Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Amazon S3 ist eines der Tools, die dir immer wieder begegnen, wenn du in der Cloud arbeitest. S3 wird in den meisten AWS-Projekten verwendet, sei es für die Speicherung statischer Dateien oder den Aufbau einer skalierbaren Architektur, was erklärt, warum es ein so beliebtes Interviewthema ist. Im Vorstellungsgespräch geht es nicht nur darum, wie viele S3-Fakten du kennst, sondern auch darum, ob du diesen Dienst effektiv nutzen kannst, um reale Probleme zu lösen, die Leistung zu optimieren und sicherzustellen, dass deine Systeme sicher und skalierbar bleiben.
In diesem Artikel habe ich eine Liste von 25 AWS S3-Interviewfragen zusammengestellt, die reale Szenarien widerspiegeln. Ich habe sie in Kategorien eingeteilt - Grundlagen, Mittelstufe, Fortgeschrittene und ein spezieller Abschnitt für Cloud/DevOps-Ingenieure - also egal, wo du in deiner Karriere stehst, hier ist etwas für dich dabei!
Und bevor du anfängst: Wenn du ganz neu im Cloud Computing bist, empfehle ich dir, zuerst unseren Kurs Einführung in das Cloud Computing zu besuchen. In diesem Kurs werden die Grundlagen der Cloud erläutert, Schlüsselbegriffe wie Skalierbarkeit und Latenz erklärt und die Vorteile von Cloud-Tools von Anbietern wie AWS behandelt.
Diese Fragen konzentrieren sich darauf, was S3 ist und wie es funktioniert. Diese Fragen werden dir höchstwahrscheinlich gestellt, wenn du noch nie mit S3 gearbeitet hast oder wenn der Interviewer nicht sicher ist, wie gut du bist und mit den Grundlagen beginnen möchte.
Amazon S3 (Simple Storage Service) ist ein Objektspeicherdienst, mit dem du Daten in beliebigem Umfang speichern, abrufen und verwalten kannst.
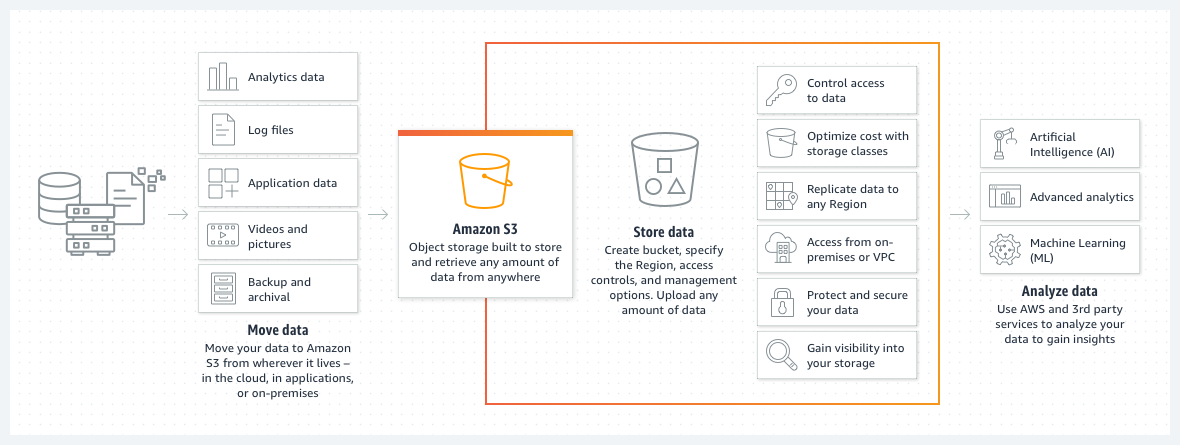
Quelle: AWS
Hauptmerkmale:
Ein S3-Bucket ist ein Container zum Speichern von Objekten in Amazon S3. Jeder Bucket hat einen weltweit eindeutigen Namen und dient als Stammverzeichnis, in das du Dateien (Objekte) hochladen kannst. Buckets werden verwendet, um Daten zu organisieren und Zugriffsrechte zu verwalten.
Amazon S3 bietet mehrere Speicherklassen an, die auf verschiedene Anwendungsfälle zugeschnitten sind:
 S3 Storage Class Types. Bild vom Autor
S3 Storage Class Types. Bild vom Autor
Langlebigkeit misst die Wahrscheinlichkeit, dass deine Daten intakt bleiben und nicht aufgrund von Hardwareausfällen, Korruption oder anderen unerwarteten Ereignissen verloren gehen. S3 sorgt für eine 99,999999999%ige Beständigkeit, indem es die Daten automatisch über mehrere Geräte in mehreren Availability Zones (AZs) repliziert. In der Praxis bedeutet das: Wenn du 10 Millionen Objekte in S3 speicherst, musst du im Durchschnitt damit rechnen, dass du alle 10.000 Jahre ein Objekt durch einen Speicherausfall verlierst.
Verfügbarkeit bezieht sich darauf, wie oft du auf deine Daten zugreifen kannst, wenn du sie brauchst. S3 Standard hat zum Beispiel eine Verfügbarkeit von 99,99%, was bedeutet, dass es in einem Jahr bis zu 53 Minuten Ausfallzeit geben kann, in denen S3 vorübergehend nicht erreichbar ist. Der Dienst ist so konzipiert, dass er mit Störungen umgehen kann, ohne die Nutzer/innen zu beeinträchtigen.
Es gibt mehrere Mechanismen, die helfen können, Daten in S3 zu sichern:
S3 (Simple Storage Service): Objektspeicher für unstrukturierte Daten. Ideal zum Speichern von Dateien, Backups und statischen Assets. Der Zugriff erfolgt über HTTP/HTTPS.
Wenn du mehr zu diesem Thema lesen möchtest, schau dir dieses praktische Tutorial zu S3 und EFS an.
Die Fragen auf mittlerem Niveau konzentrieren sich auf praktische Funktionen und Strategien, wie z.B. die Verwaltung von Kosten, die Einrichtung von Replikationen und die Integration von S3 mit anderen AWS-Diensten. Auf diese Art von Konzepten wirst du stoßen, wenn du eine Anwendung mit S3 optimierst oder skalierst.
Eine Lebenszyklusrichtlinie in S3 ist eine Reihe von Regeln, die den Lebenszyklus der in einem Bucket gespeicherten Objekte automatisch verwalten. Damit kannst du Objekte zwischen den Speicherklassen hin- und herbewegen oder sie nach einem bestimmten Zeitraum löschen. Das kann die Datenverwaltung vereinfachen und die Kosten drastisch senken.
Die S3-Replikation wird verwendet, um Objekte automatisch von einem Bucket in einen anderen zu kopieren.
Die Replikation erfordert die Aktivierung der Versionskontrolle sowohl für den Quell- als auch für den Ziel-Bucket und wird häufig für Backup- und Compliance-Anforderungen verwendet.
S3 + Lambda: Trigger Lambda-Funktionen mit S3 Event Notifications für serverlose Workflows wie Bildverarbeitung, Datentransformation oder Log-Analyse.
S3 + CloudFront: Nutze CloudFront als Content Delivery Network (CDN), um in S3 gespeicherte Inhalte mit geringer Latenz und hoher Leistung zu verbreiten. CloudFront kann S3-Objekte an Edge-Standorten zwischenspeichern, um sie Nutzern weltweit schneller zur Verfügung zu stellen.
Die Versionierung ist eine Funktion in S3, die es dir ermöglicht, mehrere Versionen eines Objekts in einem Bucket zu verwalten und ist nützlich für:
Mit S3 Event Notifications kannst du S3 so konfigurieren, dass es bei bestimmten Ereignissen, wie der Erstellung, Löschung oder Aktualisierung von Objekten, Benachrichtigungen sendet. Benachrichtigungen können an Dienste wie Amazon SQS gesendet werden, um Ereignisse in eine Warteschlange zu stellen, AWS Lambda, um Ereignisse in Echtzeit zu verarbeiten, oder Amazon SNS, um Ereignisse an mehrere Abonnenten zu senden.
Eine vorsignierte URL bietet temporären, zeitlich begrenzten Zugriff auf ein bestimmtes Objekt in S3.Sie ermöglichen es Nutzern, private Dateien herunterzuladen, ohne die Bucket-Berechtigungen zu ändern, und Uploads in ein bestimmtes Bucket zu ermöglichen, ohne vollen Zugriff zu gewähren, und sind daher ideal für die gemeinsame Nutzung von Dateien.
Im Abschnitt für Fortgeschrittene geht es um komplexere Szenarien, in denen du zeigen musst, dass du S3 im großen Maßstab verstehst, wie du Probleme behebst und wie du deine Speicherlösungen sichern und optimieren kannst. Diese Fragen zielen darauf ab, zu bewerten, wie gut du S3 in einer Produktionsumgebung unter Berücksichtigung von Sicherheits-, Leistungs- und Kostenaspekten einsetzen kannst.
Sicherheitsrichtlinien für S3-Buckets können mit IAM-Richtlinien (Identity and Access Management) und Bucket-Richtlinien umgesetzt werden.
IAM-Richtlinien: Lege Berechtigungen für AWS-Benutzer oder -Gruppen fest, die angeben, welche Aktionen für welche S3-Ressourcen durchgeführt werden können. Eine IAM-Richtlinie könnte zum Beispiel einer Anwendung erlauben, Objekte aus einem S3-Bucket zu lesen, sie aber nicht zu löschen.
Eimer-Politik: Lege die Berechtigungen direkt auf S3-Buckets fest. Sie können den Zugang auf der Grundlage von Bedingungen wie IP-Adresse, User Agent oder dem Vorhandensein einer Multi-Faktor-Authentifizierung (MFA) erlauben oder verweigern. Bucket-Richtlinien sind granularer als IAM-Richtlinien und können verwendet werden, um den Zugriff auf Bucket-Ebene zu kontrollieren.
Es gibt einige Best Practices, die du befolgen solltest, wie z.B. die Verwendung von Least Privilege-Prinzipien, die Aktivierung von Bucket Encryption und Logging zur Überwachung des Zugriffs sowie die Verwendung von MFA Delete für zusätzlichen Schutz bei Löschvorgängen.
Mit der S3-Objektsperre kannst du verhindern, dass Objekte für eine bestimmte Aufbewahrungszeit gelöscht oder überschrieben werden.
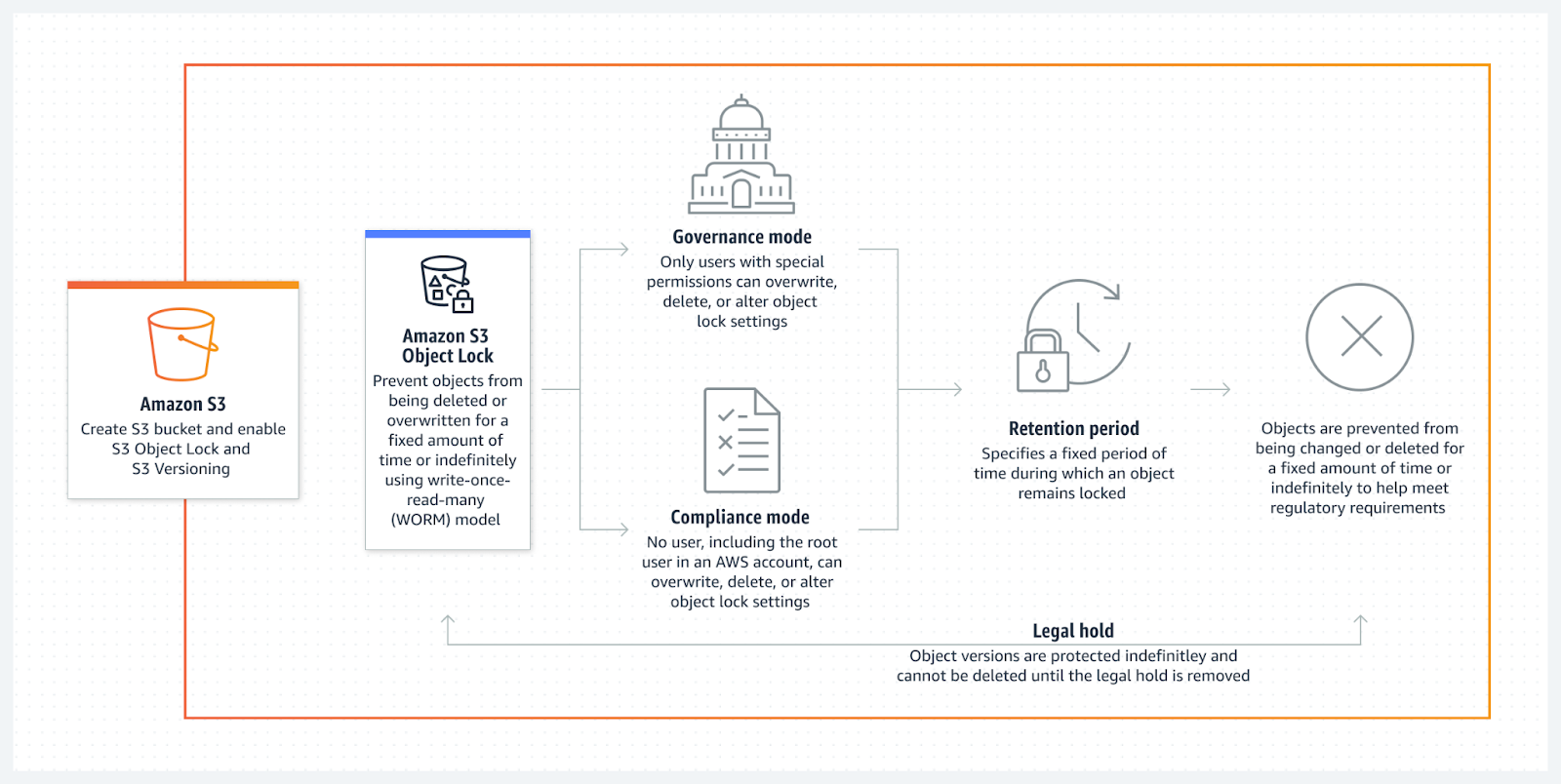
Quelle: AWS
Dies ist in den folgenden Szenarien sehr hilfreich:
Je nach deinen Bedürfnissen funktioniert Object Lock in zwei Modi:
Um große Datei-Uploads auf S3 zu optimieren, kannst du Folgendes verwenden:
Mit S3 Select kannst du eine Teilmenge von Daten aus einem Objekt (z. B. einer CSV- oder JSON-Datei) abrufen, ohne das gesamte Objekt herunterladen zu müssen. Dadurch können sowohl die Kosten für die Datenübertragung als auch die Zeit, die für die Verarbeitung großer Datensätze wie großer Protokolldateien oder Analysedatensätze benötigt wird, erheblich gesenkt werden.Du definierst eine SQL-Abfrage, um bestimmte Spalten oder Zeilen aus einem Objekt zu filtern oder abzurufen. Es werden nur die Daten übertragen, die von der Abfrage zurückgegeben werden. So vermeidest du, dass große Objekte in ihrer Gesamtheit übertragen werden.
