Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Grok 3 ist das neueste große Sprachmodell von xAI, das speziell für schrittweises Denken, logische Konsistenz und strukturierte Ausgaben entwickelt wurde. Im Gegensatz zu typischen Chatmodellen, die den Gesprächsfluss in den Vordergrund stellen, denkt Grok 3 mit, bevor es antwortet. Das macht es ideal für Aufgaben, die eine tiefgreifende Logik erfordern, wie z.B. komplexe Entscheidungsfindungen, mathematische Überlegungen und quantitative Analysen.
Die Grok 3 gibt es in zwei verschiedenen Varianten: das normale Modell und ein Mini-Modell. Während sich das Mini-Modell ganz auf den Aspekt des Denkens konzentriert und den Zugriff auf seine Denkspuren ermöglicht, wird das reguläre Modell mit umfangreichem Fachwissen in Bereichen wie Finanzen, Gesundheitswesen, Recht und Wissenschaft beworben.
Beide Modellversionen unterstützen erweiterte Funktionen wie den nativen Funktionsaufruf und die strukturierte Antwortgenerierung und helfen Entwicklern so, zuverlässige und vorhersehbare KI-Workflows zu erstellen.
Wenn du mehr über die Architektur und die Leistung von Grok 3 erfahren möchtest, solltest du einen Blick auf diesen Überblick über Grok 3.
In diesem Abschnitt erkläre ich, wie du einen API-Schlüssel erstellst, eine Python-Umgebung einrichtest, um dich mit der Grok-API zu verbinden, und deine erste Benutzeranfrage stellst.
Um den Python-Client bei der API zu authentifizieren, müssen wir einen API-Schlüssel erstellen. Der Prozess sieht folgendermaßen aus:
.env in deinem Projektverzeichnis und füge den Schlüssel im folgenden Format ein:XAI_API_KEY=<your_api_key>Obwohl die Nutzung der API oft mit geringeren Kosten verbunden ist als die Nutzung eines Premium-Abonnements, ist sie nicht kostenlos. Statt eines festen Betrags pro Monat, der beim SuperGrok-Abonnement bei 30 Dollar beginnt, sind die Kosten vollständig von der Nutzungsmenge abhängig. Um einen Überblick über mögliche Kosten zu erhalten, besuche die xAI Preisseite.
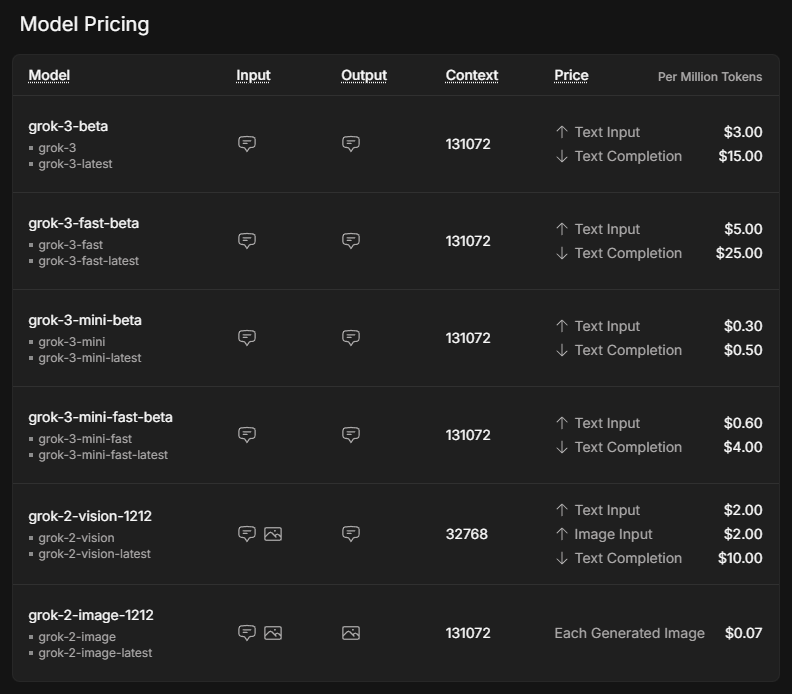
Die angegebenen Preise gelten pro Million Token, was nach einer Faustformel etwa 750.000 Wörtern an Input oder Output auf Englisch entspricht.
Das Mini-Modell ist deutlich günstiger als das normale Modell. Die schnellen Versionen von Grok 3 und Grok 3 mini verwenden genau die gleichen Modelle, werden aber auf einer schnelleren Infrastruktur betrieben, was zu besseren Reaktionszeiten führt.
Um die API zu nutzen, müssen wir Credits kaufen. Am Anfang empfiehlt es sich, Prepaid-Guthaben anstelle der automatischen Rechnungsstellung zu verwenden, da dies ein guter Schutz vor unerwarteten Kosten ist. Du kannst Token kaufen und dir in der xAI Konsole unter Rechnungen > Guthaben einen Überblick über deinen Verbrauch verschaffen.
Nachdem wir nun einen API-Schlüssel erworben und Credits gekauft haben, ist es an der Zeit, den Python-Client einzurichten. Wir müssen zwei Abhängigkeiten installieren, damit unsere API-Anfragen erfolgreich ausgeführt werden:
python-dotenv um den API-Schlüssel als Umgebungsvariable aus der Datei .env zu laden, undopenai Client als Schnittstelle, um Anfragen an Grok 3 zu senden.Um die Umgebung für unser Projekt einzurichten, empfehle ich die Verwendung von Anaconda zu verwenden, um mögliche Konflikte zwischen verschiedenen Python-Paketen zu vermeiden. Nach der Installation von Anaconda erstellen wir eine Umgebung namens grok3 mit Python 3.10 und aktivieren sie mit den folgenden Befehlen im Terminal:
conda create -n grok3 python=3.10
conda activate grok3Schließlich werden die Abhängigkeiten installiert:
pip install python-dotenv openaiZeit, mit unserem ersten Skript anzufangen! Zuerst müssen wir die Funktionen, die wir verwenden werden, aus den Paketen importieren, die wir zuvor installiert haben, sowie os, um den API-Schlüssel zu lesen.
import os
from dotenv import load_dotenv
from openai import OpenAIDie Umgebungsvariable die auf den API-Schlüssel verweist, wird durch Ausführen der Funktion load_dotenv(), die aus dem Paket dotenv importiert wurde, verfügbar gemacht.
# Load environment variables
load_dotenv()Der nächste Schritt ist die Initialisierung des Clients. Wir rufen die Funktion OpenAI mit unserem API-Schlüssel aus der Datei .env und der URL des Grok-Servers auf und weisen ihn der Variablen client zu.
client = OpenAI(
api_key=os.getenv("XAI_API_KEY"),
base_url="https://api.x.ai/v1",
)Wir fragen Grok um Rat, was man in San Francisco tun kann, wenn es regnet. Wir müssen die model und unsere messages angeben und sie als Argumente an die Funktion client.chat.completions.create übergeben. Optional können wir auch Parameter wie max_tokens einstellen, um die Länge der Antwort zu kontrollieren oder temperature, um die Zufälligkeit zu beeinflussen.
# Send a basic reasoning query
response = client.chat.completions.create(
model="grok-3",
messages=[
{"role": "user", "content": "What kind of activity would you suggest, if it rains in San Francisco? Answer in one sentence."}
],
max_tokens=1000,
temperature=0.2, # lower temperature for more deterministic answers
)Um die Antwort von Grok zu drucken, müssen wir sie aus dem resultierenden Objekt extrahieren. Da wir die Variable, die das Ergebnis speichert, response genannt haben, kann die Antwort in response.choices[0].message.content gefunden werden.
print(response.choices[0].message.content) # Print the responseIf it rains in San Francisco, I suggest visiting indoor attractions like the San Francisco Museum of Modern Art or the California Academy of Sciences for an enriching and dry experience.Um Groks Denkstil zu erkennen, stellen wir eine einfache Frage, die logisches Denken erfordert. Wir werden Grok 3 Mini für diese erste Anfrage verwenden, weil es in jeder API-Antwort eine vollständige Argumentationsspur garantiert, die es einfacher macht, den Denkprozess des Modells Schritt für Schritt nachzuvollziehen, ohne auf spezielle Eingabeaufforderungen angewiesen zu sein.
