Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.4K
Maschinelles Lernen ist wohl für die bekanntesten und sichtbarsten Anwendungsfälle von Data Science und künstlicher Intelligenz verantwortlich. Von Teslas selbstfahrenden Autos bis hin zu DeepMinds AlphaFold-Algorithmus haben maschinenlernbasierte Lösungen beeindruckende Ergebnisse erzielt und einen großen Hype ausgelöst. Aber was genau ist maschinelles Lernen? Wie funktioniert das? Und was am wichtigsten ist: Ist es den Hype wert? Dieser Artikel bietet eine intuitive Definition der wichtigsten Algorithmen des maschinellen Lernens, stellt einige ihrer wichtigsten Anwendungen vor und bietet Ressourcen für den Einstieg in das maschinelle Lernen.
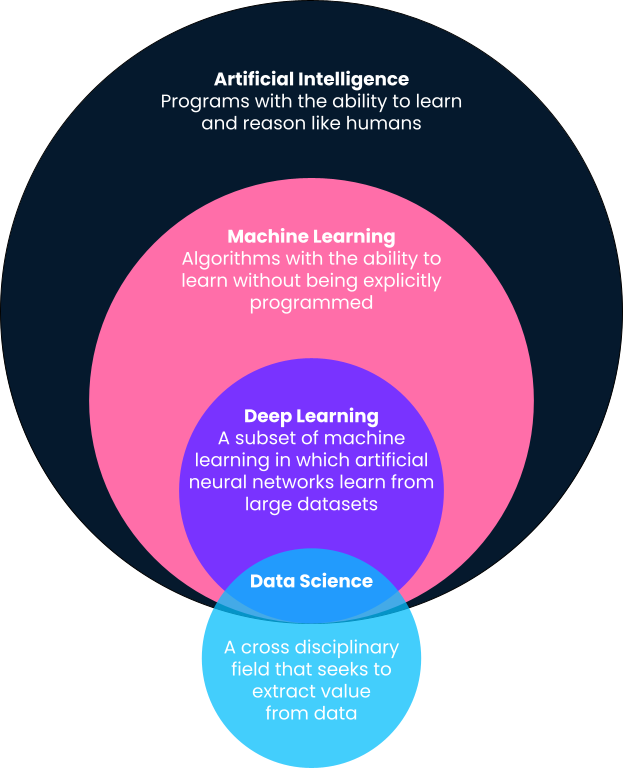
Kurz gesagt ist maschinelles Lernen ein Teilgebiet der künstlichen Intelligenz, bei dem Computer Vorhersagen auf der Grundlage von Mustern treffen, die direkt aus Daten gelernt wurden, ohne dass sie explizit dafür programmiert wurden. Du wirst in dieser Definition feststellen, dass maschinelles Lernen ein Teilbereich der künstlichen Intelligenz ist. Deshalb wollen wir die Definitionen etwas genauer aufschlüsseln, denn oft werden Begriffe wie maschinelles Lernen, künstliche Intelligenz, Deep Learning und sogar Data Science synonym verwendet.
Eine der besten Definitionen von künstlicher Intelligenz stammt von Andrew Ng, Mitbegründer von Google Brain und ehemaliger Chief Scientist bei Baidu. Laut Andrew ist künstliche Intelligenz ein "riesiger Satz von Werkzeugen, die Computer dazu bringen, sich intelligent zu verhalten". Das kann von explizit definierten Systemen wie Taschenrechnern bis hin zu auf maschinellem Lernen basierenden Lösungen wie Spam-E-Mail-Detektoren alles sein.
Wie oben beschrieben, ist maschinelles Lernen ein Teilgebiet der künstlichen Intelligenz, bei dem Algorithmen Muster aus historischen Daten lernen und auf der Grundlage dieser gelernten Muster Vorhersagen machen, indem sie sie auf neue Daten anwenden. Traditionell werden einfache, intelligente Systeme wie Taschenrechner von den Entwicklern explizit als klar definierte Schritte und Verfahren programmiert (d.h. wenn dies, dann das). Für fortgeschrittene Probleme ist das jedoch nicht skalierbar oder möglich.
Nehmen wir das Beispiel der E-Mail-Spamfilter. Entwickler können versuchen, Spamfilter zu erstellen, indem sie sie explizit definieren. Sie können zum Beispiel ein Programm definieren, das einen Spamfilter auslöst, wenn eine E-Mail eine bestimmte Betreffzeile oder bestimmte Links enthält. Dieses System wird sich jedoch als unwirksam erweisen, sobald die Spammer ihre Taktik ändern.
Eine auf maschinellem Lernen basierende Lösung hingegen nimmt Millionen von Spam-E-Mails als Eingabedaten auf, lernt durch statistische Assoziationen die häufigsten Merkmale von Spam-E-Mails und macht auf der Grundlage der gelernten Merkmale Vorhersagen über zukünftige E-Mails.
Deep Learning ist ein Teilbereich des maschinellen Lernens und ist wahrscheinlich für die bekanntesten Anwendungsfälle des maschinellen Lernens in der Popkultur verantwortlich. Deep Learning-Algorithmen sind von der Struktur des menschlichen Gehirns inspiriert und benötigen unglaubliche Datenmengen für das Training. Sie werden oft für die komplexesten "kognitiven" Probleme eingesetzt, wie z.B. Spracherkennung, Sprachübersetzung, selbstfahrende Autos und mehr. In unserem Vergleich von Deep Learning und maschinellem Lernen findest du weitere Informationen.
