Cours
Introduction à Python
4 h
6.9M
Un arbre de décision est une structure arborescente semblable à un organigramme dans laquelle un nœud interne représente une caractéristique (ou un attribut), la branche représente une règle de décision et chaque nœud feuille représente le résultat.
Le nœud le plus élevé dans un arbre de décision est appelé nœud racine. Il apprend à partitionner sur la base de la valeur de l'attribut. Il partitionne l'arbre de manière récursive, ce que l'on appelle le partitionnement récursif. Cette structure, semblable à un organigramme, vous assiste dans la prise de décision. Il s'agit d'une visualisation sous forme d'organigramme qui reproduit facilement le niveau de réflexion humain. C'est pourquoi les arbres de décision sont faciles à comprendre et à interpréter.
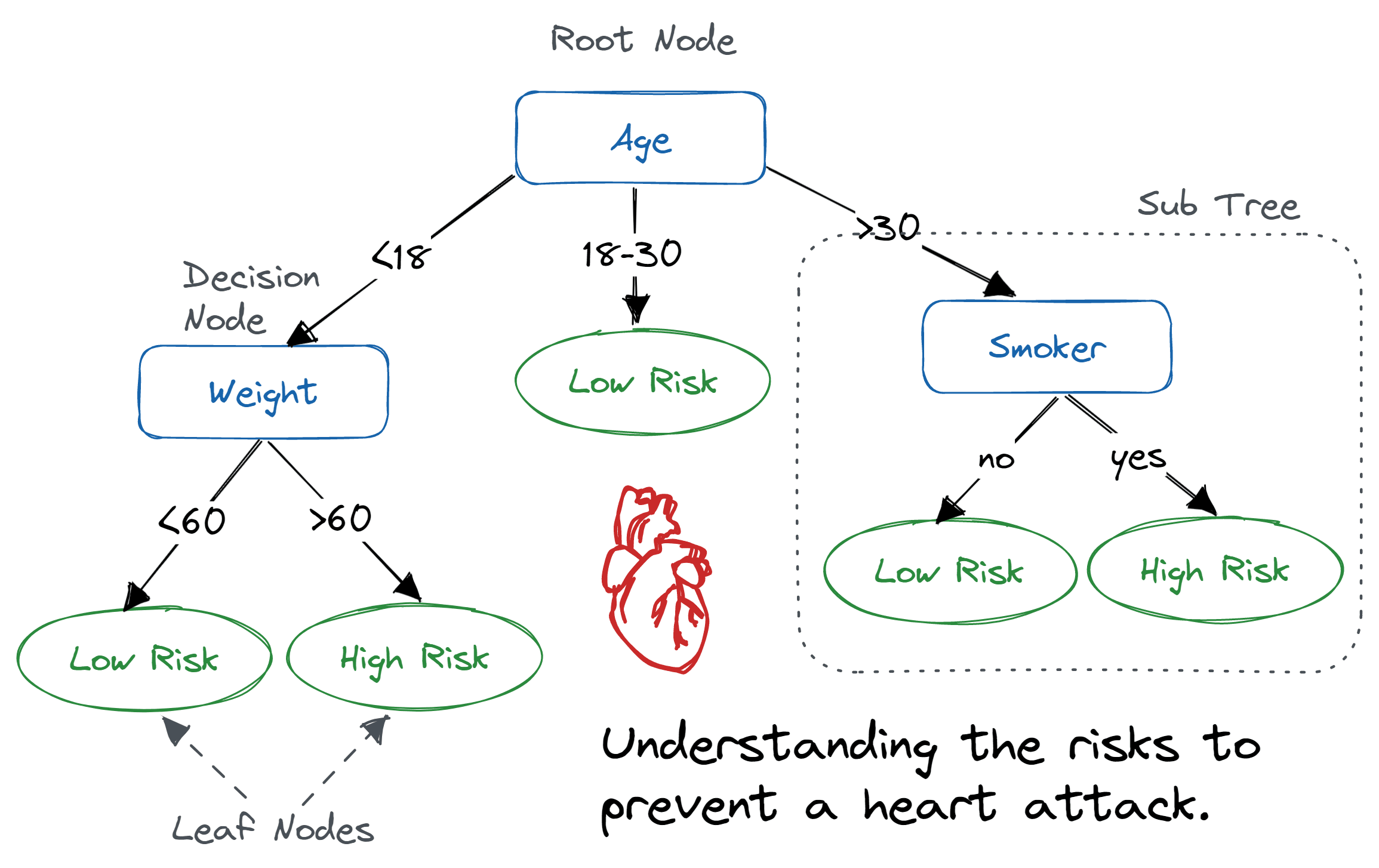
Algorithme d'arbre décisionnel. Image by Abid Ali Awan
Un arbre de décision est un algorithme d'apprentissage automatique de type boîte blanche. Il partage une logique décisionnelle interne, qui n'est pas disponible dans les algorithmes de type boîte noire tels que les réseaux neuronaux. Son temps d'apprentissage est plus rapide par rapport à l'algorithme de réseau neuronal.