Bei diesen Fragen geht es nicht nur um technisches Wissen, sondern auch darum, wie du S3 bei der Lösung von Geschäftsproblemen, der Aufrechterhaltung der Systemzuverlässigkeit und der Integration in breitere Arbeitsabläufe wie CI/CD-Pipelines einsetzt.
Es gibt hier keine "richtige" Antwort, denn du wirst nach deiner Erfahrung gefragt und danach, was du in bestimmten Situationen tun würdest. Ich habe jedoch eine Liste mit der Art von Fragen zusammengestellt, die dir gestellt werden könnten, worauf der Interviewer achtet und welche Elemente eine gute Antwort enthalten sollte.
Wonach die Interviewer suchen:
Bei dieser Frage geht es um deine Fähigkeit, geschäftliche Herausforderungen zu erkennen, und darum, wie du S3 genutzt hast, um diese Herausforderungen effektiv anzugehen. Der Interviewer interessiert sich für deine Problemlösungsfähigkeiten, wie du S3-Funktionen eingesetzt hast und wie die von dir implementierte Lösung dem Unternehmen zugute kam.
Was du in deiner Antwort angeben solltest:
Beispielantwort:
"Bei einem früheren Projekt arbeiteten wir mit einem Medienunternehmen zusammen, das große Videodateien speichern und an Nutzer auf der ganzen Welt liefern musste. Die Herausforderung waren die hohen Latenzzeiten und Speicherkosten. Wir haben S3 verwendet, um die Videos zu speichern, und CloudFront für eine schnelle globale Auslieferung integriert. Außerdem haben wir S3 Intelligent-Tiering implementiert, um Videos, auf die nur selten zugegriffen wird, automatisch in günstigere Speicherklassen zu verschieben. Dadurch konnten wir unsere Lagerkosten um 30 % senken und die Liefergeschwindigkeit um 50 % verbessern, was zu einer höheren Kundenzufriedenheit führte."
Wonach die Interviewer suchen:
Die Interviewer prüfen, ob du die AWS-Preisgestaltung verstehst und wie du fundierte Entscheidungen über Speicherstrategien treffen kannst. Sie wollen wissen, ob du ein Gleichgewicht zwischen Kosteneffizienz und Leistung herstellen kannst.
