Imaginez que vous êtes en train de former un modèle d'apprentissage automatique, mais que vous n'êtes pas sûr de ses performances sur de nouvelles données inédites. C'est là qu'intervient la validation croisée K-Fold. Il donne un aperçu de la façon dont votre modèle pourrait se comporter dans le monde réel. Cette technique permet de s'assurer que vos prédictions ne sont pas le fruit d'un coup d'essai, mais qu'elles sont toujours fiables pour de nouveaux ensembles de données inédits.
Dans ce guide, nous aborderons les bases de la validation croisée K-Fold et nous la comparerons à des méthodes plus simples telles que la division Train-Test. Vous explorerez diverses méthodes de validation croisée à l'aide de Python et comprendrez pourquoi le choix de la bonne méthode peut avoir un impact considérable sur vos projets. A la fin, vous serez équipé pour appliquer ces stratégies avec scikit-Learn.
Plongeons dans le vif du sujet et découvrons comment rendre vos efforts en matière d'apprentissage automatique vraiment fiables !
Qu'est-ce que la validation croisée K-Fold ?
La validation croisée K-Fold est une technique robuste utilisée pour évaluer les performances des modèles d'apprentissage automatique. Elle permet de s'assurer que le modèle se généralise bien à des données inédites en utilisant différentes parties de l'ensemble de données pour l'entraînement et le test lors de plusieurs itérations.
Validation croisée K-Fold vs. Séparation de la formation et du test
Alors que la validation croisée K-Fold divise l'ensemble de données en plusieurs sous-ensembles pour former et tester le modèle de manière itérative, la méthode Train-Test Split divise l'ensemble de données en deux parties seulement : l'une pour la formation et l'autre pour le test. La méthode Train-Test Split est simple et rapide à mettre en œuvre, mais l'estimation des performances peut dépendre fortement de la répartition spécifique, ce qui entraîne une grande variance dans les résultats.
Les images ci-dessous illustrent les différences structurelles entre ces deux méthodes. La première image montre la méthode Train-Test Split, dans laquelle l'ensemble de données est divisé en 80 % de segments de formation et 20 % de segments de test.
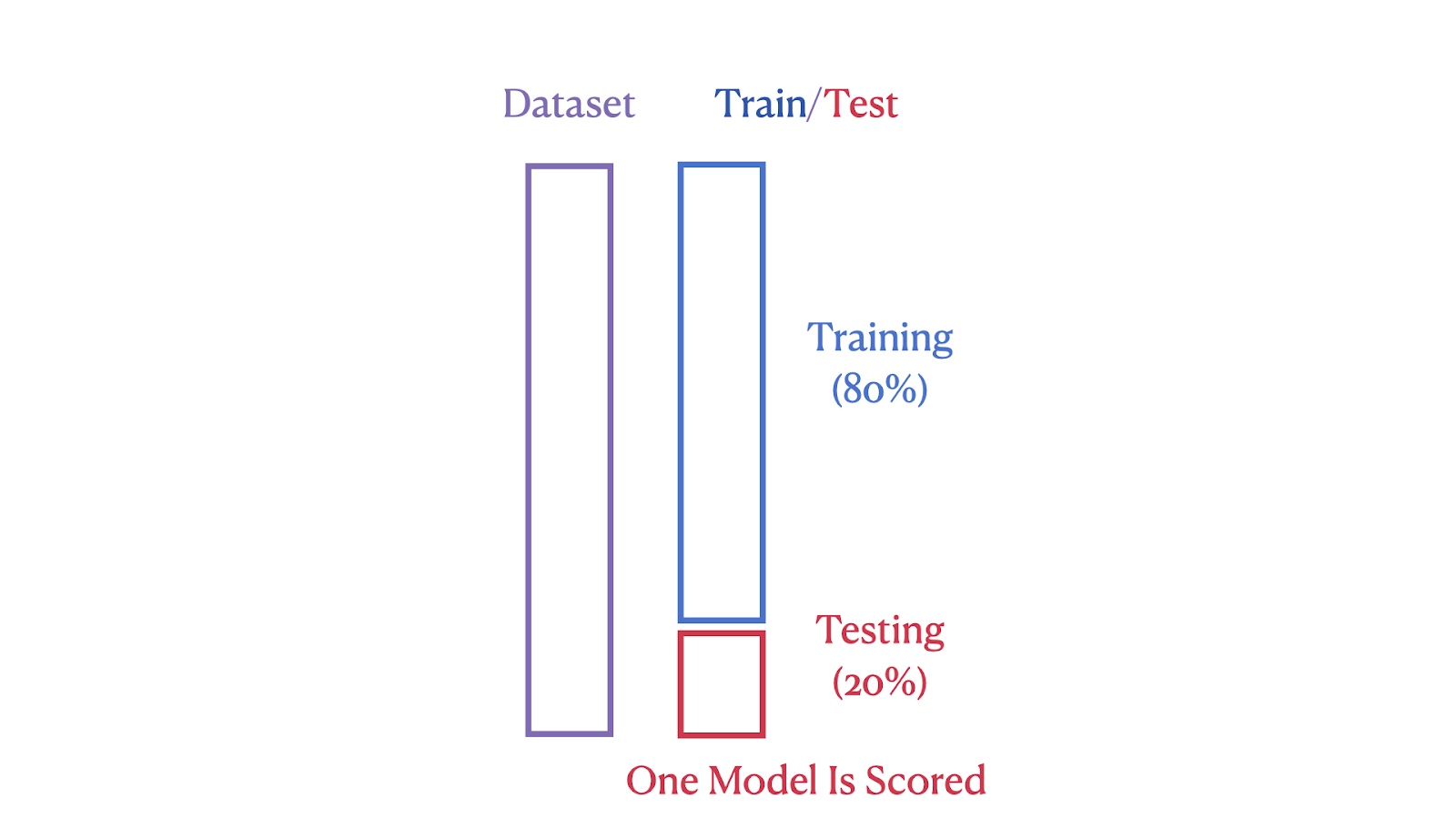
Illustration de la division formation/essai. Image par l'auteur
La deuxième image illustre une validation croisée 5 fois, où l'ensemble de données est divisé en cinq parties, chaque partie servant d'ensemble de test dans l'une des cinq itérations, en veillant à ce que chaque segment soit utilisé à la fois pour la formation et le test.
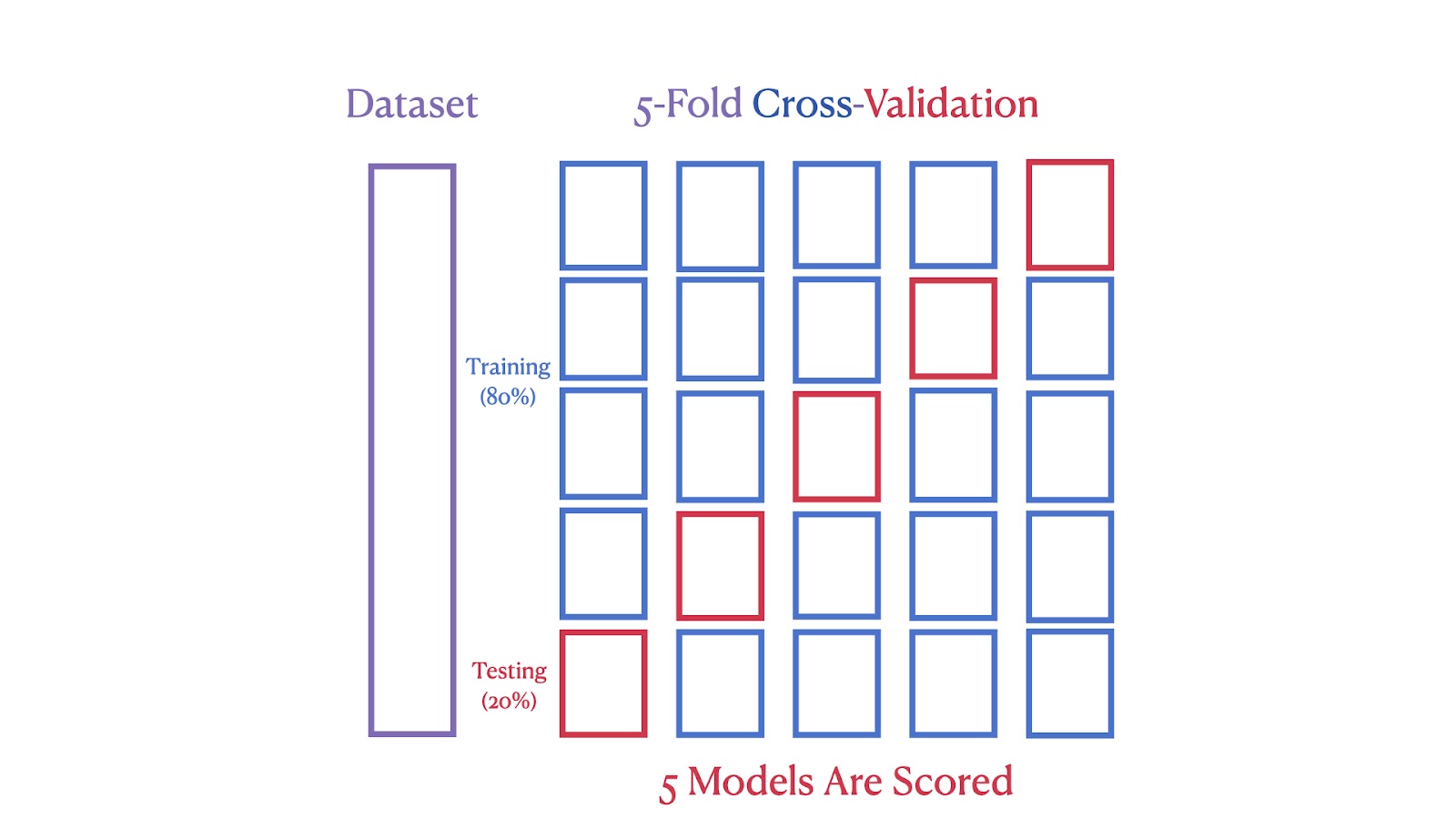
Schéma de validation croisée à cinq niveaux. Image par l'auteur
Nous pouvons constater que la validation croisée K-Fold fournit une estimation des performances plus robuste et plus fiable, car elle réduit l'impact de la variabilité des données. En utilisant plusieurs cycles de formation et de test, il minimise le risque de surajustement à une répartition particulière des données. Cette méthode garantit également que chaque point de données est utilisé à la fois pour la formation et la validation, ce qui permet une évaluation plus complète des performances du modèle.
Implémentation de la validation croisée K-Fold en Python à l'aide de scikit-learn
Démontrons maintenant la validation croisée K-Fold à l'aide de l'ensemble de données sur le logement en Californie pour évaluer les performances d'un modèle de régression linéaire. Cette méthode fournit une estimation robuste de la précision du modèle en effectuant des tests itératifs sur différents sous-ensembles de l'ensemble de données, garantissant ainsi une évaluation complète.
Aperçu de l'ensemble de données sur le logement en Californie
Le California Housing Dataset, compilé par Pace et Barry (1997), contient des données provenant de l'enquête américaine de 1990. Recensement sur le logement en Californie. Il comprend 20 640 observations avec des caractéristiques telles que la localisation, l'âge du logement et la population. La variable cible est la valeur médiane des maisons dans les districts de Californie.
L'ensemble de données fournit un ensemble diversifié de caractéristiques géographiques, démographiques et économiques, ce qui le rend bien adapté à la science des données et aux applications d'apprentissage automatique. Nous commencerons notre exemple de codage en le téléchargeant directement à partir de la bibliothèque scikit-Learn.
Chargement du jeu de données
Avant de commencer l'apprentissage et l'évaluation du modèle, nous devons charger l'ensemble de données.
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing()Ce code importe la fonction fetch_california_housing de sklearn.datasets et l'appelle pour charger l'ensemble de données sur le logement en Californie. Cet ensemble de données est stocké dans les données variables, qui contiennent à la fois les caractéristiques et la variable cible.
Préparation des données
Une fois l'ensemble de données chargé, l'étape suivante consiste à préparer les données pour l'analyse.
import pandas as pd
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.targetIci, nous utilisons la bibliothèque pandas pour créer un DataFrame X contenant les données de caractéristiques provenant de data.data. Les colonnes du DataFrame sont étiquetées à l'aide de data.feature_names. La variable cible, qui représente la valeur médiane des maisons, est stockée séparément à l'adresse y.
Configuration de la validation croisée K-Fold
Il est maintenant temps de configurer notre modèle, notamment en choisissant une valeur pour K. Le choix de la bonne valeur pour K est une étape importante que nous aborderons en détail ci-dessous.
from sklearn.model_selection import KFold
k = 5
kf = KFold(n_splits=k, shuffle=True, random_state=42)Ce code initialise la validation croisée K-Fold en utilisant la classe KFold de sklearn.model_selection. Nous avons mis en place l'instance kf avec 5 divisions. L'option shuffle=True randomise l'ordre des points de données, et l'option random_state=42 garantit que ce mélange est cohérent sur plusieurs exécutions. Cette configuration est généralement suffisante pour commencer à évaluer les performances d'un modèle par validation croisée.
Initialisation du modèle
Une fois nos données préparées et la validation croisée mise en place, l'étape suivante consiste à choisir et à initialiser le modèle.
from sklearn.linear_model import LinearRegression
model = LinearRegression()Nous importons la classe LinearRegression de sklearn.linear_model et créons un modèle d'instance. Ce modèle sera utilisé pour effectuer une régression linéaire sur l'ensemble des données.
Effectuer une validation croisée
Maintenant que le modèle est initialisé, nous pouvons passer à la partie la plus amusante et effectuer une validation croisée pour évaluer ses performances sur différents sous-ensembles de données.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=kf, scoring='r2')Cette ligne utilise la fonction cross_val_score pour évaluer le modèle à l'aide du jeu de données X et de la cible y. La validation croisée est effectuée à l'aide de l'instance Kfold kf , et la performance du modèle est mesurée à l'aide du score R².
Calcul de la note moyenne R2
Nous pouvons utiliser le R au carré comme mesure pour évaluer la proportion de la variance de la variable dépendante qui est prévisible à partir des variables indépendantes, ce qui donne une idée de la qualité de l'ajustement du modèle de régression.
import numpy as np
average_r2 = np.mean(scores)
print(f"R² Score for each fold: {[round(score, 4) for score in scores]}")
print(f"Average R² across {k} folds: {average_r2:.2f}")Cette partie calcule le score R² moyen pour tous les plis. Les notes de chaque pli sont imprimées en premier, suivies de la note moyenne. L'utilisation de np.mean() permet de calculer la moyenne des scores recueillis au cours de la validation croisée.
Affichage des résultats finaux
Nous agrégeons maintenant les résultats pour obtenir une compréhension globale de la performance du modèle. Le score R² moyen fournit une mesure unique indiquant l'efficacité du modèle.
R² Score for each fold: [0.5758, 0.6137, 0.6086, 0.6213, 0.5875]
Average R² across 5 folds: 0.60Voici le résultat du code de l'étape précédente. Il indique les scores R² pour chaque pli et le score R² moyen.
Que représente "K" dans la validation croisée K-Fold ?
Dans la validation croisée K-Fold, "K" représente le nombre de groupes dans lesquels l'ensemble de données est divisé. Ce nombre détermine le nombre de cycles de tests que le modèle subit, en veillant à ce que chaque segment soit utilisé une fois comme ensemble de tests.
Voici une méthode heuristique :
- K = 2 ou 3 : Ces choix peuvent s'avérer utiles lorsque les ressources informatiques sont limitées ou lorsqu'une évaluation plus rapide est nécessaire. Ils réduisent le nombre de cycles d'apprentissage, ce qui permet d'économiser du temps et de la puissance de calcul tout en fournissant une estimation raisonnable de la performance du modèle.
- K = 5 ou 10 : Les choix de K = 5 ou K = 10 sont populaires car ils offrent un bon équilibre entre l'efficacité du calcul et l'estimation de la performance du modèle.
- K = 20 : L'utilisation d'une valeur plus élevée de K permet d'obtenir une évaluation plus détaillée des performances. Cependant, elle augmente la charge de calcul et peut entraîner une variance plus élevée si les sous-ensembles sont trop petits.
Pour en savoir plus sur l'estimation des performances des modèles, pensez à suivre notre cours complet Validation de modèle en Python.
Considérations clés lors de l'utilisation de la validation croisée K-Fold
L'impact de "K" dans la validation croisée K-Fold
Le nombre de plis, ou "K", dans la validation croisée K-Fold affecte à la fois la granularité du processus de validation et la charge de calcul. Un K plus petit (par exemple, 3-5) pourrait être plus rapide mais pourrait produire des estimations moins fiables car chaque pli représente une plus grande partie de l'ensemble de données, ce qui pourrait entraîner l'omission de divers scénarios de données. Un K plus grand (par exemple, 10) permet une évaluation plus détaillée au prix d'une augmentation des calculs. Un point de départ courant est K=5 ou K=10, qui sont souvent suffisants pour obtenir une estimation fiable sans calculs excessifs.
Importance du brassage des données dans la validation croisée K-Fold
Il est fortement recommandé de mélanger les données lors de la validation croisée K-Fold afin d'améliorer la validité de l'évaluation du modèle. En paramétrant shuffle=True, vous brisez tout ordre inhérent à l'ensemble de données qui pourrait introduire un biais au cours du processus de validation. Cela permet de s'assurer que chaque pli est représentatif de l'ensemble des données, ce qui est essentiel pour évaluer la capacité du modèle à s'adapter à de nouvelles données. Toutefois, il est important d'éviter le brassage dans les cas où la séquence des points de données est significative, comme dans le cas des séries chronologiques, afin de préserver l'intégrité du processus d'apprentissage.
Assurer la reproductibilité de la validation croisée K-Fold
Il est essentiel de s'assurer que les résultats de la validation croisée K-Fold sont reproductibles pour vérifier la stabilité et les performances du modèle. Pour ce faire, vous pouvez définir le paramètre random_state, qui assure un brassage cohérent des données entre les différentes exécutions, ce qui permet de diviser les données de manière identique et donc d'obtenir des résultats reproductibles.
K-Fold standard vs. Autres méthodes de validation croisée
Le choix de la bonne technique de validation croisée est crucial pour construire des modèles d'apprentissage automatique fiables. Le choix dépend fortement des caractéristiques spécifiques de l'ensemble de données et du type de tâche d'apprentissage automatique à accomplir. Différentes techniques sont conçues pour relever divers défis tels que les données déséquilibrées ou les structures de données groupées.
Le tableau ci-dessous présente une comparaison complète des diverses méthodes de validation croisée les plus populaires, en soulignant leurs caractéristiques uniques et leurs meilleurs cas d'utilisation afin de vous guider dans le choix de la technique la plus efficace pour vos besoins de modélisation spécifiques.
| Type de CV | Utilisation | Description | Quand utiliser |
|---|---|---|---|
| Validation croisée K-Fold standard | La régression et la classification | Divise l'ensemble de données en k plis de taille égale. Chaque pli est utilisé une fois comme ensemble de test. | Il est préférable d'utiliser des ensembles de données équilibrés pour garantir une évaluation complète du modèle. |
| Validation croisée K-Fold stratifiée | Principalement la classification | Maintient la même proportion d'étiquettes de classe dans chaque pli que l'ensemble de données original. | Idéal pour les tâches de classification avec des classes déséquilibrées afin de maintenir les proportions des groupes. |
| Validation croisée sans interruption (LOOCV) | La régression et la classification | Chaque point de données est utilisé une fois comme ensemble de test, le reste étant utilisé comme formation. | Idéal pour les petits ensembles de données afin de maximiser les données d'entraînement, mais très gourmand en ressources informatiques. |
| Validation croisée sans interruption | La régression et la classification | Semblable à LOOCV, mais sans les p points de données de l'ensemble de test. | Idéal pour les petits ensembles de données afin de tester comment les changements dans les échantillons de données affectent la stabilité du modèle. |
| Validation croisée K-Fold par groupe | Régression et classification avec groupes | Assure qu'aucun groupe ne se trouve à la fois dans les ensembles de formation et de test, ce qui est utile lorsque les points de données ne sont pas indépendants. | Idéal pour les ensembles de données avec des regroupements logiques afin de tester les performances sur des groupes indépendants. |
| Validation croisée K-Fold pour les groupes stratifiés | Principalement la classification avec des données groupées | Combine la stratification et l'intégrité des groupes, en veillant à ce que les groupes ne soient pas divisés entre les plis. | Idéal pour les ensembles de données groupés et déséquilibrés afin de maintenir l'intégrité des classes et des groupes. |
Conclusion
Ce guide vous a montré comment la validation croisée K-Fold est un outil puissant pour évaluer les modèles d'apprentissage automatique. Cette méthode est plus efficace que la simple division Train-Test, car elle permet de tester le modèle sur différentes parties de vos données, ce qui vous permet de vous assurer qu'il fonctionnera également sur des données non visibles.
Si vous souhaitez vous lancer dans l'apprentissage automatique, voici quelques ressources intéressantes pour vous aider :
- Cours de DataCamp sur l'apprentissage supervisé avec Scikit-Learn : Ce cours vous permet de vous familiariser avec la modélisation prédictive. Il s'agit d'une formation pratique, idéale pour commencer votre voyage. Consultez le cours ici.
- Tutoriel sur l'apprentissage automatique avec Python : Ce didacticiel décompose les idées clés de l'apprentissage automatique et vous montre comment les appliquer. Il est parfait pour consolider ce que vous savez. Lisez le tutoriel ici.
- Scikit-Learn Cheat Sheet : Gardez cet aide-mémoire à portée de main. Elle est idéale pour vous rappeler rapidement comment utiliser les fonctions d'apprentissage automatique lorsque vous travaillez sur des projets. Obtenez l'aide-mémoire ici.
- Cours sur la compétition Kaggle de DataCamp : Si vous souhaitez mettre vos compétences à l'épreuve, ce cours est idéal. Il vous apprend à briller lors des concours Kaggle, où vous pouvez mettre en pratique ce que vous avez appris de manière ludique et compétitive. Commencez le cours ici.
Ces ressources sont là pour vous guider, que vous soyez débutant ou que vous souhaitiez rafraîchir vos connaissances. Ils proposent un mélange de théorie et de conseils pratiques, afin que vous soyez bien préparé à construire et à affiner des modèles précis.