superano le GPU in attività specificamente tarate sulla loro architettura, offrendo tempi di training più rapidi ed elaborazione più efficace.
Ad esempio, addestrare un modello ResNet-50 sul dataset CIFAR-10 per 10 epoche utilizzando una GPU NVIDIA Tesla V100 richiede circa 40 minuti, in media 4 minuti per epoca. Invece, usando una Google Cloud TPU v3, lo stesso training richiede solo 15 minuti, in media 1,5 minuti per epoca.
Ciononostante, le GPU mantengono prestazioni competitive in un più ampio spettro di applicazioni grazie alla loro adattabilità e ai considerevoli sforzi di ottimizzazione intrapresi dalla community.
La scelta tra GPU e TPU dipende da budget, esigenze di calcolo e disponibilità. Ogni opzione offre vantaggi unici per diverse applicazioni. In questa sezione vedremo come GPU e TPU si confrontano in termini di costo e accessibilità di mercato.
Le GPU offrono molta più flessibilità rispetto alle TPU quando si parla di costi. Per cominciare, le TPU non vengono vendute singolarmente; sono disponibili solo come servizio cloud tramite provider come Google Cloud Platform (GCP). Al contrario, le GPU possono essere acquistate individualmente.
Il costo approssimativo di una GPU NVIDIA Tesla V100 è compreso tra 8.000 e 10.000 $ per unità, mentre una GPU NVIDIA A100 tra 10.000 e 15.000 $. Ma c’è anche l’opzione dei prezzi on-demand in cloud.
Usare una GPU NVIDIA Tesla V100 per addestrare un modello di deep learning potrebbe costarti circa 2,48 $ all’ora, e la NVIDIA A100 circa 2,93 $. Dall’altra parte, la Google Cloud TPU V3 costerebbe circa 4,50 $ all’ora, e la Google Cloud TPU V4 circa 8,00 $ all’ora.
In altre parole, le TPU sono molto meno flessibili delle GPU e in genere hanno costi orari più alti per il cloud on-demand rispetto alle GPU. Tuttavia, le TPU spesso offrono prestazioni più rapide, il che può ridurre il tempo di calcolo totale necessario per compiti di machine learning su larga scala, portando potenzialmente a un risparmio complessivo nonostante le tariffe orarie più elevate.
La disponibilità di TPU e GPU sul mercato varia notevolmente, influenzandone l’adozione in diversi settori e regioni…
Le TPU, sviluppate da Google, sono principalmente accessibili tramite Google Cloud Platform (GCP) per compiti di AI basati sul cloud. Ciò significa che sono usate soprattutto da chi si affida a GCP per le proprie esigenze di calcolo, il che può renderle più popolari in aree e settori fortemente orientati al cloud, come i poli tecnologici o i luoghi con connessioni internet solide.
Le GPU, invece, sono prodotte da aziende come NVIDIA, AMD e Intel, e sono disponibili in varie opzioni sia per i consumatori sia per le imprese. Questa maggiore disponibilità rende le GPU una scelta popolare in numerosi settori, tra cui gaming, scienza, finanza, sanità e manifattura. Le GPU possono essere installate on-premise o nel cloud, offrendo agli utenti flessibilità nella configurazione del proprio ambiente di calcolo.
Di conseguenza, le GPU hanno maggiori probabilità di essere utilizzate in diversi settori e regioni, indipendentemente dall’infrastruttura tecnologica o dalle esigenze di calcolo. In generale, la disponibilità di mercato di TPU e GPU ne influenza le modalità di adozione: le TPU sono più comuni in aree e settori orientati al cloud (ad es. il machine learning), mentre le GPU sono ampiamente utilizzate in diversi ambiti e località.
Le TPU di Google sono strettamente integrate con TensorFlow, il suo principale framework open-source per il machine learning. Anche JAX, un’altra libreria per il calcolo numerico ad alte prestazioni, supporta le TPU, abilitando un machine learning e un calcolo scientifico efficienti.
Le TPU sono integrate senza soluzione di continuità nell’ecosistema TensorFlow, rendendo semplice per gli utenti TensorFlow sfruttare le capacità delle TPU. Ad esempio, TensorFlow offre strumenti come il compilatore TensorFlow XLA (Accelerated Linear Algebra), che ottimizza i calcoli per le TPU.
In sostanza, le TPU sono progettate per accelerare le operazioni di TensorFlow, fornendo prestazioni ottimizzate per training e inferenza. Supportano anche le API di alto livello di TensorFlow, facilitando la migrazione e l’ottimizzazione dei modelli per l’esecuzione su TPU.
