Programa
Desenvolvimento de aplicativos de IA
21 h
Na semana passada, a Mistral lançou o Mistral OCR, uma API inovadora de reconhecimento óptico de caracteres (OCR). Sua API define um novo padrão para os recursos de IA para entender documentos e imagens. Ele é capaz de processar e analisar documentos com imagens, matemática, tabelas e muito mais com um alto grau de precisão.
Neste artigo, explicarei passo a passo como você pode usar o Mistral OCR usando Python. Mostrarei como você pode usá-lo com documentos, imagens e como combiná-lo com o bate-papo para combinar prompts com documentos.
O reconhecimento óptico de caracteres, ou OCR, é uma tecnologia que converte diferentes tipos de documentos - como documentos digitalizados em papel, arquivos PDF ou imagens capturadas por uma câmera digital - em dados editáveis e pesquisáveis.
O OCR funciona identificando caracteres de texto em imagens, analisando seus padrões e traduzindo esses elementos visuais em texto codificado por máquina. Essa tecnologia transformou a forma como interagimos com materiais impressos, permitindo tudo, desde a digitalização de arquivos históricos até a automação da entrada de dados em formulários comerciais.
A API de OCR da Mistral representa um avanço significativo nesse campo, oferecendo aos desenvolvedores uma ferramenta poderosa para extrair texto de imagens e documentos com precisão notável.

Fonte: Mistral
Ao contrário das soluções tradicionais de OCR que apenas identificam o texto, a API da Mistral usa modelos avançados de IA para entender o contexto e a estrutura dos documentos, mantendo a formatação enquanto extrai o conteúdo. Isso significa que ele pode reconhecer layouts complexos, diferenciar entre cabeçalhos e corpo de texto e interpretar corretamente tabelas e formatos com várias colunas.
O que torna a API de OCR da Mistral particularmente especial é sua integração com os recursos de compreensão de idiomas da Mistral. O sistema não apenas extrai o texto, mas também o compreende.
Isso permite fluxos de trabalho de processamento de documentos mais sofisticados, nos quais a API pode não apenas reconhecer o texto, mas também responder a perguntas sobre o conteúdo do documento, resumir informações ou extrair pontos de dados específicos.
Além disso, a API de OCR da Mistral foi projetada para funcionar em vários idiomas e conjuntos de caracteres, o que a torna versátil para aplicativos globais. Essa combinação de reconhecimento preciso de texto com compreensão profunda da linguagem posiciona a oferta da Mistral como uma solução de inteligência de documentos de última geração, em vez de uma simples ferramenta de OCR.
A API Mistral OCR não é gratuita, mas custa apenas US$ 1 por 1.000 páginas (ou US$ 0,001 por página). Na minha opinião, esse é um preço muito competitivo e acessível.
Os arquivos de documentos não devem exceder 50 MB e não devem ter mais de 1.000 páginas.
Mais informações podem ser encontradas na sua página de preços.
