Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Letzte Woche hat Mistral Mistral OCR veröffentlicht, eine innovative API zur optischen Zeichenerkennung (OCR). Ihre API setzt einen neuen Standard für KI-Funktionen zum Verstehen von Dokumenten und Bildern. Es ist in der Lage, Dokumente mit Bildern, Mathematik, Tabellen und mehr mit einem hohen Maß an Genauigkeit zu verarbeiten und zu analysieren.
In diesem Artikel erkläre ich dir Schritt für Schritt, wie du Mistral OCR mit Python nutzen kannst. Ich zeige dir, wie du es mit Dokumenten und Bildern verwenden kannst und wie du es mit dem Chat kombinierst, um Prompts mit Dokumenten zu verbinden.
Die optische Zeichenerkennung (OCR) ist eine Technologie, die verschiedene Arten von Dokumenten - wie gescannte Papierdokumente, PDF-Dateien oder mit einer Digitalkamera aufgenommene Bilder - in bearbeitbare und durchsuchbare Daten umwandelt.
OCR erkennt Textzeichen in Bildern, analysiert deren Muster und übersetzt diese visuellen Elemente in maschinell kodierten Text. Diese Technologie hat die Art und Weise, wie wir mit gedruckten Materialien umgehen, verändert und ermöglicht alles, von der Digitalisierung historischer Archive bis hin zur automatischen Dateneingabe in Geschäftsformularen.
Die OCR-API von Mistral stellt einen bedeutenden Fortschritt in diesem Bereich dar und bietet Entwicklern ein leistungsstarkes Werkzeug, um Text mit bemerkenswerter Genauigkeit aus Bildern und Dokumenten zu extrahieren.

Quelle: Mistral
Im Gegensatz zu herkömmlichen OCR-Lösungen, die lediglich Text identifizieren, nutzt die API von Mistral fortschrittliche KI-Modelle, um den Kontext und die Struktur von Dokumenten zu verstehen und die Formatierung beizubehalten, während der Inhalt extrahiert wird. Das bedeutet, dass es komplexe Layouts erkennen, zwischen Überschriften und Text unterscheiden und Tabellen und mehrspaltige Formate richtig interpretieren kann.
Das Besondere an der OCR-API von Mistral ist die Integration mit den Sprachverständnisfunktionen von Mistral. Das System extrahiert nicht nur Text, sondern versteht ihn auch.
Dies ermöglicht anspruchsvollere Arbeitsabläufe bei der Dokumentenverarbeitung, bei denen die API nicht nur Text erkennen, sondern auch Fragen zum Inhalt des Dokuments beantworten, Informationen zusammenfassen oder bestimmte Datenpunkte extrahieren kann.
Außerdem ist die OCR-API von Mistral so konzipiert, dass sie in mehreren Sprachen und Zeichensätzen funktioniert, was sie für globale Anwendungen vielseitig macht. Diese Kombination aus präziser Texterkennung und tiefem Sprachverständnis macht das Angebot von Mistral zu einer Dokumentenintelligenzlösung der nächsten Generation und nicht nur zu einem einfachen OCR-Tool.
Die Mistral OCR API ist zwar nicht kostenlos, aber sie kostet nur $1 pro 1.000 Seiten (oder $0,001 pro Seite). Meiner Meinung nach ist das ein sehr konkurrenzfähiger und erschwinglicher Preis.
Die Dokumente dürfen nicht größer als 50 MB und nicht länger als 1.000 Seiten sein.
Weitere Informationen finden Sie auf ihrer Preisseite.
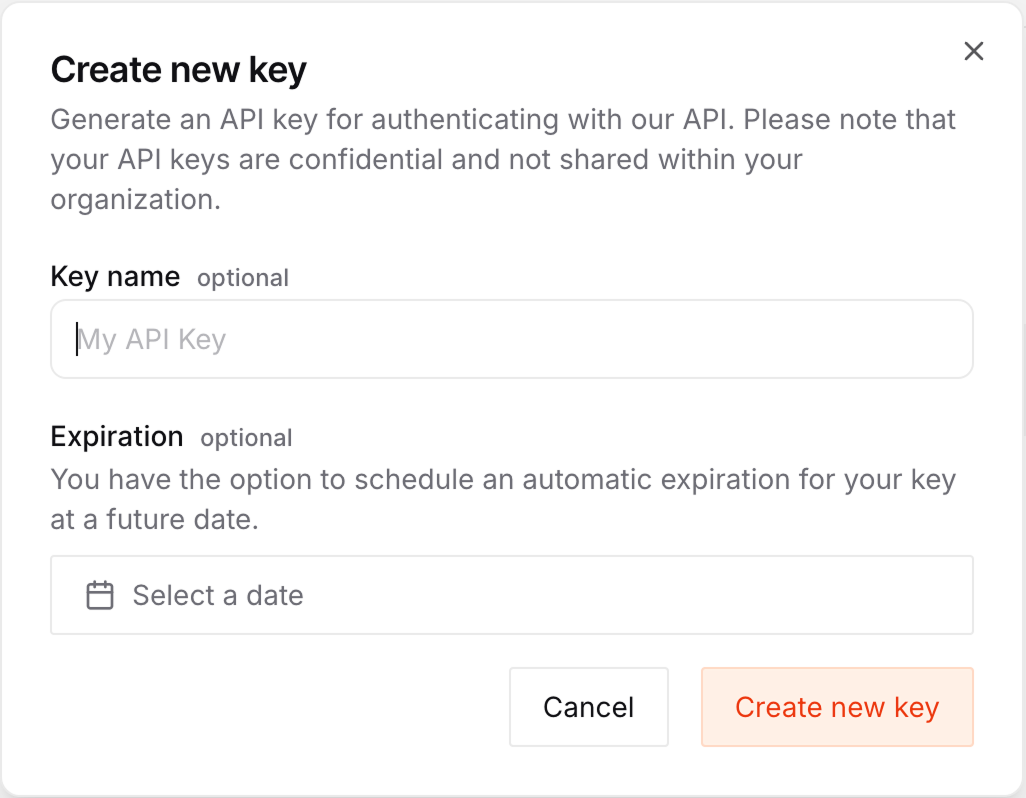
Navigieren Sie zur der Mistral-API-Schlüssel-Seite und klicke auf die Schaltfläche "Neuen Schlüssel erstellen".
Im Formular zur Schlüsselerstellung können wir ihm einen Namen und ein Ablaufdatum geben.
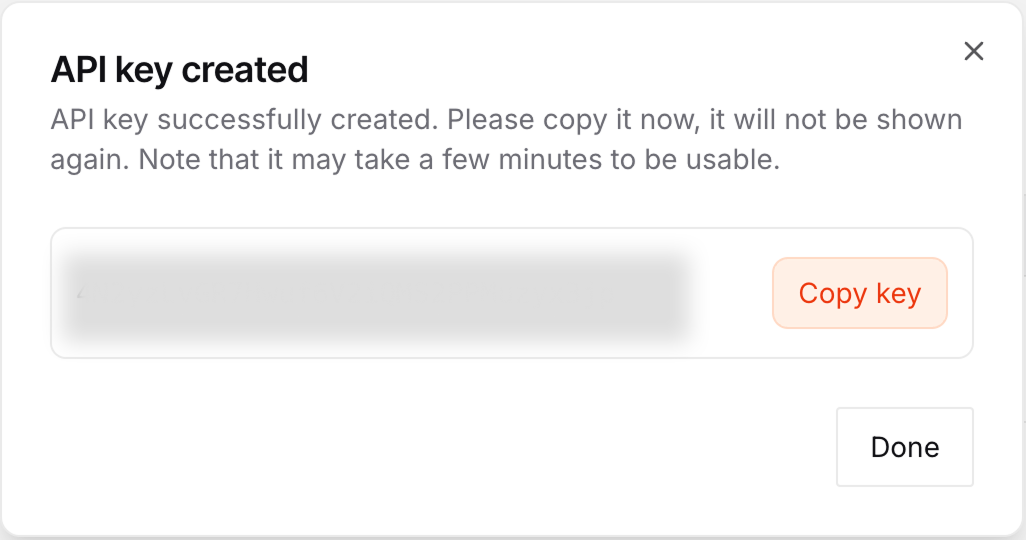
Nachdem du den Schlüssel erstellt hast, kopiere ihn und erstelle eine Datei mit dem Namen .env in demselben Ordner, in dem wir das Skript schreiben werden.
Füge den Schlüssel nach folgendem Muster in die Datei ein:
MISTRAL_API_KEY=<paste_api_key_here>Wenn du GitHub verwendest, musst du diese Datei zu .gitignore hinzufügen, damit der API-Schlüssel nicht zu GitHub hochgeladen wird.
Um die OCR-API von Mistral mit Python zu nutzen, installiere die folgenden Pakete:
mistralai: Dies ist das Paket, das von Mistral zur Verfügung gestellt wird, um mit ihrer API zu interagieren.python-dotenv: Ein Paket, das das Laden des API-Schlüssels aus der Datei .env erleichtert.datauri: Dieses Paket wird verwendet, um die Bilddaten zu verarbeiten und sie in Dateien zu speichern.Wir können diese mit dem Befehl installieren:
pip install mistralai python-dotenv datauriIch empfehle dir, eine Umgebung zu erstellen, um sicherzustellen, dass deine Installation nicht mit deiner Standard-Python-Installation kollidiert. Eine Möglichkeit, dies zu tun, ist die Verwendung von Anaconda:
conda create -n mistral -y python=3.9
conda activate mistral
pip install mistralai python-dotenv datauriDer erste Befehl erstellt eine Umgebung namens mistral, die Python 3.9 verwendet. Dann aktivieren wir diese Umgebung und installieren die oben genannten Pakete.
Schauen wir uns an, wie wir unsere erste Anfrage an die OCR-API von Mistral stellen können.
Erstelle im gleichen Ordner wie die Datei .env ein neues Python-Skript mit dem Namen ocr.py und importiere die erforderlichen Pakete:
from mistralai import Mistral
from dotenv import load_dotenv
import datauri
import osBeachte, dass wir auch os importieren, mit dem wir den API-Schlüssel aus der Umgebung in eine Variable laden. Wir brauchen es nicht zu installieren, weil es ein integriertes Paket ist.
Als nächstes fügen wir die folgenden Zeilen hinzu, um den API-Schlüssel zu laden und den Mistral-Client zu initialisieren:
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
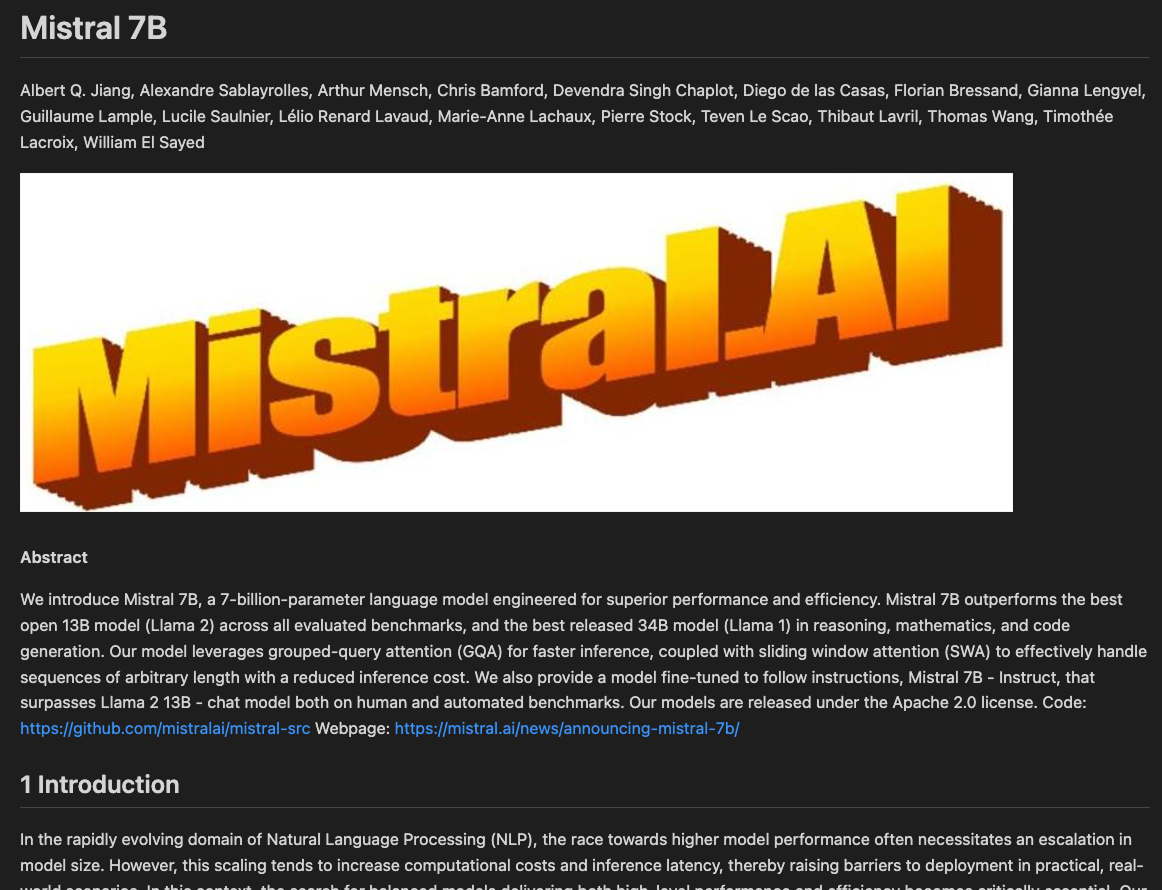
client = Mistral(api_key=api_key)Der einfachste Weg, die OCR-API zu nutzen, ist die URL einer online gehosteten PDF-Datei. Für dieses Beispiel nehmen wir dieses Mistral 7B Papier auf arXiv (eine Plattform, auf der Vorabversionen von Forschungsarbeiten veröffentlicht werden):
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2501.00663",
},
)
print(ocr_response)Wir können das Skript dann mit dem Befehl python ocr.py ausführen. Dies erzeugt die folgende Antwort:
pages=[OCRPageObject(index=0, markdown='# Mistral 7B \n\nAlbert Q. Jiang,
...Die Antwort enthält mehrere Felder. Alle Details sind verfügbar in der Mistrals API-Dokumentation. Wir interessieren uns vor allem für das Feld pages, das für jede Seite den Markdown-Text der Seite enthält.
Wir können die Anzahl der Seiten ausdrucken, um zu sehen, ob sie mit der PDF-Datei übereinstimmt:
print(len(ocr_response.pages))Ergebnis:
9Jede Seite hat mehrere Felder. Die wichtigsten davon sind:
markdown: Der Markdown-Inhalt der Seite.images: Die Bilder auf der Seite.Wir können zum Beispiel den Markdown-Inhalt für die erste Seite ausdrucken:
print(ocr_response.pages[0].markdown)# Mistral 7B
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed

#### Abstract
We introduce Mistral 7B, a 7-billion-parameter language
...Um ein PDF in Markdown zu konvertieren, gehen wir in einer Schleife über alle Seiten und schreiben den Markdown-Inhalt jeder einzelnen Seite in eine Datei. Hier ist eine Funktion, mit der du das tun kannst.
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)Hier ist ein direkter Vergleich zwischen der ursprünglichen PDF-Datei und der von uns erstellten Markdown-Datei:

Im vorherigen Beispiel haben wir gesehen, dass in der Markdown-Datei die Bilder aus der PDF-Datei fehlten. Das liegt daran, dass wir die Bilddateien nicht erstellt haben, sondern nur den Markdown-Text.
Wenn wir uns die Markdown-Ausgabe ansehen, sehen wir, dass sie einen Bildverweis enthält:
...

...Dieses Bild wird jedoch nicht gerendert. Die Bilder auf jeder Seite werden im Attribut images gespeichert.
for page in ocr_response.pages:
print(page.images)Ausgabe:
[OCRImageObject(id='img-0.jpeg', top_left_x=425, top_left_y=600, bottom_right_x=1283, bottom_right_y=893, image_base64=None)]
[OCRImageObject(id='img-1.jpeg', top_left_x=294, top_left_y=638, bottom_right_x=1405, bottom_right_y=1064, image_base64=None)]
[OCRImageObject(id='img-2.jpeg', top_left_x=294, top_left_y=191, bottom_right_x=1405, bottom_right_y=380, image_base64=None)]
[OCRImageObject(id='img-3.jpeg', top_left_x=292, top_left_y=204, bottom_right_x=1390, bottom_right_y=552, image_base64=None)]
[OCRImageObject(id='img-4.jpeg', top_left_x=464, top_left_y=202, bottom_right_x=1232, bottom_right_y=734, image_base64=None)]
[]
[OCRImageObject(id='img-5.jpeg', top_left_x=727, top_left_y=794, bottom_right_x=975, bottom_right_y=1047, image_base64=None)]
[]
[]In der obigen Ausgabe sehen wir, dass wir tatsächlich einen Verweis auf img-0.jpeg haben. Die Daten sind jedoch nicht vorhanden: image_base64=None.
Um die Bilddaten zu erhalten, müssen wir die OCR-Anfrage so ändern, dass sie die Bilddaten enthält, indem wir den Parameter include_image_base64=True hinzufügen.
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
include_image_base64=True,
)Wenn wir die Bilder erneut ausdrucken, werden wir sehen, dass die Felder von image_base_64 jetzt ausgefüllt sind. Wie der Name des Feldes schon sagt, werden die Bilddaten in Base 64 gespeichert. Wir werden nicht näher darauf eingehen, wie die Base-64-Bilddarstellung funktioniert. Stattdessen stellen wir eine Funktion bereit, die das zuvor installierte Paket datauri verwendet, um ein Bild in eine Datei zu schreiben:
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as file:
file.write(parsed.data)Jetzt können wir die Funktion create_markdown_file() aktualisieren, um auch alle Bilder in Dateien zu schreiben:
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)Wenn wir den aktualisierten Code ausführen und die Markdown-Vorschau erneut anzeigen lassen, sehen wir die Bilder.
Im obigen Beispiel haben wir eine Datei verwendet, die bereits gehostet wurde. Um mit einer PDF-Datei von unserem Computer aus zu arbeiten, ermöglicht uns die Mistral-API, eine Datei mit der Funktion client.files.upload() hochzuladen. Angenommen, die PDF-Datei myfile.pdf befindet sich im selben Ordner wie das Skript, dann gehen wir folgendermaßen vor:
filename = "myfile.pdf"
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)Jeder Datei, die auf diese Weise hochgeladen wird, ist eine eindeutige ID zugeordnet, die benötigt wird, um auf diese Datei zu verweisen. Wir können sie über das id Attribut des Ergebnisses aufrufen, etwa so:
print(uploaded_pdf.id)Um die OCR für diese Datei durchzuführen, müssen wir ihre URL angeben. Wir können sie mit der Funktion client.files.get_signed_url() abrufen, indem wir die Datei-ID angeben:
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)Zusammengenommen können wir eine Funktion implementieren, die eine Datei über die Mistral-API hochlädt und ihre URL abruft:
def upload_pdf(filename):
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
return signed_url.urlHier ist ein Beispiel für eine OCR-Anfrage mit einer lokalen Datei:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": upload_pdf("myfile.pdf"),
},
include_image_base64=True,
)Um eine andere Datei zu verwenden, ersetzen wir myfile.pdf durch den Namen der Datei, die wir verwenden wollen.
Die OCR-API funktioniert auch mit Bildeingaben. Um ein Bild zu verwenden, benutzen wir den Typ image_url anstelle von document_url:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": <url of the image>,
},
)Im obigen Beispiel müssen wir durch die URL des Bildes ersetzen.
Um ein lokales Bild zu verwenden, können wir die folgende Funktion verwenden, um es zu laden:
def load_image(image_path):
import base64
mime_type, _ = mimetypes.guess_type(image_path)
with open(image_path, "rb") as image_file:
image_data = image_file.read()
base64_encoded = base64.b64encode(image_data).decode('utf-8')
base64_url = f"data:{mime_type};base64,{base64_encoded}"
return base64_urlDiese Funktion verwendet das Paket base64, das ein eingebautes Paket ist, sodass wir es nicht installieren müssen.
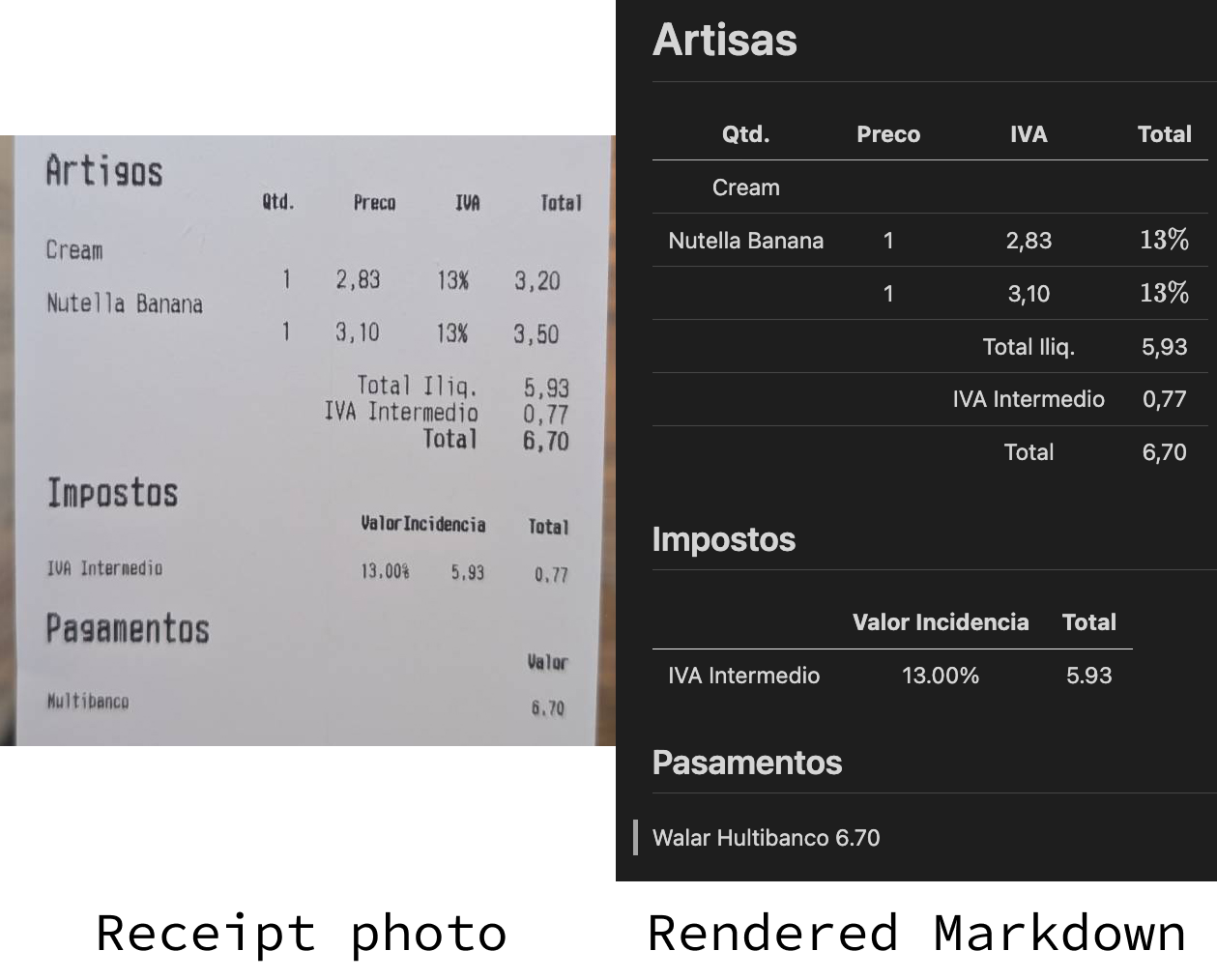
Versuchen wir, diese Quittung, die wir in einer Datei namens receipt.jpeg gespeichert haben, mit OCR zu bearbeiten:
Wir können die OCR-Anfrage stellen, indem wir die Funktion load_image() verwenden, um das Bild von unserem Computer zu laden:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": load_image("receipt.jpeg"),
},
)Das Ergebnis siehst du auf dem Bild oben. Es ist bei weitem nicht perfekt, aber das Ergebnis ist nicht so weit weg.
OCR bietet eine effiziente Möglichkeit, Daten in ein Textformat umzuwandeln, das für LLMs verwendbar ist. Die Mistral-API ermöglicht es den Nutzern, Dokumente und Eingabeaufforderungen in den LLM-Anfragen zu kombinieren. Hinter den Kulissen wird die OCR-API verwendet, um die Dokumente für den LLM-Verbrauch zu verarbeiten.
Versuchen wir, den Artikel, auf den wir uns in diesem Lernprogramm beziehen, auf diese Weise zusammenzufassen.
Wenn du die Mistral-Chat-API zum ersten Mal verwendest, solltest du vielleicht diesen umfassenden Mistral-Leitfaden lesen, da wir hier nicht ins Detail gehen werden, wie sie funktioniert.
Hier ist ein vollständiges Python-Beispiel für die Frage nach einer leicht verständlichen Erklärung des Artikels:
from mistralai import Mistral
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Explain this article in detail to someone who doesn't have a technical background",
},
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
],
}
]
chat_response = client.chat.complete(
model="mistral-small-latest",
messages=messages,
)
print(chat_response.choices[0].message.content)Beachte, dass die Datei in demselben Format bereitgestellt wird, das wir oben gelernt haben:
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
}Nachdem du nun gelernt hast, wie du Mistral OCR in deine Python-Projekte einbauen kannst, wollen wir uns nun einige praktische Anwendungen ansehen, bei denen du das Gelernte anwenden kannst.
Du kannst Texte, Gleichungen, Tabellen und Abbildungen aus wissenschaftlichen Arbeiten extrahieren, um einen personalisierten Forschungsassistenten zu erstellen. Du könntest ein System entwickeln, das die wichtigsten Ergebnisse zusammenfasst, Details zur Methodik extrahiert oder eine durchsuchbare Datenbank mit Artikeln aus deinem Fachgebiet erstellt.
Du kannst physische Archive oder gescannte Dokumente in durchsuchbare digitale Sammlungen umwandeln. Das ist besonders wertvoll für historische Dokumente, Familienunterlagen oder Organisationsarchive, die bewahrt werden und leicht zugänglich sein müssen.
Du kannst die mehrsprachigen Fähigkeiten von Mistral OCR nutzen, um Dokumente in verschiedenen Sprachen zu verarbeiten. Das kann für internationale Unternehmen, Übersetzungsdienste oder globale Forschungsprojekte nützlich sein, die Informationen aus Dokumenten in verschiedenen Schriften extrahieren müssen.
Du kannst Lehrbücher, Vorlesungsfolien und handschriftliche Notizen in digitale Formate umwandeln. Erstelle ein System, das Schlüsselkonzepte, Formeln und Diagramme extrahiert, um personalisierte Lernmaterialien oder Fragebänke zu erstellen.
Du kannst die Extraktion von Daten aus Rechnungen, Quittungen, Jahresabschlüssen oder Steuerunterlagen automatisieren. Dies könnte die Buchhaltungsprozesse rationalisieren oder bei der Ausgabenverwaltung und Finanzanalyse helfen.
Die OCR-API von Mistral ist ein leistungsfähiges Werkzeug zum Extrahieren und Verstehen von Text aus Dokumenten und Bildern. In diesem Lernprogramm haben wir uns angesehen, wie du diese Funktion für verschiedene Aufgaben der Dokumentenverarbeitung einrichtest und nutzt.
Wenn du die in diesem Tutorial beschriebenen Schritte befolgst, kannst du die OCR von Mistral in deine Anwendungen einbinden, egal ob du Archive digitalisierst, die Dateneingabe automatisierst oder intelligente Dokumentenmanagementsysteme aufbaust. Wenn sich die Technologie weiterentwickelt, können wir mit noch genaueren und kontextbezogenen Dokumentenverarbeitungsfunktionen rechnen, die die Lücke zwischen physischen Dokumenten und digitalen Arbeitsabläufen weiter schließen.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
