
programa
Científico especializado en machine learning en Python
85 h
Así que has entrenado un modelo en PyTorch, pero tu sistema de producción utiliza TensorFlow. ¿Necesitas reescribir todo desde cero?
No, no lo haces.
La interoperabilidad de los modelos puede causar dolores de cabeza a los ingenieros de machine learning. Los diferentes marcos utilizan formatos distintos, y la conversión entre ellos puede dañar tu modelo o provocar un comportamiento inesperado. No quieres eso, pero tampoco quieres mantener varias versiones del mismo modelo.
ONNX (Open Neural Network Exchange) resuelve este problema proporcionando un formato universal para los modelos de machine learning. Te permite entrenar en un marco y desplegar en otro sin necesidad de reescribir el código ni lidiar con errores.
En este artículo, te mostraré cómo convertir modelos al formato ONNX, ejecutar inferencias con ONNX Runtime, optimizar modelos para producción e implementarlos en diversas plataformas, desde dispositivos periféricos hasta servidores en la nube.
No puedes utilizar ONNX sin configurar primero tu entorno de desarrollo.
En esta sección, te explicaré todo lo que necesitas, desde los requisitos de software hasta cómo crear un espacio de trabajo limpio y reproducible. Te mostraré cómo instalar ONNX y ONNX Runtime en Windows, Linux y macOS.
ONNX funciona en cualquier sistema operativo importante.
Necesitas tener instalado Python 3.8 o superior en tu equipo. Eso es todo en cuanto a lo básico. ONNX es compatible con la interfaz binaria de aplicaciones ( ABI3, ABI) de Python, lo que significa que puedes utilizar paquetes binarios precompilados sin necesidad de compilar desde el código fuente.
Esto es lo que instalarás:
uv (descárgalo de astral.sh/uv)
Python 3.8+ (uv se encarga de esto por ti)
pip (incluye uv)
Si deseas obtener más información sobre cómo funciona uv y por qué debería ser tu opción preferida, lee nuestra guía sobre el gestor de paquetes Python más rápido.
Los usuarios de Windows pueden instalar uv mediante PowerShell:
powershell -c "irm <https://astral.sh/uv/install.ps1> | iex"Si recibes un error de política de ejecución, ejecuta primero PowerShell como administrador.
Los usuarios de Linux pueden instalar uv con este comando de terminal:
curl -LsSf <https://astral.sh/uv/install.sh> | shEsto funciona en cualquier distribución de Linux.
Por último, los usuarios de macOS pueden instalar uv utilizando Homebrew o mediante un comando curl:
brew install uv
# or
curl -LsSf <https://astral.sh/uv/install.sh> | shA continuación se explica cómo configurar un proyecto con uv:
mkdir onnx-project
cd onnx-project
# Initialize a uv project with Python 3.10
uv init --python 3.13uv crea un directorio .venv y un archivo pyproject.toml. El entorno virtual se activa automáticamente cuando ejecutas comandos a través de uv.
Ahora instala ONNX y ONNX Runtime:
uv add onnx onnxruntime
# Verify the installation
uv run python -c "import onnx; print(onnx.__version__)"
uv run python -c "import onnxruntime; print(onnxruntime.__version__)"Los comandos de verificación deben mostrar los números de versión:
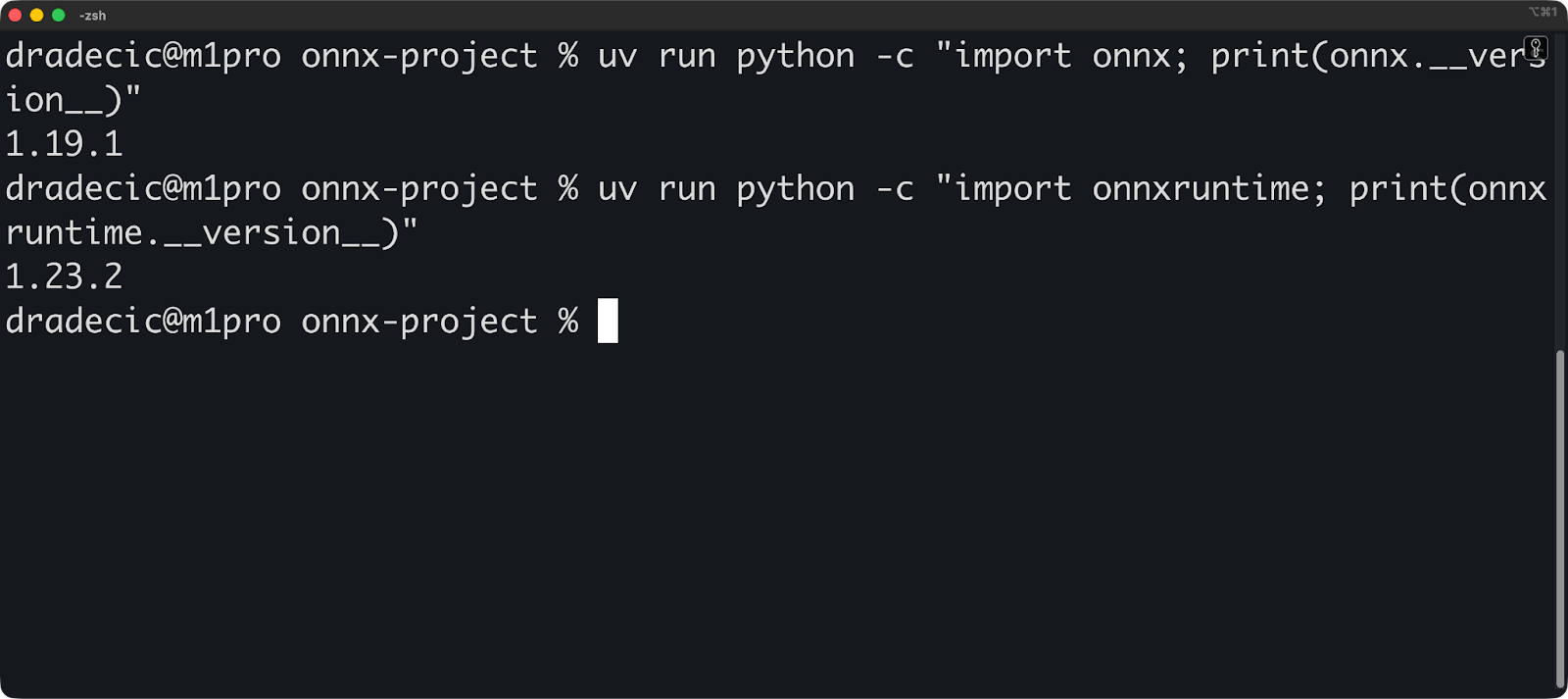
Tus dependencias ya están fijadas. uv escribe automáticamente todas las versiones de los paquetes en uv.lock. Esto hace que tus compilaciones sean reproducibles: cualquiera puede recrear tu entorno exacto ejecutando uv sync.
Así es como se ve tu pyproject.toml:
[project]
name = "onnx-project"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"onnx>=1.19.1",
"onnxruntime>=1.23.2",
]¡Y eso es todo, el entorno está configurado! Comencemos con los conceptos básicos.
Es necesario comprender cómo funciona ONNX antes de empezar a convertir modelos.
En esta sección, analizaré el formato ONNX y explicaré su arquitectura basada en grafos. Te mostraré qué hay dentro de un archivo ONNX y cómo fluyen los datos a través de él.
Un modelo ONNX es un archivo que contiene la estructura y los pesos de tu red neuronal.
Piensa en ello como un proyecto. El archivo describe qué operaciones realizar, en qué orden y con qué parámetros. Tus pesos entrenados se almacenan junto con este plano, por lo que el modelo está listo para ejecutarse sin necesidad de archivos adicionales.
ONNX se lanzó en 2017 como una colaboración entre Microsoft y Facebook (ahora Meta). El objetivo era sencillo: dejar de reescribir modelos cada vez que cambias de marco de trabajo. PyTorch, TensorFlow y otros marcos siguieron mejorando, pero los modelos no podían moverse entre ellos sin una conversión manual.
ONNX cambió eso. La versión 1.0 admitía operaciones básicas para la visión artificial y redes neuronales simples. El ONNX actual es compatible con transformadores, modelos de lenguaje grandes y arquitecturas complejas que no existían en 2017.
Utiliza Protocol Buffers (protobuf) para serializar estos datos. Protobuf es un formato binario desarrollado por Google para el almacenamiento y la transmisión eficientes de datos. Es mucho más rápido de leer y escribir que JSON o XML, y los archivos son más pequeños. Beneficioso para todos.
Esto es lo que contiene un modelo ONNX:
La versión de opset es importante. ONNX evoluciona con el tiempo y sigue añadiendo nuevas operaciones y mejorando las ya existentes. Tu archivo de modelo especifica qué versión de opset utiliza, por lo que el tiempo de ejecución sabe cómo ejecutarlo.
ONNX representa tu modelo como un gráfico computacional.
Un gráfico tiene nodos y aristas. Los nodos son operaciones (como la multiplicación de matrices o las funciones de activación), y los bordes son tensores (tus datos) que fluyen entre esas operaciones. Así es como ONNX describe «multiplicar estas matrices, luego aplicar ReLU y volver a multiplicar».
Aquí tienes un ejemplo sencillo:
import onnx
from onnx import helper, TensorProto
# Create input and output tensors
input_tensor = helper.make_tensor_value_info(
"input", TensorProto.FLOAT, [1, 3, 224, 224]
)
output_tensor = helper.make_tensor_value_info("output", TensorProto.FLOAT, [1, 1000])
# Create a node (operation)
node = helper.make_node(
"Relu", # Operation type
["input"], # Input edges
["output"], # Output edges
)
# Create the graph
graph = helper.make_graph(
[node], # List of nodes
"simple_model", # Graph name
[input_tensor], # Inputs
[output_tensor], # Outputs
)
# Create the model
model = helper.make_model(graph)
onnx.save(model, "simple_model.onnx")
Cada nodo realiza una operación. El tipo de operación (como Relu, Conv o MatMul) proviene del conjunto de operadores ONNX. No puedes inventarte nombres de operaciones, deben existir en la versión de opset que estás utilizando.
Los bordes conectan nodos y transportan tensores. Un tensor tiene una forma y un tipo de datos. Cuando defines un tensor, estás diciendo «est [1, 3, 224, 224] tiene 4 dimensiones con estos tamaños». El tiempo de ejecución utiliza esta información para asignar memoria y validar el gráfico.
El gráfico fluye en una sola dirección. Los datos entran por los nodos de entrada, pasan por las operaciones y salen por los nodos de salida. No se permiten ciclos: ONNX no admite conexiones recurrentes directamente. Debes desenrollar los bucles o utilizar operaciones específicas diseñadas para secuencias.
Esta estructura gráfica permite la interoperabilidad del marco. PyTorch piensa en términos de ejecución inmediata, TensorFlow utiliza gráficos estáticos y scikit-learn tiene una abstracción completamente diferente. Pero todos pueden exportar al mismo formato de gráfico.
El gráfico también permite la optimización compartida. Un optimizador ONNX puede fusionar operaciones (combinar varios nodos en uno solo), eliminar código muerto (eliminar nodos no utilizados) o sustituir operaciones lentas por otras equivalentes más rápidas. Estas optimizaciones funcionan independientemente del marco en el que se haya creado el modelo.
A continuación, te mostraré los entresijos de la conversión de modelos al formato ONNX.
En esta sección, te mostraré cómo exportar modelos desde PyTorch, TensorFlow y scikit-learn. Te guiaré a través del proceso de conversión y te mostraré cómo validar que tu modelo funciona correctamente después de la conversión.
ONNX es compatible con los marcos de machine learning más populares.
PyTorch tiene una función integrada de exportación a ONNX a través de torch.onnx.export(). Es el convertidor más maduro porque tanto PyTorch como ONNX son mantenidos por Meta.
TensorFlow utiliza tf2onnx para la conversión. Es una biblioteca independiente que convierte gráficos TensorFlow al formato ONNX. Instálalo con uv add tf2onnx y ya estarás listo para empezar.
scikit-learn convierte a través de skl2onnx. Esta biblioteca maneja modelos tradicionales de machine learning como bosques aleatorios, regresión lineal y SVM. Los marcos de aprendizaje profundo reciben más atención, pero los modelos scikit-learn funcionan igual de bien.