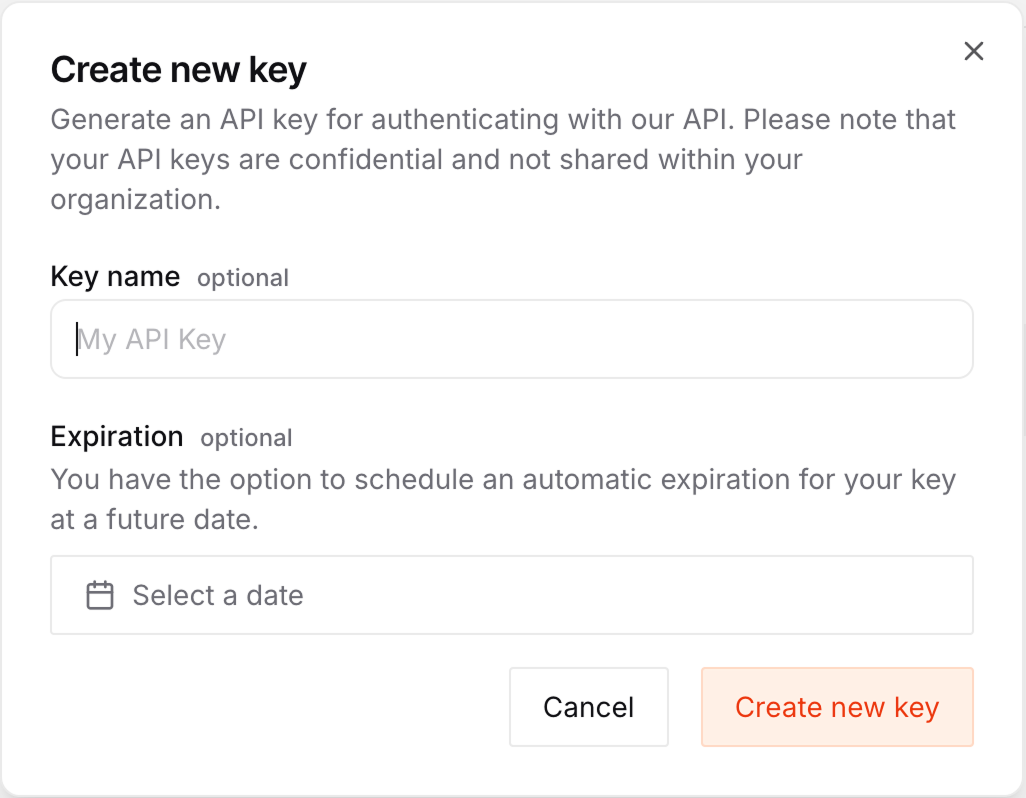
Navegue até a a página da chave da API da Mistral e clique no botão "Criar nova chave".
No formulário de criação de chave, podemos dar a ela um nome e uma data de validade.
Depois de criar a chave, copie-a e crie um arquivo chamado .env na mesma pasta em que escreveremos o script.
Cole a chave no arquivo usando o seguinte formato:
MISTRAL_API_KEY=<paste_api_key_here>Se você usa o GitHub, certifique-se de adicionar esse arquivo a .gitignore para evitar o upload da chave de API para o GitHub.
Para usar a API de OCR da Mistral com Python, instale os seguintes pacotes:
mistralai: Este é o pacote fornecido pela Mistral para que você interaja com sua API.python-dotenv: Um pacote para facilitar o carregamento da chave de API do arquivo .env.datauri: Esse pacote é usado para processar os dados da imagem e salvá-los em arquivos.Você pode instalá-los usando o comando:
pip install mistralai python-dotenv datauriRecomendo que você crie um ambiente para garantir que sua instalação não entre em conflito com a instalação padrão do Python. Uma maneira de fazer isso é usar o Anaconda:
conda create -n mistral -y python=3.9
conda activate mistral
pip install mistralai python-dotenv datauriO primeiro comando cria um ambiente chamado mistral que usa o Python 3.9. Em seguida, ativamos esse ambiente e instalamos os pacotes mencionados acima.
Vamos ver como podemos fazer nossa primeira solicitação à API de OCR da Mistral.
Na mesma pasta que o arquivo .env, crie um novo script Python chamado ocr.py e importe os pacotes necessários:
from mistralai import Mistral
from dotenv import load_dotenv
import datauri
import osObserve que também importamos os, que usamos para carregar a chave da API do ambiente em uma variável. Você não precisa instalá-lo porque ele é um pacote integrado.
