
Kurs
Einführung in MongoDB mit Python
3 Std.
24K
MongoDB ist eine beliebte NoSQL-Datenbank, die auf Flexibilität und Leistung ausgelegt ist. Im Gegensatz zu traditionellen relationalen Datenbanken, die strukturierte Tabellen und SQL verwenden, speichert MongoDB Daten in flexiblen, JSON-ähnlichen Dokumenten. Das macht sie ideal für Entwickler, die mit dynamischen oder halbstrukturierten Daten arbeiten.
Eine der wichtigsten Operationen, die du in MongoDB durchführen wirst, ist die Abfrage von Daten, und die am häufigsten verwendete Methode dafür ist find(). Ganz gleich, ob du gerade erst anfängst oder deine Abfragekenntnisse verbessern willst: Um deine MongoDB-Daten effektiv zu navigieren und zu bearbeiten, musst du verstehen, wie find() funktioniert.
Stell dir vor, du durchsuchst eine Filmdatenbank. Du willst alle Science-Fiction-Filme finden, die nach dem Jahr 2000 erschienen sind, oder alle Kommentare von Nutzern in einem bestimmten Zeitraum auflisten. Das ist der Punkt, an dem find() glänzt.
In diesem Artikel erfährst du, wie du mit der Methode find() Dokumente aus einer Sammlung abrufen, Filter anwenden, Felder projizieren, Ergebnisse sortieren und die Leistung optimieren kannst - und das alles bei der Arbeit mit dem Datensatz sample_mflix.
Eine praktische Einführung in die Verwendung von MongoDB in Data Science Workflows findest du im Kurs Einführung in MongoDB in Python.
Die Methode find() ist die wichtigste Methode von MongoDB, um Dokumente aus einer Sammlung abzurufen. Sie gibt einen Cursor zu den Dokumenten zurück, die mit der angegebenen Abfrage übereinstimmen. Du kannst dann über diesen Cursor iterieren oder ihn in ein Array umwandeln, je nachdem, was deine Anwendung braucht.
Hier ist die vollständige Syntax:
db.collection.find(<query>, <projection>, <options>)query (optional): Ein Dokument, das die Kriterien für die Auswahl von Dokumenten festlegt. Wenn du diesen Parameter weglässt oder ein leeres Dokument übergibst ({}), gibt find() alle Dokumente in der Sammlung zurück.projection (optional): Ein Dokument, das angibt, welche Felder zurückgegeben werden sollen. Du kannst Felder einschließen (1) oder ausschließen (0). Standardmäßig gibt MongoDB alle Felder zurück, einschließlich _id.options (optional): Ein zusätzliches Dokument, um das Abfrageverhalten zu konfigurieren. Du kannst Dinge wie Sortierreihenfolge, Paginierungsgrenzen, Timeouts und Index-Hinweise einstellen.Um die Konzepte so klar und anwendbar wie möglich zu machen, verwenden wir den MongoDB Atlas-Beispieldatensatz, genauer gesagtdie Datenbank sample_mflix. Dieser Datensatz enthält Sammlungen wie Filme, Kommentare, Benutzer und Theater, auf die wir im Laufe des Artikels Bezug nehmen werden, um jedes Beispiel zu veranschaulichen.
db.books.find(
{ year: { $gte: 2000 } }, // query: books published in or after 2000
{ title: 1, author: 1, _id: 0 }, // projection: include only title and author
{ sort: { title: 1 }, limit: 5 } // options: sort by title, return only 5 books
)Diese Anfrage:
_id aus).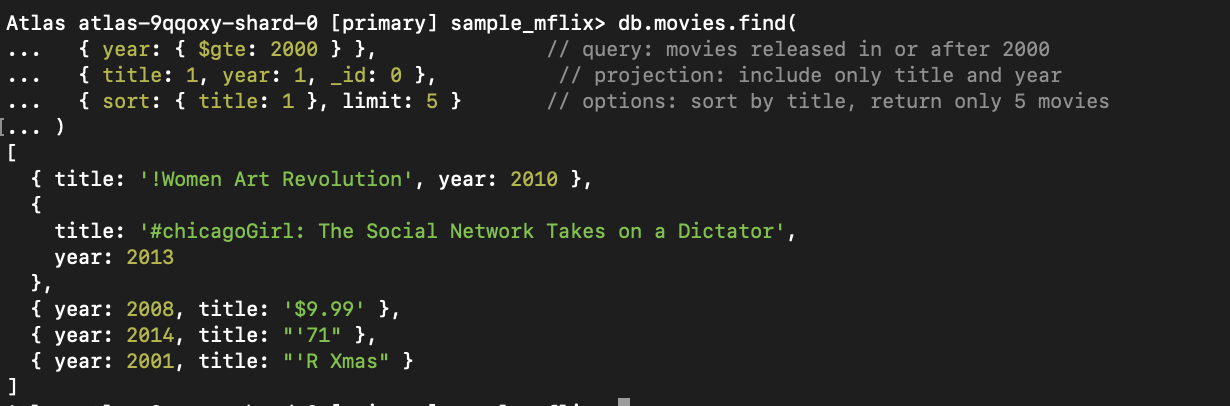
Abbildung 1. Diese Abfrage findet Filme, die nach 2000 veröffentlicht wurden, sortiert nach Titel und begrenzt auf fünf Ergebnisse.
