
Unüberwachtes Lernen, eine grundlegende Form des maschinellen Lernens, entwickelt sich ständig weiter. Dieser Ansatz, der sich auf Eingangsvektoren ohne entsprechende Zielwerte konzentriert, hat bemerkenswerte Entwicklungen in seiner Fähigkeit erlebt, Informationen auf der Grundlage von Ähnlichkeiten, Mustern und Unterschieden zu gruppieren und zu interpretieren. Die jüngsten Fortschritte bei tiefen, unüberwachten Lernmodellen haben diese Fähigkeit verbessert und ermöglichen ein differenzierteres Verständnis komplexer Datensätze.
Im Jahr 2024 sind Algorithmen für unüberwachtes Lernen, die traditionell nicht auf Input-Output-Mappings angewiesen sind, noch autonomer und effizienter bei der Entdeckung der zugrundeliegenden Strukturen von unbeschrifteten Daten geworden. Diese Unabhängigkeit von einem "Lehrer" wurde durch das Aufkommen ausgefeilter selbstüberwachterLerntechniken gestärkt, die die Abhängigkeit von gelabelten Daten deutlich verringern.
Außerdem hat das Feld Fortschritte bei der Integration von unüberwachtem Lernen mit anderen KI-Disziplinen gemacht, wie z.B. dem Verstärkungslernen, was zu anpassungsfähigeren und intelligenteren Systemen führt. Diese Systeme zeichnen sich durch die Erkennung von Mustern und Anomalien in Daten aus und ebnen den Weg für innovative Anwendungen in verschiedenen Sektoren. In diesem Artikel werden die verschiedenen Arten des unüberwachten Lernens und ihre Einsatzmöglichkeiten näher erläutert.
Überwachtes vs. unüberwachtes Lernen
In der folgenden Tabelle haben wir einige der wichtigsten Unterschiede zwischen unüberwachtem und überwachtem Lernen verglichen:
|
Überwachtes Lernen |
Unüberwachtes Lernen |
|
|
Zielsetzung |
Annäherung an eine Funktion, die Eingaben auf Ausgaben abbildet, anhand von Beispiel-Eingabe-Ausgabe-Paaren. |
Eine übersichtliche Darstellung der Daten erstellen und daraus fantasievolle Inhalte generieren. |
|
Genauigkeit |
Äußerst genau und zuverlässig. |
Weniger genau und zuverlässig. |
|
Komplexität |
Einfachere Methode. |
Computergestützt komplex. |
|
Klassen |
Die Anzahl der Klassen ist bekannt. |
Die Anzahl der Klassen ist unbekannt. |
|
Ausgabe |
Ein gewünschter Ausgangswert (auch Überwachungssignal genannt). |
Keine entsprechenden Ausgangswerte. |
Arten des unüberwachten Lernens
In der Einleitung haben wir erwähnt, dass unüberwachtes Lernen eine Methode ist, mit der wir Daten gruppieren, wenn keine Labels vorhanden sind. Da keine Kennzeichnungen vorhanden sind, werden in der Regel unüberwachte Lernmethoden eingesetzt, um eine prägnante Darstellung der Daten zu erstellen, damit wir daraus fantasievolle Inhalte ableiten können.
Wenn wir zum Beispiel ein neues Produkt auf den Markt bringen, können wir mit Methoden des unüberwachten Lernens herausfinden, wer der Zielmarkt für das neue Produkt sein wird: Denn es gibt keine historischen Informationen darüber, wer der Zielkunde ist und welche demografischen Merkmale er hat.
Unüberwachtes Lernen lässt sich jedoch in drei Hauptaufgaben unterteilen:
- Clustering
- Assoziationsregeln
- Dimensionalitätsreduktion.
Lass uns jede einzelne davon näher betrachten:
Clustering
Aus theoretischer Sicht haben Instanzen innerhalb derselben Gruppe tendenziell ähnliche Eigenschaften. Du kannst dieses Phänomen im Periodensystem beobachten. Mitglieder derselben Gruppe, die durch achtzehn Spalten voneinander getrennt sind, haben die gleiche Anzahl von Elektronen in den äußersten Schalen ihrer Atome und bilden Bindungen desselben Typs.
Das ist die Idee, die bei Clustering-Algorithmen im Spiel ist. Bei Clustering-Methoden werden unmarkierte Daten auf der Grundlage ihrer Ähnlichkeiten und Unterschiede gruppiert. Wenn zwei Instanzen in verschiedenen Gruppen auftauchen, können wir daraus schließen, dass sie unterschiedliche Eigenschaften haben.
Clustering ist eine beliebte Methode des unüberwachten Lernens. Du kannst es sogar noch weiter in verschiedene Arten von Clustern unterteilen, zum Beispiel:
- Exklusive Clustering: Die Daten werden so gruppiert, dass ein einzelner Datenpunkt ausschließlich zu einem Cluster gehört.
- Überlappendes Clustering: Ein Soft-Cluster, bei dem ein einzelner Datenpunkt zu mehreren Clustern mit unterschiedlichen Zugehörigkeitsgraden gehören kann.
- Hierarchisches Clustering: Eine Art von Clustering, bei dem Gruppen so erstellt werden, dass ähnliche Instanzen in derselben Gruppe und unterschiedliche Objekte in anderen Gruppen sind.
- Probalistisches Clustering: Cluster werden mithilfe einer Wahrscheinlichkeitsverteilung erstellt.
Association Rule Mining
Diese Art des unüberwachten maschinellen Lernens verfolgt einen regelbasierten Ansatz, um interessante Beziehungen zwischen Merkmalen in einem bestimmten Datensatz zu entdecken. Dabei wird ein Maß von Interesse verwendet, um starke Regeln in einem Datensatz zu identifizieren.
Typischerweise wird Assoziationsregel-Mining für Warenkorbanalysen verwendet: Dies ist eine Data-Mining-Technik, die Einzelhändler nutzen, um ein besseres Verständnis des Kaufverhaltens ihrer Kunden auf der Grundlage der Beziehungen zwischen verschiedenen Produkten zu erhalten.
Der am häufigsten verwendete Algorithmus für das Lernen von Assoziationsregeln ist der Apriori-Algorithmus. Für diese Art des unüberwachten Lernens werden jedoch auch andere Algorithmen verwendet, wie z. B. der Eclat- und der FP-Growth-Algorithmus.
Dimensionalitätsreduktion
Beliebte Algorithmen zur Dimensionalitätsreduktion sind die Hauptkomponentenanalyse (PCA) und die Singulärwertzerlegung (SVD). Diese Algorithmen versuchen, Daten aus hochdimensionalen Räumen in niedrigdimensionale Räume umzuwandeln, ohne dass dabei aussagekräftige Eigenschaften der ursprünglichen Daten beeinträchtigt werden. Diese Techniken werden in der Regel bei der explorativen Datenanalyse (EDA) oder der Datenverarbeitung eingesetzt, um die Daten für die Modellierung vorzubereiten.
Es ist hilfreich, die Dimensionalität eines Datensatzes während der EDA zu reduzieren, um die Visualisierung der Daten zu erleichtern: Denn die Visualisierung von Daten in mehr als drei Dimensionen ist schwierig. Aus Sicht der Datenverarbeitung vereinfacht die Reduzierung der Dimensionalität der Daten das Modellierungsproblem.
Wenn mehr Eingangsmerkmale in das Modell eingespeist werden, muss das Modell eine komplexere Näherungsfunktion lernen. Dieses Phänomen lässt sich mit einem Sprichwort zusammenfassen, das als "Fluch der Dimensionalität" bezeichnet wird.
Unüberwachtes Lernen Anwendungen
Die meisten Führungskräfte hätten kein Problem damit, Anwendungsfälle für überwachte maschinelle Lernaufgaben zu identifizieren; dasselbe gilt jedoch nicht für unüberwachtes Lernen.
Ein Grund dafür könnte in der einfachen Natur des Risikos liegen. Unüberwachtes Lernen birgt viel mehr Risiken als unüberwachtes Lernen, da es keine eindeutige Möglichkeit gibt, die Ergebnisse offline an der Grundwahrheit zu messen, und es zu riskant sein kann, eine Online-Evaluation durchzuführen.
Dennoch gibt es mehrere wertvolle Anwendungsfälle für unüberwachtes Lernen auf Unternehmensebene. Neben der Verwendung von unüberwachten Techniken zur Datenerhebung gibt es in der Praxis einige häufige Anwendungsfälle:
- Natürliche Sprachverarbeitung (NLP). Google News ist dafür bekannt, dass es unüberwachtes Lernen einsetzt, um Artikel zu kategorisieren, die auf derselben Geschichte aus verschiedenen Nachrichtenquellen basieren. Die Ergebnisse des Fußballtransferfensters können zum Beispiel alle unter Fußball kategorisiert werden.
- Bild- und Videoanalyse. Visuelle Wahrnehmungsaufgaben wie die Objekterkennung nutzen das unüberwachte Lernen.
- Erkennung von Anomalien. Unüberwachtes Lernen wird eingesetzt, um Datenpunkte, Ereignisse und/oder Beobachtungen zu identifizieren, die vom normalen Verhalten eines Datensatzes abweichen.
- Kundensegmentierung. Durch unüberwachtes Lernen können interessante Buyer Persona Profile erstellt werden. Das hilft den Unternehmen, die Gemeinsamkeiten und Kaufgewohnheiten ihrer Kundinnen und Kunden zu verstehen und ihre Produkte besser darauf abzustimmen.
- Recommendation Engines. Vergangenes Kaufverhalten in Verbindung mit unüberwachtem Lernen kann Unternehmen dabei helfen, Datentrends zu entdecken, die sie zur Entwicklung effektiver Cross-Selling-Strategien nutzen können.
Beispiel für unüberwachtes Lernen in Python
Bei der Hauptkomponentenanalyse (PCA) werden die Hauptkomponenten berechnet und dann verwendet, um die Daten auf eine andere Grundlage zu stellen. Mit anderen Worten: Die PCA ist eine Technik zur Dimensionalitätsreduktion, die nicht überwacht wird.
Es ist aus zwei Gründen sinnvoll, die Dimensionalität eines Datensatzes zu reduzieren:
- Wenn es zu viele Dimensionen in einem Datensatz gibt, um ihn zu visualisieren
- Ermittlung der prädiktivsten n Dimensionen für die Merkmalsauswahl beim Aufbau eines Vorhersagemodells.
In diesem Abschnitt implementieren wir den PCA-Algorithmus in Python für den Iris-Datensatz und visualisieren ihn anschließend mit matplotlib. Schau dir diese DataLab-Arbeitsmappe an, um den in diesem Lernprogramm verwendeten Code nachzuvollziehen.
Beginnen wir damit, die notwendigen Bibliotheken und Daten zu importieren.
from sklearn.datasets import load_iris # Dataset
from sklearn.decomposition import PCA # Algorithm
import matplotlib.pyplot as plt # Visualization
# Load the data
iris_data = load_iris(as_frame=True)
# Preview
iris_data.data.head()|
Kelchblattlänge (cm) |
Kelchblattbreite (cm) |
Blütenblattlänge (cm) |
Blütenblattbreite (cm) |
|
|
0 |
5.1 |
3.5 |
1.4 |
0.2 |
|
1 |
4.9 |
3 |
1.4 |
0.2 |
|
2 |
4.7 |
3.2 |
1.3 |
0.2 |
|
3 |
4.6 |
3.1 |
1.5 |
0.2 |
|
4 |
5 |
3.6 |
1.4 |
0.2 |
Der Iris-Datensatz hat vier Merkmale. Der Versuch, Daten in vier oder mehr Dimensionen zu visualisieren, ist unmöglich, weil wir keine Ahnung haben, wie die Dinge in einer so hohen Dimension aussehen würden. Das Nächstbeste, was wir tun können, ist, es dreidimensional darzustellen, was zwar nicht unmöglich ist, aber dennoch eine Herausforderung darstellt.
Zum Beispiel:
"""
Credit: Rishikesh Kumar Rishi
Link: https://www.tutorialspoint.com/how-to-make-a-4d-plot-with-matplotlib-using-arbitrary-data
"""
plt.rcParams["figure.figsize"] = [7.00, 3.50]
plt.rcParams["figure.autolayout"] = True
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
sepal_length = iris_data.data["sepal length (cm)"]
sepal_width = iris_data.data["sepal width (cm)"]
petal_length = iris_data.data["petal length (cm)"]
petal_width = iris_data.data["petal width (cm)"]
ax.scatter(sepal_length, sepal_width, petal_length, c=petal_width)
plt.show()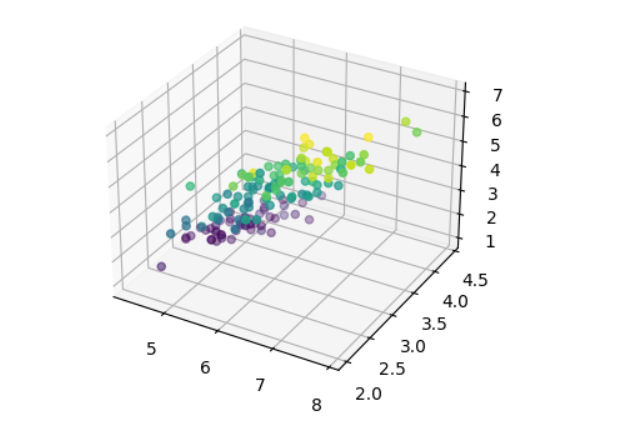
Es ist ziemlich schwierig, aus dieser Visualisierung Erkenntnisse zu gewinnen, weil alle Instanzen durcheinandergewürfelt sind, da wir nur Zugang zu einem Blickwinkel haben, wenn wir Daten in diesem Szenario dreidimensional visualisieren.
Mit der PCA können wir die Dimensionen der Daten auf zwei reduzieren, was es einfacher macht, unsere Daten zu visualisieren und die Klassen zu unterscheiden.
Hinweis: Lerne, wie man PCA in R implementiert in "Hauptkomponentenanalyse in R Tutorial."
# Instantiate PCA with 2 components
pca = PCA(n_components=2)
# Train the model
pca.fit(iris_data.data)
iris_data_reduced = pca.fit_transform(iris_data.data)
# Plot data
plt.scatter(
iris_data_reduced[:,0],
iris_data_reduced[:,1],
c=iris_data.target
)
plt.show()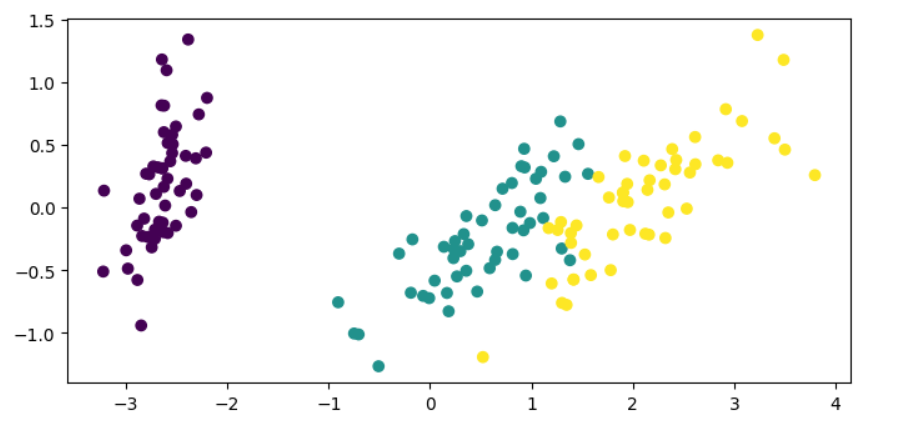
Im obigen Code transformieren wir die Merkmale des Iris-Datensatzes, wobei nur zwei Komponenten erhalten bleiben, und stellen die reduzierten Daten dann in einer zweidimensionalen Ebene dar.
Jetzt ist es für uns viel einfacher, Informationen über die Daten und die Aufteilung der Klassen zu sammeln. Diese Erkenntnisse können wir nutzen, um über die nächsten Schritte zu entscheiden, wenn wir ein maschinelles Lernmodell auf unsere Daten anwenden wollen.
Abschließende Gedanken
Unüberwachtes Lernen bezieht sich auf eine Klasse von Problemen des maschinellen Lernens, bei denen ein Modell verwendet wird, um Beziehungen in Daten zu charakterisieren oder zu extrahieren.
Im Gegensatz zum überwachten Lernen entdecken unüberwachte Lernalgorithmen die zugrunde liegende Struktur eines Datensatzes, indem sie nur die Eingangsmerkmale verwenden. Das bedeutet, dass unüberwachte Lernmodelle im Gegensatz zum überwachten Lernen keinen Lehrer benötigen, der sie korrigiert.
In diesem Artikel hast du die drei Hauptarten des unüberwachten Lernens kennengelernt: Assoziationsregel-Mining, Clustering und Dimensionalitätsreduktion. Außerdem hast du verschiedene Anwendungen des unüberwachten Lernens kennengelernt und erfahren, wie du die Dimensionalität mit dem PCA-Algorithmus in Python reduzieren kannst.
Schau dir doch mal diese Ressourcen an, um dich weiterzubilden: