Stell dir vor, du trainierst ein maschinelles Lernmodell, bist dir aber nicht sicher, wie es bei neuen, ungesehenen Daten abschneiden wird. Hier kommt die K-Fold Cross-Validation ins Spiel. Sie bietet einen Vorgeschmack darauf, wie dein Modell in der realen Welt abschneiden könnte. Diese Technik stellt sicher, dass deine Vorhersagen nicht nur einmalig sind, sondern auch bei neuen, unbekannten Datensätzen zuverlässig sind.
In diesem Leitfaden werden wir die Grundlagen der K-Fold Cross-Validation erläutern und sie mit einfacheren Methoden wie dem Train-Test Split vergleichen. Du wirst verschiedene Methoden der Kreuzvalidierung mit Python kennenlernen und verstehen, warum die Wahl der richtigen Methode große Auswirkungen auf deine Projekte haben kann. Am Ende wirst du in der Lage sein, diese Strategien mit scikit-Learn anzuwenden.
Lass uns eintauchen und lernen, wie du deine Bemühungen um maschinelles Lernen wirklich verlässlich machst!
Was ist K-Fold Cross-Validation?
Die K-Fold Cross-Validation ist eine robuste Technik, um die Leistung von Machine-Learning-Modellen zu bewerten. Es hilft sicherzustellen, dass das Modell gut auf ungesehene Daten verallgemeinert werden kann, indem verschiedene Teile des Datensatzes zum Trainieren und Testen in mehreren Iterationen verwendet werden.
K-Fold Cross-Validation vs. Zug-Test-Teilung
Während die K-Fold Cross-Validation den Datensatz in mehrere Teilmengen aufteilt, um das Modell iterativ zu trainieren und zu testen, unterteilt die Train-Test Split-Methode den Datensatz in nur zwei Teile: einen zum Trainieren und einen zum Testen. Die Train-Test-Split-Methode ist einfach und schnell zu implementieren, aber die Leistungseinschätzung kann stark vom jeweiligen Split abhängen, was zu einer hohen Streuung der Ergebnisse führt.
Die Bilder unten veranschaulichen die strukturellen Unterschiede zwischen diesen beiden Methoden. Das erste Bild zeigt die Train-Test-Split-Methode, bei der der Datensatz in 80% Trainings- und 20% Testsegmente unterteilt wird.
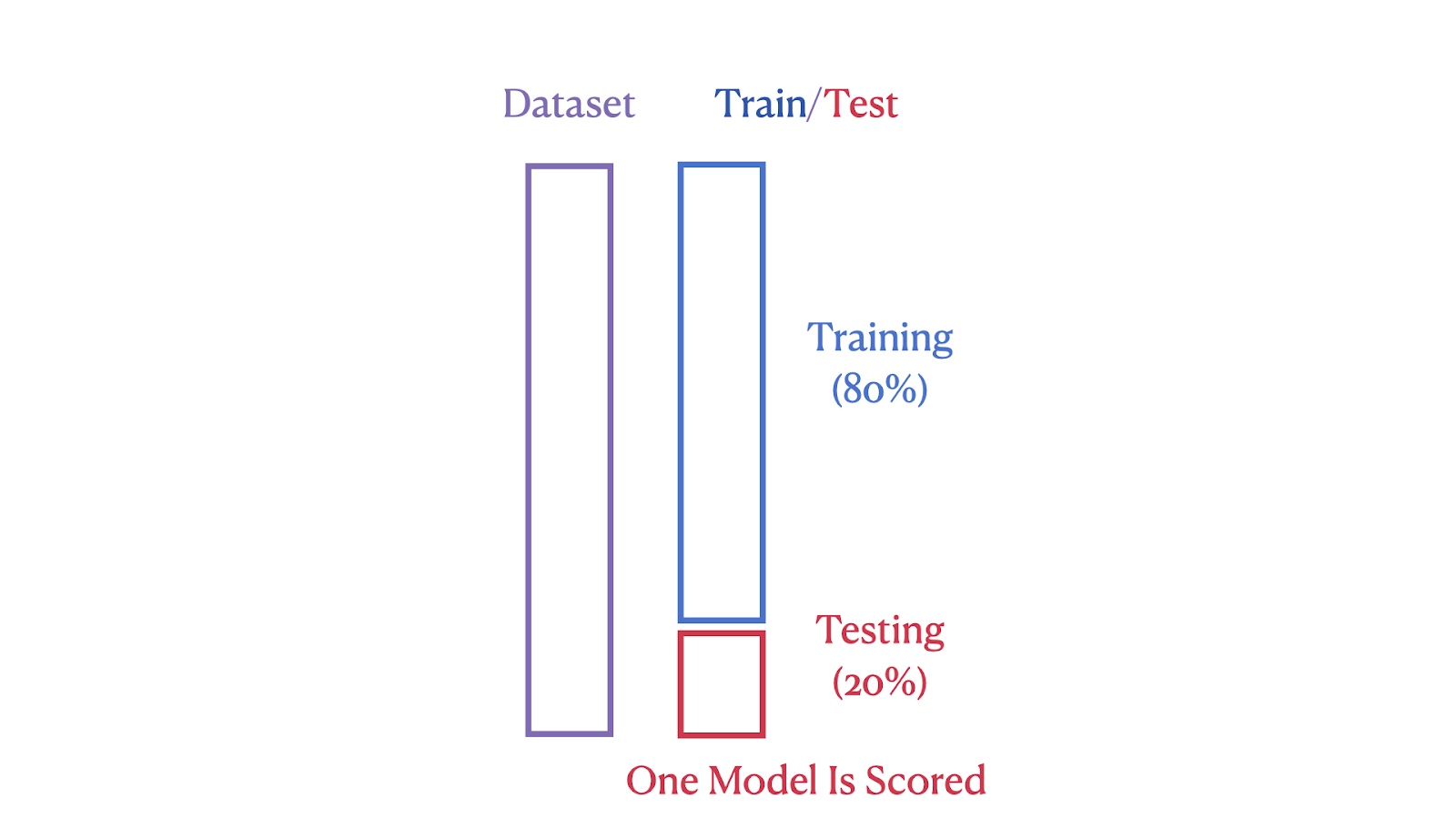
Zug/Test Split Illustration. Bild vom Autor
Das zweite Bild zeigt eine 5-fache Kreuzvalidierung, bei der der Datensatz in fünf Teile aufgeteilt wird, wobei jeder Teil in einer der fünf Iterationen als Testsatz dient, um sicherzustellen, dass jedes Segment sowohl zum Training als auch zum Testen verwendet wird.
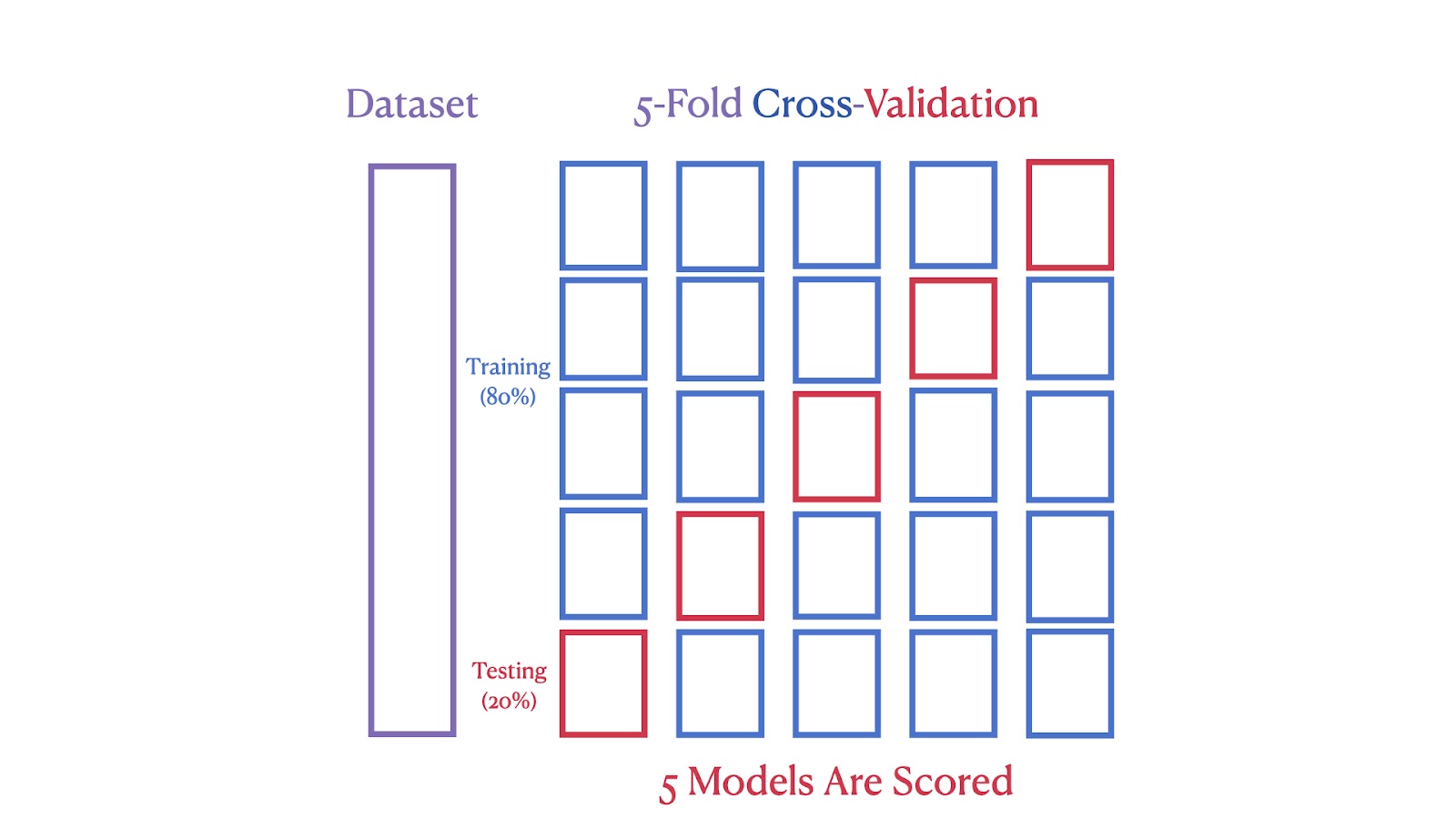
5-Fold Cross-Validation Schema. Bild vom Autor
Wir sehen, dass die K-Fold Cross-Validation eine robustere und zuverlässigere Leistungsschätzung liefert, weil sie die Auswirkungen der Datenvariabilität reduziert. Durch die Verwendung mehrerer Trainings- und Testzyklen wird das Risiko einer Überanpassung an einen bestimmten Datensplit minimiert. Diese Methode stellt außerdem sicher, dass jeder Datenpunkt sowohl für das Training als auch für die Validierung verwendet wird, was zu einer umfassenderen Bewertung der Leistung des Modells führt.
Implementierung von K-Fold Cross-Validation in Python mit scikit-learn
Jetzt wollen wir die K-Fold Cross-Validation mit dem California Housing Dataset demonstrieren, um die Leistung eines linearen Regressionsmodells zu bewerten. Diese Methode liefert eine robuste Schätzung der Modellgenauigkeit, indem sie iterativ verschiedene Teilmengen des Datensatzes testet und so eine umfassende Bewertung gewährleistet.
Überblick über den Datensatz "California Housing
Der California Housing Dataset, der von Pace und Barry (1997) zusammengestellt wurde, enthält Daten aus dem U.S.-amerikanischen Wohnungsmarkt von 1990. Volkszählung zum Wohnungsbau in Kalifornien. Sie enthält 20.640 Beobachtungen mit Merkmalen wie Standort, Alter der Wohnungen und Bevölkerung. Die Zielvariable ist der Medianwert der Häuser in den kalifornischen Bezirken.
Der Datensatz enthält eine Vielzahl von geografischen, demografischen und wirtschaftlichen Merkmalen und eignet sich daher gut für Data Science und maschinelles Lernen. Wir beginnen unser Programmierbeispiel, indem wir es direkt aus der scikit-Learn-Bibliothek herunterladen.
Laden des Datensatzes
Bevor wir mit dem Modelltraining und der Auswertung beginnen, müssen wir den Datensatz laden.
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing()Dieser Code importiert die Funktion fetch_california_housing von sklearn.datasets und ruft sie dann auf, um den Datensatz "California Housing" zu laden. Dieser Datensatz wird in den Variablendaten gespeichert, die sowohl die Merkmale als auch die Zielvariable enthalten.
Aufbereitung der Daten
Sobald der Datensatz geladen ist, besteht der nächste Schritt darin, die Daten für die Analyse vorzubereiten.
import pandas as pd
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.targetHier verwenden wir die Pandas-Bibliothek, um einen DataFrame X zu erstellen, der die Merkmalsdaten aus data.data enthält. Die Spalten des DataFrame werden mit data.feature_names beschriftet. Die Zielvariable, die den Median der Hauswerte darstellt, wird separat in y gespeichert.
Einrichten der K-Fold Cross-Validation
Jetzt ist es an der Zeit, unser Modell einzurichten und einen Wert für K zu wählen. Die Wahl des richtigen Werts für K ist ein wichtiger Schritt, den wir weiter unten im Detail behandeln werden.
from sklearn.model_selection import KFold
k = 5
kf = KFold(n_splits=k, shuffle=True, random_state=42)Dieser Code initialisiert die K-Fold Cross-Validation mit Hilfe der KFold-Klasse von sklearn.model_selection. Wir haben die Instanz kf mit 5 Splits eingerichtet. Die Option shuffle=True sorgt für eine zufällige Reihenfolge der Datenpunkte, und random_state=42 stellt sicher, dass die Reihenfolge über mehrere Durchläufe hinweg konsistent ist. Dieser Aufbau ist in der Regel ausreichend, um die Leistung eines Modells mit Kreuzvalidierung zu bewerten.
Initialisierung des Modells
Nachdem wir unsere Daten vorbereitet und die Kreuzvalidierung eingerichtet haben, müssen wir im nächsten Schritt das Modell auswählen und initialisieren.
from sklearn.linear_model import LinearRegression
model = LinearRegression()Wir importieren die Klasse LinearRegression von sklearn.linear_model und erstellen ein Instanzmodell. Dieses Modell wird verwendet, um eine lineare Regression für den Datensatz durchzuführen.
Durchführung der Kreuzvalidierung
Jetzt, da das Modell initialisiert ist, können wir zum spannenden Teil übergehen und eine Kreuzvalidierung durchführen, um die Leistung des Modells auf verschiedenen Teilmengen der Daten zu bewerten.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=kf, scoring='r2')In dieser Zeile wird die Funktion cross_val_score verwendet, um das Modell anhand des Datensatzes X und des Ziels y auszuwerten. Die Kreuzvalidierung wird mit der Instanz Kfold kf durchgeführt, und die Leistung des Modells wird mit dem R²-Wert gemessen.
Berechnung der durchschnittlichen R2-Punktzahl
Mit dem R-Quadrat können wir den Anteil der Varianz in der abhängigen Variable bewerten, der sich aus den unabhängigen Variablen vorhersagen lässt. Dies gibt Aufschluss darüber, wie gut das Regressionsmodell passt.
import numpy as np
average_r2 = np.mean(scores)
print(f"R² Score for each fold: {[round(score, 4) for score in scores]}")
print(f"Average R² across {k} folds: {average_r2:.2f}")In diesem Teil wird der durchschnittliche R²-Wert für alle Faltungen berechnet. Die Noten für jede Falte werden zuerst gedruckt, gefolgt von der Durchschnittsnote. Durch die Verwendung von np.mean() wird der Mittelwert der während der Kreuzvalidierung gesammelten Punkte berechnet.
Anzeige der Endergebnisse
Wir fassen nun die Ergebnisse zusammen, um ein umfassendes Verständnis für die Leistung des Modells zu erhalten. Der durchschnittliche R²-Wert liefert eine einzige Kennzahl, die die Effektivität des Modells angibt.
R² Score for each fold: [0.5758, 0.6137, 0.6086, 0.6213, 0.5875]
Average R² across 5 folds: 0.60Dies ist die Ausgabe des Codes aus dem vorherigen Schritt. Sie zeigt die R²-Werte für jede Falte und den durchschnittlichen R²-Wert an.
Was bedeutet "K" bei der K-Fold Cross-Validation?
Bei der K-fachen Kreuzvalidierung steht "K" für die Anzahl der Gruppen, in die der Datensatz unterteilt wird. Diese Zahl legt fest, wie viele Testrunden das Modell durchläuft, um sicherzustellen, dass jedes Segment einmal als Testsatz verwendet wird.
