Kurs
Einführung in Python
4 Std.
6.9M
Ein Entscheidungsbaum ist so eine Art Flussdiagramm, wo ein innerer Knoten ein Merkmal (oder Attribut) zeigt, der Zweig eine Entscheidungsregel und jeder Blattknoten das Ergebnis.
Der oberste Knoten in einem Entscheidungsbaum wird als Wurzelknoten bezeichnet. Es lernt, anhand des Attributwerts zu partitionieren. Es teilt den Baum auf eine rekursive Art und Weise auf, die als rekursive Partitionierung bezeichnet wird. Diese flussdiagrammartige Struktur hilft dir bei der Entscheidungsfindung. Es ist eine Visualisierung wie ein Flussdiagramm, das das menschliche Denken einfach nachahmt. Deshalb sind Entscheidungsbäume einfach zu verstehen und zu interpretieren.
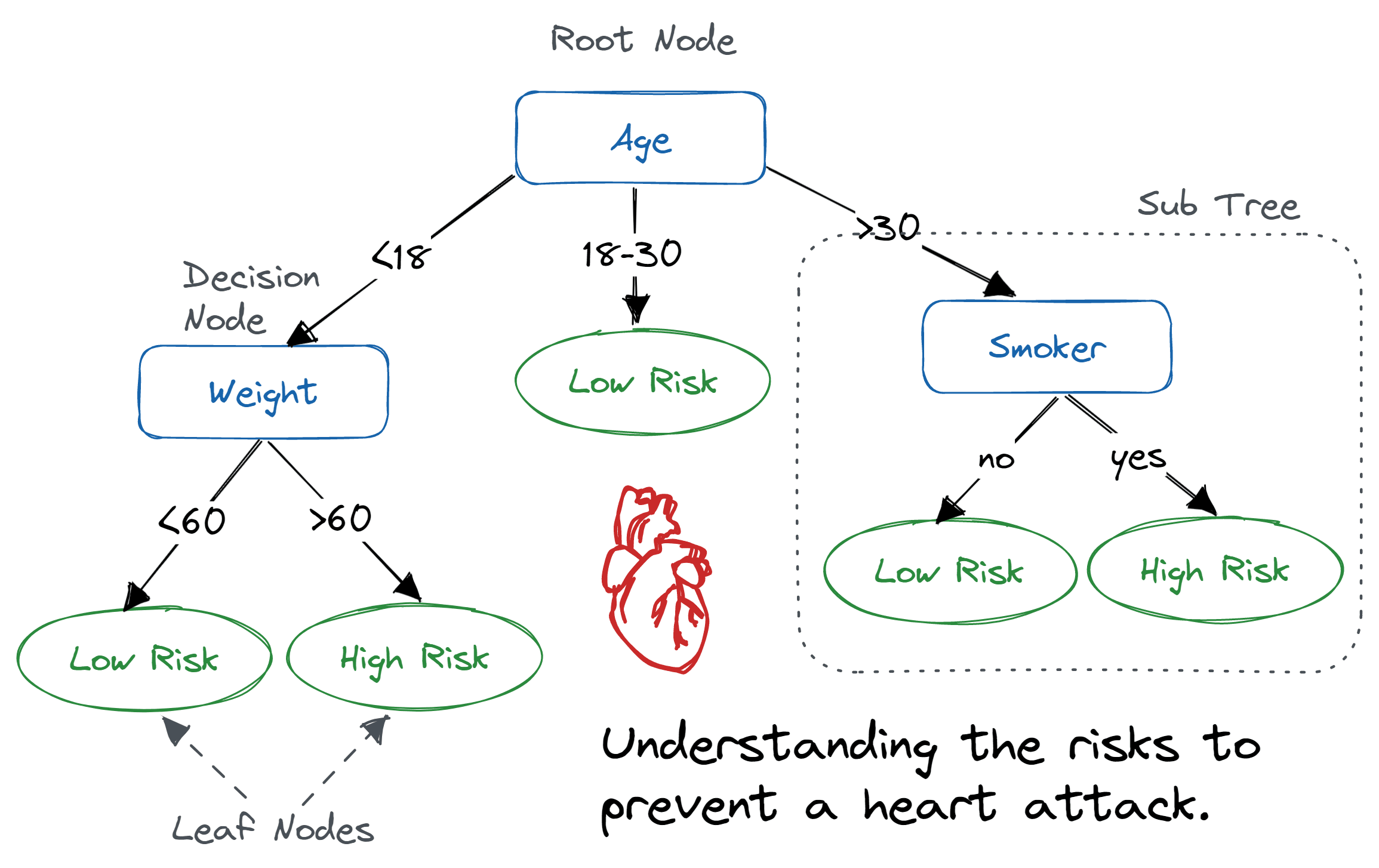
Entscheidungsbaum-Algorithmus. Bild von Abid Ali Awan
Ein Entscheidungsbaum ist ein ML-Algorithmus vom Typ „White Box“. Es teilt die interne Entscheidungslogik, die bei Black-Box-Algorithmen wie neuronalen Netzen nicht verfügbar ist. Die Trainingszeit ist im Vergleich zum neuronalen Netzwerk-Algorithmus schneller.
Die Zeitkomplexität von Entscheidungsbäumen hängt von der Anzahl der Datensätze und Attribute in den gegebenen Daten ab. Der Entscheidungsbaum ist eine verteilungsfreie oder nichtparametrische Methode, die nicht von Annahmen über die zugrunde liegende Wahrscheinlichkeitsverteilung der Daten abhängt. Entscheidungsbäume können hochdimensionale Daten ziemlich genau verarbeiten.
