

Track
Developing AI Applications
21 hr
Last week, Mistral released Mistral OCR, an innovative optical character recognition (OCR) API. Their API sets a new standard for AI capabilities to understand documents and images. It’s able to process and parse documents with images, math, tables, and more with a high degree of accuracy.
In this article, I’ll explain step-by-step how to use Mistral OCR using Python. I’ll show you how you can use it with documents, images, and how to combine it with chat to combine prompts with documents.
Optical character recognition, or OCR, is a technology that converts different types of documents—such as scanned paper documents, PDF files, or images captured by a digital camera—into editable and searchable data.
OCR works by identifying text characters in images, analyzing their patterns, and translating these visual elements into machine-encoded text. This technology has transformed how we interact with printed materials, enabling everything from digitizing historical archives to automating data entry from business forms.
Mistral's OCR API represents a significant advancement in this field, offering developers a powerful tool to extract text from images and documents with remarkable accuracy.

Source: Mistral
Unlike traditional OCR solutions that merely identify text, Mistral's API uses advanced AI models to understand the context and structure of documents, maintaining formatting while extracting content. This means it can recognize complex layouts, differentiate between headers and body text, and properly interpret tables and multi-column formats.
What makes Mistral's OCR API particularly special is its integration with Mistral's language understanding capabilities. The system doesn't just extract text—it comprehends it.
This allows for more sophisticated document processing workflows where the API can not only recognize text but also answer questions about document content, summarize information, or extract specific data points.
Additionally, Mistral's OCR API is designed to work across multiple languages and character sets, making it versatile for global applications. This combination of precise text recognition with deep language understanding positions Mistral's offering as a next-generation document intelligence solution rather than just a simple OCR tool.
The Mistral OCR API isn’t free, but it costs only $1 per 1,000 pages (or $0.001 per page). This is a very competitive and affordable pricing, in my opinion.
Documents files must not exceed 50 MB in size and should be no longer than 1,000 pages.
More information can be found on their pricing page.
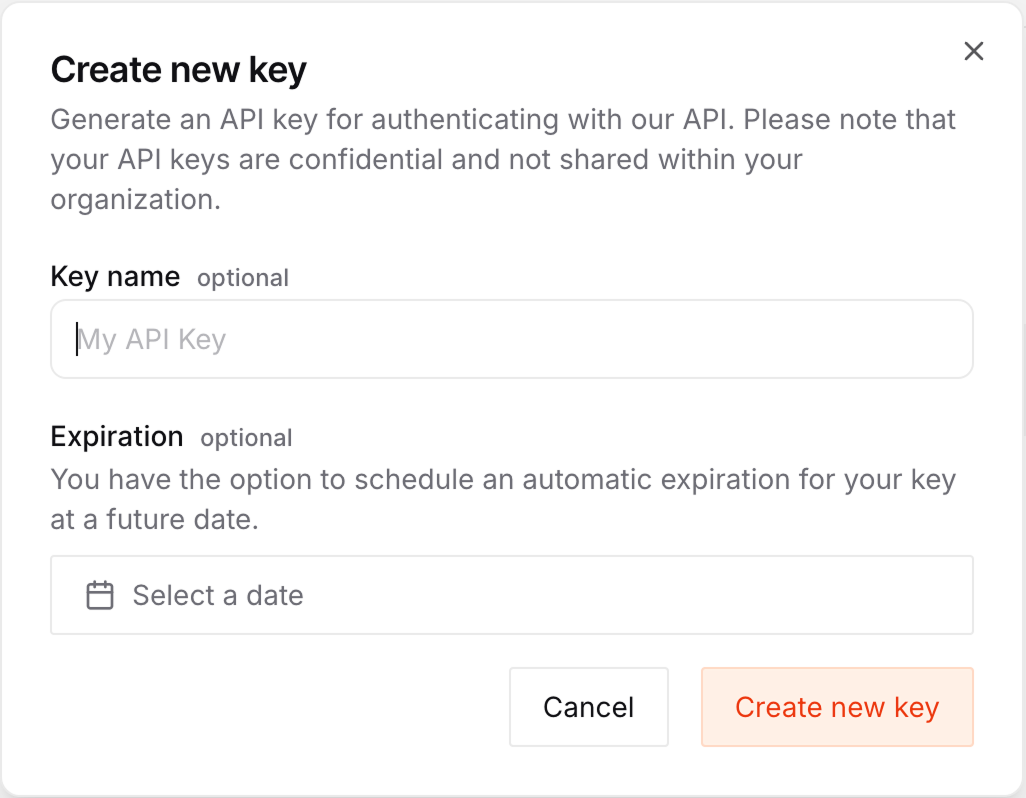
Navigate to the Mistral API key page and click the "Create new key" button.
