
Track
AWS Cloud Practitioner (CLF-C02)
10 hr
Amazon S3 is one of those tools that you’ll encounter again and again when working in the cloud. S3 is used in most AWS projects, whether it is for storing static files or building a scalable architecture, which explains why it is such a popular interview topic. What interviewers will assess is not just how many S3 facts you know, but if you can use this service effectively to solve real-world problems, optimize performance and ensure your systems remain secure and scalable.
In this article, I’ve put together a list of 25 AWS S3 interview questions that reflect real-world scenarios. I’ve grouped them into categories – Basic, Intermediate, Advanced, and a special section for Cloud/DevOps Engineers – so no matter where you are in your career, there’s something here for you!
And before you start: If you are completely new to cloud computing, I recommend taking our Introduction to Cloud Computing course first. This course breaks down cloud basics, explains key terms like scalability and latency, and covers the advantages of cloud tools from providers like AWS.
These questions focus on what S3 is and how it works. You will most likely encounter these questions if you have never worked with S3 before, or if the interviewer isn’t certain of your skill level and wants to start with the basics.
Amazon S3 (Simple Storage Service) is an object storage service that allows you to store, retrieve, and manage data at any scale.
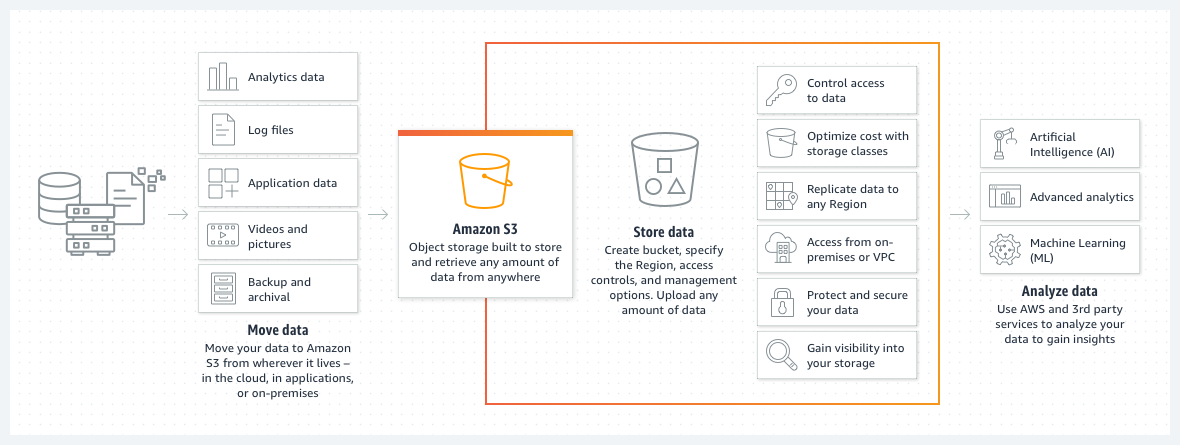
Source: AWS
Main Features:
An S3 bucket is a container for storing objects in Amazon S3. Each bucket has a globally unique name and serves as the root directory where you can upload files (objects). Buckets are used to organize data and manage access permissions.
Amazon S3 offers multiple storage classes tailored to different use cases:

S3 Storage Class Types. Image by Author
Durability measures the likelihood that your data will remain intact and not be lost due to hardware failures, corruption, or other unexpected events. S3 ensures 99.999999999% durability by automatically replicating data across multiple devices in multiple Availability Zones (AZs). In practical terms, this means that if you store 10 million objects in S3, on average, you could expect to lose one object every 10,000 years due to a storage failure.
Availability refers to how often you can access your data when you need it. For example, S3 Standard has 99.99% availability, meaning that in a given year, there might be up to 53 minutes of downtime where S3 is temporarily inaccessible. The service is designed to handle disruptions without impacting users.
There are multiple mechanisms that can help keep data secure in S3:
S3 (Simple Storage Service): Object storage for unstructured data. Ideal for storing files, backups, and static assets. Accessed via HTTP/HTTPS.
If you’re interested in reading more on this topic, have a look at this hands-on tutorial on S3 and EFS.
The intermediate-level questions focus on practical features and strategies, like managing costs, setting up replication, and integrating S3 with other AWS services. These are the kinds of concepts you’ll encounter when optimizing or scaling an application using S3.
A lifecycle policy in S3 is a set of rules that automatically manage the lifecycle of objects stored in a bucket. You can use it to transition objects between storage classes or delete them after a specified period. This can simplify data management and drastically reduce costs.
S3 replication is used to copy objects from one bucket to another automatically.
Replication requires enabling versioning on both the source and destination buckets and is commonly used for backup and compliance needs.
S3 + Lambda: Trigger Lambda functions using S3 Event Notifications for serverless workflows like image processing, data transformation, or log analysis.
S3 + CloudFront: Use CloudFront as a Content Delivery Network (CDN) to distribute content stored in S3 with low latency and high performance. CloudFront can cache S3 objects at edge locations for faster delivery to users worldwide.
Versioning is a feature in S3 that allows you to maintain multiple versions of an object within a bucket and is useful for:
S3 Event Notifications let you configure S3 to send notifications when specific events occur, such as object creation, deletion, or updates. Notifications can be sent to services like Amazon SQS to queue of events, AWS Lambda to process events in real time or Amazon SNS to broadcast events to multiple subscribers.
A pre-signed URL provides temporary, time-limited access to a specific object in S3.They allow users to download private files without changing bucket permissions and enable uploads to a specific bucket without granting full access, so they’re great for file sharing.
The advanced section dives into more complex scenarios, where you’ll need to demonstrate your understanding of S3 at scale, how to troubleshoot issues, and how to secure and optimize your storage solutions. These questions are designed to evaluate how well you can apply S3 in a production environment with security, performance, and cost considerations in mind.
Security policies for S3 buckets can be implemented using IAM (Identity and Access Management) policies and bucket policies.
IAM policies: Define permissions for AWS users or groups, specifying which actions can be performed on which S3 resources. For example, an IAM policy might allow an application to read objects from an S3 bucket but not delete them.
Bucket policies: Define permissions directly on S3 buckets. They can allow or deny access based on conditions like IP address, user agent, or the presence of multi-factor authentication (MFA). Bucket policies are more granular than IAM policies and can be used to control access at the bucket level.
There are some best practices to follow, like using least privilege principles, enabling bucket encryption and logging to monitor access and using MFA delete for added protection on delete operations.
S3 Object Lock enables you to prevent objects from being deleted or overwritten for a specified retention period.
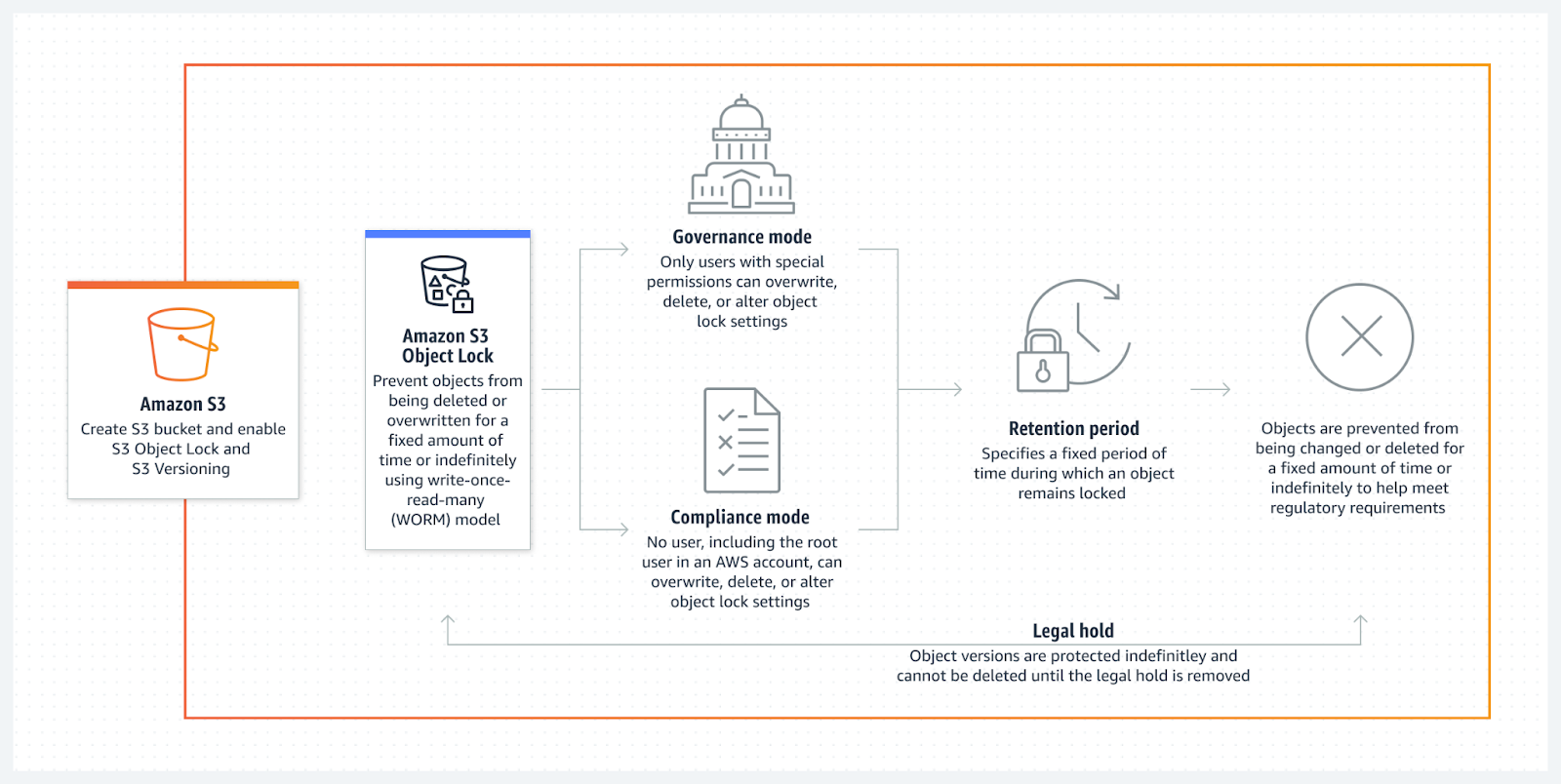
Source: AWS
This is really helpful in the following scenarios:
Depending on your needs, Object Lock works in two modes:
To optimize large file uploads to S3, you can use:
S3 Select allows you to retrieve a subset of data from an object (like a CSV or JSON file) without needing to download the entire object. This can significantly reduce both data transfer costs and the time it takes to process large datasets like large log files or analytics datasets.You define a SQL query to filter or retrieve specific columns or rows from an object. Only the data returned by the query is transmitted, so you avoid transferring large objects in their entirety.
These are the questions that evaluate not just technical knowledge but also how you apply S3 in solving business problems, maintaining system reliability, and integrating with broader workflows like CI/CD pipelines.
There is no “right” answer here, as you’ll be asked to talk about your experience and what you might do in specific scenarios, but I’ve compiled a list of the type of questions you might get, what the interviewer is looking to assess and what elements a good answer would include.
What interviewers are looking for:
This question is about understanding your ability to identify business challenges and how you leveraged S3 to address those challenges effectively. The interviewer is looking for your problem-solving skills, how you applied S3 features, and how the solution you implemented benefited the business.
What to include in your answer:
Example answer:
"In a previous project, we were working with a media company that needed to store and deliver large video files to users worldwide. The challenge was high latency and storage costs. We used S3 to store the videos and integrated CloudFront for fast global delivery. Additionally, we implemented S3 Intelligent-Tiering to automatically move infrequently accessed videos to cheaper storage classes. This reduced our storage costs by 30% and improved the delivery speed by 50%, resulting in higher customer satisfaction."
What interviewers are looking for:
Interviewers are testing your understanding of AWS pricing and how you can make informed decisions about storage strategies. They want to know if you can balance cost-efficiency with performance.
What to include in your answer:
Example answer:
"In a project, we had a large dataset that was frequently accessed in the early stages and rarely accessed after a month. To optimize costs, I set up S3 Lifecycle policies to transition older data to S3 Glacier after 30 days. Additionally, I used S3 Intelligent-Tiering for data that had unpredictable access patterns. As a result, our storage costs decreased by 40%, and we were able to allocate more budget to other parts of the infrastructure."
What interviewers are looking for:
For this question, interviewers want to assess your knowledge of designing for availability, resilience, and cost efficiency in a global architecture. They want to see if you understand the trade-offs of a multi-region setup, such as latency, replication, and costs.
What to include in your answer:
Example answer:
"In a previous project, I was tasked with designing an S3 architecture to serve customers across multiple continents. To achieve high availability and fault tolerance, I set up Cross-Region Replication (CRR) between S3 buckets in two regions: one in the US and another in Europe. This ensured that data was available even if one region failed. To minimize latency, I also integrated CloudFront as a CDN to cache data closer to users, reducing access times. While CRR added some additional cost, it was justified by the need for resilience in our global user base."
What interviewers are looking for:
Interviewers want to see that you understand how to proactively monitor and detect potential issues in your S3 infrastructure. They want to see your ability to use AWS tools for monitoring and how you can set up alerts for effective incident management.
What to include in your answer:
Example answer:
"For monitoring S3 buckets, I primarily use CloudWatch to track metrics such as request count, storage usage, and error rates. I set up alarms for unusual spikes in request rates or storage usage, which can indicate potential issues. Additionally, I enable CloudTrail to log S3 API calls, ensuring I can trace and audit all interactions with the buckets. This helped me quickly identify issues with unexpected changes to bucket policies and prevent unauthorized access."
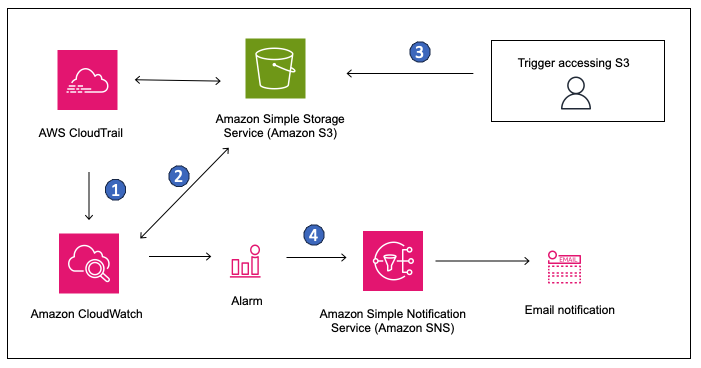
Source: AWS
What interviewers are looking for:
Interviewers want to understand how well you can integrate S3 into modern development workflows like CI/CD. They’re assessing your experience with automating storage operations as part of a broader DevOps pipeline.
What to include in your answer:
Example answer:
"In one of my recent projects, we integrated S3 into our CI/CD pipeline to manage build artifacts. After a successful build, the pipeline automatically uploaded the artifacts to a dedicated S3 bucket. We then used S3 Event Notifications to trigger AWS Lambda, which initiated the deployment process. This streamlined the deployment pipeline and allowed us to manage artifacts centrally. It significantly reduced deployment times and allowed for better versioning of build artifacts."
What interviewers are looking for:
The interviewer wants to know if you can design for redundancy and resilience, and make sure your application remains operational even in the face of failures. They are looking for specific strategies and tools you have used to build fault tolerance into S3-based applications.
What to include in your answer:
Example answer:
"To ensure high availability and fault tolerance for an application that relied heavily on S3, I used Cross-Region Replication (CRR) to replicate data between regions. This setup guaranteed that even if one region went down, the application could still access data from another region. I also enabled versioning on S3 to avoid data loss from accidental deletions or overwrites. Additionally, I set up CloudWatch alarms to monitor the health of replication processes and notify us in case of failure, allowing us to take corrective action quickly."
What interviewers are looking for:
This question tests your understanding of compliance and governance in AWS environments. The interviewer is looking for your experience in maintaining security standards, auditing, and ensuring that all configurations comply with organizational policies.
What to include in your answer:
Example answer:
"To enforce compliance with S3 bucket configurations, I used AWS Config to track whether buckets met our internal policies, such as ensuring that public access was blocked and encryption was enabled. I also implemented IAM policies to restrict who could access or modify S3 buckets, ensuring only authorized users could make changes. We used CloudTrail to log all S3 activity for auditing purposes, making it easier to track access patterns and ensure compliance with regulatory requirements."
If you have made it this far, you’re all set for your AWS S3 interview!
That said, S3 is only a small part of AWS, and you will probably be asked questions about other services. If you want to be prepared, or just reduce the gaps in your knowledge, I’d recommend taking our Introduction to AWS course, or, if you prefer hands-on learning, our AWS Cloud Technologies and Services course.
You can also take your studies further and add an official AWS certification to your CV or LinkedIn profile to showcase your skills to prospective employers. AWS offers a few different certifications depending on your level and role, so there is something for everyone!
I wish you the best of luck with your interview!
Learn AWS with DataCamp
Track
Course
blog
Zoumana Keita
15 min
blog
Zoumana Keita
15 min
blog
Zoumana Keita
12 min
blog
Marie Fayard
15 min
blog
Thalia Barrera
15 min
blog
Marie Fayard
13 min