Die Grundidee hinter jedem Entscheidungsbaum-Algorithmus ist wie folgt:
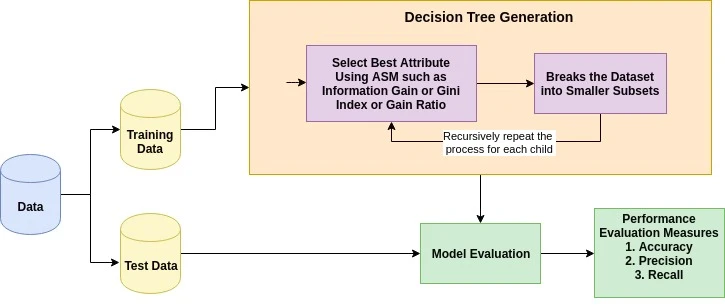
Die Attributauswahl ist eine Methode, um das beste Kriterium für die Aufteilung der Daten zu finden. Es wird auch als Aufteilungsregeln bezeichnet, weil es uns hilft, Bruchstellen für Tupel auf einem bestimmten Knoten zu bestimmen. ASM gibt jedem Merkmal (oder Attribut) eine Rangfolge, indem es den gegebenen Datensatz erklärt. Das Attribut mit der besten Punktzahl wird als Trennattribut ausgewählt (Quelle). Bei einem Attribut mit kontinuierlichen Werten musst du auch die Teilungspunkte für die Verzweigungen festlegen. Die beliebtesten Auswahlkriterien sind Informationsgewinn, Gewinnverhältnis und Gini-Index.
Claude Shannon hat das Konzept der Entropie erfunden, das die Unreinheit der Eingabemenge misst. In der Physik und Mathe wird Entropie als die Zufälligkeit oder Unreinheit in einem System bezeichnet. In der Informationstheorie geht's um die Unreinheit in einer Gruppe von Beispielen. Informationsgewinn ist die Abnahme der Entropie. Der Informationsgewinn berechnet den Unterschied zwischen der Entropie vor der Aufteilung und der durchschnittlichen Entropie nach der Aufteilung des Datensatzes, basierend auf den gegebenen Attributwerten. Der ID3-Algorithmus (Iterative Dichotomiser) für Entscheidungsbäume nutzt den Informationsgewinn.
