
Lernpfad
Containerisierung und Virtualisierung mit Docker und Kubernetes
13 Std.
Brauchst du Objektspeicher für die Entwicklung, willst aber AWS S3 nicht einrichten und dafür bezahlen?
MinIO bietet dir S3-kompatiblen Speicher, der überall läuft – auf deinem Laptop, einer VM oder einem Kubernetes-Cluster. Es ist Open Source, also unabhängig vom Anbieter, und du bekommst am Monatsende keine überraschenden Rechnungen. Und zusammen mit Docker ist die Ausführung von MinIO noch einfacher, weil du einen Speicherserver in Sekundenschnelle starten kannst, ohne irgendwas direkt auf deinem Rechner installieren zu müssen.
Docker-Container halten MinIO von deinem System getrennt und geben dir gleichzeitig die volle Kontrolle über die Konfiguration und die Datenpersistenz. Du kannst S3-APIs lokal testen, Produktionsspeicher-Setups simulieren oder einen schlanken Objektspeicher für kleine Projekte nutzen.
In diesem Artikel zeige ich dir, wie du MinIO mit Docker laufen lässt, überprüfst, ob alles richtig funktioniert, und die gängigsten Einstellungsoptionen konfigurierst.
Wenn du noch nie mit Docker gearbeitet hast, nimm dir einen Samstagnachmittag Zeit, um die Grundlagen zu lernen – DataCamps Einführung in Docker von DataCamp ist genau das Richtige für dich.
Du brauchst drei Sachen, um MinIO mit Docker zu nutzen.
Docker ist auf deinem Rechner installiert und läuft unter. Du kannst das überprüfen, indem du in deinem Terminal „ docker --version “ ausführst. Wenn du eine Versionsnummer zurückbekommst, kannst du loslegen.
Grundkenntnisse in Docker-Befehlen. Du solltest wissen, wie man Container startet und stoppt, Protokolle ansieht und mit Docker-Images arbeitet. Wenn du schon mal „ docker run “ ausgeführt oder mit Docker Compose gearbeitet hast, wirst du keine Probleme haben.
Ein lokales Verzeichnis für persistente Speicher. MinIO braucht einen Ort, um deine Daten außerhalb des Containers zu speichern. Mach auf deinem Host-Rechner ein leeres Verzeichnis – so was wie „ ~/minio/data “ ist gut.
Das ist alles. Die Liste ist kurz und einfach, aber stell sicher, dass du alle Punkte abgehakt hast, bevor du weitermachst.
Bei einer MinIO-Einrichtung mit einem einzigen Knoten läuft eine Instanz von MinIO in einem Docker-Container und speichert alle deine Daten an einem Ort.
Diese Konfiguration eignet sich für Entwicklungs-, Test- und kleine Produktions-Workloads, bei denen du keine hohe Verfügbarkeit oder verteilten Speicher brauchst. Du bekommst volle S3-API-Kompatibilität, ohne dass du mehrere Knoten verwalten musst.
Der Befehl „ docker run “ startet MinIO in einem neuen Container, wobei alles in einer Zeile konfiguriert wird.
Hier ist der grundlegende Befehl:
docker run -p 9000:9000 -p 9001:9001 \
--name minio \
-v ~/minio/data:/data \
-e "MINIO_ROOT_USER=admin" \
-e "MINIO_ROOT_PASSWORD=password123" \
quay.io/minio/minio server /data --console-address ":9001"
MinIO mit Docker ausführen
Schauen wir uns mal an, was jeder Teil macht.
Port 9000 ist der API-Endpunkt, über den deine Apps Dateien hoch- und runterladen. Hier schicken S3-kompatible Clients ihre Anfragen hin.
Port 9001 ist der Ort für die Webkonsole, wo du Buckets verwalten, Berechtigungen festlegen und den Speicher überwachen kannst. Damit kannst du überprüfen, ob MinIO richtig läuft.
Das Flag „ -v ~/minio/data:/data “ ordnet dein lokales Verzeichnis dem Speicherort des Containers zu. Alles, was MinIO speichert, landet im Ordner „ ~/minio/data “ auf deinem Host-Rechner. Wenn du den Container anhaltest oder entfernst, bleiben deine Daten in diesem Verzeichnis sicher gespeichert.
Umgebungsvariablen leg deine Zugangsdaten fest. MINIO_ROOT_USER ist dein Admin-Benutzername und MINIO_ROOT_PASSWORD ist das Passwort. Das sind die Anmeldedaten, die du brauchst, um dich bei der Webkonsole anzumelden und den API-Zugriff einzurichten.
Das Argument „ server /data “ sagt MinIO, dass es im Servermodus laufen und „ /data “ als Speicherverzeichnis benutzen soll. Die Option „ --console-address ":9001" “ sagt, auf welchem Port die Webkonsole wartet.
Es gibt noch 'ne andere Möglichkeit, MinIO zu starten, die super ist, wenn du keine Lust auf lange, mehrzeilige Terminalbefehle hast.
Anmerkung: MinIO aktualisiert seine Docker Hub- und Quay-Images nicht mehr (Stand: Oktober 2025). Der Code in diesem Artikel klappt immer noch für die lokale Entwicklung, aber für den Einsatz in der Produktion solltest du lieber gepflegte Alternativen wie das MinIO-Image von Chainguard (cgr.dev/chainguard/minio:latest) in Betracht ziehen.
Mit Docker Compose kannst du deine MinIO-Konfiguration in einer YAML-Datei festlegen, anstatt lange Befehle einzugeben.
Dadurch wird deine Konfiguration wiederholbar und versionskontrolliert. Du kannst die Datei mit deinem Team teilen, sie in Git committen und MinIO jedes Mal mit genau denselben Einstellungen neu starten.
Mach eine Datei namens „ docker-compose.yml “:
services:
minio:
image: quay.io/minio/minio
container_name: minio
ports:
- "9000:9000"
- "9001:9001"
environment:
MINIO_ROOT_USER: admin
MINIO_ROOT_PASSWORD: password123
volumes:
- ./minio/data:/data
command: server /data --console-address ":9001"Die Struktur ist wie der Befehl „ docker run “, aber alles ist in benannten Abschnitten organisiert. Ports, Umgebungsvariablen und Volumes haben jeweils ihren eigenen Block.
Volume Mapping funktioniert genauso – „ ./minio/data:/data “ erstellt ein Verzeichnis in deinem aktuellen Ordner und hängt es an den Container an. „ ./ “ bezieht sich auf den Speicherort der Datei „ docker-compose.yml “.
Jetzt kannst du MinIO starten mit:
docker-compose up -d
MinIO mit Docker Compose ausführen
Mit dem Flag „ -d “ läuft der Container im Hintergrund. Dein Terminal wird nicht durch MinIO-Protokolle blockiert, und der Container läuft weiter, nachdem du das Terminal geschlossen hast.
Hör auf mit:
docker-compose downCompose ist besser für die Entwicklung, weil du Healthchecks, Neustartrichtlinien und mehrere Dienste in derselben Datei hinzufügen kannst. Wenn du später neben MinIO noch eine Datenbank oder andere Dienste hinzufügen musst, machst du einfach weitere Einträge unter „ services: “.
Jetzt, wo MinIO läuft, solltest du erst mal checken, ob es richtig gestartet ist, bevor du es als Speicher nutzen kannst.
Es gibt zwei Möglichkeiten, deine Einrichtung zu überprüfen: die Webkonsole für die visuelle Bestätigung und den MinIO-Client für die Überprüfung über die Befehlszeile.
Öffne deinen Browser und geh auf http://localhost:9001.
Du siehst einen Anmeldebildschirm, auf dem du nach deinen Zugangsdaten gefragt wirst:
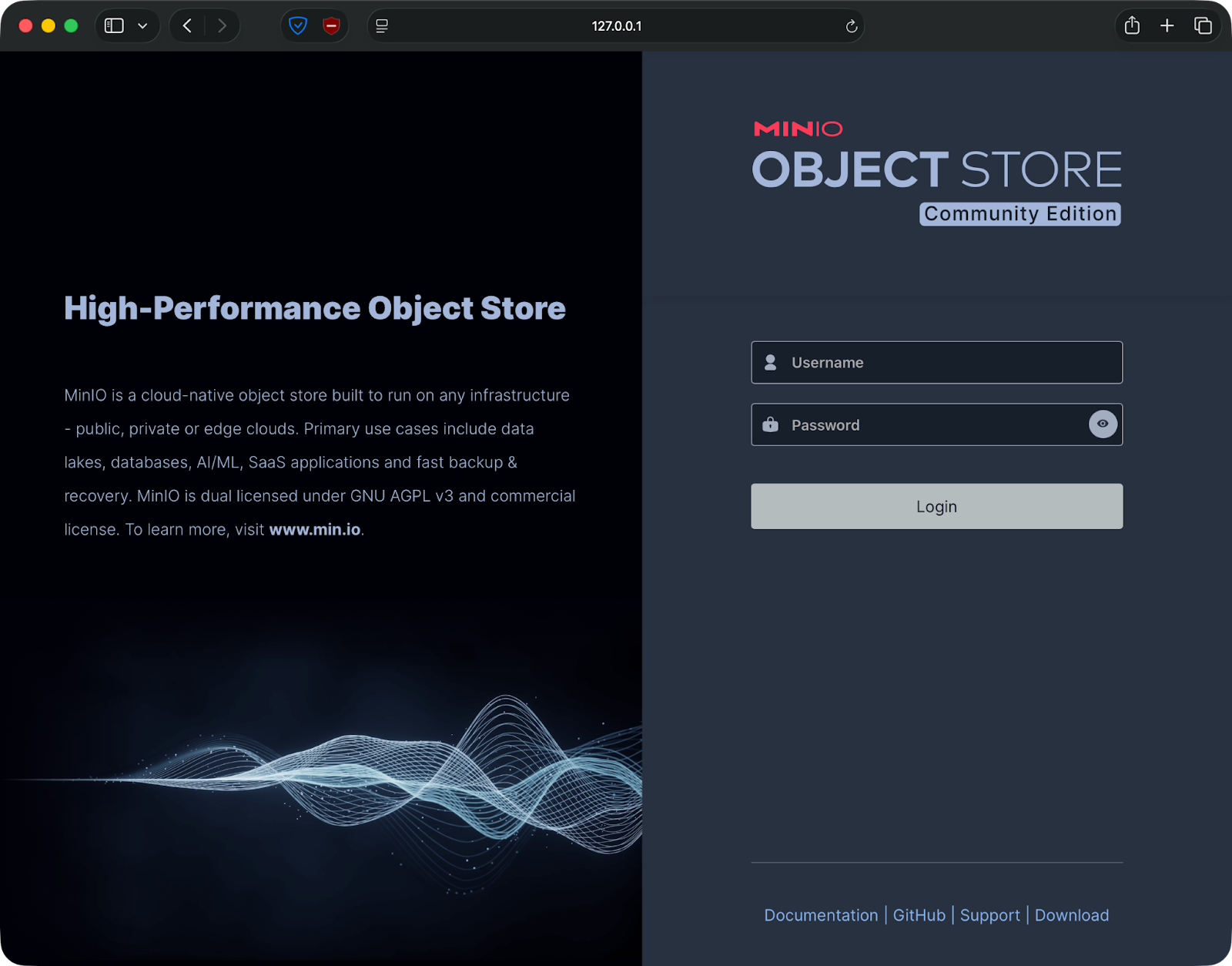
MinIO-Weboberfläche
Du kannst dich mit den Anmeldedaten einloggen, die du als Umgebungsvariablen angegeben hast – in meinem Fall admin/password123.
Nach dem Einloggen kommst du zum MinIO-Dashboard. Auf der Hauptseite siehst du die Speicherauslastung, die Anzahl der Buckets und den Systemzustand. In der linken Seitenleiste gibt's Optionen zum Erstellen von Buckets, zum Verwalten von Benutzern und zum Anzeigen von Metriken.
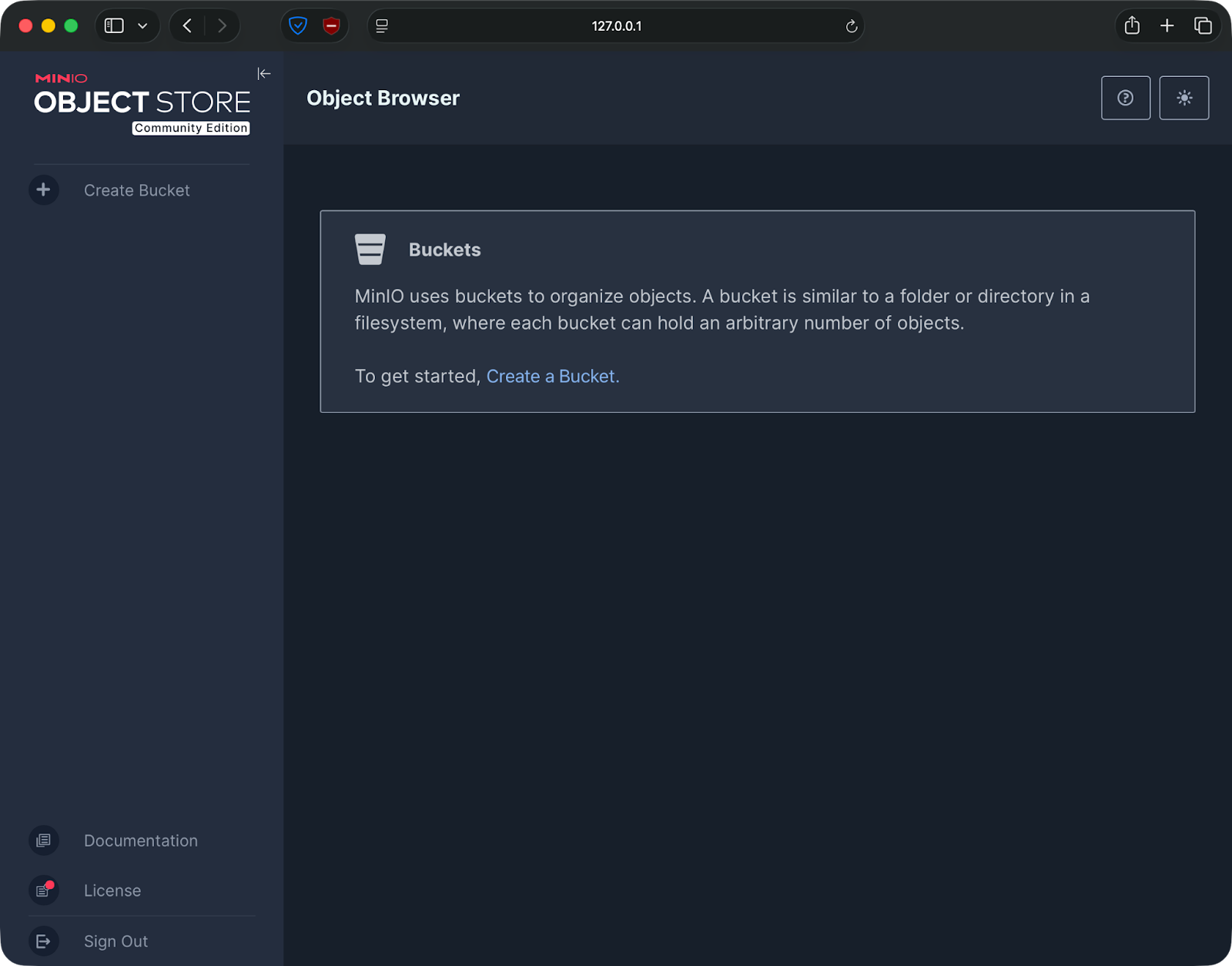
Erstellen eines Buckets über die MinIO-Weboberfläche
Mach einen Test-Bucket, um zu checken, ob alles klappt. Klick in der Seitenleiste auf „Buckets“ und dann auf „Bucket erstellen“. Gib ihm einen Namen wie „ test-bucket “ und klick auf „Erstellen“. Wenn der Bucket in deiner Liste auftaucht, läuft MinIO richtig und speichert Daten.
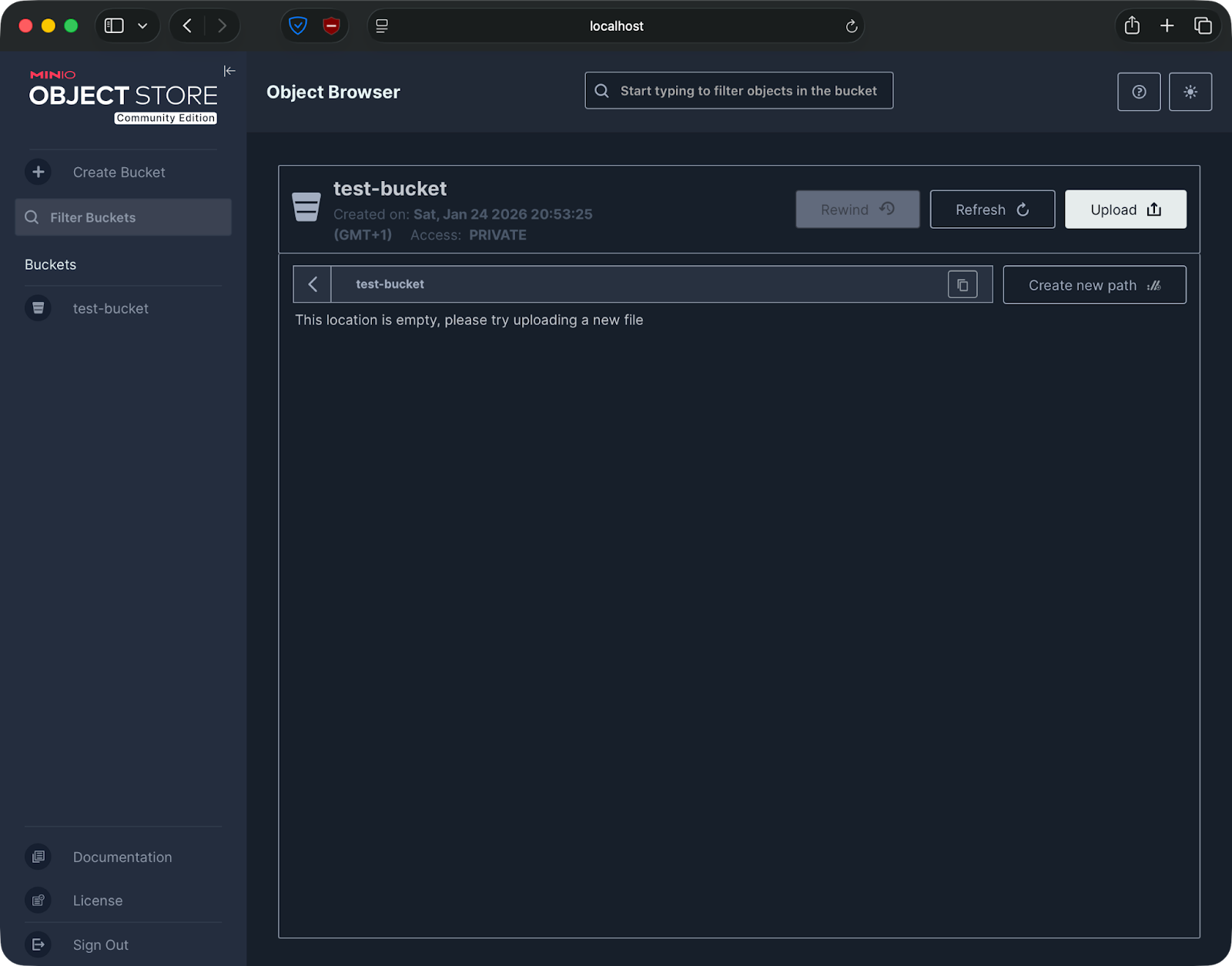
Erstellen eines Buckets über die MinIO-Weboberfläche
Der MinIO-Client ist ein Befehlszeilentool, mit dem du mit MinIO so interagieren kannst, wie du es mit der AWS-CLI tun würdest.
Führ einen dieser Befehle aus, um es zu installieren:
# macOS
brew install minio/stable/mc
# Linux
wget https://dl.min.io/client/mc/release/linux-amd64/mc
chmod +x mc
sudo mv mc /usr/local/bin/Und jetzt mach diesen Befehl ab, um den Client mit deiner lokalen MinIO-Instanz zu verbinden:
mc alias set local http://localhost:9000 admin password123Dadurch wird ein Alias namens „ local “ erstellt, der auf deinen MinIO-Server zeigt. Du kannst jetzt Befehle dafür ausführen.
