Imagine que você está treinando um modelo de machine learning, mas não tem certeza de como será o desempenho dele em dados novos e inéditos. É aí que entra o K-Fold Cross-Validation. Ele oferece uma prévia de como seu modelo pode se sair no mundo real. Essa técnica ajuda a garantir que suas previsões não sejam apenas uma maravilha, mas que sejam consistentemente confiáveis em conjuntos de dados novos e inéditos.
Neste guia, vamos analisar os conceitos básicos da validação cruzada K-Fold e compará-la com métodos mais simples, como a divisão de treinamento e teste. Você explorará vários métodos de validação cruzada usando Python e entenderá por que a escolha do método certo pode afetar muito os seus projetos. Ao final, você estará preparado para aplicar essas estratégias com o scikit-Learn.
Vamos nos aprofundar e aprender como tornar seus esforços de machine learning realmente confiáveis!
O que é K-Fold Cross-Validation?
O K-Fold Cross-Validation é uma técnica robusta usada para avaliar o desempenho dos modelos de machine learning. Isso ajuda a garantir que o modelo seja bem generalizado para dados não vistos, usando diferentes partes do conjunto de dados para treinamento e teste em várias iterações.
Validação cruzada K-Fold vs. Divisão entre treinamento e teste
Enquanto o K-Fold Cross-Validation divide o conjunto de dados em vários subconjuntos para treinar e testar iterativamente o modelo, o método Train-Test Split divide o conjunto de dados em apenas duas partes: uma para treinamento e outra para teste. O método Train-Test Split é simples e rápido de implementar, mas a estimativa de desempenho pode ser altamente dependente da divisão específica, o que leva a uma alta variação nos resultados.
As imagens abaixo ilustram as diferenças estruturais entre esses dois métodos. A primeira imagem mostra o método Train-Test Split, em que o conjunto de dados é dividido em 80% de segmentos de treinamento e 20% de teste.
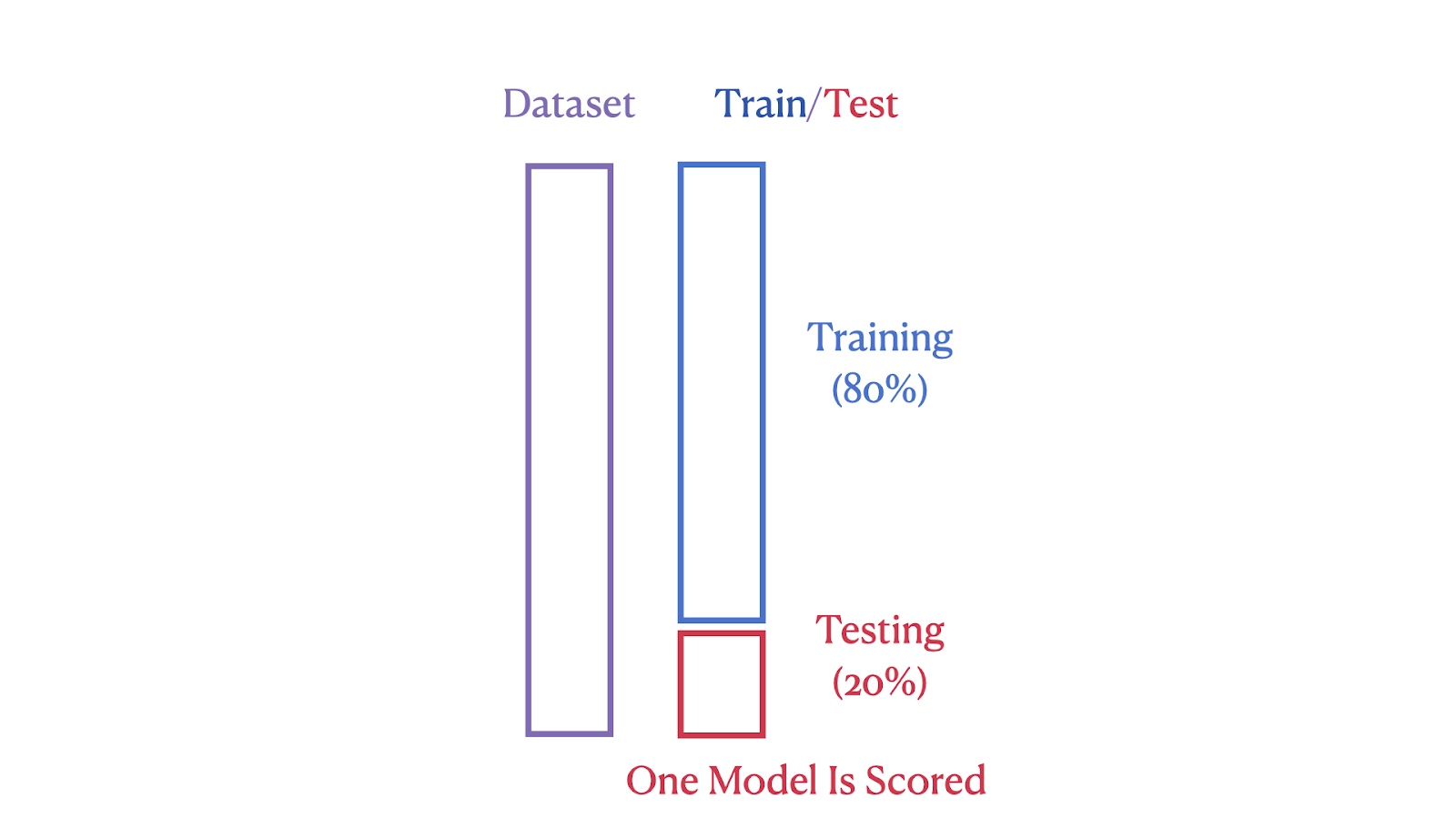
Ilustração de divisão de treinamento/teste. Imagem do autor
A segunda imagem mostra uma validação cruzada 5 vezes, em que o conjunto de dados é dividido em cinco partes, com cada parte servindo como um conjunto de teste em uma das cinco iterações, garantindo que cada segmento seja usado tanto para treinamento quanto para teste.
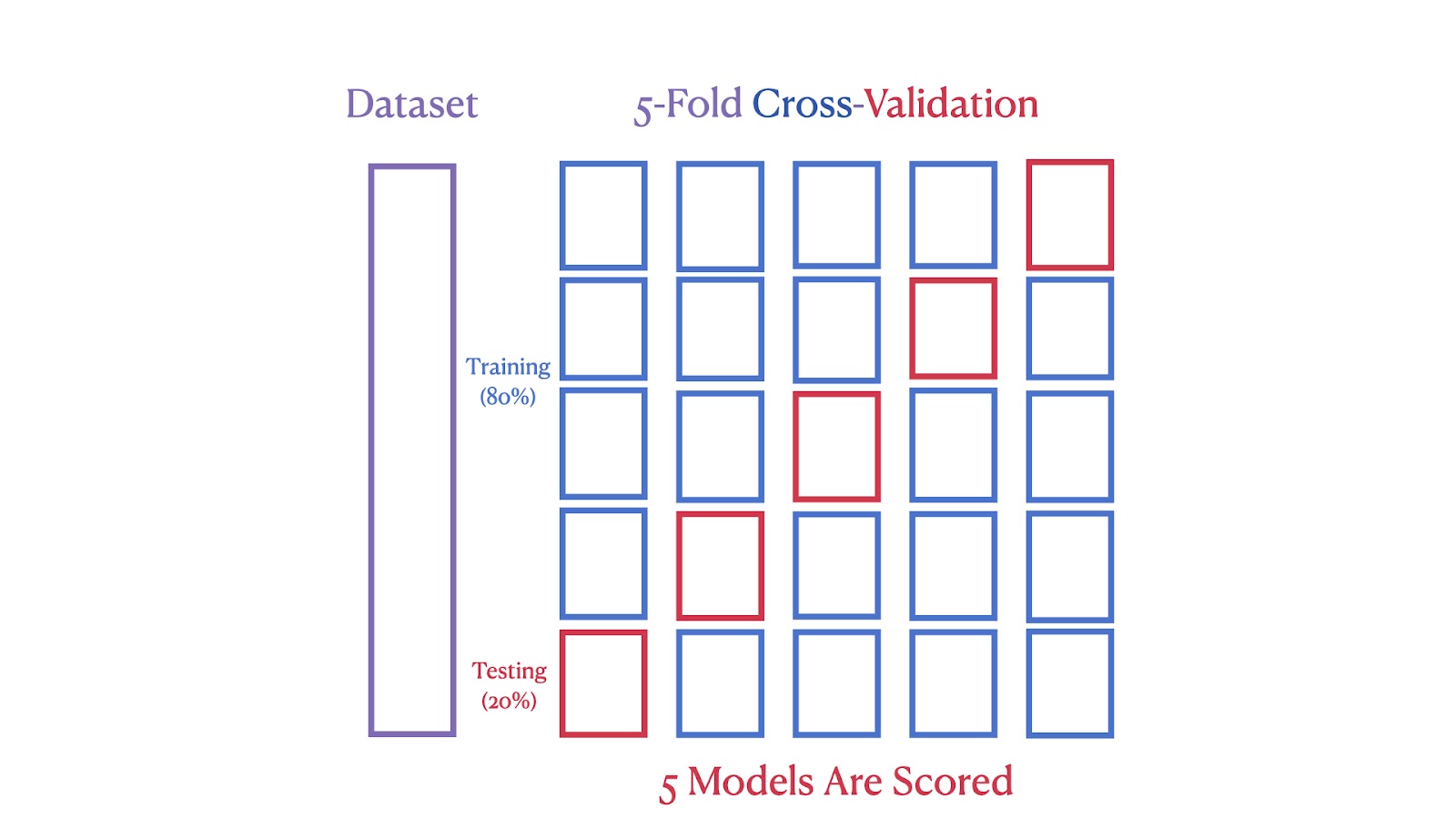
Esquema de validação cruzada 5 vezes. Imagem do autor
Podemos ver que a validação cruzada K-Fold fornece uma estimativa de desempenho mais robusta e confiável porque reduz o impacto da variabilidade dos dados. Ao usar vários ciclos de treinamento e teste, você minimiza o risco de ajuste excessivo a uma determinada divisão de dados. Esse método também garante que cada ponto de dados seja usado tanto para treinamento quanto para validação, o que resulta em uma avaliação mais abrangente do desempenho do modelo.
Implementando a validação cruzada K-Fold em Python usando o scikit-learn
Vamos agora demonstrar a validação cruzada K-Fold usando o conjunto de dados California Housing para avaliar o desempenho de um modelo de regressão linear. Esse método fornece uma estimativa robusta da precisão do modelo por meio de testes iterativos em diferentes subconjuntos do conjunto de dados, garantindo uma avaliação abrangente.
Visão geral do conjunto de dados do California Housing
O California Housing Dataset, compilado por Pace e Barry (1997), contém dados do U.S. 1990. Censo sobre moradias na Califórnia. Ele inclui 20.640 observações com recursos como localização, idade da moradia e população. A variável-alvo é o valor médio da casa para os distritos da Califórnia.
O conjunto de dados fornece um conjunto diversificado de características geográficas, demográficas e econômicas, tornando-o adequado para aplicações de ciência de dados e machine learning. Começaremos nosso exemplo de codificação baixando-o diretamente da biblioteca do scikit-Learn.
Carregando o conjunto de dados