La complexité temporelle des arbres de décision dépend du nombre d'enregistrements et d'attributs dans les données fournies. L'arbre décisionnel est une méthode sans distribution ou non paramétrique qui ne dépend pas d'hypothèses sur la distribution de probabilité sous-jacente des données. Les arbres de décision peuvent traiter des données à haute dimension avec une bonne précision.
Le principe de base de tout algorithme d'arbre de décision est le suivant :
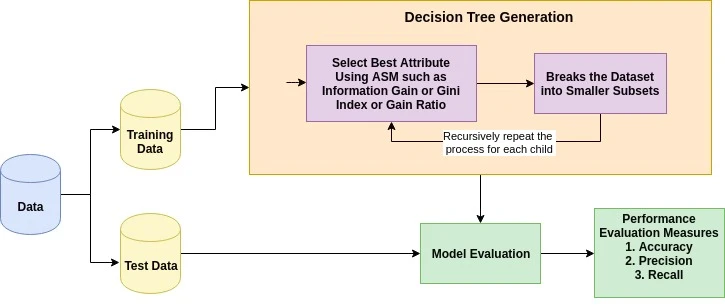
La mesure de sélection des attributs est une méthode heuristique permettant de sélectionner le critère de partitionnement qui divise les données de la manière la plus optimale. On l'appelle également « règles de fractionnement » car elle nous aide à déterminer les points de rupture pour les tuples sur un nœud donné. ASM attribue un classement à chaque caractéristique (ou attribut) en expliquant l'ensemble de données donné. L'attribut de meilleur score sera sélectionné comme attribut de fractionnement (Source). Dans le cas d'un attribut à valeur continue, les points de division pour les branches doivent également être définis. Les mesures de sélection les plus courantes sont le gain d'information, le rapport de gain et l'indice de Gini.
Claude Shannon a introduit le concept d'entropie, qui mesure le degré d'impureté de l'ensemble d'entrée. En physique et en mathématiques, l'entropie désigne le caractère aléatoire ou l'impureté d'un système. En théorie de l'information, ce terme désigne l'impureté dans un ensemble d'exemples. Le gain d'information correspond à la diminution de l'entropie. Le gain d'information calcule la différence entre l'entropie avant la division et l'entropie moyenne après la division de l'ensemble de données en fonction des valeurs d'attributs données. L'algorithme d'arbre de décision ID3 (Iterative Dichotomiser) utilise le gain d'information.
Où Pi est la probabilité qu'un tuple arbitraire dans D appartienne à la classe Ci.
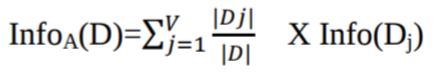
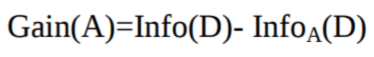
Où :
Info(D) est la quantité moyenne d'informations nécessaires pour identifier l'étiquette de classe d'un tuple dans l'D.
|Dj|/|D| agit comme le poids de la partition j.
InfoA(D) est l'information attendue nécessaire pour classer un tuple provenant de D en fonction du partitionnement par A.
L'attribut A présentant le gain d'information le plus élevé, Gain(A), est sélectionné comme attribut de division au nœud N().
Le gain d'information est biaisé pour l'attribut présentant de nombreux résultats. Cela signifie qu'il privilégie l'attribut présentant un grand nombre de valeurs distinctes. Par exemple, considérons un attribut avec un identifiant unique, tel que customer_ID, qui ne contient aucune information (D) en raison d'une partition pure. Cela maximise le gain d'informations et crée un partitionnement inefficace.