Em seguida, adicionamos as seguintes linhas para carregar a chave da API e inicializar o cliente Mistral:
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
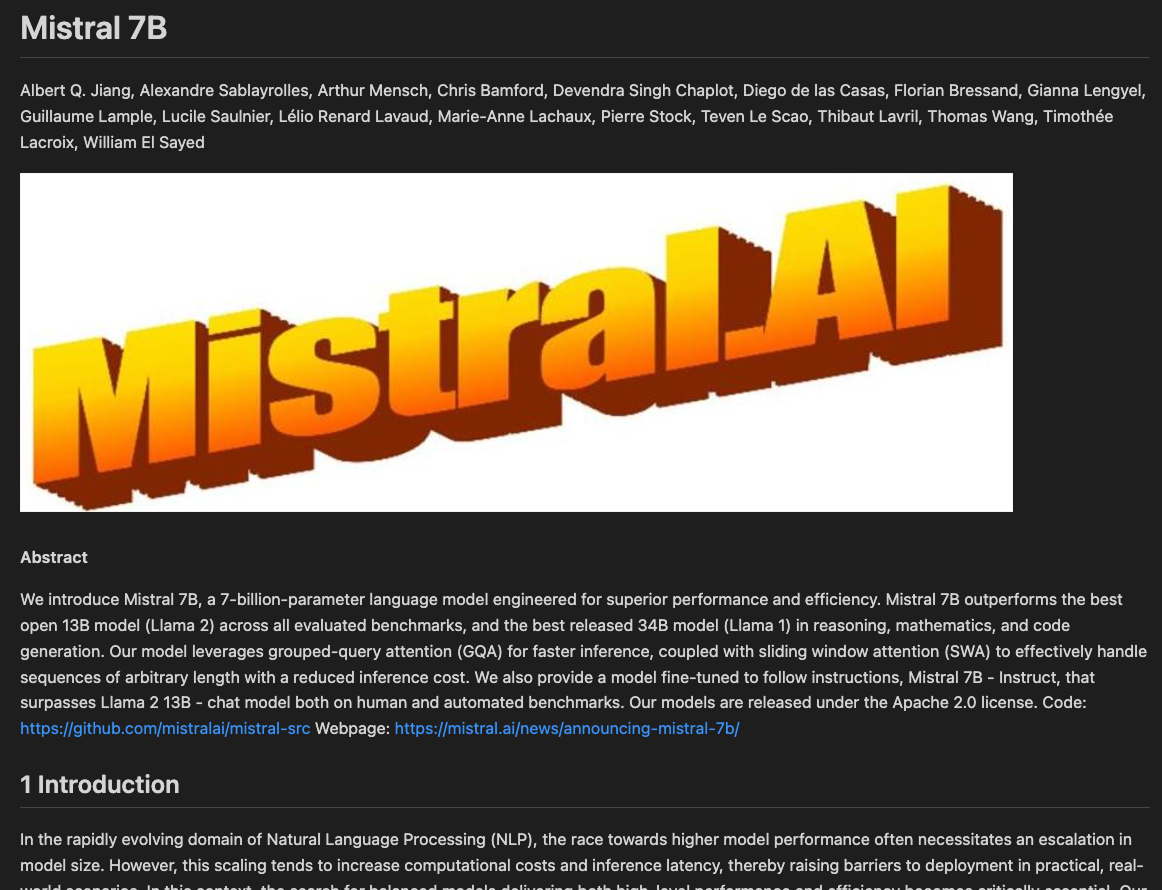
client = Mistral(api_key=api_key)A maneira mais simples de usar a API de OCR é com o URL de um PDF hospedado on-line. Para este exemplo, vamos usar este artigo do Mistral 7B hospedado no arXiv (uma plataforma que hospeda versões de pré-submissão de trabalhos de pesquisa):
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2501.00663",
},
)
print(ocr_response)Em seguida, podemos executar o script usando o comando python ocr.py. Isso gerará a seguinte resposta:
pages=[OCRPageObject(index=0, markdown='# Mistral 7B \n\nAlbert Q. Jiang,
...A resposta contém vários campos. Detalhes completos estão disponíveis na Documentação da API do Mistral. O campo pages, que contém, para cada página, o texto de remarcação da página, é especialmente importante para nós.
Podemos imprimir o número de páginas para ver se ele corresponde ao arquivo PDF:
print(len(ocr_response.pages))Resultado:
9Cada página tem vários campos. Os mais importantes são:
markdown: O conteúdo de markdown da página.images: As imagens na página.Por exemplo, podemos imprimir o conteúdo de remarcação para a primeira página usando:
print(ocr_response.pages[0].markdown)# Mistral 7B
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed

#### Abstract
We introduce Mistral 7B, a 7-billion-parameter language
...Para converter um PDF em Markdown, percorremos todas as páginas e gravamos o conteúdo Markdown de cada uma delas em um arquivo. Aqui está uma função para você fazer isso.
