programa
Desarrollo de aplicaciones de IA
21 h
La semana pasada, Mistral lanzó Mistral OCR, una innovadora API de reconocimiento óptico de caracteres (OCR). Su API establece un nuevo estándar de capacidades de IA para comprender documentos e imágenes. Es capaz de procesar y analizar documentos con imágenes, matemáticas, tablas y mucho más con un alto grado de precisión.
En este artículo, te explicaré paso a paso cómo utilizar Mistral OCR utilizando Python. Te mostraré cómo puedes utilizarlo con documentos, imágenes y cómo combinarlo con el chat para combinar avisos con documentos.
El reconocimiento óptico de caracteres, o OCR, es una tecnología que convierte distintos tipos de documentos -como documentos en papel escaneados, archivos PDF o imágenes capturadas por una cámara digital- en datos editables y que permiten realizar búsquedas.
El OCR funciona identificando caracteres de texto en las imágenes, analizando sus patrones y traduciendo estos elementos visuales en texto codificado por la máquina. Esta tecnología ha transformado la forma en que interactuamos con los materiales impresos, permitiendo desde digitalizar archivos históricos hasta automatizar la introducción de datos de formularios comerciales.
La API de OCR de Mistral representa un avance significativo en este campo, ya que ofrece a los desarrolladores una potente herramienta para extraer texto de imágenes y documentos con notable precisión.

Fuente: Mistral
A diferencia de las soluciones tradicionales de OCR que se limitan a identificar el texto, la API de Mistral utiliza modelos avanzados de IA para comprender el contexto y la estructura de los documentos, manteniendo el formato mientras extrae el contenido. Esto significa que puede reconocer diseños complejos, diferenciar entre cabeceras y cuerpo de texto, e interpretar correctamente tablas y formatos de varias columnas.
Lo que hace especialmente especial a la API de OCR de Mistral es su integración con las capacidades de comprensión lingüística de Mistral. El sistema no sólo extrae texto, sino que lo comprende.
Esto permite flujos de trabajo de procesamiento de documentos más sofisticados, en los que la API no sólo puede reconocer texto, sino también responder a preguntas sobre el contenido del documento, resumir información o extraer puntos de datos concretos.
Además, la API de OCR de Mistral está diseñada para funcionar en varios idiomas y conjuntos de caracteres, lo que la hace versátil para aplicaciones globales. Esta combinación de reconocimiento de texto preciso con comprensión profunda del lenguaje posiciona la oferta de Mistral como una solución de inteligencia documental de nueva generación, y no como una simple herramienta de OCR.
La API Mistral OCR no es gratuita, pero sólo cuesta 1 $ por cada 1.000 páginas (o 0,001 $ por página). En mi opinión, es un precio muy competitivo y asequible.
Los archivos de los documentos no deben superar los 50 MB de tamaño y no deben tener más de 1.000 páginas.
Puedes encontrar más información en su página de precios.
Navega hasta la página de la clave API de Mistral y haz clic en el botón "Crear nueva clave".
En el formulario de creación de claves, podemos darle un nombre y una fecha de caducidad.
Después de crear la clave, cópiala y crea un archivo llamado .env en la misma carpeta donde escribiremos el script.
Pega la clave en el archivo utilizando el siguiente formato:
MISTRAL_API_KEY=<paste_api_key_here>Si utilizas GitHub, asegúrate de añadir este archivo a .gitignore para evitar subir la clave API a GitHub.
Para utilizar la API OCR de Mistral con Python, instala los siguientes paquetes:
mistralai: Este es el paquete proporcionado por Mistral para interactuar con su API.python-dotenv: Un paquete para facilitar la carga de la clave API desde el archivo .env.datauri: Este paquete se utiliza para procesar los datos de la imagen y guardarlos en archivos.Podemos instalarlos utilizando el comando
pip install mistralai python-dotenv datauriTe recomiendo que crees un entorno para asegurarte de que tu instalación no entra en conflicto con tu instalación por defecto de Python. Una forma de hacerlo es utilizar Anaconda:
conda create -n mistral -y python=3.9
conda activate mistral
pip install mistralai python-dotenv datauriEl primer comando crea un entorno llamado mistral que utiliza Python 3.9. A continuación, activamos ese entorno e instalamos los paquetes mencionados anteriormente.
Veamos cómo podemos hacer nuestra primera petición a la API OCR de Mistral.
En la misma carpeta que el archivo .env, crea un nuevo script de Python llamado ocr.py e importa los paquetes necesarios:
from mistralai import Mistral
from dotenv import load_dotenv
import datauri
import osTen en cuenta que también importamos os, que utilizamos para cargar la clave API del entorno en una variable. No necesitamos instalarlo porque es un paquete incorporado.
A continuación, añadimos las siguientes líneas para cargar la clave API e inicializar el cliente Mistral:
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
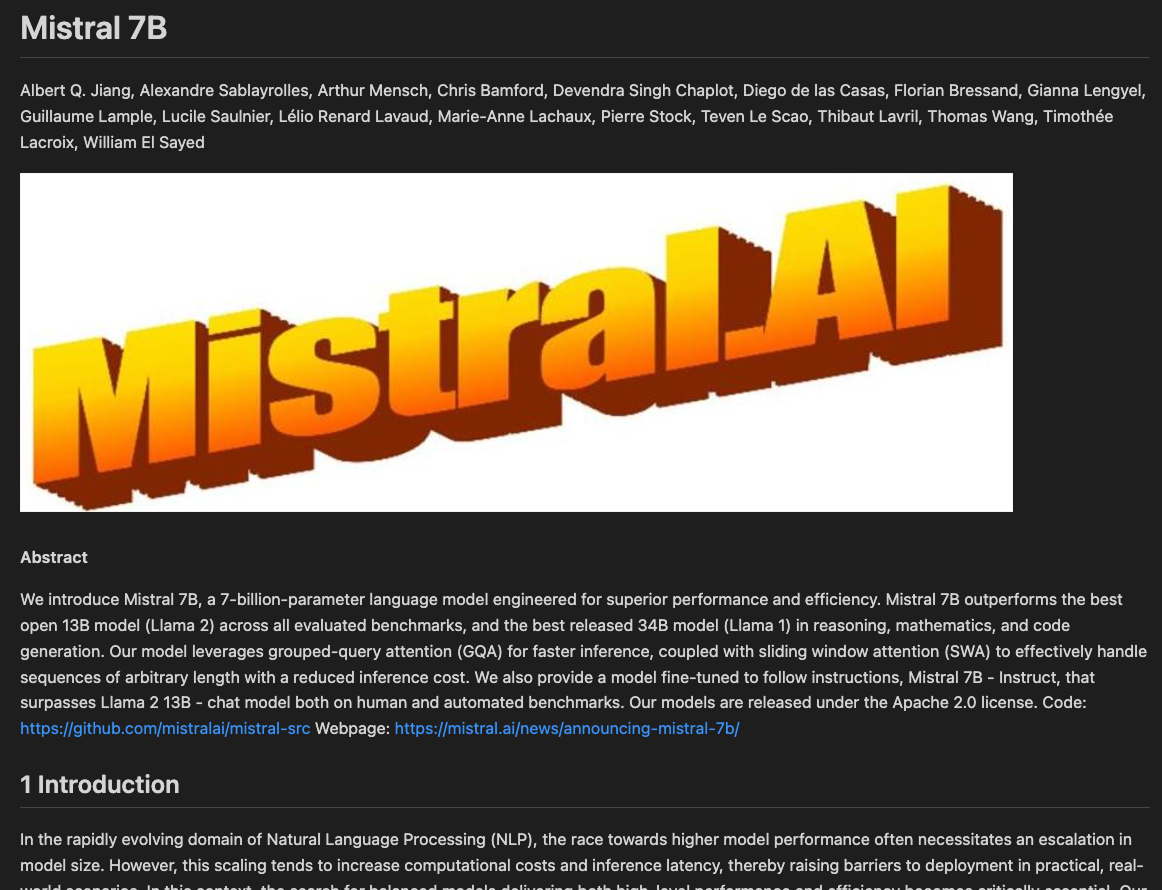
client = Mistral(api_key=api_key)La forma más sencilla de utilizar la API de OCR es con la URL de un PDF alojado en Internet. Para este ejemplo, vamos a utilizar este artículo Mistral 7B alojado en arXiv (una plataforma que aloja versiones previas a la presentación de trabajos de investigación):
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2501.00663",
},
)
print(ocr_response)A continuación, podemos ejecutar el script utilizando el comando python ocr.py. Esto generará la siguiente respuesta:
pages=[OCRPageObject(index=0, markdown='# Mistral 7B \n\nAlbert Q. Jiang,
...La respuesta contiene varios campos. Encontrarás todos los detalles en la documentación de la API de Mistral. Nos interesa en particular el campo pages, que contiene, para cada página, el texto de la página en formato markdown.
Podemos imprimir el número de páginas para ver que coincide con el archivo PDF:
print(len(ocr_response.pages))Resultado:
9Cada página tiene varios campos. Los más importantes son:
markdown: El contenido markdown de la página.images: Las imágenes de la página.Por ejemplo, podemos imprimir el contenido markdown de la primera página utilizando:
print(ocr_response.pages[0].markdown)# Mistral 7B
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed

#### Abstract
We introduce Mistral 7B, a 7-billion-parameter language
...Para convertir un PDF en Markdown, hacemos un bucle sobre todas las páginas y escribimos el contenido Markdown de cada una de ellas en un archivo. Aquí tienes una función para hacerlo.
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)Aquí tienes una comparación entre el archivo PDF original y el archivo Markdown que hemos generado:

En el ejemplo anterior, vimos que el archivo Markdown no tenía las imágenes del PDF. Eso es porque no hemos creado los archivos de imagen, sino sólo el texto Markdown.
Si miramos la salida markdown, vemos que tiene una referencia de imagen:
...

...Sin embargo, esa imagen no se renderiza. Las imágenes de cada página se almacenan en el atributo images.
for page in ocr_response.pages:
print(page.images)Salida:
[OCRImageObject(id='img-0.jpeg', top_left_x=425, top_left_y=600, bottom_right_x=1283, bottom_right_y=893, image_base64=None)]
[OCRImageObject(id='img-1.jpeg', top_left_x=294, top_left_y=638, bottom_right_x=1405, bottom_right_y=1064, image_base64=None)]
[OCRImageObject(id='img-2.jpeg', top_left_x=294, top_left_y=191, bottom_right_x=1405, bottom_right_y=380, image_base64=None)]
[OCRImageObject(id='img-3.jpeg', top_left_x=292, top_left_y=204, bottom_right_x=1390, bottom_right_y=552, image_base64=None)]
[OCRImageObject(id='img-4.jpeg', top_left_x=464, top_left_y=202, bottom_right_x=1232, bottom_right_y=734, image_base64=None)]
[]
[OCRImageObject(id='img-5.jpeg', top_left_x=727, top_left_y=794, bottom_right_x=975, bottom_right_y=1047, image_base64=None)]
[]
[]En la salida anterior, vemos que efectivamente tenemos una referencia a img-0.jpeg. Sin embargo, los datos no están presentes: image_base64=None.
Para obtener los datos de la imagen, tenemos que modificar la petición OCR para incluir los datos de la imagen añadiendo el parámetro include_image_base64=True.
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
include_image_base64=True,
)Si volvemos a imprimir las imágenes, veremos que los campos image_base_64 están ahora rellenos. Como indica el nombre del campo, los datos de la imagen se almacenan en base 64. No vamos a entrar en los detalles de cómo funciona la representación de imágenes en base-64. En su lugar, proporcionamos una función que utiliza el paquete datauri que instalamos antes para escribir una imagen en un archivo:
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as file:
file.write(parsed.data)Ahora podemos actualizar la función create_markdown_file() para que también escriba todas las imágenes en archivos:
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)Si ejecutamos el código actualizado y volvemos a renderizar la vista previa de Markdown, veremos las imágenes.
En el ejemplo anterior, hemos utilizado un archivo que ya estaba alojado. Para trabajar con un archivo PDF desde nuestro ordenador, la API de Mistral nos permite subir un archivo utilizando la función client.files.upload(). Suponiendo que el archivo PDF, myfile.pdf esté en la misma carpeta que el script, así es como se hace:
filename = "myfile.pdf"
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)Cada archivo subido de esta forma tiene asociado un ID único, que es necesario para referirse a ese archivo. Podemos acceder a él utilizando el atributo id del resultado, así:
print(uploaded_pdf.id)Para realizar el OCR en ese archivo, necesitamos proporcionar su URL. Podemos obtenerlo utilizando la función client.files.get_signed_url() proporcionando el ID del archivo:
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)Juntándolo todo, podemos implementar una función que suba un archivo utilizando la API de Mistral y recupere su URL:
def upload_pdf(filename):
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
return signed_url.urlAquí tienes un ejemplo de solicitud de OCR con un archivo local:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": upload_pdf("myfile.pdf"),
},
include_image_base64=True,
)Para utilizar otro archivo, sustituimos myfile.pdf por el nombre del archivo que queremos utilizar.
La API de OCR también funciona con entradas de imágenes. Para utilizar una imagen, utilizamos el tipo image_url en lugar de document_url:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": <url of the image>,
},
)En el ejemplo anterior, tendríamos que sustituir por la URL de la imagen.
Para utilizar una imagen local, podemos utilizar la siguiente función para cargarla:
def load_image(image_path):
import base64
mime_type, _ = mimetypes.guess_type(image_path)
with open(image_path, "rb") as image_file:
image_data = image_file.read()
base64_encoded = base64.b64encode(image_data).decode('utf-8')
base64_url = f"data:{mime_type};base64,{base64_encoded}"
return base64_urlEsta función utiliza el paquete base64, que es un paquete incorporado, por lo que no necesitamos instalarlo.
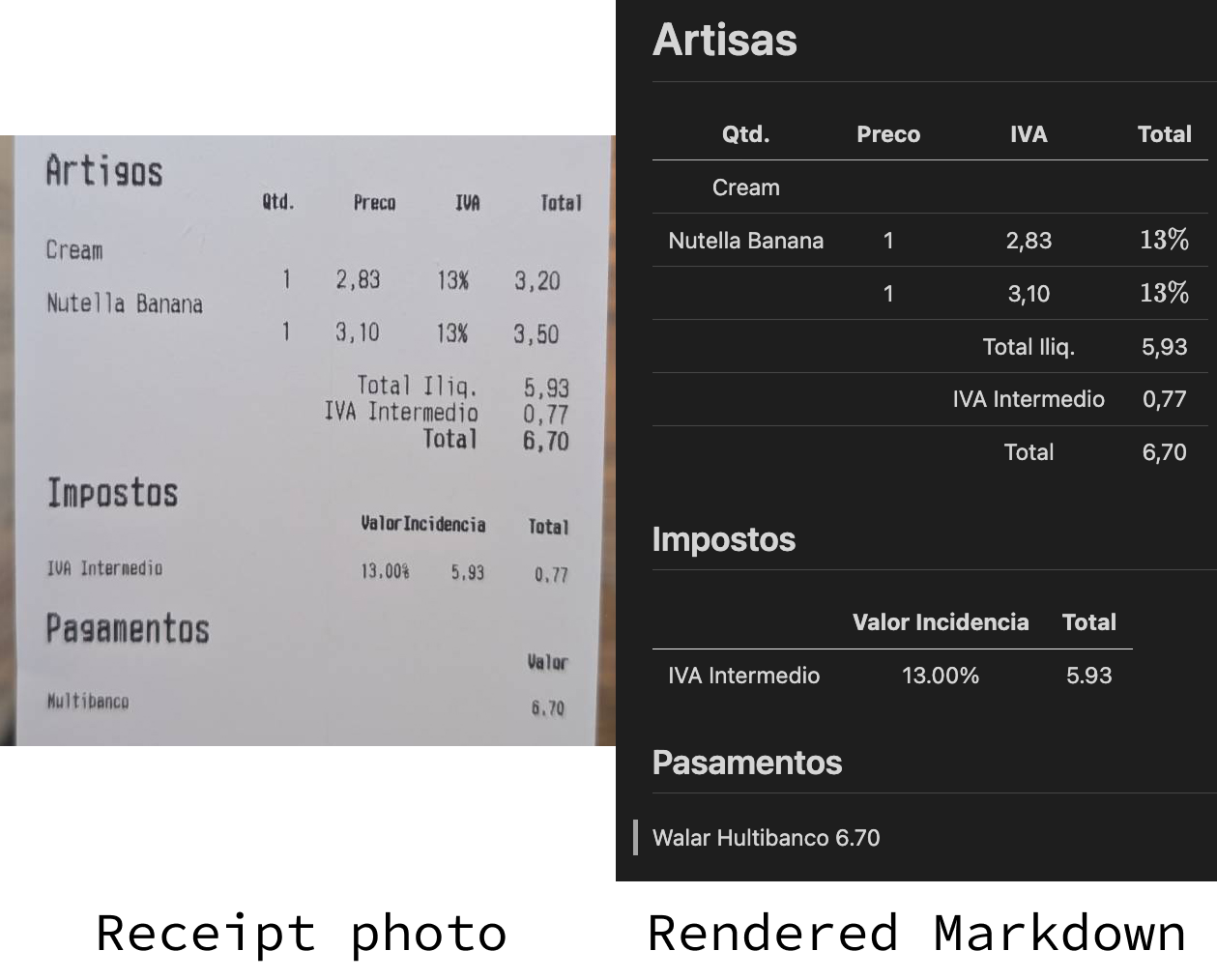
Intentemos realizar un reconocimiento óptico de caracteres en este recibo que hemos guardado en un archivo llamado receipt.jpeg:
Podemos realizar la solicitud de OCR utilizando la función load_image() para cargar la imagen desde nuestro ordenador:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": load_image("receipt.jpeg"),
},
)Puedes ver el resultado en la imagen superior. Está lejos de ser perfecto, pero el resultado no está tan lejos.
El OCR proporciona una forma eficaz de convertir los datos en un formato de texto listo para ser utilizado por los LLM. La API de Mistral permite a los usuarios combinar documentos y peticiones en las solicitudes LLM. Entre bastidores, la API de OCR se utiliza para procesar los documentos para el consumo de LLM.
Intentemos utilizarlo para resumir el artículo al que hemos hecho referencia a lo largo de este tutorial.
Si es la primera vez que utilizas la API de chat de Mistral, quizá quieras leer esta completa guía de Mistral ya que no entraremos en detalles sobre su funcionamiento.
Aquí tienes un ejemplo completo en Python para pedir una explicación fácil de entender del artículo:
from mistralai import Mistral
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Explain this article in detail to someone who doesn't have a technical background",
},
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
],
}
]
chat_response = client.chat.complete(
model="mistral-small-latest",
messages=messages,
)
print(chat_response.choices[0].message.content)Ten en cuenta que el archivo se proporciona utilizando el mismo formato que aprendimos anteriormente:
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
}Ahora que has aprendido a implementar Mistral OCR en tus proyectos de Python, vamos a explorar algunas aplicaciones prácticas en las que podrías aplicar lo que hemos aprendido.
Puedes extraer texto, ecuaciones, tablas y figuras de artículos científicos para construir un asistente de investigación personalizado. Podrías crear un sistema que resuma las conclusiones clave, extraiga detalles metodológicos o cree una base de datos de artículos de tu campo en la que se puedan hacer búsquedas.
Puedes transformar archivos físicos o documentos escaneados en colecciones digitales en las que se puedan realizar búsquedas. Esto es especialmente valioso para documentos históricos, registros familiares o archivos de organizaciones que necesitan conservación y fácil acceso.
Puedes utilizar las funciones multilingües de Mistral OCR para procesar documentos en varios idiomas. Esto podría ser útil para empresas internacionales, servicios de traducción o proyectos de investigación globales que necesiten extraer información de documentos en diferentes alfabetos.
Puedes convertir libros de texto, diapositivas de clases y apuntes escritos a mano en formatos digitales. Crea un sistema que extraiga conceptos clave, fórmulas y diagramas para construir materiales de estudio personalizados o bancos de preguntas.
Puedes automatizar la extracción de datos de facturas, recibos, estados financieros o documentos fiscales. Esto podría agilizar los procesos contables o ayudar en la gestión de gastos y el análisis financiero.
La API de OCR de Mistral proporciona una potente herramienta para extraer y comprender texto de documentos e imágenes. En este tutorial, hemos explorado cómo configurar y utilizar esta capacidad para diversas tareas de tratamiento de documentos.
Siguiendo los pasos descritos en este tutorial, podrás incorporar el OCR de Mistral a tus aplicaciones, tanto si digitalizas archivos como si automatizas la entrada de datos o creas sistemas inteligentes de gestión de documentos. A medida que la tecnología siga evolucionando, podemos esperar capacidades de procesamiento de documentos aún más precisas y conscientes del contexto, que acorten aún más la distancia entre los documentos físicos y los flujos de trabajo digitales.
Aprende IA con estos cursos
programa
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Duong Vu


