
Tracks
Cơ bản về Trí tuệ Nhân tạo
10 giờ
Sự bùng nổ phát triển Trí tuệ nhân tạo (AI) đã tạo ra nhu cầu tính toán tăng đáng kể, thúc đẩy sự cần thiết của các giải pháp phần cứng mạnh mẽ. Bộ xử lý đồ họa (GPU) và Bộ xử lý tensor (TPU) đã nổi lên như những công nghệ then chốt để đáp ứng các nhu cầu này.
Ban đầu được thiết kế để kết xuất đồ họa, GPU đã phát triển thành các bộ xử lý đa năng có khả năng xử lý hiệu quả các tác vụ AI nhờ năng lực xử lý song song. Ngược lại, TPU, do Google phát triển, được tối ưu hóa đặc thù cho tính toán AI, mang lại hiệu năng vượt trội hướng đến các tác vụ như dự án máy học.
Trong bài viết này, chúng tôi sẽ bàn về GPU so với TPU và so sánh hai công nghệ dựa trên các thước đo như hiệu năng, chi phí, hệ sinh thái, v.v. Chúng tôi cũng sẽ điểm qua hiệu quả năng lượng, tác động môi trường và khả năng mở rộng của chúng trong các ứng dụng doanh nghiệp.
GPU là các bộ xử lý chuyên dụng được phát triển ban đầu để kết xuất hình ảnh và đồ họa trên máy tính và máy chơi game. Chúng hoạt động bằng cách chia nhỏ các bài toán phức tạp thành nhiều tác vụ và xử lý đồng thời thay vì tuần tự như trên CPU.
Nhờ sức mạnh xử lý song song, khả năng của chúng đã vượt xa xử lý đồ họa, trở thành thành phần không thể thiếu trong nhiều ứng dụng tính toán, như phát triển mô hình AI.
Nhưng hãy tua ngược lại một chút.
GPU xuất hiện từ những năm 1980 như phần cứng chuyên dụng để tăng tốc kết xuất đồ họa. Các công ty như NVIDIA và ATI (nay thuộc AMD) đóng vai trò then chốt trong quá trình phát triển. Tuy nhiên, chúng chưa phổ biến rộng rãi cho đến cuối thập niên 1990 và đầu 2000. Việc được đón nhận là nhờ sự ra đời của programmable shaders, cho phép nhà phát triển tận dụng xử lý song song cho các tác vụ ngoài đồ họa.
Trong những năm 2000, nhiều nghiên cứu khám phá GPU cho các tác vụ tính toán mục đích chung ngoài đồ họa. CUDA (Compute Unified Device Architecture) của NVIDIA và Stream SDK của AMD cho phép nhà phát triển khai thác sức mạnh xử lý của GPU cho mô phỏng khoa học, phân tích dữ liệu và hơn thế nữa.
Rồi làn sóng AI và học sâu trỗi dậy.
GPU trở thành công cụ không thể thiếu để huấn luyện và triển khai các mô hình học sâu nhờ khả năng xử lý lượng dữ liệu khổng lồ và thực hiện tính toán song song.
Các framework như TensorFlow và PyTorch tận dụng tăng tốc GPU, giúp học sâu trở nên dễ tiếp cận với giới nghiên cứu và nhà phát triển trên toàn thế giới.
Tensor Processing Unit (TPU) là một loại mạch tích hợp chuyên dụng (ASIC) do Google tiên phong phát triển để đáp ứng nhu cầu tính toán ngày càng tăng của máy học.
Trái với GPU, vốn được tạo ra cho tác vụ xử lý đồ họa và sau đó điều chỉnh để đáp ứng nhu cầu AI, TPU được thiết kế riêng để tăng tốc khối lượng công việc máy học.
Vì được thiết kế cho máy học, TPU được xây dựng chuyên biệt cho các phép toán tensor, vốn là nền tảng của các thuật toán học sâu.
Nhờ kiến trúc tùy biến tối ưu cho phép nhân ma trận, một phép toán then chốt trong mạng nơ-ron, chúng vượt trội trong xử lý khối lượng dữ liệu lớn và thực thi hiệu quả các mạng nơ-ron phức tạp, cho phép thời gian huấn luyện và suy luận nhanh.