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)Aqui está uma comparação lado a lado entre o arquivo PDF original e o arquivo Markdown que geramos:

No exemplo anterior, vimos que o arquivo Markdown não continha as imagens do PDF. Isso ocorre porque não criamos os arquivos de imagem, apenas o texto Markdown.
Se você observar o resultado do markdown, verá que ele tem uma referência de imagem:
...

...No entanto, essa imagem não está sendo renderizada. As imagens em cada página são armazenadas no atributo images.
for page in ocr_response.pages:
print(page.images)Saída:
[OCRImageObject(id='img-0.jpeg', top_left_x=425, top_left_y=600, bottom_right_x=1283, bottom_right_y=893, image_base64=None)]
[OCRImageObject(id='img-1.jpeg', top_left_x=294, top_left_y=638, bottom_right_x=1405, bottom_right_y=1064, image_base64=None)]
[OCRImageObject(id='img-2.jpeg', top_left_x=294, top_left_y=191, bottom_right_x=1405, bottom_right_y=380, image_base64=None)]
[OCRImageObject(id='img-3.jpeg', top_left_x=292, top_left_y=204, bottom_right_x=1390, bottom_right_y=552, image_base64=None)]
[OCRImageObject(id='img-4.jpeg', top_left_x=464, top_left_y=202, bottom_right_x=1232, bottom_right_y=734, image_base64=None)]
[]
[OCRImageObject(id='img-5.jpeg', top_left_x=727, top_left_y=794, bottom_right_x=975, bottom_right_y=1047, image_base64=None)]
[]
[]No resultado acima, vemos que de fato temos uma referência a img-0.jpeg. No entanto, os dados não estão presentes: image_base64=None.
Para obter os dados da imagem, precisamos modificar a solicitação de OCR para incluir os dados da imagem, adicionando o parâmetro include_image_base64=True.
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
include_image_base64=True,
)Se imprimirmos as imagens novamente, veremos que os campos image_base_64 agora estão preenchidos. Como o nome do campo indica, os dados da imagem são armazenados na base 64. Não entraremos em detalhes sobre como funciona a representação de imagens base-64. Em vez disso, fornecemos uma função que usa o pacote datauri que instalamos anteriormente para gravar uma imagem em um arquivo:
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as file:
file.write(parsed.data)Agora, podemos atualizar a função create_markdown_file() para que você também grave todas as imagens em arquivos:
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)Se executarmos o código atualizado e renderizarmos novamente a visualização do Markdown, veremos as imagens.
No exemplo acima, usamos um arquivo que já estava hospedado. Para trabalhar com um arquivo PDF de nosso computador, a API do Mistral permite que você faça upload de um arquivo usando a função client.files.upload(). Supondo que o arquivo PDF, myfile.pdf, esteja na mesma pasta que o script, veja como você pode fazer isso:
filename = "myfile.pdf"
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)Cada arquivo carregado dessa forma tem um ID exclusivo associado a ele, que é necessário para fazer referência a esse arquivo. Podemos acessá-lo usando o atributo id do resultado, da seguinte forma:
print(uploaded_pdf.id)Para executar o OCR nesse arquivo, precisamos fornecer seu URL. Você pode obtê-lo usando a função client.files.get_signed_url(), fornecendo o ID do arquivo:
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)Juntando tudo isso, podemos implementar uma função que carrega um arquivo usando a API Mistral e recupera seu URL:
def upload_pdf(filename):
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
return signed_url.urlAqui está um exemplo de como fazer uma solicitação de OCR com um arquivo local:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": upload_pdf("myfile.pdf"),
},
include_image_base64=True,
)Para usar outro arquivo, substituímos myfile.pdf pelo nome do arquivo que queremos usar.