Al contrario, le GPU sono ampiamente adottate in vari settori e ambiti di ricerca, diventando popolari per applicazioni di machine learning diversificate. Ciò significa che hanno più integrazioni rispetto alle GPU e sono supportate da un’ampia gamma di framework di deep learning, tra cui TensorFlow, PyTorch, Keras, MXNet e Caffe.
Le GPU beneficiano inoltre di librerie e strumenti estesi come CUDA, cuDNN e RAPIDS, che ne aumentano ulteriormente la versatilità e la facilità di integrazione in vari workflow di machine learning e data science.
Per quanto riguarda il supporto della community, le GPU dispongono di un ecosistema più ampio con forum, tutorial e documentazione estesi disponibili da diverse fonti come NVIDIA, AMD e piattaforme guidate dalla community. Gli sviluppatori possono accedere a community online vivaci, forum e gruppi di utenti per chiedere aiuto, condividere conoscenze e collaborare a progetti. Inoltre, sono disponibili numerosi tutorial, corsi e risorse di documentazione che coprono la programmazione GPU, i framework di deep learning e le tecniche di ottimizzazione.
Il supporto della community per le TPU è più centralizzato nell’ecosistema di Google, con risorse disponibili principalmente tramite la documentazione GCP, forum e canali di supporto. Sebbene Google fornisca documentazione e tutorial completi, specificamente pensati per usare le TPU con TensorFlow, il supporto della community può essere più limitato rispetto al più ampio ecosistema GPU. Tuttavia, i canali di supporto ufficiali di Google e le risorse per sviluppatori offrono comunque un valido aiuto a chi utilizza le TPU per carichi di lavoro di AI.
L’efficienza energetica di GPU e TPU varia in base alle loro architetture e applicazioni previste. In generale, le TPU sono più efficienti dal punto di vista energetico rispetto alle GPU, in particolare la Google Cloud TPU v3, che è significativamente più efficiente delle GPU NVIDIA di fascia alta.
Per maggiore contesto:
Il minor consumo delle TPU può contribuire a costi operativi molto più bassi e a una maggiore efficienza energetica, soprattutto in distribuzioni di machine learning su larga scala.
TPU e GPU impiegano ottimizzazioni specifiche per aumentare l’efficienza energetica durante operazioni di AI su larga scala.
Come accennato in precedenza, l’architettura delle TPU è progettata per dare priorità alle operazioni sui tensori comunemente utilizzate nelle reti neurali, consentendo l’esecuzione efficiente dei compiti di AI con un consumo energetico minimo. Le TPU presentano anche gerarchie di memoria personalizzate ottimizzate per i calcoli di AI, riducendo la latenza di accesso alla memoria e l’overhead energetico.
Sfruttano tecniche come quantizzazione e sparsità per ottimizzare le operazioni aritmetiche, minimizzando i consumi senza sacrificare l’accuratezza. Questi fattori consentono alle TPU di offrire alte prestazioni risparmiando energia.
Allo stesso modo, le GPU implementano ottimizzazioni orientate al risparmio energetico per migliorare le prestazioni nelle operazioni di AI. Le architetture GPU moderne incorporano funzionalità come power gating e scaling dinamico di tensione e frequenza (DVFS) per regolare i consumi in base ai carichi di lavoro. Utilizzano anche tecniche di elaborazione parallela per distribuire i compiti computazionali su più core, massimizzando la throughput e minimizzando l’energia per operazione.
I produttori di GPU sviluppano architetture di memoria e gerarchie di cache efficienti dal punto di vista energetico per ottimizzare i pattern di accesso alla memoria e ridurre i consumi durante i trasferimenti di dati. Queste ottimizzazioni, unite a tecniche software come la fusione dei kernel e l’unrolling dei loop, migliorano ulteriormente l’efficienza energetica dei carichi di lavoro di AI accelerati da GPU.
Sia le TPU sia le GPU offrono scalabilità per grandi progetti di AI, ma la affrontano in modo diverso. Le TPU sono strettamente integrate nell’infrastruttura cloud, in particolare tramite Google Cloud Platform (GCP), offrendo risorse scalabili per i carichi di lavoro di AI. Gli utenti possono accedere alle TPU on-demand, aumentando o riducendo le risorse in base alle esigenze computazionali, fondamentale per gestire in modo efficiente progetti di AI su larga scala. Google fornisce servizi gestiti e ambienti preconfigurati per distribuire modelli di AI su TPU, semplificando l’integrazione nell’infrastruttura cloud.