Antes de iniciarmos o treinamento e a avaliação do modelo, precisamos carregar o conjunto de dados.
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing()Esse código importa a função fetch_california_housing de sklearn.datasets e a chama para carregar o conjunto de dados do California Housing. Esse conjunto de dados é armazenado nos dados variáveis, que contêm os recursos e a variável de destino.
Preparando os dados
Depois que o conjunto de dados é carregado, a próxima etapa é preparar os dados para análise.
import pandas as pd
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.targetAqui, usamos a biblioteca pandas para criar um DataFrame X contendo os dados de recursos de data.data. As colunas do DataFrame são rotuladas usando data.feature_names. A variável de destino, que representa os valores médios dos imóveis, é armazenada separadamente em y.
Configuração da validação cruzada K-Fold
Agora é hora de configurar nosso modelo, incluindo a seleção de um valor para K. A escolha do valor correto para K é uma etapa importante que abordaremos em detalhes a seguir.
from sklearn.model_selection import KFold
k = 5
kf = KFold(n_splits=k, shuffle=True, random_state=42)Esse código inicializa o K-Fold Cross-Validation usando a classe KFold de sklearn.model_selection. Configuramos a instância kf com 5 divisões. A opção shuffle=True randomiza a ordem dos pontos de dados, e a opção random_state=42 garante que esse embaralhamento seja consistente em várias execuções. Normalmente, essa configuração é suficiente para você começar a avaliar o desempenho de um modelo com validação cruzada.
Inicialização do modelo
Com nossos dados preparados e a validação cruzada configurada, a próxima etapa é escolher e inicializar o modelo.
from sklearn.linear_model import LinearRegression
model = LinearRegression()Importamos a classe LinearRegression de sklearn.linear_model e criamos um modelo de instância. Esse modelo será usado para realizar a regressão linear no conjunto de dados.
Realização de validação cruzada
Agora que o modelo foi inicializado, podemos passar para a parte divertida e realizar a validação cruzada para avaliar seu desempenho em diferentes subconjuntos de dados.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=kf, scoring='r2')Essa linha usa a função cross_val_score para avaliar o modelo usando o conjunto de dados X e o destino y. A validação cruzada é realizada usando a instância Kfold kf , e o desempenho do modelo é medido usando a pontuação R².
Cálculo da pontuação média de R2
Podemos usar o R-quadrado como uma métrica para avaliar a proporção da variação na variável dependente que é previsível a partir das variáveis independentes, fornecendo informações sobre a qualidade do ajuste do modelo de regressão.
import numpy as np
average_r2 = np.mean(scores)
print(f"R² Score for each fold: {[round(score, 4) for score in scores]}")
print(f"Average R² across {k} folds: {average_r2:.2f}")Essa parte calcula a pontuação R² média para todas as dobras. As pontuações de cada dobra são impressas primeiro, seguidas pela pontuação média. O uso do site np.mean() calcula a média das pontuações coletadas durante a validação cruzada.
Exibindo os resultados finais
Agora, agregamos os resultados para obter uma compreensão abrangente do desempenho do modelo. A pontuação R² média fornece uma única métrica que indica a eficácia do modelo.
R² Score for each fold: [0.5758, 0.6137, 0.6086, 0.6213, 0.5875]
Average R² across 5 folds: 0.60Este é o resultado do código da etapa anterior. Ele mostra as pontuações R² para cada dobra e a pontuação R² média.
O que "K" representa em K-Fold Cross-Validation?
Na validação cruzada K-Fold, "K" representa o número de grupos em que o conjunto de dados é dividido. Esse número determina quantas rodadas de testes o modelo passa, garantindo que cada segmento seja usado como um conjunto de testes uma vez.
Aqui você encontra uma heurística:
- K = 2 ou 3: Essas opções podem ser benéficas quando os recursos computacionais são limitados ou quando é necessária uma avaliação mais rápida. Eles reduzem o número de ciclos de treinamento, economizando tempo e poder computacional e, ao mesmo tempo, fornecendo uma estimativa razoável do desempenho do modelo.
- K = 5 ou 10: Escolher K = 5 ou K = 10 são escolhas populares porque proporcionam um bom equilíbrio entre a eficiência computacional e a estimativa de desempenho do modelo.
- K = 20: O uso de um valor maior de K pode proporcionar uma avaliação de desempenho mais detalhada. No entanto, isso aumenta a carga computacional e pode resultar em uma variação maior se os subconjuntos forem muito pequenos.
Para saber mais sobre a estimativa de desempenho do modelo, considere fazer nosso curso abrangente Model Validation in Python.
Principais considerações ao usar a validação cruzada K-Fold
O impacto de "K" em K-Fold Cross-Validation
O número de dobras, ou "K", na validação cruzada K-Fold afeta tanto a granularidade do processo de validação quanto a carga computacional. Um K menor (por exemplo, 3 a 5) pode ser mais rápido, mas pode gerar estimativas menos confiáveis, pois cada dobra representa uma parte maior do conjunto de dados, o que pode deixar de fora diversos cenários de dados. Um K maior (por exemplo, 10) oferece uma avaliação mais detalhada ao custo de mais cálculos. Um ponto de partida comum é K=5 ou K=10, que geralmente são suficientes para obter uma estimativa confiável sem cálculos excessivos.
Importância de embaralhar os dados na validação cruzada K-Fold
É altamente recomendável embaralhar os dados na validação cruzada K-Fold para aumentar a validade da avaliação do modelo. Ao definir shuffle=True, o embaralhamento quebra qualquer ordem inerente no conjunto de dados que poderia introduzir viés durante o processo de validação. Isso garante que cada dobra seja representativa de todo o conjunto de dados, o que é fundamental para avaliar a capacidade de generalização do modelo para novos dados. No entanto, é importante evitar o embaralhamento nos casos em que a sequência de pontos de dados é significativa, como nos dados de séries temporais, para preservar a integridade do processo de aprendizado.