A API de OCR também funciona com entradas de imagem. Para usar uma imagem, usamos o tipo image_url em vez de document_url:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": <url of the image>,
},
)No exemplo acima, precisaríamos substituir pelo URL da imagem.
Para usar uma imagem local, podemos usar a seguinte função para carregá-la:
def load_image(image_path):
import base64
mime_type, _ = mimetypes.guess_type(image_path)
with open(image_path, "rb") as image_file:
image_data = image_file.read()
base64_encoded = base64.b64encode(image_data).decode('utf-8')
base64_url = f"data:{mime_type};base64,{base64_encoded}"
return base64_urlEssa função usa o pacote base64, que é um pacote interno, portanto, você não precisa instalá-lo.
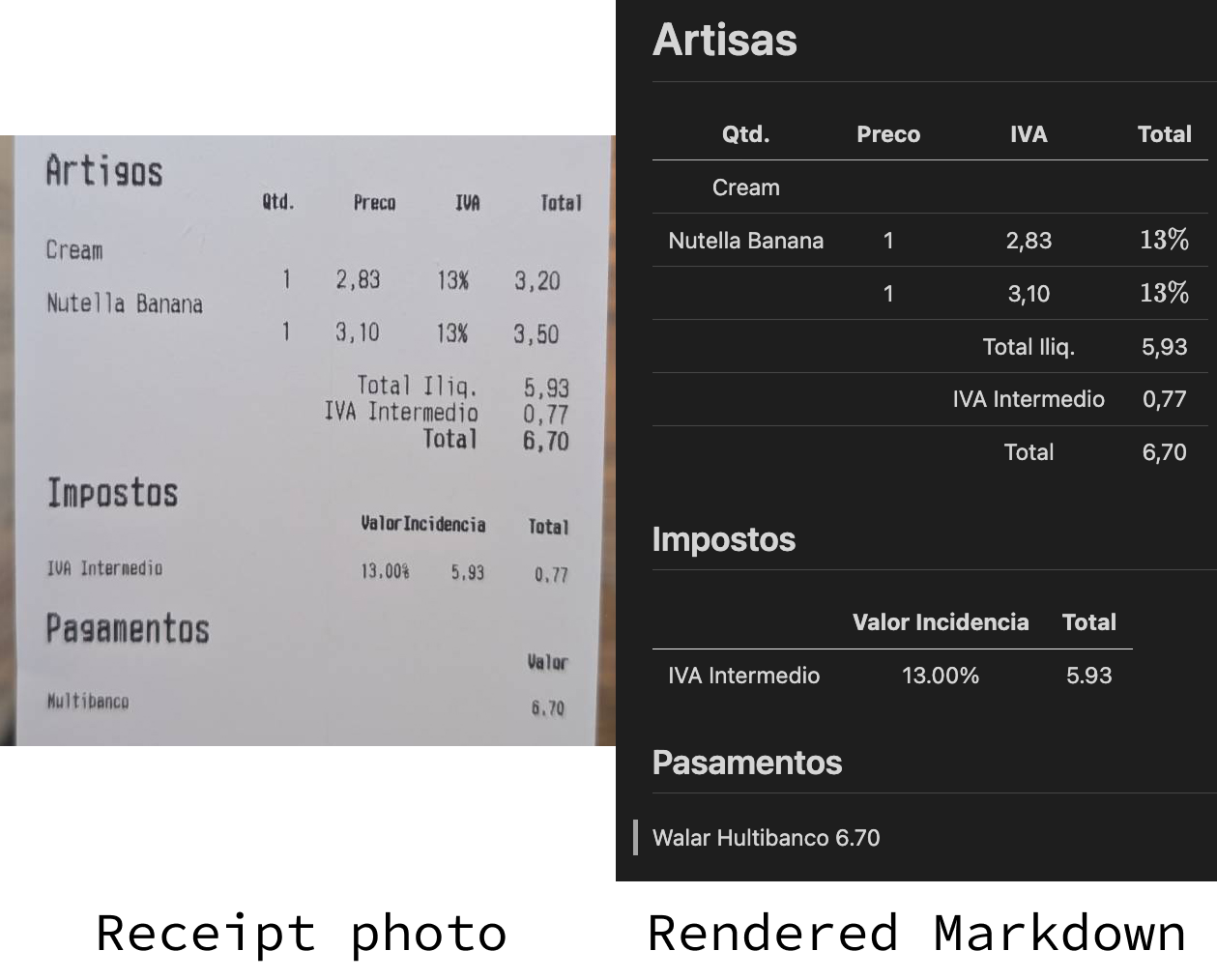
Vamos tentar executar o OCR nesse recibo que salvamos em um arquivo chamado receipt.jpeg:
Podemos fazer a solicitação de OCR usando a função load_image() para carregar a imagem do nosso computador:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": load_image("receipt.jpeg"),
},
)Você pode ver o resultado na imagem acima. Está longe de ser perfeito, mas o resultado não está tão longe assim.