Le GPU, dal canto loro, scalano efficacemente per grandi progetti di AI, con opzioni per la distribuzione on-premise o l’utilizzo in ambienti cloud offerti da provider come Amazon Web Services (AWS) e Microsoft Azure. Le GPU offrono flessibilità nello scaling, consentendo di distribuire più GPU in parallelo per aumentare la potenza computazionale.
Inoltre, le GPU eccellono nella gestione di grandi dataset grazie all’elevata ampiezza di banda della memoria e alle capacità di elaborazione parallela. Questo consente un’elaborazione efficiente dei dati e l’addestramento dei modelli, essenziale per progetti di AI su larga scala che trattano dataset molto ampi.
In sintesi, sia le TPU sia le GPU offrono scalabilità per grandi progetti di AI, con le TPU strettamente integrate nell’infrastruttura cloud e le GPU che forniscono flessibilità per distribuzioni on-premise o in cloud. La loro capacità di gestire grandi dataset e scalare le risorse computazionali le rende preziose per affrontare compiti di AI complessi su larga scala.
| Caratteristica | GPU | TPU |
|---|---|---|
| Architettura computazionale | Migliaia di core piccoli ed efficienti per l’elaborazione parallela | Priorità alle operazioni sui tensori, architettura specializzata |
| Prestazioni | Versatili, eccellono in vari compiti di AI, incluso deep learning e inferenza | Ottimizzate per operazioni sui tensori, spesso superano le GPU in specifici compiti di deep learning |
| Velocità ed efficienza | Es.: 128 sequenze con modello BERT: 3,8 ms su GPU V100 | Es.: 128 sequenze con modello BERT: 1,7 ms su TPU v3 |
| Benchmark | ResNet-50 su CIFAR-10: 40 minuti per 10 epoche (4 minuti/epoca) su Tesla V100 | ResNet-50 su CIFAR-10: 15 minuti per 10 epoche (1,5 minuti/epoca) su Google Cloud TPU v3 |
| Costo | NVIDIA Tesla V100: 8.000 - 10.000 $/unità, 2,48 $/ora; NVIDIA A100: 10.000 - 15.000 $/unità, 2,93 $/ora | Google Cloud TPU v3: 4,50 $/ora; TPU v4: 8,00 $/ora |
| Disponibilità | Ampiamente disponibili da più vendor (NVIDIA, AMD, Intel), per consumer e aziende | Principalmente accessibili tramite Google Cloud Platform (GCP) |
| Ecosistema e strumenti di sviluppo | Supportate da molti framework (TensorFlow, PyTorch, Keras, MXNet, Caffe), librerie estese (CUDA, cuDNN, RAPIDS) | Integrate con TensorFlow, supportano JAX, ottimizzate dal compilatore TensorFlow XLA |
| Supporto della community e risorse | Ecosistema ampio con forum, tutorial e documentazione estesi da NVIDIA, AMD e community | Centralizzato nell’ecosistema Google con documentazione, forum e canali di supporto GCP |
| Efficienza energetica | NVIDIA Tesla V100: 250 watt; NVIDIA A100: 400 watt | Google Cloud TPU v3: 120-150 watt; TPU v4: 200-250 watt |
| Ottimizzazione per i compiti di AI | Ottimizzazioni per l’efficienza energetica (power gating, DVFS, elaborazione parallela, fusione dei kernel) | Gerarchie di memoria personalizzate, quantizzazione e sparsità per un calcolo di AI efficiente |
| Scalabilità nelle applicazioni enterprise | Scalabili per grandi progetti di AI, on-premise o cloud (AWS, Azure), ampiezza di banda memoria elevata, elaborazione parallela | Strettamente integrate nell’infrastruttura cloud (GCP), scalabilità on-demand, servizi gestiti per distribuire modelli di AI |
Scegli le GPU quando:
Scegli le TPU quando:
GPU e TPU sono acceleratori hardware specializzati utilizzati nelle applicazioni di AI. Originariamente sviluppate per il rendering grafico, le GPU eccellono nell’elaborazione parallela e sono state adattate ai compiti di AI, offrendo versatilità in vari settori. Le TPU, invece, sono realizzate su misura da Google specificamente per i carichi di lavoro di AI, dando priorità alle operazioni sui tensori comuni nelle reti neurali.
Questo articolo ha confrontato le tecnologie GPU e TPU in base a prestazioni, costo e disponibilità, ecosistema e sviluppo, efficienza energetica e impatto ambientale, e scalabilità nelle applicazioni di AI. Per approfondire il tuo apprendimento su TPU e GPU, dai un’occhiata a queste risorse per continuare a imparare:
Impara competenze di AI con DataCamp
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