Wobei Pi die Wahrscheinlichkeit ist, dass ein beliebiges Tupel in D zur Klasse Ci gehört.
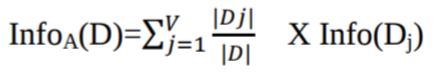
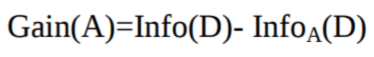
Wo:
Info(D) ist die durchschnittliche Menge an Infos, die man braucht, um die Klassenbezeichnung eines Tupels in „ D “ zu bestimmen.
|Dj|/|D| dient als Gewicht der j. Partition.
InfoA(D) Das sind die Infos, die man braucht, um eine Tupel aus D zu klassifizieren, basierend auf der Aufteilung durch A.
Das Attribut A mit dem höchsten Informationsgewinn, Gain(A), wird als Teilungsattribut am Knoten N() genommen.
Der Informationsgewinn ist bei dem Attribut mit vielen Ergebnissen verzerrt. Das heißt, es wählt lieber das Attribut mit vielen unterschiedlichen Werten. Nimm zum Beispiel ein Attribut mit einer eindeutigen Kennung wie customer_ID, das wegen einer reinen Partition null Info(D) hat. Das sorgt für den maximalen Informationsgewinn und macht unnötige Unterteilungen.
C4.5, eine Verbesserung von ID3, nutzt eine Erweiterung des Informationsgewinns, die als Gewinnverhältnis bekannt ist. Der Gewinnfaktor löst das Problem der Verzerrung, indem er den Informationsgewinn mit Split Info normalisiert. Die Java-Implementierung des C4.5-Algorithmus heißt J48 und ist im Data-Mining-Tool WEKA verfügbar.
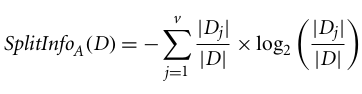
Wo:
Das Verstärkungsverhältnis kann man so definieren:
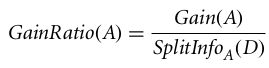
Das Attribut mit dem höchsten Gewinnverhältnis wird als Teilungsattribut ausgewählt (Quelle).
Ein anderer Entscheidungsbaum-Algorithmus namens CART (Classification and Regression Tree) nutzt die Gini-Methode, um Trennpunkte zu erzeugen.
Wobei pi die Wahrscheinlichkeit ist, dass ein Tupel in D zur Klasse Ci gehört.
Der Gini-Index geht von einer binären Aufteilung für jedes Attribut aus. Du kannst eine gewichtete Summe der Verunreinigung jeder Partition berechnen. Wenn eine binäre Aufteilung nach Attribut A die Daten D in D1 und D2 teilt, ist der Gini-Index von D:
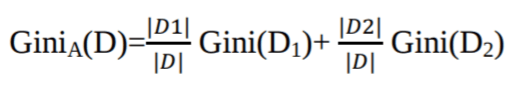
Bei einem diskret bewerteten Attribut wird die Teilmenge, die den niedrigsten Gini-Index für die Auswahl ergibt, als Teilungsattribut genommen. Bei Attributen mit kontinuierlichen Werten geht's so: Man nimmt jedes Paar benachbarter Werte als möglichen Teilungspunkt und wählt dann den Punkt mit dem niedrigeren Gini-Index als Teilungspunkt.
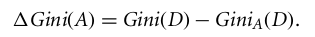
Das Attribut mit dem niedrigsten Gini-Index wird als Teilungsattribut genommen.
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenLass uns zuerst die benötigten Bibliotheken laden.
# Load libraries
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
Lass uns zuerst den benötigten Datensatz zu Diabetes bei den Pima-Indianern mit der CSV-Lesefunktion von pandas laden. Du kannst den Kaggle-Datensatz runterladen, um mitzumachen.