On the key creation form, we can give it a name and an expiry date.
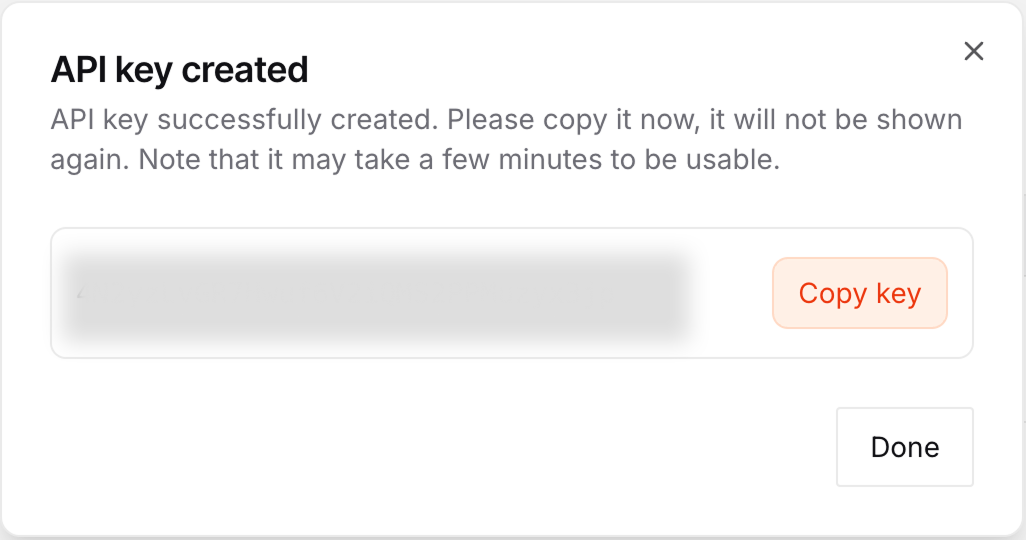
After creating the key, copy it and create a file named .env in the same folder where we'll write the script.
Paste the key into the file using the following format:
MISTRAL_API_KEY=<paste_api_key_here>If you use GitHub, make sure to add this file to the .gitignore to avoid uploading the API key to GitHub.
To use Mistral's OCR API with Python, install the following packages:
mistralai: This is the package provided by Mistral to interact with their API.python-dotenv: A package to make it easy to load the API key from the .env file.datauri: This package is used to process the image data and save them into files.We can install these using the command:
pip install mistralai python-dotenv datauriI recommend creating an environment to make sure that your installation doesn't conflict with your default Python installation. One way to do so is to use Anaconda:
conda create -n mistral -y python=3.9
conda activate mistral
pip install mistralai python-dotenv datauriThe first command creates an environment named mistral that uses Python 3.9. Then, we activate that environment and install the packages mentioned above.
Let's see how we can make our first request to Mistral's OCR API.
In the same folder as the .env file, create a new Python script named ocr.py and import the necessary packages:
from mistralai import Mistral
from dotenv import load_dotenv
import datauri
import osNote that we also import os, which we use to load the API key from the environment into a variable. We don't need to install it because it is a built-in package.
