
Curso
Introduction to MongoDB in Python
3 h
24K
O MongoDB é um banco de dados NoSQL popular, projetado para oferecer flexibilidade e desempenho. Ao contrário dos bancos de dados relacionais tradicionais que usam tabelas estruturadas e SQL, o MongoDB armazena dados em documentos flexíveis, semelhantes a JSON. Isso o torna ideal para desenvolvedores que trabalham com dados dinâmicos ou semiestruturados.
Uma das operações mais importantes que você executará no MongoDB é a consulta de dados, e o método mais comumente usado para fazer isso é find(). Se você está apenas começando ou quer aprimorar suas habilidades de consulta, entender como o find() funciona é essencial para navegar e manipular os dados do MongoDB com eficiência.
Imagine que você está explorando um banco de dados de filmes. Você deseja encontrar todos os filmes de ficção científica lançados após o ano 2000 ou talvez listar todos os comentários de usuários feitos em um período específico. É nesse ponto que o find() se destaca.
Neste artigo, você aprenderá a usar o método find() para recuperar documentos de uma coleção, aplicar filtros, campos de projeto, classificar resultados e otimizar o desempenho - tudo isso enquanto trabalha com o conjunto de dados sample_mflix.
Para obter um passo a passo prático sobre o uso do MongoDB em fluxos de trabalho de ciência de dados, confira o curso Introdução ao MongoDB em Python.
O método find() é a principal maneira do MongoDB de recuperar documentos de uma coleção. Ele retorna um cursor para os documentos que correspondem à consulta especificada. Você pode então iterar sobre esse cursor ou convertê-lo em uma matriz, dependendo das necessidades do seu aplicativo.
Aqui está a sintaxe completa:
db.collection.find(<query>, <projection>, <options>)query (opcional): Um documento que define os critérios para a seleção de documentos. Se você omitir esse parâmetro ou passar um documento vazio ({}), find() retornará todos os documentos da coleção.projection (opcional): Um documento que especifica quais campos você deve retornar. Você pode incluir (1) ou excluir (0) campos. Por padrão, o MongoDB retorna todos os campos, inclusive _id.options (opcional): Um documento adicional para configurar o comportamento da consulta. Você pode definir itens como ordem de classificação, limites de paginação, tempos limite e dicas de índice.Para tornar os conceitos o mais claros e aplicáveis possível, usaremos o conjunto de dados de amostra do MongoDB Atlas - especificamente, o banco de dados sample_mflix. Esse conjunto de dados inclui coleções como filmes, comentários, usuários e cinemas, aos quais faremos referência ao longo do artigo para demonstrar cada exemplo.
db.books.find(
{ year: { $gte: 2000 } }, // query: books published in or after 2000
{ title: 1, author: 1, _id: 0 }, // projection: include only title and author
{ sort: { title: 1 }, limit: 5 } // options: sort by title, return only 5 books
)Essa consulta:
_id).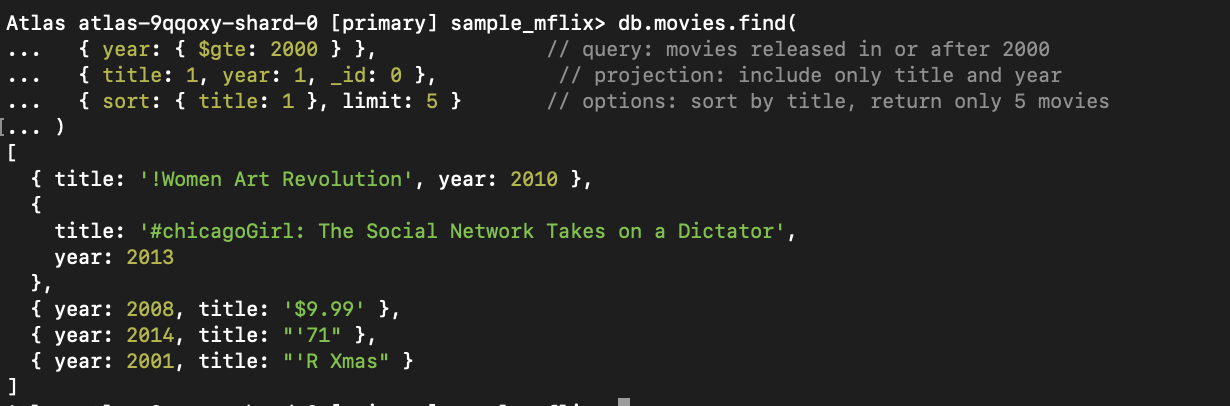
Figura 1. Essa consulta encontra filmes lançados depois de 2000, classificados por título e limitados a cinco resultados.
O resultado é um cursor, que carrega preguiçosamente os documentos correspondentes à medida que você os itera. Você pode usar .toArray() ou .forEach() para processar os resultados.
Se você estiver conectado por meio do shell do MongoDB (mongosh) e não atribuir o resultado a uma variável, somente os primeiros 20 documentos serão exibidos por padrão. Para exibir documentos adicionais, digite-o e pressione Enter. Esse processo continuará a buscar o próximo lote do cursor.
> Observação: O que você disse acima é um comportamento específico do shell, não uma limitação do MongoDB. Na maioria dos drivers do MongoDB (por exemplo, Node.js, Python, Java), chamar .toArray() ou iterar sobre o cursor busca automaticamente todos os resultados correspondentes. O comportamento do cursor pode variar de acordo com o ambiente e o idioma que você está usando.
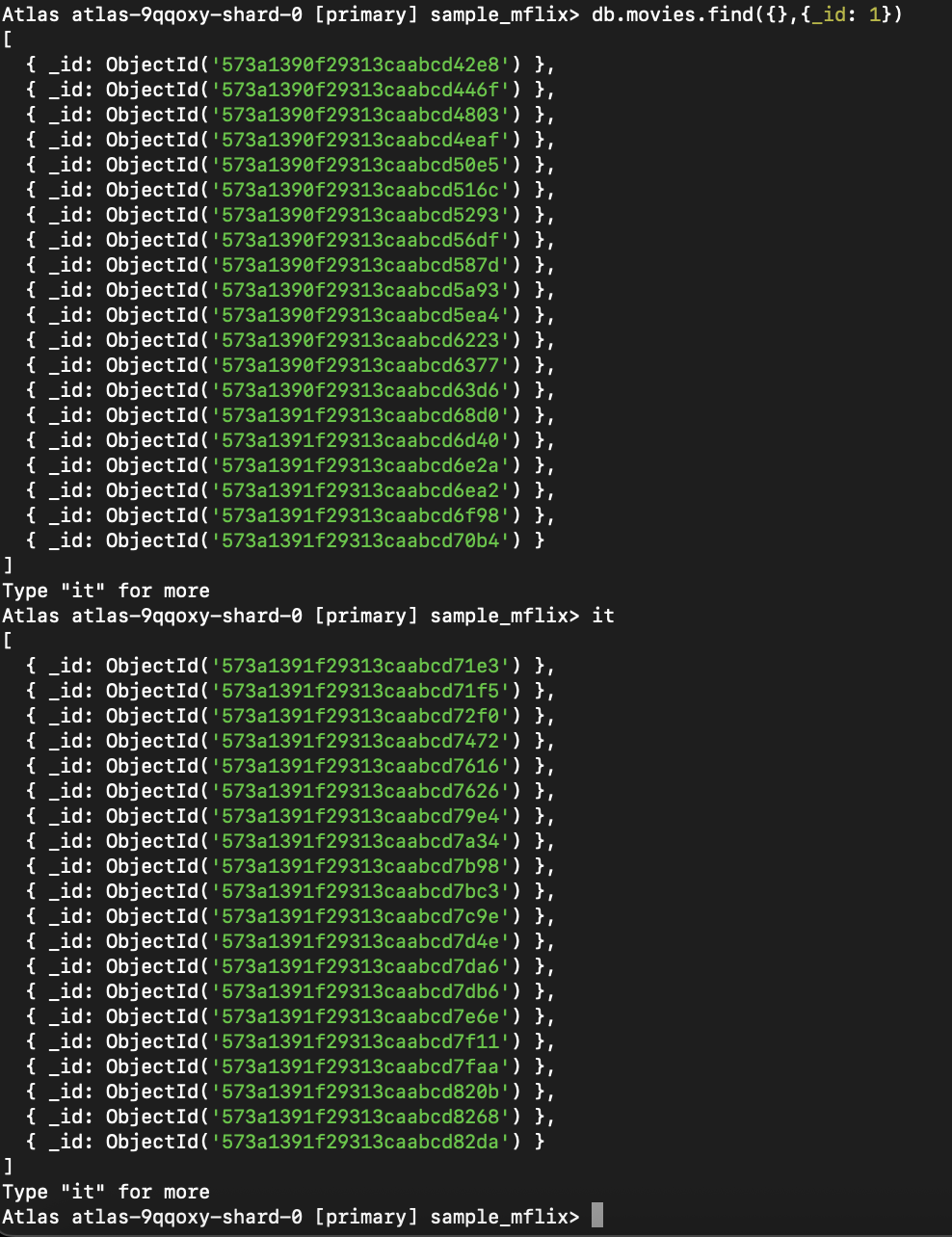
Figura 2. Essa consulta recupera todos os filmes, retornando apenas o campo _id e usando o cursor para buscar resultados adicionais.
Se você não conhece os bancos de dados NoSQL, o curso Introduction to NoSQL oferece conceitos básicos que complementam este tutorial.
Continuando com o exemplo do filme, digamos que você queira buscar todos os filmes do gênero Sci-Fi. Veja como você faria isso:
db.movies.find({ genres: "Sci-Fi" })Agora, você quer apenas filmes lançados no ano 2000 ou depois:
db.movies.find({ year: { $gte: 2000 } })E se você quiser os dois? Combine as condições:
db.movies.find({ genres: "Sci-Fi", year: { $gte: 2000 } })Como alternativa, você pode escrevê-lo explicitamente usando $and:
db.movies.find({ $and: [ { genres: "Sci-Fi" }, { year: { $gte: 2000 } } ] })Ambas as consultas retornam o mesmo resultado - documentos com o gênero Sci-Fi e o ano de lançamento 2000 ou posterior. O primeiro formulário é mais conciso e preferível quando os campos são diferentes.

Figura 3. Essas são maneiras diferentes de escrever a consulta que produzem o mesmo resultado.
Use o site find() como um funil de filtragem - cada condição restringe seus resultados.
Agora, vamos analisar como usar operadores lógicos e de comparação para levar suas consultas ao próximo nível.
$eq, $ne: igual, não igual$gt, $gte, $lt, $lte: maior/menor que (ou igual)$in, $nin: dentro ou fora da matrizImagine que você esteja programando pedidos de clientes e queira pedidos entre US$ 100 e US$ 500:
db.orders.find({ total: { $gte: 100, $lte: 500 } })$and, $or, $nor, $notAgora, imagine que você queira mostrar produtos da categoria "Livros" ou com preço abaixo de US$ 20. Aqui está um exemplo de consulta:
db.products.find({ $or: [ { category: "Books" }, { price: { $lt: 20 } } ] })Você pode acessar campos aninhados usando a notação de ponto:
db.customers.find({ "address.city": "Chicago" })A projeção permite que você retorne apenas o que precisa, o que pode melhorar significativamente o desempenho e a clareza.
db.movies.find({}, { directors: 1, languages: 1, _id: 0 })Importante: Ao especificar uma projeção, o MongoDB exige que você escolha entre dois modos: Você pode incluir campos específicos (1) ou excluir campos específicos (0). Você não pode misturar os dois estilos na mesma projeção, exceto pelo campo _id, que pode ser excluído mesmo quando outros campos são incluídos.
Válido (somente para inclusão):
db.movies.find({}, { directors: 1, languages: 1 })Válido (somente exclusão):
db.movies.find({}, { directors: 0, _id: 0 })Inválido (mistura de inclusão e exclusão):
db.movies.find({}, { directors: 1, languages: 0 }) // Not allowedA única exceção é o campo _id, que você pode excluir mesmo quando incluir outros campos:
db.movies.find({}, { directors: 1, _id: 0 }) // Allowed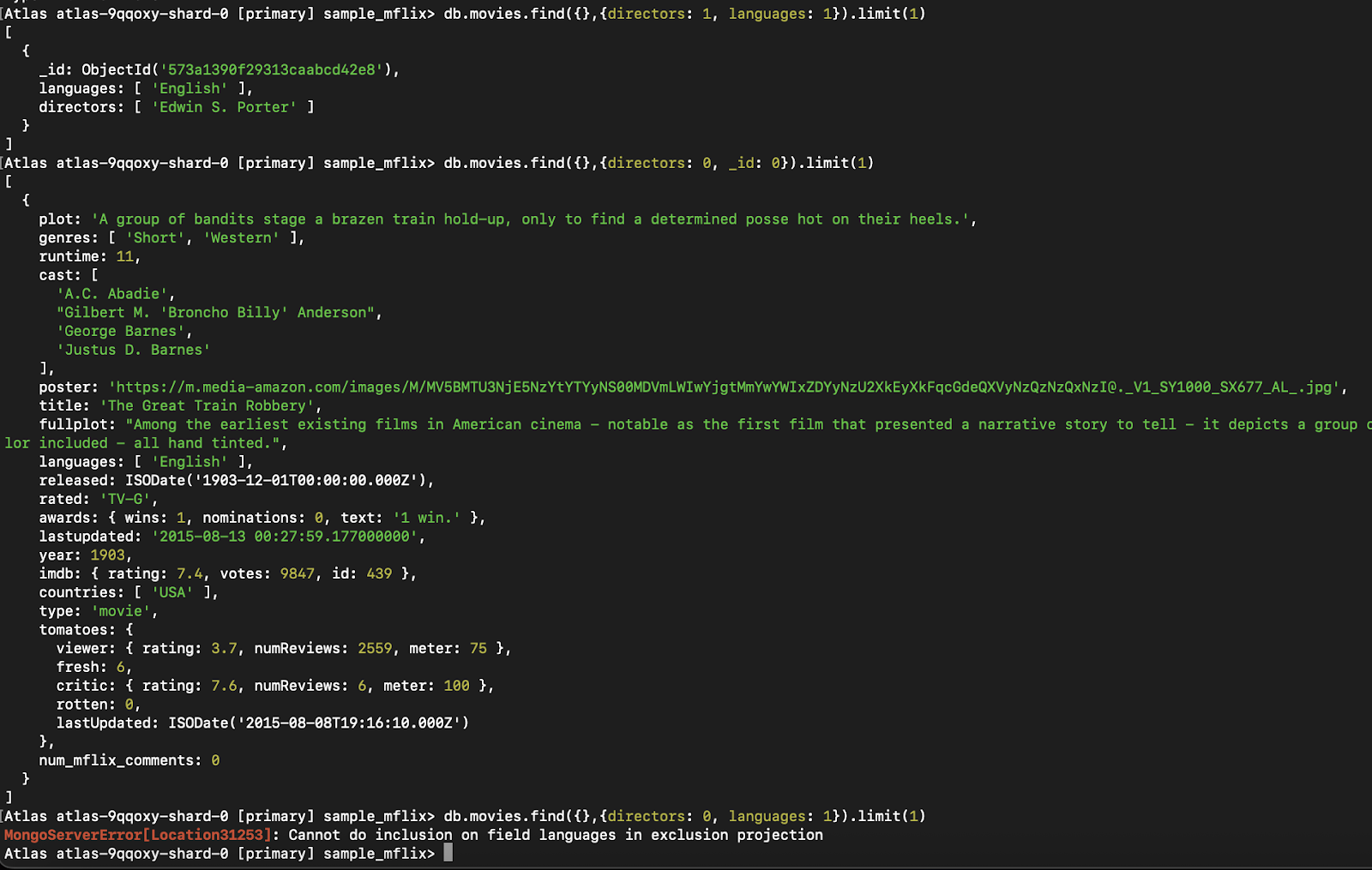
Figura 4. Esse exemplo demonstra o erro acionado pela mistura de inclusão e exclusão de campos em uma única projeção, o que o MongoDB não permite, exceto para `_id`.
Ao trabalhar com grandes conjuntos de dados, é comum mostrar aos usuários apenas uma parte dos dados de cada vez, uma técnica conhecida como paginação. Por exemplo, um aplicativo de streaming pode exibir 10 filmes por página em vez de carregar milhares de uma vez. Isso não apenas melhora o desempenho, mas também aprimora a experiência do usuário.
No MongoDB, a paginação é obtida por meio de uma combinação de sort(), limit() e skip().
Se você vem de uma experiência com SQL, veja como os conceitos comuns de paginação se comparam:
Consulta básica em SQL:
SELECT * FROM movies WHERE year >= 2000O mesmo pode ser expresso no MongoDB da seguinte forma:
db.movies.find({ year: { $gte: 2000 } })Seleção de campo no SQL:
SELECT title, year FROM moviesSeleção de campo no MongoDB:
db.movies.find({}, { title: 1, year: 1, _id: 0 })Agora, vamos dar uma olhada em mais alguns exemplos de operações de consulta comuns:
Classificação:
ORDER BY title ASC.sort({ title: 1 })Limitação:
LIMIT 10.limit(10)Pular:
OFFSET 10.skip(10)A compreensão desses paralelos pode ajudar os usuários de SQL a fazer a transição mais facilmente para o sistema de consulta baseado em documentos do MongoDB.
A classificação ajuda você a organizar seus resultados com base em um campo específico - por exemplo, para classificar filmes por título em ordem alfabética:
db.movies.find().sort({ title: 1 }) // ascending (A–Z)1 significa ordem ascendente (A-Z, 0-9)-1 significa ordem decrescente (Z-A, 9-0)Retornar apenas um determinado número de resultados - por exemplo, os 10 primeiros:
db.movies.find().limit(10)Isso é útil ao implementar listas de "10 principais" ou exibições iniciais.
Use essa opção para ignorar documentos. É frequentemente usado com limit() para paginação:
db.movies.find().skip(10).limit(10)Isso pula os primeiros 10 documentos e retorna os próximos 10, mostrando efetivamente a página 2 quando pageSize = 10.
Fórmula de paginação:
skip = (pageNumber - 1) * pageSize> Observação: O uso do site skip() para paginação profunda (por exemplo, skip(10000)) pode ser ineficiente, pois o MongoDB ainda verifica e descarta os documentos ignorados. Para melhorar o desempenho com grandes conjuntos de dados, considere a paginação baseada em intervalo usando campos indexados como _id.
db.movies.find()
.sort({ title: 1 })
.skip(20)
.limit(10)Esse padrão também é útil para recursos como "carregar mais" ou rolagem infinita.
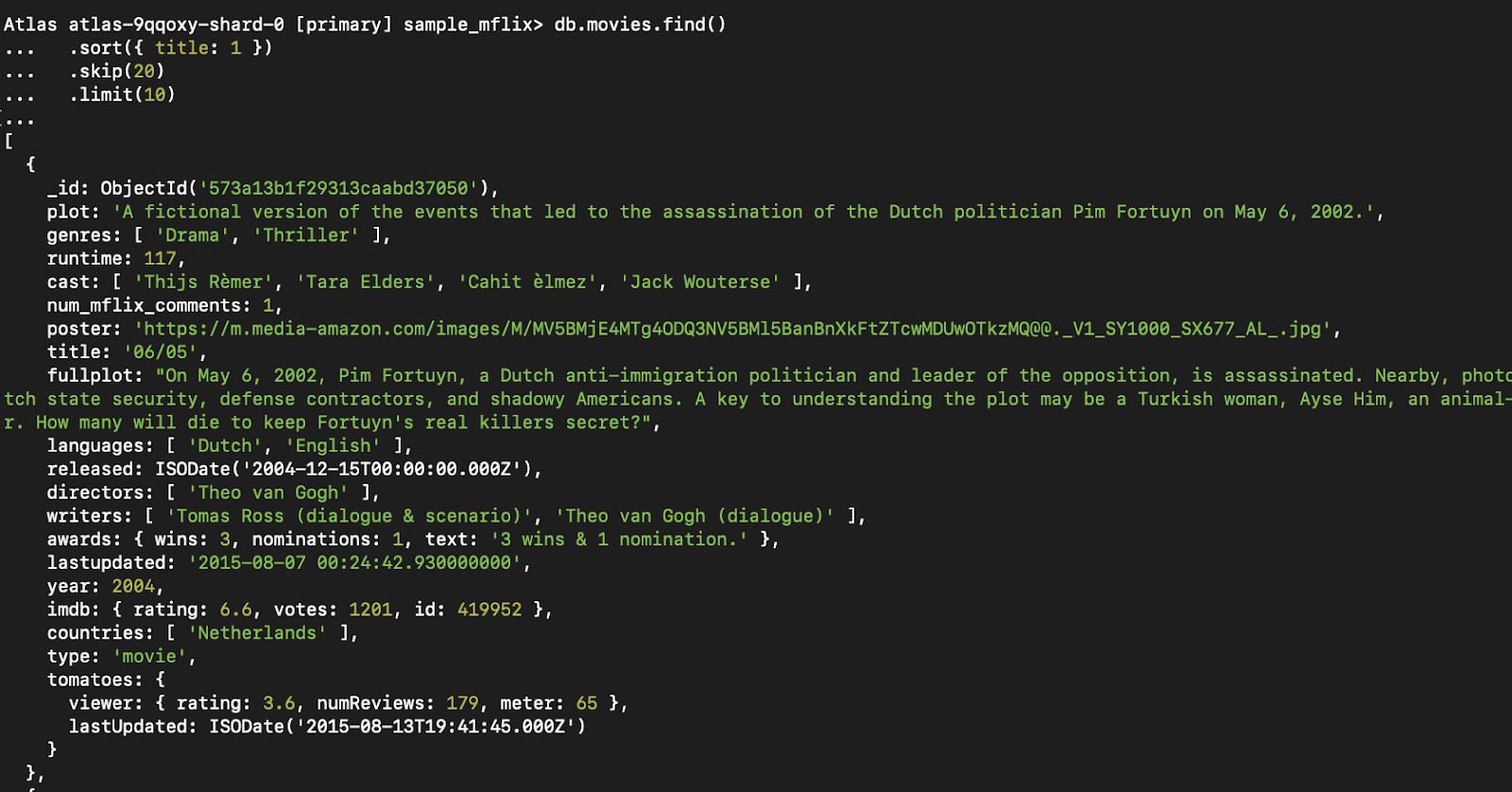
Figura 5. Essa consulta recupera a terceira página de resultados (10 filmes por página), ordenados por título.
O método find() retorna um cursor - um ponteiro para o conjunto de resultados. Você pode iterar sobre ele:
const cursor = db.movies.find({ type: "movie" });
cursor.forEach(doc => print(doc.name));Ou converta-o em uma matriz:
const results = db.collection.find().toArray();
Figura 6. Depois de chamar `find()`, você recebe um cursor. Você pode usá-lo para iterar sobre documentos ou converter o conjunto completo de resultados em uma matriz.
> Observação: O objeto cursor está disponível em mongosh ou no código por meio de drivers (por exemplo, Node.js, Python). Ferramentas de GUI, como o MongoDB Compass, tratam os cursores internamente. Você não acessará nem iterará sobre eles diretamente.
Para ajustar suas consultas, você pode usar métodos de cursor adicionais:
db.users.find({ age: { $gte: 30 } })
.sort({ name: 1 })
.limit(10)
.skip(5)
.maxTimeMS(200)
.hint({ age: 1 })maxTimeMS(ms)Se a consulta demorar muito, você a interrompehint()força o MongoDB a usar um índice específicobatchSize(n)Controle do número de documentos por lote: controla o número de documentos por loteVocê está se preparando para as entrevistas? Exploreas 25 principais perguntas e respostas da entrevista sobre o MongoDB para testarsua compreensão de conceitos fundamentais, como find().
Os índices são como folhas de consulta - eles ajudam o MongoDB a recuperar documentos mais rapidamente.
db.movies.createIndex({ type: 1 })db.users.find({ type: "movie" }).explain()Isso revela se os índices estão sendo usados e qual é a eficiência da sua consulta.
Sem um índice: 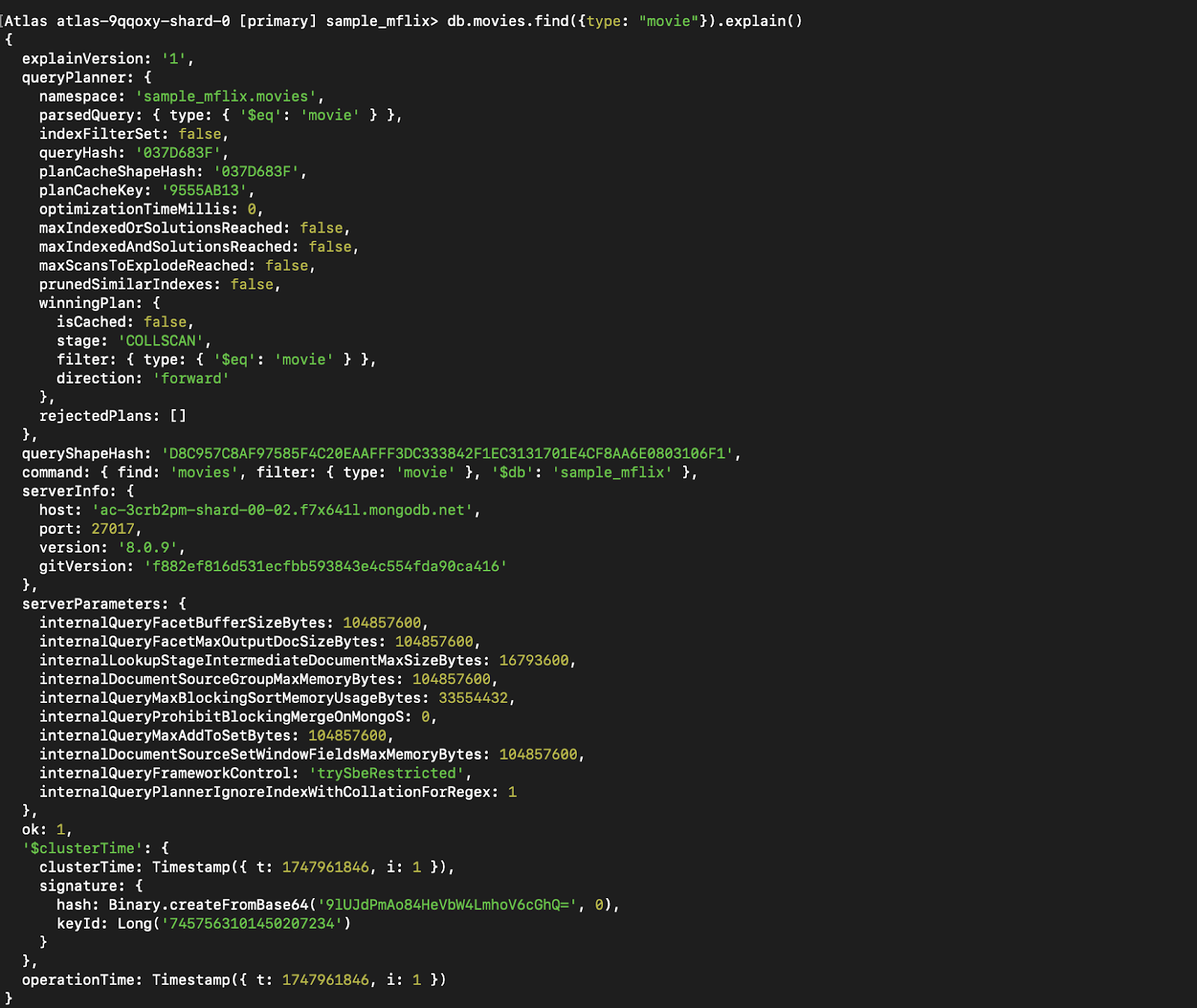
Figura 7. Execute `explain()` na consulta antes da indexação.
Criando um índice:
![]()
Figura 8. Crie um índice simples no campo type.
Com um índice:
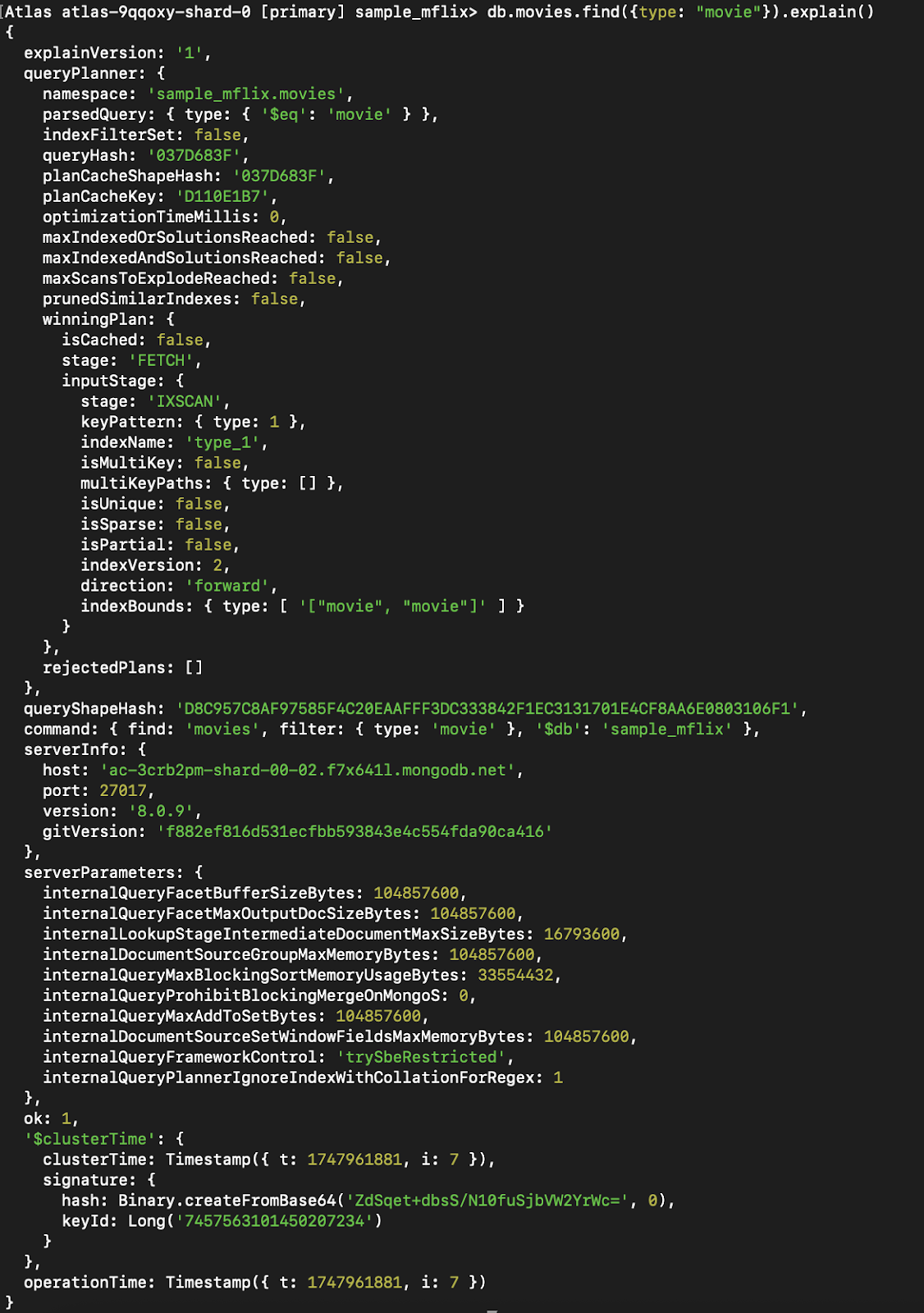
Figura 9. Execute a mesma consulta com `explain()`, agora usando um índice.