C4.5, une amélioration de l'ID3, utilise une extension du gain d'information appelée « rapport de gain ». Le rapport de gain traite la question du biais en normalisant le gain d'information à l'aide de Split Info. L'implémentation Java de l'algorithme C4.5 est connue sous le nom de J48, disponible dans l'outil d'exploration de données WEKA.
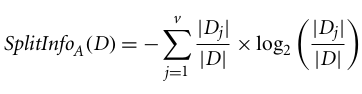
Où :
Le rapport de gain peut être défini comme suit :
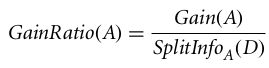
L'attribut présentant le ratio de gain le plus élevé est sélectionné comme attribut de division (Source).
Un autre algorithme d'arbre de décision, CART (Classification and Regression Tree), utilise la méthode de Gini pour créer des points de division.
Où pi est la probabilité qu'un tuple dans D appartienne à la classe Ci.
L'indice de Gini considère une division binaire pour chaque attribut. Vous pouvez calculer une somme pondérée de l'impureté de chaque partition. Si une division binaire sur l'attribut A partitionne les données D en D1 et D2, l'indice de Gini de D est :
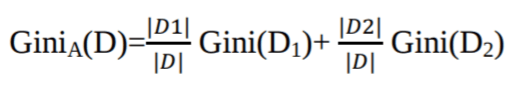
Dans le cas d'un attribut à valeurs discrètes, le sous-ensemble qui donne l'indice de Gini minimal pour celui qui a été choisi est sélectionné comme attribut de division. Dans le cas d'attributs à valeurs continues, la stratégie consiste à sélectionner chaque paire de valeurs adjacentes comme point de division possible, et un point avec un indice de Gini plus faible est choisi comme point de division.
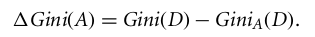
L'attribut présentant l'indice de Gini minimal est sélectionné comme attribut de division.
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeCommençons par charger les bibliothèques requises.
# Load libraries
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
Commençons par charger l'ensemble de données requis sur le diabète chez les Indiens Pima à l'aide de la fonction CSV de lecture de pandas. Vous pouvez télécharger l'ensemble de données Kaggle pour suivre le cours.
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("diabetes.csv", header=None, names=col_names)
pima.head()
| enceinte | glucose | bp | peau | insuline | bmi | pedigree | âge | étiquette | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33,6 | 0,627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26,6 | 0,351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23,3 | 0,672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28,1 | 0,167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43,1 | 2,288 | 33 | 1 |
Ici, il est nécessaire de diviser les colonnes données en deux types de variables : les variables dépendantes (ou variables cibles) et les variables indépendantes (ou variables caractéristiques).
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variable
Pour appréhender les performances d'un modèle, il est judicieux de diviser l'ensemble de données en un ensemble d'apprentissage et un ensemble de test.
Veuillez diviser l'ensemble de données en utilisant la fonction train_test_split(). Il est nécessaire de fournir trois paramètres : les caractéristiques, la cible et la taille du test_set.
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
Veuillez créer un modèle d'arbre de décision à l'aide de Scikit-learn.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
Évaluons avec quelle précision le classificateur ou le modèle peut prédire le type de cultivars.
La précision peut être calculée en comparant les valeurs réelles de l'ensemble de test et les valeurs prédites.
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.6753246753246753
Nous avons obtenu un taux de classification de 67,53 %, ce qui est considéré comme une bonne précision. Vous pouvez améliorer cette précision en ajustant les paramètres de l'algorithme de l'arbre de décision.
Vous pouvez utiliser la fonction ` export_graphviz() ` de Scikit-learn pour afficher l'arbre dans un notebook Jupyter. Pour réaliser un graphique de l'arbre, il est également nécessaire d'installer graphviz et pydotplus.
pip install graphviz
pip install pydotplusLa fonction ` export_graphviz() ` convertit le classificateur d'arbre de décision en un fichier dot, et pydotplus convertit ce fichier dot en PNG ou en un format affichable sur Jupyter.
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())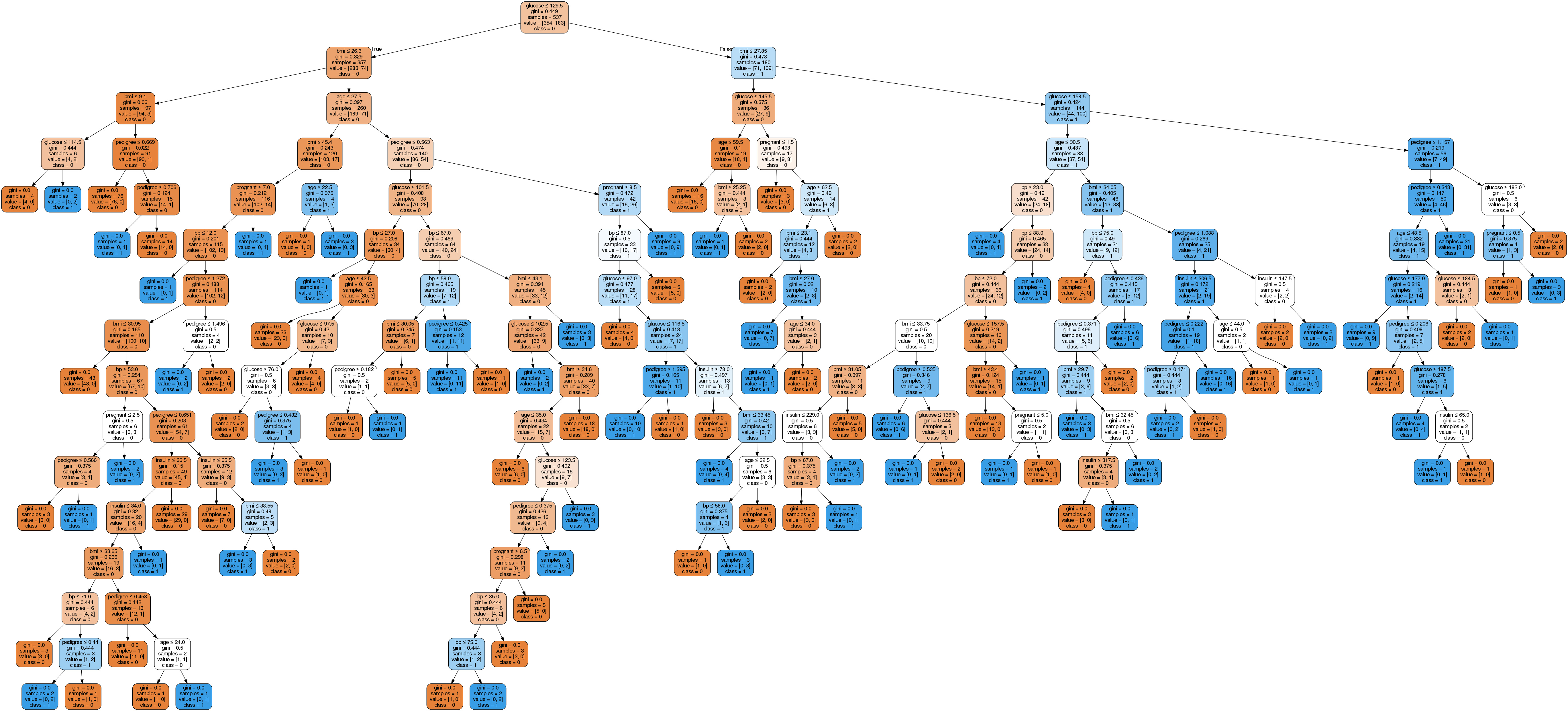
Dans l'arbre décisionnel, chaque nœud interne est associé à une règle de décision qui divise les données. Le coefficient de Gini, également appelé ratio de Gini, mesure l'impureté du nœud. On peut affirmer qu'un nœud est pur lorsque tous ses enregistrements appartiennent à la même classe. Ces nœuds sont appelés nœuds feuilles.
Ici, l'arbre résultant n'est pas élagué. Cet arbre non taillé est difficile à expliquer et à comprendre. Dans la section suivante, nous allons l'optimiser par élagage.
critère : facultatif (valeur par défaut = « gini ») ou Veuillez sélectionner la mesure de sélection des attributs. Ce paramètre nous permet d'utiliser la mesure de sélection d'attributs différente-différente. Les critères pris en charge sont « gini » pour l'indice de Gini et « entropy » pour le gain d'information.
splitter : chaîne, facultatif (valeur par défaut = « best ») ou stratégie de fractionnement. Ce paramètre nous permet de sélectionner la stratégie de fractionnement. Les stratégies prises en charge sont « best » pour choisir la meilleure division et « random » pour choisir la meilleure division aléatoire.
max_depth : int ou None, facultatif (par défaut = None) ou profondeur maximale d'un arbre. La profondeur maximale de l'arbre. Si Aucun, les nœuds sont développés jusqu'à ce que toutes les feuilles contiennent moins que min_samples_split échantillons. Une valeur plus élevée de profondeur maximale entraîne un surajustement, tandis qu'une valeur plus faible entraîne un sous-ajustement (Source).