Das Ergebnis ist ein Cursor, der übereinstimmende Dokumente nach und nach lädt, während du sie durchgehst. Du kannst .toArray() oder .forEach() verwenden, um die Ergebnisse zu verarbeiten.
Wenn du über die MongoDB-Shell (mongosh) verbunden bist und das Ergebnis nicht einer Variablen zuweist, werden standardmäßig nur die ersten 20 Dokumente angezeigt. Um weitere Dokumente anzuzeigen, gib sie ein und drücke die Eingabetaste. Dieser Vorgang wird fortgesetzt, um die nächste Charge vom Cursor zu holen.
> Hinweis: Dies ist ein Shell-spezifisches Verhalten und keine Einschränkung von MongoDB. In den meisten MongoDB-Treibern (z. B. Node.js, Python, Java) werden durch den Aufruf von .toArray() oder die Iteration über den Cursor automatisch alle passenden Ergebnisse geholt. Das Verhalten des Cursors kann je nach Umgebung und Sprache, die du verwendest, variieren.
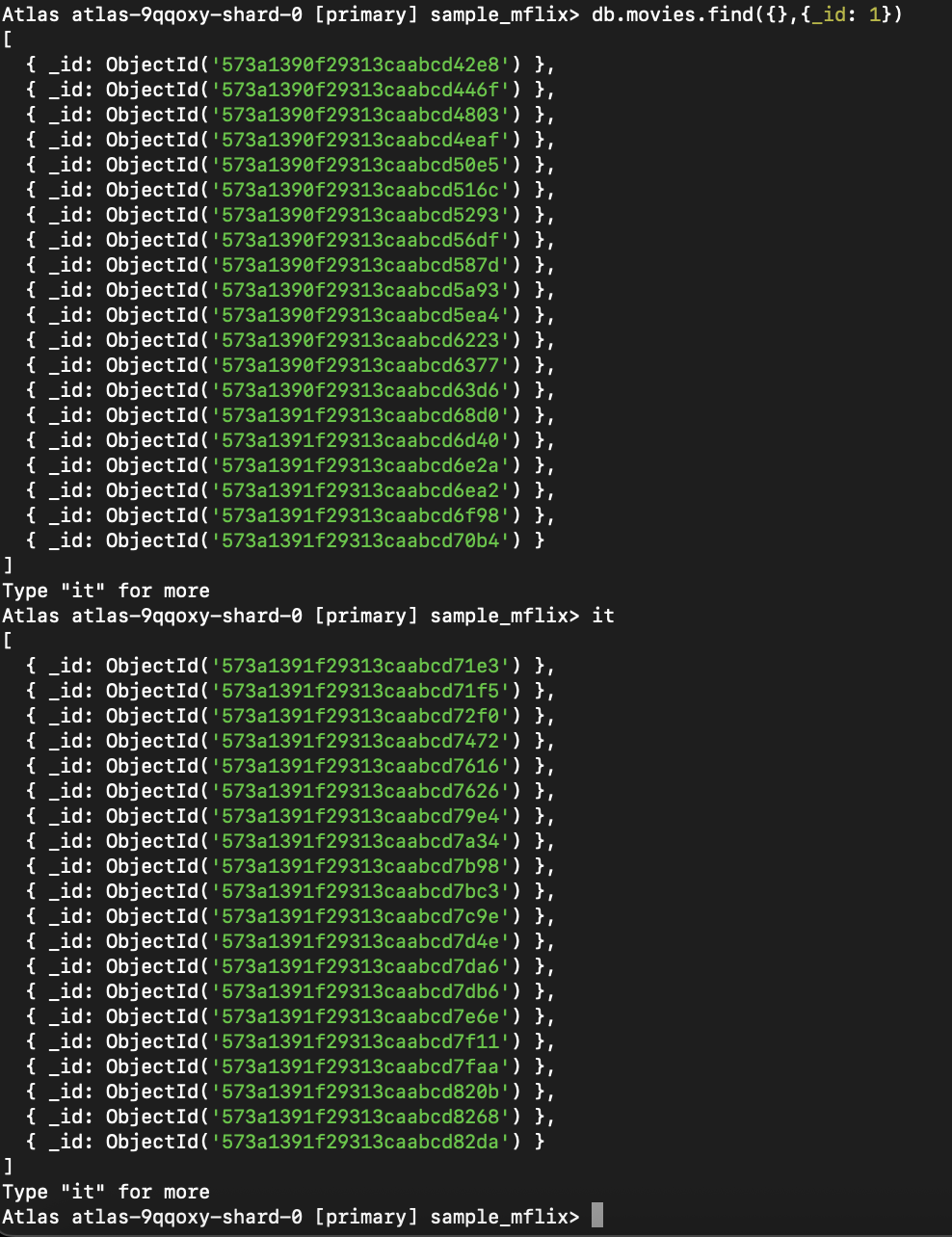
Abbildung 2. Diese Abfrage ruft alle Filme ab, wobei nur das Feld _id zurückgegeben wird und der Cursor verwendet wird, um weitere Ergebnisse abzurufen.
Wenn du dich noch nicht mit NoSQL-Datenbanken auskennst, bietet der Kurs Einführung in NoSQL grundlegende Konzepte, die dieses Tutorial ergänzen.
Bleiben wir bei dem Beispiel mit den Filmen. Nehmen wir an, du möchtest alle Filme aus dem Sci-Fi-Genre finden. So würdest du das machen:
db.movies.find({ genres: "Sci-Fi" })Du willst also nur Filme, die im Jahr 2000 oder später veröffentlicht wurden:
db.movies.find({ year: { $gte: 2000 } })Und wenn du beides willst? Kombiniere die Bedingungen:
db.movies.find({ genres: "Sci-Fi", year: { $gte: 2000 } })Alternativ kannst du es auch explizit mit $and schreiben:
db.movies.find({ $and: [ { genres: "Sci-Fi" }, { year: { $gte: 2000 } } ] })Beide Abfragen liefern die gleichen Ergebnisse - Dokumente mit dem Genre Sci-Fi und dem Erscheinungsjahr 2000 oder später. Die erste Form ist prägnanter und wird bevorzugt, wenn die Felder unterschiedlich sind.

Abbildung 3. Das sind verschiedene Arten, die Abfrage zu schreiben, die das gleiche Ergebnis liefern.
Verwende find() wie einen Filtertrichter - jede Bedingung schränkt deine Ergebnisse ein.
Jetzt wollen wir uns ansehen, wie du Vergleichs- und logische Operatoren verwenden kannst, um deine Abfragen auf die nächste Stufe zu heben.
$eq$ne: gleich, nicht gleich$gt, $gte, $lt, $lte: größer/kleiner als (oder gleich)$in$nin: in oder nicht in ArrayStell dir vor, du verfolgst die Kundenbestellungen und willst Bestellungen zwischen 100 und 500 US-Dollar:
db.orders.find({ total: { $gte: 100, $lte: 500 } })$and, $or, $nor, $notStell dir vor, du möchtest Produkte aus der Kategorie "Bücher" oder Produkte unter 20 $ anzeigen. Hier ist eine Beispielabfrage:
db.products.find({ $or: [ { category: "Books" }, { price: { $lt: 20 } } ] })Du kannst mit der Punktnotation auf verschachtelte Felder zugreifen:
db.customers.find({ "address.city": "Chicago" })Durch die Projektion kannst du nur das zurückgeben, was du brauchst, was die Leistung und Klarheit deutlich verbessern kann.
db.movies.find({}, { directors: 1, languages: 1, _id: 0 })Wichtig! Wenn du eine Projektion angibst, musst du in MongoDB zwischen zwei Modi wählen: Entweder bestimmte Felder einschließen (1) oder bestimmte Felder ausschließen (0). Du kannst nicht beide Stile in derselben Projektion mischen, mit Ausnahme des Feldes _id, das ausgeschlossen werden kann, auch wenn andere Felder enthalten sind.
✅ Gültig (nur Aufnahme):
db.movies.find({}, { directors: 1, languages: 1 })✅ Gültig (nur Ausschluss):
db.movies.find({}, { directors: 0, _id: 0 })❌ Ungültig (Mischung aus Einschluss und Ausschluss):
db.movies.find({}, { directors: 1, languages: 0 }) // Not allowedDie einzige Ausnahme ist das Feld _id, das du ausschließen kannst, auch wenn du andere Felder einschließt:
db.movies.find({}, { directors: 1, _id: 0 }) // Allowed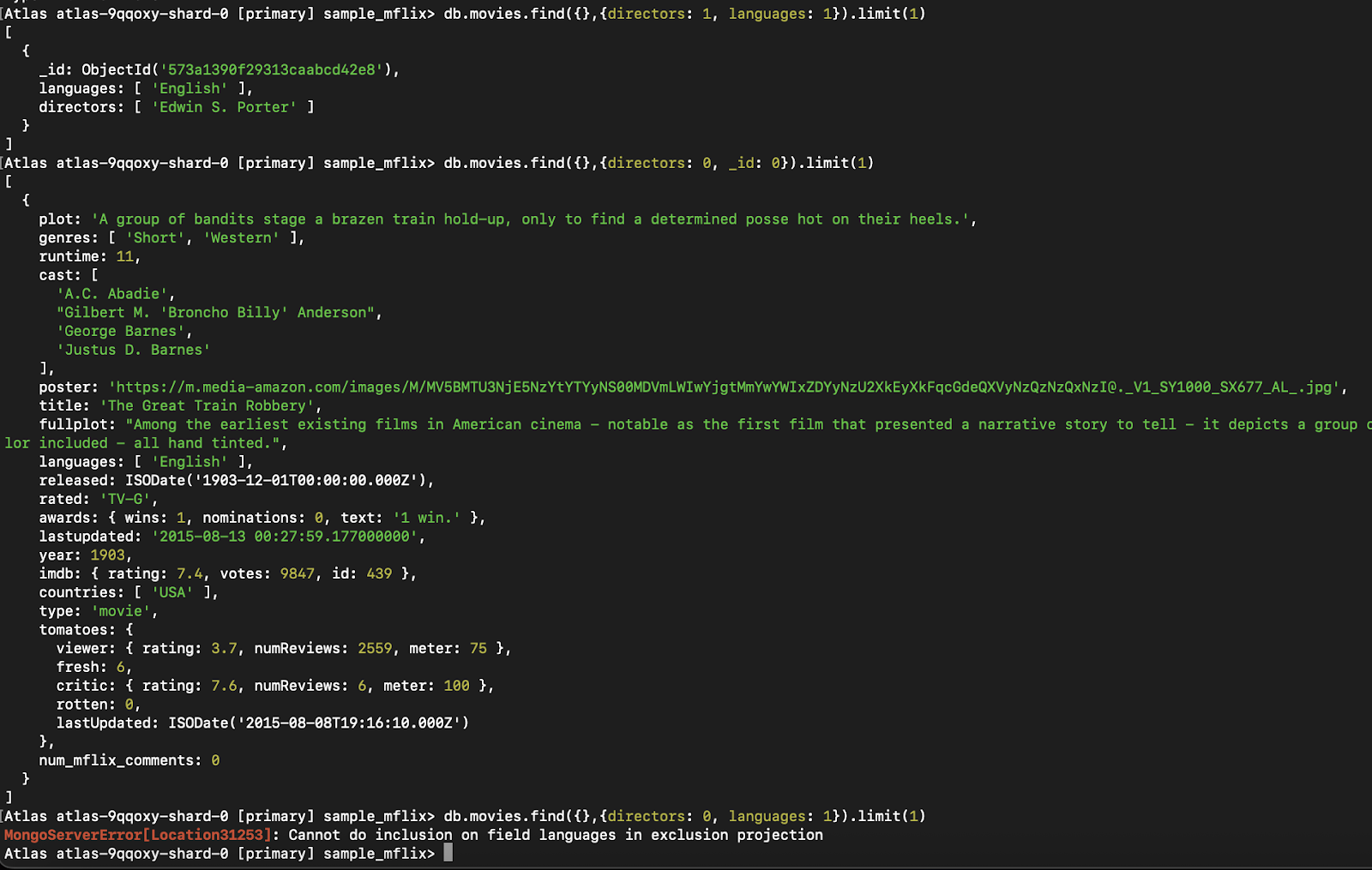
Abbildung 4. Dieses Beispiel zeigt den Fehler, der durch die Vermischung von Feldein- und -ausschlüssen in einer einzigen Projektion ausgelöst wird, was MongoDB nicht zulässt, außer für `_id`.
Bei der Arbeit mit großen Datensätzen ist es üblich, den Nutzern immer nur einen Teil der Daten zu zeigen - eine Technik, die als Paginierung bekannt ist. Eine Streaming-App könnte zum Beispiel 10 Filme pro Seite zeigen, anstatt Tausende auf einmal zu laden. Das verbessert nicht nur die Leistung, sondern auch das Nutzererlebnis.
In MongoDB wird die Paginierung durch eine Kombination aus sort(), limit() und skip() erreicht.
Wenn du von einem SQL-Hintergrund kommst, findest du hier einen Überblick über die gängigen Paginierungskonzepte:
Grundlegende Abfrage in SQL:
SELECT * FROM movies WHERE year >= 2000Das Gleiche kann in MongoDB wie folgt ausgedrückt werden:
db.movies.find({ year: { $gte: 2000 } })Feldauswahl in SQL:
SELECT title, year FROM moviesFeldauswahl in MongoDB:
db.movies.find({}, { title: 1, year: 1, _id: 0 })Schauen wir uns nun ein paar weitere Beispiele für gängige Abfrageoperationen an:
Sortieren:
ORDER BY title ASC.sort({ title: 1 })Begrenzung:
LIMIT 10.limit(10)Überspringen:
OFFSET 10.skip(10)Wenn du diese Parallelen verstehst, kannst du SQL-Nutzern den Umstieg auf das dokumentenbasierte Abfragesystem von MongoDB erleichtern.
Die Sortierung hilft dir, deine Ergebnisse nach einem bestimmten Feld zu ordnen, z. B. um Filme nach Titel in alphabetischer Reihenfolge zu sortieren:
db.movies.find().sort({ title: 1 }) // ascending (A–Z)1 bedeutet aufsteigende Reihenfolge (A-Z, 0-9)-1 bedeutet absteigende Reihenfolge (Z-A, 9-0)Gib nur eine bestimmte Anzahl von Ergebnissen zurück - zum Beispiel die ersten 10:
db.movies.find().limit(10)Dies ist nützlich, wenn du "Top 10"-Listen oder erste Ansichten implementierst.
Verwende dies, um Dokumente zu überspringen. Sie wird oft zusammen mit limit() für die Paginierung verwendet:
db.movies.find().skip(10).limit(10)Damit werden die ersten 10 Dokumente übersprungen und die nächsten 10 zurückgegeben, so dass effektiv Seite 2 angezeigt wird, wenn pageSize = 10.
Paginierungsformel:
skip = (pageNumber - 1) * pageSize> Hinweis: Die Verwendung von skip() für eine tiefe Paginierung (z. B. skip(10000)) kann ineffizient sein, da MongoDB die übersprungenen Dokumente immer noch scannt und verwirft. Um die Leistung bei großen Datensätzen zu verbessern, solltest du eine bereichsbasierte Paginierung mit indizierten Feldern wie _id in Betracht ziehen.
db.movies.find()
.sort({ title: 1 })
.skip(20)
.limit(10)Dieses Muster ist auch für Funktionen wie "mehr laden" oder unendliches Scrollen hilfreich.
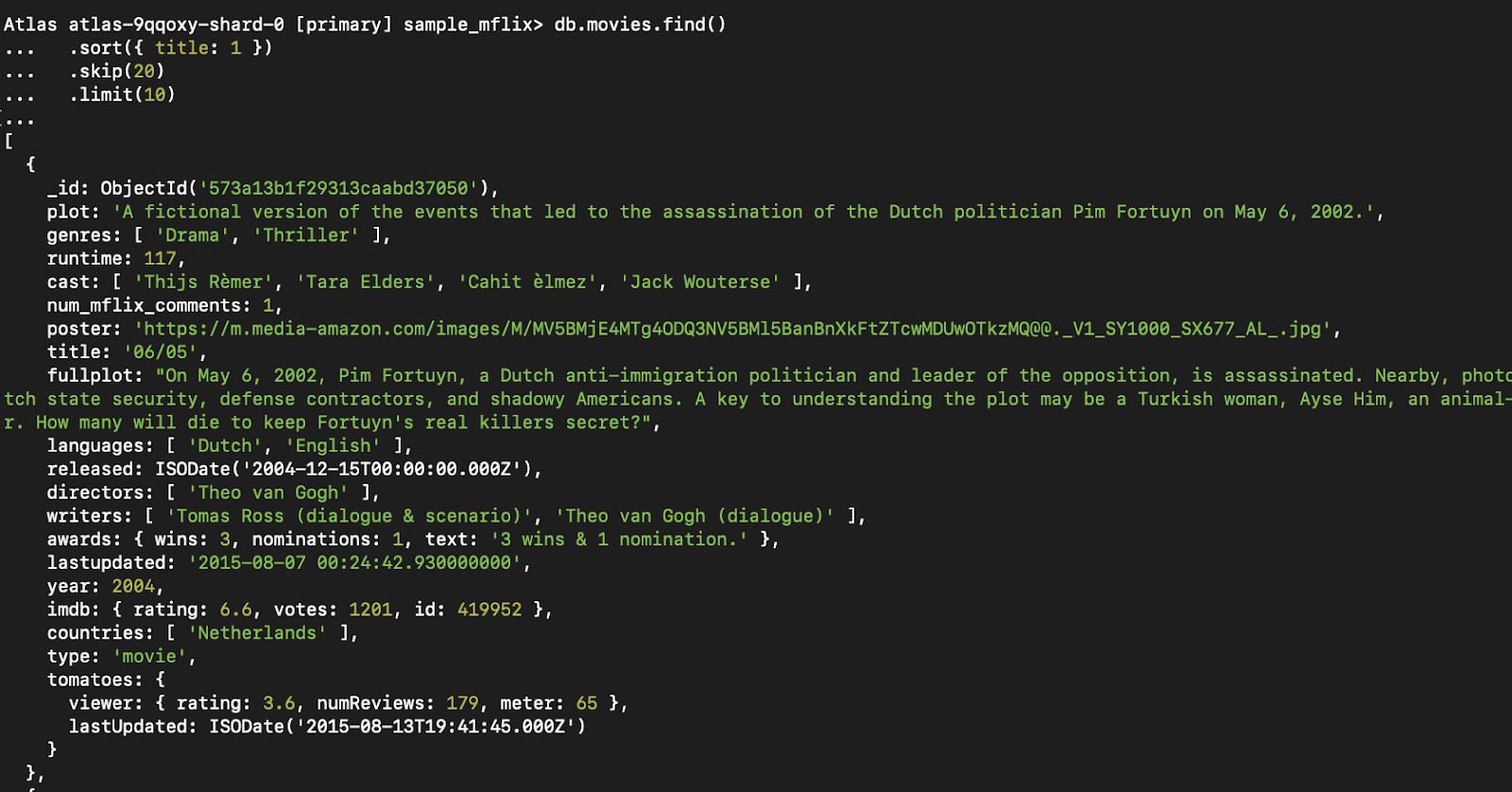
Abbildung 5. Diese Abfrage ruft die dritte Ergebnisseite (10 Filme pro Seite), geordnet nach Titel, ab.
Die Methode find() gibt einen Cursor zurück - einen Zeiger auf die Ergebnismenge. Du kannst darüber iterieren:
const cursor = db.movies.find({ type: "movie" });
cursor.forEach(doc => print(doc.name));Oder wandle sie in ein Array um:
const results = db.collection.find().toArray();
Abbildung 6. Nach dem Aufruf von `find()` erhältst du einen Cursor. Du kannst damit über Dokumente iterieren oder die gesamte Ergebnismenge in ein Array umwandeln.
> Hinweis: Das Cursor-Objekt ist in mongosh oder im Code über Treiber (z. B. Node.js, Python) verfügbar. GUI-Tools wie MongoDB Compass behandeln Cursors intern. Du wirst nicht direkt auf sie zugreifen oder über sie iterieren.
Zur Feinabstimmung deiner Abfragen kannst du zusätzliche Cursor-Methoden verwenden:
db.users.find({ age: { $gte: 30 } })
.sort({ name: 1 })
.limit(10)
.skip(5)
.maxTimeMS(200)
.hint({ age: 1 })maxTimeMS(ms): bricht die Abfrage ab, wenn sie zu lange dauerthint()Zwingt MongoDB, einen bestimmten Index zu verwenden.batchSize(n): steuert die Anzahl der Belege pro StapelDu bereitest dich auf Vorstellungsgespräche vor? Unter findest dudie 25 besten MongoDB-Interviewfragen und -Antworten, mit denen dudein Wissen über Kernkonzepte wie find()testen kannst.
Indizes sind wie Spickzettel - sie helfen MongoDB, Dokumente schneller zu finden.
db.movies.createIndex({ type: 1 })db.users.find({ type: "movie" }).explain()Dies zeigt, ob Indizes verwendet werden und wie effizient deine Abfrage ist.
Ohne einen Index: 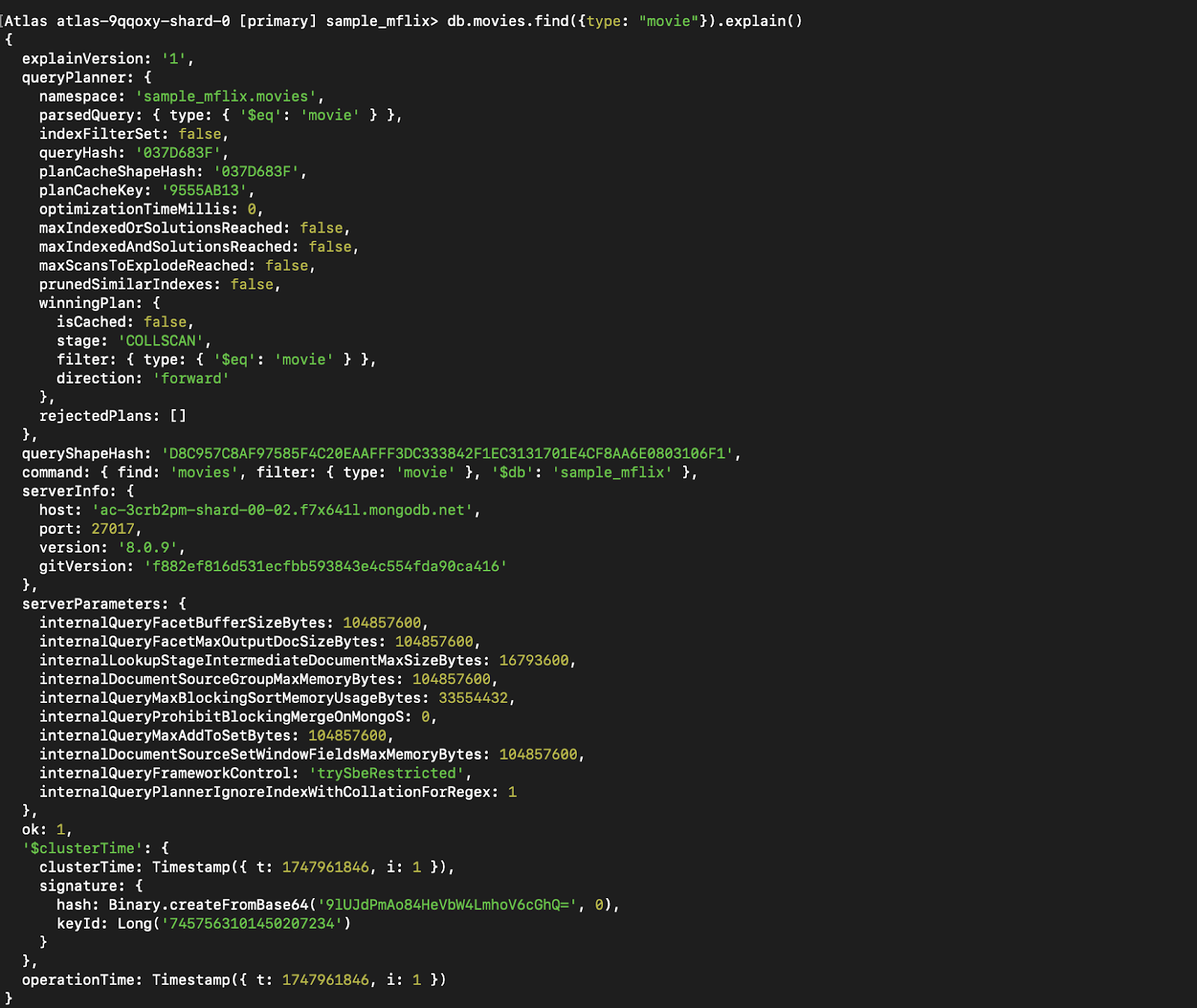
Abbildung 7. Führe `explain()` für die Abfrage aus, bevor du sie indizierst.
Einen Index erstellen:
![]()
Abbildung 8. Erstelle einen einfachen Index für das Feld "Typ".
Mit einem Index:
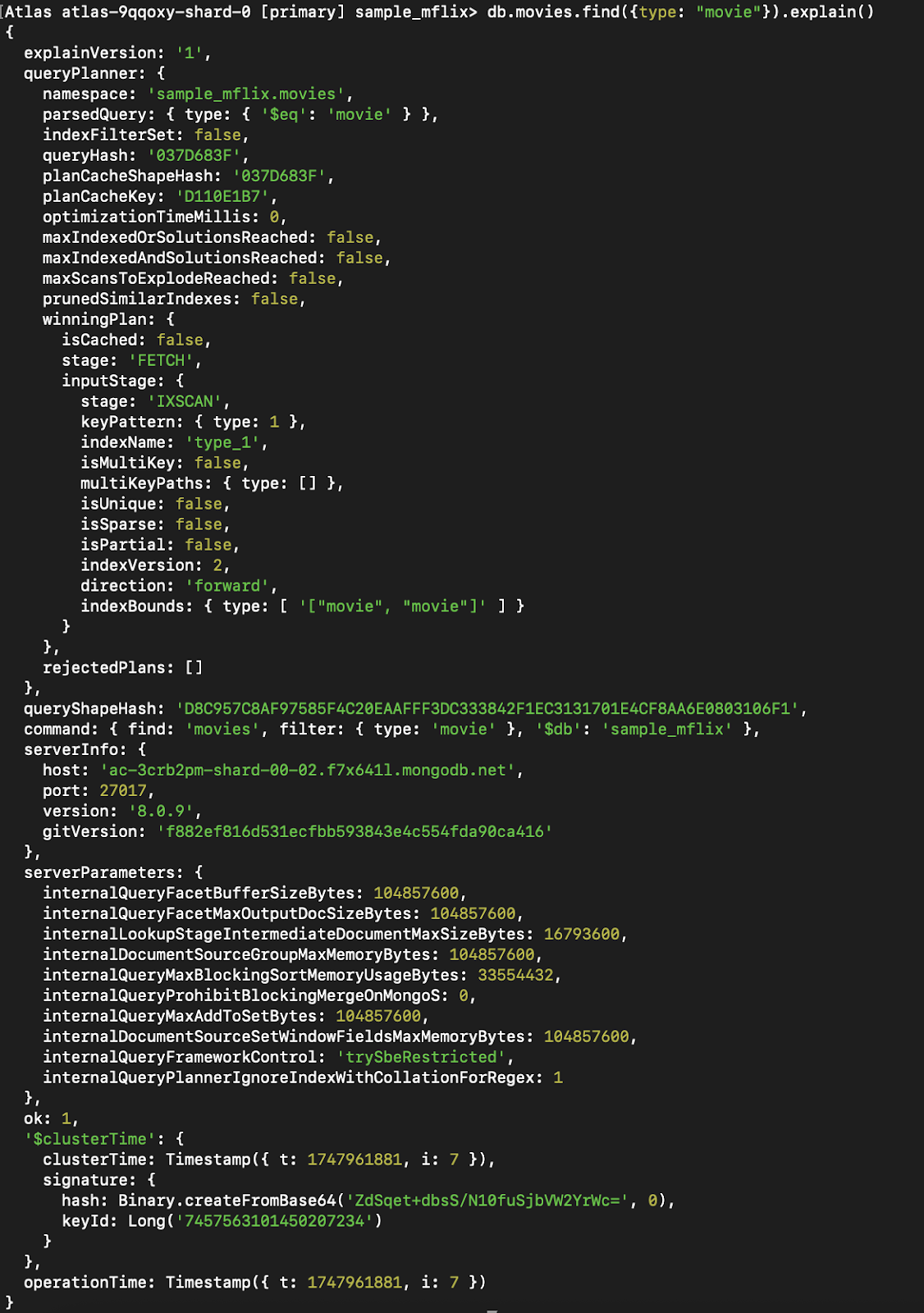
Abbildung 9. Führe die gleiche Abfrage mit `explain()` aus, jetzt mit einem Index.
Du kannst sehen, dass die Phase, die vorher CollScan (Scannen der Sammlung) war, zu Fetch + IXSCAN geworden ist, die im Grunde den Index verwendet und nach anderen Daten sucht, die nicht Teil des Index sind (da wir alles zurückgeben).
Wenn du visuelle Tools bevorzugst, ist MongoDB Compass der offizielle GUI-Client. Es ermöglicht dir,..:
Du kannst sogar zur "JSON-Ansicht" wechseln, um Abfragen in deinen Code zu kopieren/einzufügen.
Wenn du MongoDB Atlas verwendest, kannst du Atlas Search mit dem KI-gestützten Query Builder nutzen.
Gib einfach eine Aufforderung in natürlicher Sprache ein, wie zum Beispiel:
"Zeig mir alle Kunden aus Brasilien, die im letzten Monat Bestellungen über $100 aufgegeben haben."
Atlas schlägt eine passende MongoDB-Abfrage mit find() oder $search vor. Es ist ein hervorragender Produktivitätsbooster, vor allem, wenn du dir bei der Syntax unsicher bist.
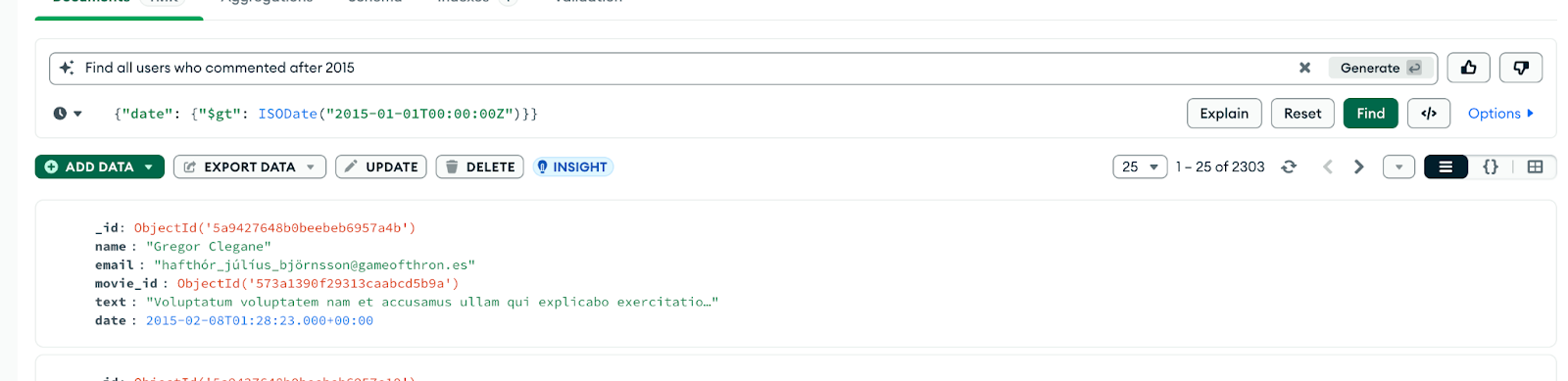
Abbildung 10. Verwende Compass, um eine Abfrage aus natürlicher Sprache zu erstellen.
limit + skip )_idWenn du von einem SQL-Hintergrund kommst, kann das Verständnis dafür, wie MongoDBs find() im Vergleich zu vertrauten SQL-Abfragen funktioniert, den Übergang erleichtern. Hier ist ein allgemeineral Vergleich der häufigsten Operationen:
|
Konzept |
SQL-Beispiel |
MongoDB-Äquivalent |
|
Grundlegende Abfrage |
|
|
|
Feldauswahl |
|
|
|
Sortieren |
|
|
|
Begrenzung |
|
|
|
Skippen |
|
|
Wie du siehst, ist die Syntax von MongoDB eher JavaScript-ähnlich und expressiv im JSON-Format, während SQL eher deklarativ und strukturiert ist. Wenn du diese Parallelen kennst, wirst du dich in MongoDB schneller zu Hause fühlen.
find() als deinen Datenfilter - kombiniere die Bedingungen für präzise Ergebnisse.Ganz gleich, ob du ein Startup-Dashboard, ein Datenanalyse-Tool oder ein E-Commerce-Backend entwickelst, die Beherrschung von find() wird deine MongoDB-Erfahrung reibungsloser, schneller und effektiver machen.
Bleib dran, wenn du in zukünftigen Artikeln mehr über MongoDB erfährst!
Willst du deine MongoDB-Kenntnisse unter Beweis stellen? Lies den Vollständigen Leitfaden zur MongoDB-Zertifizierung, um dich über deine Möglichkeiten zu informieren.
Lerne mehr über MongoDB und Datenbanken mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