Was du in deiner Antwort angeben solltest:
Beispielantwort:
"In einem Projekt hatten wir einen großen Datensatz, auf den in der Anfangsphase häufig und nach einem Monat kaum noch zugegriffen wurde. Um die Kosten zu optimieren, habe ich S3 Lifecycle-Richtlinien eingerichtet, um ältere Daten nach 30 Tagen in S3 Glacier zu übertragen. Außerdem habe ich S3 Intelligent-Tiering für Daten verwendet, die unvorhersehbare Zugriffsmuster hatten. Dadurch sind unsere Lagerkosten um 40 % gesunken, und wir konnten mehr Budget für andere Teile der Infrastruktur bereitstellen."
Wonach die Interviewer suchen:
Bei dieser Frage wollen die Interviewer dein Wissen über die Gestaltung von Verfügbarkeit, Ausfallsicherheit und Kosteneffizienz in einer globalen Architektur bewerten. Sie wollen herausfinden, ob du die Nachteile einer Einrichtung mit mehreren Regionen, wie Latenz, Replikation und Kosten, verstehst.
Was du in deiner Antwort angeben solltest:
Beispielantwort:
"In einem früheren Projekt hatte ich die Aufgabe, eine S3-Architektur zu entwickeln, um Kunden auf mehreren Kontinenten zu bedienen. Um eine hohe Verfügbarkeit und Fehlertoleranz zu erreichen, habe ich eine regionenübergreifende Replikation (Cross-Region Replication, CRR) zwischen S3-Buckets in zwei Regionen eingerichtet: eine in den USA und eine in Europa. So war sichergestellt, dass die Daten auch dann verfügbar waren, wenn eine Region ausfiel. Um die Latenz zu minimieren, habe ich außerdem CloudFront als CDN integriert, um die Daten näher an den Nutzern zwischenzuspeichern und so die Zugriffszeiten zu verkürzen. CRR hat zwar zusätzliche Kosten verursacht, aber das war durch den Bedarf an Ausfallsicherheit für unsere globale Nutzerbasis gerechtfertigt."
Wonach die Interviewer suchen:
Die Interviewer wollen sehen, dass du weißt, wie du potenzielle Probleme in deiner S3-Infrastruktur proaktiv überwachen und erkennen kannst. Sie wollen sehen, ob du die AWS-Tools für die Überwachung nutzen kannst und wie du Warnmeldungen für ein effektives Vorfallsmanagement einrichtest.
Was du in deiner Antwort angeben solltest:
Beispielantwort:
"Für die Überwachung von S3-Buckets verwende ich in erster Linie CloudWatch, um Metriken wie die Anzahl der Anfragen, die Speichernutzung und die Fehlerraten zu verfolgen. Ich habe Alarme für ungewöhnliche Spitzen bei den Anfrageraten oder der Speichernutzung eingerichtet, die auf mögliche Probleme hinweisen können. Außerdem aktiviere ich CloudTrail, um S3-API-Aufrufe zu protokollieren, damit ich alle Interaktionen mit den Buckets nachvollziehen und überprüfen kann. Das hat mir geholfen, Probleme mit unerwarteten Änderungen an den Eimerrichtlinien schnell zu erkennen und unbefugten Zugriff zu verhindern."
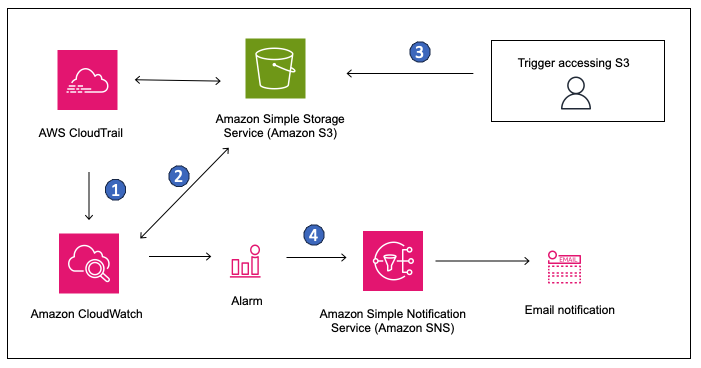
Quelle: AWS
Wonach die Interviewer suchen:
Interviewer wollen wissen, wie gut du S3 in moderne Entwicklungsworkflows wie CI/CD integrieren kannst. Sie bewerten deine Erfahrung mit der Automatisierung von Speicheroperationen als Teil einer breiteren DevOps-Pipeline.