Next, we add the following lines to load the API key and initialize the Mistral client:
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)The simplest way to use the OCR API is with the URL of a PDF hosted online. For this example, let's use this Mistral 7B paper hosted on arXiv (a platform that hosts pre-submission versions of research papers):
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2501.00663",
},
)
print(ocr_response)We can then run the script using the command python ocr.py. This will generate the following response:
pages=[OCRPageObject(index=0, markdown='# Mistral 7B \n\nAlbert Q. Jiang,
...The response contains several fields. Full details are available in Mistral’s API documentation. We care in particular about the pages field, which contains, for each page, the markdown text of the page.
We can print the number of pages to see that it matches the PDF file:
print(len(ocr_response.pages))Result:
9Each page has several fields. The most important ones are:
markdown: The markdown content of the page.images: The images on the page.For example, we can print the markdown content for the first page using:
print(ocr_response.pages[0].markdown)# Mistral 7B
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed

#### Abstract
We introduce Mistral 7B, a 7-billion-parameter language
...To convert a PDF into Markdown, we loop over all pages and write the Markdown content of each of them into a file. Here's a function for doing that.
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)Here's a side-by-side comparison between the original PDF file and the Markdown file we generated:

In the previous example, we saw that the Markdown file didn't have the images from the PDF. That's because we didn't create the image files, only the Markdown text.
If we look at the markdown output, we see that it has an image reference:
...

...However, that image isn't being rendered. The images on each page are stored in the images attribute.
for page in ocr_response.pages:
print(page.images)Output:
[OCRImageObject(id='img-0.jpeg', top_left_x=425, top_left_y=600, bottom_right_x=1283, bottom_right_y=893, image_base64=None)]
[OCRImageObject(id='img-1.jpeg', top_left_x=294, top_left_y=638, bottom_right_x=1405, bottom_right_y=1064, image_base64=None)]
[OCRImageObject(id='img-2.jpeg', top_left_x=294, top_left_y=191, bottom_right_x=1405, bottom_right_y=380, image_base64=None)]
[OCRImageObject(id='img-3.jpeg', top_left_x=292, top_left_y=204, bottom_right_x=1390, bottom_right_y=552, image_base64=None)]
[OCRImageObject(id='img-4.jpeg', top_left_x=464, top_left_y=202, bottom_right_x=1232, bottom_right_y=734, image_base64=None)]
[]
[OCRImageObject(id='img-5.jpeg', top_left_x=727, top_left_y=794, bottom_right_x=975, bottom_right_y=1047, image_base64=None)]
[]
[]In the above output, we see that we indeed have a reference to img-0.jpeg. However, the data is not present: image_base64=None.
To obtain the image data, we need to modify the OCR request to include the image data by adding the include_image_base64=True parameter.
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
include_image_base64=True,
)If we print the images again, we'll see that the image_base_64 fields are now populated. As the name of the field indicates, the image data is stored in base 64. We won't go into the details of how base-64 image representation works. Instead, we provide a function that uses the datauri package we installed earlier to write an image into a file:
def save_image(image):
parsed = datauri.parse(image.image_base64)
with open(image.id, "wb") as file:
file.write(parsed.data)Now we can update the create_markdown_file() function to also write all images to files:
def create_markdown_file(ocr_response, output_filename = "output.md"):
with open(output_filename, "wt") as f:
for page in ocr_response.pages:
f.write(page.markdown)
for image in page.images:
save_image(image)If we run the updated code and re-render the Markdown preview, we see the images.