Sự tối ưu hóa chuyên biệt này khiến TPU trở nên không thể thiếu cho các ứng dụng AI, thúc đẩy tiến bộ trong nghiên cứu và triển khai máy học.
TPU và GPU mang lại những lợi thế khác nhau và được tối ưu cho các tác vụ tính toán khác nhau. Dù cả hai đều có thể tăng tốc khối lượng công việc máy học, kiến trúc và tối ưu hóa của chúng dẫn đến khác biệt về hiệu năng tùy theo tác vụ cụ thể.
Trước hết, cả GPU và TPU đều là các bộ tăng tốc phần cứng chuyên dụng nhằm nâng cao hiệu năng trong các tác vụ AI, nhưng chúng khác nhau ở kiến trúc tính toán, điều này ảnh hưởng đáng kể đến hiệu quả và hiệu lực khi xử lý các loại phép tính cụ thể.
GPU bao gồm hàng nghìn lõi nhỏ, hiệu quả, được thiết kế cho xử lý song song.
Kiến trúc này cho phép chúng thực thi nhiều tác vụ đồng thời, khiến chúng rất hiệu quả cho các tác vụ có thể song song hóa, như kết xuất đồ họa và học sâu.
GPU đặc biệt thành thạo ở các phép toán ma trận, vốn phổ biến trong tính toán mạng nơ-ron. Khả năng xử lý khối lượng dữ liệu lớn và thực thi tính toán song song khiến chúng phù hợp với các tác vụ AI liên quan đến xử lý tập dữ liệu khổng lồ và thực hiện các phép toán học phức tạp.
Ngược lại, TPU ưu tiên các phép toán tensor, cho phép thực hiện tính toán hiệu quả. Dù TPU có thể không có nhiều lõi như GPU, kiến trúc chuyên biệt của chúng giúp vượt trội hơn GPU ở một số loại tác vụ AI, đặc biệt là những tác vụ phụ thuộc nhiều vào phép toán tensor.
Nói vậy để thấy, GPU xuất sắc ở những tác vụ hưởng lợi từ xử lý song song và phù hợp với nhiều phép tính vượt ngoài AI, như kết xuất đồ họa và mô phỏng khoa học.
Trong khi đó, TPU được tối ưu cho xử lý tensor, giúp chúng rất hiệu quả cho các tác vụ học sâu liên quan đến phép toán ma trận. Tùy yêu cầu cụ thể của khối lượng công việc AI, GPU hoặc TPU có thể mang lại hiệu năng và hiệu quả tốt hơn.
GPU nổi tiếng về tính đa dụng trong xử lý nhiều tác vụ AI, bao gồm huấn luyện mô hình học sâu và thực hiện suy luận. Điều này là do kiến trúc GPU dựa trên xử lý song song, giúp tăng đáng kể tốc độ huấn luyện và suy luận trên nhiều mô hình AI. Ví dụ, xử lý một lô 128 chuỗi với mô hình BERT mất 3,8 mili giây trên GPU V100 so với 1,7 mili giây trên TPU v3.
Ngược lại, TPU được tinh chỉnh kỹ lưỡng cho các phép toán tensor nhanh và hiệu quả, là thành phần then chốt của mạng nơ-ron. Sự chuyên môn hóa này thường cho phép TPU vượt trội GPU trong các tác vụ học sâu cụ thể, đặc biệt là những tác vụ được Google tối ưu, như huấn luyện mạng nơ-ron quy mô lớn và các mô hình máy học phức tạp.