Was du in deiner Antwort angeben solltest:
Beispielantwort:
"In einem meiner letzten Projekte haben wir S3 in unsere CI/CD-Pipeline integriert, um Build-Artefakte zu verwalten. Nach einem erfolgreichen Build lud die Pipeline die Artefakte automatisch in einen speziellen S3-Bucket hoch. Dann haben wir S3 Event Notifications verwendet, um AWS Lambda auszulösen, das den Bereitstellungsprozess gestartet hat. Dadurch wurde die Verteilungspipeline gestrafft und wir konnten die Artefakte zentral verwalten. Es verkürzte die Bereitstellungszeiten erheblich und ermöglichte eine bessere Versionierung der Build-Artefakte."
Wonach die Interviewer suchen:
Der Interviewer möchte wissen, ob du in der Lage bist, Redundanz und Ausfallsicherheit zu gewährleisten und sicherzustellen, dass deine Anwendung auch bei Ausfällen betriebsbereit bleibt. Sie sind auf der Suche nach spezifischen Strategien und Tools, die du benutzt hast, um Fehlertoleranz in S3-basierte Anwendungen einzubauen.
Was du in deiner Antwort angeben solltest:
Beispielantwort:
"Um Hochverfügbarkeit und Fehlertoleranz für eine Anwendung zu gewährleisten, die stark auf S3 angewiesen war, habe ich die regionenübergreifende Replikation (CRR) eingesetzt, um Daten zwischen den Regionen zu replizieren. So war sichergestellt, dass die Anwendung auch bei einem Ausfall einer Region weiterhin auf Daten aus einer anderen Region zugreifen konnte. Außerdem habe ich die Versionierung auf S3 aktiviert, um Datenverluste durch versehentliches Löschen oder Überschreiben zu vermeiden. Außerdem habe ich CloudWatch Alarme eingerichtet, um den Zustand der Replikationsprozesse zu überwachen und uns im Falle eines Ausfalls zu benachrichtigen, damit wir schnell Gegenmaßnahmen ergreifen können."
Wonach die Interviewer suchen:
Diese Frage prüft dein Verständnis von Compliance und Governance in AWS-Umgebungen. Der Interviewer sucht nach deiner Erfahrung mit der Einhaltung von Sicherheitsstandards, Audits und der Sicherstellung, dass alle Konfigurationen den Unternehmensrichtlinien entsprechen.
Was du in deiner Antwort angeben solltest:
Beispielantwort:
"Um die Einhaltung der S3-Bucket-Konfigurationen durchzusetzen, habe ich mit AWS Config verfolgt, ob die Buckets unseren internen Richtlinien entsprechen, z. B. ob der öffentliche Zugang gesperrt und die Verschlüsselung aktiviert ist. Außerdem habe ich IAM-Richtlinien implementiert, um einzuschränken, wer auf S3-Buckets zugreifen oder sie verändern kann. So wird sichergestellt, dass nur autorisierte Benutzer Änderungen vornehmen können. Wir haben CloudTrail genutzt, um alle S3-Aktivitäten zu Prüfzwecken zu protokollieren, was es einfacher macht, Zugriffsmuster zu verfolgen und die Einhaltung gesetzlicher Vorschriften zu gewährleisten."
Wenn du es bis hierher geschafft hast, bist dubereit für dein AWS S3-Interview!
Allerdings ist S3 nur ein kleiner Teil von AWS, und du wirst wahrscheinlich auch Fragen zu anderen Diensten gestellt bekommen. Wenn du dich vorbereiten oder einfach nur deine Wissenslücken schließen willst, empfehle ich dir unseren Kurs "Einführung in AWS " oder, wenn du lieber praktisch lernst, unseren Kurs " AWS Cloud Technologies and Services".
Du kannst dein Studium auch fortsetzen und eine offizielle AWS-Zertifizierung in deinen Lebenslauf oder dein LinkedIn-Profil aufnehmen, um deine Fähigkeiten bei potenziellen Arbeitgebern zu präsentieren. AWS bietet je nach Stufe und Rolle verschiedene Zertifizierungen an, sodass für jeden etwas dabei ist!
Ich wünsche dir viel Glück bei deinem Vorstellungsgespräch!
AWS lernen mit DataCamp
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