Garantia de reprodutibilidade na validação cruzada K-Fold
Garantir que os resultados do K-Fold Cross-Validation sejam reproduzíveis é fundamental para verificar a estabilidade e o desempenho do modelo. Isso pode ser obtido com a configuração do parâmetro random_state, que garante o embaralhamento consistente dos dados em diferentes execuções, permitindo divisões de dados idênticas e, portanto, resultados reproduzíveis.
K-Fold padrão vs. Outros métodos de validação cruzada
A escolha da técnica correta de validação cruzada é crucial para a criação de modelos confiáveis de machine learning. A escolha depende muito das características específicas do conjunto de dados e do tipo de tarefa de machine learning que você tem em mãos. Diferentes técnicas são projetadas para lidar com vários desafios, como dados desequilibrados ou estruturas de dados agrupadas.
A tabela abaixo fornece uma comparação abrangente dos vários métodos de validação cruzada mais populares, destacando seus recursos exclusivos e os melhores casos de uso para orientar você na seleção da técnica mais eficaz para suas necessidades específicas de modelagem.
| Tipo de CV | Uso | Descrição | Quando usar |
|---|---|---|---|
| Validação cruzada K-Fold padrão | Tanto a regressão quanto a classificação | Divide o conjunto de dados em k dobras de tamanho igual. Cada dobra é usada uma vez como um conjunto de teste. | Melhor para conjuntos de dados equilibrados para garantir uma avaliação abrangente do modelo. |
| Validação cruzada K-Fold estratificada | Principalmente classificação | Mantém a mesma proporção de rótulos de classe em cada dobra que o conjunto de dados original. | Excelente para tarefas de classificação com classes desequilibradas para manter as proporções dos grupos. |
| Validação cruzada leave-one-out (LOOCV) | Tanto a regressão quanto a classificação | Cada ponto de dados é usado uma vez como um conjunto de teste, e o restante como treinamento. | Ótimo para pequenos conjuntos de dados para maximizar os dados de treinamento, embora seja computacionalmente intensivo. |
| Validação cruzada leave-p-out | Tanto a regressão quanto a classificação | Semelhante ao LOOCV, mas deixa de fora p pontos de dados do conjunto de teste. | Ideal para pequenos conjuntos de dados para testar como as alterações nas amostras de dados afetam a estabilidade do modelo. |
| Validação cruzada K-Fold do grupo | Regressão e classificação com grupos | Garante que nenhum grupo esteja em ambos os conjuntos de treinamento e teste, o que é útil quando os pontos de dados não são independentes. | Excelente para conjuntos de dados com agrupamentos lógicos para testar o desempenho em grupos independentes. |
| Validação cruzada K-Fold de grupo estratificado | Principalmente classificação com dados agrupados | Combina estratificação e integridade de grupo, garantindo que os grupos não sejam divididos entre as dobras. | Excelente para conjuntos de dados agrupados e desequilibrados para manter a integridade da classe e do grupo. |
Conclusão
Este guia mostrou a você como o K-Fold Cross-Validation é uma ferramenta poderosa para avaliar modelos de machine learning. É melhor do que a simples divisão entre treinamento e teste porque testa o modelo em várias partes dos dados, ajudando você a confiar que ele funcionará bem também em dados não vistos.
Se você está mergulhando no machine learning, aqui estão alguns recursos excelentes para ajudá-lo:
- Com o curso Aprendizado supervisionado com Scikit-Learn do DataCamp, você pode aprender mais: Este curso ajuda você a se familiarizar com a modelagem preditiva. É prático e prático, ideal para você começar sua jornada. Confira o curso aqui.
- Tutorial de machine learning com Python: Este tutorial detalha as principais ideias de machine learning e mostra a você como aplicá-las. É perfeito para solidificar o que você sabe. Leia o tutorial aqui.
- Folha de dicas do Scikit-Learn: Mantenha esta folha de dicas à mão. É perfeito para um lembrete rápido de como usar as funções de machine learning quando você estiver trabalhando em projetos. Obtenha a folha de dicas aqui.
- Curso de competição Kaggle da DataCamp: Se você quiser colocar suas habilidades à prova, este curso é excelente. Ele ensina como brilhar nas competições da Kaggle, onde você pode aplicar o que aprendeu de forma divertida e competitiva. Comece o curso aqui.
Esses recursos estão aqui para orientá-lo, esteja você apenas começando ou procurando aprimorar suas habilidades. Eles oferecem uma combinação de teoria e dicas práticas, garantindo que você esteja bem preparado para criar e refinar modelos precisos.