Dans Scikit-learn, l'optimisation du classificateur d'arbre de décision est réalisée uniquement par pré-élagage. La profondeur maximale de l'arbre peut être utilisée comme variable de contrôle pour l'élagage préalable. Dans l'exemple suivant, vous pouvez créer un graphique d'arbre de décision sur les mêmes données avec max_depth=3. Outre les paramètres de pré-élagage, vous pouvez également envisager d'autres mesures de sélection d'attributs, telles que l'entropie.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier(criterion="entropy", max_depth=3)
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.7705627705627706Le taux de classification a augmenté pour atteindre 77,05 %, ce qui représente une précision supérieure à celle du modèle précédent.
Simplifions notre arbre de décision à l'aide du code suivant :
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True,
rounded=True,
special_characters=True,
feature_names=feature_cols,
class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())Ici, nous avons effectué les étapes suivantes :
Les bibliothèques requises ont été importées.
Création d'un objet StringIO nommé dot_data pour contenir la représentation textuelle de l'arbre de décision.
Veuillez exporter l'arbre de décision au format dot à l'aide de la fonction export_graphviz et enregistrer le résultat dans le tampon dot_data.
Création d'un objet graphique pydotplus à partir de la représentation au format dot de l'arbre de décision stocké dans le tampon dot_data.
Enregistrer le graphique généré dans un fichier PNG nommé « diabète.png ».
Affichage de l'image PNG générée de l'arbre de décision à l'aide de l'objet Image du module IPython.display.
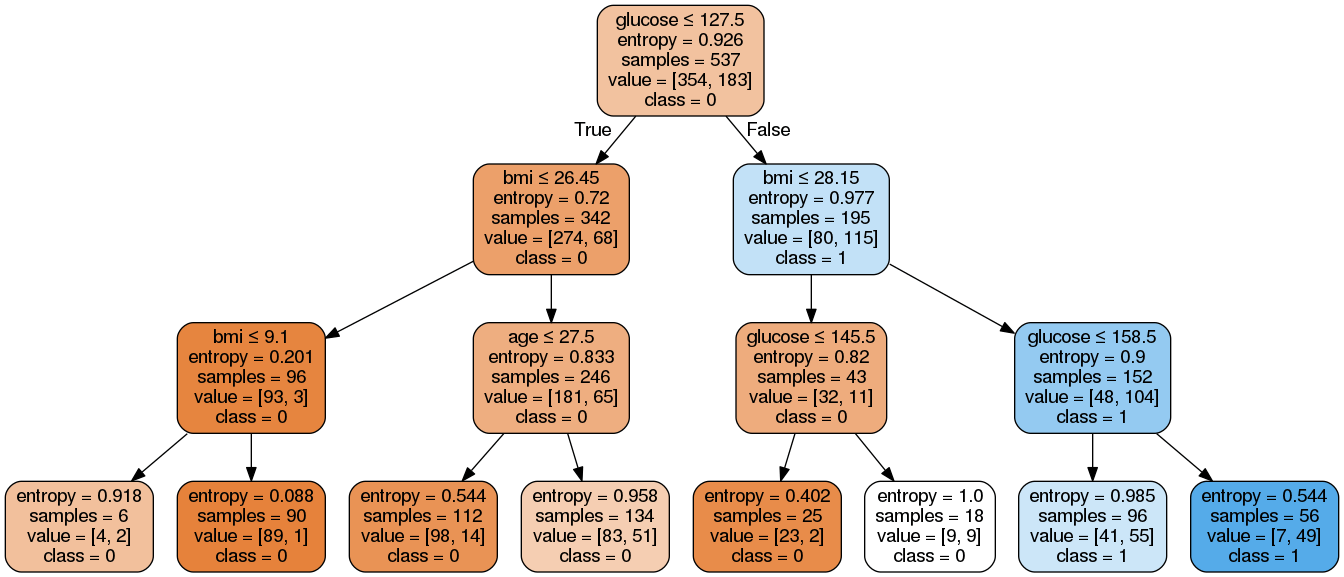
Comme vous pouvez le constater, ce modèle simplifié est moins complexe, plus explicite et plus facile à comprendre que le précédent graphique d'arbre décisionnel.