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("diabetes.csv", header=None, names=col_names)
pima.head()
| schwanger | Glukose | bp | Haut | insulin | BMI | Stammbaum | Alter | Etikett | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33,6 | 0,627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26,6 | 0,351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23,3 | 0,672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0,167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43,1 | 2.288 | 33 | 1 |
Hier musst du die angegebenen Spalten in zwei Arten von Variablen aufteilen: abhängige (oder Zielvariable) und unabhängige Variablen (oder Merkmalsvariablen).
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variable
Um die Leistung eines Modells zu verstehen, ist es eine gute Idee, den Datensatz in einen Trainingssatz und einen Testsatz aufzuteilen.
Teilen wir den Datensatz mit der Funktion „ train_test_split() “ auf. Du musst drei Parameter übergeben: features, target und test_set size.
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
Lass uns mit Scikit-learn ein Entscheidungsbaummodell erstellen.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
Schauen wir mal, wie gut der Klassifikator oder das Modell die Sorten vorhersagen kann.
Die Genauigkeit kann man berechnen, indem man die tatsächlichen Testwerte mit den vorhergesagten Werten vergleicht.
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.6753246753246753
Wir haben eine Klassifizierungsrate von 67,53 % erreicht, was als gute Genauigkeit gilt. Du kannst die Genauigkeit verbessern, indem du die Parameter im Entscheidungsbaum-Algorithmus anpasst.
Du kannst die Funktion „ export_graphviz() ” von Scikit-learn nutzen, um den Baum in einem Jupyter-Notebook anzuzeigen. Um den Baum zu zeichnen, musst du auch graphviz und pydotplus installieren.
pip install graphviz
pip install pydotplusDie Funktion „ export_graphviz() ” macht aus dem Entscheidungsbaum-Klassifikator eine Dot-Datei, und pydotplus wandelt diese Dot-Datei in eine PNG-Datei oder ein Format um, das man in Jupyter anzeigen kann.
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())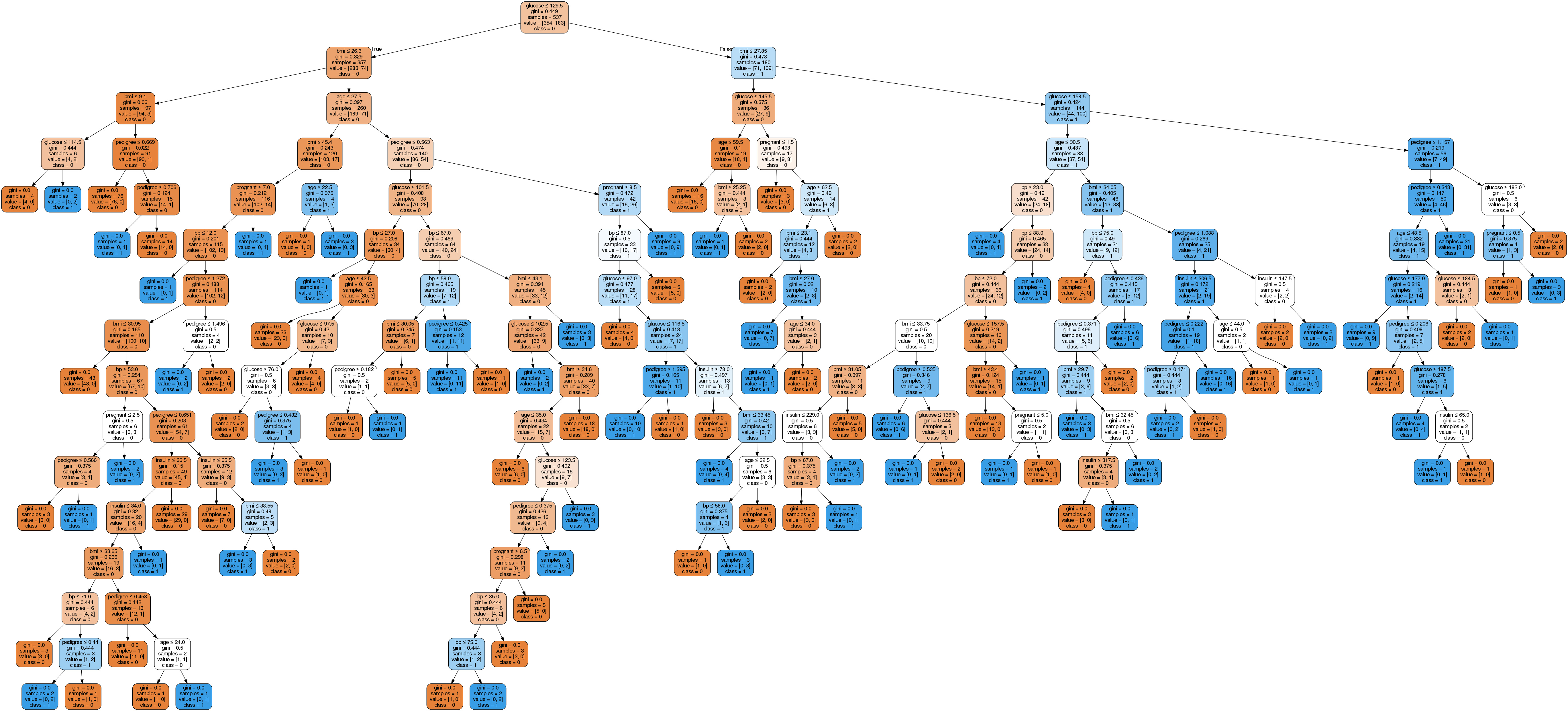