Der Parameter, der bestimmt, wie tief das Modell denkt, heißt reasoning_effort. Sie ist exklusiv für Grok 3 Mini und ist standardmäßig auf die schnellere Option ”low” eingestellt. Wenn du reasoning_effort="high" einstellst, kann das Modell das Problem Schritt für Schritt durchgehen, bevor es die endgültige Antwort gibt - perfekt für Aufgaben wie Planung, Entscheidungsfindung oder mathematisches Denken.
Stell dir vor, wir wollen Grok benutzen, um herauszufinden, was wir an einem freien Tag je nach Wetterlage machen sollen. Wir könnten Grok eine Aktivität für sonnige und regnerische Tage definieren und eine Prämisse, die auf dem aktuellen Wetter basiert.
response = client.chat.completions.create(
model="grok-3-mini-beta",
reasoning_effort="high",
messages=[
{"role": "user", "content": (
"Premises:\n"
"- If it is raining, the weather is suitable for indoor activities.\n"
"- Visiting a museum is an indoor activity.\n"
"- Today, it is raining.\n"
"Question: What should we do today?"
)}
],
max_tokens=1000,
temperature=0.2,
)Um mit dem Reasoning Trace zu arbeiten, müssen wir zunächst die API-Antwort analysieren und das Attribut reasoning_content aus dem message Objekt extrahieren. Der folgende Code zeigt, wie du sowohl die detaillierten Argumentationsschritte als auch die endgültige Antwort ausdrucken kannst, ähnlich wie sie in einer Weboberfläche erscheinen würden.
# Print the reasoning trace if available
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
if reasoning:
print("Reasoning steps:\n")
print(reasoning)
else:
print("No detailed reasoning trace found.")
# Print the final answer
print("\nFinal Answer:\n")
print(response.choices[0].message.content)Das Ergebnis sieht so aus:
Reasoning steps:
First, the premises are:
1. If it is raining, the weather is suitable for indoor activities.
2. Visiting a museum is an indoor activity.
3. Today, it is raining.
The question is: What should we do today?
I need to reason step by step based on the given premises.
From premise 3, today it is raining.
From premise 1, if it is raining, then the weather is suitable for indoor activities. Since it's raining today, the weather is suitable for indoor activities today.
From premise 2, visiting a museum is an indoor activity. So, if the weather is suitable for indoor activities, and visiting a museum is an indoor activity, it makes sense that visiting a museum would be a good choice today.
The conclusion should be that we should visit a museum or engage in some indoor activity. But the question is "What should we do today?" and the premises point towards indoor activities, with a specific example given.
Let me chain the logic:
- It is raining (premise 3).
- Therefore, weather is suitable for indoor activities (from premise 1).
- Visiting a museum is an indoor activity (premise 2).
- So, since the weather is suitable for indoor activities, and museum visiting is an indoor activity, it should be suitable to visit a museum.
The premises don't explicitly say that we should do the most suitable activity or anything like that. They just provide conditions and facts.
However, the question implies a recommendation based on the premises. Given that it's raining and indoor activities are suitable, and a museum is mentioned, it's logical to suggest visiting a museum.
I should stick to what's given. The premises don't suggest any other activities or constraints, so based on the information, visiting a museum is a reasonable suggestion.
Final answer should be something like: "We should visit a museum today."
To make it clear, I can phrase it as: "Since it is raining and the weather is suitable for indoor activities, and visiting a museum is an indoor activity, we should visit a museum today."
But since the instruction is to put the final answer in a box, probably a concise statement.
Looking back at the user's message, it's a reasoning exercise, so the answer should be direct.
Final Answer:
Based on the given premises:
- It is raining today (premise 3).