O OCR oferece uma maneira eficiente de converter dados em um formato de texto pronto para ser usado pelos LLMs. A API do Mistral permite que os usuários combinem documentos e prompts nas solicitações do LLM. Nos bastidores, a API de OCR é usada para processar os documentos para consumo do LLM.
Vamos tentar usar isso para resumir o artigo ao qual fizemos referência ao longo deste tutorial.
Se for a primeira vez que você usa a API de bate-papo da Mistral, talvez queira ler este guia abrangente da Mistral pois não entraremos em detalhes sobre como ela funciona.
Aqui está um exemplo completo em Python em que você pede uma explicação fácil de entender sobre o artigo:
from mistralai import Mistral
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Explain this article in detail to someone who doesn't have a technical background",
},
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
],
}
]
chat_response = client.chat.complete(
model="mistral-small-latest",
messages=messages,
)
print(chat_response.choices[0].message.content)Observe que o arquivo é fornecido usando o mesmo formato que aprendemos acima:
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
}Agora que você aprendeu a implementar o Mistral OCR em seus projetos Python, vamos explorar algumas aplicações práticas em que você pode aplicar o que aprendemos.
Você pode extrair texto, equações, tabelas e figuras de artigos científicos para criar um assistente de pesquisa personalizado. Você pode criar um sistema que resuma as principais descobertas, extraia detalhes da metodologia ou crie um banco de dados pesquisável de artigos em sua área.
Você pode transformar arquivos físicos ou documentos digitalizados em coleções digitais pesquisáveis. Isso é particularmente valioso para documentos históricos, registros familiares ou arquivos organizacionais que precisam de preservação e fácil acesso.
Você pode usar os recursos multilíngues do Mistral OCR para processar documentos em vários idiomas. Isso pode ser útil para empresas internacionais, serviços de tradução ou projetos de pesquisa global que precisem extrair informações de documentos em diferentes scripts.
Você pode converter livros didáticos, slides de palestras e anotações escritas à mão em formatos digitais. Crie um sistema que extraia conceitos-chave, fórmulas e diagramas para criar materiais de estudo personalizados ou bancos de questões.
Você pode automatizar a extração de dados de faturas, recibos, demonstrações financeiras ou documentos fiscais. Isso pode simplificar os processos contábeis ou ajudar no gerenciamento de despesas e na análise financeira.
A API de OCR da Mistral fornece uma ferramenta poderosa para extrair e entender o texto de documentos e imagens. Neste tutorial, exploramos como configurar e usar esse recurso para várias tarefas de processamento de documentos.
Seguindo as etapas descritas neste tutorial, você pode incorporar o OCR da Mistral em seus aplicativos, seja digitalizando arquivos, automatizando a entrada de dados ou criando sistemas inteligentes de gerenciamento de documentos. À medida que a tecnologia continua a evoluir, podemos esperar recursos de processamento de documentos ainda mais precisos e sensíveis ao contexto, que preencham ainda mais a lacuna entre documentos físicos e fluxos de trabalho digitais.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Moez Ali
Tutorial
Tutorial
Natassha Selvaraj
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes


