When working with machine learning models, it's easy to try them all out without understanding what each model does and when to use them. In this cheat sheet, you'll find a handy guide describing the most widely used unsupervised machine learning models, their advantages, disadvantages, and some key use cases.
Have this cheat sheet at your fingertips
Download PDFUnsupervised Learning
Unsupervised learning is about discovering general patterns in data. The most popular example is clustering or segmenting customers and users. This type of segmentation is generalizable and can be applied broadly, such as to documents, companies, and genes. Unsupervised learning consists of clustering models that learn how to group similar data points together or association algorithms that group different data points based on pre-defined rules.
Clustering Models
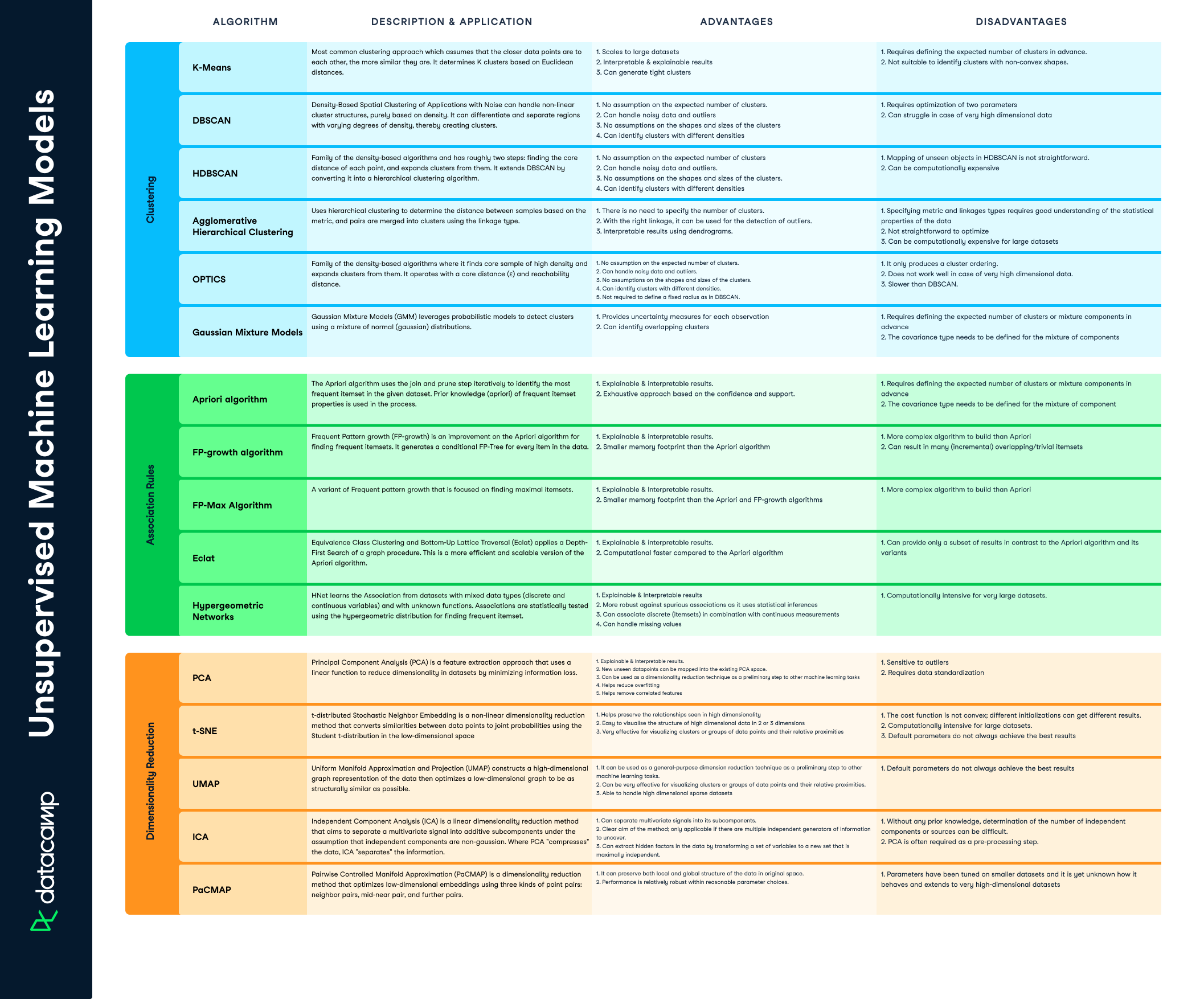
| Algorithm | Description and Application | Advantages | Disadvantages |
| K-Means |
Most common clustering approach which assumes that the closer data points are to each other, the more similar they are. It determines K clusters based on Euclidean distances. |
|
|
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise can handle non-linear cluster structures, purely based on density. It can differentiate and separate regions with varying degrees of density, thereby creating clusters. |
|
|
| HDBSCAN | Family of the density-based algorithms and has roughly two steps: finding the core distance of each point, and expands clusters from them. It extends DBSCAN by converting it into a hierarchical clustering algorithm. |
|
|
| Agglomerative Hierarchical Clustering | Uses hierarchical clustering to determine the distance between samples based on the metric, and pairs are merged into clusters using the linkage type. |
|
|
| OPTICS | Family of the density-based algorithms where it finds core sample of high density and expands clusters from them. It operates with a core distance (ɛ) and reachability distance. |
|
|
| Gaussian Mixture Models | Gaussian Mixture Models (GMM) leverages probabilistic models to detect clusters using a mixture of normal (gaussian) distributions. |
|
|
Association Rules
| Algorithm | Description and Application | Advantages | Disadvantages |
| Apriori algorithm | The Apriori algorithm uses the join and prune step iteratively to identify the most frequent itemset in the given dataset. Prior knowledge (apriori) of frequent itemset properties is used in the process. |
|
|
| FP-growth algorithm | Frequent Pattern growth (FP-growth) is an improvement on the Apriori algorithm for finding frequent itemsets. It generates a conditional FP-Tree for every item in the data. |
|
|
| FP-Max Algorithm | A variant of Frequent pattern growth that is focused on finding maximal itemsets. |
|
|
| Eclat | Equivalence Class Clustering and Bottom-Up Lattice Traversal (Eclat) applies a Depth-First Search of a graph procedure. This is a more efficient and scalable version of the Apriori algorithm. |
|
|
| Hypergeometric Networks | HNet learns the Association from datasets with mixed data types (discrete and continuous variables) and with unknown functions. Associations are statistically tested using the hypergeometric distribution for finding frequent itemset. |
|
|
Dimensionality Reduction
| Algorithm | Description and Application | Advantages | Disadvantages |
| PCA | Principal Component Analysis (PCA) is a feature extraction approach that uses a linear function to reduce dimensionality in datasets by minimizing information loss. |
|
|
| t-SNE | t-distributed Stochastic Neighbor Embedding is a non-linear dimensionality reduction method that converts similarities between data points to joint probabilities using the Student t-distribution in the low-dimensional space |
|
|
| UMAP | Uniform Manifold Approximation and Projection (UMAP) constructs a high-dimensional graph representation of the data then optimizes a low-dimensional graph to be as structurally similar as possible. |
|
|
| ICA | Independent Component Analysis (ICA) is a linear dimensionality reduction method that aims to separate a multivariate signal into additive subcomponents under the assumption that independent components are non-gaussian. Where PCA "compresses" the data, ICA "separates" the information. |
|
|
| PaCMAP | Pairwise Controlled Manifold Approximation (PaCMAP) is a dimensionality reduction method that optimizes low-dimensional embeddings using three kinds of point pairs: neighbor pairs, mid-near pair, and further pairs. |
|
|