- If it is raining, the weather is suitable for indoor activities (premise 1).
- Therefore, the weather is suitable for indoor activities today.
- Visiting a museum is an indoor activity (premise 2).
A suitable activity for today would be an indoor one, such as visiting a museum.
**Recommendation:** We should visit a museum today.Obwohl es sich hier um ein recht einfaches Beispiel handelt, können wir sehen, wie Grok-3-mini jede Prämisse sorgfältig durchgeht und die Logik Schritt für Schritt verkettet, bevor es zu einer Empfehlung kommt. Die Argumentation ist methodisch und transparent, so dass man leicht nachvollziehen kann, wie das Modell von den Fakten zum endgültigen Vorschlag kommt.
Eine der Funktionen, die Grok 3 interessant machen, ist der Funktionsaufruf, mit dem es sich mit externen Tools und Systemen verbinden kann. So kann das Modell nicht nur Text generieren, sondern auch Aktionen auslösen, z. B. Wettervorhersagen abrufen, Veranstaltungspläne nachschlagen, Datenbankeinträge analysieren oder sogar intelligente Geräte steuern.
Wenn wir eine Benutzeranfrage senden, kann Grok 3 erkennen, dass es zusätzliche Informationen benötigt und einen Funktionsaufruf mit bestimmten Argumenten anfordern. Der Python-Client führt die Funktion dann lokal aus, sendet das Ergebnis zurück an Grok 3 und erhält die endgültige, vollständig begründete Antwort.
Quelle: xAI
Wir brauchen das Paket json, um auf die Argumentstruktur einer Funktion zuzugreifen, die von Grok aufgerufen wurde, also müssen wir es importieren.
import jsonUm den Funktionsaufruf auszuprobieren, müssen wir eine Callback-Funktion definieren, die aufgerufen wird, wenn Grok sie in seiner Antwort anfordert. In unserem Fall ist die Funktion get_weather_forecast eine einfache Python-Funktion, die eine fest programmierte Wettervorhersage liefert. Zu Demonstrationszwecken habe ich es hart kodiert, um die Erklärung einfach zu halten und nicht auf externe Dienste angewiesen zu sein.
# Define the dummy function
def get_weather_forecast(location: str, date: str) -> dict:
"""Simulated function to always return rainy weather."""
return {
"location": location,
"date": “this weekend”, # hardcoded for demo purposes
"forecast": "rainy" # hardcoded for demo purposes
}Wir müssen auch das verfügbare Tool definieren, indem wir seinen Namen, seinen Zweck und die erforderlichen Parameter in einem JSON-Schema angeben, das später mit unserer Anfrage an Grok gesendet wird. Durch diese Einstellung weiß Grok 3, dass es dieses Tool immer dann aufrufen kann, wenn es Wetterinformationen für seine Überlegungen benötigt.
tools = [
{
"type": "function",
"function": {
"name": "get_weather_forecast",
"description": "Get a simulated weather forecast for a given location and date.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city where the activity will take place."
},
"date": {
"type": "string",
"description": "The date for which the weather is needed, in YYYY-MM-DD format."
}
},
"required": ["location", "date"]
}
}
}
]Schließlich verknüpft die tools_map dictionary die von Grok 3 verwendeten Funktionsnamen mit den tatsächlichen lokalen Python-Funktionen, damit der Client die angeforderten Tool-Aufrufe korrekt ausführen kann.
# Link the function names to the functions
tools_map = {
"get_weather_forecast": get_weather_forecast
}Während die manuelle Definition von Toolschemata für einfache Projekte völlig in Ordnung ist, wird der Einsatz eines Datenvalidierungsmoduls wie Pydantic immer wertvoller, je größer und komplexer die Projekte werden. Sie ermöglicht die automatische Validierung von Funktionseingaben, eine bessere Fehlerbehandlung und einen saubereren, besser wartbaren Code.
Mal sehen, ob Grok unsere Wettervorhersagefunktion nutzt, wenn wir nach einer vorgeschlagenen Aktivität in San Francisco an diesem Wochenende fragen. Wir folgen der Struktur des Arbeitsablaufs beim Funktionsaufruf:
tools an die Grok.tools_map auf. Wenn Grok keinen Werkzeugaufruf anfordert, können wir das erledigen, indem wir die ursprüngliche Antwort des Modells zurückgeben.# Step 1: Send the initial user request
messages = [
{"role": "user", "content": "What should I do this weekend in San Francisco?"}
]
response = client.chat.completions.create(
model="grok-3",
messages=messages,
tools=tools,
tool_choice="auto",
)
# Step 2: Check if a tool call was requested
tool_calls = getattr(response.choices[0].message, "tool_calls", [])
if tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# Find and call the matching local function
if function_name in tools_map:
function_result = tools_map[function_name](**function_args)
# Step 3: Add the function result back to the message history
messages.append(response.choices[0].message) # Grok's tool call message
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(function_result)
})
# Step 4: Send a new request including the tool response
final_response = client.chat.completions.create(
model="grok-3",
messages=messages,
tools=tools,
tool_choice="auto"
)
# Print the final answer
print("\nFinal Answer:")
print(final_response.choices[0].message.content)
else:
# No tool call: respond directly
print("\nNo tool call was requested. Final Answer:")
print(response.choices[0].message.content)Die Funktion wurde angefordert und erfolgreich ausgeführt, wie die Antwort von Grok zeigt:
Thanks for the weather update. Since it's going to be rainy this weekend in San Francisco, I’ll suggest some indoor activities to keep you entertained and dry. Here are a few ideas for your weekend: (...)Dir ist vielleicht das Argument tool_choice in der ersten Benutzeranfrage aufgefallen, das sich auf den Modus des Funktionsaufrufs bezieht. Standardmäßig lässt der "auto" Modus Grok 3 anhand der Konversation entscheiden, ob und welche Funktion aufgerufen werden soll. Alternativ können wir das Verhalten steuern, indem wir einen Funktionsaufruf mit ”required” erzwingen, eine genaue Funktion angeben, die aufgerufen werden soll, oder den Funktionsaufruf mit ”none” komplett deaktivieren.
Strukturierte Ausgaben ermöglichen es Grok 3, Antworten in einem strengen, vordefinierten Format wie JSON anstelle von Freiformtext zurückzugeben. Das macht es viel einfacher, Modellantworten automatisch zu analysieren, zu validieren und in Anwendungen oder Workflows zu integrieren.
Indem wir im Voraus ein Schema definieren, können wir sicherstellen, dass die Ausgaben von Grok konsistent und maschinenlesbar sind und für die Weiterverarbeitung bereit. Daher ist es eine sehr nützliche Funktion für Anwendungsfälle wie strukturierte Daten aus Dokumenten oder die Einspeisung von KI-generierten Erkenntnissen in nachgelagerte Systeme wie Datenbanken, Dashboards oder Automatisierungspipelines, ohne dass ein fragiles Textparsing erforderlich ist.
Wir verwenden Pydantic, um das Ausgabeschema zu definieren, weil es eine übersichtlichere und besser lesbare Möglichkeit bietet, komplexe Daten zu strukturieren. Sowohl BaseModel als auch Field müssen von pydantic importiert werden, damit diese Schemadefinition korrekt funktioniert. Da unsere Ausgabe eine Liste von Argumentationsschritten enthält, importieren wir auch List aus Pythons typing Modul, um den Elementtyp genauer zu bestimmen.
Es ist zwar auch möglich, das Schema mit einfachem JSON zu definieren, aber beim Testen habe ich festgestellt, dass Grok 3 manchmal eine Ausgabe liefert, die nicht genau der erwarteten Struktur entspricht. Das zurückgegebene JSON war von der Bedeutung her ähnlich, folgte aber einem anderen Schema, was Anwendungen, die eine bestimmte Struktur erwarteten, stören konnte. Aufgrund dieser Inkonsistenz, insbesondere bei verschachtelten Elementen wie Listen, empfehle ich dringend, Pydantic zu verwenden, um sicherzustellen, dass die strukturierte Ausgabe validiert und zuverlässig geparst wird.
from pydantic import BaseModel, Field
from typing import ListUnser Schema, genannt DecisionPlan, besteht aus unserer anfänglichen situation und einer Liste von DecisionSteps, die durch ihre step Nummer, die reasoning dahinter und eine vorgeschlagene action definiert sind.
