Cursus
Développer des applications d'IA
21 h
La semaine dernière, Mistral a lancé Mistral OCR, une API innovante de reconnaissance optique de caractères (OCR). Leur API établit une nouvelle norme pour les capacités de l'IA à comprendre les documents et les images. Il est capable de traiter et d'analyser avec une grande précision des documents contenant des images, des mathématiques, des tableaux, etc.
Dans cet article, je vais vous expliquer pas à pas comment utiliser Mistral OCR à l'aide de Python. Je vous montrerai comment vous pouvez l'utiliser avec des documents, des images, et comment le combiner avec le chat pour associer des messages-guides à des documents.
La reconnaissance optique de caractères, ou OCR, est une technologie qui convertit différents types de documents - tels que des documents papier numérisés, des fichiers PDF ou des images capturées par un appareil photo numérique - en données modifiables et consultables.
L'OCR identifie les caractères du texte dans les images, analyse leurs motifs et traduit ces éléments visuels en texte codé par la machine. Cette technologie a transformé la façon dont nous interagissons avec les documents imprimés, permettant tout, de la numérisation des archives historiques à l'automatisation de la saisie de données dans les formulaires commerciaux.
L'API OCR de Mistral représente une avancée significative dans ce domaine, offrant aux développeurs un outil puissant pour extraire du texte à partir d'images et de documents avec une précision remarquable.

Source : Mistral
Contrairement aux solutions OCR traditionnelles qui se contentent d'identifier le texte, l'API de Mistral utilise des modèles d'IA avancés pour comprendre le contexte et la structure des documents, en conservant le formatage tout en extrayant le contenu. Cela signifie qu'il peut reconnaître des mises en page complexes, faire la différence entre les en-têtes et le corps du texte et interpréter correctement les tableaux et les formats à plusieurs colonnes.
Ce qui rend l'API OCR de Mistral particulièrement spéciale, c'est son intégration avec les capacités de compréhension de la langue de Mistral. Le système ne se contente pas d'extraire du texte, il le comprend.
Cela permet des flux de traitement de documents plus sophistiqués où l'API peut non seulement reconnaître du texte mais aussi répondre à des questions sur le contenu du document, résumer des informations ou extraire des points de données spécifiques.
En outre, l'API OCR de Mistral est conçue pour fonctionner dans plusieurs langues et jeux de caractères, ce qui la rend polyvalente pour les applications internationales. Cette combinaison d'une reconnaissance précise du texte et d'une compréhension approfondie du langage positionne l'offre de Mistral comme une solution d'intelligence documentaire de nouvelle génération plutôt que comme un simple outil d'OCR.
L'API OCR de Mistral n'est pas gratuite, mais elle ne coûte qu'un dollar pour 1 000 pages (ou 0,001 dollar par page). Il s'agit d'un prix très compétitif et abordable, à mon avis.
Les fichiers de documents ne doivent pas dépasser 50 Mo et ne doivent pas comporter plus de 1 000 pages.
Vous trouverez plus d'informations sur leur page de tarification.
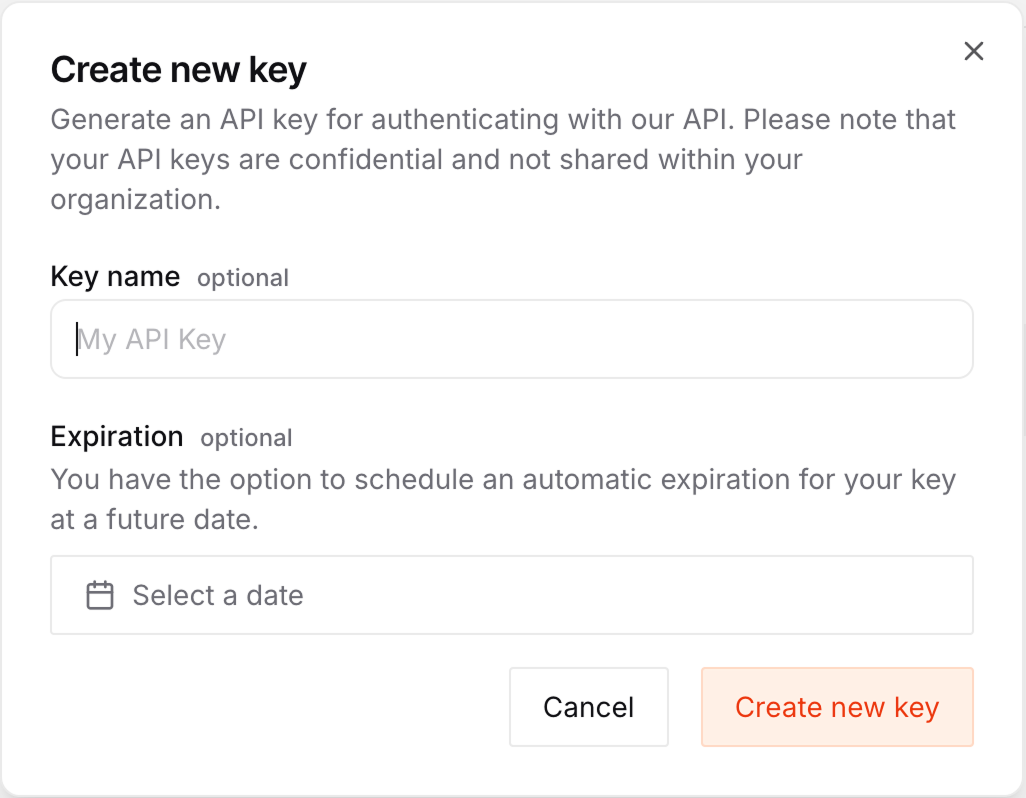
Naviguez jusqu'à la page de la clé API Mistral et cliquez sur le bouton "Créer une nouvelle clé".
Sur le formulaire de création de clé, nous pouvons lui donner un nom et une date d'expiration.
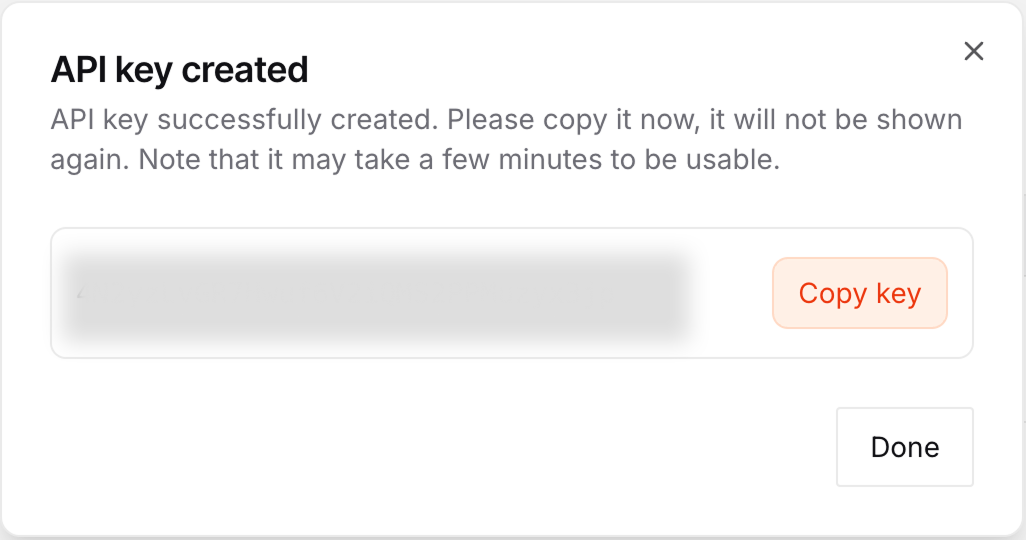
Après avoir créé la clé, copiez-la et créez un fichier nommé .env dans le même dossier que celui où nous écrirons le script.
Collez la clé dans le fichier en utilisant le format suivant :
MISTRAL_API_KEY=<paste_api_key_here>Si vous utilisez GitHub, assurez-vous d'ajouter ce fichier à l'adresse .gitignore pour éviter de télécharger la clé API sur GitHub.
Pour utiliser l'API OCR de Mistral avec Python, installez les paquets suivants :
mistralai: Il s'agit du paquetage fourni par Mistral pour interagir avec leur API.python-dotenv: Un paquet pour faciliter le chargement de la clé API à partir du fichier .env.datauri: Ce logiciel est utilisé pour traiter les données de l'image et les enregistrer dans des fichiers.Nous pouvons les installer à l'aide de la commande :
pip install mistralai python-dotenv datauriJe vous recommande de créer un environnement pour vous assurer que votre installation n'entre pas en conflit avec votre installation par défaut de Python. Une façon de le faire est d'utiliser Anaconda:
conda create -n mistral -y python=3.9
conda activate mistral
pip install mistralai python-dotenv datauriLa première commande crée un environnement nommé mistral qui utilise Python 3.9. Ensuite, nous activons cet environnement et installons les paquets mentionnés ci-dessus.
Voyons comment nous pouvons faire notre première demande à l'API OCR de Mistral.
Dans le même dossier que le fichier .env, créez un nouveau script Python nommé ocr.py et importez les paquets nécessaires :
from mistralai import Mistral
from dotenv import load_dotenv
import datauri
import osNotez que nous importons également os, que nous utilisons pour charger la clé API de l'environnement dans une variable. Nous n'avons pas besoin de l'installer car il s'agit d'un paquet intégré.
Ensuite, nous ajoutons les lignes suivantes pour charger la clé API et initialiser le client Mistral :
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)La façon la plus simple d'utiliser l'API OCR consiste à utiliser l'URL d'un PDF hébergé en ligne. Pour cet exemple, utilisons ce document Mistral 7B hébergé sur arXiv (une plateforme qui héberge des versions préliminaires de documents de recherche) :
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2501.00663",
},
)
print(ocr_response)Nous pouvons ensuite exécuter le script à l'aide de la commande python ocr.py. Vous obtiendrez la réponse suivante :
pages=[OCRPageObject(index=0, markdown='# Mistral 7B \n\nAlbert Q. Jiang,
...La réponse contient plusieurs champs. Tous les détails sont disponibles dans la la documentation de l'API de Mistral. Nous nous intéressons en particulier au champ pages, qui contient, pour chaque page, le texte en markdown de la page.
Nous pouvons imprimer le nombre de pages pour vérifier qu'il correspond au fichier PDF :
print(len(ocr_response.pages))Résultat :
9Chaque page comporte plusieurs champs. Les plus importantes sont les suivantes :
markdown: Le contenu en markdown de la page.images: Les images de la page.Par exemple, nous pouvons imprimer le contenu markdown de la première page en utilisant :
print(ocr_response.pages[0].markdown)# Mistral 7B
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed

#### Abstract
We introduce Mistral 7B, a 7-billion-parameter language
...Pour convertir un PDF en Markdown, nous parcourons toutes les pages et écrivons le contenu Markdown de chacune d'entre elles dans un fichier. Voici une fonction qui permet de le faire.
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
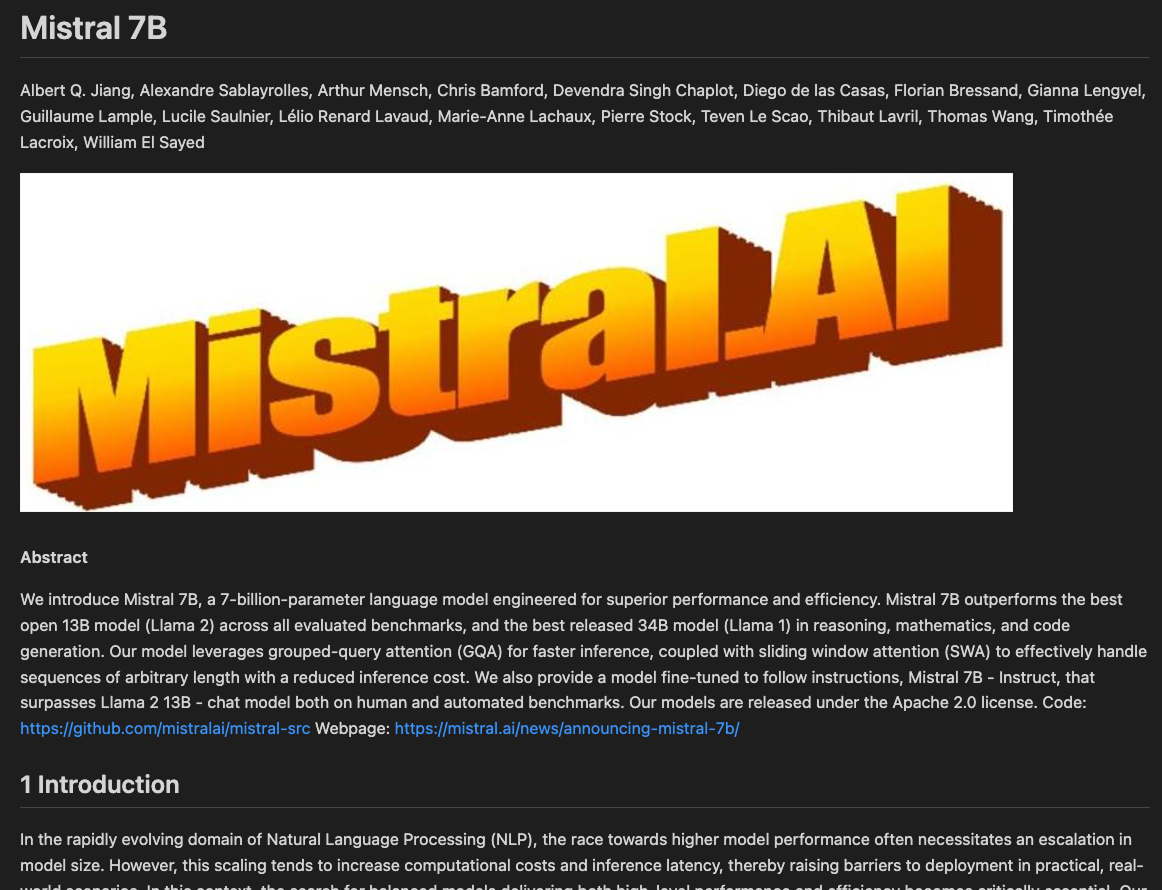
f.write(page.markdown)Voici une comparaison côte à côte entre le fichier PDF original et le fichier Markdown que nous avons généré :

Dans l'exemple précédent, nous avons vu que le fichier Markdown ne contenait pas les images du PDF. C'est parce que nous n'avons pas créé les fichiers images, mais seulement le texte Markdown.
Si nous examinons la sortie markdown, nous constatons qu'elle contient une référence d'image :
...

...Cependant, cette image n'est pas rendue. Les images de chaque page sont stockées dans l'attribut images.
for page in ocr_response.pages:
print(page.images)Sortie :
[OCRImageObject(id='img-0.jpeg', top_left_x=425, top_left_y=600, bottom_right_x=1283, bottom_right_y=893, image_base64=None)]
[OCRImageObject(id='img-1.jpeg', top_left_x=294, top_left_y=638, bottom_right_x=1405, bottom_right_y=1064, image_base64=None)]
[OCRImageObject(id='img-2.jpeg', top_left_x=294, top_left_y=191, bottom_right_x=1405, bottom_right_y=380, image_base64=None)]
[OCRImageObject(id='img-3.jpeg', top_left_x=292, top_left_y=204, bottom_right_x=1390, bottom_right_y=552, image_base64=None)]
[OCRImageObject(id='img-4.jpeg', top_left_x=464, top_left_y=202, bottom_right_x=1232, bottom_right_y=734, image_base64=None)]
[]
[OCRImageObject(id='img-5.jpeg', top_left_x=727, top_left_y=794, bottom_right_x=975, bottom_right_y=1047, image_base64=None)]
[]
[]Dans la sortie ci-dessus, nous voyons que nous avons effectivement une référence à img-0.jpeg. Cependant, les données ne sont pas présentes : image_base64=None.
Pour obtenir les données de l'image, nous devons modifier la requête OCR pour inclure les données de l'image en ajoutant le paramètre include_image_base64=True.
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
include_image_base64=True,
)Si nous imprimons à nouveau les images, nous verrons que les champs image_base_64 sont maintenant remplis. Comme le nom du champ l'indique, les données de l'image sont stockées en base 64. Nous n'entrerons pas dans les détails du fonctionnement de la représentation des images en base 64. Au lieu de cela, nous fournissons une fonction qui utilise le paquetage datauri que nous avons installé plus tôt pour écrire une image dans un fichier :
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as file:
file.write(parsed.data)Nous pouvons maintenant mettre à jour la fonction create_markdown_file() pour qu'elle écrive également toutes les images dans des fichiers :
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)Si nous exécutons le code mis à jour et réexécutons l'aperçu Markdown, nous voyons les images.
Dans l'exemple ci-dessus, nous avons utilisé un fichier déjà hébergé. Pour travailler avec un fichier PDF à partir de notre ordinateur, l'API Mistral nous permet de télécharger un fichier à l'aide de la fonction client.files.upload(). En supposant que le fichier PDF, myfile.pdf, se trouve dans le même dossier que le script, voici comment procéder :
filename = "myfile.pdf"
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)Chaque fichier téléchargé de cette manière est associé à un identifiant unique, qui est nécessaire pour faire référence à ce fichier. Nous pouvons y accéder en utilisant l'attribut id du résultat, comme suit :
print(uploaded_pdf.id)Pour effectuer l'OCR sur ce fichier, nous devons fournir son URL. Nous pouvons l'obtenir à l'aide de la fonction client.files.get_signed_url() en fournissant l'ID du fichier :
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)Ensemble, nous pouvons mettre en œuvre une fonction qui télécharge un fichier à l'aide de l'API Mistral et récupère son URL :
def upload_pdf(filename):
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
return signed_url.urlVoici un exemple de demande d'OCR à partir d'un fichier local :
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": upload_pdf("myfile.pdf"),
},
include_image_base64=True,
)Pour utiliser un autre fichier, nous remplaçons myfile.pdf par le nom du fichier que nous voulons utiliser.
L'API OCR fonctionne également avec des images. Pour utiliser une image, nous utilisons le type image_url au lieu de document_url:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": <url of the image>,
},
)Dans l'exemple ci-dessus, nous devons remplacer par l'URL de l'image.
Pour utiliser une image locale, nous pouvons utiliser la fonction suivante pour la charger :
def load_image(image_path):
import base64
mime_type, _ = mimetypes.guess_type(image_path)
with open(image_path, "rb") as image_file:
image_data = image_file.read()
base64_encoded = base64.b64encode(image_data).decode('utf-8')
base64_url = f"data:{mime_type};base64,{base64_encoded}"
return base64_urlCette fonction utilise le paquetage base64, qui est un paquetage intégré, il n'est donc pas nécessaire de l'installer.
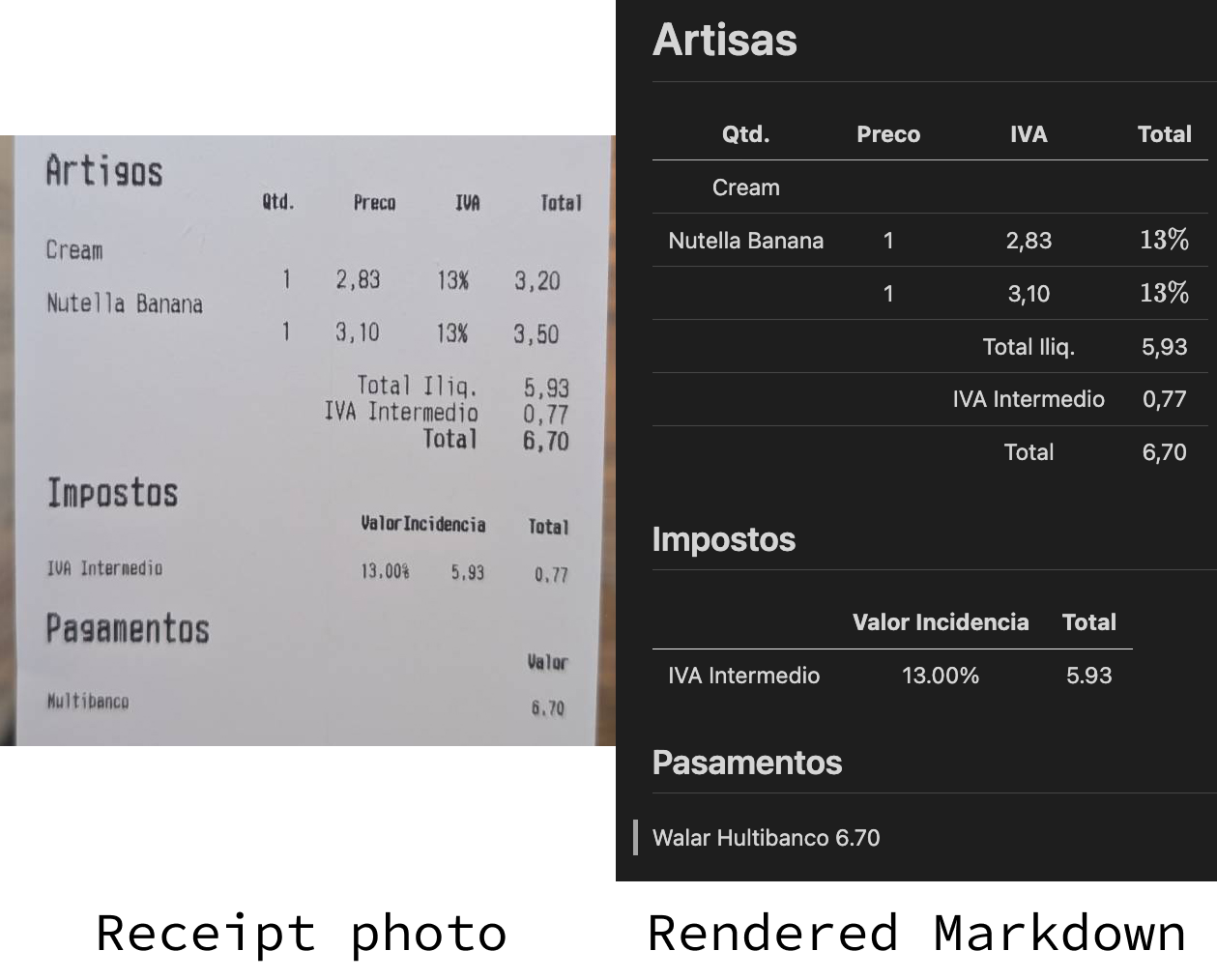
Essayons d'effectuer une OCR sur ce reçu que nous avons enregistré dans un fichier nommé receipt.jpeg:
Nous pouvons effectuer la demande d'OCR en utilisant la fonction load_image() pour charger l'image à partir de notre ordinateur :
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": load_image("receipt.jpeg"),
},
)Vous pouvez voir le résultat dans l'image ci-dessus. C'est loin d'être parfait, mais le résultat n'est pas si éloigné.
L'OCR constitue un moyen efficace de convertir les données en un format texte prêt à être utilisé par les LLM. L'API de Mistral permet aux utilisateurs de combiner des documents et des invites dans les demandes de LLM. En coulisses, l'API OCR est utilisée pour traiter les documents pour la consommation LLM.
Essayons de l'utiliser pour résumer l'article auquel nous nous sommes référés tout au long de ce tutoriel.
Si vous utilisez l'API de chat de Mistral pour la première fois, vous voudrez peut-être lire ce ce guide complet de Mistral car nous n'entrerons pas dans les détails de son fonctionnement.
Voici un exemple complet en Python de demande d'explication facile à comprendre de l'article :
from mistralai import Mistral
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Explain this article in detail to someone who doesn't have a technical background",
},
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
],
}
]
chat_response = client.chat.complete(
model="mistral-small-latest",
messages=messages,
)
print(chat_response.choices[0].message.content)Notez que le fichier est fourni en utilisant le même format que celui que nous avons appris plus haut :
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
}Maintenant que vous avez appris à mettre en œuvre l'OCR de Mistral dans vos projets Python, explorons quelques applications pratiques où vous pourriez mettre en œuvre ce que nous avons appris.
Vous pouvez extraire du texte, des équations, des tableaux et des figures à partir d'articles scientifiques pour construire un assistant de recherche personnalisé. Vous pourriez créer un système qui résume les principaux résultats, extrait les détails de la méthodologie ou crée une base de données consultable d'articles dans votre domaine.
Vous pouvez transformer des archives physiques ou des documents numérisés en collections numériques consultables. Ceci est particulièrement utile pour les documents historiques, les dossiers familiaux ou les archives d'organisations qui doivent être préservés et facilement accessibles.
Vous pouvez utiliser les capacités multilingues de Mistral OCR pour traiter des documents dans différentes langues. Cela peut être utile pour les entreprises internationales, les services de traduction ou les projets de recherche mondiaux qui doivent extraire des informations de documents rédigés dans différentes langues.
Vous pouvez convertir des manuels, des diapositives de cours et des notes manuscrites en format numérique. Créez un système qui extrait les concepts clés, les formules et les diagrammes pour créer des supports d'étude personnalisés ou des banques de questions.
Vous pouvez automatiser l'extraction de données à partir de factures, de reçus, d'états financiers ou de documents fiscaux. Cela peut permettre de rationaliser les processus comptables ou de faciliter la gestion des dépenses et l'analyse financière.
L'API OCR de Mistral fournit un outil puissant pour extraire et comprendre le texte à partir de documents et d'images. Dans ce tutoriel, nous avons exploré la manière de configurer et d'utiliser cette fonctionnalité pour diverses tâches de traitement de documents.
En suivant les étapes décrites dans ce tutoriel, vous pouvez intégrer l'OCR de Mistral dans vos applications, qu'il s'agisse de numériser des archives, d'automatiser la saisie de données ou de créer des systèmes intelligents de gestion de documents. Au fur et à mesure que la technologie évolue, nous pouvons nous attendre à des capacités de traitement des documents encore plus précises et contextuelles, qui combleront le fossé entre les documents physiques et les flux de travail numériques.
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach