
Lernpfad
Wissenschaftler für maschinelles Lernen in Python
85 Std.
Du hast also ein Modell in PyTorch trainiert, aber dein Produktionssystem läuft mit TensorFlow. Musst du alles von Grund auf neu schreiben?
Nein, das musst du nicht.
Die Interoperabilität von Modellen kann Machine-Learning-Ingenieuren echt Kopfzerbrechen bereiten. Verschiedene Frameworks haben unterschiedliche Formate, und wenn du zwischen diesen Formaten hin und her konvertierst, kann das dein Modell kaputt machen oder zu unerwarteten Problemen führen. Das willst du nicht, aber du willst auch nicht mehrere Versionen desselben Modells verwalten.
ONNX (Open Neural Network Exchange) löst dieses Problem, indem es ein universelles Format für Modelle des maschinellen Lernens bereitstellt. Damit kannst du in einem Framework trainieren und in einem anderen bereitstellen, ohne Code umschreiben oder dich mit Bugs rumschlagen zu müssen.
In diesem Artikel zeige ich dir, wie du Modelle ins ONNX-Format umwandelst, Inferenz mit ONNX Runtime durchführst, Modelle für die Produktion optimierst und sie auf verschiedenen Plattformen, von Edge-Geräten bis hin zu Cloud-Servern, einsetzt.
Du kannst ONNX nicht nutzen, ohne vorher deine Entwicklungsumgebung einzurichten.
In diesem Abschnitt zeige ich dir alles, was du brauchst – von den Softwareanforderungen bis hin zur Einrichtung eines übersichtlichen, reproduzierbaren Arbeitsbereichs. Ich zeige dir, wie du ONNX und ONNX Runtime unter Windows, Linux und macOS installierst.
ONNX läuft auf allen gängigen Betriebssystemen.
Du musst Python 3.8 oder höher auf deinem Rechner installiert haben. Das war's schon mit den Grundlagen. ONNX unterstützt die Python-Schnittstelle „ ABI3 “ (Application Binary Interface), was bedeutet, dass du vorgefertigte Binärpakete verwenden kannst, ohne sie aus dem Quellcode kompilieren zu müssen.
Das wirst du installieren:
uv (Hol es dir unter astral.sh/uv)
Python 3.8+ (uv ) kümmert sich für dich darum.
pip (im Lieferumfang enthalten uv)
Wenn du mehr darüber erfahren möchtest, wie uv funktioniert und warum es deine erste Wahl sein sollte, lies unseren Leitfaden zum schnellsten Python-Paketmanager.
Windows-Nutzer können uv über PowerShell installieren:
powershell -c "irm <https://astral.sh/uv/install.ps1> | iex"Wenn du einen Fehler bei der Ausführungsrichtlinie bekommst, starte PowerShell erst mal als Administrator.
Linux-Nutzer können uv mit diesem shell-Befehl installieren:
curl -LsSf <https://astral.sh/uv/install.sh> | shDas klappt auf jeder Linux-Distribution.
Endlich können macOS-Nutzer „ uv “ über Homebrew oder mit einem Curl-Befehl installieren:
brew install uv
# or
curl -LsSf <https://astral.sh/uv/install.sh> | shSo richtest du ein Projekt mit UV ein:
mkdir onnx-project
cd onnx-project
# Initialize a uv project with Python 3.10
uv init --python 3.13uv erstellt ein Verzeichnis namens „ .venv “ und eine Datei namens „ pyproject.toml “. Die virtuelle Umgebung startet automatisch, wenn du Befehle über uv ausführst.
Jetzt installierst du ONNX und ONNX Runtime:
uv add onnx onnxruntime
# Verify the installation
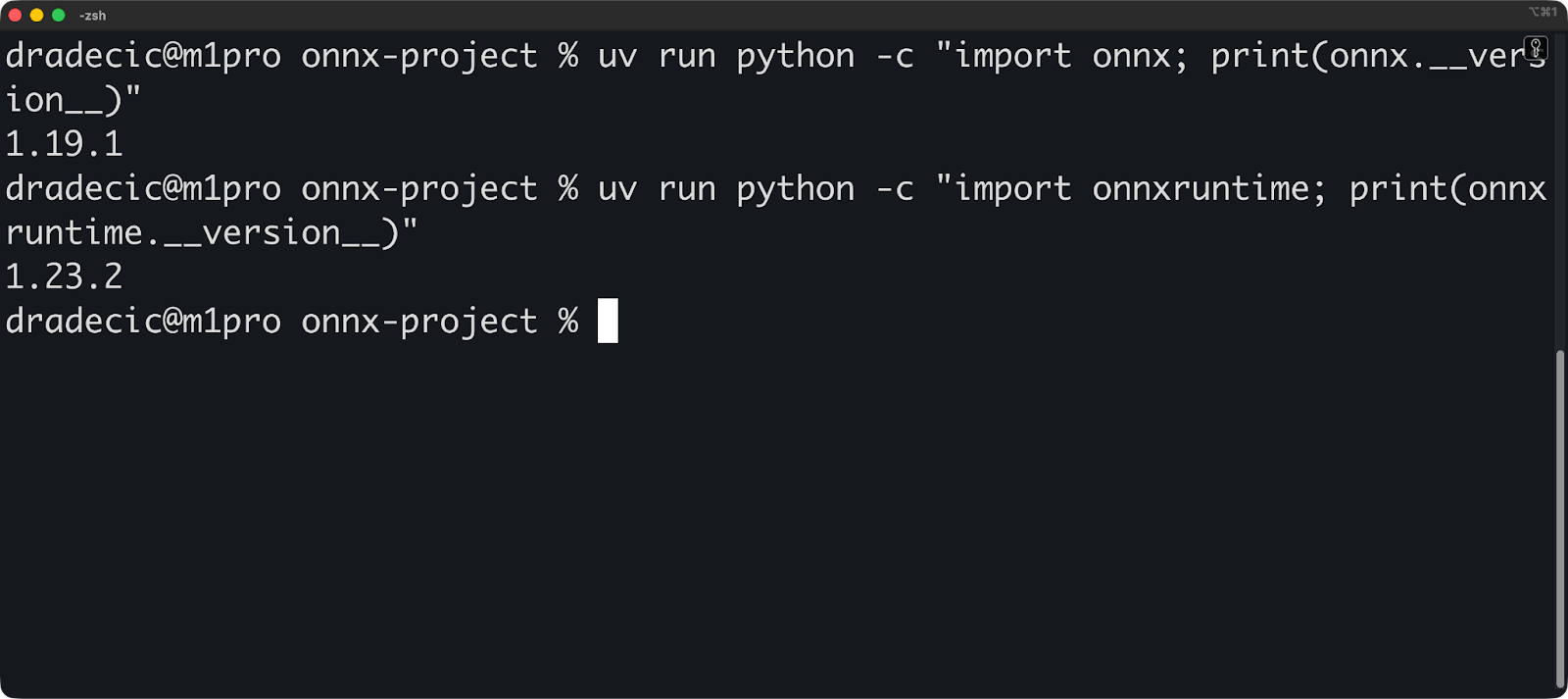
uv run python -c "import onnx; print(onnx.__version__)"
uv run python -c "import onnxruntime; print(onnxruntime.__version__)"Die Verifizierungsbefehle sollten Versionsnummern anzeigen:
Deine Abhängigkeiten sind schon fixiert. uv schreibt automatisch alle Paketversionen in uv.lock. Dadurch werden deine Builds reproduzierbar – jeder kann deine Umgebung genau nachbauen, indem er „ uv sync “ ausführt.
So sieht dein „ pyproject.toml ” aus:
[project]
name = "onnx-project"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"onnx>=1.19.1",
"onnxruntime>=1.23.2",
]Und das war's schon, die Umgebung ist fertig eingerichtet! Kommen wir zu den Grundlagen.
Bevor du mit der Konvertierung von Modellen anfängst, solltest du wissen, wie ONNX funktioniert.
In diesem Abschnitt werde ich das ONNX-Format genauer anschauen und seine graphbasierte Architektur erklären. Ich zeig dir mal, was in einer ONNX-Datei drin ist und wie die Daten da durchlaufen.
Ein ONNX-Modell ist eine Datei, die die Struktur und Gewichte deines neuronalen Netzwerks enthält.
Sieh es einfach als einen Entwurf. Die Datei sagt dir, welche Vorgänge in welcher Reihenfolge und mit welchen Parametern gemacht werden sollen. Deine trainierten Gewichte werden zusammen mit diesem Entwurf gespeichert, sodass das Modell ohne zusätzliche Dateien einsatzbereit ist.
ONNX wurde 2017 als Zusammenarbeit zwischen Microsoft und Facebook (jetzt Meta) gestartet. Das Ziel war einfach: Man wollte nicht mehr jedes Mal, wenn man das Framework wechselte, die Modelle neu schreiben müssen. PyTorch, TensorFlow und andere Frameworks wurden immer besser, aber Modelle konnten nicht ohne manuelle Konvertierung zwischen ihnen verschoben werden.
ONNX hat das geändert. Version 1.0 hat die grundlegenden Funktionen für Computer Vision und einfache neuronale Netze unterstützt. Das heutige ONNX unterstützt Transformatoren, große Sprachmodelle und komplexe Architekturen, die es 2017 noch nicht gab.
Es nutzt Protocol Buffers (protobuf), um diese Daten zu serialisieren. Protobuf ist ein Binärformat, das von Google für die effiziente Speicherung und Übertragung von Daten entwickelt wurde. Es ist viel schneller zu lesen und zu schreiben als JSON oder XML, und die Dateien sind kleiner. Win-Win-Situation.
Hier ist, was in einem ONNX-Modell drin ist:
Die Opset-Version ist wichtig. ONNX entwickelt sich ständig weiter, es kommen immer neue Funktionen dazu und die alten werden verbessert. Deine Modelldatei sagt, welche Opset-Version sie benutzt, damit die Laufzeit weiß, wie sie ausgeführt werden soll.
ONNX zeigt dein Modell als Berechnungsgraphen.
Ein Graph hat Knoten und Kanten. Knoten sind Operationen (wie Matrixmultiplikation oder Aktivierungsfunktionen), und Kanten sind Tensoren (deine Daten), die zwischen diesen Operationen fließen. So beschreibt ONNX „diese Matrizen multiplizieren, dann ReLU anwenden, dann erneut multiplizieren“.
Hier ist ein einfaches Beispiel:
import onnx
from onnx import helper, TensorProto
# Create input and output tensors
input_tensor = helper.make_tensor_value_info(
"input", TensorProto.FLOAT, [1, 3, 224, 224]
)
output_tensor = helper.make_tensor_value_info("output", TensorProto.FLOAT, [1, 1000])
# Create a node (operation)
node = helper.make_node(
"Relu", # Operation type
["input"], # Input edges
["output"], # Output edges
)
# Create the graph
graph = helper.make_graph(
[node], # List of nodes
"simple_model", # Graph name
[input_tensor], # Inputs
[output_tensor], # Outputs
)
# Create the model
model = helper.make_model(graph)
onnx.save(model, "simple_model.onnx")
Jeder Knoten macht eine Sache. Der Operationstyp (wie Relu, Conv oder MatMul) kommt aus dem ONNX-Operatorsatz. Du kannst dir nicht einfach irgendwelche Operationsnamen ausdenken – sie müssen in der von dir verwendeten Opset-Version vorhanden sein.
Kanten verbinden Knoten und transportieren Tensoren. Ein Tensor hat eine Form und einen Datentyp. Wenn du „ [1, 3, 224, 224] “ definierst, sagst du damit: „Dieser Tensor hat vier Dimensionen mit diesen Größen.“ Die Laufzeit nutzt diese Infos, um Speicher zuzuweisen und den Graphen zu überprüfen.
Der Graph fließt in eine Richtung. Die Daten kommen über Eingabeknoten rein, werden verarbeitet und gehen dann über Ausgabeknoten raus. Keine Zyklen erlaubt – ONNX unterstützt keine wiederkehrenden Verbindungen direkt. Du musst Schleifen entrollen oder spezielle Operationen für Sequenzen verwenden.
Diese Grafikstruktur macht es möglich, dass verschiedene Frameworks zusammenarbeiten können. PyTorch arbeitet mit Eager Execution, TensorFlow nutzt statische Graphen und scikit-learn hat eine ganz andere Abstraktion. Aber sie können alle ins gleiche Grafikformat exportieren.
Der Graph ermöglicht auch eine gemeinsame Optimierung. Ein ONNX-Optimierer kann Operationen zusammenfassen (mehrere Knoten zu einem kombinieren), ungenutzten Code entfernen (nicht verwendete Knoten löschen) oder langsame Operationen durch schnellere ersetzen. Diese Optimierungen funktionieren unabhängig davon, mit welchem Framework das Modell erstellt wurde.
Als Nächstes zeige ich dir, wie du Modelle ins ONNX-Format umwandelst.
In diesem Abschnitt zeige ich dir, wie du Modelle aus PyTorch, TensorFlow und scikit-learn exportieren kannst. Ich zeige dir, wie die Konvertierung läuft und wie du nach der Konvertierung checken kannst, ob dein Modell richtig funktioniert.
ONNX unterstützt die gängigsten Frameworks für maschinelles Lernen.
PyTorch hat einen eingebauten ONNX-Export über torch.onnx.export(). Das ist der ausgereifteste Konverter, weil sowohl PyTorch als auch ONNX von Meta gepflegt werden.
TensorFlow nutzt tf2onnx für die Konvertierung. Das ist 'ne separate Bibliothek, die TensorFlow-Graphen ins ONNX-Format umwandelt. Installiere es mit „ uv add tf2onnx “ und schon kann es losgehen.
scikit-learn konvertiert über skl2onnx. Diese Bibliothek unterstützt klassische Modelle des maschinellen Lernens wie Random Forests, lineare Regression und SVMs. Deep-Learning-Frameworks kriegen mehr Aufmerksamkeit, aber scikit-learn-Modelle funktionieren genauso gut.
Diese drei sind die beliebtesten, aber du kannst auch jedes andere unterstützte Framework verwenden – installiere einfach die Abhängigkeit über uv add :
Keras: Benutze „ tf2onnx “ (Keras ist Teil von TensorFlow).
XGBoost: Benutzen onnxmltools
LightGBM: Benutzen onnxmltools
MATLAB: Integrierter ONNX-Export
Paddel: Benutzen paddle2onnx
Jedes Framework hat seinen eigenen Konverter, weil sie Modelle unterschiedlich darstellen. PyTorch nutzt dynamische Berechnungsgraphen, TensorFlow nutzt statische Graphen und scikit-learn nutzt überhaupt keine Graphen. Die Konverter machen diese Darstellungen ins ONNX-Graphenformat um.
Du kannst auch Modelle nutzen, die von anderen trainiert wurden. DerONNX Model Zoo „ “ hat schon trainierte Modelle, die du direkt nutzen kannst. Du findest Computer-Vision-Modelle (ResNet, YOLO, EfficientNet), NLP-Modelle (BERT, GPT-2) und vieles mehr. Lade sie einfach aus dem offiziellen GitHub-Repository runter.
Hugging Face hat auch ONNX-Modelle. Such nach Modellen mit „onnx” im Namen oder filter nach dem ONNX-Format. Viele beliebte Transformator-Modelle sind im ONNX-Format verfügbar und schon für die Inferenz optimiert.
Bevor du weitermachst, führe diesen Befehl aus, um alle benötigten Bibliotheken mit uv zu holen:
uv add torch torchvision tensorflow tf2onnx scikit-learn skl2onnx onnxscriptSo konvertierst du ein PyTorch-Modell in ONNX:
import torch
import torch.nn as nn
# Define a simple model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 5)
def forward(self, x):
return self.fc(x)
# Create and prepare the model
model = SimpleModel()
model.eval() # Set to evaluation mode
# Create dummy input with the same shape as your real data
dummy_input = torch.randn(1, 10)
# Export to ONNX
torch.onnx.export(
model, # Model to export
dummy_input, # Example input
"simple_model.onnx", # Output file
input_names=["input"], # Name for the input
output_names=["output"], # Name for the output
dynamic_shapes={"x": {0: "batch_size"}}, # Allow variable batch size
)Neu bei PyTorch? Lass dich davon nicht aufhalten. Unser Kurs „Deep Learning mit PyTorch” bringt dir die Grundlagen in ein paar Stunden bei.
Der Dummy-Input ist wichtig. ONNX muss die Eingabeform kennen, um den Graphen zu erstellen. Wenn dein Modell Sequenzen mit variabler Länge oder unterschiedliche Batchgrößen akzeptiert, markiere diese Dimensionen mit „ dynamic_shapes ” als dynamisch.
Stell dein Modell vor dem Export immer auf den Bewertungsmodus „ “ mit „ model.eval() “ ein. Das deaktiviert das Training mit Dropout und Batch-Normalisierung. Wenn du diesen Schritt vergisst, passt dein konvertiertes Modell nicht zum Original.
Dynamische Formen machen Probleme. Wenn dein Konverter wegen unbekannter Abmessungen Probleme macht, stell sicher, dass du „ dynamic_shapes “ richtig angibst oder konkrete Formen angibst.
Jetzt zu TensorFlow: Hier ist ein alternativer Code, den du ausführen kannst:
import numpy as np
# Temporary compatibility fixes for tf2onnx
if not hasattr(np, "object"):
np.object = object
if not hasattr(np, "cast"):
np.cast = lambda dtype: np.asarray
import tensorflow as tf
import tf2onnx
# Define a simple Keras model (same spirit as your PyTorch one)
inputs = tf.keras.Input(shape=(10,), name="input")
outputs = tf.keras.layers.Dense(5, name="output")(inputs)
model = tf.keras.Model(inputs, outputs)
# Save the model (optional, if you want a .h5 file)
model.save("simple_tf_model.h5")
# Define a dynamic input spec (None = dynamic batch dimension)
spec = (tf.TensorSpec((None, 10), tf.float32, name="input"),)
# Convert to ONNX
model_proto, _ = tf2onnx.convert.from_keras(
model, input_signature=spec, output_path="simple_tf_model.onnx"
)Wenn du noch nie mit TensorFlow gearbeitet hast, empfehlen wir dir, unseren Kurs „Einführung in TensorFlow in Python“ zu besuchen.
Leider gibt's ein kleines Problem mit der neuesten Version von Numpy, also hab ich eine vorübergehende Lösung eingebaut. Wenn du das hier liest, kannst du den Code hoffentlich ohne die ersten sechs Zeilen ausführen.
Und zum Schluss schauen wir uns die ONNX-Konvertierung für scikit-learn-Modelle an:
from sklearn.ensemble import RandomForestClassifier
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Train a simple model
model = RandomForestClassifier(n_estimators=10)
model.fit(X_train, y_train)
# Define input type and shape
initial_type = [('float_input', FloatTensorType([None, 4]))]
# Convert to ONNX
onnx_model = convert_sklearn(model, initial_types=initial_type)
# Save the model
with open("sklearn_model.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())Ähnlich wie TensorFlow hat auch DataCamp einen kostenlosen Kurs zum Thema „Supervised Learning with scikit-learn” – schau ihn dir an, wenn du den obigen Ausschnitt verwirrend findest.
Das war's schon!
Du kannst jetzt diesen Codeausschnitt ausführen, um dein konvertiertes Modell zu überprüfen:
import onnx
import onnxruntime as ort
import numpy as np
# Load and check the ONNX model
onnx_model = onnx.load("simple_model.onnx")
onnx.checker.check_model(onnx_model)
# Run inference with ONNX Runtime
session = ort.InferenceSession("simple_model.onnx")
input_name = session.get_inputs()[0].name
# Create test input
test_input = np.random.randn(1, 10).astype(np.float32)
# Get prediction
onnx_output = session.run(None, {input_name: test_input})
# Compare with original model
with torch.no_grad():
original_output = model(torch.from_numpy(test_input))
# Check if outputs match (within floating point tolerance)
np.testing.assert_allclose(
original_output.numpy(),
onnx_output[0],
rtol=1e-3,
atol=1e-5
)
print("Model conversion successful - outputs match!")
Mach diese Überprüfung jedes Mal, wenn du ein Modell umwandelst. Kleine numerische Unterschiede sind okay (Fließkomma-Mathematik ist nicht immer exakt), aber große Unterschiede deuten darauf hin, dass bei der Konvertierung was schiefgelaufen ist.
Zum Schluss noch zwei wichtige Hinweise, die du beachten solltest:
Als Nächstes schauen wir uns ONNX Runtime an.
In diesem Abschnitt zeige ich dir, wie du mit ONNX Runtime Modelle laden und Vorhersagen treffen kannst. Ich zeige dir die Optionen für die Hardwarebeschleunigung und wo ONNX Runtime in der Produktion richtig gut ist.
ONNX Runtime ist eine plattformübergreifende Inferenz-Engine. Microsoft hat es entwickelt, damit ONNX-Modelle auf jeder Hardware schnell laufen – egal ob CPUs, GPUs, mobile Chips oder spezielle KI-Beschleuniger.
So geht's: Du lädst ein ONNX-Modell, und ONNX Runtime erstellt einen Ausführungsplan. Es checkt den Rechengraphen, macht Optimierungen und findet den besten Weg, um die Vorgänge auf deiner Hardware durchzuführen. Dann macht es die Schlussfolgerung mit dem optimierten Plan.
Die Architektur trennt die Ausführungslogik vom hardwarespezifischen Code. Ausführungsanbieter kümmern sich um die Hardware-Schnittstelle. Willst du auf NVIDIA-GPUs laufen? Benutze den CUDA-Ausführungsanbieter. Willst du Apple Silicon? Dein zugrunde liegender Code bleibt unverändert.
ONNX Runtime hat diese Ausführungsanbieter:
CPUExecutionProvider: Standardanbieter, funktioniert überall
CUDAExecutionProvider: NVIDIA-Grafikprozessoren mit CUDA
TensorRTExecutionProvider: NVIDIA-GPUs mit TensorRT-Optimierung
CoreMLExecutionProvider: Apple-Geräte (macOS, iOS)
DmlExecutionProvider: DirectML für Windows (funktioniert mit jeder GPU)
OpenVINOExecutionProvider: Intel-CPUs und -GPUs
ROCMExecutionProvider: AMD-Grafikkarten
Jeder Anbieter übersetzt ONNX-Operationen in Anweisungen, die speziell für die jeweilige Hardware passen. Der CPU-Anbieter nutzt Standard-CPU-Operationen. Der CUDA-Anbieter nutzt cuDNN und cuBLAS. Der TensorRT-Anbieter kompiliert dein Modell zu optimierten GPU-Kernels und so weiter.
Du kannst ein ONNX-Modell mit drei Zeilen Code laden:
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession("simple_model.onnx")
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].nameDer „ InferenceSession ” macht die ganze harte Arbeit. Es lädt das Modell, checkt den Graphen und macht alles für die Inferenz klar. Standardmäßig wird der CPU-Ausführungsanbieter benutzt.
Jetzt die Schlussfolgerung ziehen:
import numpy as np
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession("simple_model.onnx")
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
# Prepare input data
input_data = np.random.randn(1, 10).astype(np.float32)
# Run inference
outputs = session.run(
[output_name],
{input_name: input_data},
)
# Get predictions
predictions = outputs[0]
print(predictions.shape)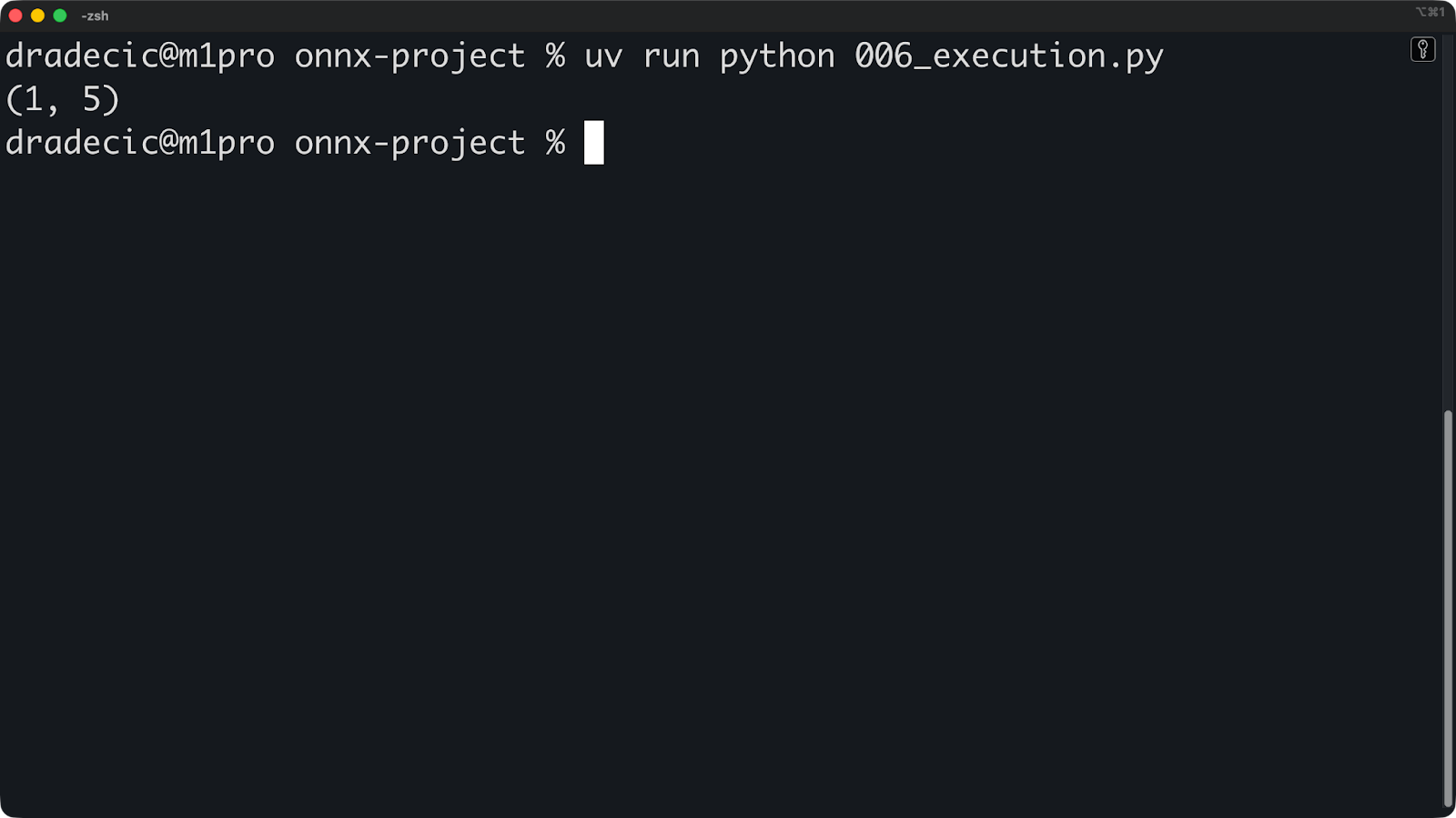
Die Methode „ run() “ braucht zwei Argumente. Zuerst mal eine Liste mit den Namen der Ausgänge (oder „ None “ für alle Ausgänge). Zweitens ein Wörterbuch, das Eingabenamen mit Numpy-Arrays verbindet.
Die Eingabeformen müssen übereinstimmen. Wenn dein Modell [1, 10] erwartet und du [1, 10, 3] übergibst, schlägt die Inferenz fehl.
Wenn du GPU-Beschleunigung willst, gib einfach beim Erstellen der Sitzung Ausführungsanbieter an:
# For NVIDIA GPUs with CUDA
session = ort.InferenceSession(
"model.onnx",
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
# For Apple Silicon
session = ort.InferenceSession(
"model.onnx",
providers=['CoreMLExecutionProvider', 'CPUExecutionProvider']
)
# For Intel hardware
session = ort.InferenceSession(
"model.onnx",
providers=['OpenVINOExecutionProvider', 'CPUExecutionProvider']
)Listen die Anbieter in der Reihenfolge ihrer Priorität auf. ONNX Runtime probiert den ersten Anbieter aus und wechselt zum nächsten, wenn der erste nicht verfügbar ist. Füge immer CPUExecutionProvider als letzte Ausweichmöglichkeit hinzu.
Du kannst nachsehen, welcher Anbieter gerade benutzt wird:
import numpy as np
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession(
"simple_model.onnx", providers=["CoreMLExecutionProvider", "CPUExecutionProvider"]
)
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
# Prepare input data
input_data = np.random.randn(1, 10).astype(np.float32)
# Run inference
outputs = session.run(
[output_name],
{input_name: input_data},
)
# Get predictions
predictions = outputs[0]
print(predictions.shape)
print("Providers:")
print(session.get_providers())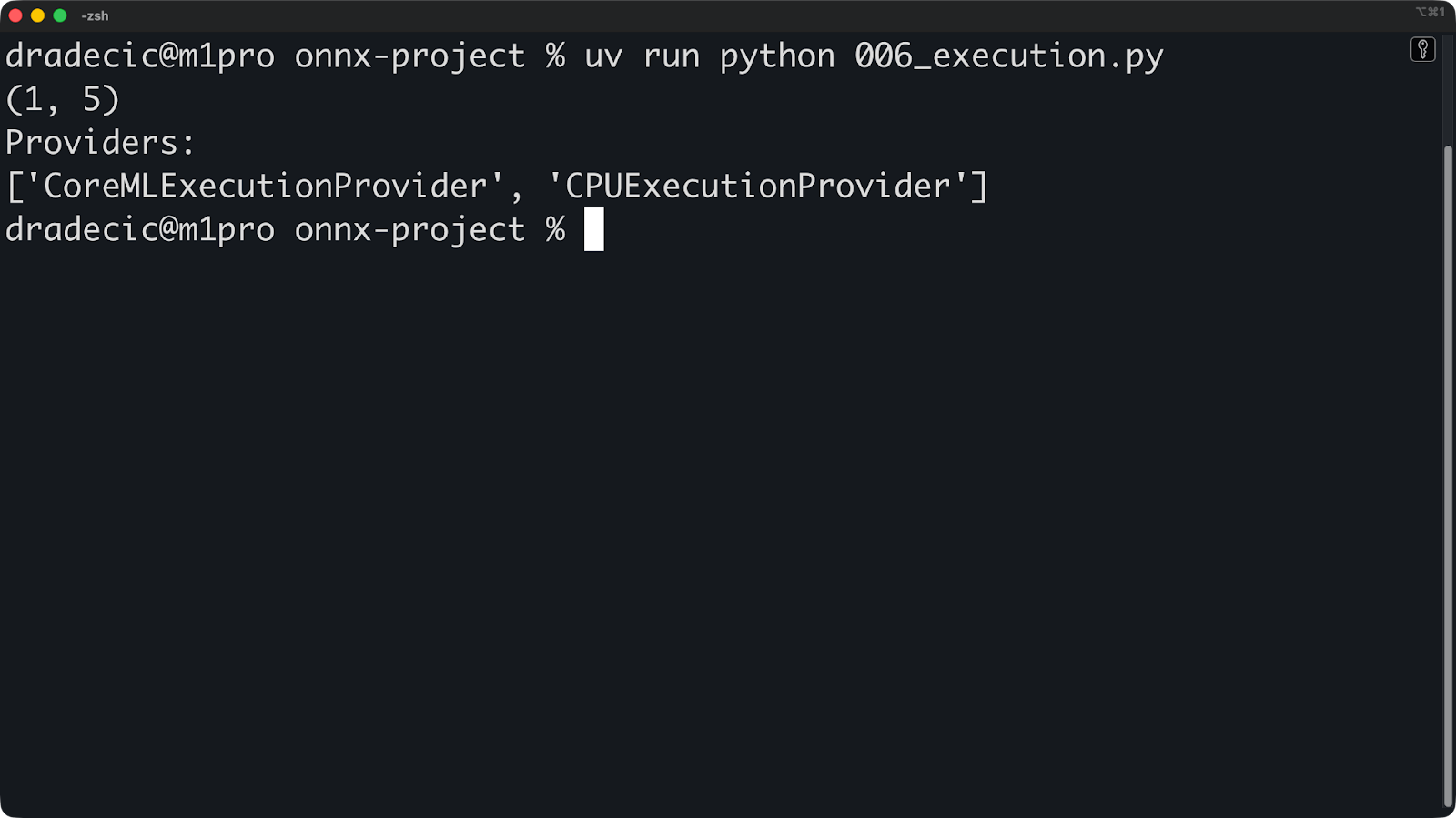
Wenn du „ ["CPUExecutionProvider"] “ siehst, obwohl du eine GPU erwartest, ist der GPU-Anbieter nicht verfügbar. Häufige Gründe könnten fehlende Treiber, ein falsches ONNX-Laufzeitpaket oder eine inkompatible GPU sein.
Die Konfiguration hört hier nicht auf. Du kannst den Ausführungsanbieter noch weiter optimieren, um eine bessere Leistung zu kriegen:
providers = [
(
"TensorRTExecutionProvider",
{
"device_id": 0,
"trt_max_workspace_size": 2147483648, # 2GB
"trt_fp16_enable": True, # Use FP16 precision
},
),
"CUDAExecutionProvider",
"CPUExecutionProvider",
]
session = ort.InferenceSession("simple_model.onnx", providers=providers)Du kannst in der offiziellen ONNX Runtime-Dokumentation nachsehen, um eine Liste aller verfügbaren Optionen für den Anbieter deiner Wahl zu bekommen.
Das Coole an ONNX Runtime ist, dass es überall läuft – auf Servern, in Browsern und auf mobilen Geräten.
ONNX Runtime Web macht Inferenz in Browsern mit WebAssembly und WebGL möglich. Dein Modell läuft auf der Client-Seite, ohne Daten an Server zu schicken. Das ist super für Anwendungen, bei denen Datenschutz wichtig ist, wie zum Beispiel bei der Analyse medizinischer Bilder oder der Verarbeitung von Dokumenten.
Hier ist ein einfaches Beispiel dafür, wie du ONNX Runtime in einer einfachen HTML-Datei nutzen kannst:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>ONNXRuntime Web Demo</title>
</head>
<body>
<h1>ONNXRuntime Web Demo</h1>
<!-- Load ONNXRuntime-Web from CDN -->
<script src="<https://cdn.jsdelivr.net/npm/onnxruntime-web/dist/ort.min.js>"></script>
<script>
async function runModel() {
// Create inference session
const session = await ort.InferenceSession.create('./simple_model.onnx');
// Prepare input
const inputData = new Float32Array(10).fill(0).map(() => Math.random());
const tensor = new ort.Tensor('float32', inputData, [1, 10]);
// Run inference
const results = await session.run({ input: tensor });
const output = results.output;
console.log('Output shape:', output.dims);
console.log('Output values:', output.data);
}
runModel();
</script>
</body>
</html>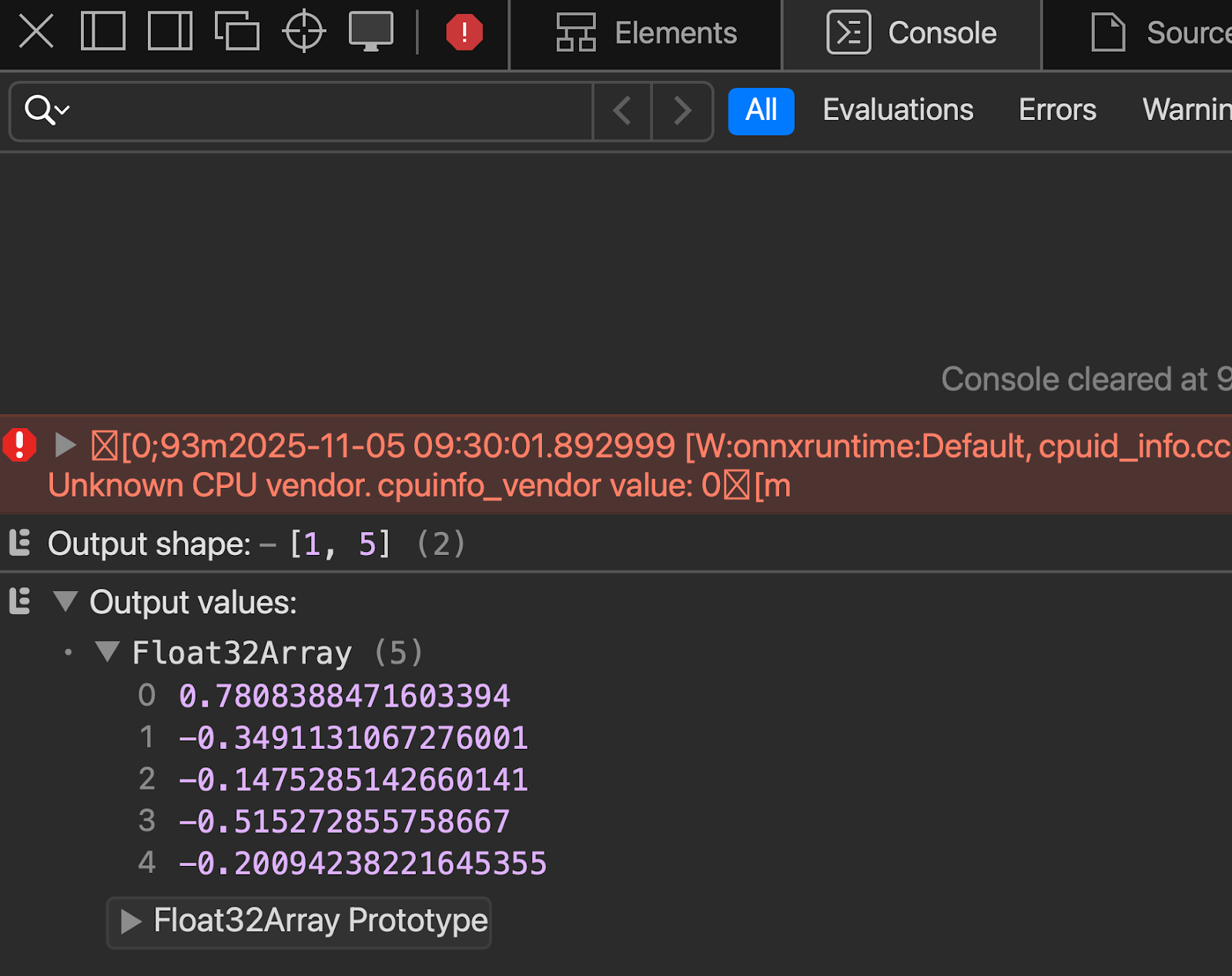
Für den Einsatz auf Mobilgeräten kannst du ONNX Runtime Mobile nutzen – eine leichte Version, die für iOS und Android optimiert ist. Es entfernt unnötige Funktionen und macht die Binärdatei kleiner.
Hier ist ein Beispiel für eine iOS-Konfiguration:
import onnxruntime_objc
let modelPath = Bundle.main.path(forResource: "simple_model", ofType: "onnx")!
let session = try ORTSession(modelPath: modelPath)
let inputData = // Your input as Data
let inputTensor = try ORTValue(tensorData: inputData,
elementType: .float,
shape: [1, 10])
let outputs = try session.run(withInputs: ["input": inputTensor])Oder wenn du Python zum Erstellen einer REST-API verwendest, kannst du ONNX Runtime wie folgt in einen deiner Endpunkte einbinden:
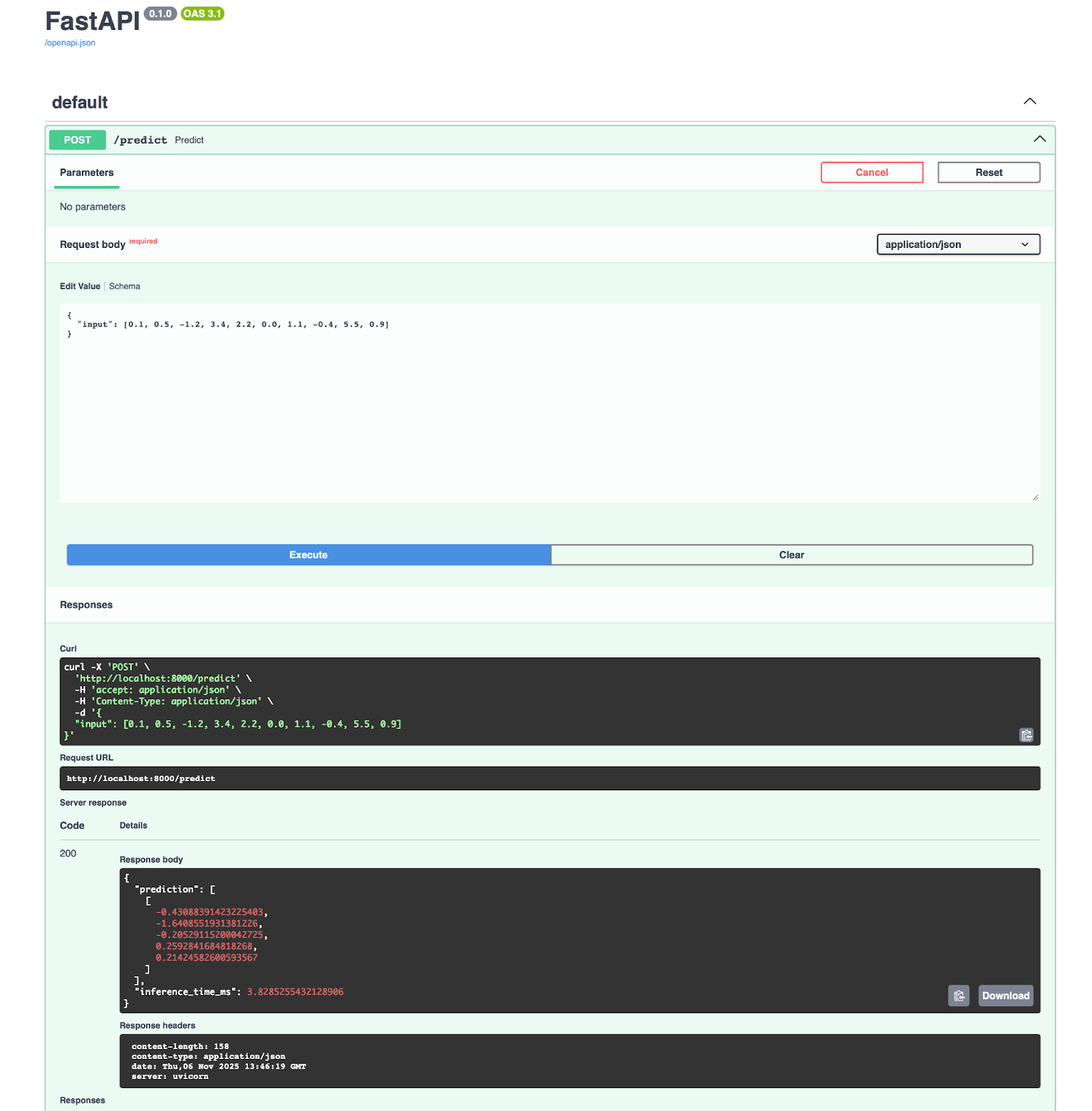
from fastapi import FastAPI
import onnxruntime as ort
import numpy as np
app = FastAPI()
session = ort.InferenceSession("simple_model.onnx")
@app.post("/predict")
async def predict(data: dict):
input_data = np.array(data["input"]).astype(np.float32)
outputs = session.run(None, {"input": input_data})
return {"prediction": outputs[0].tolist()}Das war's schon! Andere Umgebungen werden einen ähnlichen Ansatz verwenden, aber du verstehst schon, worum es geht – ONNX Runtime ist einfach zu verwenden. Als Nächstes reden wir über Optimierung.
In diesem Abschnitt zeige ich dir, wie du ONNX-Modelle durch Quantisierung und Graphenoptimierungen schneller und kleiner machen kannst. Ich zeig dir die Techniken, die für echte Einsätze am wichtigsten sind.
Quantisierung macht dein Modell weniger genau, damit es schneller und kleiner wird.
Anstatt Gewichte als 32-Bit-Gleitkommazahlen zu speichern, speicherst du sie als 8-Bit-Ganzzahlen. Das spart 75 % Speicherplatz und macht die Schlussfolgerung schneller, weil ganzzahlige Berechnungen auf den meisten Geräten schneller sind als Fließkomma-Berechnungen.
Bei der dynamischen Quantisierung werden Gewichte in eine niedrigere Genauigkeit umgewandelt, aber die Aktivierungen (Zwischenwerte während der Inferenz) bleiben in voller Genauigkeit erhalten. Das ist die einfachste Quantisierungsmethode, weil du keine Kalibrierungsdaten brauchst.
So wendest du die dynamische Quantisierung an:
from onnxruntime.quantization import quantize_dynamic, QuantType
# Quantize the model
quantize_dynamic(
model_input="model.onnx",
model_output="model_quantized.onnx",
weight_type=QuantType.QUInt8 # 8-bit unsigned integers
)Das ist alles. Dein quantisiertes Modell nutzt jetzt 8-Bit-Ganzzahlen ohne Vorzeichen und ist einsatzbereit.
Bei der statischen Quantisierung werden sowohl Gewichte als auch Aktivierungen in eine geringere Genauigkeit umgewandelt. Es ist aggressiver und schneller als die dynamische Quantisierung, aber du brauchst repräsentative Kalibrierungsdaten, um die Aktivierungsbereiche zu messen.
Hier ist eine allgemeine Strategie für die Anwendung der statischen Quantisierung:
from onnxruntime.quantization import quantize_static, CalibrationDataReader
import numpy as np
# Create a calibration data reader
class DataReader(CalibrationDataReader):
def __init__(self, calibration_data):
self.data = calibration_data
self.index = 0
def get_next(self):
if self.index >= len(self.data):
return None
batch = {"input": self.data[self.index]}
self.index += 1
return batch
# Load calibration data (100-1000 samples from your dataset)
calibration_data = [np.random.randn(1, 10).astype(np.float32)
for _ in range(100)]
data_reader = DataReader(calibration_data)
# Quantize
quantize_static(
model_input="model.onnx",
model_output="model_static_quantized.onnx",
calibration_data_reader=data_reader
)Die Kalibrierungsdaten sollten deine tatsächliche Inferenz-Arbeitslast widerspiegeln, also nimm keine zufälligen Daten, wie ich oben gezeigt habe. Benutz echte Beispiele aus deinem Datensatz.
Im Allgemeinen hat die Quantisierung ein paar Vorteile und Nachteile, die du als Machine-Learning-Ingenieur kennen solltest. Hier sind die Vorteile:
Und hier sind die Vor- und Nachteile:
Quantisierung ist auch super für große Sprachmodelle und generative KI. Ein 7B-Parametermodell in FP32 braucht 28 GB Speicherplatz. Wenn man es auf INT8 quantisiert, geht es runter auf 7 GB. Auf INT4 quantisiert sind es 3,5 GB – klein genug, um auf handelsüblicher Hardware zu laufen.
Graphenoptimierungen schreiben den Berechnungsgraphen deines Modells um, damit er schneller wird.
Das Konzept der Knotenfusion macht mehrere Vorgänge zu einem einzigen Vorgang. Wenn dein Modell eine Conv-Schicht hat, gefolgt von BatchNorm und dann ReLU, kombiniert der Optimierer sie zu einem einzigen „ ConvBnRelu ”-Knoten. Das spart Speicherplatz und macht die Ausführung schneller.
So sieht die Grafik vor der Fusion aus:
Input -> Conv -> BatchNorm -> ReLU -> OutputNach der Fusion ist es einfacher:
Input -> ConvBnRelu -> OutputEs gibt noch zwei weitere Begriffe, die du in Sachen Graphenoptimierung kennen solltest:
So kannst du Grafikoptimierungen in ONNX Runtime aktivieren:
import onnxruntime as ort
# Set optimization level
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# Create session with optimizations
session = ort.InferenceSession(
"simple_model.onnx",
sess_options,
providers=["CPUExecutionProvider"]
)ONNX Runtime hat die folgenden Optimierungsstufen:
ORT_DISABLE_ALL: Keine Optimierungen (hilfreich beim Debuggen)
ORT_ENABLE_BASIC: Sichere Optimierungen, die die numerischen Ergebnisse nicht verändern
ORT_ENABLE_EXTENDED: Aggressive Optimierungen können kleine numerische Unterschiede haben.
ORT_ENABLE_ALL: Alle Optimierungen, einschließlich Layout-Transformationen
Benutz „ ORT_ENABLE_ALL “ für die Produktion. Die Beschleunigung ist die winzigen numerischen Unterschiede wert.
Du kannst diesen Codeausschnitt ausführen, um optimierte Modelle für die Wiederverwendung zu speichern:
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
sess_options.optimized_model_filepath = "model_optimized.onnx"
# This creates and saves the optimized model
session = ort.InferenceSession("simple_model.onnx", sess_options)Die Optimierungen des Graphen funktionieren unabhängig davon, mit welchem Framework dein Modell erstellt wurde. Ein PyTorch Conv-BN-ReLU-Muster und ein TensorFlow Conv-BN-ReLU-Muster werden beide auf die gleiche Weise zusammengefügt. Das ist der Vorteil der gemeinsamen Optimierung: Du musst die Optimierung nur einmal schreiben und kannst sie dann auf Modelle aus jedem Framework anwenden.
Als Nächstes reden wir über die Bereitstellung.
In diesem Abschnitt werde ich drei Einsatzszenarien durchgehen: Edge-Geräte, Cloud-Infrastruktur und Webbrowser. Ich zeig dir die Herausforderungen und Lösungen für jede Umgebung.
Das Hauptproblem bei Edge-Geräten ist, dass sie nur begrenzte Ressourcen haben.
Dein Smartphone hat 4 bis 16 GB RAM. Ein Raspberry Pi hat sogar noch weniger. IoT-Geräte haben vielleicht 512 MB oder weniger. Du kannst nicht einfach ein 7B-Parametermodell auf diese Geräte werfen und erwarten, dass es funktioniert.
Fang mit der Quantisierung an. INT8-Modelle sollten deine Basis sein. Nimm ruhig INT4, wenn du mit dem Genauigkeitsverlust leben kannst. Dadurch wird dein Modell klein genug, um in den Speicher zu passen.
Wenn es um die Bereitstellung auf Edge-Geräten geht, ist ONNX Runtime Mobile dein Freund. Es entfernt Serverfunktionen, die du nicht brauchst, und sorgt für eine längere Akkulaufzeit. Die Binärdatei ist kleiner, der Startvorgang schneller und der Stromverbrauch niedriger.
So kannst du es zu deinem mobilen App-Projekt hinzufügen:
# iOS
pod 'onnxruntime-mobile-objc'
# Android
implementation 'com.microsoft.onnxruntime:onnxruntime-android:latest.version'Ausführungsanbieter kümmern sich um Hardware-Unterschiede. Android-Geräte nutzen ARM-CPUs, manche haben GPUs von verschiedenen Herstellern, und neuere Handys haben NPUs (Neural Processing Units). Du willst doch nicht für jeden Chip Code schreiben.
Schau dir diesen Ausschnitt an, um den richtigen Ausführungsanbieter auszuwählen:
# iOS - use CoreML for Apple Silicon optimization
session = ort.InferenceSession(
"simple_model.onnx",
providers=["CoreMLExecutionProvider", "CPUExecutionProvider"]
)
# Android - use NNAPI for hardware acceleration
session = ort.InferenceSession(
"simple_model.onnx",
providers=["NnapiExecutionProvider", "CPUExecutionProvider"]
)CoreML auf iOS nutzt die Neural Engine (Apples NPU). NNAPI auf Android nutzt den Beschleuniger, den dein Gerät hat – GPU, DSP oder NPU. Der Anbieter abstrahiert die Hardware, sodass dein Code gleich bleibt. Wenn ein neuer Chip mit besserer Leistung rauskommt, musst du nur den Ausführungsanbieter aktualisieren, und schon läuft deine App schneller, ohne dass du was am Code ändern musst.
Mit Cloud-Bereitstellung kriegst du unbegrenzte Skalierbarkeit und die neueste Hardware.
Du kannst ONNX-Modelle auf jeder Cloud einsetzen – AWS, Azure, GCP oder deinen eigenen Servern. Das Prinzip ist immer dasselbe: Pack deinen Inferenzdienst in einen Container und stell ihn hinter einem Load Balancer bereit.
Hier ist ein kleines Python FastAPI-Beispiel:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import onnxruntime as ort
import numpy as np
import logging
app = FastAPI()
logger = logging.getLogger(__name__)
# Load model at startup
session = None
@app.on_event("startup")
async def load_model():
global session
session = ort.InferenceSession(
"simple_model.onnx",
providers=[
"CUDAExecutionProvider",
"CoreMLExecutionProvider",
"CPUExecutionProvider",
],
)
logger.info("Model loaded successfully")
class PredictionRequest(BaseModel):
input: list
class PredictionResponse(BaseModel):
prediction: list
inference_time_ms: float
@app.post("/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
try:
import time
start = time.time()
# Input shape: (1, 10)
input_data = np.array(request.input, dtype=np.float32).reshape(1, 10)
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_data})
inference_time = (time.time() - start) * 1000
return PredictionResponse(
prediction=outputs[0].tolist(), inference_time_ms=inference_time
)
except Exception as e:
logger.error(f"Prediction failed: {str(e)}")
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health():
return {"status": "healthy", "model_loaded": session is not None}Dieses FastAPI-Beispiel ist zwar klein, aber für Machine-Learning-Ingenieure nicht ganz einfach zu verstehen. Du kannst die Grundlagen mit unserem kostenlosen Einführungskurs in FastAPI.
Dann kannst du es mit Docker in einen Container packen:
FROM python:3.13-slim
WORKDIR /app
# Install dependencies
RUN pip install onnx onnxruntime onnxscript fastapi pydantic numpy uvicorn
# Copy model and code
COPY simple_model.onnx .
COPY main.py .
# Expose port
EXPOSE 8000
# Run the service
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]Jeder, der sich für maschinelles Lernen interessiert, sollte die Grundlagen von Docker kennen. Mach unsere Einführung in Docker, um endlich zu lernen, wie man ein Machine-Learning-Modell einsetzt.
Du bekommst eine Anwendung, die auf Port 8000 läuft. Dort kannst du die Dokumentation direkt öffnen und den Vorhersage-Endpunkt ausprobieren:
Wenn du Azure Machine Learning nutzt, wirst du dich freuen zu hören, dass es direkt mit ONNX zusammenarbeitet. Du kannst dein Modell in drei Schritten bereitstellen:
from azureml.core import Workspace, Model
from azureml.core.webservice import AciWebservice, Webservice
# Register model
ws = Workspace.from_config()
model = Model.register(
workspace=ws, model_path="simple_model.onnx", model_name="my-onnx-model"
)
# Deploy
deployment_config = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1)
service = Model.deploy(
workspace=ws,
name="onnx-service",
models=[model],
deployment_config=deployment_config,
)Azure kümmert sich um Skalierung, Überwachung und Updates. Du bekommst automatische Protokollierung, Anforderungsverfolgung und Zustandsprüfungen.
Wenn du neu bei Azure Machine Learning bist, schau dir unseren Einsteigerhandbuch , um schnell die Grundlagen zu lernen.
Wenn wir über MLOps-Workflows brauchen wir diese Teile:
Hier ist ein Beispiel-Snippet, das du verwenden kannst:
import prometheus_client as prom
import onnxruntime as ort
import numpy as np
# Define metrics
inference_duration = prom.Histogram(
"model_inference_duration_seconds", "Time spent processing inference"
)
inference_count = prom.Counter("model_inference_total", "Total number of inferences")
# Load model
session = ort.InferenceSession("simple_model.onnx")
@app.post("/predict")
@inference_duration.time()
async def predict(request: PredictionRequest):
inference_count.inc()
# Input shape: (1, 10)
input_data = np.array(request.input, dtype=np.float32).reshape(1, 10)
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_data})
return {"prediction": outputs[0].tolist()}Von dort aus kannst du horizontal skalieren, indem du mehrere Service-Instanzen hinter einem Load Balancer laufen lässt. ONNX Runtime ist zustandslos, also kann jede Instanz jede Anfrage bearbeiten.
ONNX Runtime Web lässt Modelle direkt im Browser laufen, indem es WebAssembly und WebGL nutzt.
Anstatt Daten an einen Server zu schicken, schickst du das Modell einmalig an den Browser und führst die Inferenz lokal aus. Die Leute kriegen sofort Antworten, ohne dass das Netzwerk nervt.
Mach einfach eine HTML-Datei, die ein Inline-JS-Skript benutzt:
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<script src="<https://cdn.jsdelivr.net/npm/onnxruntime-web/dist/ort.min.js>"></script>
</head>
<body>
<script>
async function run() {
try {
const session = await ort.InferenceSession.create("simple_model.onnx", {
executionProviders: ["wasm"]
});
console.log("Session loaded:", session);
// Inspect names
console.log("Inputs:", session.inputNames);
console.log("Outputs:", session.outputNames);
const inputName = session.inputNames[0];
const inputData = new Float32Array(10).fill(0).map(() => Math.random());
const tensor = new ort.Tensor("float32", inputData, [1, 10]);
const feeds = {};
feeds[inputName] = tensor;
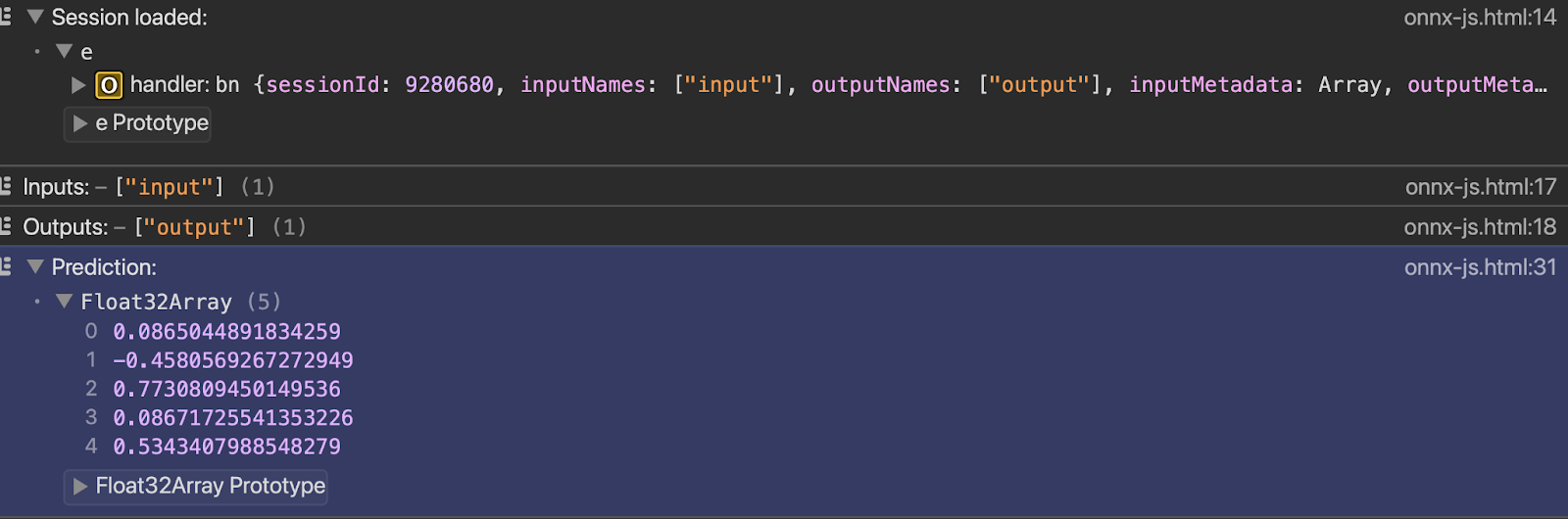
const results = await session.run(feeds);
const outputName = session.outputNames[0];
console.log("Prediction:", results[outputName].data);
} catch (err) {
console.error("ERROR:", err);
}
}
run();
</script>
</body>
</html>Du kannst die Ausgabe in der Konsole sehen, sobald du die Datei mit dem Live-Server öffnest:
Und zum Schluss wollen wir noch ein paar fortgeschrittene Themen anschneiden.
Die Standard-ONNX-Operationen decken die meisten Anwendungsfälle ab. Wenn du aber mehr brauchst, ist dieser Abschnitt genau das Richtige für dich.
Ich werde auf benutzerdefinierte Operatoren und die Bereitstellung großer Sprachmodelle eingehen. Ich erkläre dir, wann du diese erweiterten Funktionen brauchst und welche Vor- und Nachteile sie haben.
ONNX kommt mit Hunderten von Operationen, aber dein Modell könnte was Einzigartiges verwenden.
Mit benutzerdefinierten Operatoren kannst du Operationen festlegen, die im Standard-ONNX-Operatorsatz nicht vorhanden sind. Du schreibst die Operationslogik selbst und sagst ONNX Runtime, wie sie ausgeführt werden soll. Das erweitert ONNX über seine eingebauten Funktionen hinaus.
Wann brauchst du benutzerdefinierte Operatoren? Wenn du topaktuelle Forschung nutzt, die ONNX noch nicht unterstützt. Oder wenn du eigene, für deinen Bereich spezifische Abläufe entwickelt hast. Oder wenn du hardwarespezifische Optimierungen brauchst, die Standardoperationen nicht bieten können.
Aber hier ist der Haken: Benutzerdefinierte Operatoren beeinträchtigen die Portabilität. Dein Modell läuft nicht auf Systemen, die nicht über deine benutzerdefinierte Operatorimplementierung verfügen. Wenn du ein PyTorch-Modell mit benutzerdefinierten Operationen nach ONNX exportierst, musst du diese Operationen separat packen und bei ONNX Runtime registrieren.
Der Einsatz wird schwieriger. Jede Umgebung braucht deine eigene Operator-Bibliothek. Edge-Geräte, Cloud-Server und Browser brauchen alle die gleiche Implementierung. Du verlierst den größten Vorteil von ONNX: einmal schreiben, überall ausführen.
Hier ist ein kleines Beispiel für benutzerdefinierte Operatoren, damit du sehen kannst, wie sie funktionieren:
import numpy as np
import onnxruntime as ort
from onnxruntime import InferenceSession, SessionOptions
# Define the custom operation
def custom_square(x):
return x * x
# Register the custom op with ONNX Runtime
# This tells ONNX Runtime how to execute "CustomSquare" operations
class CustomSquareOp:
@staticmethod
def forward(x):
return np.square(x).astype(np.float32)
# Create a simple ONNX model with a custom op using the helper
from onnx import helper, TensorProto
import onnx
# Create a graph with custom operator
node = helper.make_node(
"CustomSquare", # Custom operation name
["input"],
["output"],
domain="custom.ops", # Custom domain
)
graph = helper.make_graph(
[node],
"custom_op_model",
[helper.make_tensor_value_info("input", TensorProto.FLOAT, [1, 10])],
[helper.make_tensor_value_info("output", TensorProto.FLOAT, [1, 10])],
)
model = helper.make_model(graph)
onnx.save(model, "custom_op_model.onnx")
# To use this model, you'd need to implement the custom op in C++
# and register it with ONNX Runtime - Python-only custom ops aren't supported
print("Custom operator model created - requires C++ implementation to run")Die meisten Teams vermeiden benutzerdefinierte Operatoren, wenn's geht. Probier's erstmal mit Standardoperationen. Mach nur dann was Individuelles, wenn Standardlösungen nicht das tun, was du brauchst, oder wenn die Leistung es erfordert.
Speicherplatz ist ein Problem, wenn es um LLMs geht. Ein 7B-Parametermodell braucht 28 GB in FP32, 14 GB in FP16 und 7 GB in INT8. Die meisten Geräte für Verbraucher können das nicht. Du brauchst Quantisierung, und oft eine aggressive Quantisierung auf INT4 oder INT3.
Wenn du dich noch nicht mit LLMs auskennst und mehr darüber erfahren möchtest, ist unser Kurs „Konzepte großer Sprachmodelle (LLMs)“ ist ein super Einstieg.
Das KV-Cache-Management- t wichtig für die autoregressive Generierung. Jedes Token, das du erstellst, muss auf alle vorherigen Token verweisen. Der Cache wird mit der Sequenzlänge größer. Lange Gespräche fressen schnell Speicherplatz. ONNX Runtime GenAI hat eine optimierte KV-Cache-Verwaltung, die Speicher wiederverwendet und den Overhead reduziert.
Die Inferenzgeschwindigkeit hängt von deiner Hardware und der Modellgröße ab. Kleinere Modelle (unter 3B-Parametern) laufen gut auf normalen GPUs. Größere Modelle brauchen mehrere GPUs oder spezielle Inferenzbeschleuniger. ONNX Runtime kann mehrere GPUs für die Inferenz nutzen, aber du musst dein Modell selbst auf die Geräte verteilen.
Flash Attention macht den Aufmerksamkeitsmechanismus in Transformatoren schneller. Die Standardaufmerksamkeit ist O(n²) in der Sequenzlänge – das wird schnell langsam. Flash Attention reduziert Speicherbewegungen und macht das System schneller, ohne die Ergebnisse zu verändern. ONNX Runtime hat Flash Attention-Optimierungen für die unterstützte Hardware eingebaut.
Das Training von LLMs mit ONNX Runtime ist möglich, kommt aber selten vor. Die meisten Teams trainieren mit PyTorch oder JAX und exportieren dann nur für die Inferenz nach ONNX. ONNX Runtime Training ist für die Feinabstimmung und das fortlaufende Vortraining da, aber das Ökosystem rund um das PyTorch-Training ist schon weiter entwickelt.
Generative KI-Workloads werden in ONNX Runtime besonders behandelt. Die GenAI-Erweiterungen bieten hochentwickelte APIs für die Textgenerierung, die Aufrechterhaltung des Status zwischen Aufrufen und die Verwaltung von Beam-Search- oder Sampling-Strategien. So musst du die Generierungslogik nicht selbst programmieren.
Die LLM-Landschaft ändert sich schnell, und die Updates von ONNX Runtime versuchen, da mitzuhalten. Die Operatorsätze und Optimierungen werden regelmäßig aktualisiert, aber es gibt immer eine Verzögerung zwischen Forschung und produktionsreifer Unterstützung.
Jetzt weißt du, wie du Modelle aus jedem Framework konvertieren, für die Produktion optimieren und überall bereitstellen kannst.
ONNX macht Schluss mit den Problemen zwischen Training und Einsatz. Lerne PyTorch, weil es super für die Forschung ist. Nutze ONNX Runtime, weil es schnell ist und überall läuft. Quantisiere auf INT8 und halbier deine Inferenzkosten. Wechsel von CPU zu GPU, ohne den Code zu ändern. Modelle zwischen Cloud-Anbietern verschieben, ohne an einen Anbieter gebunden zu sein.
ONNX macht das möglich.
Das Ökosystem wird immer besser. Die generative KI-Unterstützung wird mit jeder Version besser – schnellere LLM-Inferenz, besseres Speichermanagement und neue Optimierungstechniken. Die Hardwareunterstützung wird auf mehr Beschleuniger und Edge-Geräte ausgeweitet. Die Community entwickelt Tools, die die Nutzung von ONNX einfacher machen. Du kannst mitmachen, indem du neue Funktionen testest, Probleme meldest oder Code über die GitHub-Repositorys.
Bereit für die nächste Stufe? Meister Konzepte der erklärbaren künstlichen Intelligenz (XAI), um Modelle endlich nicht mehr als Black Boxes zu sehen.
Lerne mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
DataCamp Team
Tutorial
Matt Crabtree
Tutorial
Moez Ali