Im Gegensatz zu maschinellem Lernen, künstlicher Intelligenz und Deep Learning ist die Definition von Data Science recht weit gefasst. Kurz gesagt geht es bei Data Science darum, aus Daten Werte und Erkenntnisse zu gewinnen. Dieser Wert kann in Form von Vorhersagemodellen vorliegen, die maschinelles Lernen nutzen, aber er kann auch bedeuten, dass Erkenntnisse in einem Dashboard oder Bericht dargestellt werden. Lies mehr über die täglichen Aufgaben von Datenwissenschaftlern in diesem Artikel.
Neben der Erkennung von Spam-E-Mails gibt es weitere bekannte Anwendungen für maschinelles Lernen, wie z. B. die Kundensegmentierung auf der Grundlage demografischer Daten (Vertrieb und Marketing), die Vorhersage von Aktienkursen (Finanzwesen), die Automatisierung der Schadensregulierung (Versicherungswesen), Inhaltsempfehlungen auf der Grundlage des Fernsehverhaltens (Medien und Unterhaltung) und vieles mehr. Maschinelles Lernen ist mittlerweile allgegenwärtig und findet in unserem Alltag vielfältige Anwendungen.
Am Ende dieses Artikels findest du viele Ressourcen, die dir den Einstieg in das maschinelle Lernen erleichtern.
Nachdem wir nun einen Überblick über maschinelles Lernen gegeben haben und wo es sich in die anderen Schlagworte einfügt, die dir in diesem Bereich begegnen können, wollen wir uns die verschiedenen Arten von maschinellen Lernalgorithmen genauer ansehen. Algorithmen für maschinelles Lernen werden grob in überwachtes, unüberwachtes, verstärkendes und selbstüberwachtes Lernen eingeteilt. Wir wollen sie im Detail verstehen und ihre häufigsten Anwendungsfälle kennenlernen.
Bei den meisten Anwendungsfällen des maschinellen Lernens geht es darum, dass Algorithmen Muster aus historischen Daten lernen und diese auf neue Daten in Form von Vorhersagen anwenden. Dies wird oft als überwachtes Lernen bezeichnet. Algorithmen des überwachten Lernens zeigen sowohl historische Eingaben als auch Ausgaben für ein bestimmtes Problem, das wir zu lösen versuchen, wobei die Eingaben im Wesentlichen Merkmale oder Dimensionen der Beobachtung sind, die wir vorhersagen wollen, und die Ausgaben die Ergebnisse, die wir vorhersagen wollen. Lass uns das anhand unseres Beispiels für die Spam-Erkennung veranschaulichen.
Im Anwendungsfall der Spam-Erkennung würde ein überwachter Lernalgorithmus auf einem Datensatz von Spam-E-Mails trainiert werden. Die Eingaben wären Merkmale oder Dimensionen der E-Mails, wie z.B. die Betreffzeile, die E-Mail-Adresse des Absenders, der Inhalt der E-Mail, ob die E-Mail gefährlich aussehende Links enthält und andere relevante Informationen, die Aufschluss darüber geben könnten, ob eine E-Mail spammy ist.
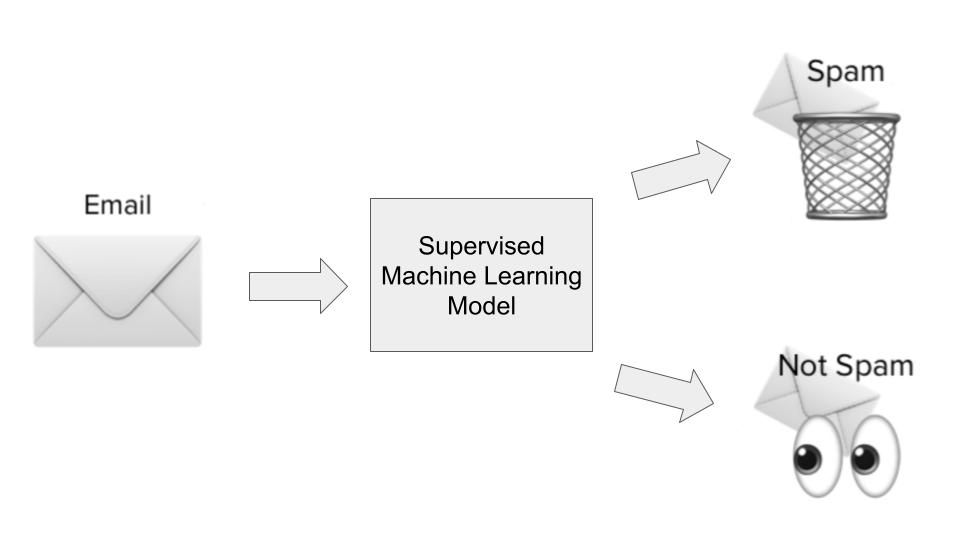
Die Ausgabe würde zeigen, ob es sich bei der E-Mail tatsächlich um Spam handelt oder nicht. Während der Modelllernphase lernt der Algorithmus eine Funktion, um die statistische Beziehung zwischen den Eingabevariablen (den verschiedenen Dimensionen von Spam-E-Mails) und der Ausgabevariable (ob es sich um Spam handelt oder nicht) abzubilden. Dieses funktionale Mapping wird dann verwendet, um den Output der zuvor ungesehenen Daten vorherzusagen.