In the above example, we used a file that was already hosted. To work with a PDF file from our computer, the Mistral API allows us to upload a file using the client.files.upload() function. Assuming the PDF file, myfile.pdf is on the same folder as the script, here's how to do it:
filename = "myfile.pdf"
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)Each file uploaded this way has a unique ID associated with it, which is required to refer to that file. We can access it using the id attribute of the result, like so:
print(uploaded_pdf.id)To perform OCR on that file, we need to provide its URL. We can get it using the client.files.get_signed_url() function by providing the file ID:
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)Putting it together, we can implement a function that uploads a file using the Mistral API and retrieves its URL:
def upload_pdf(filename):
uploaded_pdf = client.files.upload(
file={
"file_name": filename,
"content": open(filename, "rb"),
},
purpose="ocr"
)
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
return signed_url.urlHere's an example of making an OCR request with a local file:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": upload_pdf("myfile.pdf"),
},
include_image_base64=True,
)To use another file, we replace myfile.pdf with the name of the file we want to use.
The OCR API also works with image inputs. To use an image, we use the image_url type instead of document_url:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": <url of the image>,
},
)In the above example, we would need to replace <url of the image> with the URL of the image.
To use a local image, we can use the following function to load it:
def load_image(image_path):
import base64
mime_type, _ = mimetypes.guess_type(image_path)
with open(image_path, "rb") as image_file:
image_data = image_file.read()
base64_encoded = base64.b64encode(image_data).decode('utf-8')
base64_url = f"data:{mime_type};base64,{base64_encoded}"
return base64_urlThis function uses the base64 package, which is a built-in package, so we don't need to install it.
Let's try to perform OCR on this receipt that we saved in a file named receipt.jpeg:
We can make the OCR request by using the load_image() function to load the image from our computer:
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": load_image("receipt.jpeg"),
},
)Here's the result:
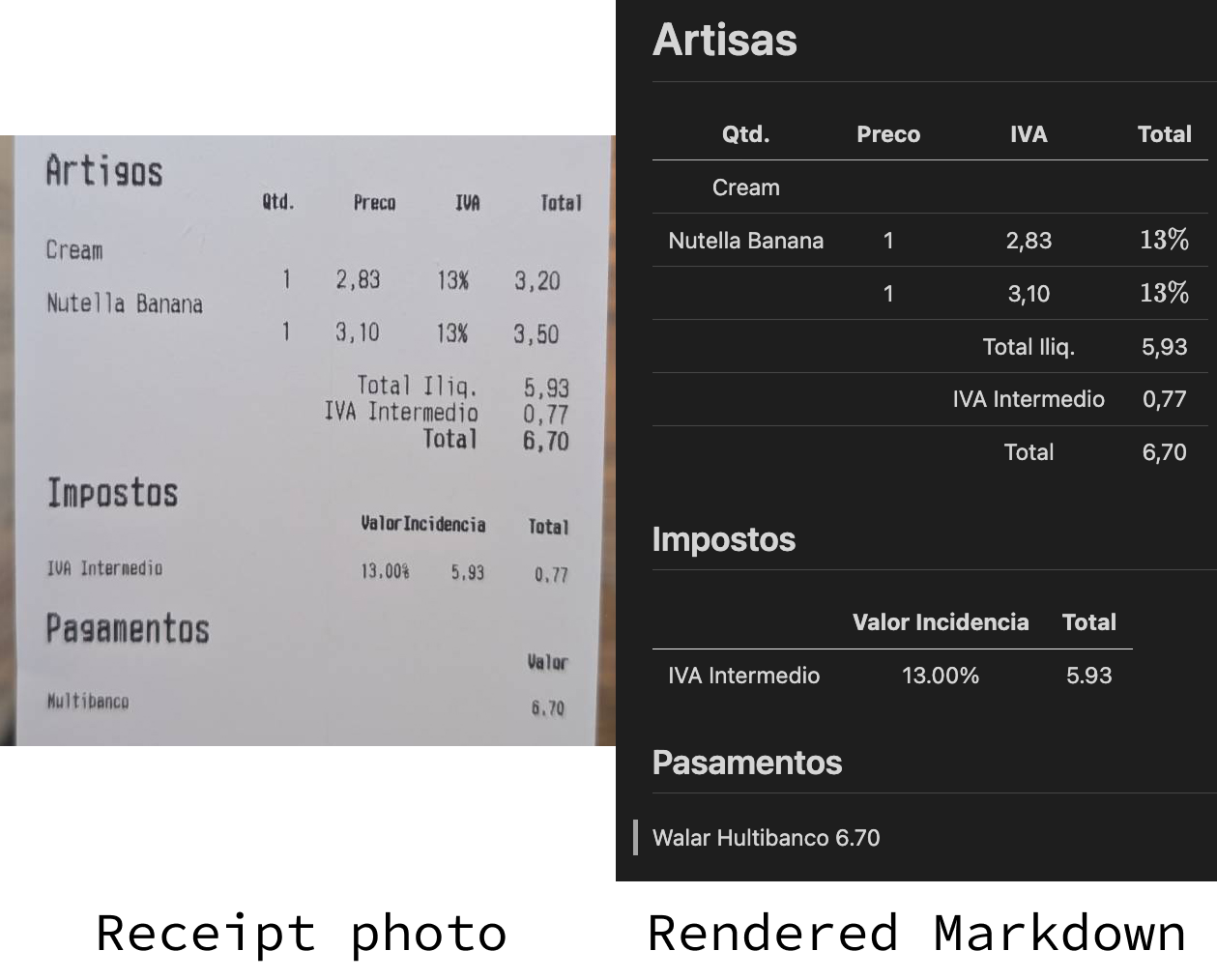
It's far from perfect, but the result is not that far off.
OCR provides an efficient way to convert data into a text format that is ready for LLMs to use. The Mistral API allows users to combine documents and prompts in the LLM requests. Behind the scenes, the OCR API is used to process the documents for LLM consumption.
Let's try using this to summarize the article we've been referencing throughout this tutorial.