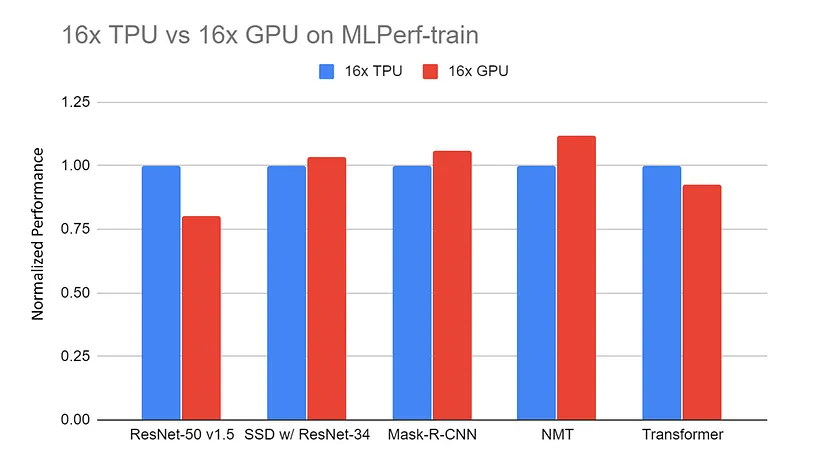
Hiệu năng chuẩn hóa: máy chủ 16x GPU (DGX-2H) so với máy chủ 16x TPU v3 trên các điểm chuẩn MLPerf-train. Dữ liệu được thu thập từ trang web MLPerf. Tất cả kết quả TPU dùng TensorFlow. Tất cả kết quả GPU dùng Pytorch, trừ ResNet dùng MxNet |
Nguồn: TPU vs. GPU vs Cerebras vs. Graphcore: So sánh công bằng giữa các phần cứng ML của Mahmoud Khairy
Các so sánh giữa TPU và GPU trên các tác vụ tương tự thường cho thấy TPU vượt trội GPU trong những tác vụ được điều chỉnh phù hợp với kiến trúc của chúng, mang lại thời gian huấn luyện nhanh hơn và xử lý hiệu quả hơn.
Ví dụ, huấn luyện mô hình ResNet-50 trên bộ dữ liệu CIFAR-10 trong 10 epoch bằng GPU NVIDIA Tesla V100 mất khoảng 40 phút, trung bình 4 phút mỗi epoch. Ngược lại, dùng Google Cloud TPU v3, cùng bài huấn luyện chỉ mất 15 phút, trung bình 1,5 phút mỗi epoch.
Dẫu vậy, GPU vẫn giữ hiệu năng cạnh tranh trên phổ ứng dụng rộng hơn nhờ tính thích ứng và nỗ lực tối ưu hóa đáng kể từ cộng đồng.
Việc chọn GPU hay TPU phụ thuộc vào ngân sách, nhu cầu tính toán và mức độ sẵn có. Mỗi lựa chọn mang lại lợi thế riêng cho các ứng dụng khác nhau. Phần này sẽ xem GPU và TPU so sánh thế nào về chi phí và khả năng tiếp cận thị trường.
GPU linh hoạt hơn nhiều so với TPU khi nói về chi phí. Trước hết, TPU không bán lẻ; chúng chỉ có dưới dạng dịch vụ đám mây thông qua các nhà cung cấp như Google Cloud Platform (GCP). Ngược lại, GPU có thể mua lẻ.
Chi phí xấp xỉ của một GPU NVIDIA Tesla V100 là từ 8.000 đến 10.000 USD mỗi chiếc, và một GPU NVIDIA A100 là từ 10.000 đến 15.000 USD. Nhưng bạn cũng có lựa chọn giá theo giờ trên đám mây.
Dùng GPU NVIDIA Tesla V100 để huấn luyện mô hình học sâu có thể tốn khoảng 2,48 USD mỗi giờ, và NVIDIA A100 khoảng 2,93 USD. Mặt khác, Google Cloud TPU V3 khoảng 4,50 USD mỗi giờ, và Google Cloud TPU V4 khoảng 8,00 USD mỗi giờ.
Nói cách khác, TPU kém linh hoạt hơn GPU và thường có chi phí theo giờ cao hơn cho tính toán đám mây theo nhu cầu so với GPU. Tuy nhiên, TPU thường mang lại hiệu năng nhanh hơn, có thể rút ngắn tổng thời gian tính toán cần thiết cho các tác vụ máy học quy mô lớn, tiềm ẩn khả năng tiết kiệm chi phí tổng thể dù giá theo giờ cao hơn.
Mức độ sẵn có của TPU và GPU trên thị trường khác nhau rất nhiều, ảnh hưởng đến việc được chấp nhận ở các ngành và khu vực khác nhau…
TPU, do Google phát triển, chủ yếu truy cập được qua Google Cloud Platform (GCP) cho các tác vụ AI dựa trên đám mây. Điều này có nghĩa chúng chủ yếu được dùng bởi những người dựa vào GCP cho nhu cầu tính toán, có thể khiến chúng phổ biến hơn ở các khu vực và ngành tập trung vào điện toán đám mây, như các trung tâm công nghệ hoặc nơi có hạ tầng internet mạnh.