# Define the schema for the structured output
class DecisionStep(BaseModel):
step: int = Field(description="Step number in the decision process")
reasoning: str = Field(description="Reasoning behind this step")
action: str = Field(description="Suggested action at this step")
class DecisionPlan(BaseModel):
situation: str = Field(description="The initial situation to consider")
steps: List[DecisionStep] = Field(description="List of reasoning steps leading to the final action")Es gibt ein paar Dinge zu beachten, was den Antrag selbst angeht. Zunächst einmal müssen wir client.beta.chat.completions.parse() statt create() verwenden, damit Grok weiß, dass wir ein bestimmtes Format für die Ausgabe haben wollen. Dies ist das Schema, das wir gerade definiert haben, und dementsprechend übergeben wir unser DecisionPlan als response_format Argument.
Es kann nützlich sein, alle wichtigen Anweisungen für eine bestimmte Aufgabe in die Systemaufforderung aufzunehmen, da dies Grok 3 hilft, sich während des gesamten Gesprächs auf die Aufgabe zu konzentrieren. In Kombination mit dem separat definierten Schema muss die Benutzeraufforderung keine Pflichtfelder in der JSON-Ausgabe angeben, sondern kann sich auf die Aufgabe selbst konzentrieren.
Wir könnten zum Beispiel den Prozess der Aktivitätenplanung ganz einfach in drei klar definierte Schritte unterteilen:
# Send a prompt and request structured output
completion = client.beta.chat.completions.parse(
model="grok-3",
messages=[
{"role": "system", "content": (
"You are an expert travel planner."
"When asked about activities, always break down the decision process into exactly 3 logical reasoning steps."
"Return the output in structured JSON format following the provided schema, without any extra text."
)},
{"role": "user", "content": (
"It's raining today in San Francisco. What indoor activity would you recommend?"
)}
],
response_format=DecisionPlan,
)Nachdem wir die strukturierte Ausgabe von Grok 3 analysiert haben, können wir auf die Ergebnisse reagieren, indem wir die wichtigsten Empfehlungen zusammenfassen, automatisierte Workflows auslösen oder sogar weitere Entscheidungen programmgesteuert treffen.
Nehmen wir das erste Beispiel und zeigen wir nur unsere Situation und die endgültige Empfehlung unseres Reiseexperten Grok. Da unsere Ausgabe in unserem vordefinierten JSON-Format vorliegt, können wir die Empfehlung des letzten Schritts einfach abrufen:
# Access the parsed result
plan = completion.choices[0].message.parsed
# Use the final action to create a summary message
final_step = plan.steps[-1]
print(f"\nSummary:")
print(f"Situation: {plan.situation}")
print(f"Recommended Action: {final_step.action}")Summary:
Situation: It's raining today in San Francisco, and an indoor activity is needed to make the most of the day.
Recommended Action: Visiting the California Academy of Sciences in Golden Gate Park for an educational and entertaining indoor experience.Wir können den Funktionsaufruf und die strukturierten Ausgaben kombinieren, um eine einfache App zu erstellen, die Groks Argumentation nutzt. Wir können den Code für kopieren und einfügen:
tools_map; undWir beginnen mit einem API-Aufruf mit der Funktion create(), um den Tool-Aufruf auszulösen. Damit der Benutzer die Frage in das Terminal eingeben kann, ersetzen wir unsere Frage nach der Aktivität in San Francisco einfach durch input("> ").
Nach dem Anhängen von function_result an die messages Liste kommt der Clou: Anstatt einen weiteren API-Aufruf zu erstellen, der create(), we parse() and pass our DecisionPlan as the response_format` verwendet.
