
Programa
Cientista de machine learning em Python
85 h
Então você treinou um modelo no PyTorch, mas seu sistema de produção usa o TensorFlow. Precisa reescrever tudo do zero?
Não, você não precisa.
A interoperabilidade dos modelos pode ser um problema para os engenheiros de machine learning. Diferentes estruturas usam formatos diferentes, e converter entre eles pode danificar seu modelo ou causar um comportamento inesperado. Você não quer isso, mas também não quer manter várias versões do mesmo modelo.
O ONNX (Open Neural Network Exchange) resolve isso oferecendo um formato universal para modelos de machine learning. Permite que você treine em uma estrutura e implemente em outra sem precisar reescrever o código ou lidar com bugs.
Neste artigo, vou mostrar como converter modelos para o formato ONNX, fazer inferência com o ONNX Runtime, otimizar modelos para produção e implantá-los em várias plataformas, desde dispositivos de ponta até servidores em nuvem.
Você não pode usar o ONNX sem configurar primeiro seu ambiente de desenvolvimento.
Nesta seção, vou te mostrar tudo o que você precisa, desde os requisitos de software até a criação de um espaço de trabalho limpo e reproduzível. Vou te mostrar como instalar o ONNX e o ONNX Runtime no Windows, Linux e macOS.
O ONNX funciona em qualquer sistema operacional principal.
Você precisa ter o Python 3.8 ou superior instalado no seu computador. É isso aí, o básico. O ONNX suporta a Interface Binária de Aplicativos ( ABI3 ) do Python, o que significa que você pode usar pacotes binários pré-construídos sem precisar compilar a partir do código-fonte.
Aqui está o que você vai instalar:
uv (pegue em astral.sh/uv)
Python 3.8+ (uv cuida disso pra você)
pip (vem com uv)
Se você quiser saber mais sobre como o uv funciona e por que ele deve ser sua escolha preferida, leia nosso guia sobre o gerenciador de pacotes Python mais rápido.
Para quem usa Windows, dá pra instalar o uv usando o PowerShell:
powershell -c "irm <https://astral.sh/uv/install.ps1> | iex"Se você receber um erro de política de execução, execute primeiro o PowerShell como administrador.
Os usuários do Linux podem instalar o uv com este comando shell:
curl -LsSf <https://astral.sh/uv/install.sh> | shIsso funciona em qualquer distribuição Linux.
Por fim, os usuários do macOS podem instalar o uv usando o Homebrew ou um comando curl:
brew install uv
# or
curl -LsSf <https://astral.sh/uv/install.sh> | shVeja como configurar um projeto com uv:
mkdir onnx-project
cd onnx-project
# Initialize a uv project with Python 3.10
uv init --python 3.13O uv cria um diretório .venv e um arquivo pyproject.toml. O ambiente virtual é ativado automaticamente quando você executa comandos através do uv.
Agora instale o ONNX e o ONNX Runtime:
uv add onnx onnxruntime
# Verify the installation
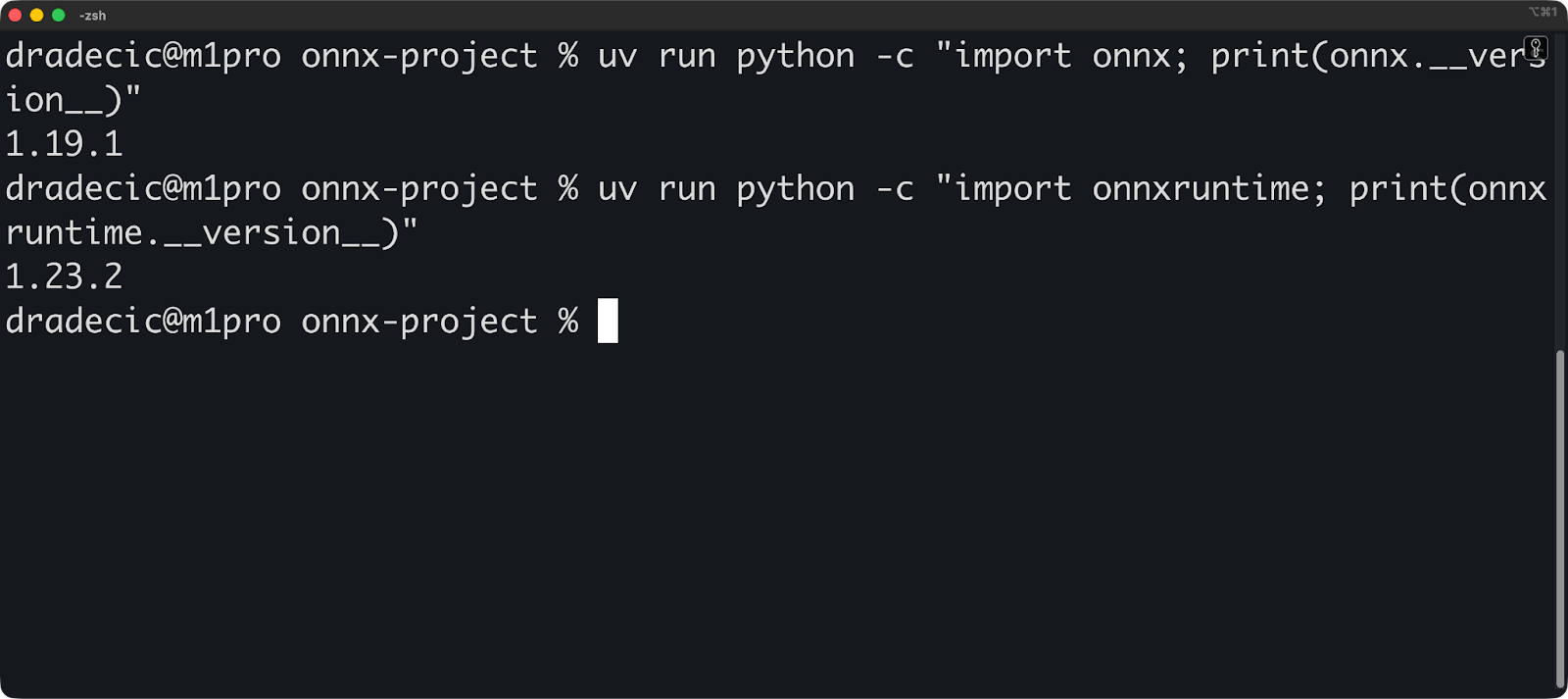
uv run python -c "import onnx; print(onnx.__version__)"
uv run python -c "import onnxruntime; print(onnxruntime.__version__)"Os comandos de verificação devem mostrar os números das versões:
Suas dependências já estão fixadas. O uv grava automaticamente todas as versões dos pacotes em uv.lock. Isso torna suas compilações reproduzíveis — qualquer pessoa pode recriar seu ambiente exato executando o comando` uv sync`.
Aqui tá como fica o seu pyproject.toml:
[project]
name = "onnx-project"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"onnx>=1.19.1",
"onnxruntime>=1.23.2",
]E pronto, o ambiente está configurado! Vamos continuar com o básico.
Você precisa entender como o ONNX funciona antes de começar a converter modelos.
Nesta seção, vou detalhar o formato ONNX e explicar sua arquitetura baseada em gráficos. Vou mostrar o que tem dentro de um arquivo ONNX e como os dados fluem por ele.
Um modelo ONNX é um arquivo que contém a estrutura e os pesos da sua rede neural.
Pense nisso como um projeto. O arquivo fala quais operações fazer, em que ordem e com quais parâmetros. Os pesos treinados são armazenados junto com esse projeto, então o modelo está pronto para ser executado sem arquivos adicionais.
O ONNX foi lançado em 2017 como uma parceria entre a Microsoft e o Facebook (agora Meta). O objetivo era simples: parar de reescrever modelos toda vez que você troca de estrutura. PyTorch, TensorFlow e outras estruturas continuaram melhorando, mas os modelos não podiam ser transferidos entre elas sem conversão manual.
O ONNX mudou isso. A versão 1.0 tinha suporte para operações básicas de visão computacional e redes neurais simples. O ONNX de hoje dá suporte a transformadores, grandes modelos de linguagem e arquiteturas complexas que não existiam em 2017.
Ele usa Protocol Buffers (protobuf) para serializar esses dados. Protobuf é um formato binário desenvolvido pelo Google para armazenamento e transmissão eficientes de dados. É bem mais rápido de ler e escrever do que JSON ou XML, e os arquivos são menores. Todos ganham.
E aí, o que tem dentro de um modelo ONNX:
A versão do opset é importante. O ONNX evolui com o tempo e continua adicionando novas operações e melhorando as já existentes. Seu arquivo de modelo diz qual versão do opset ele usa, então o tempo de execução sabe como rodá-lo.
O ONNX mostra seu modelo como um gráfico computacional.
Um gráfico tem nós e arestas. Os nós são operações (como multiplicação de matrizes ou funções de ativação), e as arestas são tensores (seus dados) que fluem entre essas operações. É assim que o ONNX descreve “multiplique essas matrizes, depois aplique ReLU e multiplique de novo”.
Aqui vai um exemplo simples:
import onnx
from onnx import helper, TensorProto
# Create input and output tensors
input_tensor = helper.make_tensor_value_info(
"input", TensorProto.FLOAT, [1, 3, 224, 224]
)
output_tensor = helper.make_tensor_value_info("output", TensorProto.FLOAT, [1, 1000])
# Create a node (operation)
node = helper.make_node(
"Relu", # Operation type
["input"], # Input edges
["output"], # Output edges
)
# Create the graph
graph = helper.make_graph(
[node], # List of nodes
"simple_model", # Graph name
[input_tensor], # Inputs
[output_tensor], # Outputs
)
# Create the model
model = helper.make_model(graph)
onnx.save(model, "simple_model.onnx")
Cada nó faz uma operação. O tipo de operação (como Relu, Conv ou MatMul) vem do conjunto de operadores ONNX. Você não pode simplesmente inventar nomes de operações - eles precisam existir na versão do conjunto de operações que você está usando.
As arestas conectam os nós e transportam os tensores. Um tensor tem uma forma e um tipo de dados. Quando você define um tensor como [1, 3, 224, 224], tá dizendo “esse tensor tem 4 dimensões com esses tamanhos”. O tempo de execução usa essas informações para alocar memória e validar o gráfico.
O gráfico flui numa direção. Os dados entram pelos nós de entrada, passam pelas operações e saem pelos nós de saída. Não são permitidos ciclos - o ONNX não suporta conexões recorrentes diretamente. Você precisa desenrolar loops ou usar operações específicas projetadas para sequências.
Essa estrutura gráfica permite que as estruturas funcionem juntas. O PyTorch pensa em termos de execução ansiosa, o TensorFlow usa gráficos estáticos e o scikit-learn tem uma abstração totalmente diferente. Mas todos eles podem exportar para o mesmo formato de gráfico.
O gráfico também permite a otimização compartilhada. Um otimizador ONNX pode juntar operações (combinar vários nós em um só), eliminar código morto (tirar nós que não são usados) ou trocar operações lentas por outras mais rápidas. Essas otimizações funcionam independentemente da estrutura que criou o modelo.
A seguir, vou mostrar como converter modelos para o formato ONNX.
Nesta seção, vou mostrar como exportar modelos do PyTorch, TensorFlow e scikit-learn. Vou te explicar o processo de conversão e mostrar como verificar se o seu modelo funciona direitinho depois da conversão.
O ONNX dá suporte às estruturas de machine learning mais populares.
O PyTorch tem exportação ONNX integrada através do torch.onnx.export(). É o conversor mais avançado porque o PyTorch e o ONNX são mantidos pela Meta.
O TensorFlow usa tf2onnx para conversão. É uma biblioteca separada que transforma gráficos do TensorFlow para o formato ONNX. Instale com o comando` uv add tf2onnx` e pronto, você está pronto para começar.
scikit-learn faz a conversão através de skl2onnx. Essa biblioteca lida com modelos tradicionais de machine learning, como florestas aleatórias, regressão linear e SVMs. As estruturas de deep learning chamam mais atenção, mas os modelos scikit-learn funcionam tão bem quanto.
Esses três são os mais populares, mas você pode usar qualquer outro framework compatível - basta instalar a dependência via uv add :
Keras: Use tf2onnx (Keras faz parte do TensorFlow)
XGBoost: Usar onnxmltools
LightGBM: Usar onnxmltools
MATLAB: Exportação ONNX integrada
: Usar paddle2onnx
Cada estrutura tem seu próprio conversor porque elas representam os modelos de maneiras diferentes. O PyTorch usa gráficos de computação dinâmicos, o TensorFlow usa gráficos estáticos e o scikit-learn não usa gráficos. Os conversores transformam essas representações no formato gráfico do ONNX.
Você também pode usar modelos treinados por outras pessoas. OONNX Model Zoo da tem modelos pré-treinados prontos para usar. Você vai encontrar modelos de visão computacional (ResNet, YOLO, EfficientNet), modelos de NLP (BERT, GPT-2) e muito mais. Baixe-os do repositório oficial do GitHub.
O Hugging Face também hospeda modelos ONNX. Procure modelos com “onnx” no nome ou filtre pelo formato ONNX. Muitos modelos populares de transformadores já estão disponíveis no formato ONNX, otimizados para inferência.
Antes de continuar, execute este comando para buscar todas as bibliotecas necessárias com o uv:
uv add torch torchvision tensorflow tf2onnx scikit-learn skl2onnx onnxscriptVeja como converter um modelo PyTorch para ONNX:
import torch
import torch.nn as nn
# Define a simple model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 5)
def forward(self, x):
return self.fc(x)
# Create and prepare the model
model = SimpleModel()
model.eval() # Set to evaluation mode
# Create dummy input with the same shape as your real data
dummy_input = torch.randn(1, 10)
# Export to ONNX
torch.onnx.export(
model, # Model to export
dummy_input, # Example input
"simple_model.onnx", # Output file
input_names=["input"], # Name for the input
output_names=["output"], # Name for the output
dynamic_shapes={"x": {0: "batch_size"}}, # Allow variable batch size
)É novo no PyTorch? Não deixe que isso te impeça. Nosso curso Deep Learning com PyTorch aborda os fundamentos em poucas horas.
A entrada fictícia é importante. O ONNX precisa saber o formato da entrada para construir o gráfico. Se o seu modelo aceita sequências de comprimento variável ou tamanhos de lote diferentes, use dynamic_shapes para marcar essas dimensões como dinâmicas.
Sempre coloque seu modelo no modo de avaliação com model.eval() antes de exportar. Isso desativa o comportamento de treinamento de normalização de dropout e batch. Se você esquecer essa etapa, o modelo convertido não vai ficar igual ao original.
Formas dinâmicas causam problemas. Se o seu conversor reclamar de dimensões desconhecidas, certifique-se de especificar corretamente dynamic_shapes ou forneça formas concretas.
Agora, mudando para o TensorFlow, aqui está um código alternativo que você pode executar:
import numpy as np
# Temporary compatibility fixes for tf2onnx
if not hasattr(np, "object"):
np.object = object
if not hasattr(np, "cast"):
np.cast = lambda dtype: np.asarray
import tensorflow as tf
import tf2onnx
# Define a simple Keras model (same spirit as your PyTorch one)
inputs = tf.keras.Input(shape=(10,), name="input")
outputs = tf.keras.layers.Dense(5, name="output")(inputs)
model = tf.keras.Model(inputs, outputs)
# Save the model (optional, if you want a .h5 file)
model.save("simple_tf_model.h5")
# Define a dynamic input spec (None = dynamic batch dimension)
spec = (tf.TensorSpec((None, 10), tf.float32, name="input"),)
# Convert to ONNX
model_proto, _ = tf2onnx.convert.from_keras(
model, input_signature=spec, output_path="simple_tf_model.onnx"
)Se você nunca trabalhou com o TensorFlow, a gente recomenda que você faça nosso curso Introdução ao TensorFlow em Python.
Infelizmente, tem um pequeno problema com a versão mais recente do Numpy, então eu coloquei uma correção temporária. Na hora de ler, espero que você consiga rodar o trecho sem as seis primeiras linhas.
E, por fim, vamos ver a conversão ONNX para modelos scikit-learn:
from sklearn.ensemble import RandomForestClassifier
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Train a simple model
model = RandomForestClassifier(n_estimators=10)
model.fit(X_train, y_train)
# Define input type and shape
initial_type = [('float_input', FloatTensorType([None, 4]))]
# Convert to ONNX
onnx_model = convert_sklearn(model, initial_types=initial_type)
# Save the model
with open("sklearn_model.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())Parecido com o TensorFlow, o DataCamp também tem um curso grátis de Aprendizado Supervisionado com scikit-learn — dá uma olhada nele se achar o trecho acima confuso.
E é isso!
Agora você pode rodar esse trecho de código pra validar seu modelo convertido:
import onnx
import onnxruntime as ort
import numpy as np
# Load and check the ONNX model
onnx_model = onnx.load("simple_model.onnx")
onnx.checker.check_model(onnx_model)
# Run inference with ONNX Runtime
session = ort.InferenceSession("simple_model.onnx")
input_name = session.get_inputs()[0].name
# Create test input
test_input = np.random.randn(1, 10).astype(np.float32)
# Get prediction
onnx_output = session.run(None, {input_name: test_input})
# Compare with original model
with torch.no_grad():
original_output = model(torch.from_numpy(test_input))
# Check if outputs match (within floating point tolerance)
np.testing.assert_allclose(
original_output.numpy(),
onnx_output[0],
rtol=1e-3,
atol=1e-5
)
print("Model conversion successful - outputs match!")
Faça essa validação sempre que converter um modelo. Pequenas diferenças numéricas são normais (a matemática de ponto flutuante não é exata), mas grandes diferenças significam que algo deu errado durante a conversão.
Pra fechar, aqui vão duas coisas importantes que você precisa saber:
A seguir, vamos falar sobre o ONNX Runtime.
Nesta seção, vou mostrar como usar o ONNX Runtime para carregar modelos e fazer previsões. Vou te mostrar as opções de aceleração de hardware e onde o ONNX Runtime se destaca na produção.
O ONNX Runtime é um mecanismo de inferência multiplataforma. A Microsoft desenvolveu essa tecnologia para executar modelos ONNX rapidamente em qualquer hardware — CPUs, GPUs, chips móveis e aceleradores de IA especializados.
Funciona assim: Você carrega um modelo ONNX e o ONNX Runtime cria um plano de execução. Ele analisa o gráfico computacional, aplica otimizações e descobre a melhor maneira de executar operações no seu hardware. Em seguida, ele faz a inferência usando o plano otimizado.
A arquitetura separa a lógica de execução do código específico do hardware. Os provedores de execução cuidam da interface de hardware. Quer rodar em GPUs NVIDIA? Use o provedor de execução CUDA. Quer o Apple Silicon? Seu código subjacente continua o mesmo.
O ONNX Runtime tem estes provedores de execução:
CPUExecutionProvider: Provedor padrão, funciona em qualquer lugar
CUDAExecutionProvider: GPUs NVIDIA com CUDA
TensorRTExecutionProvider: GPUs NVIDIA com otimização TensorRT
CoreMLExecutionProvider: Dispositivos Apple (macOS, iOS)
DmlExecutionProvider: DirectML para Windows (funciona com qualquer GPU)
OpenVINOExecutionProvider: CPUs e GPUs Intel
ROCMExecutionProvider: AMD GPUs
Cada provedor transforma as operações ONNX em instruções específicas para o hardware. O provedor de CPU usa operações padrão de CPU. O provedor CUDA usa cuDNN e cuBLAS. O provedor TensorRT transforma seu modelo em kernels de GPU otimizados e assim por diante.
Você pode carregar um modelo ONNX com três linhas de código:
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession("simple_model.onnx")
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].nameO InferenceSession faz todo o trabalho pesado. Ele carrega o modelo, valida o gráfico e se prepara para a inferência. Por padrão, ele usa o provedor de execução da CPU.
Agora execute a inferência:
import numpy as np
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession("simple_model.onnx")
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
# Prepare input data
input_data = np.random.randn(1, 10).astype(np.float32)
# Run inference
outputs = session.run(
[output_name],
{input_name: input_data},
)
# Get predictions
predictions = outputs[0]
print(predictions.shape)
O método ` run() ` recebe dois argumentos. Primeiro, uma lista de nomes de saídas (ou None para todas as saídas). Segundo, um dicionário que mapeia nomes de entrada para matrizes numpy.
As formas de entrada precisam ser iguais. Se o seu modelo espera [1, 10] e você passar [1, 10, 3], a inferência vai falhar.
Se você quiser aceleração por GPU, basta especificar os provedores de execução ao criar a sessão:
# For NVIDIA GPUs with CUDA
session = ort.InferenceSession(
"model.onnx",
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
# For Apple Silicon
session = ort.InferenceSession(
"model.onnx",
providers=['CoreMLExecutionProvider', 'CPUExecutionProvider']
)
# For Intel hardware
session = ort.InferenceSession(
"model.onnx",
providers=['OpenVINOExecutionProvider', 'CPUExecutionProvider']
)Liste os fornecedores por ordem de prioridade. O ONNX Runtime tenta o primeiro provedor e, se ele não estiver disponível, tenta o próximo. Sempre inclua CPUExecutionProvider como último recurso.
Você pode ver qual provedor está sendo usado:
import numpy as np
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession(
"simple_model.onnx", providers=["CoreMLExecutionProvider", "CPUExecutionProvider"]
)
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
# Prepare input data
input_data = np.random.randn(1, 10).astype(np.float32)
# Run inference
outputs = session.run(
[output_name],
{input_name: input_data},
)
# Get predictions
predictions = outputs[0]
print(predictions.shape)
print("Providers:")
print(session.get_providers())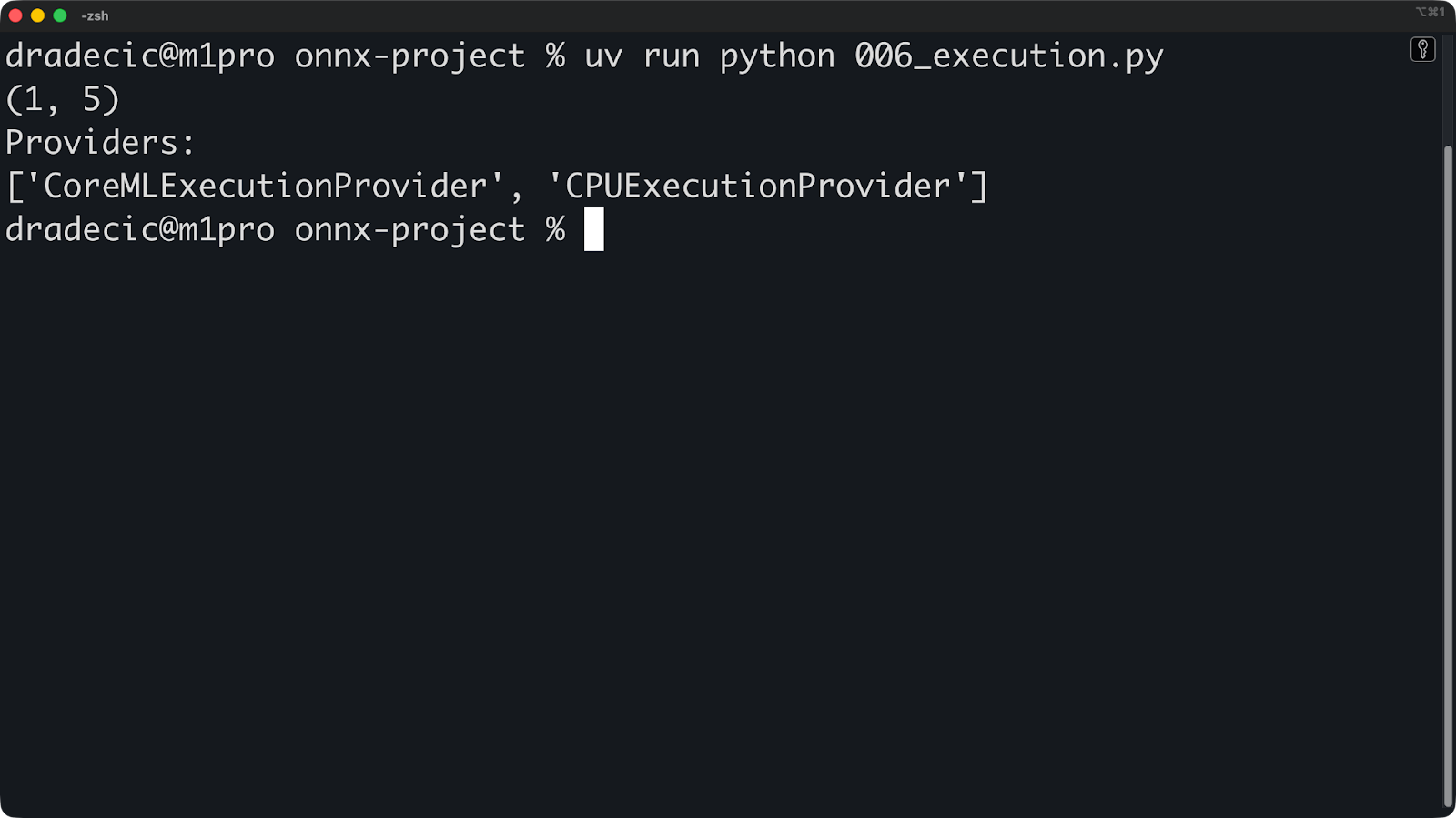
Se você vir um ["CPUExecutionProvider"], mas esperava uma GPU, é porque o provedor da GPU não está disponível. Os motivos mais comuns podem ser drivers que estão faltando, um pacote ONNX Runtime errado ou uma GPU incompatível.
A configuração não para por aqui. Você pode otimizar ainda mais o provedor de execução para obter um melhor desempenho:
providers = [
(
"TensorRTExecutionProvider",
{
"device_id": 0,
"trt_max_workspace_size": 2147483648, # 2GB
"trt_fp16_enable": True, # Use FP16 precision
},
),
"CUDAExecutionProvider",
"CPUExecutionProvider",
]
session = ort.InferenceSession("simple_model.onnx", providers=providers)Você pode conferir a documentação oficial do ONNX Runtime pra ver uma lista de todas as opções disponíveis pro provedor que você escolher.
O mais impressionante sobre o ONNX Runtime é que ele funciona em qualquer lugar: servidores, navegadores e dispositivos móveis.
O ONNX Runtime Web traz inferência para navegadores usando WebAssembly e WebGL. Seu modelo funciona no lado do cliente, sem enviar dados para servidores. Isso funciona muito bem para aplicações que exigem privacidade, como análise de imagens médicas ou processamento de documentos.
Aqui está um exemplo simples de como você pode usar o ONNX Runtime em um arquivo HTML simples:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>ONNXRuntime Web Demo</title>
</head>
<body>
<h1>ONNXRuntime Web Demo</h1>
<!-- Load ONNXRuntime-Web from CDN -->
<script src="<https://cdn.jsdelivr.net/npm/onnxruntime-web/dist/ort.min.js>"></script>
<script>
async function runModel() {
// Create inference session
const session = await ort.InferenceSession.create('./simple_model.onnx');
// Prepare input
const inputData = new Float32Array(10).fill(0).map(() => Math.random());
const tensor = new ort.Tensor('float32', inputData, [1, 10]);
// Run inference
const results = await session.run({ input: tensor });
const output = results.output;
console.log('Output shape:', output.dims);
console.log('Output values:', output.data);
}
runModel();
</script>
</body>
</html>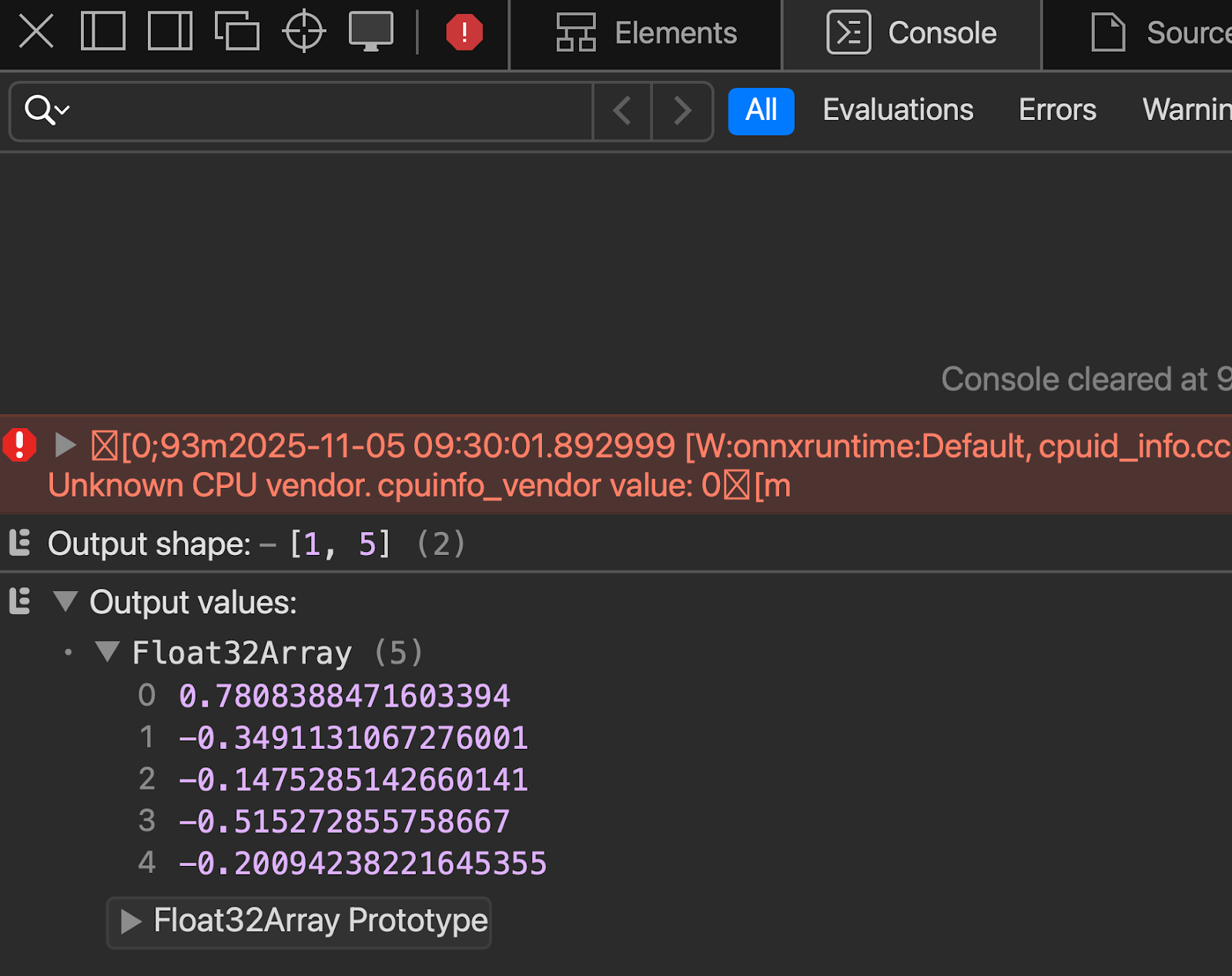
Para implantação móvel, você pode usar o ONNX Runtime Mobile, uma versão leve otimizada para iOS e Android. Ele tira recursos desnecessários e diminui o tamanho do binário.
Este é um exemplo de configuração do iOS:
import onnxruntime_objc
let modelPath = Bundle.main.path(forResource: "simple_model", ofType: "onnx")!
let session = try ORTSession(modelPath: modelPath)
let inputData = // Your input as Data
let inputTensor = try ORTValue(tensorData: inputData,
elementType: .float,
shape: [1, 10])
let outputs = try session.run(withInputs: ["input": inputTensor])Ou, se você estiver usando Python para criar uma API REST, pode incluir o ONNX Runtime em um dos seus endpoints seguindo esta abordagem:
from fastapi import FastAPI
import onnxruntime as ort
import numpy as np
app = FastAPI()
session = ort.InferenceSession("simple_model.onnx")
@app.post("/predict")
async def predict(data: dict):
input_data = np.array(data["input"]).astype(np.float32)
outputs = session.run(None, {"input": input_data})
return {"prediction": outputs[0].tolist()}E é isso! Outros ambientes vão usar uma abordagem parecida, mas você já entendeu a ideia: o ONNX Runtime é fácil de usar. A seguir, vamos falar sobre otimização.