Schreib deine Eimer auf:
mc ls local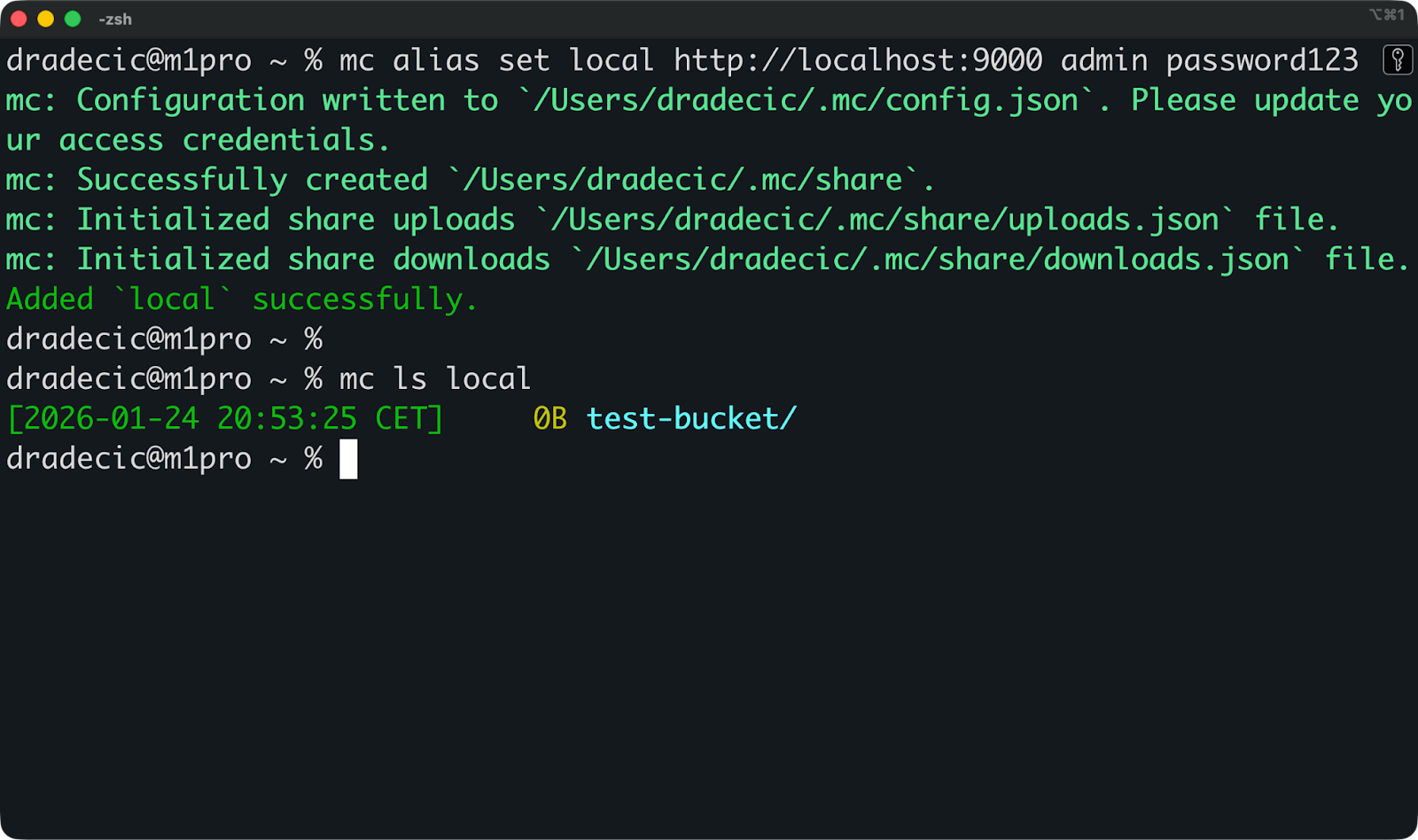
Buckets auflisten
Wenn du den Test-Bucket schon vorher erstellt hast, wird er in der Ausgabe angezeigt. Wenn der Befehl nichts zurückgibt oder deine Buckets anzeigt, funktioniert MinIO.
Du kannst jetzt eine Testdatei in den Bucket hochladen:
echo "test" > test.txt
mc cp test.txt local/test-bucket/Und dann check mal, ob es da ist:
mc ls local/test-bucketWenn du in der Ausgabe „ test.txt “ siehst, hast du alles richtig eingerichtet.
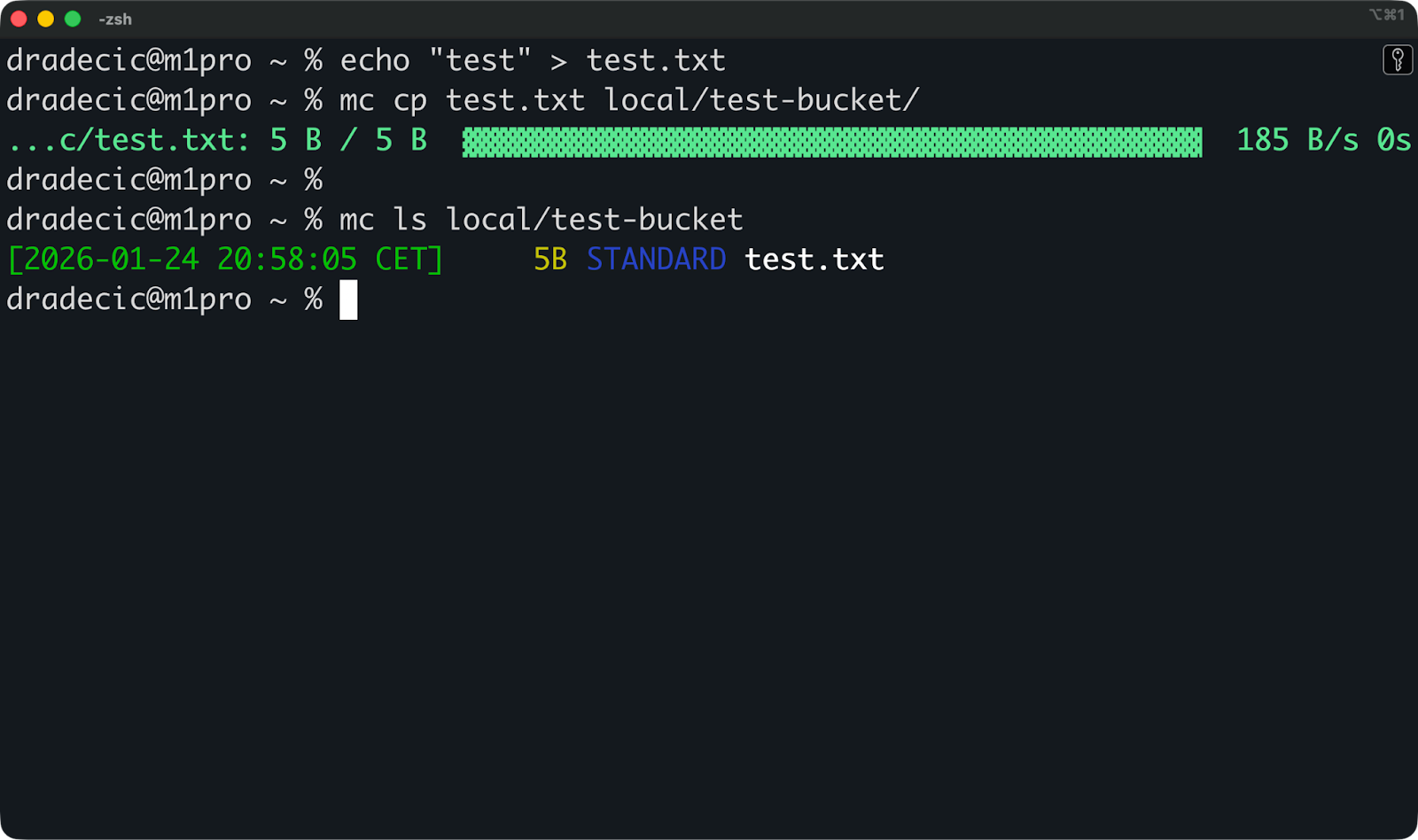
Dateien in einem Bucket auflisten
Hier sind ein paar schnelle Tipps zur Fehlerbehebung , falls etwas nicht funktioniert:
Schau mal, ob der Container läuft, indem du „ docker ps “ eingibst. Wenn du keinen Container namens „ minio ” siehst, wurde er nicht gestartet oder ist abgestürzt.
Schau dir die Protokolle mit „ docker logs minio “ an. Such nach Fehlern wegen schon genutzter Ports oder Berechtigungsproblemen im Datenverzeichnis.
Wenn du nicht auf die Webkonsole zugreifen kannst, check mal, ob die Ports nicht blockiert sind, indem du docker port minio überprüfst. Du solltest sehen, dass sowohl 9000 als auch 9001 richtig zugeordnet sind.
Wenn du auf Berechtigungsfehler im Datenverzeichnis stößt, führe „ chmod -R 755 ~/minio/data “ aus, um die Zugriffsprobleme zu beheben.
Container sind standardmäßig kurzlebig – wenn du einen Container löschst, verschwindet alles, was drin ist.
MinIO speichert Objekte, Metadaten und Konfigurationsdateien. Wenn du den persistenten Speicher nicht richtig einrichtest, gehen alle deine Daten verloren, sobald du den Container neu startest oder entfernst.
Docker-Volumes und Bind-Mounts sorgen dafür, dass deine Daten außerhalb des Containers sicher sind.
Wenn du „ -v ~/minio/data:/data “ benutzt oder ein Volume in Docker Compose zuordnest, schreibt MinIO alles auf deinen Host-Rechner. Der Container liest und schreibt Dateien in „ /data “, aber diese Dateien sind eigentlich in „ ~/minio/data “ auf deinem Host gespeichert.
Wenn du den Container stoppst, ihn entfernst oder sogar das Image löschst, bleiben deine Daten in „ ~/minio/data “ gespeichert. Starte einen neuen MinIO-Container, der auf dasselbe Verzeichnis zeigt, und alle deine Buckets, Objekte und Einstellungen sind wieder da, genau so, wie du sie verlassen hast.
Wenn du kein Volume zuordnest, nutzt MinIO das interne Dateisystem des Containers. Alles läuft super, bis du den Container stoppst. Wenn du es neu startest, fängt MinIO ganz von vorne an, ohne Buckets, ohne Objekte und ohne Konfiguration.
Das Compose-Beispiel, das ich vorhin gezeigt habe, erstellt einen Ordner namens „ minio/data “ genau dort, wo deine Compose-Datei ist:
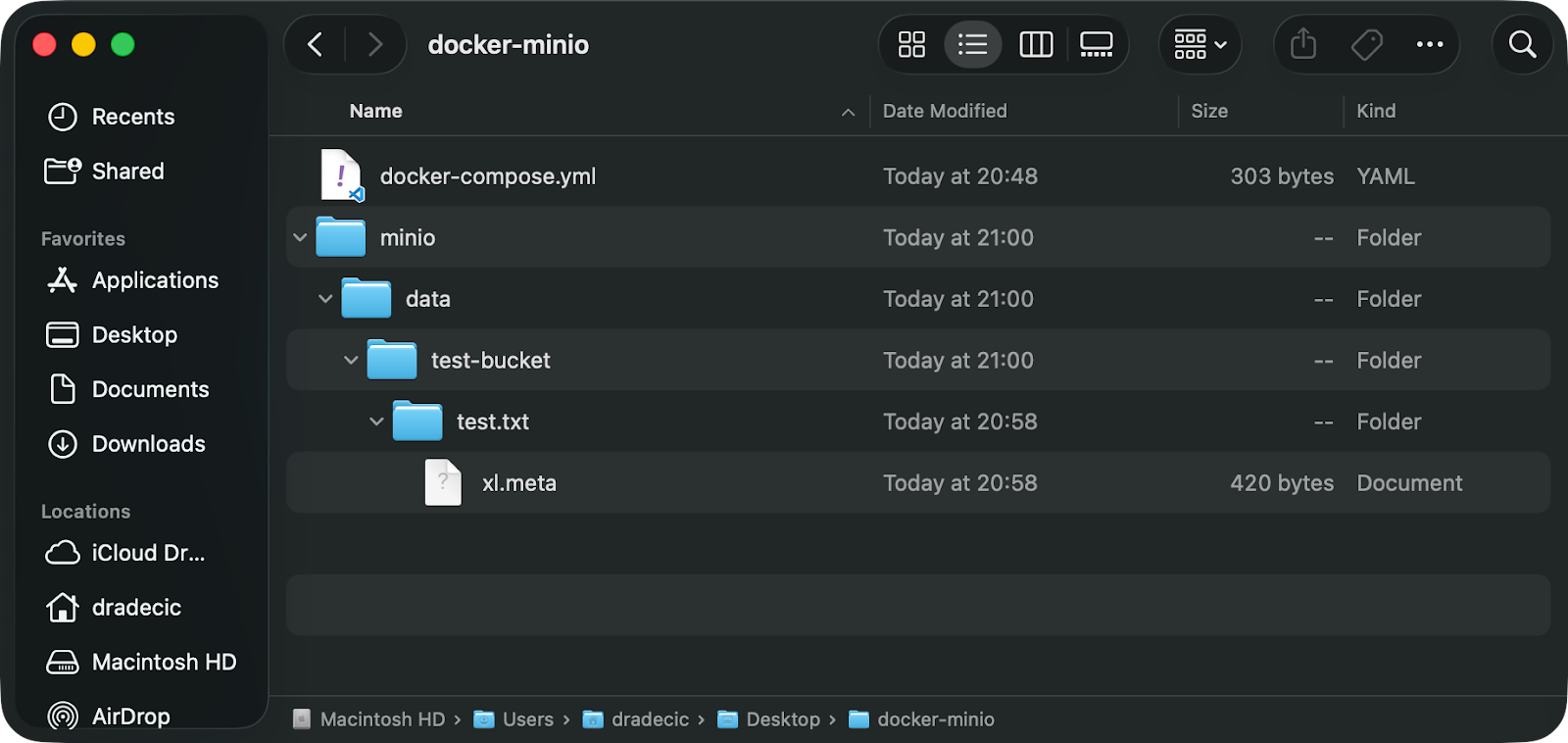
MinIO-Datenordner
Ohne Lautstärke zu laufen ist der häufigste Fehler.
Du startest MinIO, lädst Dateien hoch, erstellst Buckets, und alles scheint gut zu laufen. Dann startest du den Container neu, um ein Update oder eine Konfigurationsänderung durchzuführen. Alle deine Daten sind weg, weil sie im Container gespeichert waren und nicht auf deinem Host.
Überprüfe immer, ob dein Docker-Befehl oder deine Compose-Datei eine Volume-Zuordnung hat, bevor du echte Daten in MinIO speicherst.
Es kann zu Berechtigungsproblemen kommen treten auf, wenn Docker nicht in dein gemountetes Verzeichnis schreiben kann.
Der MinIO-Prozess im Container läuft als bestimmter Benutzer. Wenn dieser Benutzer keine Schreibrechte für das Host-Verzeichnis hat, stürzt MinIO beim Start ab oder schlägt beim Versuch, Objekte zu speichern, stillschweigend fehl.
Du kannst das beheben, indem du sicherstellst, dass dein Datenverzeichnis beschreibbar ist:
chmod -R 755 ~/minio/dataOder starte den Container mit einem Benutzer, der deinem Host-Benutzer entspricht:
docker run --user $(id -u):$(id -g) ...Kurz gesagt: Richte deine Volumes einmal richtig ein, dann musst du dir keine Sorgen mehr über Datenverluste machen.
MinIO liest seine Konfiguration beim Start aus Umgebungsvariablen.
Das heißt, du kannst das Verhalten von MinIO ändern, ohne Konfigurationsdateien zu bearbeiten oder Container neu zu erstellen. Du legst diese Variablen in deinem Befehl „ docker run “ oder in deiner Docker-Compose-Datei fest.
MinIO braucht zwei Umgebungsvariablen für die Authentifizierung: MINIO_ROOT_USER und MINIO_ROOT_PASSWORD.
Damit erstellst du das Root-Admin-Konto, das die volle Kontrolle über deine MinIO-Instanz hat. Der Root-Benutzer kann Buckets erstellen, andere Benutzer verwalten, Richtlinien festlegen und auf alle gespeicherten Objekte zugreifen.
Mach das so in der Datei „ docker run “:
-e "MINIO_ROOT_USER=admin" \
-e "MINIO_ROOT_PASSWORD=your-secure-password"Oder in Docker Compose:
environment:
MINIO_ROOT_USER: admin
MINIO_ROOT_PASSWORD: your-secure-passwordBenutze keine Standard-Anmeldedaten in der Produktion. Die Beispiele in diesem Artikel verwenden der Einfachheit halber admin und password123, aber das sind echt schlechte Optionen für echte Implementierungen.
Wähle ein starkes Passwort mit mindestens 8 Zeichen. Noch besser ist es, wenn du zufällig generierte Anmeldedaten verwendest und diese in einem Passwort-Manager oder einem System zur Verwaltung geheimer Daten speicherst.
Schreib keine Anmeldedaten fest in Docker Compose-Dateien, bevor du sie in die Versionskontrolle übernimmst. Benutz stattdessen Umgebungsdateien:
environment:
MINIO_ROOT_USER: ${MINIO_ROOT_USER}
MINIO_ROOT_PASSWORD: ${MINIO_ROOT_PASSWORD}Dann mach mal eine Datei namens „ .env “ mit deinen echten Zugangsdaten und leg sie in „ .gitignore “ ab.
MinIO braucht zwei Ports, um richtig zu funktionieren.
Ordne diese Ports in deinem Docker-Befehl zu:
-p 9000:9000 -p 9001:9001Portkonflikte treten auf, wenn ein anderer Dienst auf deinem Host bereits die Ports 9000 oder 9001 nutzt.
Beim Starten des Containers wird eine Fehlermeldung wie „bind: Adresse bereits in Verwendung“ angezeigt. Behebe das Problem, indem du verschiedene Host-Ports zuordnest:
-p 9090:9000 -p 9091:9001Jetzt findest du die API von MinIO unter http://localhost:9090 und die Konsole unter http://localhost:9091. Der Container nutzt intern immer noch 9000 und 9001, aber von außen greift man über verschiedene Ports drauf zu.
Mit diesen Befehlen kannst du vor dem Start von MinIO überprüfen, was einen Port nutzt:
# Linux/macOS
lsof -i :9000
lsof -i :9001
# Windows
netstat -ano | findstr :9000
netstat -ano | findstr :9001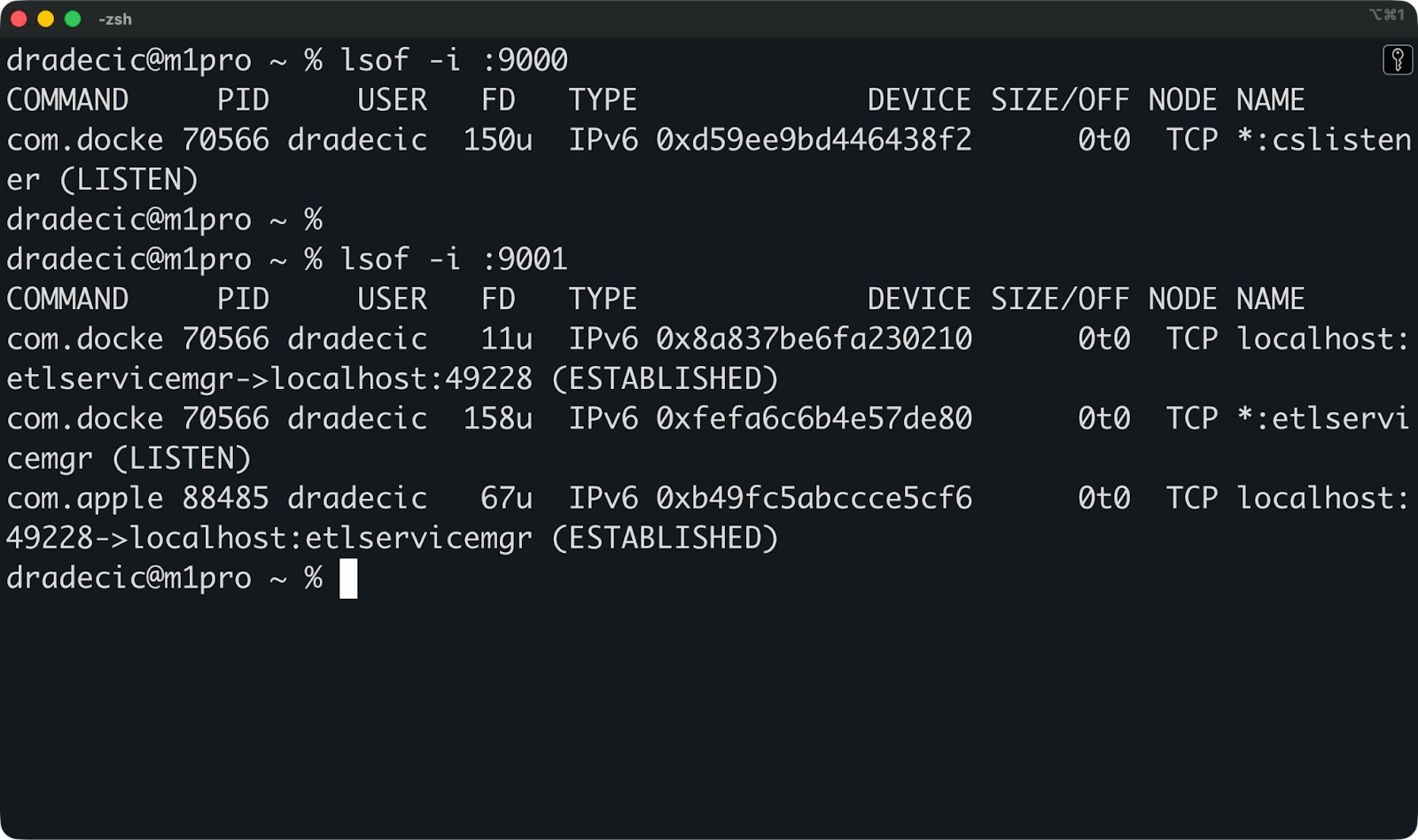
Überprüfen, was einen Port benutzt
Wenn du mehrere MinIO-Instanzen auf demselben Rechner laufen hast, gib jeder Instanz eine eigene Portzuordnung, damit sie sich nicht gegenseitig stören.
Der verteilte Modus lässt MinIO auf mehreren Servern mit mehreren Laufwerken laufen, um hohe Verfügbarkeit und Datenredundanz zu gewährleisten.
Du brauchst das nicht für die Entwicklung oder zum Testen. Der Einzelknotenmodus klappt für die meisten Fälle super. Überspringe diesen Abschnitt, wenn du keine Produktionsumgebung planst, die auch bei Serverausfällen online bleiben muss.
Benutze den verteilten Modus, wenn du Fehlertoleranz brauchst.
Wenn in einer verteilten Konfiguration ein Server ausfällt, läuft MinIO weiter und deine Daten bleiben zugänglich. Das System nutzt Löschcodierung, um Objekte auf mehrere Laufwerke und Server zu verteilen, sodass du Laufwerke oder ganze Knoten verlieren kannst, ohne dass Daten verloren gehen.
Für die Speicherung großer Datenmengen brauchst du auch den verteilten Modus. Wenn du Terabytes oder Petabytes an Daten speicherst, bekommst du durch die Verteilung auf mehrere Maschinen eine bessere Leistung und mehr Kapazität, als ein einzelner Server bieten kann.
Die lokale Entwicklung braucht das alles nicht. Der verteilte Modus macht die Sache komplizierter – du brauchst mehrere Rechner oder VMs, ein gut koordiniertes Netzwerk und eine sorgfältige Festplattenkonfiguration. Wenn du S3-APIs testen oder Objektspeicher auf deinem Laptop nutzen willst, reicht der Einzelknotenmodus völlig aus.
Produktionsumgebungen nutzen den verteilten Modus, wenn Ausfallzeiten nicht okay sind und Datenverluste echt schlimm wären. Denk mal an Backup-Systeme, Data Lakes oder Anwendungen, bei denen die Nutzer auf ständige Speicherverfügbarkeit angewiesen sind.
Das verteilte MinIO braucht mindestens vier Laufwerke über mehrere Knoten verteilt.
Jeder Knoten hat einen MinIO-Container laufen, und alle Knoten müssen die gleiche Laufwerkskonfiguration sehen. Du kannst Knoten mit einem Laufwerk nicht mit Knoten mit mehreren Laufwerken mischen oder die Anzahl der Laufwerke nach der Einrichtung ändern.
Ein einfaches verteiltes Setup sieht so aus:
Du kannst die Koordination in einer einzigen Compose-Datei machen, aber ich sag dir gleich: Das wird eine lange Datei. Du musst alle Knoten definieren, ihre Laufwerkspfade festlegen und sie zusammen starten.
Hier ist ein komplettes Beispiel für vier Knoten mit jeweils zwei Laufwerken:
version: "3.9"
services:
minio1:
image: quay.io/minio/minio:latest
hostname: minio1
container_name: minio1
command: server http://minio{1...4}/data{1...2} --console-address ":9001"
ports:
- "9001:9000"
- "9091:9001"
environment:
MINIO_ROOT_USER: admin
MINIO_ROOT_PASSWORD: password123
volumes:
- ./data/minio1/data1:/data1
- ./data/minio1/data2:/data2
networks:
- minio
minio2:
image: quay.io/minio/minio:latest
hostname: minio2
container_name: minio2
command: server http://minio{1...4}/data{1...2} --console-address ":9001"
ports:
- "9002:9000"
- "9092:9001"
environment:
MINIO_ROOT_USER: admin
MINIO_ROOT_PASSWORD: password123
volumes:
- ./data/minio2/data1:/data1
- ./data/minio2/data2:/data2
networks:
- minio
minio3:
image: quay.io/minio/minio:latest
hostname: minio3
container_name: minio3
command: server http://minio{1...4}/data{1...2} --console-address ":9001"
ports:
- "9003:9000"
- "9093:9001"
environment:
MINIO_ROOT_USER: admin
MINIO_ROOT_PASSWORD: password123
volumes:
- ./data/minio3/data1:/data1
- ./data/minio3/data2:/data2
networks:
- minio
minio4:
image: quay.io/minio/minio:latest
hostname: minio4
container_name: minio4
command: server http://minio{1...4}/data{1...2} --console-address ":9001"
ports:
- "9004:9000"
- "9094:9001"
environment:
MINIO_ROOT_USER: admin
MINIO_ROOT_PASSWORD: password123
volumes:
- ./data/minio4/data1:/data1
- ./data/minio4/data2:/data2
networks:
- minio
networks:
minio:
driver: bridgeDie Syntax „ {1...4} “ sagt MinIO, dass es sich mit vier Knoten (minio1 bis minio4) mit jeweils zwei Laufwerken (data1 und data2) verbinden soll. Jeder Knoten kriegt eigene Portzuweisungen, damit du auf jeden einzeln zugreifen kannst – Knoten 1 nutzt 9001/9091, Knoten 2 nutzt 9002/9092 und so weiter.
Mit dem Netzwerk „ minio-distributed “ können Container sich über den Hostnamen erreichen. Alle Knoten müssen die gleichen Anmeldedaten verwenden und dasselbe Laufwerkslayout sehen.
Um den Cluster zu starten, erst mal die Datenverzeichnisse anlegen und dann die Compose-Datei ausführen.
mkdir -p data/minio{1..4}/data{1..2}
docker compose up -d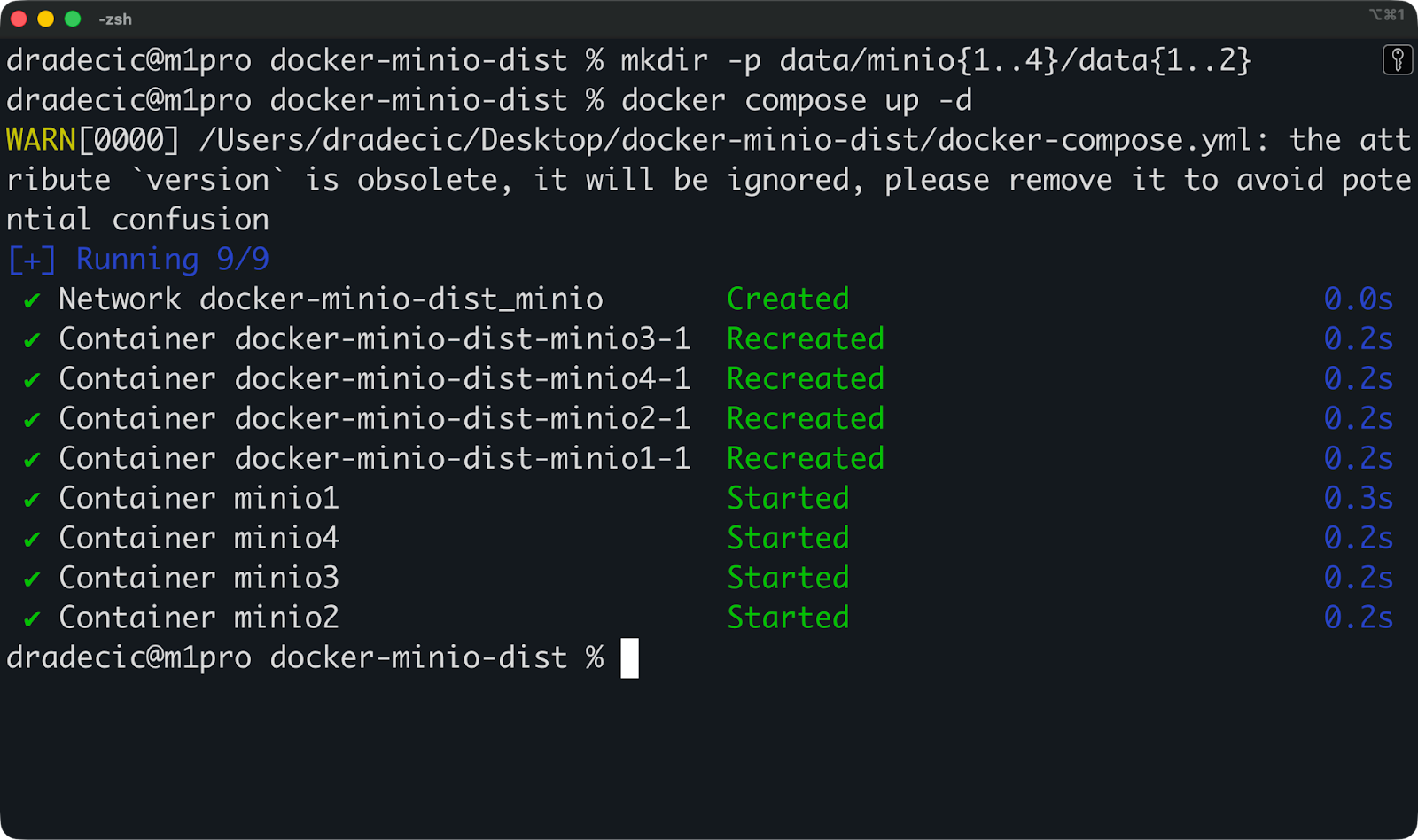
MinIO im verteilten Modus ausführen
Das war's! Du kannst jetzt eine der folgenden URLs aufrufen, um auf die Web-Benutzeroberfläche zuzugreifen:
Aber noch mal: Bau das nur, wenn du es wirklich brauchst – der verteilte Modus ist für Produktions-Workloads gedacht, bei denen Verfügbarkeit und Redundanz die zusätzliche Komplexität rechtfertigen.
Außerdem wirst du wahrscheinlich Sachen wie TLS, einen einzigen Konsolenendpunkt und externe Volumes/Festplatten für eine komplette Produktionsumgebung brauchen.
Die meisten Probleme mit MinIO Docker kommen von falsch eingestellten Volumes, Ports oder Anmeldedaten.
Hier sind die Probleme, auf die du tatsächlich stoßen wirst, und wie du sie schnell beheben kannst.
Du startest „ docker ps “ und siehst, dass der Container läuft, aber „ http://localhost:9001 “ gibt nichts zurück oder läuft ab.
Um das zu klären, check erst mal, ob der Konsolenport richtig zugeordnet ist:
docker port minioDu solltest dir mal 9001/tcp -> 0.0.0.0:9001 anschauen. Wenn du den Port 9001 nicht in der Liste siehst, hast du vergessen, ihn in deinem Befehl„ “ oder deiner Compose-Datei zuzuordnen.
Schau dir auch die MinIO-Protokolle an:
docker logs minioSuch nach der Zeile „Console: http://...“ – die zeigt dir, auf welcher Adresse MinIO gerade lauscht. Wenn du einen anderen Port als erwartet siehst, könnte dein Flag „ --console-address “ falsch sein.
MinIO stürzt beim Start ab oder du siehst Fehlermeldungen wie „Zugriff verweigert“ in den Protokollen, wenn es versucht, in „ /data “ zu schreiben.
Der MinIO-Prozess läuft als bestimmter Benutzer im Container, und dieser Benutzer braucht Schreibzugriff auf dein gemountetes Verzeichnis. Behebt das Problem mit:
chmod -R 755 ~/minio/dataOder wenn du Linux benutzt, starte den Container mit deiner Benutzer-ID:
docker run --user $(id -u):$(id -g) ...Beim Starten des Containers bekommst du die Meldung „bind: address already in use” (Bindung: Adresse bereits in Verwendung).
Das heißt, dass ein anderer Dienst schon den Port 9000 oder 9001 benutzt. Finde heraus, was es nutzt:
# Linux/macOS
lsof -i :9000
lsof -i :9001
# Windows
netstat -ano | findstr :9000Und dann ordne MinIO stattdessen verschiedenen Host-Ports zu:
docker run -p 9090:9000 -p 9091:9001 ...Jetzt kannst du auf die API unter localhost:9090 und die Konsole unter localhost:9091 zugreifen.
Du hast MINIO_ROOT_USER und MINIO_ROOT_PASSWORD eingerichtet, kannst dich aber nicht anmelden oder der Container startet nicht.
Um das Problem zu lösen, check mal, ob du die Umgebungsvariablen wirklich übergeben hast:
docker inspect minio | grep -A 5 EnvSuch in der Ausgabe nach „ MINIO_ROOT_USER “ und „ MINIO_ROOT_PASSWORD “. Wenn sie fehlen, hast du die Flags „ -e “ oder den Abschnitt „ environment: “ in deiner Compose-Datei vergessen.
MinIO verlangt außerdem, dass Passwörter mindestens 8 Zeichen lang sind. Wenn dein Passwort kürzer ist, könnte der Container es ablehnen oder stattdessen ein Standardpasswort verwenden.
Wenn du die Anmeldedaten bei einer bestehenden Konfiguration geändert hast, hör bitte auf und entferne den Container komplett. Starte dann neu:
docker stop minio
docker rm minio
docker run ... # with new credentialsAlte Anmeldedateien können in deinem Datenverzeichnis liegen bleiben und Probleme verursachen.
Mach's so, um häufige Fehler zu vermeiden und dein MinIO-Setup wartungsfreundlich zu halten.
Benutz Docker Compose, um die Wiederholbarkeit zu sichern. Eine Compose-Datei dokumentiert deine genaue Konfiguration – Ports, Volumes, Umgebungsvariablen und Befehle. Du kannst es versionieren, mit deinem Team teilen und identische Setups auf verschiedenen Rechnern erstellen. Wenn du lange Befehle wie „ docker run “ aus deinem shell-Verlauf ausführst, kann das zu Konfigurationsabweichungen und Fehlern führen.
Stell immer persistenten Speicher ein. Mach ein Volume oder bind mount, bevor du irgendwelche echten Daten speicherst. Container sind kurzlebig – wenn du diesen Schritt überspringst, geht beim Neustart des Containers alles verloren. Schau mal unter docker inspect minio nach, ob deine Einstellungen stimmen und die Lautstärke richtig zugeordnet ist.
Halt deine Zugangsdaten aus dem Befehlsverlauf raus. Schreib Passwörter nicht direkt in „ docker run “-Befehle oder speicher sie in deinen Compose-Dateien in Git. Benutze Umgebungsdateien (.env) mit Docker Compose oder gib die Anmeldedaten über Umgebungsvariablen zur Laufzeit weiter. Füge .env sofort zu deinen .gitignore hinzu.
Benutz den Einzelknotenmodus nur für die Entwicklung. Der verteilte Modus ist kompliziert und dauert beim Einrichten ewig. Du brauchst auf deinem Laptop keine Hochverfügbarkeit oder Löschcodierung. Verwendest verteilte Bereitstellungen nur für die Produktion, wo Ausfallzeiten echt wichtig sind.
Überwache die Protokolle beim Start. Führ beim ersten Start von MinIO das Programm „ docker logs -f minio “ aus. Die Protokolle zeigen dir den API-Endpunkt, die Konsolen-URL und alle Konfigurationsfehler. Wenn was nicht stimmt, siehst du es sofort und musst dich nicht fragen, warum nichts klappt.
Befolge diese Vorgehensweisen, und deine MinIO-Einrichtung wird vom ersten Tag an stabil sein.
Wenn du MinIO mit Docker nutzt, kannst du in weniger als einer Minute einen S3-kompatiblen Objektspeicher auf deinem Rechner einrichten.
Für die Entwicklung, das Testen und kleine Projekte bietet dir MinIO mit einem einzigen Knoten in Docker alles, was du brauchst. Du bekommst volle S3-API-Kompatibilität, eine Webkonsole für die Verwaltung und die volle Kontrolle über deine Daten, ohne von Cloud-Diensten abhängig zu sein oder für Speicherplatz zu bezahlen, den du nicht nutzt.
Fang mit den Grundlagen an: einem einfachen Befehl „ docker run “ oder einer Docker-Compose-Datei mit persistenten Volumes und sicheren Anmeldedaten (letzteres ist besser). Teste deine Einrichtung, schau, ob sie funktioniert, und mach sie nur dann komplizierter, wenn du es wirklich brauchst.
Verteilte Modi, hohe Verfügbarkeit und produktionsreife Konfigurationen gibt's aus gutem Grund – aber der Grund ist nicht die lokale Entwicklung. Wechsel zu diesen Konfigurationen, wenn du in der Produktion einsetzt, wenn Ausfallzeiten dich Geld kosten oder wenn du Daten speicherst, die nicht verloren gehen dürfen. Bis dahin halte es einfach und konzentriere dich darauf, deine Anwendung zu entwickeln, anstatt dich um die Infrastruktur zu kümmern.
Wenn du bereit bist, dich mit komplexeren Docker-Themen zu beschäftigen, schau dir unsere Kurs „Containerisierung und Virtualisierung mit Docker und Kubernetes” an.
Lerne Docker mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Tutorial
Moez Ali
Tutorial
Matt Crabtree
Tutorial
Javier Canales Luna
