
Cours
Introduction à MongoDB en Python
3 h
24K
MongoDB est une base de données NoSQL populaire conçue pour la flexibilité et la performance. Contrairement aux bases de données relationnelles traditionnelles qui utilisent des tableaux structurés et le langage SQL, MongoDB stocke les données dans des documents flexibles de type JSON. Il est donc idéal pour les développeurs qui travaillent avec des données dynamiques ou semi-structurées.
L'une des opérations les plus importantes que vous effectuerez dans MongoDB est l'interrogation des données, et la méthode la plus couramment utilisée pour ce faire est find(). Que vous débutiez ou que vous cherchiez à améliorer vos compétences en matière de requêtes, il est essentiel de comprendre le fonctionnement de find() pour naviguer et manipuler efficacement vos données MongoDB.
Imaginez que vous explorez une base de données de films. Vous souhaitez trouver tous les films de science-fiction sortis après l'an 2000 ou dresser la liste de tous les commentaires d'utilisateurs émis au cours d'une période donnée. C'est là que find() brille.
Dans cet article, vous apprendrez à utiliser la méthode find() pour extraire des documents d'une collection, appliquer des filtres, projeter des champs, trier les résultats et optimiser les performances, tout en travaillant avec le jeu de données sample_mflix.
Pour une démonstration pratique de l'utilisation de MongoDB dans les flux de travail de la science des données, consultez le cours Introduction à MongoDB en Python.
La méthode find() est le principal moyen utilisé par MongoDB pour extraire des documents d'une collection. Il renvoie un curseur vers les documents qui correspondent à la requête spécifiée. Vous pouvez ensuite itérer sur ce curseur ou le convertir en tableau, selon les besoins de votre application.
Voici la syntaxe complète :
db.collection.find(<query>, <projection>, <options>)query (facultatif) : Document qui définit les critères de sélection des documents. Si vous omettez ce paramètre ou si vous transmettez un document vide ({}), find() renverra tous les documents de la collection.projection (facultatif) : Un document qui spécifie les champs à renvoyer. Vous pouvez inclure (1) ou exclure (0) des champs. Par défaut, MongoDB renvoie tous les champs, y compris _id.options (facultatif) : Un document supplémentaire pour configurer le comportement des requêtes. Vous pouvez définir des éléments tels que l'ordre de tri, les limites de pagination, les délais d'attente et les indices d'indexation.Pour que les concepts soient aussi clairs et applicables que possible, nous utiliserons l'échantillon de données de l'Atlas MongoDB, en particulierla base de données sample_mflix. Cet ensemble de données comprend des collections telles que les films, les commentaires, les utilisateurs et les cinémas, auxquelles nous ferons référence tout au long de l'article pour illustrer chaque exemple.
db.books.find(
{ year: { $gte: 2000 } }, // query: books published in or after 2000
{ title: 1, author: 1, _id: 0 }, // projection: include only title and author
{ sort: { title: 1 }, limit: 5 } // options: sort by title, return only 5 books
)Cette requête :
_id).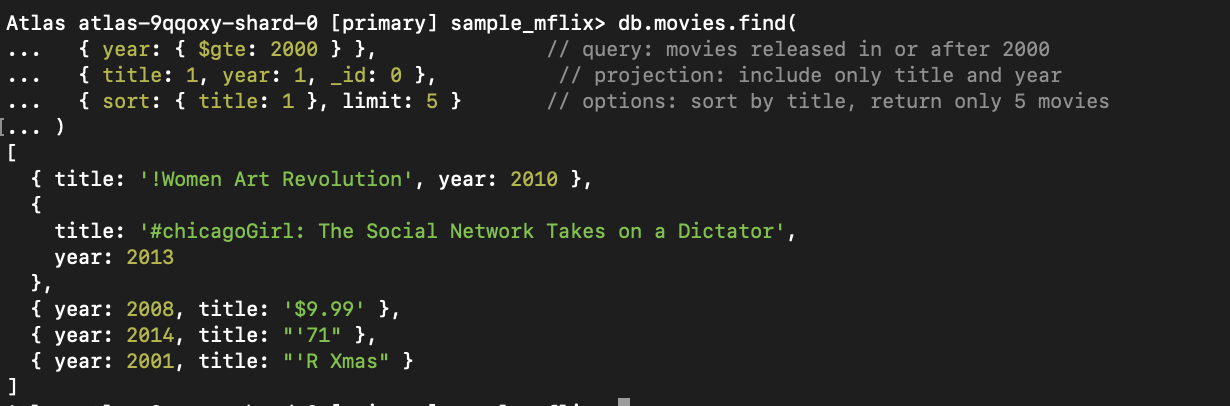
Figure 1. Cette requête recherche les films sortis après 2000, triés par titre et limités à cinq résultats.
Le résultat est un curseur qui charge paresseusement les documents correspondants au fur et à mesure que vous les parcourez. Vous pouvez utiliser .toArray() ou .forEach() pour traiter les résultats.
Si vous êtes connecté via le shell MongoDB (mongosh) et que vous n'affectez pas le résultat à une variable, seuls les 20 premiers documents s'afficheront par défaut. Pour afficher des documents supplémentaires, saisissez-le et appuyez sur Entrée. Ce processus se poursuivra pour récupérer le lot suivant dans le curseur.
> Note : Ce qui précède est un comportement spécifique au shell, et non une limitation de MongoDB. Dans la plupart des pilotes MongoDB (par exemple, Node.js, Python, Java), l'appel à .toArray() ou l'itération sur le curseur permet de récupérer automatiquement tous les résultats correspondants. Le comportement du curseur peut varier en fonction de l'environnement et de la langue que vous utilisez.
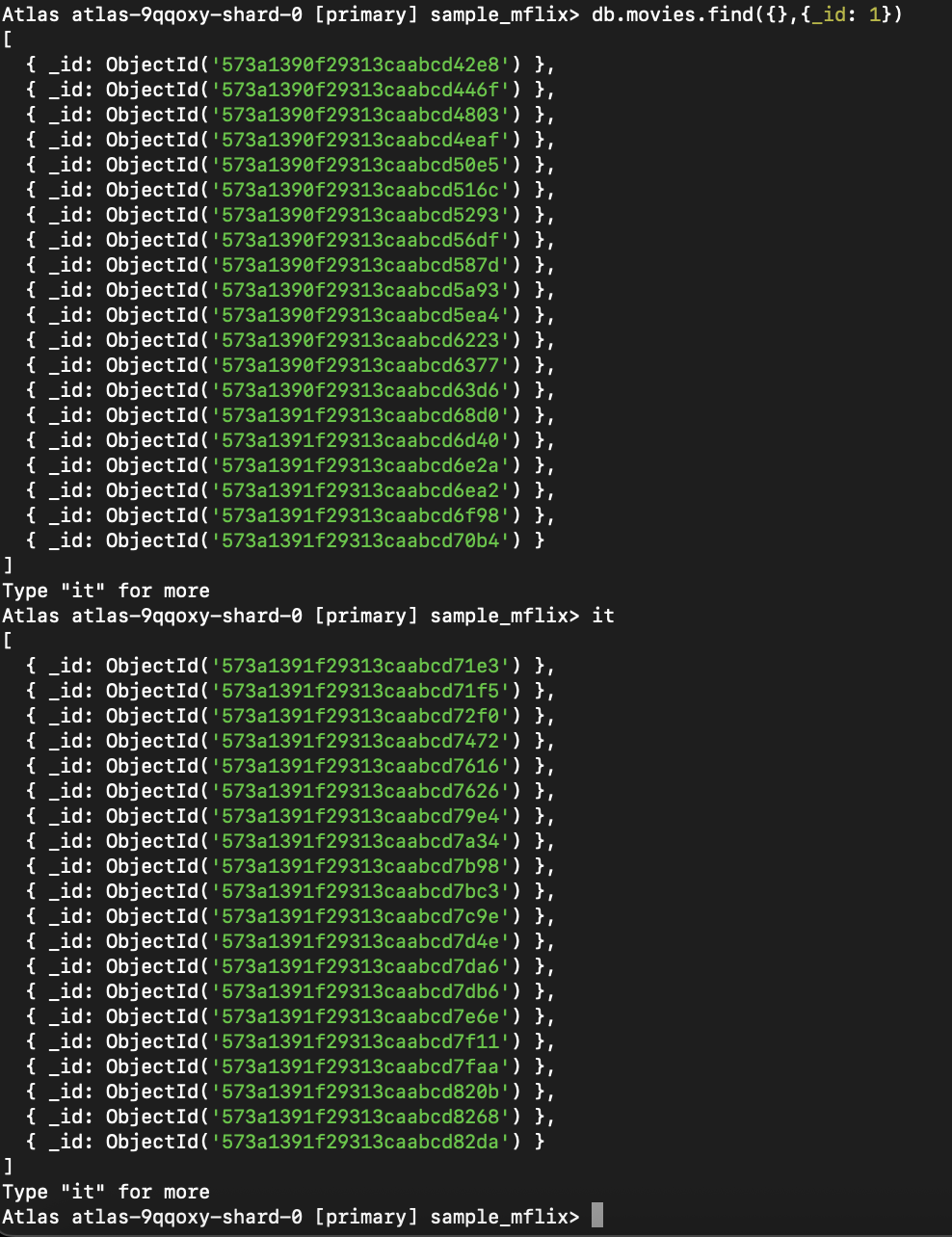
Figure 2. Cette requête permet de récupérer tous les films, en ne renvoyant que le champ _id et en utilisant le curseur pour obtenir d'autres résultats.
Si vous êtes novice en matière de bases de données NoSQL, le cours Introduction à NoSQL propose des concepts fondamentaux qui complètent ce tutoriel.
Reprenons l'exemple des films. Supposons que vous souhaitiez rechercher tous les films de science-fiction. Voici comment procéder :
db.movies.find({ genres: "Sci-Fi" })Maintenant, vous ne voulez que des films sortis en 2000 ou après :
db.movies.find({ year: { $gte: 2000 } })Et si vous voulez les deux ? Conditions de combinaison :
db.movies.find({ genres: "Sci-Fi", year: { $gte: 2000 } })Vous pouvez également l'écrire explicitement en utilisant $and:
db.movies.find({ $and: [ { genres: "Sci-Fi" }, { year: { $gte: 2000 } } ] })Les deux requêtes renvoient les mêmes résultats, à savoir des documents du genre Sci-Fi et de l'année de publication 2000 ou ultérieure. La première forme est plus concise et préférable lorsque les champs sont différents.

Figure 3. Il s'agit de différentes façons d'écrire la requête qui produisent le même résultat.
Utilisez find() comme un entonnoir de filtrage : chaque condition réduit vos résultats.
Voyons maintenant comment utiliser les opérateurs logiques et de comparaison pour améliorer vos requêtes.
$eq, $ne: égal, non égal$gt, $gte, $lt, $lte: plus grand/moins grand que (ou égal)$in, $nin: dans ou hors du tableauImaginez que vous fassiez le cursus des commandes de vos clients et que vous souhaitiez des commandes comprises entre 100 et 500 dollars :
db.orders.find({ total: { $gte: 100, $lte: 500 } })$and, $or, $nor, $notImaginons maintenant que vous souhaitiez afficher les produits de la catégorie "Livres" ou dont le prix est inférieur à 20 euros. Voici un exemple de requête :
db.products.find({ $or: [ { category: "Books" }, { price: { $lt: 20 } } ] })Vous pouvez accéder aux champs imbriqués en utilisant la notation par points :
db.customers.find({ "address.city": "Chicago" })La projection vous permet de ne renvoyer que ce dont vous avez besoin, ce qui peut améliorer considérablement les performances et la clarté.
db.movies.find({}, { directors: 1, languages: 1, _id: 0 })Important : Lorsque vous spécifiez une projection, MongoDB vous demande de choisir entre deux modes : Vous pouvez soit inclure des champs spécifiques (1), soit exclure des champs spécifiques (0). Vous ne pouvez pas mélanger les deux styles dans la même projection, à l'exception du champ _id, qui peut être exclu même si d'autres champs sont inclus.
✅ Valable (inclusion uniquement) :
db.movies.find({}, { directors: 1, languages: 1 })✅ Valable (exclusion uniquement) :
db.movies.find({}, { directors: 0, _id: 0 })❌ Invalide (mélange d'inclusion et d'exclusion) :
db.movies.find({}, { directors: 1, languages: 0 }) // Not allowedLa seule exception est le champ _id, que vous pouvez exclure même si vous incluez d'autres champs :
db.movies.find({}, { directors: 1, _id: 0 }) // Allowed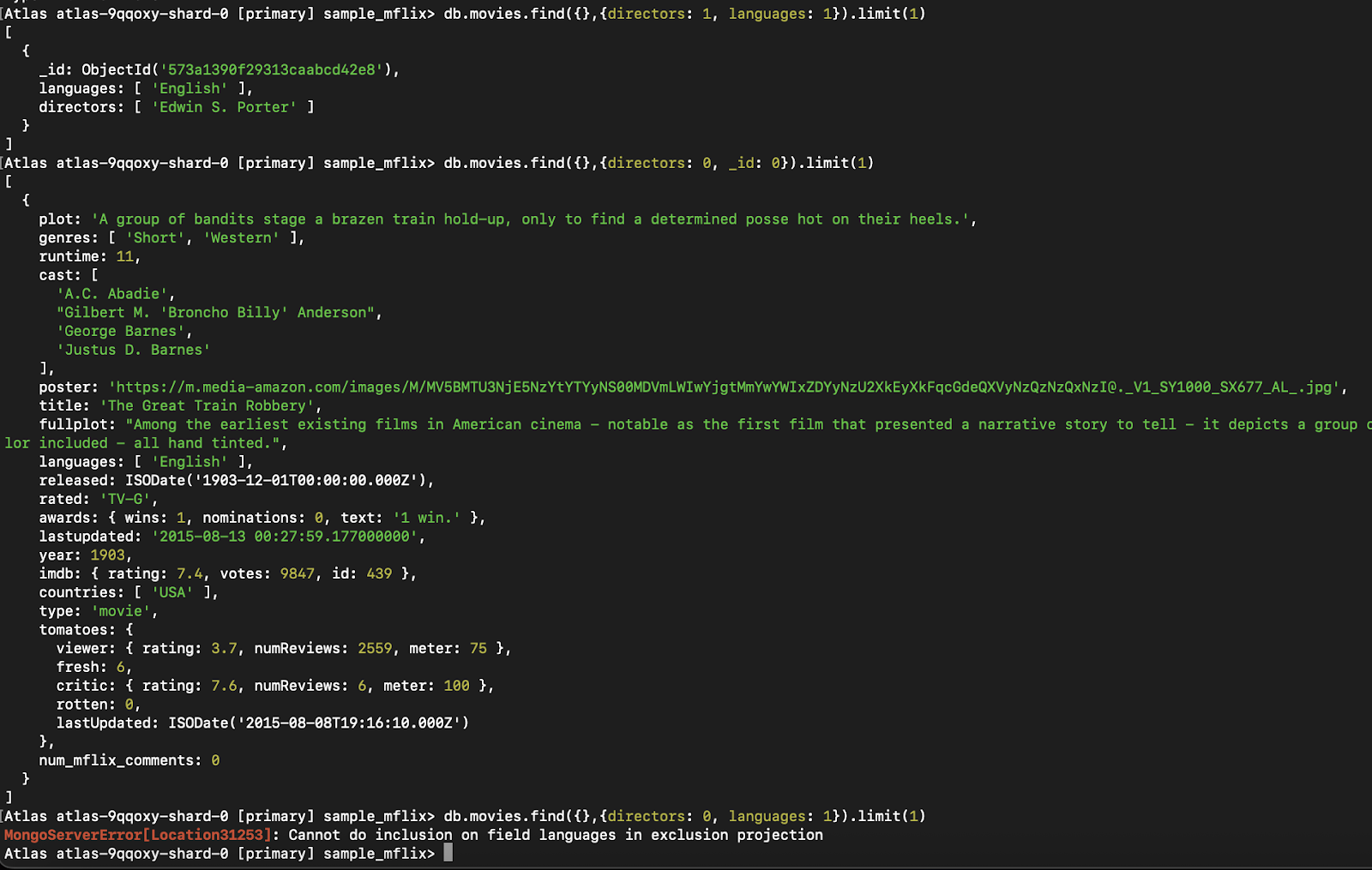
Figure 4. Cet exemple montre l'erreur déclenchée par le mélange de l'inclusion et de l'exclusion de champs dans une seule projection, ce que MongoDB ne permet pas, à l'exception de `_id`.
Lorsque vous travaillez avec de grands ensembles de données, il est courant de ne montrer aux utilisateurs qu'une partie des données à la fois, une technique connue sous le nom de pagination. Par exemple, une application de diffusion en continu peut afficher 10 films par page au lieu d'en charger des milliers en même temps. Cela permet non seulement d'améliorer les performances, mais aussi l'expérience de l'utilisateur.
Dans MongoDB, la pagination est réalisée à l'aide d'une combinaison de sort(), limit(), et skip().
Si vous venez d'un milieu SQL, voici comment les concepts de pagination les plus courants se comparent :
Requête de base en SQL :
SELECT * FROM movies WHERE year >= 2000La même chose peut être exprimée dans MongoDB comme suit :
db.movies.find({ year: { $gte: 2000 } })Sélection de champs en SQL :
SELECT title, year FROM moviesSélection de champs dans MongoDB :
db.movies.find({}, { title: 1, year: 1, _id: 0 })Voyons maintenant quelques autres exemples d'opérations de requête courantes :
Tri :
ORDER BY title ASC.sort({ title: 1 })Limitation :
LIMIT 10.limit(10)Saut à la corde :
OFFSET 10.skip(10)La compréhension de ces parallèles peut aider les utilisateurs de SQL à passer plus facilement au système d'interrogation basé sur les documents de MongoDB.
Le tri vous permet d'organiser vos résultats en fonction d'un champ spécifique - par exemple, pour trier les films par titre dans l'ordre alphabétique :
db.movies.find().sort({ title: 1 }) // ascending (A–Z)1 signifie ordre croissant (A-Z, 0-9)-1 signifie ordre décroissant (Z-A, 9-0)Ne renvoyer qu'un certain nombre de résultats, par exemple les 10 premiers :
db.movies.find().limit(10)Cette fonction est utile lors de la mise en œuvre de listes "Top 10" ou de vues initiales.
Utilisez cette option pour sauter des documents. Il est souvent utilisé avec limit() pour la pagination :
db.movies.find().skip(10).limit(10)Cette méthode permet de sauter les 10 premiers documents et de renvoyer les 10 suivants, affichant ainsi la page 2 lorsque pageSize = 10.
Formule de pagination :
skip = (pageNumber - 1) * pageSize> Note : L'utilisation de skip() pour la pagination profonde (par exemple, skip(10000)) peut s'avérer inefficace, car MongoDB scanne et rejette toujours les documents ignorés. Pour améliorer les performances des grands ensembles de données, envisagez une pagination basée sur l'intervalle en utilisant des champs indexés tels que _id.
db.movies.find()
.sort({ title: 1 })
.skip(20)
.limit(10)Ce modèle est également utile pour les fonctions telles que "charger plus" ou le défilement infini.
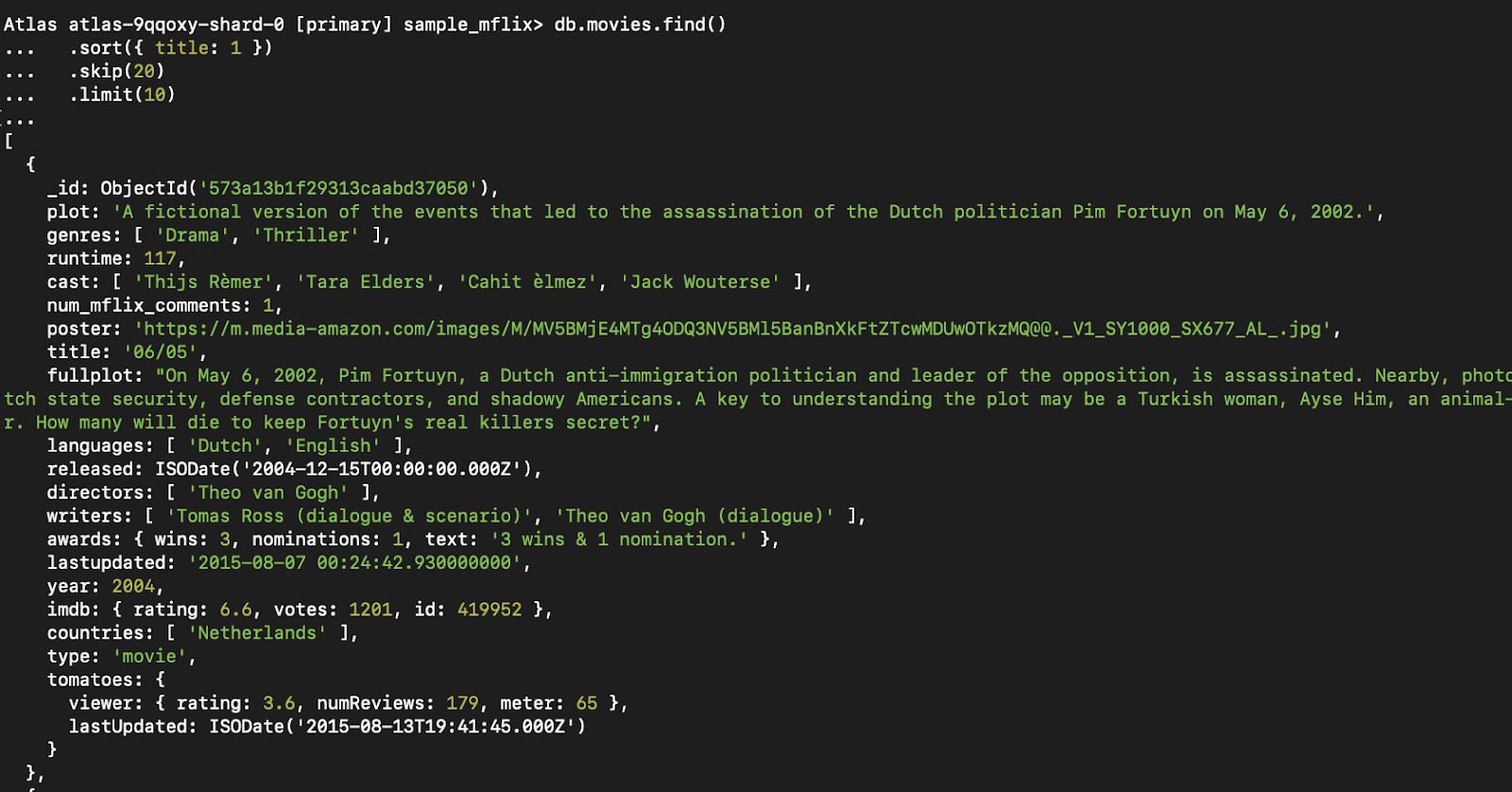
Figure 5. Cette requête permet d'obtenir la troisième page de résultats (10 films par page), classés par titre.
La méthode find() renvoie un curseur, c'est-à-dire un pointeur sur l'ensemble des résultats. Vous pouvez l'itérer :
const cursor = db.movies.find({ type: "movie" });
cursor.forEach(doc => print(doc.name));Ou convertissez-le en tableau :
const results = db.collection.find().toArray();
Figure 6. Après avoir appelé `find()`, vous recevez un curseur. Vous pouvez l'utiliser pour itérer sur les documents ou convertir l'ensemble des résultats en un tableau.
> Note : L'objet curseur est disponible sur mongosh ou dans le code via des pilotes (par exemple, Node.js, Python). Les outils d'interface graphique tels que MongoDB Compass gèrent les curseurs en interne. Vous n'y accéderez pas et n'effectuerez pas d'itération directement.
Pour affiner vos requêtes, vous pouvez utiliser des méthodes de curseur supplémentaires :
db.users.find({ age: { $gte: 30 } })
.sort({ name: 1 })
.limit(10)
.skip(5)
.maxTimeMS(200)
.hint({ age: 1 })maxTimeMS(ms): interrompt la requête si elle prend trop de tempshint(): force MongoDB à utiliser un index spécifiquebatchSize(n): contrôle le nombre de documents par lotVous préparez des entretiens ? Explorezles 25 meilleures questions et réponses d'entretien sur MongoDB pour tester votrecompréhension des concepts de base tels que find().
Les index sont comme des antisèches : ils permettent à MongoDB de retrouver les documents plus rapidement.
db.movies.createIndex({ type: 1 })db.users.find({ type: "movie" }).explain()Cela permet de savoir si des index sont utilisés et si votre requête est efficace.
Sans index : 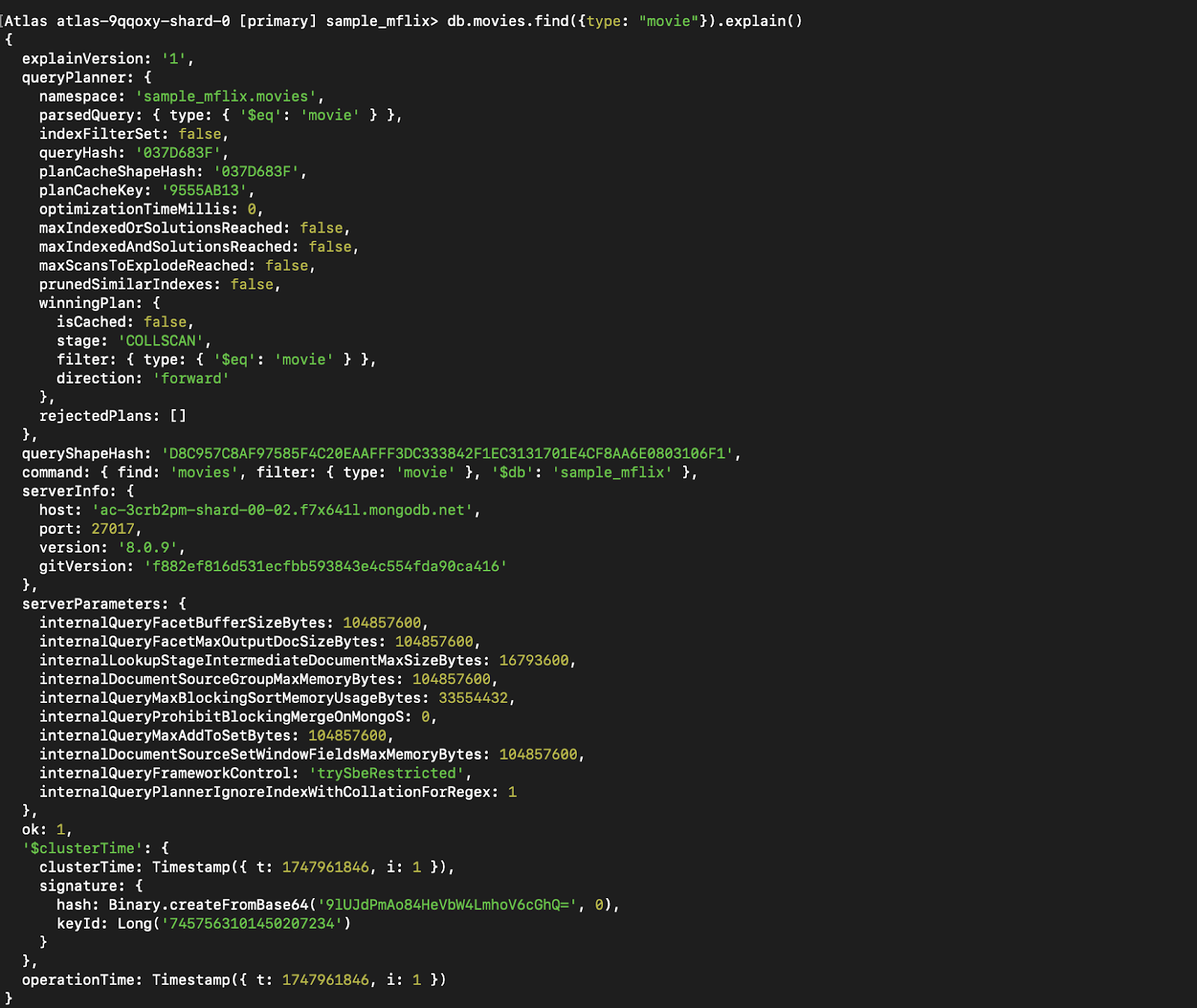
Figure 7. Exécutez `explain()` sur la requête avant l'indexation.
Création d'un index :
![]()
Figure 8. Créez un index simple sur le champ type.
Avec un index :
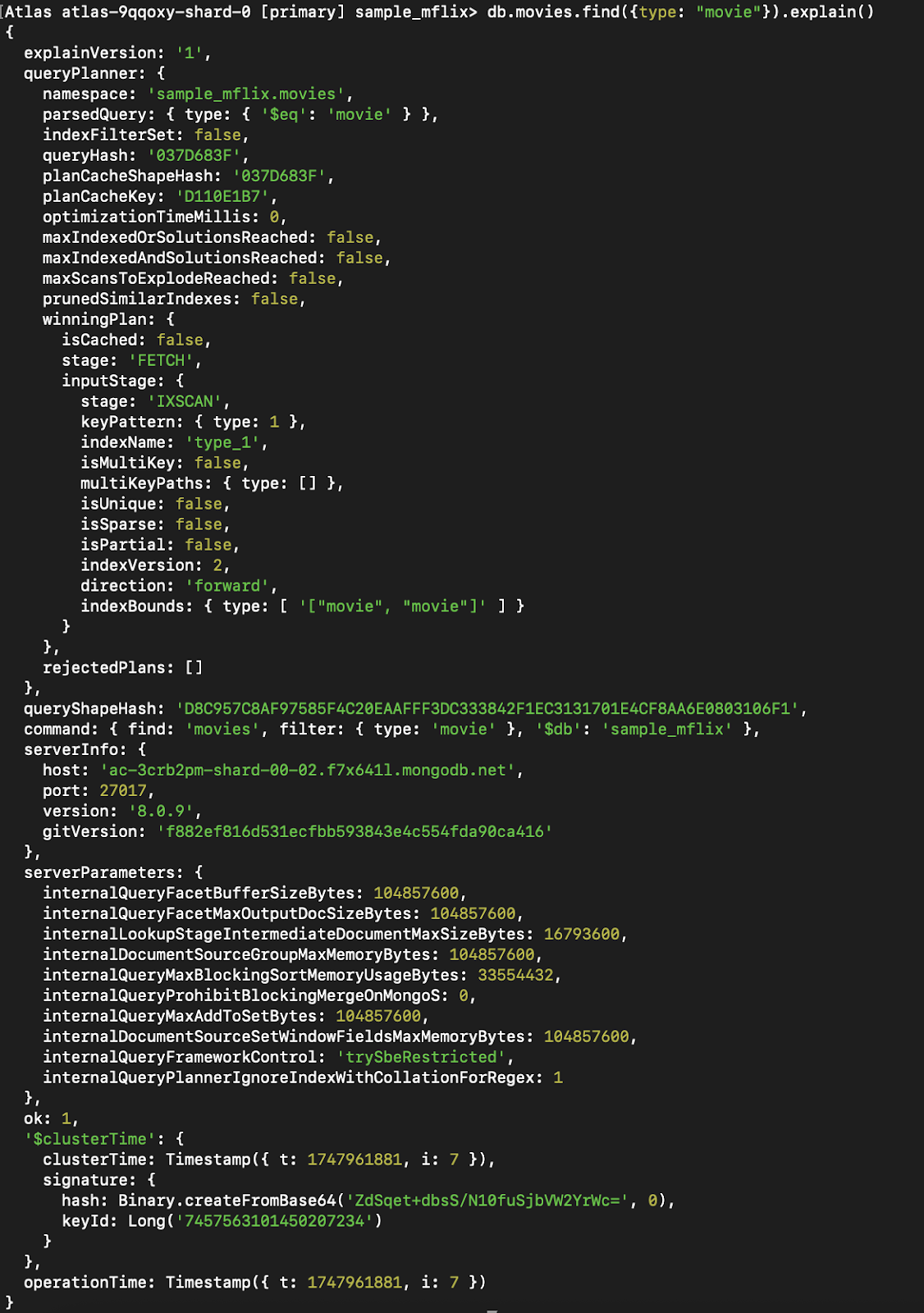
Figure 9. Exécutez la même requête avec `explain()`, en utilisant maintenant un index.
Vous pouvez voir que l'étape qui était auparavant CollScan (analyse de la collection) est devenue Fetch + IXSCAN, qui consiste essentiellement à utiliser l'index et à rechercher d'autres données qui ne font pas partie de l'index (puisque nous renvoyons tout).
Si vous préférez les outils visuels, MongoDB Compass est le client GUI officiel. Il vous permet de :
Vous pouvez même passer à la "vue JSON" pour copier/coller des requêtes dans votre code.
Si vous utilisez MongoDB Atlas, vous pouvez tirer parti d'Atlas Search avec le générateur de requêtes alimenté par l'IA.
Il suffit de taper une invite en langage naturel, comme par exemple :
"Montrez-moi tous les clients du Brésil qui ont passé des commandes de plus de 100 dollars au cours du dernier mois.
Atlas suggère une requête MongoDB correspondante en utilisant find() ou $search. C'est un excellent stimulant de la productivité, surtout lorsque vous n'êtes pas sûr de la syntaxe.
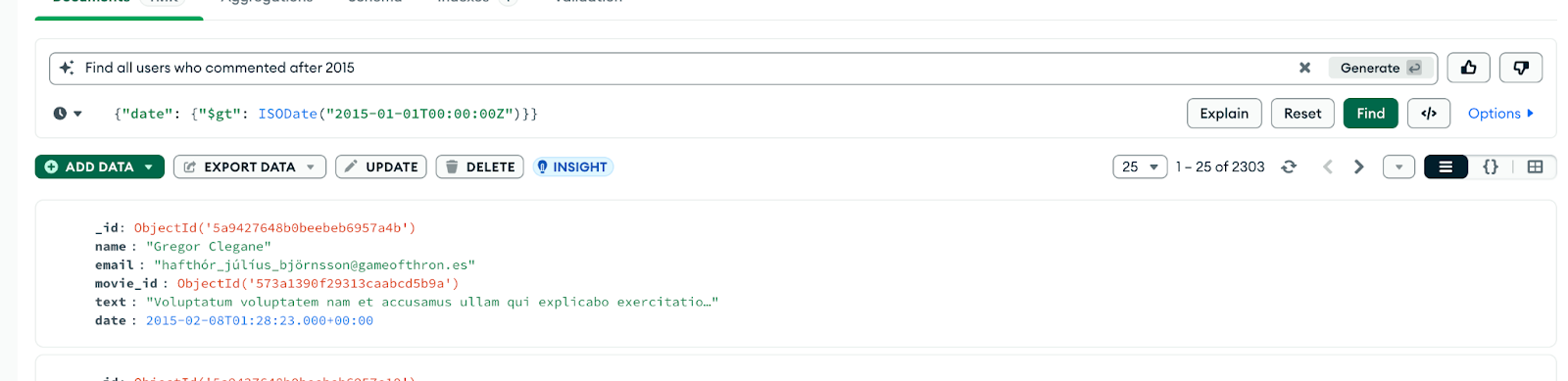
Figure 10. Utilisez Compass pour générer une requête à partir d'un langage naturel.
limit + skip )_idSi vous venez d'un milieu SQL, le fait de comprendre comment find() de MongoDB se compare aux requêtes SQL familières peut faciliter la transition. Voici une comparaison généraleal des opérations courantes :
|
Concept |
Exemple SQL |
MongoDB Equivalent |
|
Requête de base |
|
|
|
Sélection des champs |
|
|
|
Tri |
|
|
|
Limitation |
|
|
|
Saut à la corde |
|
|
Comme vous pouvez le constater, la syntaxe de MongoDB est plus proche de JavaScript et expressive au format JSON, tandis que SQL est plus déclaratif et structuré. La connaissance de ces parallèles vous aidera à vous sentir plus rapidement à l'aise avec MongoDB.
find() comme votre filtre de données - combinez les conditions pour obtenir des résultats précis.Que vous construisiez un tableau de bord de startup, un outil d'analyse de données ou un back-end de commerce électronique, la maîtrise de find() rendra votre expérience de MongoDB plus fluide, plus rapide et plus efficace.
Restez à l'écoute pour d'autres articles sur MongoDB !
Vous souhaitez valider vos compétences en MongoDB ? Lisez le Guide complet de la certification MongoDB pour explorer vos options.
Apprenez-en plus sur MongoDB et les bases de données avec ces cours !
Cours
Cours
Cours