Nesta seção, vou mostrar como deixar os modelos ONNX mais rápidos e menores usando quantização e otimizações de gráficos. Vou te mostrar as técnicas mais importantes para implementações no mundo real.
A quantização reduz a precisão do seu modelo para torná-lo mais rápido e menor.
Em vez de guardar pesos como floats de 32 bits, você os guarda como inteiros de 8 bits. Isso reduz o uso de memória em 75% e acelera a inferência, porque a matemática inteira é mais rápida do que a matemática de ponto flutuante na maioria dos hardwares.
A quantização dinâmica transforma os pesos em menos precisão, mas mantém as ativações (valores intermediários durante a inferência) com precisão total. É o método de quantização mais fácil, porque você não precisa de dados de calibração.
Veja como aplicar a quantização dinâmica:
from onnxruntime.quantization import quantize_dynamic, QuantType
# Quantize the model
quantize_dynamic(
model_input="model.onnx",
model_output="model_quantized.onnx",
weight_type=QuantType.QUInt8 # 8-bit unsigned integers
)É isso aí. Seu modelo quantizado agora usa inteiros sem sinal de 8 bits e está pronto para ser usado.
A quantização estática transforma tanto os pesos quanto as ativações em uma precisão menor. É mais agressivo e rápido do que a quantização dinâmica, mas você precisa de dados de calibração representativos para medir os intervalos de ativação.
Aqui vai uma estratégia geral pra aplicar a quantização estática:
from onnxruntime.quantization import quantize_static, CalibrationDataReader
import numpy as np
# Create a calibration data reader
class DataReader(CalibrationDataReader):
def __init__(self, calibration_data):
self.data = calibration_data
self.index = 0
def get_next(self):
if self.index >= len(self.data):
return None
batch = {"input": self.data[self.index]}
self.index += 1
return batch
# Load calibration data (100-1000 samples from your dataset)
calibration_data = [np.random.randn(1, 10).astype(np.float32)
for _ in range(100)]
data_reader = DataReader(calibration_data)
# Quantize
quantize_static(
model_input="model.onnx",
model_output="model_static_quantized.onnx",
calibration_data_reader=data_reader
)Os dados de calibração devem representar sua carga de trabalho de inferência real, portanto, não use dados aleatórios como mostrei acima. Use amostras reais do seu conjunto de dados.
Em geral, a quantização tem algumas vantagens e desvantagens que você precisa conhecer como engenheiro de machine learning. Aqui estão os benefícios:
E aqui estão as vantagens e desvantagens:
A quantização também é ótima para grandes modelos de linguagem e IA generativa. Um modelo de parâmetro 7B em FP32 ocupa 28 GB de memória. Quantizado para INT8, ele cai para 7 GB. Quantizado para INT4, tem 3,5 GB — pequeno o suficiente para rodar em hardware comum.
As otimizações gráficas reescrevem o gráfico computacional do seu modelo para torná-lo mais rápido.
O conceito de fusão de nós junta várias operações em uma só. Se o seu modelo tiver uma camada Conv seguida por BatchNorm e depois por ReLU, o otimizador vai juntar tudo num único nó e ConvBnRelu. Isso reduz o tráfego de memória e acelera a execução.
Este é o aspecto do gráfico antes da fusão:
Input -> Conv -> BatchNorm -> ReLU -> OutputFica mais simples depois da fusão:
Input -> ConvBnRelu -> OutputTem mais dois conceitos que você precisa saber quando se trata de otimização de gráficos:
É assim que você pode ativar as otimizações de gráfico no ONNX Runtime:
import onnxruntime as ort
# Set optimization level
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# Create session with optimizations
session = ort.InferenceSession(
"simple_model.onnx",
sess_options,
providers=["CPUExecutionProvider"]
)O ONNX Runtime tem os seguintes níveis de otimização:
ORT_DISABLE_ALL: Sem otimizações (útil para depuração)
ORT_ENABLE_BASIC: Otimizações seguras que não alteram os resultados numéricos
ORT_ENABLE_EXTENDED: Otimizações agressivas podem apresentar pequenas diferenças numéricas.
ORT_ENABLE_ALL: Todas as otimizações, incluindo transformações de layout
Use ORT_ENABLE_ALL para produção. A aceleração compensa as pequenas diferenças numéricas.
Você pode usar esse trecho de código para salvar modelos otimizados para reutilização:
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
sess_options.optimized_model_filepath = "model_optimized.onnx"
# This creates and saves the optimized model
session = ort.InferenceSession("simple_model.onnx", sess_options)As otimizações de gráficos funcionam independentemente da estrutura que criou seu modelo. Um padrão PyTorch Conv-BN-ReLU e um padrão TensorFlow Conv-BN-ReLU são fundidos da mesma maneira. Essa é a vantagem da otimização compartilhada: você escreve a otimização uma vez e aplica a modelos de qualquer estrutura.
A seguir, vamos falar sobre implantação.
Nesta seção, vou falar sobre três cenários de implantação: dispositivos de borda, nuvem e navegadores da web. Vou mostrar os desafios e as soluções para cada ambiente.
O principal desafio dos dispositivos de ponta é que eles têm recursos limitados.
Seu smartphone tem de 4 a 16 GB de RAM. Um Raspberry Pi tem ainda menos. Os dispositivos IoT podem ter 512 MB ou menos. Não dá pra simplesmente jogar um modelo de parâmetro 7B nesses dispositivos e esperar que funcione.
Comece com a quantização. Os modelos INT8 devem ser sua referência. Use INT4 se você não se importar com a perda de precisão. Isso deixa seu modelo pequeno o suficiente para caber na memória.
Quando se trata de implantar em dispositivos de ponta, o ONNX Runtime Mobile é seu amigo. Ele tira os recursos do servidor que você não precisa e otimiza a duração da bateria. O binário é menor, a inicialização é mais rápida e o consumo de energia é menor.
Veja como você pode adicioná-lo ao seu projeto de aplicativo móvel:
# iOS
pod 'onnxruntime-mobile-objc'
# Android
implementation 'com.microsoft.onnxruntime:onnxruntime-android:latest.version'Os provedores de execução cuidam das diferenças de hardware. Os dispositivos Android usam CPUs ARM, alguns têm GPUs de diferentes fornecedores e os telefones mais recentes têm NPUs (Unidades de Processamento Neural). Você não quer escrever código para cada chip.
Dá uma olhada nesse trecho pra escolher o provedor de execução certo:
# iOS - use CoreML for Apple Silicon optimization
session = ort.InferenceSession(
"simple_model.onnx",
providers=["CoreMLExecutionProvider", "CPUExecutionProvider"]
)
# Android - use NNAPI for hardware acceleration
session = ort.InferenceSession(
"simple_model.onnx",
providers=["NnapiExecutionProvider", "CPUExecutionProvider"]
)O CoreML no iOS usa o Neural Engine (NPU da Apple). O NNAPI no Android usa qualquer acelerador que o seu dispositivo tiver - GPU, DSP ou NPU. O provedor abstrai o hardware para que seu código permaneça o mesmo. Quando um novo chip com melhor desempenho for lançado, basta atualizar o provedor de execução e seu aplicativo funcionará mais rápido, sem alterações no código.
A implantação em nuvem oferece escala ilimitada e o hardware mais recente.
Você pode usar modelos ONNX em qualquer nuvem — AWS, Azure, GCP ou seus próprios servidores. O padrão é o mesmo: coloque seu serviço de inferência em um contêiner e implante-o atrás de um balanceador de carga.
Aqui vai um pequeno exemplo em Python FastAPI:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import onnxruntime as ort
import numpy as np
import logging
app = FastAPI()
logger = logging.getLogger(__name__)
# Load model at startup
session = None
@app.on_event("startup")
async def load_model():
global session
session = ort.InferenceSession(
"simple_model.onnx",
providers=[
"CUDAExecutionProvider",
"CoreMLExecutionProvider",
"CPUExecutionProvider",
],
)
logger.info("Model loaded successfully")
class PredictionRequest(BaseModel):
input: list
class PredictionResponse(BaseModel):
prediction: list
inference_time_ms: float
@app.post("/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
try:
import time
start = time.time()
# Input shape: (1, 10)
input_data = np.array(request.input, dtype=np.float32).reshape(1, 10)
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_data})
inference_time = (time.time() - start) * 1000
return PredictionResponse(
prediction=outputs[0].tolist(), inference_time_ms=inference_time
)
except Exception as e:
logger.error(f"Prediction failed: {str(e)}")
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health():
return {"status": "healthy", "model_loaded": session is not None}Esse exemplo do FastAPI, mesmo sendo pequeno, não é dos mais fáceis de entender para os engenheiros de machine learning. Você pode dominar os fundamentos com nosso curso gratuito Introdução ao FastAPI.
Depois, você pode fazer a conteinerização com o Docker:
FROM python:3.13-slim
WORKDIR /app
# Install dependencies
RUN pip install onnx onnxruntime onnxscript fastapi pydantic numpy uvicorn
# Copy model and code
COPY simple_model.onnx .
COPY main.py .
# Expose port
EXPOSE 8000
# Run the service
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]Todo mundo que curte machine learning precisa saber o básico sobre o Docker. Faça nosso Introdução ao Docker para finalmente aprender como implantar um modelo de machine learning.
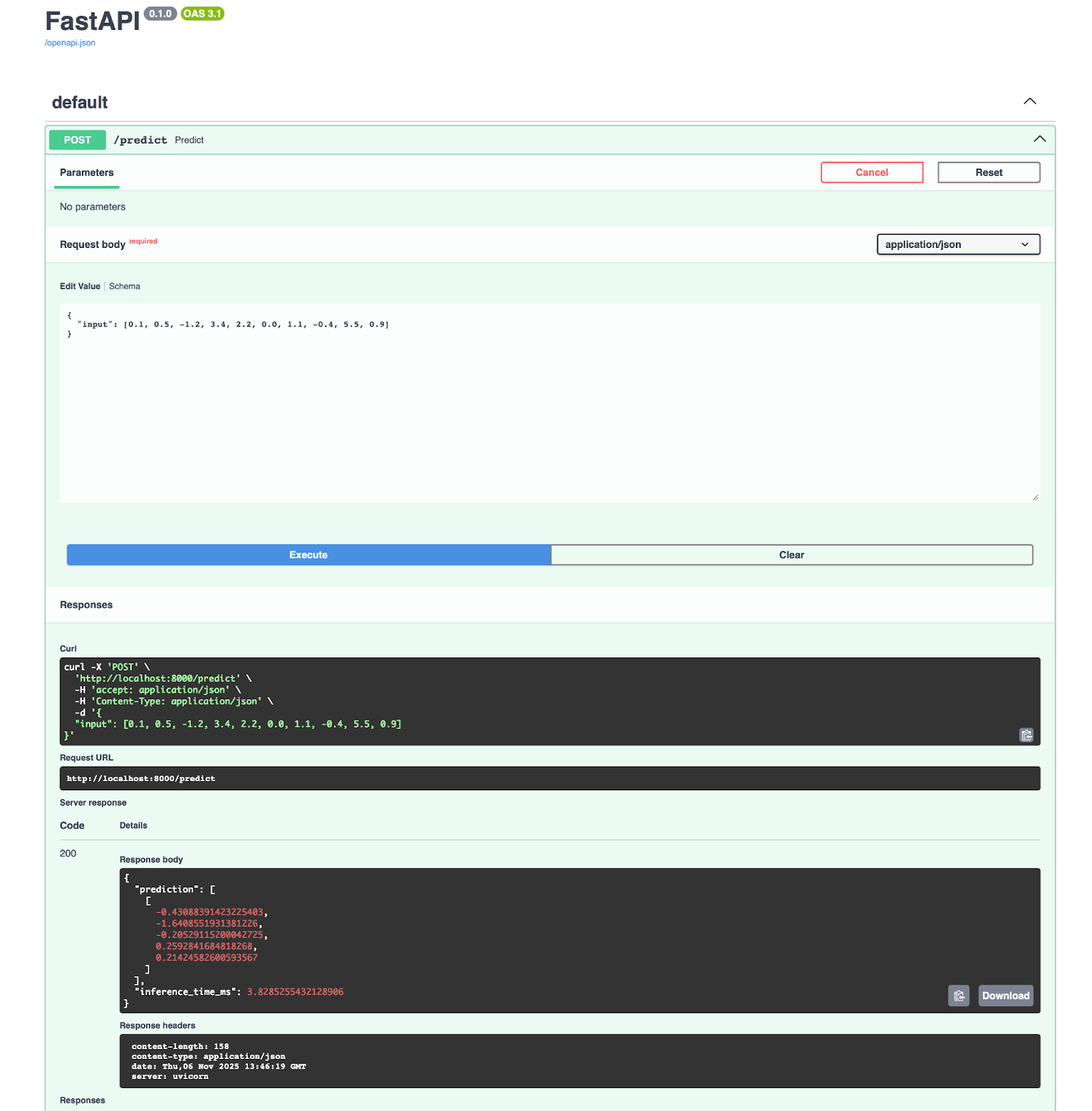
Você vai ter um aplicativo rodando na porta 8000, onde pode abrir a documentação direto e testar o endpoint de previsão:
Se você estiver usando o Azure Machine Learning, vai ficar feliz em saber que ele se integra direto com o ONNX. Você pode implementar seu modelo em três etapas:
from azureml.core import Workspace, Model
from azureml.core.webservice import AciWebservice, Webservice
# Register model
ws = Workspace.from_config()
model = Model.register(
workspace=ws, model_path="simple_model.onnx", model_name="my-onnx-model"
)
# Deploy
deployment_config = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1)
service = Model.deploy(
workspace=ws,
name="onnx-service",
models=[model],
deployment_config=deployment_config,
)O Azure cuida do dimensionamento, monitoramento e atualizações. Você tem registro automático, rastreamento de solicitações e verificações de integridade.
Se você é novo no Azure Machine Learning, dê uma olhada no nosso Guia para Iniciantes para aprender rapidamente os fundamentos.
Se estamos falando sobre fluxos de trabalho MLOps precisamos desses componentes:
Aqui está um exemplo de trecho que você pode usar:
import prometheus_client as prom
import onnxruntime as ort
import numpy as np
# Define metrics
inference_duration = prom.Histogram(
"model_inference_duration_seconds", "Time spent processing inference"
)
inference_count = prom.Counter("model_inference_total", "Total number of inferences")
# Load model
session = ort.InferenceSession("simple_model.onnx")
@app.post("/predict")
@inference_duration.time()
async def predict(request: PredictionRequest):
inference_count.inc()
# Input shape: (1, 10)
input_data = np.array(request.input, dtype=np.float32).reshape(1, 10)
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_data})
return {"prediction": outputs[0].tolist()}A partir daí, você pode escalar horizontalmente executando várias instâncias de serviço atrás de um balanceador de carga. O ONNX Runtime não tem estado, então qualquer instância pode lidar com qualquer solicitação.
O ONNX Runtime Web roda modelos direto nos navegadores usando WebAssembly e WebGL.
Em vez de mandar dados para um servidor, você manda o modelo para o navegador uma vez e faz a inferência localmente. Os usuários recebem respostas instantâneas sem atrasos na rede.
Pra começar, é só criar um arquivo HTML que use um script JS embutido:
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<script src="<https://cdn.jsdelivr.net/npm/onnxruntime-web/dist/ort.min.js>"></script>
</head>
<body>
<script>
async function run() {
try {
const session = await ort.InferenceSession.create("simple_model.onnx", {
executionProviders: ["wasm"]
});
console.log("Session loaded:", session);
// Inspect names
console.log("Inputs:", session.inputNames);
console.log("Outputs:", session.outputNames);
const inputName = session.inputNames[0];
const inputData = new Float32Array(10).fill(0).map(() => Math.random());
const tensor = new ort.Tensor("float32", inputData, [1, 10]);
const feeds = {};
feeds[inputName] = tensor;
const results = await session.run(feeds);
const outputName = session.outputNames[0];
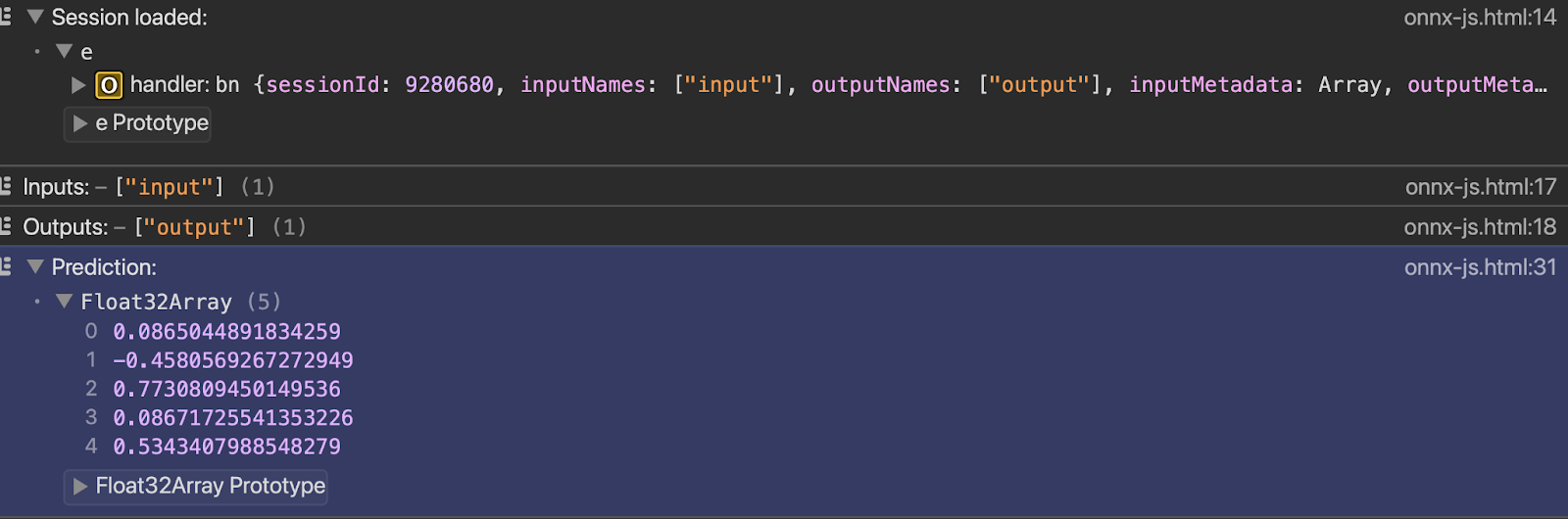
console.log("Prediction:", results[outputName].data);
} catch (err) {
console.error("ERROR:", err);
}
}
run();
</script>
</body>
</html>Você pode ver o resultado no console assim que abrir o arquivo com o servidor ativo:
E, por fim, vamos falar sobre alguns tópicos mais avançados.
As operações padrão do ONNX cobrem a maioria dos casos de uso, mas se você precisar de mais, esta seção é para você.
Vou falar sobre operadores personalizados e implantação de modelos de linguagem grandes. Vou explicar quando você precisa desses recursos avançados e quais são as vantagens e desvantagens que eles trazem.
O ONNX vem com centenas de operações, mas seu modelo pode usar algo único.
Os operadores personalizados permitem definir operações que não existem no conjunto padrão de operadores ONNX. Você mesmo escreve a lógica da operação e diz ao ONNX Runtime como executá-la. Isso faz com que o ONNX vá além das suas funcionalidades integradas.
Quando você precisa de operadores personalizados? Quando você está usando pesquisas de ponta que o ONNX ainda não suporta. Ou quando você criou operações específicas para o seu domínio. Ou quando você precisa de otimizações específicas de hardware que as operações padrão não conseguem oferecer.
Mas tem um porém: os operadores personalizados acabam com a portabilidade. Seu modelo não vai funcionar em sistemas que não tenham sua implementação de operador personalizado. Se você exportar um modelo PyTorch com operações personalizadas para ONNX, vai precisar empacotar essas operações separadamente e registrá-las no ONNX Runtime.
A implantação fica mais difícil. Todo ambiente precisa da sua biblioteca de operadores personalizada. Dispositivos de ponta, servidores em nuvem e navegadores precisam todos da mesma implementação. Você perde a maior vantagem do ONNX: escreva uma vez, execute em qualquer lugar.
Aqui está um pequeno exemplo prático de operadores personalizados, só para você ver como eles funcionam:
import numpy as np
import onnxruntime as ort
from onnxruntime import InferenceSession, SessionOptions
# Define the custom operation
def custom_square(x):
return x * x
# Register the custom op with ONNX Runtime
# This tells ONNX Runtime how to execute "CustomSquare" operations
class CustomSquareOp:
@staticmethod
def forward(x):
return np.square(x).astype(np.float32)
# Create a simple ONNX model with a custom op using the helper
from onnx import helper, TensorProto
import onnx
# Create a graph with custom operator
node = helper.make_node(
"CustomSquare", # Custom operation name
["input"],
["output"],
domain="custom.ops", # Custom domain
)
graph = helper.make_graph(
[node],
"custom_op_model",
[helper.make_tensor_value_info("input", TensorProto.FLOAT, [1, 10])],
[helper.make_tensor_value_info("output", TensorProto.FLOAT, [1, 10])],
)
model = helper.make_model(graph)
onnx.save(model, "custom_op_model.onnx")
# To use this model, you'd need to implement the custom op in C++
# and register it with ONNX Runtime - Python-only custom ops aren't supported
print("Custom operator model created - requires C++ implementation to run")A maioria das equipes evita operadores personalizados sempre que possível. Tenta usar combinações de operações padrão primeiro. Só opte por soluções personalizadas quando as operações padrão não forem suficientes para expressar sua operação ou quando o desempenho assim o exigir.
A memória é um problema quando se trata de LLMs. Um modelo com 7B parâmetros precisa de 28 GB em FP32, 14 GB em FP16 e 7 GB em INT8. A maioria dos equipamentos de hardware não aguenta isso. Você precisa de quantização, e muitas vezes uma quantização agressiva para INT4 ou INT3.
Se você é novo no mundo dos LLMs e quer saber mais, nosso curso curso Conceitos de Modelos de Linguagem de Grande Porte (LLMs) é um ótimo lugar pra começar.
A gestão da cache KV é importante para a geração autoregressiva. Cada token que você gera precisa fazer referência a todos os tokens anteriores. O cache aumenta com o comprimento da sequência. Conversas longas acabam com a memória rapidinho. O ONNX Runtime GenAI inclui um gerenciamento otimizado do cache KV que reutiliza a memória e reduz a sobrecarga.
A velocidade da inferência depende do seu hardware e do tamanho do modelo. Modelos menores (com menos de 3B parâmetros) funcionam bem em GPUs comuns. Modelos maiores precisam de várias GPUs ou aceleradores de inferência especializados. O ONNX Runtime dá suporte à inferência multi-GPU por meio de provedores de execução, mas você precisa dividir seu modelo entre os dispositivos manualmente.
Flash Attention acelera o mecanismo de atenção nos transformadores. A atenção padrão é O(n²) no comprimento da sequência - fica lenta rapidamente. O Flash Attention reduz o movimento da memória e melhora a velocidade sem alterar os resultados. O ONNX Runtime inclui otimizações do Flash Attention para hardware compatível.
Treinar LLMs com o ONNX Runtime é possível, mas não é muito comum. A maioria das equipes treina com PyTorch ou JAX e depois exporta para ONNX só para fazer inferência. O ONNX Runtime Training existe para ajustes finos e pré-treinamento contínuo, mas o ecossistema em torno do treinamento PyTorch é mais maduro.
As cargas de trabalho de IA generativa têm um tratamento especial no ONNX Runtime. As extensões GenAI oferecem APIs de alto nível para gerar texto, manter o estado entre chamadas e gerenciar estratégias de pesquisa ou amostragem. Isso evita que você mesmo tenha que implementar a lógica de geração.
O cenário do LLM muda rápido, e as atualizações do ONNX Runtime fazem o possível para acompanhar. O conjunto de operadores e as otimizações são atualizados regularmente, mas sempre tem um atraso entre a pesquisa e o suporte pronto para produção.
Agora você sabe como converter modelos de qualquer estrutura, otimizá-los para produção e implantá-los em qualquer lugar.
O ONNX acaba com o atrito entre o treinamento e a implantação. Treine no PyTorch porque é ótimo para pesquisa. Implemente com o ONNX Runtime porque é rápido e funciona em qualquer lugar. Quantize para INT8 e reduza seus custos de inferência pela metade. Mude da CPU para a GPU sem alterar o código. Mude os modelos entre provedores de nuvem sem ficar preso a um único fornecedor.
O ONNX é o que torna isso possível.
O ecossistema continua melhorando. O suporte à IA generativa fica melhor a cada lançamento — inferência LLM mais rápida, melhor gerenciamento de memória e novas técnicas de otimização. O suporte de hardware agora dá conta de mais aceleradores e dispositivos de ponta. A galera cria ferramentas que facilitam o uso do ONNX. Você pode participar testando novos recursos, relatando problemas ou contribuindo com código através dos repositórios GitHub. repositórios GitHub.
Pronto para o próximo nível? Mestre Conceitos de Inteligência Artificial Explicável (XAI) para finalmente parar de pensar nos modelos como caixas pretas.
Aprenda com o DataCamp
Programa
Curso
Curso
blog
Abid Ali Awan
5 min
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
7 min
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Arjun Sarkar



