Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.4K
Überwachtes maschinelles Lernen ist eine Art des maschinellen Lernens, bei dem die Beziehung zwischen Eingabe und Ausgabe gelernt wird. Die Inputs werden als Merkmale oder "X-Variablen" bezeichnet und der Output wird im Allgemeinen als Ziel oder "Y-Variable" bezeichnet. Der Datentyp, der sowohl die Merkmale als auch das Ziel enthält, wird als gelabelte Daten bezeichnet. Das ist der Hauptunterschied zwischen überwachtem und unüberwachtem maschinellen Lernen, zwei wichtigen Arten des maschinellen Lernens. In diesem Lernprogramm lernst du:
Überwachtes maschinelles Lernen lernt Muster und Beziehungen zwischen Eingangs- und Ausgangsdaten. Sie wird durch die Verwendung von markierten Daten definiert. Ein markierter Datensatz ist ein Datensatz, der viele Beispiele für Merkmale und Ziele enthält. Beim überwachten Lernen werden Algorithmen verwendet, die die Beziehung zwischen Merkmalen und Ziel aus dem Datensatz lernen. Dieser Prozess wird als Ausbildung oder Anpassung bezeichnet.
Es gibt zwei Arten von überwachten Lernalgorithmen:
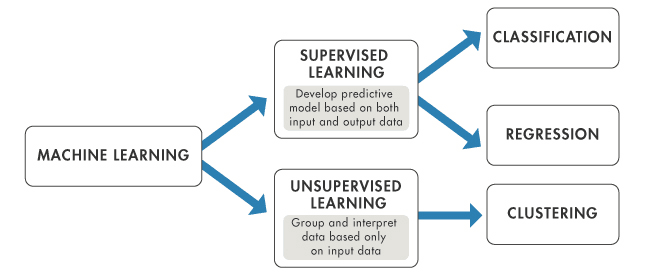
Bildquelle: https://www.mathworks.com/help/stats/machine-learning-in-matlab.html
Klassifizierung ist eine Art des überwachten maschinellen Lernens, bei dem Algorithmen aus den Daten lernen, um ein Ergebnis oder ein Ereignis in der Zukunft vorherzusagen. Zum Beispiel:
Eine Bank hat vielleicht einen Kundendatensatz mit Kreditgeschichte, Darlehen, Anlagedaten usw. und möchte wissen, ob ein Kunde in Verzug geraten wird. In den historischen Daten haben wir Merkmale und Ziel.
Klassifizierungsalgorithmen werden für die Vorhersage diskreter Ergebnisse verwendet. Wenn das Ergebnis zwei mögliche Werte annehmen kann, z. B. Wahr oder Falsch, Standard oder kein Standard, Ja oder Nein, wird es als binäre Klassifizierung bezeichnet. Wenn das Ergebnis mehr als zwei mögliche Werte enthält, spricht man von Multiklassen-Klassifikation. Es gibt viele maschinelle Lernalgorithmen, die für Klassifizierungsaufgaben verwendet werden können. Einige von ihnen sind:
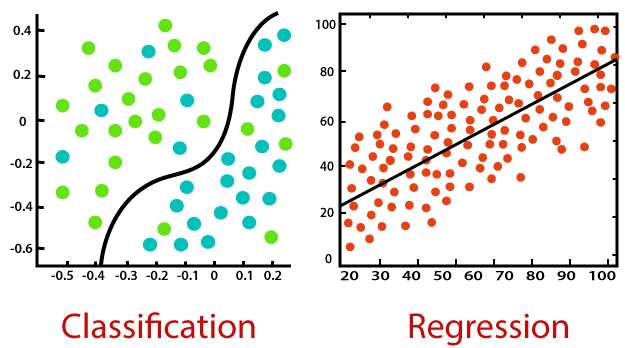
Regression ist eine Art des überwachten maschinellen Lernens, bei dem Algorithmen aus den Daten lernen, um kontinuierliche Werte wie Umsatz, Gehalt, Gewicht oder Temperatur vorherzusagen. Zum Beispiel:
Mit einem Datensatz, der Merkmale des Hauses wie Grundstücksgröße, Anzahl der Schlafzimmer, Anzahl der Bäder, Nachbarschaft usw. und den Preis des Hauses enthält, kann ein Regressionsalgorithmus trainiert werden, um die Beziehung zwischen den Merkmalen und dem Preis des Hauses zu lernen.
Es gibt viele maschinelle Lernalgorithmen, die für Regressionsaufgaben verwendet werden können. Einige von ihnen sind:
Bildquelle: https://static.javatpoint.com/tutorial/machine-learning/images/regression-vs-classification-in-machine-learning.png
Der Hauptunterschied zwischen überwachtem und unüberwachtem maschinellem Lernen besteht darin, dass beim überwachten Lernen gelabelte Daten verwendet werden. Beschriftete Daten sind Daten, die sowohl die Merkmale (X-Variablen) als auch das Ziel (y-Variable) enthalten.
Beim überwachten Lernen lernt der Algorithmus iterativ, die Zielvariable aus den Merkmalen vorherzusagen, und passt sie für die richtige Antwort an, um aus dem Trainingsdatensatz zu "lernen". Dieser Prozess wird als Ausbildung oder Anpassung bezeichnet. Modelle des überwachten Lernens liefern in der Regel genauere Ergebnisse als Modelle des unüberwachten Lernens, aber sie erfordern zu Beginn menschliche Interaktion, um die Daten richtig zu identifizieren. Wenn die Labels im Datensatz nicht richtig identifiziert werden, lernen überwachte Algorithmen die falschen Details.
Unüberwachte Lernmodelle hingegen arbeiten selbstständig, um die innere Struktur von Daten zu erkennen, die noch nicht gekennzeichnet wurden. Es ist wichtig zu bedenken, dass die Validierung der Ausgangsvariablen immer noch ein gewisses Maß an menschlichem Engagement erfordert. Ein unüberwachtes Lernmodell kann zum Beispiel feststellen, dass Kunden, die online einkaufen, dazu neigen, mehrere Artikel aus derselben Kategorie gleichzeitig zu kaufen. Ein menschlicher Analytiker müsste jedoch überprüfen, ob es für eine Empfehlungsmaschine sinnvoll ist, Artikel X mit Artikel Y zu kombinieren.
Es gibt zwei wichtige Anwendungsfälle für überwachtes Lernen: Klassifizierung und Regression. Bei beiden Aufgaben lernt ein überwachter Algorithmus aus den Trainingsdaten, um etwas vorherzusagen. Wenn die vorhergesagte Variable diskret ist, z. B. "Ja" oder "Nein", 1 oder 0, "Betrug" oder "kein Betrug", dann ist ein Klassifizierungsalgorithmus erforderlich. Wenn die vorhergesagte Variable kontinuierlich ist, z. B. Umsatz, Kosten, Gehalt, Temperatur usw., dann ist der Regressionsalgorithmus erforderlich.
Clustering und Anomalieerkennung sind zwei wichtige Anwendungsfälle des unüberwachten Lernens. Wenn du mehr über Clustering erfahren willst, schau dir diesen Artikel an. Wenn du tiefer in das unüberwachte maschinelle Lernen eintauchen möchtest, schau dir diesen interessanten Kurs von DataCamp an. Du lernst, wie du mit scikit-learn und scipy Datensätze clustern, transformieren, visualisieren und Erkenntnisse aus unmarkierten Datensätzen gewinnen kannst.
Das Ziel des überwachten Lernens ist es, die Ergebnisse für neue Daten auf der Grundlage eines Modells vorherzusagen, das aus einem markierten Trainingsdatensatz gelernt hat. Die Ergebnisse, die du erwarten kannst, sind im Voraus in Form von beschrifteten Daten bekannt. Das Ziel eines unüberwachten Lernalgorithmus ist es, Erkenntnisse aus riesigen Datenmengen ohne explizite Kennzeichnung abzuleiten. Unüberwachte Algorithmen lernen auch aus dem Trainingsdatensatz, aber die Trainingsdaten enthalten keine Labels.
Überwachtes maschinelles Lernen ist im Vergleich zum unüberwachten Lernen sehr einfach. Unüberwachte Lernmodelle benötigen in der Regel eine große Trainingsmenge, um die gewünschten Ergebnisse zu erzielen, was sie rechenintensiv macht.