Es gibt im Wesentlichen zwei Arten von Anwendungsfällen für überwachtes Lernen:
In einem der nächsten Abschnitte werden wir uns bestimmte Algorithmen des überwachten Lernens und einige ihrer Anwendungsfälle genauer ansehen.
Anstatt Muster zu lernen, die Eingaben auf Ausgaben abbilden, entdecken unüberwachte Lernalgorithmen allgemeine Muster in Daten, ohne dass ihnen explizit Ausgaben gezeigt werden. Unüberwachte Lernalgorithmen werden häufig verwendet, um verschiedene Objekte und Entitäten zu gruppieren und zu clustern. Ein gutes Beispiel für unüberwachtes Lernen ist die Kundensegmentierung. Unternehmen haben oft eine Vielzahl von Kundenpersönlichkeiten, die sie bedienen. Unternehmen wollen oft einen faktenbasierten Ansatz zur Identifizierung ihrer Kundensegmente, um sie besser bedienen zu können. Hier kommt das unüberwachte Lernen ins Spiel.
In diesem Anwendungsfall würde ein Algorithmus für unüberwachtes Lernen lernen, Kunden auf der Grundlage verschiedener Attribute zu gruppieren, z. B. wie oft sie ein Produkt benutzt haben, ihre demografischen Daten, wie sie mit Produkten interagieren und mehr. Dann kann derselbe Algorithmus anhand der gleichen Dimensionen vorhersagen, zu welchem Segment neue Kunden wahrscheinlich gehören.
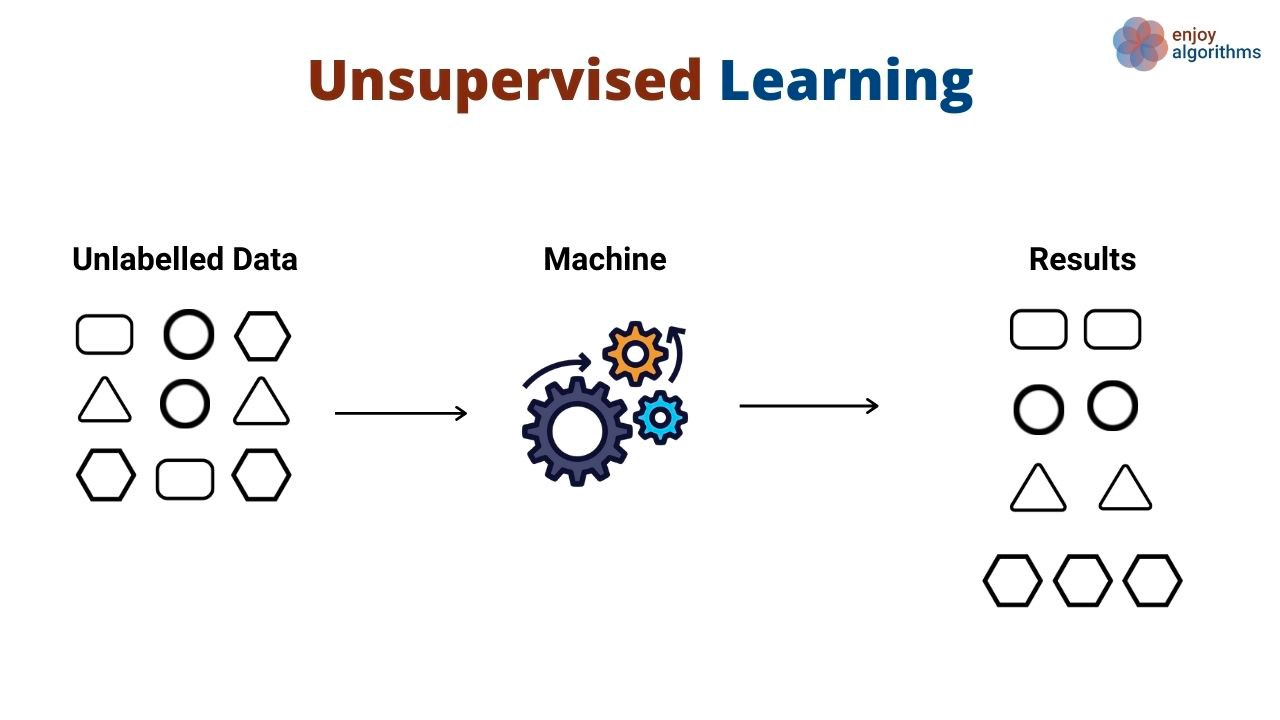
Unüberwachte Algorithmen werden auch verwendet, um die Dimensionen eines Datensatzes (d. h. die Anzahl der Merkmale) mit Hilfe von Dimensionalitätsreduktionstechniken zu reduzieren. Diese Algorithmen werden oft als Zwischenschritt beim Training eines überwachten Lernalgorithmus verwendet.
Ein großer Kompromiss, den Datenwissenschaftler beim Training von Algorithmen für maschinelles Lernen häufig eingehen müssen, ist die Leistung im Vergleich zur Vorhersagegenauigkeit. Im Allgemeinen gilt: Je mehr Informationen sie über ein bestimmtes Problem haben, desto besser. Das kann aber auch zu langsamen Trainingszeiten und Leistungen führen. Techniken zur Dimensionalitätsreduzierung helfen dabei, die Anzahl der Merkmale in einem Datensatz zu reduzieren, ohne die Vorhersagekraft zu beeinträchtigen.