Im Entscheidungsbaum hat jeder interne Knoten eine Regel, die die Daten aufteilt. Gini, auch Gini-Koeffizient genannt, misst die Unreinheit des Knotens. Man kann sagen, dass ein Knoten rein ist, wenn alle seine Datensätze zur selben Klasse gehören. Solche Knoten werden als Blattknoten bezeichnet.
Hier ist der resultierende Baum nicht beschnitten. Dieser unbeschnittene Baum ist echt seltsam und nicht leicht zu kapieren. Im nächsten Abschnitt optimieren wir es durch Beschneiden.
Kriterium: optional (Standard = „gini”) oder Wähle Attributauswahlmaß. Mit diesem Parameter können wir die Auswahlmethode „different-different“ nutzen. Unterstützte Kriterien sind „gini“ für den Gini-Index und „entropy“ für den Informationsgewinn.
splitter: Zeichenfolge, optional (Standard = „best“) oder Split-Strategie. Mit diesem Parameter können wir die Aufteilungsstrategie auswählen. Unterstützte Strategien sind „best“, um die beste Aufteilung zu wählen, und „random“, um die beste zufällige Aufteilung zu wählen.
max_depth: int oder None, optional (Standardwert=None) oder maximale Tiefe eines Baums. Die maximale Tiefe des Baums. Wenn „None“, werden die Knoten erweitert, bis alle Blätter weniger als min_samples_split Samples haben. Ein höherer Wert für die maximale Tiefe führt zu Überanpassung, ein niedrigerer Wert zu Unteranpassung (Quelle).
In Scikit-learn wird die Optimierung des Entscheidungsbaumklassifikators nur durch Vorausdünnung gemacht. Die maximale Tiefe des Baums kann als Kontrollvariable für das Vorausdünnen genutzt werden. Im folgenden Beispiel kannst du einen Entscheidungsbaum für dieselben Daten mit max_depth=3 zeichnen. Außer den Parametern für das Vorausdünnen kannst du auch andere Attributauswahlmaßnahmen wie Entropie ausprobieren.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier(criterion="entropy", max_depth=3)
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.7705627705627706Also, die Klassifizierungsrate ist auf 77,05 % gestiegen, was eine bessere Genauigkeit als beim vorherigen Modell ist.
Lass uns unseren Entscheidungsbaum mit dem folgenden Code etwas verständlicher machen:
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True,
rounded=True,
special_characters=True,
feature_names=feature_cols,
class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())Hier haben wir die folgenden Schritte erledigt:
Die benötigten Bibliotheken wurden importiert.
Ich hab ein „ StringIO “-Objekt namens „ dot_data “ erstellt, um die Textdarstellung des Entscheidungsbaums zu speichern.
Exportiere den Entscheidungsbaum mit der Funktion „ export_graphviz “ ins Format „ dot “ und schreib die Ausgabe in den Puffer „ dot_data “.
Ein „ pydotplus “-Grafikobjekt aus der „ dot “-Formatausgabe des Entscheidungsbaums erstellt, der im „ dot_data “-Puffer gespeichert ist.
Schreib die erstellte Grafik in eine PNG-Datei namens „diabetes.png“.
Das erstellte PNG-Bild des Entscheidungsbaums wurde mit dem Objekt „ Image ” aus dem Modul „ IPython.display ” angezeigt.
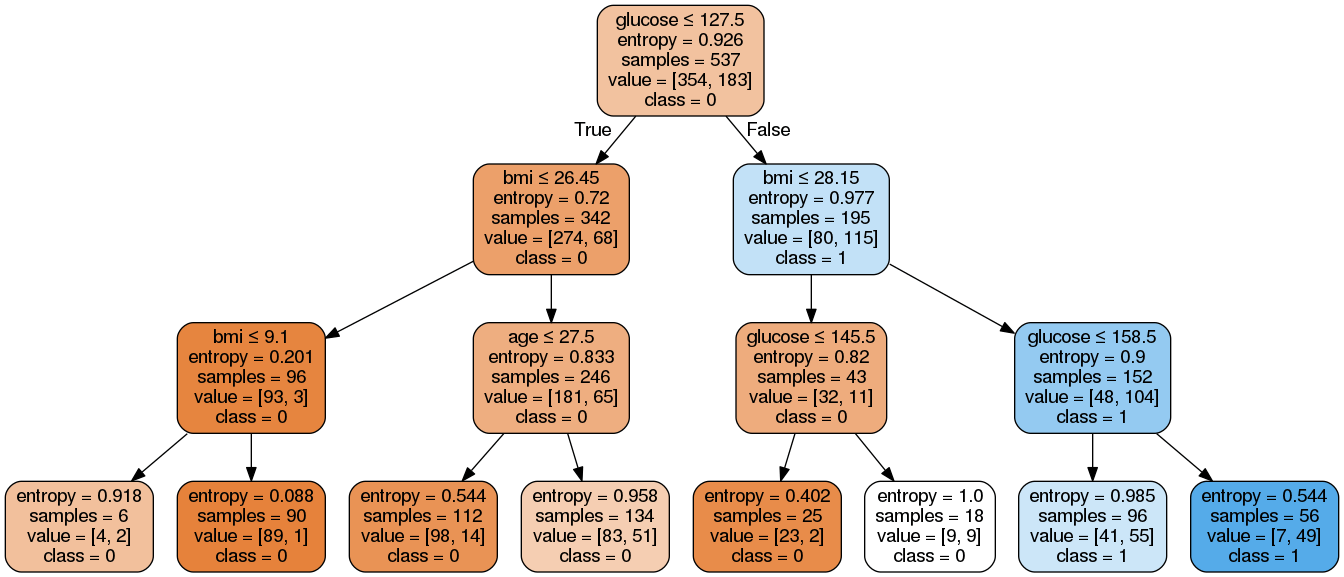
Wie du siehst, ist dieses bereinigte Modell weniger komplex, besser erklärbar und leichter zu verstehen als das vorherige Entscheidungsbaummodell.