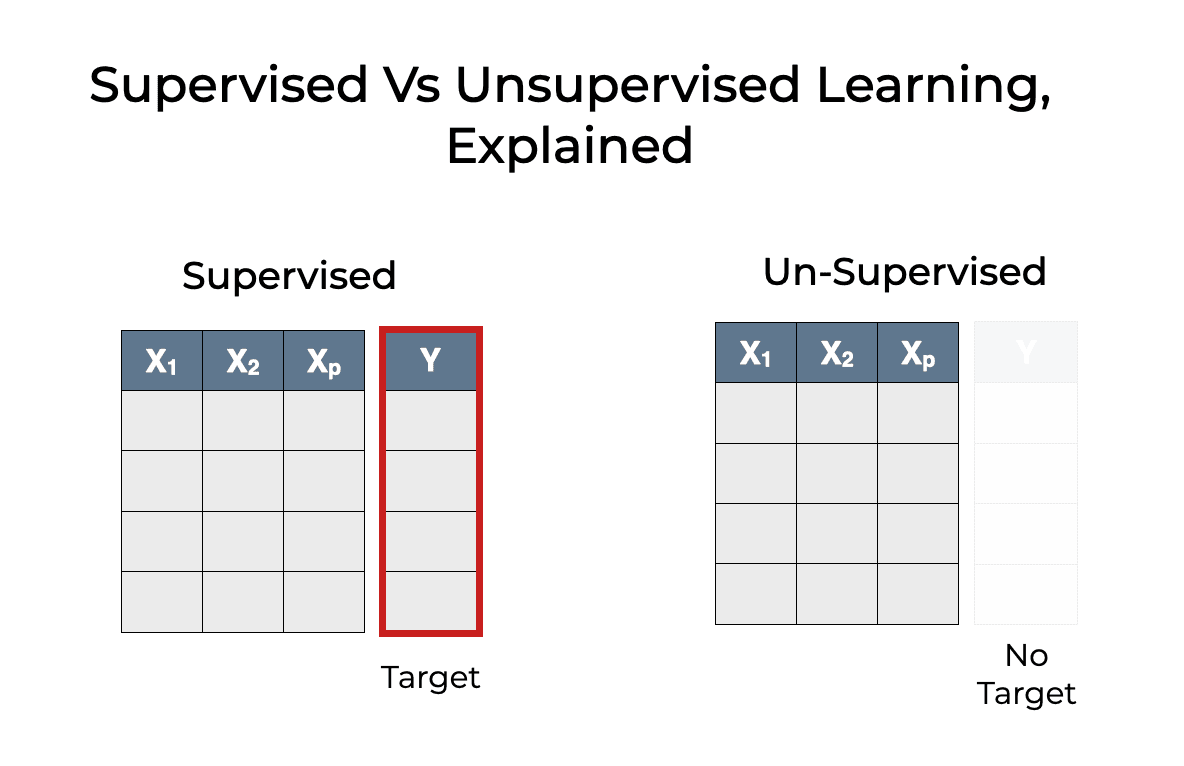
Bild Bildquelle: https://www.sharpsightlabs.com/blog/supervised-vs-unsupervised-learning/
Semi-überwachtes Lernen ist eine relativ neue und weniger populäre Art des maschinellen Lernens, bei der während des Trainings eine große Menge an unmarkierten Daten mit einer kleinen Menge an markierten Daten gemischt wird. Semi-überwachtes Lernen liegt zwischen überwachtem Lernen (mit gelabelten Trainingsdaten) und unüberwachtem Lernen (ohne gelabelte Trainingsdaten).
Semi-überwachtes Lernen bietet viele praktische Anwendungsmöglichkeiten. In vielen Bereichen gibt es einen Mangel an beschrifteten Daten. Da sie menschliche Annotatoren, spezielle Ausrüstung oder teure, zeitaufwändige Studien erfordern, kann es schwierig sein, die Labels (Zielvariable) zu erhalten.
Beim halbüberwachten Lernen gibt es zwei Arten:
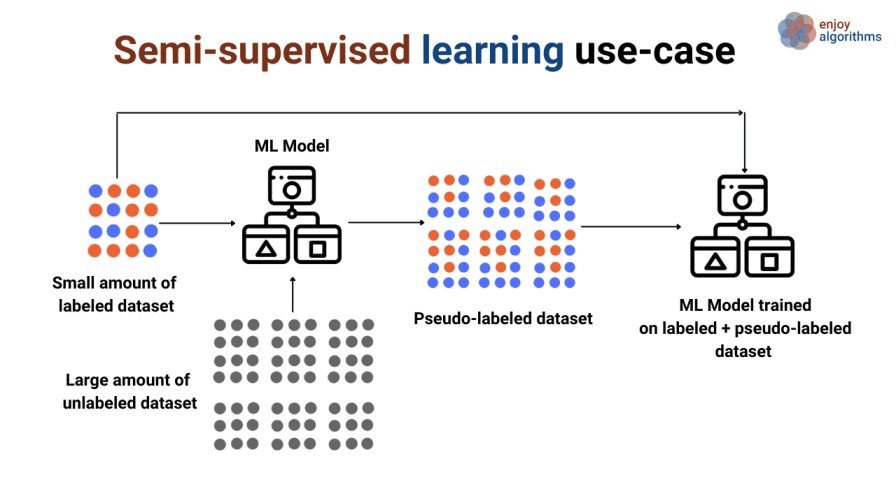
Bildquelle: https://www.enjoyalgorithms.com/blogs/supervised-unsupervised-and-semisupervised-learning
In diesem Abschnitt werden wir einige gängige Algorithmen für überwachtes maschinelles Lernen behandeln:
Die lineare Regression ist einer der einfachsten Algorithmen für maschinelles Lernen. Sie wird verwendet, um zu lernen, einen kontinuierlichen Wert (abhängige Variable) auf der Grundlage der Merkmale (unabhängige Variable) im Trainingsdatensatz vorherzusagen. Der Wert der abhängigen Variable, die die Wirkung darstellt, wird durch Veränderungen im Wert der unabhängigen Variable beeinflusst.
Wenn du dich an die "Linie der besten Anpassung" aus deiner Schulzeit erinnerst, ist das genau das, was die lineare Regression ist. Die Vorhersage des Gewichts einer Person auf der Grundlage ihrer Größe ist ein einfaches Beispiel für dieses Konzept.
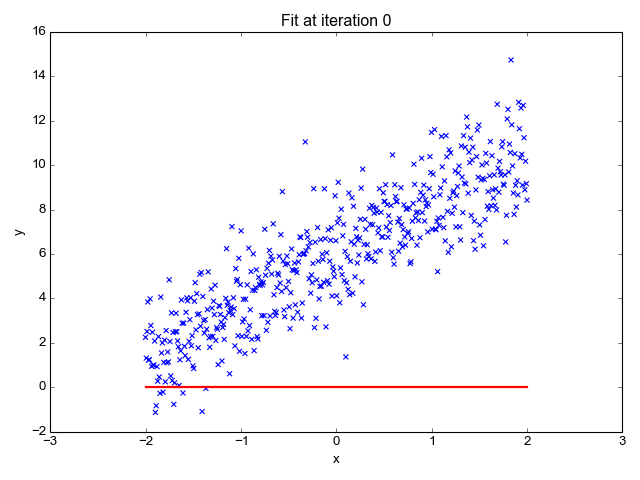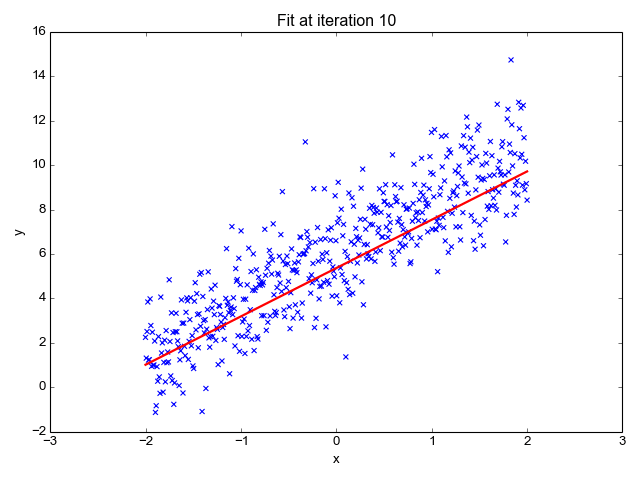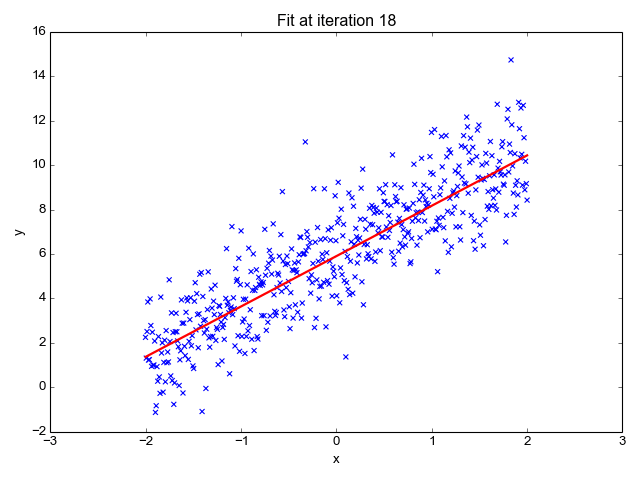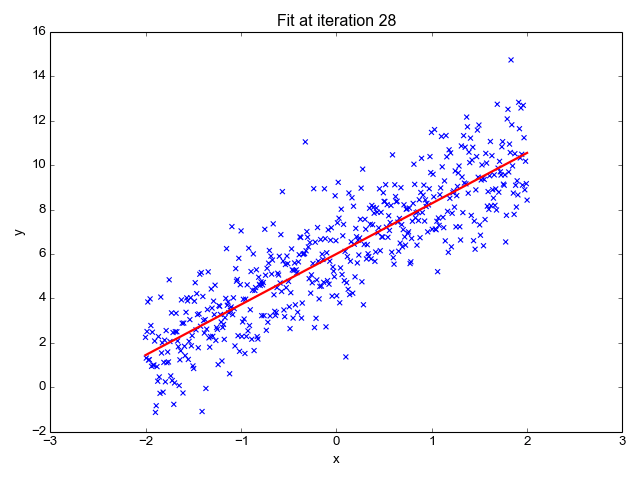
Bildquelle: http://primo.ai/index.php?title=Linear_Regression
|
PROS |
CONS |
|
Einfach, leicht zu verstehen und zu interpretieren |
Leicht zu überrüsten |
|
Außergewöhnlich gute Leistung bei linear trennbaren Daten |
Setzt eine Linearität zwischen Merkmalen und Zielvariable voraus. |
Die logistische Regression ist ein Spezialfall der linearen Regression, bei der die Zielvariable (y) diskret / kategorisch ist, z. B. 1 oder 0, Wahr oder Falsch, Ja oder Nein, Standard oder kein Standard. Als abhängige Variable wird ein Logarithmus der Quoten verwendet. Mithilfe einer Logit-Funktion macht die logistische Regression Vorhersagen über die Wahrscheinlichkeit, dass ein binäres Ereignis eintritt.
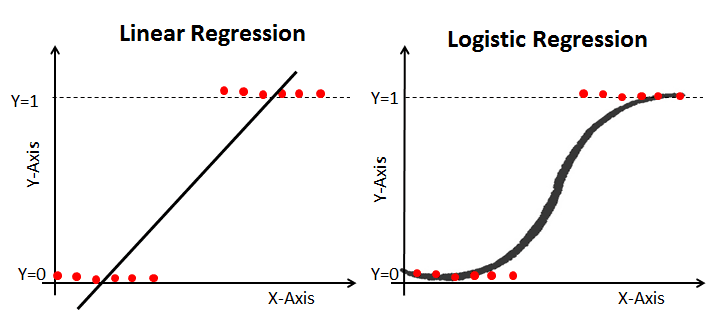
Wenn du mehr über dieses Thema erfahren möchtest, schau dir den hervorragenden Artikel Understanding Logistic Regression in Python Tutorial auf DataCamp an.
|
PROS |
CONS |
|
Einfach, leicht zu verstehen und zu interpretieren |
Überanpassung |
|
Gut kalibriert für Ausgangswahrscheinlichkeiten |
Schwierigkeiten beim Erfassen komplexer Beziehungen haben |
Entscheidungsbaum-Algorithmen sind eine Art Wahrscheinlichkeitsbaum-ähnliches Strukturmodell, das Daten fortlaufend trennt, um je nach den Ergebnissen der vorangegangenen Fragen eine Kategorisierung oder Vorhersage zu treffen. Das Modell analysiert die Daten und gibt Antworten auf die Fragen, um dir dabei zu helfen, fundiertere Entscheidungen zu treffen.
Du könntest zum Beispiel einen Entscheidungsbaum verwenden, in dem die Antworten Ja oder Nein verwendet werden, um eine bestimmte Vogelart auszuwählen, basierend auf Datenelementen wie dem Gefieder des Vogels, seiner Fähigkeit zu fliegen oder zu schwimmen, der Art seines Schnabels und so weiter.
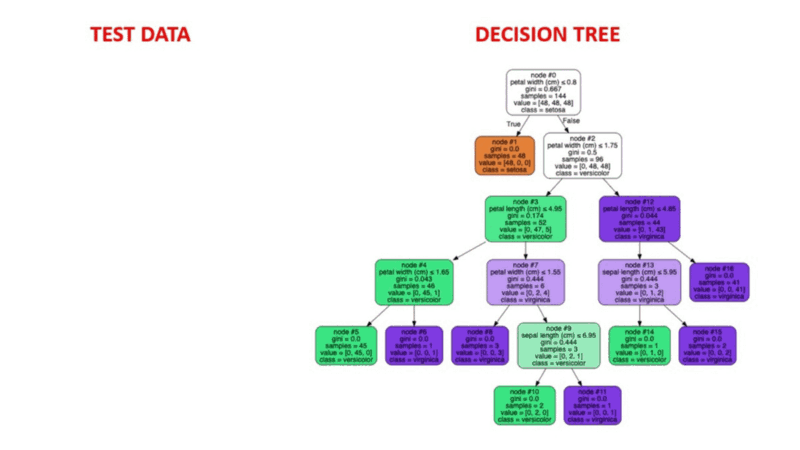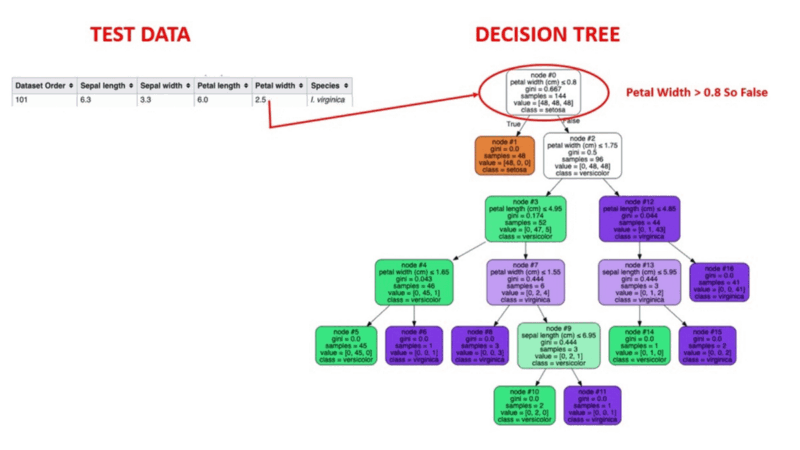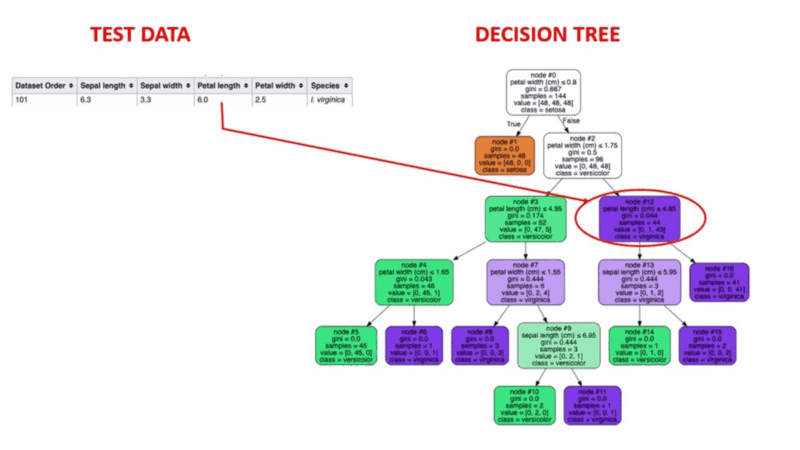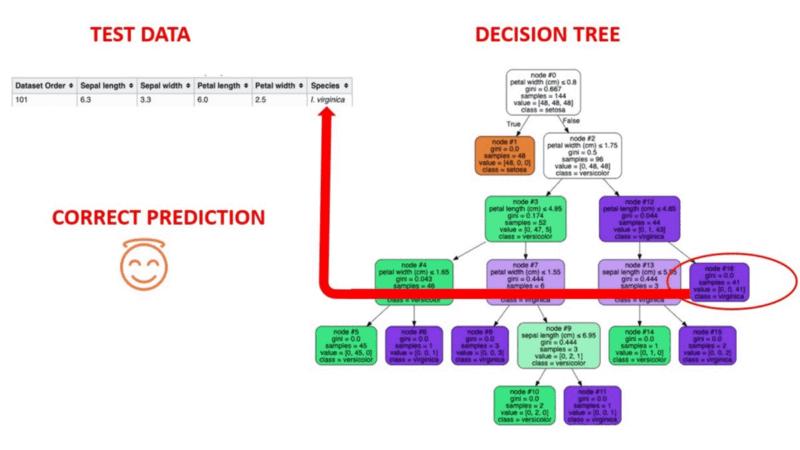
Image Source: https://aigraduate.com/decision-tree-visualisation---quick-ml-tutorial-for-beginners/
|
PROS |
CONS |
|
Sehr intuitiv und leicht zu erklären |
Instabil - eine kleine Änderung der Trainingsdaten kann zu großen Unterschieden in der Vorhersage führen. |
|
Entscheidungsbäume erfordern nicht so viel Datenaufbereitung wie einige lineare Modelle. |
Anfällig für Überanpassung |
Um mehr über maschinelles Lernen mit baumbasierten Modellen in Python zu erfahren, schau dir diesen interessanten Kurs von DataCamp an. In diesem Kurs lernst du, wie du baumbasierte Modelle und Ensembles für Regression und Klassifizierung mit Scikit-Learn verwendest.
K-Nächste Nachbarn ist eine statistische Methode, die die Nähe eines Datenpunkts zu einem anderen Datenpunkt auswertet, um zu entscheiden, ob die beiden Datenpunkte zu einer Gruppe zusammengefasst werden können oder nicht. Die Nähe der Datenpunkte zeigt an, inwieweit sie miteinander vergleichbar sind.
Nehmen wir zum Beispiel an, wir hätten ein Diagramm mit zwei verschiedenen Gruppen von Datenpunkten, die sich in unmittelbarer Nähe zueinander befinden und jeweils Gruppe A und Gruppe B heißen. Jede dieser Gruppen von Datenpunkten würde durch einen Punkt auf dem Diagramm dargestellt werden. Wenn wir einen neuen Datenpunkt hinzufügen, hängt die Gruppe dieser Instanz davon ab, welcher Gruppe der neue Punkt näher ist.
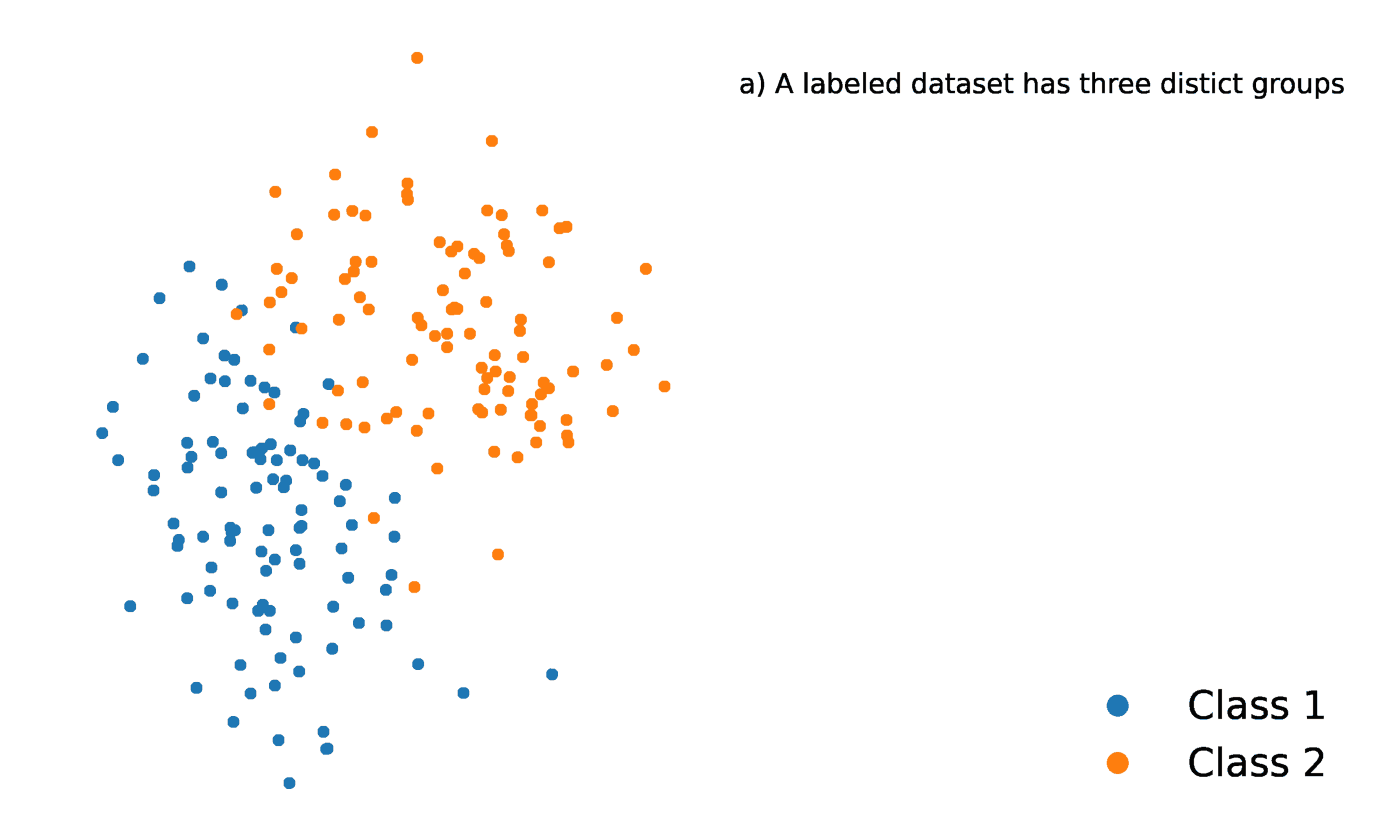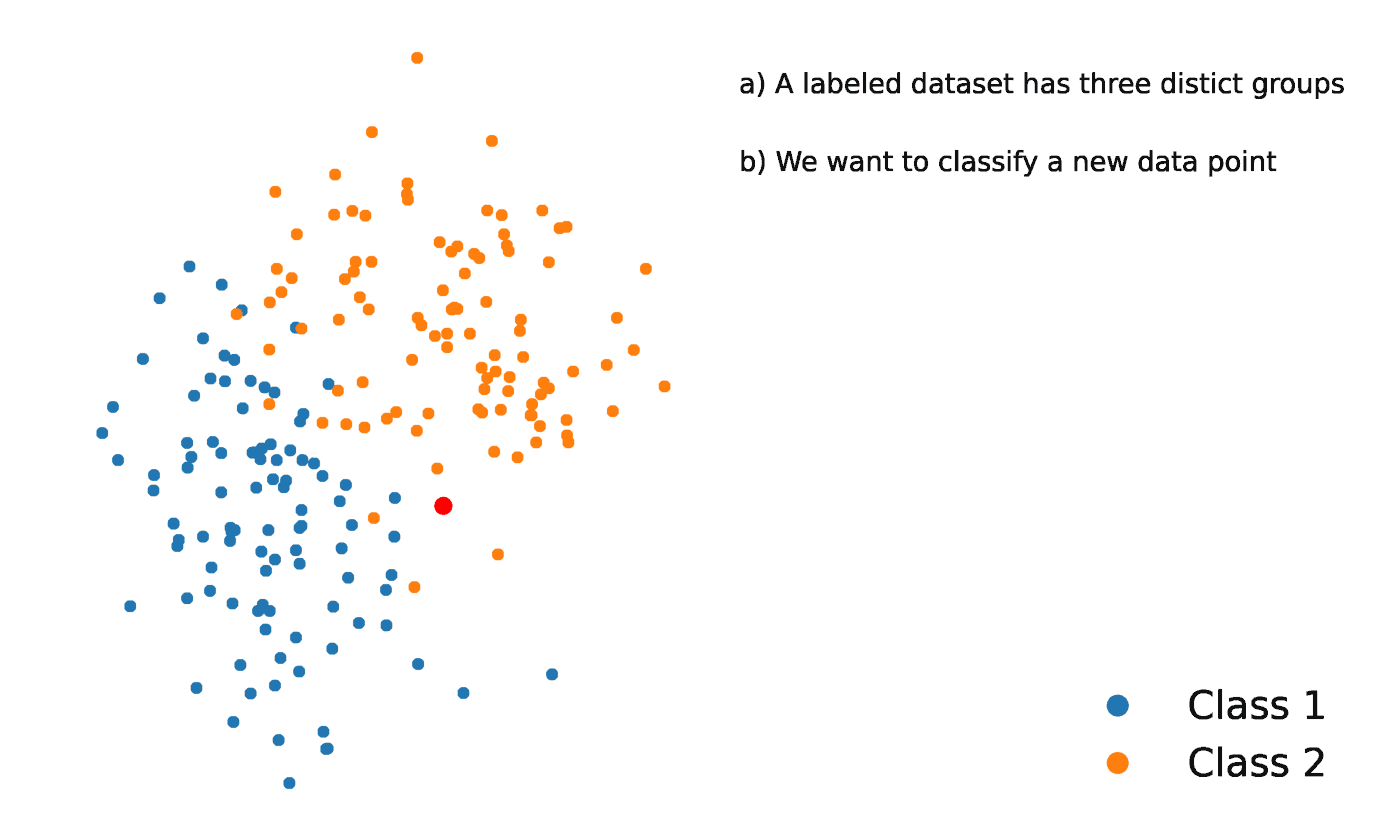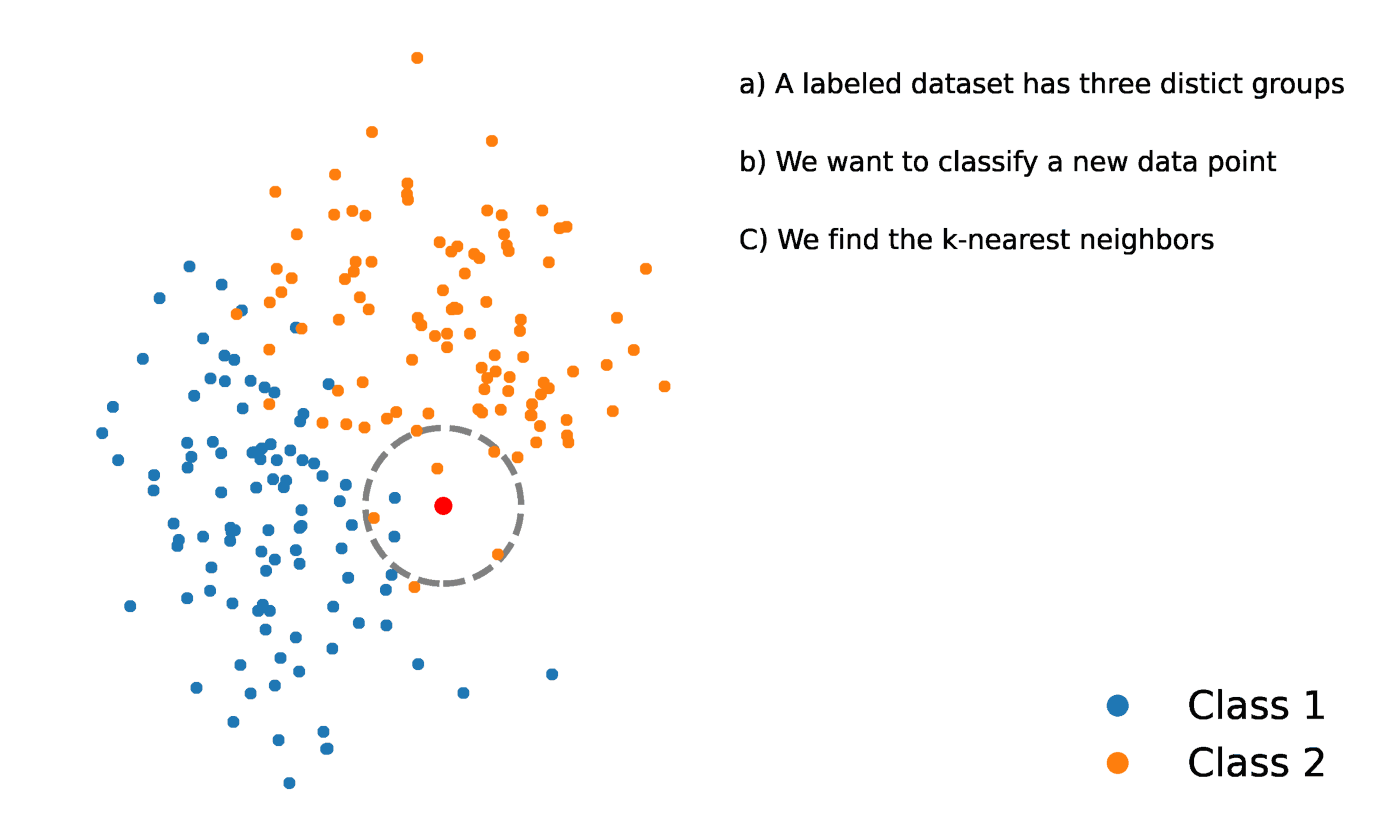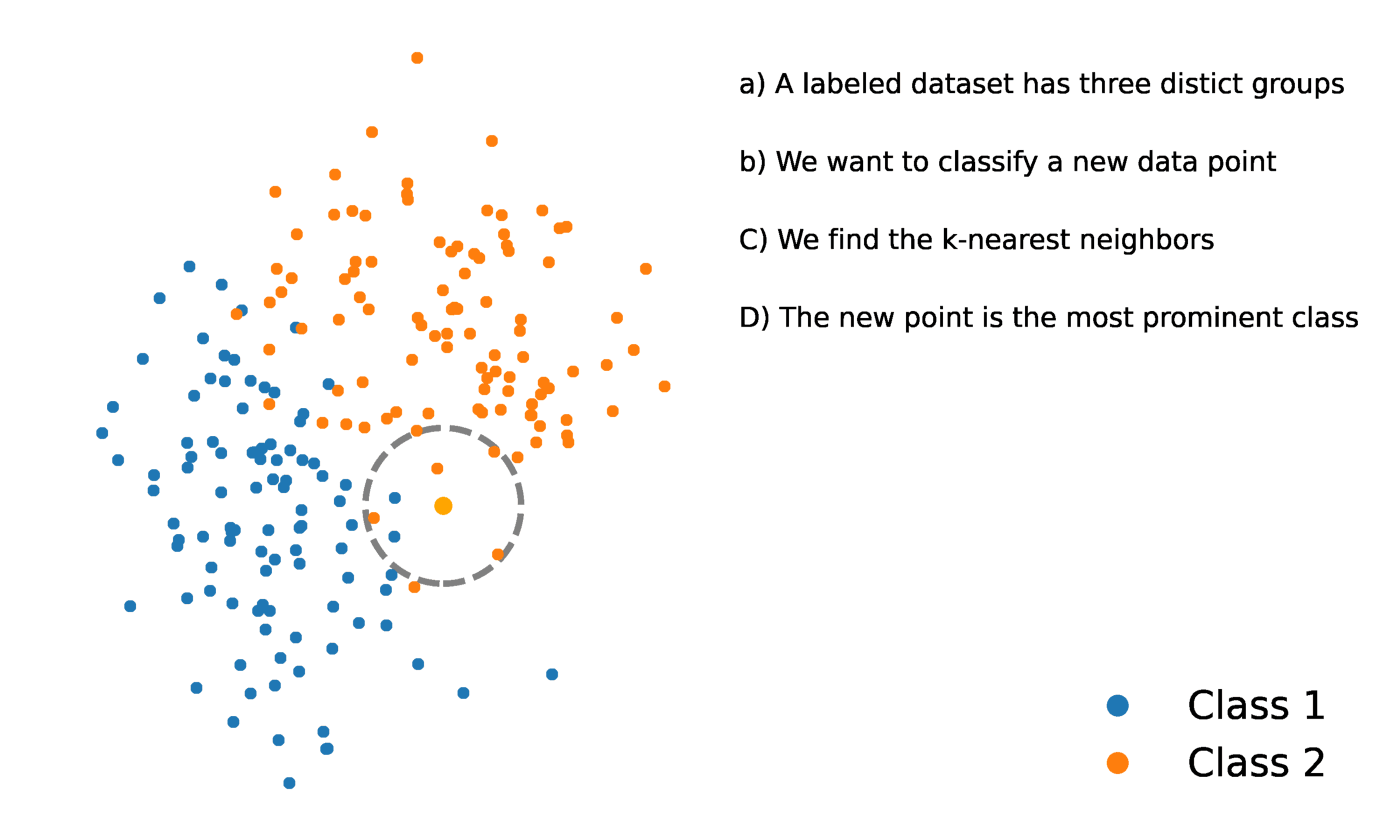
Quelle: https://towardsdatascience.com/getting-acquainted-with-k-nearest-neighbors-ba0a9ecf354f
|
PROS |
CONS |
|
Macht keine Annahmen über die Daten |
Die Ausbildung nimmt viel Zeit in Anspruch |
|
Intuitiv und einfach |
KNN funktioniert gut mit einer kleinen Anzahl von Merkmalen, aber wenn die Anzahl der Merkmale wächst, hat es Schwierigkeiten, genaue Vorhersagen zu treffen. |
Random Forest ist ein weiteres Beispiel für einen Algorithmus, der genau wie die Entscheidungsbäume auf Bäumen basiert. Im Gegensatz zum Entscheidungsbaum, der nur aus einem einzigen Baum besteht, verwendet der Random Forest eine Reihe von Entscheidungsbäumen, um Urteile zu fällen, so dass im Grunde ein Wald von Bäumen entsteht.
Dabei werden verschiedene Modelle kombiniert, um Vorhersagen zu treffen, und es kann sowohl für die Klassifizierung als auch für die Regression verwendet werden.
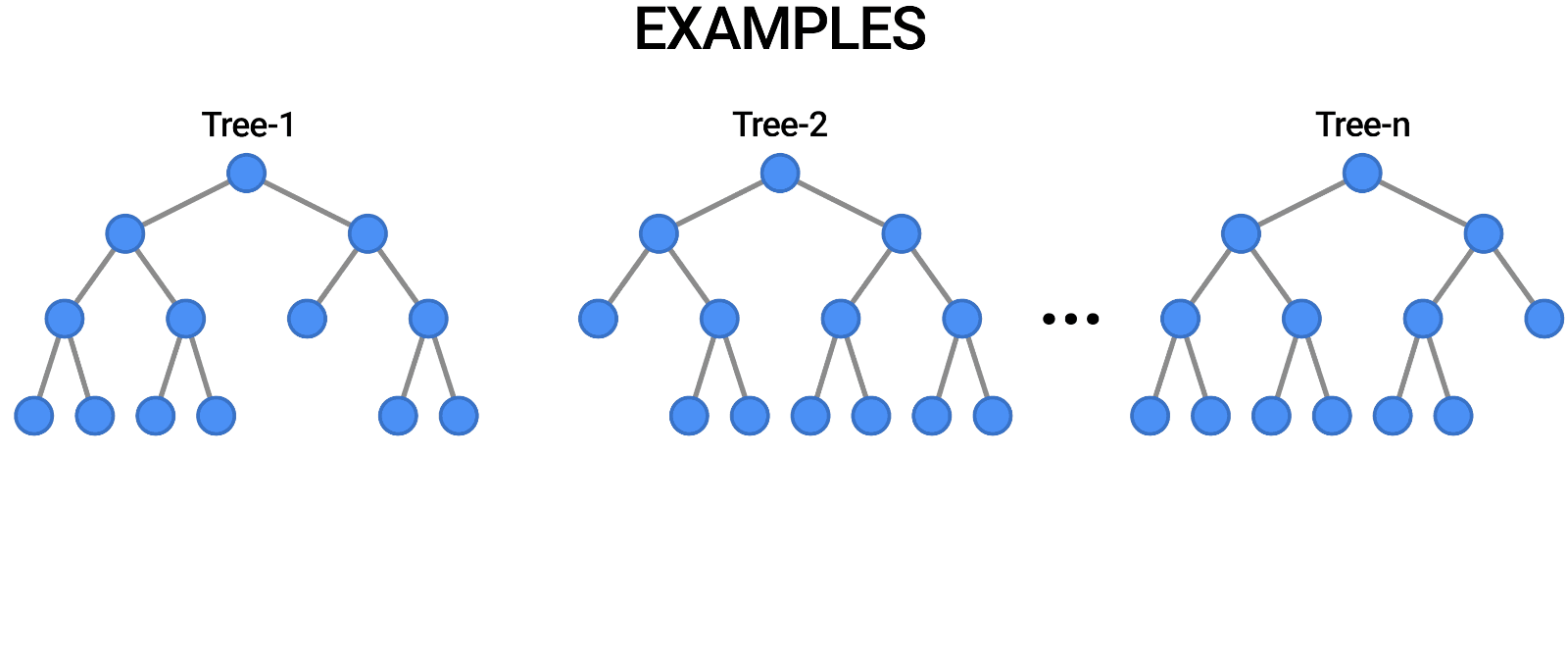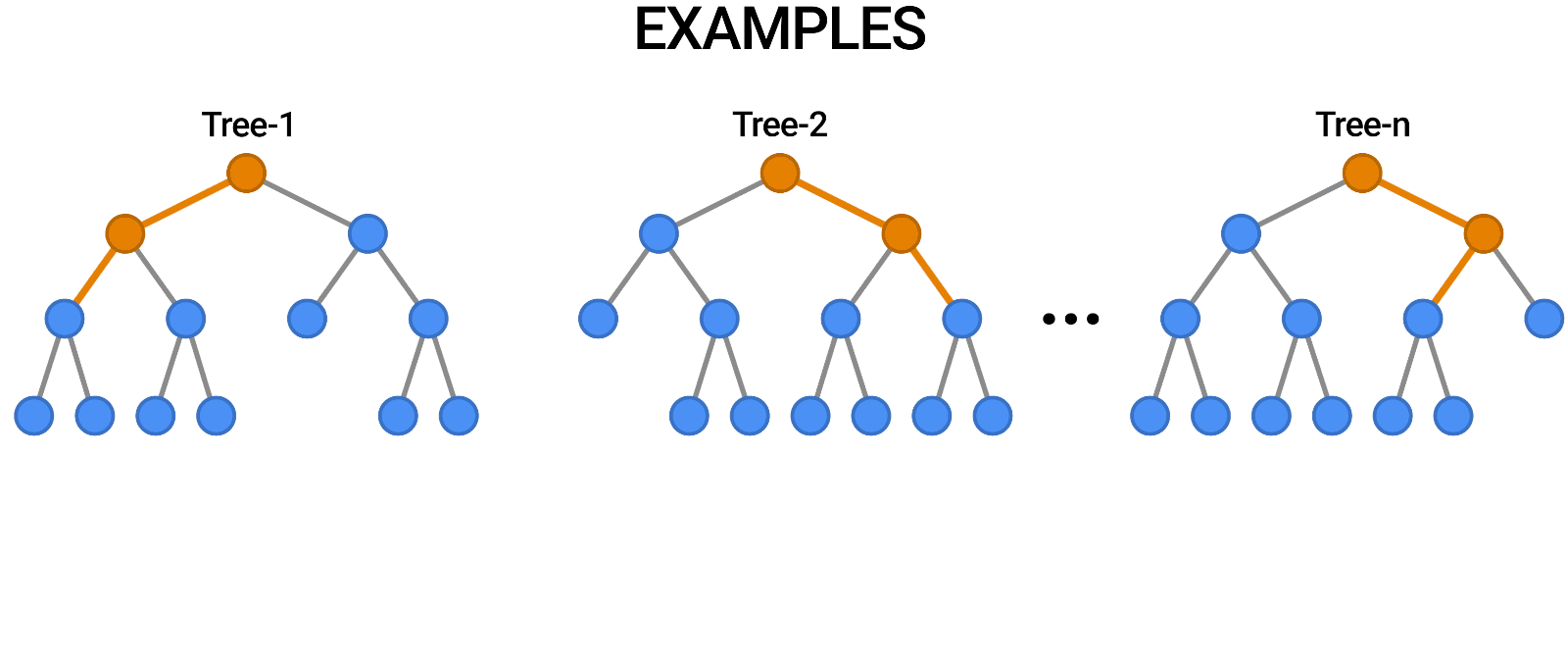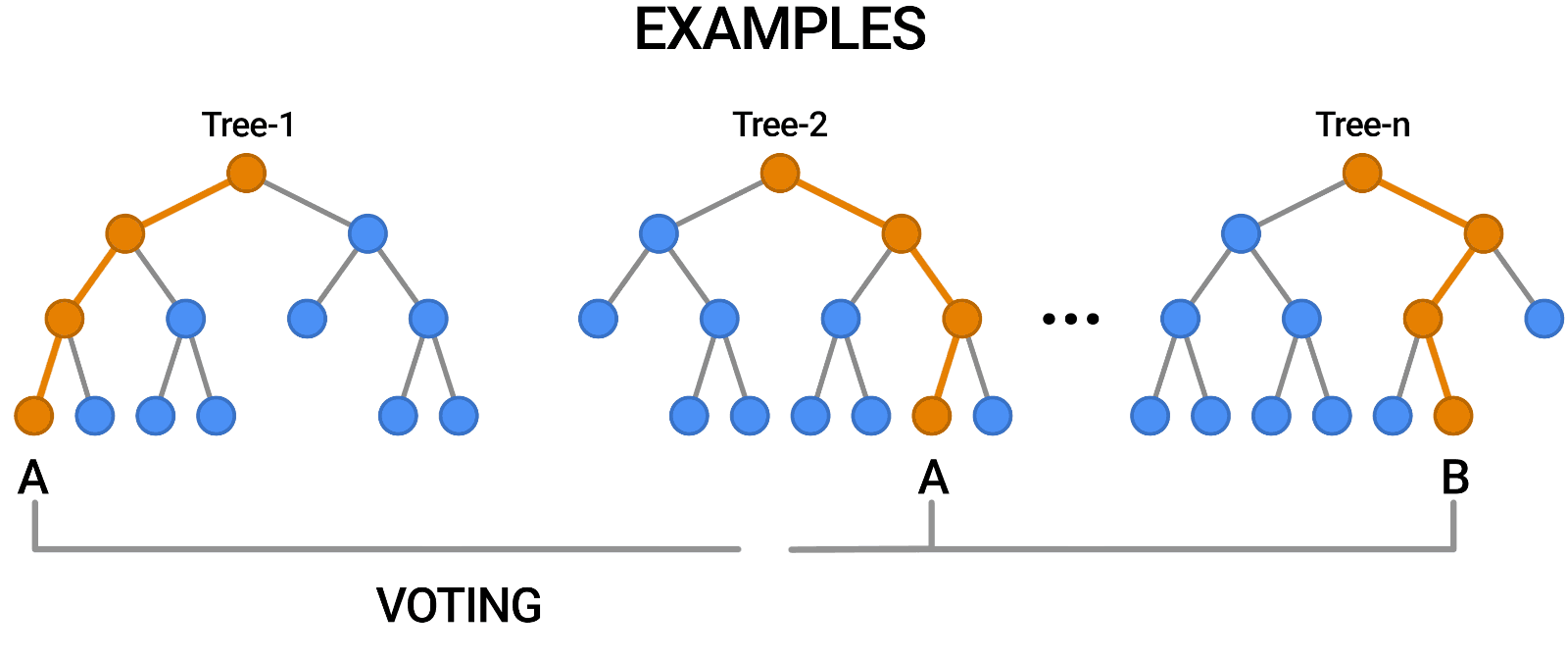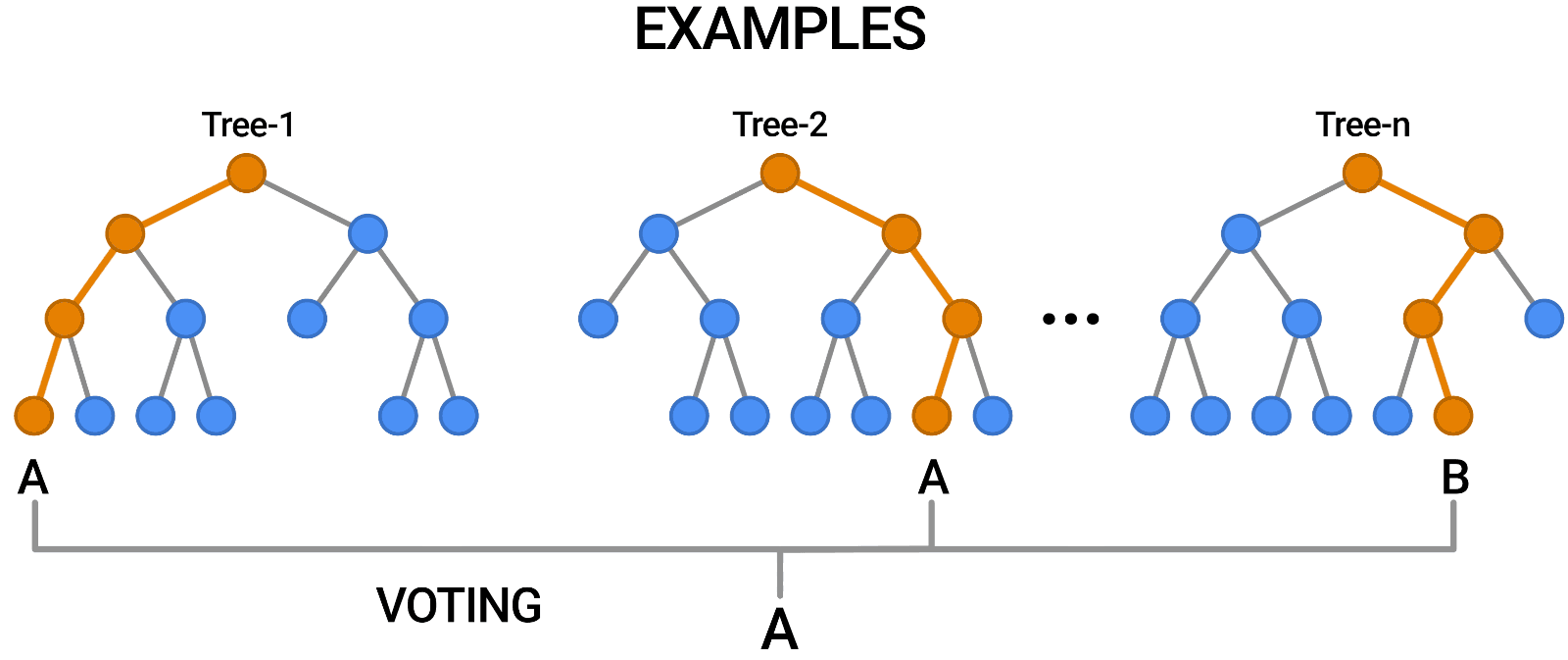
Source: https://blog.tensorflow.org/2021/05/introducing-tensorflow-decision-forests.html
|
PROS |
CONS |
|
Random Forests können nicht-lineare Beziehungen in den Daten leicht verarbeiten. |
Schwierig zu interpretieren, weil es mehrere Bäume gibt. |
|
Random Forests führen implizit eine Merkmalsauswahl durch |
Random Forests sind bei großen Datensätzen sehr rechenintensiv. |
Das Bayes-Theorem ist eine mathematische Formel, die zur Berechnung bedingter Wahrscheinlichkeiten verwendet wird, und Naive Bayes ist eine Anwendung dieser Formel. Die Wahrscheinlichkeit, dass ein Ergebnis eintritt, wenn ein anderes Ereignis bereits eingetreten ist, wird als bedingte Wahrscheinlichkeit bezeichnet.
Sie macht die Vorhersage, dass die Wahrscheinlichkeiten für jede Klasse zu einer bestimmten Klasse gehören und dass die Klasse mit der höchsten Wahrscheinlichkeit diejenige ist, die als diejenige gilt, die am wahrscheinlichsten auftritt.
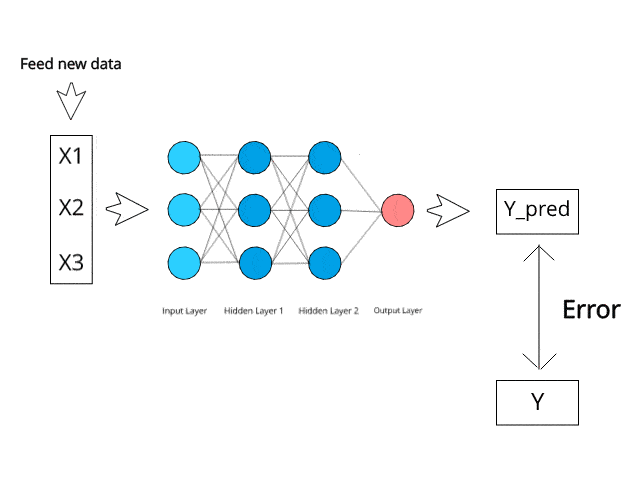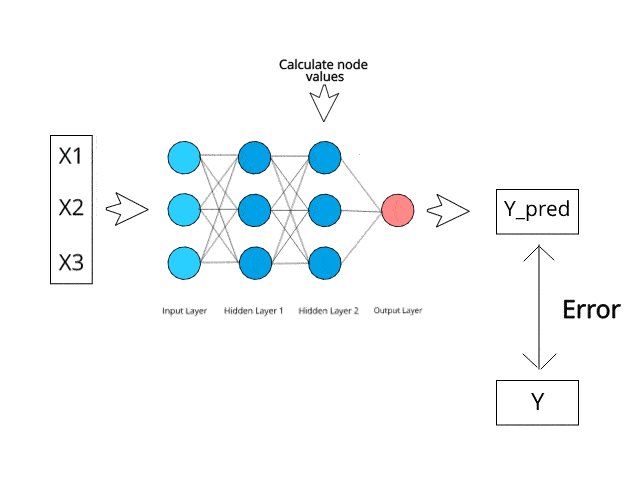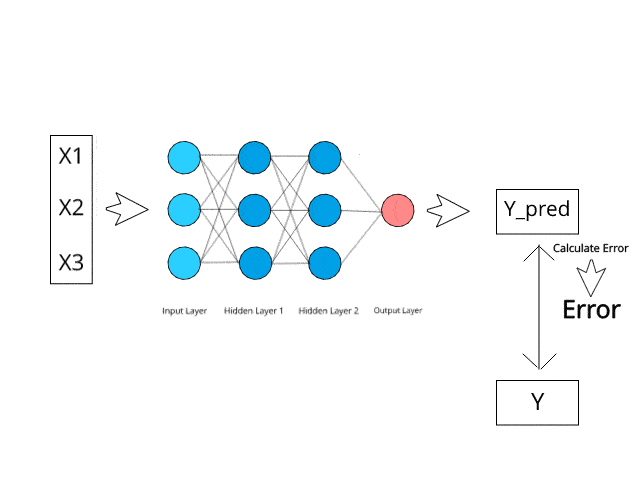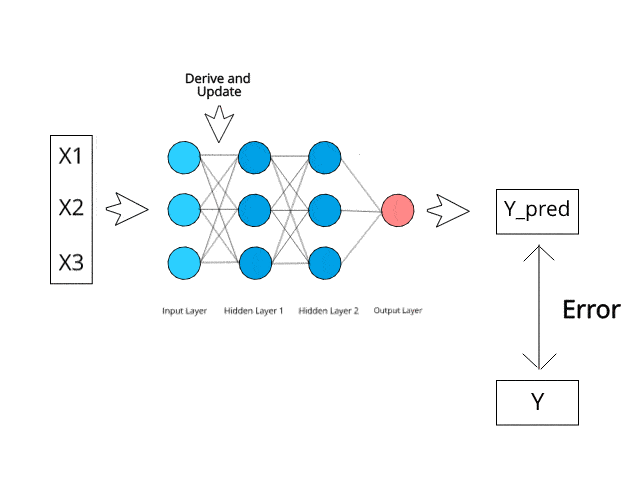
Image Source: https://www.kdnuggets.com/2019/10/introduction-artificial-neural-networks.html
|
PROS |
CONS |
|
Der Algorithmus ist sehr schnell. |
Sie geht davon aus, dass alle Merkmale unabhängig sind. |
|
Es ist einfach und leicht zu implementieren |
Der Algorithmus stößt auf das "Null-Häufigkeits-Problem", bei dem er eine kategoriale Variable mit Null-Wahrscheinlichkeit vergibt, wenn ihre Kategorie im Trainingsdatensatz nicht vorhanden war. |
In diesem Teil werden wir scikit-learn in Python verwenden, um ein logistisches Regressionsmodell (Klassifizierung) auf einem gefälschten Datensatz zu trainieren. Schau dir das komplette Notizbuch hier an.
```
# create fake binary classification dataset with 1000 rows and 10 features
from sklearn.datasets import make_classification
X, y = make_classification(n_samples = 1000, n_features = 10, n_classes = 2)
# check shape of X and y
X.shape, y.shape
# train test split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# import and initialize logistic regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
# fit logistic regression model
lr.fit(X_train, y_train)
# generate hard predictions on test set
y_pred = lr.predict(X_test)
y_pred
# evaluate accuracy score of the model
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
```Wenn du das überwachte maschinelle Lernen in R lernen möchtest, dann schau dir den Kurs Supervised Learning in R von DataCamp an. In diesem Kurs lernst du die Grundlagen des maschinellen Lernens zur Klassifizierung in der Programmiersprache R kennen.
Maschinelles Lernen hat die Art und Weise, wie wir Geschäfte machen, in den letzten Jahren völlig verändert. Eine radikale Neuerung, die das maschinelle Lernen von anderen Automatisierungsstrategien unterscheidet, ist die Abkehr von der regelbasierten Programmierung. Dank überwachter maschineller Lerntechniken können Ingenieurinnen und Ingenieure Daten nutzen, ohne die Maschinen explizit darauf zu trainieren, Probleme auf eine bestimmte Weise zu lösen.
Beim überwachten maschinellen Lernen ist die erwartete Lösung eines Problems für zukünftige Daten vielleicht nicht bekannt, aber sie kann bekannt und in einem historischen Datensatz erfasst sein, und die Aufgabe der Algorithmen des überwachten Lernens ist es, diese Beziehung aus historischen Daten zu lernen, um ein Ergebnis, ein Ereignis oder einen Wert in der Zukunft vorherzusagen.
In diesem Artikel haben wir ein grundlegendes Verständnis dafür entwickelt, was überwachtes Lernen ist und wie es sich vom unüberwachten Lernen unterscheidet. Wir haben uns auch einige gängige Algorithmen des überwachten Lernens angesehen. Es gibt jedoch viele Dinge, über die wir noch nicht gesprochen haben, wie z.B. die Modellevaluation, die Kreuzvalidierung oder das Hyperparameter-Tuning. Wenn du tiefer in eines dieser Themen einsteigen und deine Fähigkeiten weiter ausbauen möchtest, schau dir diese interessanten Kurse an:
Kurse für Maschinelles Lernen
Kurs
Kurs
Kurs