Reinforcement Learning ist eine Untergruppe von Algorithmen des maschinellen Lernens, die Belohnungen einsetzen, um ein gewünschtes Verhalten oder eine Vorhersage zu fördern, und andernfalls eine Strafe verhängen. Obwohl es sich noch um ein relativ junges Forschungsgebiet innerhalb des maschinellen Lernens handelt, ist das Reinforcement Learning für Algorithmen verantwortlich, die die menschliche Intelligenz in Spielen wie Schach, Go und anderen übertreffen.
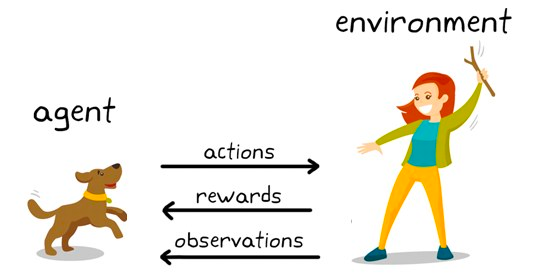
Dabei handelt es sich um eine verhaltensbasierte Modellierungstechnik, bei der das Modell durch einen Versuch-und-Irrtum-Mechanismus lernt, während es ständig mit der Umgebung interagiert. Lass uns das mit dem Schachbeispiel illustrieren. Auf einer hohen Ebene wird einem Verstärkungslernalgorithmus (oft Agent genannt) eine Umgebung (Schachbrett) zur Verfügung gestellt, in der er eine Vielzahl von Entscheidungen (Spielzüge) treffen kann.
Jeder Zug hat eine Reihe von zugehörigen Punkten, eine Belohnung für Aktionen, die den Agenten zum Sieg führen, und eine Strafe für Züge, die den Agenten zum Verlust führen.
Der Agent interagiert ständig mit der Umwelt, um zu lernen, welche Handlungen die meisten Vorteile bringen, und er wiederholt diese Handlungen immer wieder. Diese Wiederholung des geförderten Verhaltens wird als Ausbeutungsphase bezeichnet. Wenn der Agent nach neuen Wegen sucht, um Belohnungen zu verdienen, nennt man das die Erkundungsphase. Im Allgemeinen wird dies als das Paradigma der Erkundung und Ausbeutung bezeichnet.
Selbstüberwachtes Lernen ist eine dateneffiziente Technik des maschinellen Lernens, bei der das Modell aus einem unbeschrifteten Musterdatensatz lernt. Wie im folgenden Beispiel gezeigt, wird das erste Modell mit unmarkierten Bildern gefüttert, die es mit Hilfe von Merkmalen clustert, die aus diesen Bildern generiert werden.
Bei einigen dieser Beispiele ist die Wahrscheinlichkeit groß, dass sie zu den Clustern gehören, bei anderen nicht. Der zweite Schritt verwendet die mit hoher Zuverlässigkeit gekennzeichneten Daten aus dem ersten Schritt, um einen Klassifikator zu trainieren, der in der Regel leistungsfähiger ist als ein einstufiger Clustering-Ansatz.
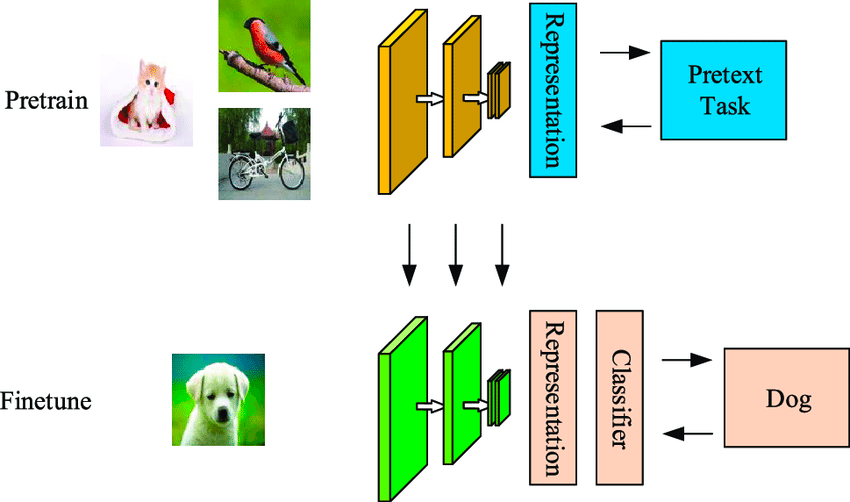
Der Unterschied zwischen selbstüberwachten und überwachten Algorithmen besteht darin, dass die klassifizierte Ausgabe bei ersteren noch keine Zuordnung der Klassen zu realen Objekten enthält. Es unterscheidet sich vom überwachten Lernen dadurch, dass es nicht von der manuell beschrifteten Menge abhängt und die Beschriftungen selbst erzeugt, daher der Name Selbstlernen.
Im Folgenden haben wir einige der wichtigsten Algorithmen für maschinelles Lernen und ihre häufigsten Anwendungsfälle beschrieben.
Ein einfacher Algorithmus modelliert eine lineare Beziehung zwischen einer oder mehreren erklärenden Variablen und einer kontinuierlichen numerischen Ausgangsvariablen. Im Vergleich zu anderen Algorithmen für maschinelles Lernen ist er schneller zu trainieren. Sein größter Vorteil liegt in seiner Fähigkeit, die Modellvorhersagen zu erklären und zu interpretieren. Dabei handelt es sich um einen Regressionsalgorithmus, der zur Vorhersage von Ergebnissen wie dem Kundenlebenszykluswert, Immobilienpreisen und Aktienkursen verwendet wird.
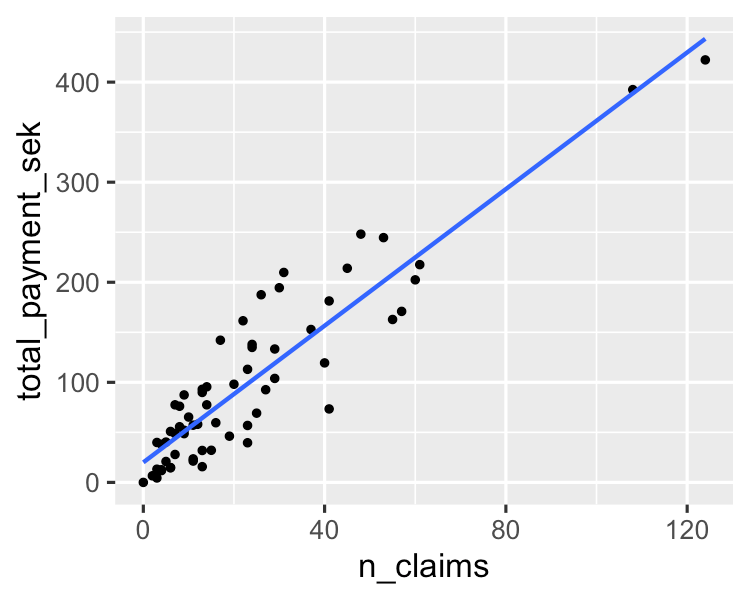
Mehr darüber erfährst du in diesem Tutorial zu den Grundlagen der linearen Regression in Python. Wenn du dich für die Regressionsanalyse interessierst, ist dieser gefragte Kurs auf DataCamp die richtige Ressource für dich.
Ein Entscheidungsbaum-Algorithmus ist eine baumartige Struktur von Entscheidungsregeln, die auf die Eingabemerkmale angewendet werden, um die möglichen Ergebnisse vorherzusagen. Sie kann zur Klassifizierung oder Regression verwendet werden. Entscheidungsbäume sind ein gutes Hilfsmittel für Gesundheitsexperten, denn es ist einfach zu interpretieren, wie diese Vorhersagen gemacht werden.
In diesem Tutorial erfährst du, wie du mit Python einen Entscheidungsbaum-Klassifikator erstellen kannst. Auch wenn du dich mit R besser auskennst, wirst du von diesem Lernprogramm profitieren. Auf DataCamp gibt es auch einen umfassenden Kurs zu Entscheidungsbäumen.
Er ist wohl einer der beliebtesten Algorithmen und baut auf den Nachteilen der Überanpassung auf, die bei den Entscheidungsbaummodellen auffällig sind. Von Overfitting spricht man, wenn Algorithmen ein bisschen zu gut auf die Trainingsdaten trainiert werden und es ihnen nicht gelingt, zu verallgemeinern oder genaue Vorhersagen für ungesehene Daten zu treffen. Random Forest löst das Problem der Überanpassung, indem er mehrere Entscheidungsbäume auf zufällig ausgewählten Stichproben aus den Daten aufbaut. Das endgültige Ergebnis in Form der besten Vorhersage ergibt sich aus der Mehrheitsentscheidung aller Bäume im Wald.
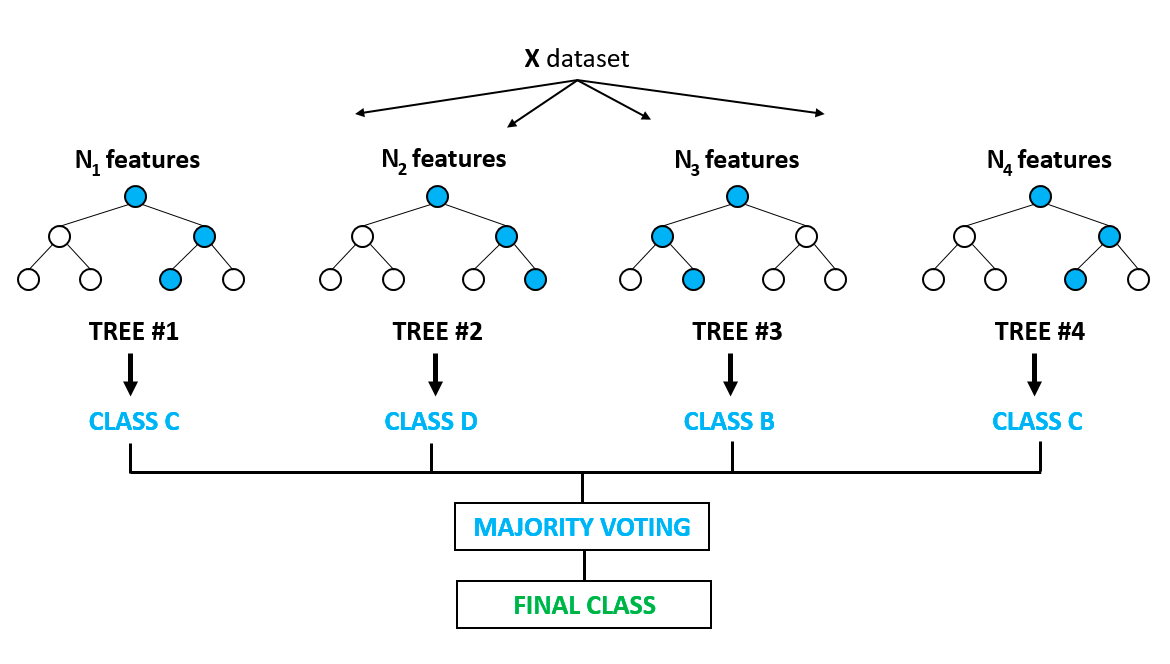
Sie wird sowohl für Klassifizierungs- als auch für Regressionsprobleme verwendet. Sie findet Anwendung bei der Auswahl von Merkmalen, der Erkennung von Krankheiten usw. Mehr über baumbasierte Modelle und Ensembles (Kombination verschiedener Einzelmodelle) erfährst du in diesem sehr beliebten Kurs auf DataCamp. Du kannst auch in diesem Python-Tutorial mehr über die Implementierung des Random-Forest-Modells erfahren.