Maintenant que vous avez créé et optimisé un classificateur d'arbre de décision, prenons un moment pour évaluer de manière plus générale certains des points forts et des limites de l'algorithme. Comprendre les compromis vous aide à déterminer quand les arbres de décision constituent le choix approprié.
| Avantages | Inconvénients |
|---|---|
| Facile à interpréter et à visualiser | Sensible aux données bruitées et susceptible de surajustement |
| Peut facilement capturer des modèles non linéaires | De légères variations dans les données peuvent entraîner des arbres très différents. |
| Nécessite un prétraitement minimal des données (aucune normalisation des colonnes n'est requise). | Biaisé avec des ensembles de données déséquilibrés (équilibrage recommandé) |
| Utile pour l'ingénierie des caractéristiques (prédiction des valeurs manquantes, sélection des variables) | |
| Aucune hypothèse sur la distribution des données (non paramétrique) |
Veuillez noter que certains inconvénients, tels que l'instabilité de la variance, peuvent être atténués grâce à des méthodes d'ensemble telles que les algorithmesde baggingetde boosting.
Bien que nous ayons utilisé des arbres de décision complets tout au long de ce tutoriel, il est utile de comprendre une variante plus simple appelée « souche de décision ». Un arbre de décision est essentiellement un arbre de décision dont la profondeur maximale est de un, ce qui signifie qu'il ne comporte qu'une seule division au niveau du nœud racine et deux nœuds feuilles.
| Aspect | Arbre de décision | Arbre décisionnel |
|---|---|---|
| Profondeur | Peut être de n'importe quelle profondeur (contrôlée par max_depth paramètre) |
Toujours profondeur 1 (une seule division) |
| Complexité | Peut modéliser des relations complexes et non linéaires | Modèles uniquement des limites de décision simples et linéaires |
| Cas d'utilisation | Classificateur autonome pour problèmes complexes | Principalement utilisé comme apprenant faible dans les méthodes d'ensemble. |
| Précision | Précision généralement supérieure en tant que modèle autonome | Précision moindre, mais efficace lorsqu'il est associé à d'autres éléments |
| Interprétabilité | Diminue avec la profondeur (comme nous l'avons observé avec notre arbre non élagué) | Extrêmement simple et facile à interpréter |
Les arbres de décision sont rarement utilisés comme classificateurs autonomes en raison de leur simplicité. Cependant, ils peuvent jouer un rôle dans les méthodes d'ensemble, en particulier AdaBoost utilise des arbres de décision comme apprenants faibles qui sont combinés pour créer un classificateur puissant, oule gradient boosting, car les arbres peuvent être utilisés comme apprenants de base dans le processus de boosting.
Vous pouvez créer un arbre de décision dans Scikit-learn en définissant simplement l'argument max_depth=1:
# Create a Decision Stump
stump = DecisionTreeClassifier(max_depth=1)
stump = stump.fit(X_train, y_train)Félicitations, vous avez terminé ce tutoriel.
Dans ce tutoriel, vous avez abordé de nombreux détails concernant les arbres de décision : leur fonctionnement, les mesures de sélection d'attributs telles que le gain d'information, le ratio de gain et l'indice de Gini, la construction de modèles d'arbres de décision, la visualisation et l'évaluation d'un ensemble de données sur le diabète à l'aide du package Scikit-learn de Python. Nous avons également abordé ses avantages, ses inconvénients et la manière d'optimiser les performances de l'arbre de décision à l'aide du réglage des paramètres.
Nous espérons que vous pourrez désormais utiliser l'algorithme de l'arbre de décision pour analyser vos propres ensembles de données.
Si vous souhaitez approfondir vos connaissances en matière d'apprentissage automatique avec Python, nous vous invitons à suivre notre cours intitulé « Apprentissage automatique avec des modèles arborescents en Python ». Veuillez également consulter notre tutoriel Kaggle sur l': Votre premier modèle d'apprentissage automatique.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Cours Python
Cours
Cours
Cours
Tutoriel
Sejal Jaiswal
Tutoriel
Sejal Jaiswal
Tutoriel
Neetika Khandelwal
Tutoriel
Abid Ali Awan
Tutoriel
Derrick Mwiti
Tutoriel
DataCamp Team