Trong khi đó, GPU do các công ty như NVIDIA, AMD và Intel sản xuất, và có sẵn nhiều lựa chọn cho cả người tiêu dùng và doanh nghiệp. Sự sẵn có rộng rãi này khiến GPU là lựa chọn phổ biến trên nhiều ngành, bao gồm game, khoa học, tài chính, y tế và sản xuất. GPU có thể được triển khai tại chỗ hoặc trên đám mây, mang lại cho người dùng sự linh hoạt trong cách thiết lập tính toán.
Do đó, GPU có khả năng được sử dụng rộng rãi hơn trên các ngành và khu vực, bất kể hạ tầng công nghệ hay nhu cầu tính toán. Nhìn chung, khả năng tiếp cận thị trường của TPU và GPU ảnh hưởng đến cách chúng được ứng dụng. TPU phổ biến hơn ở các khu vực và lĩnh vực tập trung vào đám mây (ví dụ: Máy học), trong khi GPU được dùng rộng rãi trên nhiều lĩnh vực và địa điểm.
TPU của Google tích hợp chặt chẽ với TensorFlow, framework máy học mã nguồn mở hàng đầu của hãng. JAX, một thư viện khác cho tính toán số hiệu năng cao, cũng hỗ trợ TPU, cho phép máy học và tính toán khoa học hiệu quả.
TPU được tích hợp liền mạch vào hệ sinh thái TensorFlow, giúp người dùng TensorFlow dễ dàng khai thác năng lực TPU. Ví dụ, TensorFlow cung cấp các công cụ như trình biên dịch TensorFlow XLA (Accelerated Linear Algebra), tối ưu hóa tính toán cho TPU.
Tựu chung, TPU được thiết kế để tăng tốc các phép toán của TensorFlow, mang lại hiệu năng tối ưu cho huấn luyện và suy luận. Chúng cũng hỗ trợ các API cấp cao của TensorFlow, giúp việc chuyển đổi và tối ưu mô hình để chạy trên TPU thuận tiện hơn.
Ngược lại, GPU được áp dụng rộng rãi trên nhiều ngành và lĩnh vực nghiên cứu, khiến chúng phổ biến cho các ứng dụng máy học đa dạng. Điều này có nghĩa chúng có nhiều tích hợp hơn so với TPU và được hỗ trợ bởi phạm vi rộng các framework học sâu, bao gồm TensorFlow, PyTorch, Keras, MXNet và Caffe.
GPU cũng hưởng lợi từ hệ thư viện và công cụ phong phú như CUDA, cuDNN và RAPIDS, càng tăng tính đa dụng và dễ tích hợp vào các quy trình máy học và khoa học dữ liệu khác nhau.
Về hỗ trợ cộng đồng, GPU có hệ sinh thái rộng với nhiều diễn đàn, hướng dẫn và tài liệu từ các nguồn như NVIDIA, AMD và các nền tảng cộng đồng. Nhà phát triển có thể truy cập các cộng đồng trực tuyến sôi động, diễn đàn và nhóm người dùng để tìm trợ giúp, chia sẻ kiến thức và hợp tác dự án. Ngoài ra, vô số hướng dẫn, khóa học và tài liệu bao phủ lập trình GPU, framework học sâu và kỹ thuật tối ưu hóa.
Hỗ trợ cộng đồng cho TPU tập trung hơn quanh hệ sinh thái của Google, với tài nguyên chủ yếu qua tài liệu, diễn đàn và kênh hỗ trợ của GCP. Dù Google cung cấp tài liệu và hướng dẫn toàn diện được thiết kế riêng cho việc dùng TPU với TensorFlow, hỗ trợ cộng đồng có thể hạn chế hơn so với hệ sinh thái GPU rộng lớn. Tuy nhiên, các kênh hỗ trợ chính thức và tài nguyên cho nhà phát triển của Google vẫn mang lại trợ giúp giá trị cho những người sử dụng TPU cho khối lượng công việc AI.
Hiệu quả năng lượng của GPU và TPU khác nhau tùy kiến trúc và mục đích sử dụng. Nhìn chung, TPU tiết kiệm năng lượng hơn GPU, đặc biệt là Google Cloud TPU v3, vốn hiệu quả điện năng cao hơn đáng kể so với các GPU NVIDIA cao cấp.