Support Vector Machines, kurz SVM, werden in der Regel für Klassifizierungsprobleme verwendet. Wie im folgenden Beispiel gezeigt, findet eine SVM eine Hyperebene (in diesem Fall eine Linie), die die beiden Klassen (rot und grün) voneinander trennt und den Abstand zwischen den gestrichelten Linien maximiert.
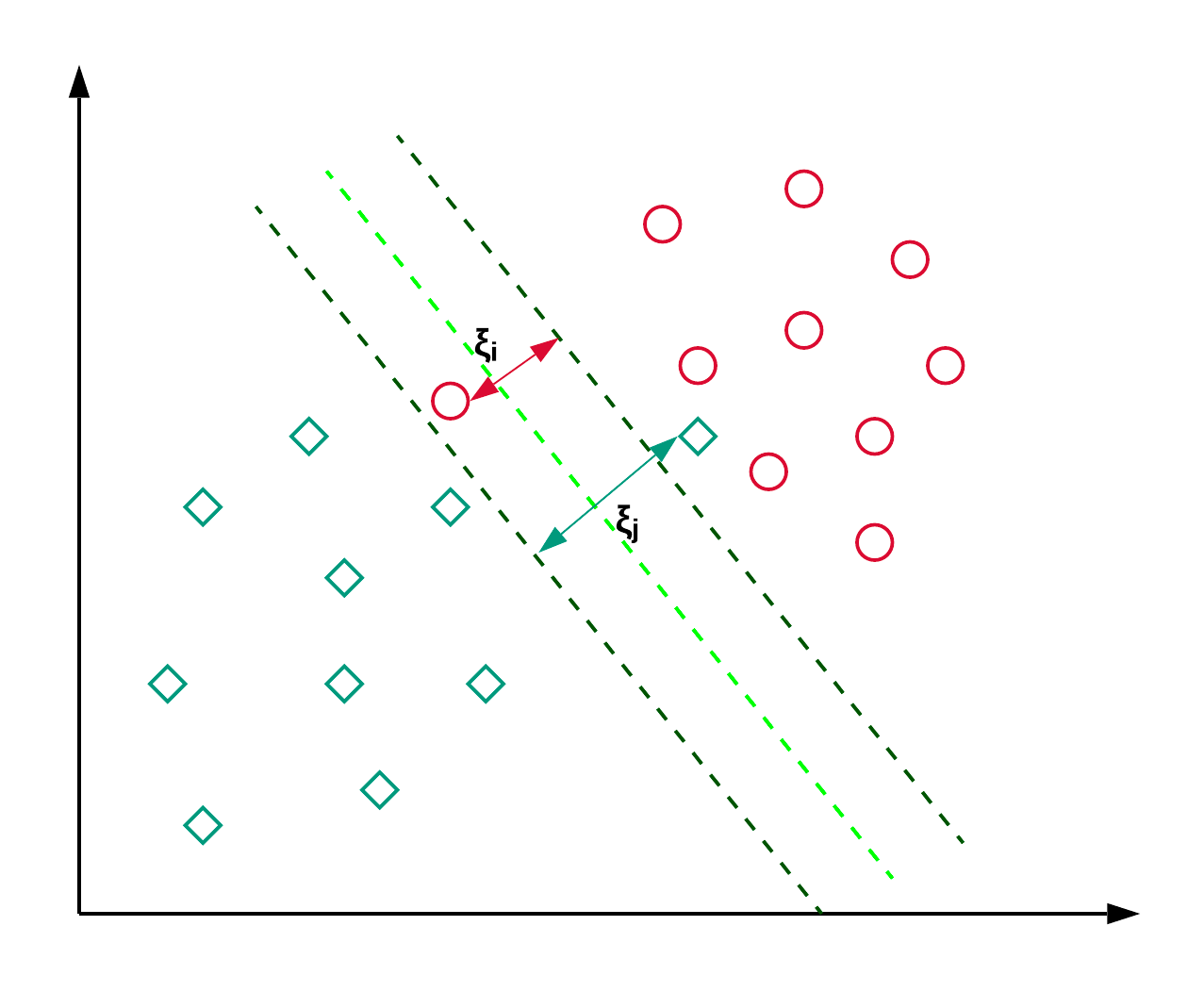
SVM wird im Allgemeinen für Klassifizierungsprobleme verwendet, kann aber auch bei Regressionsproblemen eingesetzt werden. Sie wird zur Klassifizierung von Nachrichtenartikeln und zur Handschrifterkennung verwendet. Mehr über die verschiedenen Arten von Kernel-Tricks und die Python-Implementierung kannst du in diesem scikit-learn SVM-Tutorial lesen. Du kannst auch diesem Tutorial folgen, in dem du die SVM-Implementierung in R nachbaust
Gradient Boosting Regression ist ein Ensemble-Modell, das mehrere schwache Lerner zu einem robusten Vorhersagemodell kombiniert. Sie kann gut mit Nichtlinearitäten in den Daten und Multikollinearitätsproblemen umgehen.