Hier ist der vollständige Code unserer kleinen App:
import os
import json
from dotenv import load_dotenv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
# Load environment variables
load_dotenv()
# Initialize the client
client = OpenAI(
api_key=os.getenv("XAI_API_KEY"),
base_url="https://api.x.ai/v1",
)
# 1. Define the function schema (tool definition)
tools = [
{
"type": "function",
"function": {
"name": "get_weather_forecast",
"description": "Get a simulated weather forecast for a given location and date.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city where the activity will take place."
},
"date": {
"type": "string",
"description": "The date for which the weather is needed, in YYYY-MM-DD format."
}
},
"required": ["location", "date"]
}
}
}
]
# 2. Dummy weather function (hardcoded)
def get_weather_forecast(location: str, date: str) -> dict:
return {
"location": location,
"date": "this weekend",
"forecast": "rainy"
}
# 3. Tool mapping
tools_map = {
"get_weather_forecast": get_weather_forecast
}
# 4. Define structured output schema using Pydantic
class DecisionStep(BaseModel):
step: int = Field(description="Step number in the decision process")
reasoning: str = Field(description="Reasoning behind this step")
action: str = Field(description="Suggested action at this step")
class DecisionPlan(BaseModel):
situation: str = Field(description="The initial situation to consider")
steps: List[DecisionStep] = Field(description="List of reasoning steps leading to the final action")
# 5. Defining messages: system prompt and input
messages = [
{"role": "system", "content": (
"You are an expert travel planner. When asked about weekend plans, "
"first get the weather forecast via the tool provided. Then, based on the result, "
"break down your reasoning into exactly 3 steps and return structured JSON only."
)},
{"role": "user", "content": input("> ")} # enter the question in the terminal
]
# 6. First API call to trigger the tool call
response = client.chat.completions.create(
model="grok-3",
messages=messages,
tools=tools,
tool_choice="auto",
)
tool_calls = getattr(response.choices[0].message, "tool_calls", [])
if tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
if function_name in tools_map:
function_result = tools_map[function_name](**function_args)
# Add the assistant's tool call message and the tool result to the message history
messages.append(response.choices[0].message)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(function_result)
})
# 7. Second API call with parse() to get structured output
final_response = client.beta.chat.completions.parse(
model="grok-3",
messages=messages,
response_format=DecisionPlan
)
plan = final_response.choices[0].message.parsed
# 8. Use the output
final_action = plan.steps[-1].action
print(f"\nSummary:")
print(f"Situation: {plan.situation}")
print(f"Recommended Action: {final_action}")
else:
print("No tool call was requested.")Um die App auszuprobieren, navigieren wir in unser Projektverzeichnis, laden unsere Umgebung und führen das Skript aus:
cd <your/working/directory>
conda activate grok3
python app.pyWenn wir nach einem Tipp für Helsinki fragen, antwortet unsere Grok-App:

Das ist ein guter Vorschlag, das kann ich aus Erfahrung sagen!
Wir haben viel besprochen - lass uns einpacken. Wir haben uns angeschaut, wie man mit der Grok 3 API arbeitet, um einfache Abfragen auszuführen, Argumentationsspuren zu bearbeiten und erweiterte Funktionen wie Funktionsaufrufe und strukturierte Ausgaben zu nutzen.
Wir haben diese Fähigkeiten in einem kleinen Projekt kombiniert, das zeigte, wie Grok externe Tools nutzen und strukturierte, umsetzbare Antworten liefern kann. In Kombination mit APIs - in unserem Fall eine Wetter-API - können leistungsstarke Anwendungen erstellt werden, die die Stärken von Grok 3 voll ausschöpfen.
Wenn du es bis hierher geschafft hast, bist du wahrscheinlich daran interessiert, mehr über LLMs zu erfahren. Sieh dir auch diese Ressourcen an:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Tutorial
Mark Pedigo
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
Tutorial
Matt Crabtree
Tutorial
Adel Nehme