Você pode ver que a etapa que era anteriormente CollScan (varredura da coleção) se tornou Fetch + IXSCAN, que é basicamente usar o índice + pesquisar outros dados que não fazem parte do índice (já que estamos retornando tudo).
Se você preferir ferramentas visuais, o MongoDB Compass é o cliente GUI oficial. Ele permite que você:
Você pode até mesmo alternar para a "visualização JSON" para copiar/colar consultas em seu código.
Se você estiver usando o MongoDB Atlas, poderá aproveitar o Atlas Search com o criador de consultas com tecnologia de IA.
Basta digitar um prompt em linguagem natural, como:
"Mostre-me todos os clientes do Brasil que fizeram pedidos acima de US$ 100 no último mês."
O Atlas sugere uma consulta correspondente ao MongoDB usando find() ou $search. É um excelente impulsionador de produtividade, especialmente quando você não tem certeza da sintaxe.
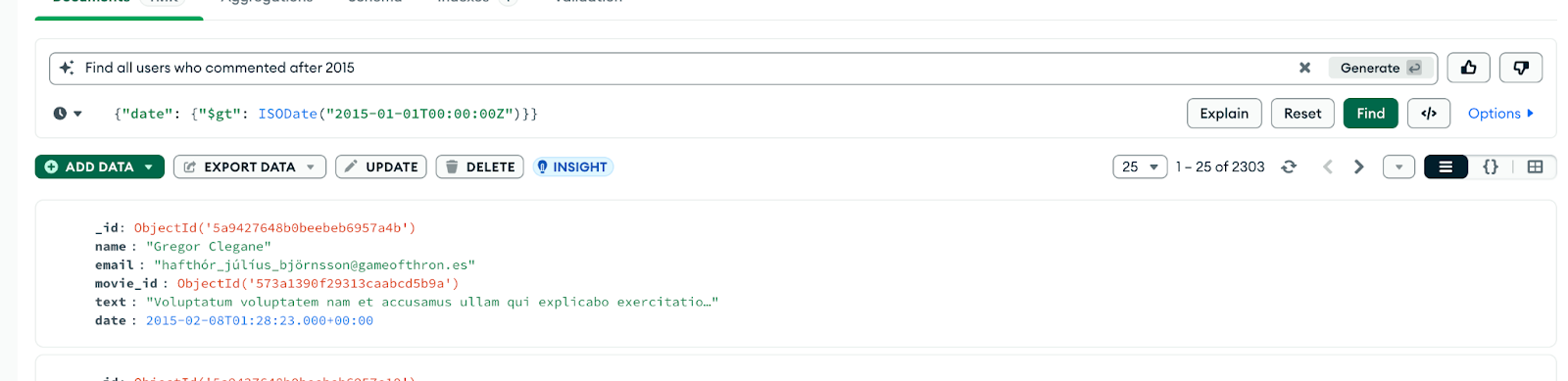
Figura 10. Use o Compass para gerar uma consulta a partir de linguagem natural.
limit + skip )_idSe você vem de uma experiência com SQL, entender como o find() do MongoDB se compara às consultas SQL conhecidas pode facilitar a transição. Aqui está uma comparação geral de operações comuns:
|
Conceito |
Exemplo de SQL |
MongoDB Equivalent |
|
Consulta básica |
|
|
|
Seleção de campo |
|
|
|
Classificação |
|
|
|
Limitação |
|
|
|
Pular |
|
|
Como você pode ver, a sintaxe do MongoDB é mais parecida com o JavaScript eexpressiva no formato JSON, enquanto o SQL é mais declarativo e estruturado. Conhecer esses paralelos ajudará você a se sentir em casa mais rapidamente no MongoDB.
find() como seu filtro de dados - combine condições para obter resultados precisos.Independentemente de você estar criando um painel de inicialização, uma ferramenta de análise de dados ou um back-end de comércio eletrônico, dominar o site find() tornará sua experiência com o MongoDB mais tranquila, rápida e eficaz.
Fique atento a mais informações sobre o MongoDB em artigos futuros!
Você quer validar suas habilidades em MongoDB? Leia o Guia completo de certificação do MongoDB para explorar suas opções.
Saiba mais sobre o MongoDB e bancos de dados com estes cursos!
Curso
Curso
Curso
blog
Zoumana Keita
12 min
blog
Kurtis Pykes
11 min
Tutorial
Javier Canales Luna
Tutorial
Sejal Jaiswal
Tutorial
Eugenia Anello
Tutorial
Tim Lu