Hier ist eine Heuristik:
- K = 2 oder 3: Diese Wahl kann von Vorteil sein, wenn die Rechenressourcen begrenzt sind oder wenn eine schnellere Auswertung benötigt wird. Sie reduzieren die Anzahl der Trainingszyklen und sparen so Zeit und Rechenleistung, während sie dennoch eine vernünftige Schätzung der Modellleistung liefern.
- K = 5 oder 10: Die Wahl von K = 5 oder K = 10 ist beliebt, weil sie ein gutes Gleichgewicht zwischen Rechenleistung und Schätzung der Modellleistung bietet.
- K = 20: Die Verwendung eines größeren Werts von K kann eine detailliertere Leistungsbewertung ermöglichen. Dies erhöht jedoch den Rechenaufwand und kann zu einer höheren Varianz führen, wenn die Teilmengen zu klein sind.
Wenn du mehr über die Schätzung der Modellleistung erfahren möchtest, solltest du unseren umfassenden Kurs "Modellvalidierung in Python " besuchen.
Wichtige Überlegungen bei der Verwendung von K-Fold Cross-Validation
Der Einfluss von "K" in der K-Fold Cross-Validation
Die Anzahl der Foldings oder "K" bei der K-Fold Cross-Validation beeinflusst sowohl die Granularität des Validierungsprozesses als auch den Rechenaufwand. Ein kleineres K (z. B. 3-5) ist zwar schneller, könnte aber weniger zuverlässige Schätzungen liefern, da jeder Fold einen größeren Teil des Datensatzes repräsentiert und damit möglicherweise verschiedene Datenszenarien übersehen werden. Ein größeres K (z. B. 10) ermöglicht eine detailliertere Auswertung auf Kosten eines höheren Rechenaufwands. Ein üblicher Ausgangspunkt ist K=5 oder K=10, die oft ausreichen, um eine zuverlässige Schätzung ohne übermäßige Berechnungen zu erhalten.
Die Bedeutung der Datenmischung bei der K-Fold Cross-Validation
Es wird dringend empfohlen, die Daten bei der K-Fold Cross-Validation zu mischen, um die Validität der Modellbewertung zu erhöhen. Wenn du shuffle=True einstellst, wird jede inhärente Ordnung im Datensatz unterbrochen, die während des Validierungsprozesses zu Verzerrungen führen könnte. Dadurch wird sichergestellt, dass jeder Fold repräsentativ für den gesamten Datensatz ist, was entscheidend dafür ist, wie gut das Modell auf neue Daten verallgemeinert werden kann. In Fällen, in denen die Reihenfolge der Datenpunkte sinnvoll ist, wie z. B. bei Zeitreihendaten, ist es jedoch wichtig, das Mischen zu vermeiden, um die Integrität des Lernprozesses zu wahren.
Sicherstellung der Reproduzierbarkeit bei der K-Fold Cross-Validation
Die Reproduzierbarkeit der Ergebnisse der K-Fold Cross-Validation ist entscheidend für die Überprüfung der Modellstabilität und -leistung. Das kannst du erreichen, indem du den random_state-Parameter setzt, der dafür sorgt, dass die Daten in den verschiedenen Durchläufen gleichmäßig gemischt werden, damit die Daten identisch aufgeteilt werden und die Ergebnisse reproduzierbar sind.
Standard K-Fold vs. Andere Kreuzvalidierungsmethoden
Die Wahl der richtigen Kreuzvalidierungstechnik ist entscheidend für die Erstellung zuverlässiger maschineller Lernmodelle. Die Wahl hängt stark von den spezifischen Merkmalen des Datensatzes und der Art der maschinellen Lernaufgabe ab, um die es geht. Verschiedene Techniken wurden entwickelt, um verschiedene Herausforderungen wie unausgewogene Daten oder gruppierte Datenstrukturen zu bewältigen.
In der folgenden Tabelle findest du einen umfassenden Vergleich der gängigsten Kreuzvalidierungsmethoden. Dabei werden ihre einzigartigen Merkmale und besten Anwendungsfälle hervorgehoben, damit du die effektivste Technik für deine speziellen Modellierungsanforderungen auswählen kannst.
| Art des Lebenslaufs | Verwendung | Beschreibung | Wann verwendet man |
|---|---|---|---|
| Standard K-Fold Cross-Validation | Sowohl Regression als auch Klassifizierung | Teilt den Datensatz in k gleich große Foldings. Jede Falte wird einmal als Testsatz verwendet. | Am besten für ausgewogene Datensätze, um eine umfassende Modellbewertung zu gewährleisten. |
| Stratifizierte K-Fold Cross-Validation | In erster Linie Klassifizierung | Behält den gleichen Anteil an Klassenlabels in jeder Falte bei wie der Originaldatensatz. | Ideal für Klassifizierungsaufgaben mit unausgewogenen Klassen, um die Gruppenproportionen zu erhalten. |
| Leave-One-Out Cross-Validation (LOOCV) | Sowohl Regression als auch Klassifizierung | Jeder Datenpunkt wird einmal als Testsatz verwendet, der Rest als Training. | Großartig für kleine Datensätze, um die Trainingsdaten zu maximieren, allerdings rechenintensiv. |
| Leave-P-Out Cross-Validation | Sowohl Regression als auch Klassifizierung | Ähnlich wie LOOCV, lässt aber p Datenpunkte für den Testsatz aus. | Ideal für kleine Datensätze, um zu testen, wie sich Änderungen in den Datenproben auf die Modellstabilität auswirken. |
| Gruppe K-Fold Cross-Validation | Sowohl Regression als auch Klassifizierung mit Gruppen | Stellt sicher, dass keine Gruppe sowohl in der Trainings- als auch in der Testmenge enthalten ist, was nützlich ist, wenn die Datenpunkte nicht unabhängig sind. | Ideal für Datensätze mit logischen Gruppierungen, um die Leistung unabhängiger Gruppen zu testen. |
| Stratifizierte Gruppe K-Fold Cross-Validation | Vor allem Klassifizierung mit gruppierten Daten | Kombiniert Schichtung und Gruppenintegrität und stellt sicher, dass Gruppen nicht über Falten hinweg aufgeteilt werden. | Ideal für gruppierte und unausgewogene Datensätze, um sowohl die Klassen- als auch die Gruppenintegrität zu wahren. |
Fazit
Dieser Leitfaden hat dir gezeigt, wie die K-Fold Cross-Validation ein leistungsfähiges Werkzeug für die Bewertung von Machine Learning-Modellen ist. Das ist besser als der einfache Train-Test-Split, denn er testet das Modell an verschiedenen Teilen deiner Daten und hilft dir, darauf zu vertrauen, dass es auch bei ungesehenen Daten gut funktioniert.
Wenn du dich mit maschinellem Lernen beschäftigst, findest du hier einige gute Ressourcen, die dir weiterhelfen:
- DataCamp's Supervised Learning with Scikit-Learn Kurs: Dieser Kurs hilft dir, die prädiktive Modellierung in den Griff zu bekommen. Es ist praxisnah und ideal, um deine Reise zu beginnen. Schau dir den Kurs hier an.
- Maschinelles Lernen mit Python Tutorial: In diesem Lernprogramm werden die wichtigsten Ideen des maschinellen Lernens aufgeschlüsselt und dir gezeigt, wie du sie anwenden kannst. Es ist perfekt, um zu festigen, was du weißt. Lies die Anleitung hier.
- Scikit-Learn Spickzettel: Halte diesen Spickzettel bereit. Sie ist perfekt, um dich bei der Arbeit an Projekten schnell daran zu erinnern, wie du die Funktionen des maschinellen Lernens nutzen kannst. Hol dir den Spickzettel hier.
- DataCamp's Kaggle Competition Kurs: Wenn du deine Fähigkeiten auf die Probe stellen willst, ist dieser Kurs großartig. Hier lernst du, wie du in Kaggle-Wettbewerben glänzen kannst, in denen du das Gelernte auf spielerische Art und Weise anwenden kannst. Starte den Kurs hier.
Diese Ressourcen sollen dir helfen, egal ob du gerade erst anfängst oder deine Kenntnisse auffrischen willst. Sie bieten eine Mischung aus Theorie und praktischen Tipps und sorgen dafür, dass du gut vorbereitet bist, um genaue Modelle zu bauen und zu verfeinern.