Để có thêm ngữ cảnh:
Mức tiêu thụ điện thấp hơn của TPU có thể góp phần giảm đáng kể chi phí vận hành và tăng hiệu quả năng lượng, đặc biệt trong các triển khai máy học quy mô lớn.
TPU và GPU áp dụng các tối ưu hóa cụ thể để tăng hiệu quả năng lượng khi thực hiện các tác vụ AI quy mô lớn.
Như đã đề cập trước đó, kiến trúc TPU được thiết kế để ưu tiên các phép toán tensor thường dùng trong mạng nơ-ron, cho phép thực thi tác vụ AI hiệu quả với mức tiêu thụ năng lượng tối thiểu. TPU cũng có phân cấp bộ nhớ tùy biến tối ưu cho tính toán AI, giảm độ trễ truy cập bộ nhớ và chi phí năng lượng.
Chúng tận dụng các kỹ thuật như lượng tử hóa (quantization) và độ thưa (sparsity) để tối ưu hóa phép toán số học, giảm tiêu thụ điện mà không đánh đổi độ chính xác. Những yếu tố này cho phép TPU mang lại hiệu năng cao trong khi vẫn tiết kiệm năng lượng.
Tương tự, GPU triển khai các tối ưu hóa tiết kiệm năng lượng để tăng hiệu năng trong vận hành AI. Kiến trúc GPU hiện đại tích hợp các tính năng như power gating và thay đổi điện áp/tần số động (DVFS) để điều chỉnh mức tiêu thụ điện theo tải công việc. Chúng cũng sử dụng kỹ thuật xử lý song song để phân phối tác vụ tính toán qua nhiều lõi, tối đa hóa thông lượng trong khi giảm năng lượng cho mỗi phép toán.
Các nhà sản xuất GPU phát triển kiến trúc bộ nhớ và phân cấp bộ nhớ đệm hiệu quả năng lượng để tối ưu mô hình truy cập và giảm tiêu thụ điện trong quá trình truyền dữ liệu. Những tối ưu hóa này, kết hợp với kỹ thuật phần mềm như hợp nhất kernel và unroll vòng lặp, càng nâng cao hiệu quả năng lượng trong các khối lượng công việc AI tăng tốc bằng GPU.
Cả TPU và GPU đều cung cấp khả năng mở rộng cho các dự án AI lớn, nhưng tiếp cận theo cách khác nhau. TPU được tích hợp chặt chẽ vào hạ tầng đám mây, đặc biệt qua Google Cloud Platform (GCP), cung cấp tài nguyên có thể mở rộng cho khối lượng công việc AI. Người dùng có thể truy cập TPU theo nhu cầu, scale lên hoặc xuống dựa trên nhu cầu tính toán, điều này rất quan trọng để xử lý hiệu quả các dự án AI quy mô lớn. Google cung cấp dịch vụ quản lý và môi trường cấu hình sẵn để triển khai mô hình AI trên TPU, đơn giản hóa quá trình tích hợp vào hạ tầng đám mây.
Mặt khác, GPU cũng mở rộng hiệu quả cho các dự án AI lớn, với lựa chọn triển khai tại chỗ hoặc sử dụng trong môi trường đám mây do các nhà cung cấp như Amazon Web Services (AWS) và Microsoft Azure cung cấp. GPU linh hoạt trong mở rộng, cho phép triển khai nhiều GPU song song để tăng sức mạnh tính toán.
Ngoài ra, GPU vượt trội trong xử lý các tập dữ liệu lớn nhờ băng thông bộ nhớ cao và khả năng xử lý song song. Điều này cho phép xử lý dữ liệu và huấn luyện mô hình hiệu quả, vốn thiết yếu cho các dự án AI quy mô lớn xử lý dữ liệu khổng lồ.
Tổng thể, cả TPU và GPU đều mang lại khả năng mở rộng cho các dự án AI lớn, với TPU tích hợp chặt chẽ vào hạ tầng đám mây và GPU cung cấp sự linh hoạt cho triển khai tại chỗ hoặc trên đám mây. Khả năng xử lý tập dữ liệu lớn và mở rộng tài nguyên tính toán khiến chúng vô giá cho việc giải quyết các tác vụ AI phức tạp ở quy mô.
| Tính năng | GPU | TPU |
|---|---|---|
| Kiến trúc tính toán | Hàng nghìn lõi nhỏ, hiệu quả cho xử lý song song | Ưu tiên phép toán tensor, kiến trúc chuyên biệt |
| Hiệu năng | Đa dụng, xuất sắc ở nhiều tác vụ AI, gồm học sâu và suy luận | Tối ưu cho phép toán tensor, thường vượt GPU ở một số tác vụ học sâu cụ thể |
| Tốc độ và hiệu suất | Ví dụ: 128 chuỗi với mô hình BERT: 3,8 ms trên V100 GPU | Ví dụ: 128 chuỗi với mô hình BERT: 1,7 ms trên TPU v3 |
| Điểm chuẩn | ResNet-50 trên CIFAR-10: 40 phút cho 10 epoch (4 phút/epoch) trên Tesla V100 GPU | ResNet-50 trên CIFAR-10: 15 phút cho 10 epoch (1,5 phút/epoch) trên Google Cloud TPU v3 |
| Chi phí | NVIDIA Tesla V100: 8.000 - 10.000 USD/chiếc, 2,48 USD/giờ; NVIDIA A100: 10.000 - 15.000 USD/chiếc, 2,93 USD/giờ | Google Cloud TPU v3: 4,50 USD/giờ; TPU v4: 8,00 USD/giờ |
| Khả dụng | Có sẵn rộng rãi từ nhiều nhà cung cấp (NVIDIA, AMD, Intel), cho người tiêu dùng và doanh nghiệp | Chủ yếu truy cập qua Google Cloud Platform (GCP) |
| Hệ sinh thái và công cụ phát triển | Được hỗ trợ bởi nhiều framework (TensorFlow, PyTorch, Keras, MXNet, Caffe), thư viện phong phú (CUDA, cuDNN, RAPIDS) | Tích hợp với TensorFlow, hỗ trợ JAX, được tối ưu bởi trình biên dịch TensorFlow XLA |
| Hỗ trợ cộng đồng và tài nguyên | Hệ sinh thái rộng với nhiều diễn đàn, hướng dẫn và tài liệu từ NVIDIA, AMD và cộng đồng | Tập trung quanh hệ sinh thái Google với tài liệu, diễn đàn và kênh hỗ trợ của GCP |
| Hiệu quả năng lượng | NVIDIA Tesla V100: 250 watt; NVIDIA A100: 400 watt | Google Cloud TPU v3: 120–150 watt; TPU v4: 200–250 watt |
| Tối ưu cho tác vụ AI | Tối ưu hóa tiết kiệm năng lượng (power gating, DVFS, xử lý song song, hợp nhất kernel) | Phân cấp bộ nhớ tùy biến, lượng tử hóa và độ thưa cho tính toán AI hiệu quả |
| Khả năng mở rộng trong ứng dụng doanh nghiệp | Có thể mở rộng cho dự án AI lớn, tại chỗ hoặc đám mây (AWS, Azure), băng thông bộ nhớ cao, xử lý song song | Tích hợp chặt chẽ vào hạ tầng đám mây (GCP), mở rộng theo nhu cầu, dịch vụ quản lý để triển khai mô hình AI |
Chọn GPU khi:
Chọn TPU khi:
GPU và TPU là các bộ tăng tốc phần cứng chuyên dụng dùng trong ứng dụng AI. Ban đầu phát triển cho kết xuất đồ họa, GPU xuất sắc ở xử lý song song và đã được điều chỉnh cho các tác vụ AI, mang lại tính đa dụng trên nhiều ngành. Ngược lại, TPU do Google tùy biến riêng cho khối lượng công việc AI, ưu tiên các phép toán tensor thường thấy trong mạng nơ-ron.
Bài viết này đã so sánh công nghệ GPU và TPU dựa trên hiệu năng, chi phí và khả dụng, hệ sinh thái và công cụ phát triển, hiệu quả năng lượng và tác động môi trường, cũng như khả năng mở rộng trong ứng dụng AI. Để tiếp tục học về TPU và GPU, hãy xem thêm các tài nguyên sau:
Học kỹ năng AI với DataCamp
Tracks
Courses
Courses