
Curso
Introducción a MongoDB en Python
3 h
24K
MongoDB es una popular base de datos NoSQL diseñada para ofrecer flexibilidad y rendimiento. A diferencia de las bases de datos relacionales tradicionales que utilizan tablas estructuradas y SQL, MongoDB almacena los datos en documentos flexibles similares a JSON. Esto lo hace ideal para programadores que trabajan con datos dinámicos o semiestructurados.
Una de las operaciones más importantes que realizarás en MongoDB es la consulta de datos, y el método más utilizado para hacerlo es find(). Tanto si acabas de empezar como si quieres mejorar tus habilidades de consulta, comprender cómo funciona find() es esencial para navegar y manipular tus datos MongoDB con eficacia.
Imagina que estás explorando una base de datos de películas. Quieres encontrar todas las películas de ciencia ficción estrenadas después del año 2000, o quizás listar todos los comentarios de los usuarios realizados en un periodo de tiempo concreto. Ahí es donde brilla find().
En este artículo, aprenderás a utilizar el método find() para recuperar documentos de una colección, aplicar filtros, proyectar campos, ordenar resultados y optimizar el rendimiento, todo ello mientras trabajas con el conjunto de datos sample_mflix.
Para un recorrido práctico sobre el uso de MongoDB en los flujos de trabajo de la ciencia de datos, consulta el curso Introducción a MongoDB en Python.
El método find() es la forma principal de MongoDB de recuperar documentos de una colección. Devuelve un cursor a los documentos que coinciden con la consulta especificada. A continuación, puedes iterar sobre este cursor, o convertirlo en un arreglo, según las necesidades de tu aplicación.
Aquí tienes la sintaxis completa:
db.collection.find(<query>, <projection>, <options>)query (opcional): Documento que define los criterios de selección de los documentos. Si omites este parámetro o pasas un documento vacío ({}), find() devolverá todos los documentos de la colección.projection (opcional): Un documento que especifica qué campos devolver. Puedes incluir (1) o excluir (0) campos. Por defecto, MongoDB devuelve todos los campos, incluido _id.options (opcional): Un documento adicional para configurar el comportamiento de la consulta. Puedes establecer cosas como el orden de clasificación, los límites de paginación, los tiempos de espera y las sugerencias de índice.Para que los conceptos sean lo más claros y aplicables posible, utilizaremos el conjunto de datos de muestra del Atlas MongoDB, en concreto, la base de datos sample_mflix. Este conjunto de datos incluye colecciones como películas, comentarios, usuarios y cines, a las que haremos referencia a lo largo del artículo para demostrar cada ejemplo.
db.books.find(
{ year: { $gte: 2000 } }, // query: books published in or after 2000
{ title: 1, author: 1, _id: 0 }, // projection: include only title and author
{ sort: { title: 1 }, limit: 5 } // options: sort by title, return only 5 books
)Esta consulta:
_id).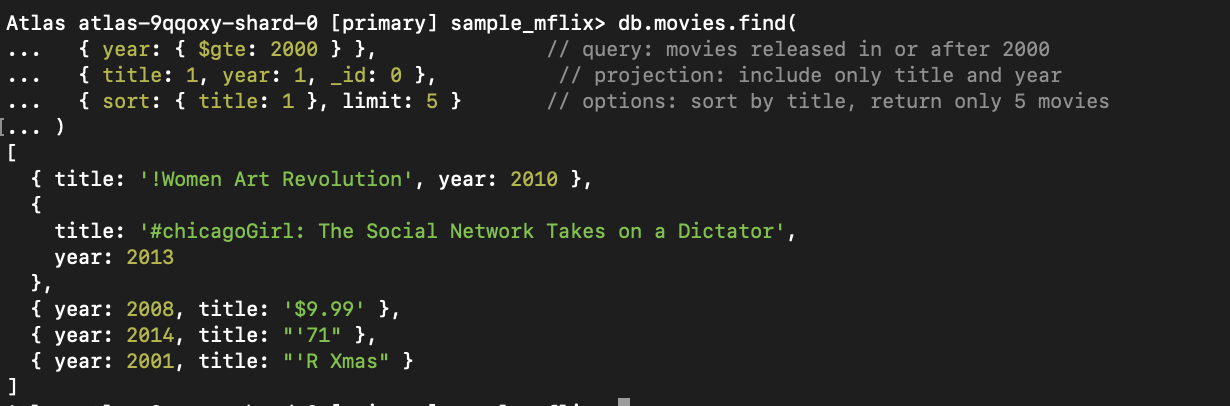
Figura 1. Esta consulta busca películas estrenadas después de 2000, ordenadas por título y limitadas a cinco resultados.
El resultado es un cursor, que carga perezosamente los documentos coincidentes a medida que iteras sobre ellos. Puedes utilizar .toArray() o .forEach() para procesar los resultados.
Si te conectas a través del terminal de MongoDB (mongosh) y no asignas el resultado a una variable, sólo se mostrarán por defecto los 20 primeros documentos. Para ver documentos adicionales, escríbelo y pulsa Intro. Este proceso continuará obteniendo el siguiente lote del cursor.
> Nota: Lo anterior es un comportamiento específico del terminal, no una limitación de MongoDB. En la mayoría de los controladores de MongoDB (por ejemplo, Node.js, Python, Java), al llamar a .toArray() o iterar sobre el cursor se obtienen automáticamente todos los resultados coincidentes. El comportamiento del cursor puede variar según el entorno y el idioma que estés utilizando.
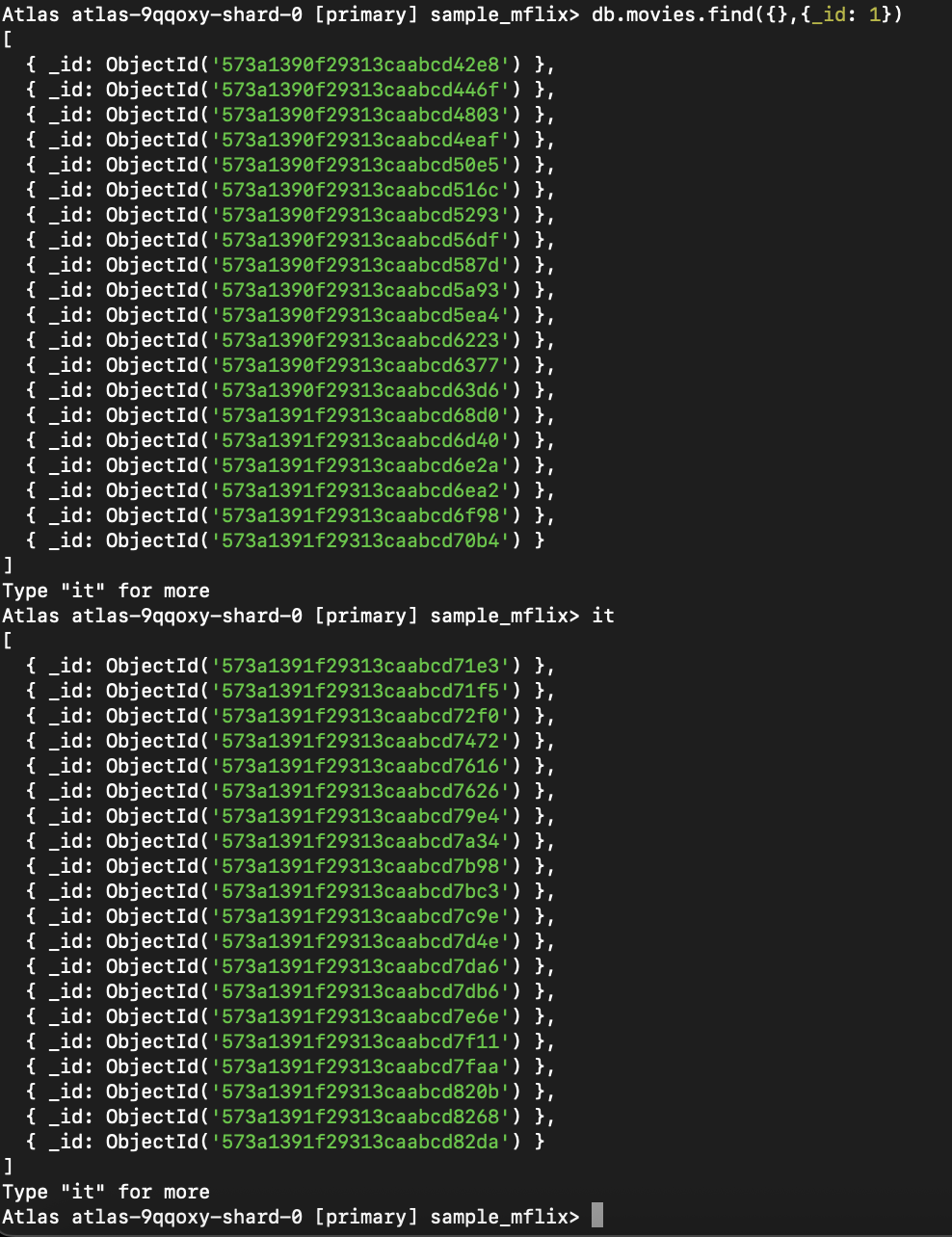
Figura 2. Esta consulta recupera todas las películas, devolviendo sólo el campo _id y utilizando el cursor para obtener resultados adicionales.
Si eres nuevo en las bases de datos NoSQL, el curso Introducción a NoSQL ofrece conceptos básicos que complementan este tutorial.
Siguiendo con el ejemplo de las películas, supongamos que quieres buscar todas las películas del género Ciencia Ficción. He aquí cómo lo harías:
db.movies.find({ genres: "Sci-Fi" })Ahora, sólo quieres películas estrenadas en el año 2000 o después:
db.movies.find({ year: { $gte: 2000 } })¿Y si quieres las dos cosas? Combina las condiciones:
db.movies.find({ genres: "Sci-Fi", year: { $gte: 2000 } })Alternativamente, puedes escribirlo explícitamente utilizando $and:
db.movies.find({ $and: [ { genres: "Sci-Fi" }, { year: { $gte: 2000 } } ] })Ambas consultas devuelven el mismo resultado: documentos con el género Ciencia Ficción y el año de publicación 2000 o posterior. La primera forma es más concisa y preferible cuando los campos son diferentes.

Figura 3. Son formas diferentes de escribir la consulta que producen el mismo resultado.
Utiliza find() como un embudo de filtrado: cada condición reduce tus resultados.
Ahora vamos a repasar cómo utilizar operadores de comparación y lógicos para llevar tus consultas al siguiente nivel.
$eq, $ne: igual, no igual$gt, $gte, $lt, $lte: mayor/menor que (o igual que)$in, $nin: en o no en arregloImagina que haces el seguimiento de los pedidos de los clientes y quieres pedidos de entre 100 y 500 $:
db.orders.find({ total: { $gte: 100, $lte: 500 } })$and, $or, $nor, $notAhora, imagina que quieres mostrar productos de la categoría "Libros" o con un precio inferior a 20 €. Aquí tienes un ejemplo de consulta:
db.products.find({ $or: [ { category: "Books" }, { price: { $lt: 20 } } ] })Puedes acceder a los campos anidados utilizando la notación con puntos:
db.customers.find({ "address.city": "Chicago" })La proyección te permite devolver sólo lo que necesitas, lo que puede mejorar significativamente el rendimiento y la claridad.
db.movies.find({}, { directors: 1, languages: 1, _id: 0 })Importante: Al especificar una proyección, MongoDB te pide que elijas entre dos modos: Incluye campos específicos (1) o excluye campos específicos (0). No puedes mezclar ambos estilos en la misma proyección, excepto para el campo _id, que puede excluirse aunque se incluyan otros campos.
✅ Válido (sólo inclusión):
db.movies.find({}, { directors: 1, languages: 1 })✅ Válido (sólo exclusión):
db.movies.find({}, { directors: 0, _id: 0 })❌ No válido (mezcla de inclusión y exclusión):
db.movies.find({}, { directors: 1, languages: 0 }) // Not allowedLa única excepción es el campo _id, que puedes excluir aunque incluyas otros campos:
db.movies.find({}, { directors: 1, _id: 0 }) // Allowed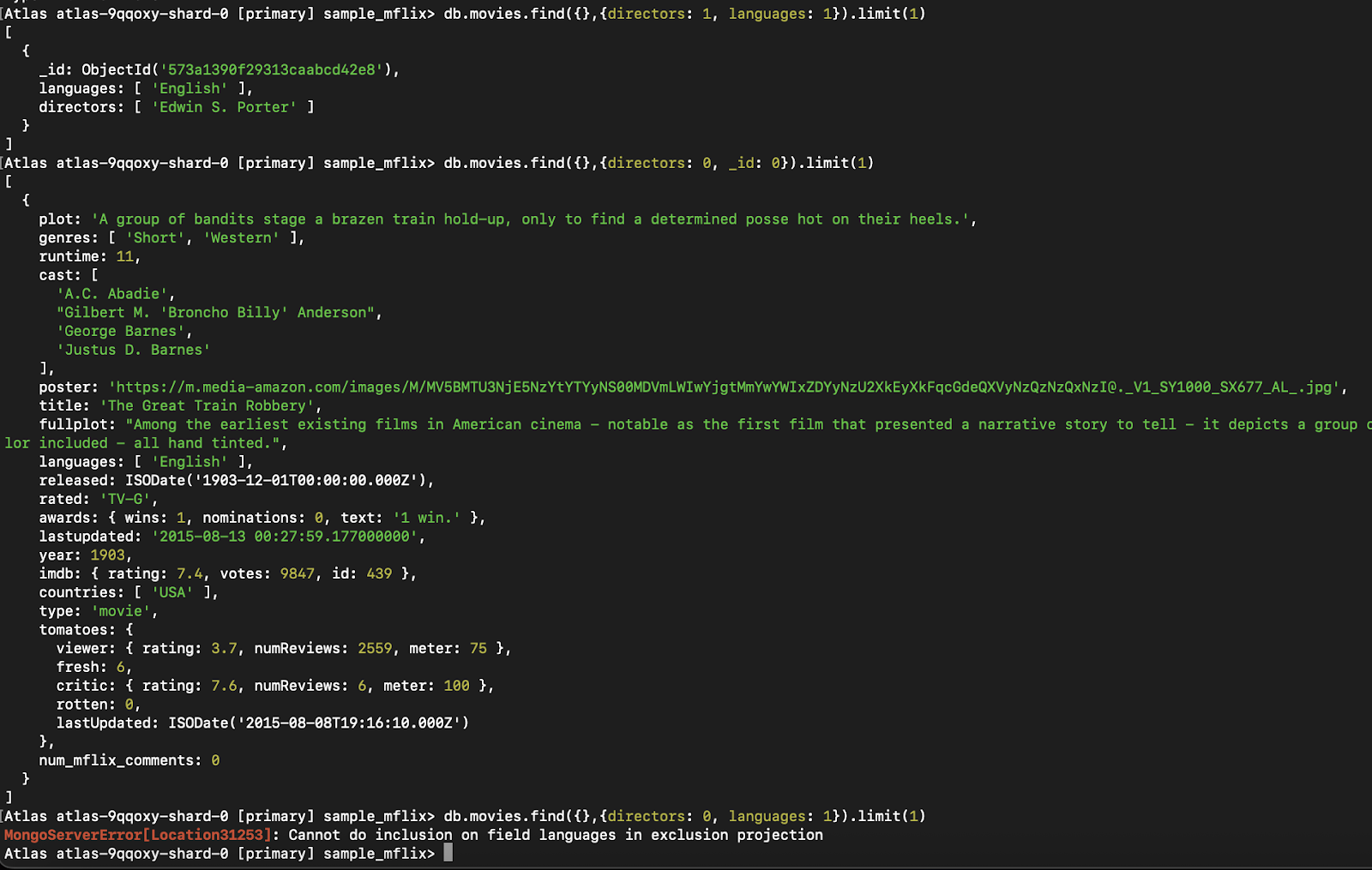
Figura 4. Este ejemplo demuestra el error que se produce al mezclar la inclusión y la exclusión de campos en una misma proyección, algo que MongoDB no permite, excepto para `_id`.
Cuando se trabaja con grandes conjuntos de datos, es habitual mostrar a los usuarios sólo una parte de los datos cada vez, una técnica conocida como paginación. Por ejemplo, una aplicación de streaming podría mostrar 10 películas por página en lugar de cargar miles a la vez. Esto no sólo mejora el rendimiento, sino que también mejora la experiencia del usuario.
En MongoDB, la paginación se consigue mediante una combinación de sort(), limit(), y skip().
Si vienes de un entorno SQL, he aquí cómo se comparan los conceptos comunes de paginación:
Consulta básica en SQL:
SELECT * FROM movies WHERE year >= 2000Lo mismo puede expresarse en MongoDB de la siguiente manera:
db.movies.find({ year: { $gte: 2000 } })Selección de campos en SQL:
SELECT title, year FROM moviesSelección de campos en MongoDB:
db.movies.find({}, { title: 1, year: 1, _id: 0 })Veamos ahora algunos ejemplos más de operaciones de consulta habituales:
Clasificación:
ORDER BY title ASC.sort({ title: 1 })Limitante:
LIMIT 10.limit(10)Saltar:
OFFSET 10.skip(10)Comprender estos paralelismos puede ayudar a los usuarios de SQL a realizar la transición más fácilmente al sistema de consulta basado en documentos de MongoDB.
La clasificación te ayuda a organizar los resultados en función de un campo concreto; por ejemplo, para ordenar las películas por título en orden alfabético:
db.movies.find().sort({ title: 1 }) // ascending (A–Z)1 significa orden ascendente (A-Z, 0-9)-1 significa orden descendente (Z-A, 9-0)Devuelve sólo un determinado número de resultados; por ejemplo, los 10 primeros:
db.movies.find().limit(10)Esto es útil cuando se implementan listas de los "10 mejores" o vistas iniciales.
Utilízalo para omitir documentos. Suele utilizarse con limit() para la paginación:
db.movies.find().skip(10).limit(10)Esto omite los 10 primeros documentos y devuelve los 10 siguientes, mostrando efectivamente la Página 2 cuando pageSize = 10.
Fórmula de paginación:
skip = (pageNumber - 1) * pageSize> Nota: Utilizar skip() para una paginación profunda (por ejemplo, skip(10000)) puede ser ineficaz, ya que MongoDB sigue escaneando y descartando los documentos omitidos. Para mejorar el rendimiento con grandes conjuntos de datos, considera la paginación basada en rangos utilizando campos indexados como _id.
db.movies.find()
.sort({ title: 1 })
.skip(20)
.limit(10)Este patrón también es útil para funciones como "cargar más" o desplazamiento infinito.
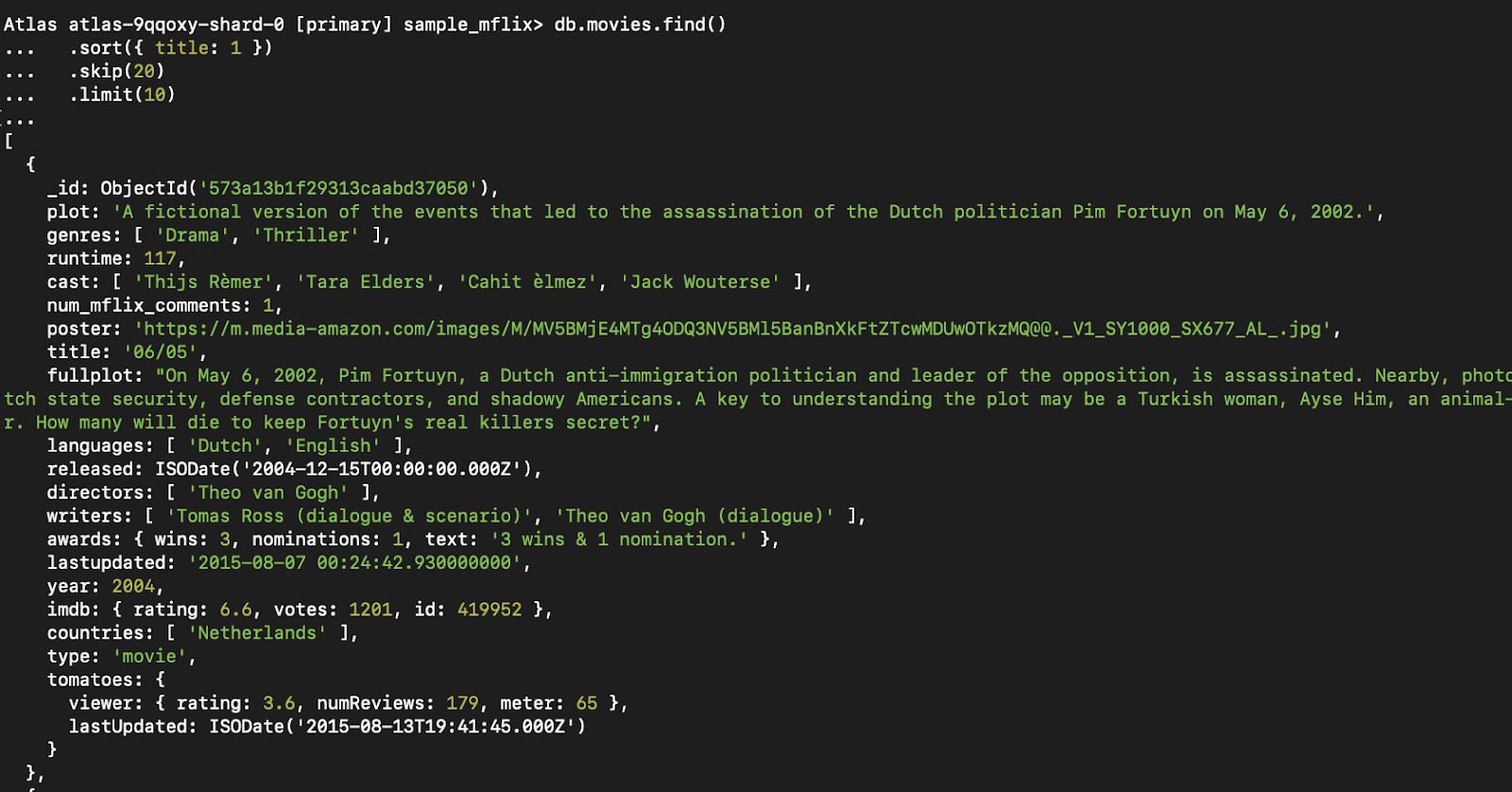
Figura 5. Esta consulta recupera la tercera página de resultados (10 películas por página), ordenadas por título.
El método find() devuelve un cursor, un puntero al conjunto de resultados. Puedes iterar sobre ella:
const cursor = db.movies.find({ type: "movie" });
cursor.forEach(doc => print(doc.name));O conviértelo en un arreglo:
const results = db.collection.find().toArray();
Figura 6. Después de llamar a `find()`, recibes un cursor. Puedes utilizarlo para iterar sobre los documentos o convertir el conjunto completo de resultados en un arreglo.
> Nota: El objeto cursor está disponible en mongosh o en código a través de controladores (por ejemplo, Node.js, Python). Las herramientas GUI como MongoDB Compass manejan los cursores internamente. No accederás a ellos ni iterarás sobre ellos directamente.
Para afinar tus consultas, puedes utilizar métodos de cursor adicionales:
db.users.find({ age: { $gte: 30 } })
.sort({ name: 1 })
.limit(10)
.skip(5)
.maxTimeMS(200)
.hint({ age: 1 })maxTimeMS(ms)aborta la consulta si tarda demasiado tiempohint(): obliga a MongoDB a utilizar un índice específicobatchSize(n): controla el número de documentos por lote¿Preparándote para las entrevistas? Explora tas 25 Mejores Preguntas y Respuestas de Entrevistas sobre MongoDB para poner a pruebatu comprensión de conceptos básicos como find().
Los índices son como hojas de trucos: ayudan a MongoDB a recuperar documentos más rápidamente.
db.movies.createIndex({ type: 1 })db.users.find({ type: "movie" }).explain()Esto revela si se están utilizando índices y la eficacia de tu consulta.
Sin índice: 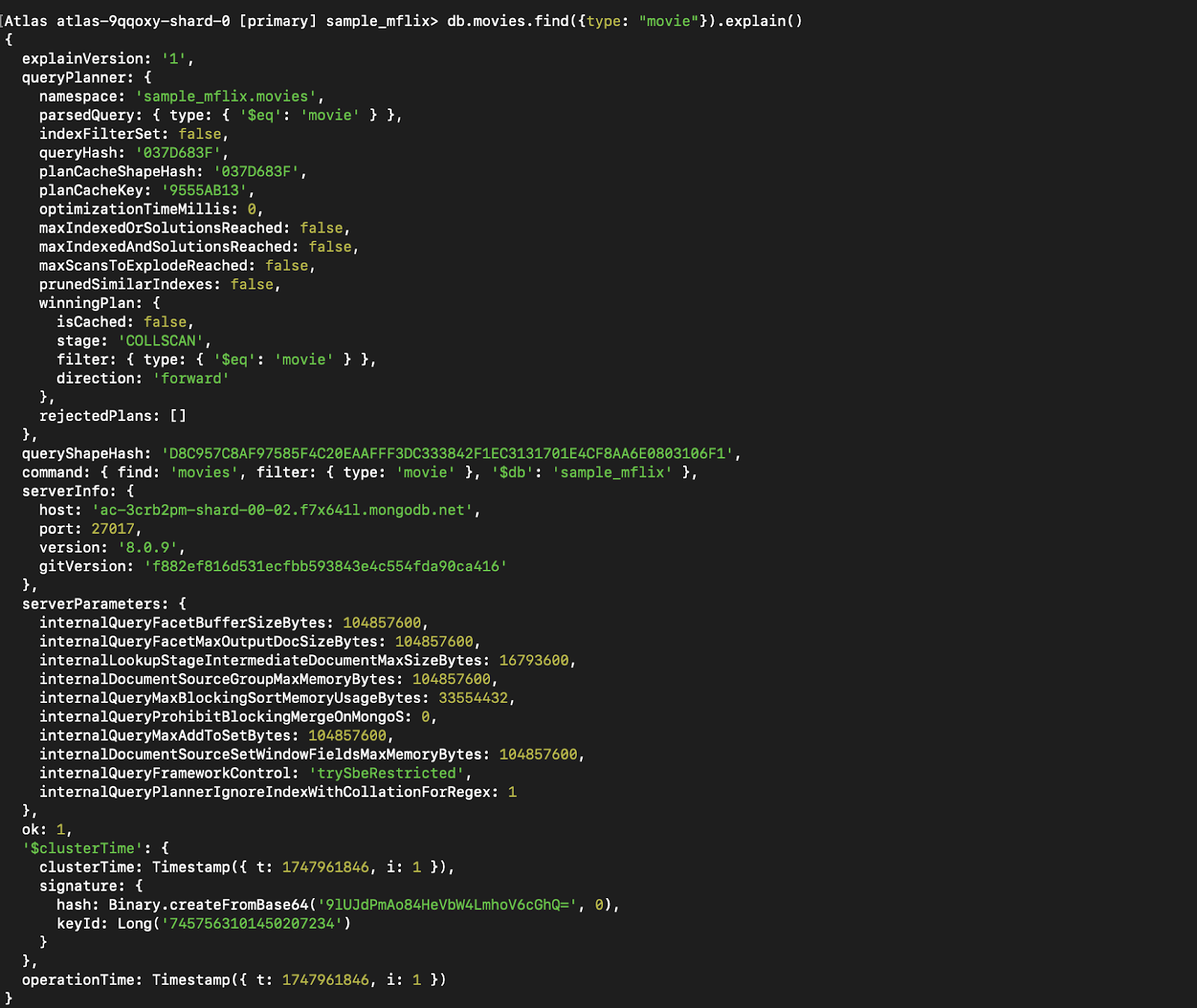
Figura 7. Ejecuta `explain()` en la consulta antes de indexarla.
Crear un índice:
![]()
Figura 8. Crea un índice simple en el campo tipo.
Con índice:
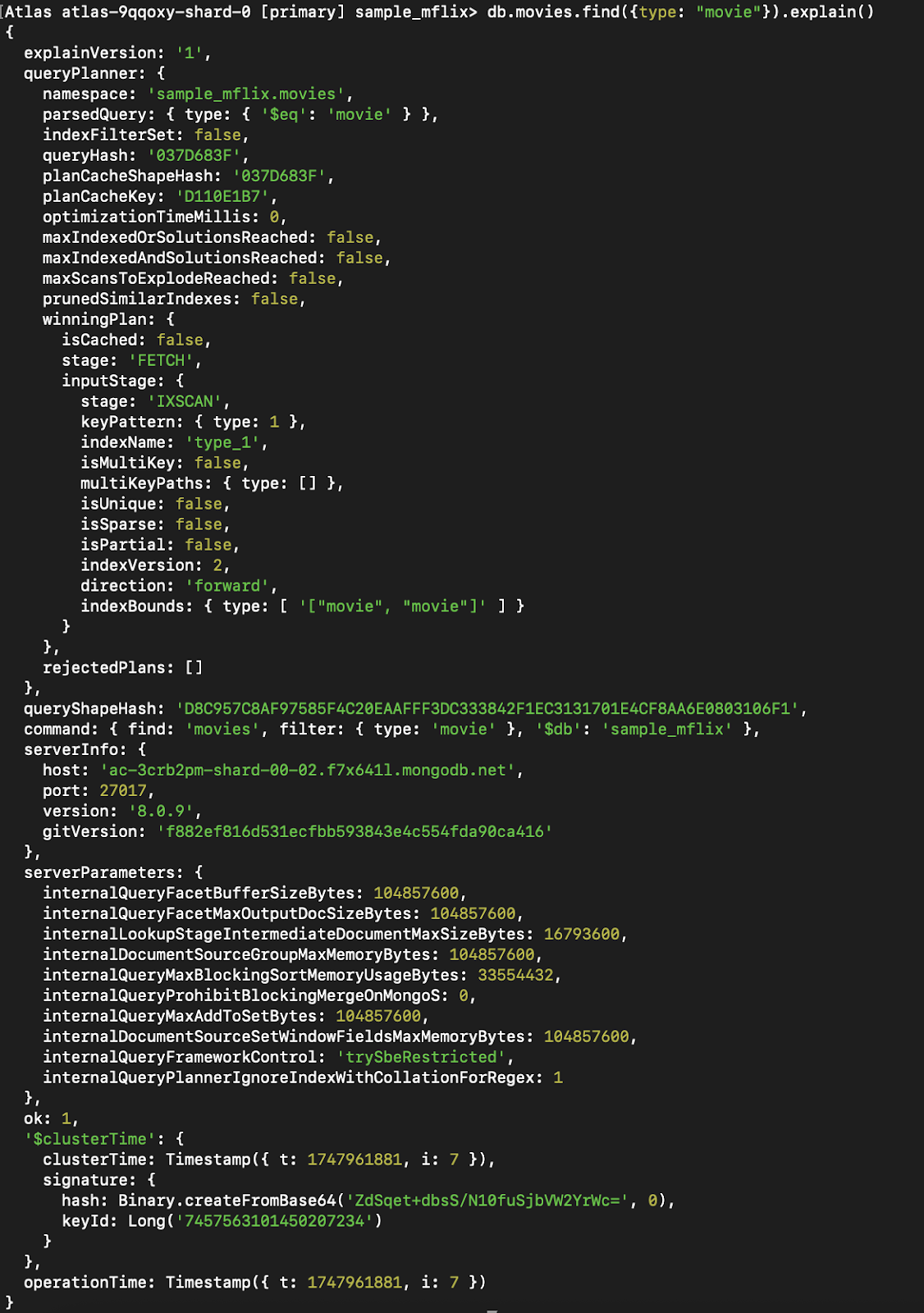
Figura 9. Ejecuta la misma consulta con `explain()`, ahora utilizando un índice.
Puedes ver que la etapa que antes era CollScan (escanear la colección) se ha convertido en Fetch + IXSCAN, que es básicamente utilizar el índice + buscar otros datos que no forman parte del índice (ya que estamos devolviendo todo).
Si prefieres herramientas visuales, MongoDB Compass es el cliente GUI oficial. Te permite:
Incluso puedes cambiar a la "vista JSON" para copiar/pegar consultas en tu código.
Si utilizas MongoDB Atlas, puedes aprovechar Atlas Search con el constructor de consultas potenciado por IA.
Sólo tienes que escribir un mensaje en lenguaje natural como
"Muéstrame todos los clientes de Brasil que hicieron pedidos superiores a 100 dólares en el último mes".
Atlas sugiere una consulta MongoDB coincidente utilizando find() o $search. Es un excelente potenciador de la productividad, sobre todo cuando no estás seguro de la sintaxis.
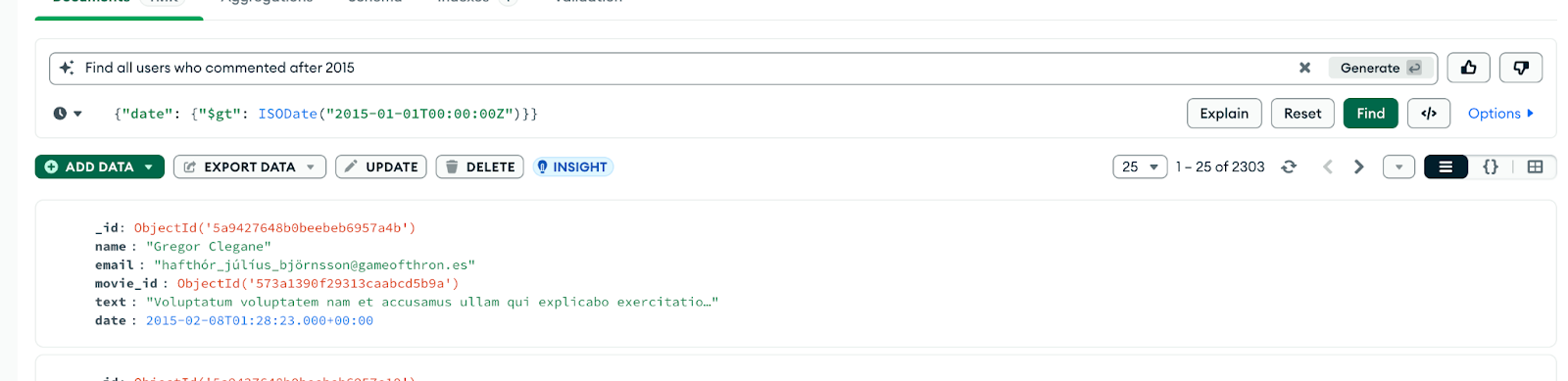
Figura 10. Utiliza Compass para generar una consulta a partir de un lenguaje natural.
limit + skip )_idSi vienes de un entorno SQL, comprender cómo se compara el find() de MongoDB con las consultas SQL conocidas puede facilitar la transición. He aquí una comparación general de operaciones comunes:
|
Concepto |
Ejemplo SQL |
Equivalente de MongoDB |
|
Consulta básica |
|
|
|
Selección de campo |
|
|
|
Clasificación |
|
|
|
Limitar |
|
|
|
Saltar |
|
|
Como puedes ver, la sintaxis de MongoDB es más parecida a JavaScript y expresiva en formato JSON, mientras que SQL es más declarativa y estructurada. Conocer estos paralelismos te ayudará a sentirte como en casa más rápidamente en MongoDB.
find() como tu filtro de datos: combina condiciones para obtener resultados precisos.Tanto si estás construyendo un panel de control para una startup, una herramienta de análisis de datos o un back-end de comercio electrónico, dominar find() hará que tu experiencia con MongoDB sea más fluida, rápida y eficaz.
Permanece atento a los próximos artículos sobre MongoDB.
¿Quieres validar tus conocimientos de MongoDB? Lee la Guía completa de la certificación MongoDB para explorar tus opciones.
¡Aprende más sobre MongoDB y las bases de datos con estos cursos!
Curso
Curso
Curso
blog
Tim Lu
12 min
blog
Kurtis Pykes
11 min
Tutorial
Sejal Jaiswal
Tutorial
Eugenia Anello
Tutorial
Tim Lu