Nachdem du jetzt einen Entscheidungsbaum-Klassifikator erstellt und optimiert hast, lass uns kurz innehalten, um einige der Stärken und Grenzen des Algorithmus allgemeiner zu bewerten. Wenn du die Vor- und Nachteile kennst, kannst du besser entscheiden, wann Entscheidungsbäume die richtige Wahl sind.
| Vorteile | Nachteile |
|---|---|
| Einfach zu verstehen und vorstellbar | Empfindlich gegenüber verrauschten Daten und kann zu stark angepasst sein |
| Kann nichtlineare Muster ganz einfach erfassen | Kleine Unterschiede in den Daten können zu ganz unterschiedlichen Bäumen führen. |
| Braucht nur wenig Datenvorbereitung (keine Normalisierung der Spalten nötig) | Verzerrt durch unausgewogene Datensätze (Ausgleich wird empfohlen) |
| Nützlich für Feature Engineering (Vorhersage fehlender Werte, Variablenauswahl) | |
| Keine Annahmen über die Datenverteilung (nichtparametrisch) |
Beachte, dass einige Nachteile, wie zum Beispiel die Instabilität der Varianz, durch Ensemble-Methoden wieBagging-undBoosting-Algorithmen gemildert werden können.
Obwohl wir in diesem Tutorial mit vollständigen Entscheidungsbäumen gearbeitet haben, lohnt es sich, eine einfachere Variante namens Entscheidungsstumpf zu verstehen. Ein Entscheidungsbaum ist im Grunde ein Entscheidungsbaum mit einer maximalen Tiefe von eins – das heißt, er hat nur eine einzige Verzweigung am Wurzelknoten und zwei Blattknoten.
| Aspekt | Entscheidungsbaum | Entscheidungsstumpf |
|---|---|---|
| Tiefe | Kann beliebig tief sein (gesteuert durch max_depth Parameter) |
Immer Tiefe 1 (nur eine Teilung) |
| Komplexität | Kann komplexe, nichtlineare Beziehungen modellieren | Modelle nur einfache, lineare Entscheidungsgrenzen |
| Anwendungsfall | Eigenständiger Klassifikator für komplizierte Probleme | Hauptsächlich als schwacher Lerner in Ensemble-Methoden eingesetzt |
| Genauigkeit | Im Allgemeinen genauer als ein einzelnes Modell | Geringere Genauigkeit, aber effektiv in Kombination |
| Interpretierbarkeit | Nimmt mit der Tiefe ab (wie wir bei unserem unbeschnittenen Baum gesehen haben) | Super einfach und leicht zu verstehen |
Entscheidungsbäume werden wegen ihrer Einfachheit selten als eigenständige Klassifikatoren benutzt. Aber sie können bei Ensemble-Methoden eine Rolle spielen, vor allem bei AdaBoost, wo Entscheidungsstumps als schwache Lerner verwendet werden, die zu einem starken Klassifikator kombiniert werden, oderbeim Gradientenboosting, weil Stumps als Basis-Lerner im Boosting-Prozess genutzt werden können.
Du kannst in Scikit-learn ganz einfach einen Entscheidungsbaum erstellen, indem du „ max_depth=1 “ festlegst:
# Create a Decision Stump
stump = DecisionTreeClassifier(max_depth=1)
stump = stump.fit(X_train, y_train)Herzlichen Glückwunsch, du hast es bis zum Ende dieses Tutorials geschafft!
In diesem Tutorial hast du viele Details über Entscheidungsbäume gelernt: wie sie funktionieren, Attributauswahlkriterien wie Informationsgewinn, Gewinnverhältnis und Gini-Index, die Erstellung von Entscheidungsbaummodellen, die Visualisierung und die Auswertung eines Diabetes-Datensatzes mit dem Scikit-learn-Paket von Python. Wir haben auch die Vor- und Nachteile besprochen und wie man die Leistung von Entscheidungsbäumen durch Parameteroptimierung verbessern kann.
Hoffentlich kannst du jetzt den Entscheidungsbaum-Algorithmus nutzen, um deine eigenen Datensätze zu analysieren.
Wenn du mehr über maschinelles Lernen in Python erfahren möchtest, mach doch unseren Kurs „Maschinelles Lernen mit baumbasierten Modellen in Python ”. Schau dir auch unser Kaggle-Tutorial „ ” an: Dein erstes Machine-Learning-Modell.
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Python-Kurse
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Derrick Mwiti
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
DataCamp Team