If it's your first time using the Mistral chat API, you may want to read this comprehensive Mistral guide as we won't go into details of how it works.
Here's a full Python example of asking for an easy-to-understand explanation of the article:
from mistralai import Mistral
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Explain this article in detail to someone who doesn't have a technical background",
},
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
},
],
}
]
chat_response = client.chat.complete(
model="mistral-small-latest",
messages=messages,
)
print(chat_response.choices[0].message.content)Note that the file is provided using the same format we learned above:
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2310.06825",
}Now that you've learned how to implement Mistral OCR in your Python projects, let's explore some practical applications where you might apply what we’ve learned.
You can extract text, equations, tables, and figures from scientific papers to build a personalized research assistant. You could create a system that summarizes key findings, extracts methodology details, or builds a searchable database of papers in your field.
You can transform physical archives or scanned documents into searchable digital collections. This is particularly valuable for historical documents, family records, or organizational archives that need preservation and easy access.
You can use Mistral OCR's multilingual capabilities to process documents in various languages. This could be useful for international businesses, translation services, or global research projects needing to extract information from documents in different scripts.
You can convert textbooks, lecture slides, and handwritten notes into digital formats. Create a system that extracts key concepts, formulas, and diagrams to build personalized study materials or question banks.
You can automate the extraction of data from invoices, receipts, financial statements, or tax documents. This could streamline accounting processes or help with expense management and financial analysis.
Mistral's OCR API provides a powerful tool for extracting and understanding text from documents and images. In this tutorial, we've explored how to set up and use this capability for various document-processing tasks.
By following the steps outlined in this tutorial, you can incorporate Mistral's OCR into your applications, whether you're digitizing archives, automating data entry, or building intelligent document management systems. As the technology continues to evolve, we can expect even more accurate and context-aware document processing capabilities that further bridge the gap between physical documents and digital workflows.
Learn AI with these courses!
Track
Course
Course
Tutorial
François Aubry
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev
Tutorial
Ryan Ong
Tutorial
Hesam Sheikh Hassani
Tutorial
Josep Ferrer