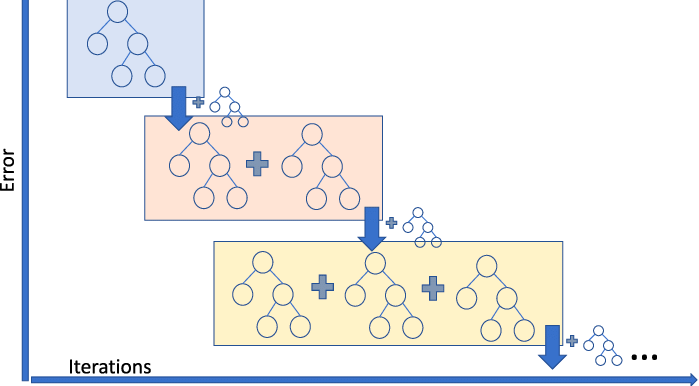
Wenn du in einem Ride-Sharing-Unternehmen tätig bist und die Höhe des Fahrpreises vorhersagen musst, kannst du einen Gradient-Boosting-Regressor verwenden. Wenn du die verschiedenen Arten von Gradient Boosting verstehen willst, kannst du dir dieses Video auf DataCamp ansehen.
K-Means ist der am weitesten verbreitete Clustering-Ansatz - er bestimmt K Cluster auf der Grundlage der euklidischen Distanz. Er ist ein sehr beliebter Algorithmus für Kundensegmentierung und Empfehlungssysteme.
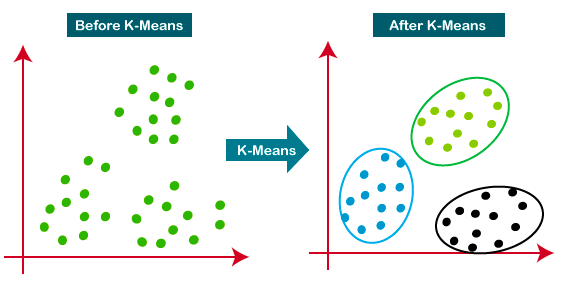
Dieses Tutorial ist eine großartige Ressource, um mehr über das K-Means-Clustering zu erfahren.
Die Hauptkomponentenanalyse (PCA) ist ein statistisches Verfahren, das verwendet wird, um die Informationen eines großen Datensatzes zusammenzufassen, indem man sie auf einen Unterraum mit niedrigerer Dimension projiziert. Sie wird auch als Dimensionalitätsreduktionstechnik bezeichnet, die dafür sorgt, dass die wesentlichen Teile der Daten mit höheren Informationen erhalten bleiben.
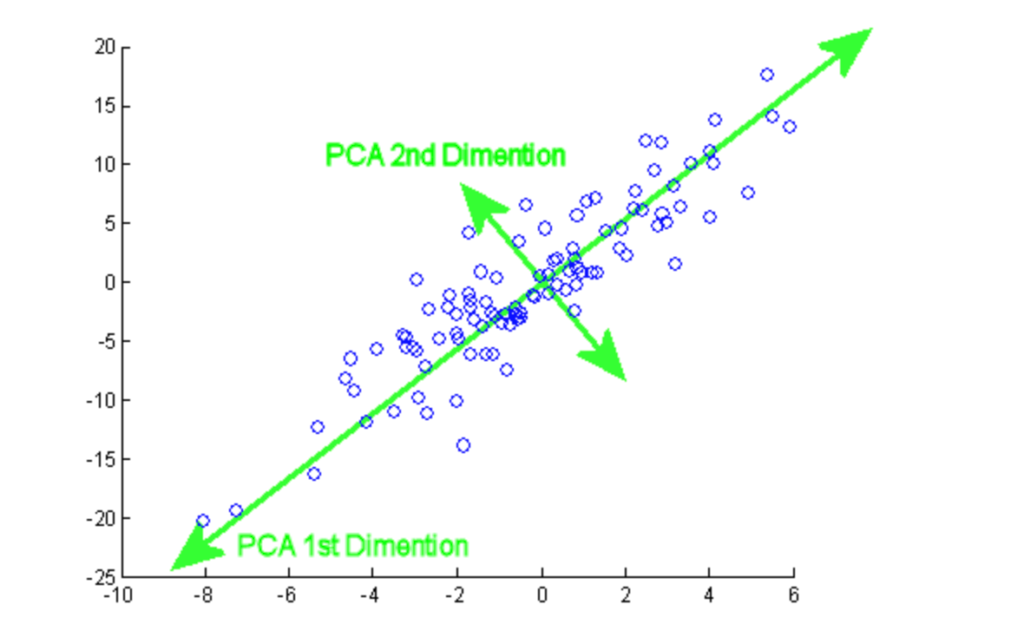
In diesem Tutorium kannst du die praktische Umsetzung der PCA an zwei beliebten Datensätzen üben: Brustkrebs und CIFAR-10.
Es handelt sich um einen Bottom-up-Ansatz, bei dem jeder Datenpunkt als eigener Cluster behandelt wird und dann die beiden nächstgelegenen Cluster iterativ zusammengeführt werden. Der größte Vorteil gegenüber dem K-Means-Clustering besteht darin, dass der Nutzer zu Beginn nicht die erwartete Anzahl von Clustern angeben muss. Sie findet Anwendung beim Clustering von Dokumenten auf Basis von Ähnlichkeit.
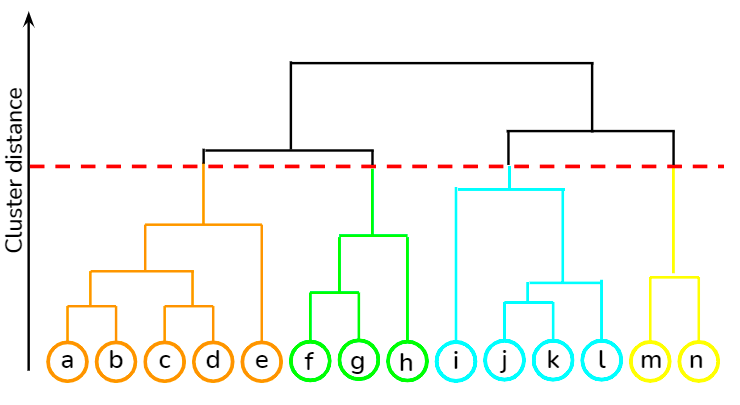
In diesem Kurs auf dem DataCamp kannst du verschiedene unüberwachte Lerntechniken wie hierarchisches Clustering und K-Means-Clustering mit der Bibliothek scipy erlernen. Außerdem lernst du in diesem Kurs, wie du Clustering-Techniken anwenden kannst, um Erkenntnisse aus unbeschrifteten Daten mit R zu gewinnen.
Es ist ein probabilistisches Modell zur Modellierung von normalverteilten Clustern in einem Datensatz. Er unterscheidet sich von den Standard-Clusteralgorithmen in dem Sinne, dass er die Wahrscheinlichkeit schätzt, dass eine Beobachtung zu einem bestimmten Cluster gehört, und dann Rückschlüsse auf die Teilpopulation zieht.
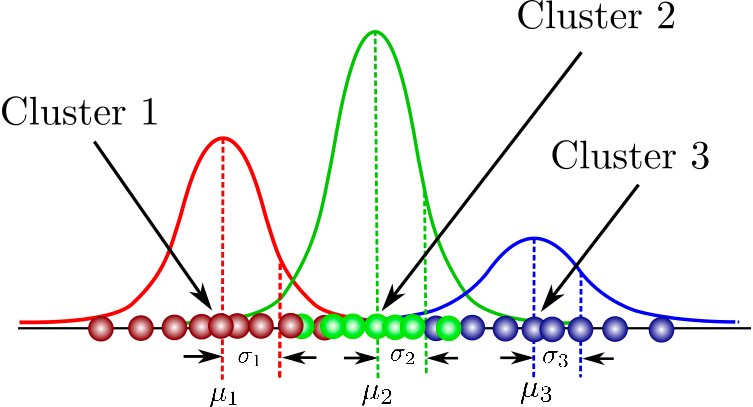
Hier findest du eine Zusammenstellung von Kursen, die die grundlegenden Konzepte des modellbasierten Clustering, die Struktur von Mixture Models und mehr abdecken. Du wirst auch die Gaußsche Mischungsmodellierung mit dem Flexmix-Paket in der Praxis üben.
Ein regelbasierter Ansatz, der das häufigste Item-Set in einem gegebenen Datensatz identifiziert, wobei das Vorwissen über die Eigenschaften häufiger Item-Sets genutzt wird. Die Warenkorbanalyse nutzt diesen Algorithmus, um Giganten wie Amazon und Netflix dabei zu helfen, die Unmengen an Informationen über ihre Nutzer/innen in einfache Regeln für Produktempfehlungen umzuwandeln. Es analysiert die Verbindungen zwischen Millionen von Produkten und deckt aufschlussreiche Regeln auf.
DataCamp bietet einen umfassenden Kurs in beiden Sprachen - Python und R- an.
Maschinelles Lernen ist nicht mehr nur ein Buzzword. Viele Unternehmen setzen maschinelle Lernmodelle ein und profitieren bereits von den Vorhersagen. Es ist überflüssig zu erwähnen, dass es auf dem Markt eine große Nachfrage nach hochqualifizierten Fachkräften für maschinelles Lernen gibt. Nachfolgend findest du eine Liste mit Ressourcen, die dir den Einstieg in die Konzepte des maschinellen Lernens erleichtern können:
Einstieg in das maschinelle Lernen
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
Laiba Siddiqui