Estos tres son los más populares, pero puedes utilizar cualquiera de estos otros marcos compatibles: solo tienes que instalar la dependencia a través de uv add :
Keras: Utiliza tf2onnx (Keras forma parte de TensorFlow).
XGBoost: Uso onnxmltools
LightGBM: Uso onnxmltools
MATLAB: Exportación ONNX integrada
Paddle: Uso paddle2onnx
Cada marco tiene su propio convertidor porque representan los modelos de manera diferente. PyTorch utiliza gráficos de cálculo dinámicos, TensorFlow utiliza gráficos estáticos y scikit-learn no utiliza gráficos en absoluto. Los convertidores traducen estas representaciones al formato gráfico de ONNX.
También puedes utilizar modelos entrenados por otras personas. ONNX Model Zoo alberga modelos preentrenados listos para usar. Encontrarás modelos de visión artificial (ResNet, YOLO, EfficientNet), modelos de PLN (BERT, GPT-2) y mucho más. Descárgalos del repositorio oficial de GitHub.
Hugging Face también aloja modelos ONNX. Busca modelos con «onnx» en el nombre o filtra por formato ONNX. Muchos modelos populares de transformadores están disponibles en formato ONNX ya optimizados para la inferencia.
Antes de continuar, ejecuta este comando para obtener todas las bibliotecas necesarias con uv:
uv add torch torchvision tensorflow tf2onnx scikit-learn skl2onnx onnxscriptA continuación se explica cómo convertir un modelo PyTorch a ONNX:
import torch
import torch.nn as nn
# Define a simple model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 5)
def forward(self, x):
return self.fc(x)
# Create and prepare the model
model = SimpleModel()
model.eval() # Set to evaluation mode
# Create dummy input with the same shape as your real data
dummy_input = torch.randn(1, 10)
# Export to ONNX
torch.onnx.export(
model, # Model to export
dummy_input, # Example input
"simple_model.onnx", # Output file
input_names=["input"], # Name for the input
output_names=["output"], # Name for the output
dynamic_shapes={"x": {0: "batch_size"}}, # Allow variable batch size
)¿Eres nuevo en PyTorch? No dejes que eso te frene. Nuestro curso Deep Learning con PyTorch cubre los fundamentos en pocas horas.
La entrada ficticia es importante. ONNX necesita conocer la forma de la entrada para construir el gráfico. Si tu modelo acepta secuencias de longitud variable o tamaños de lote diferentes, utiliza dynamic_shapes para marcar esas dimensiones como dinámicas.
Configura siempre tu modelo en modo de evaluación con model.eval() antes de exportarlo. Esto desactiva el comportamiento de entrenamiento de normalización por lotes y abandono. Si olvidas este paso, el modelo convertido no coincidirá con el original.
Las formas dinámicas causan problemas. Si tu conversor te da un error por dimensiones desconocidas, asegúrate de especificar correctamente dynamic_shapes o proporciona formas concretas.
Ahora, pasando a TensorFlow, aquí tienes un código alternativo que puedes ejecutar:
import numpy as np
# Temporary compatibility fixes for tf2onnx
if not hasattr(np, "object"):
np.object = object
if not hasattr(np, "cast"):
np.cast = lambda dtype: np.asarray
import tensorflow as tf
import tf2onnx
# Define a simple Keras model (same spirit as your PyTorch one)
inputs = tf.keras.Input(shape=(10,), name="input")
outputs = tf.keras.layers.Dense(5, name="output")(inputs)
model = tf.keras.Model(inputs, outputs)
# Save the model (optional, if you want a .h5 file)
model.save("simple_tf_model.h5")
# Define a dynamic input spec (None = dynamic batch dimension)
spec = (tf.TensorSpec((None, 10), tf.float32, name="input"),)
# Convert to ONNX
model_proto, _ = tf2onnx.convert.from_keras(
model, input_signature=spec, output_path="simple_tf_model.onnx"
)Si nunca has trabajado con TensorFlow, te recomendamos que realices nuestro curso Introducción a TensorFlow en Python.
Desafortunadamente, hay un pequeño conflicto con la última versión de Numpy, así que he añadido una solución temporal. En el momento de leer esto, es de esperar que puedas ejecutar el fragmento sin las primeras seis líneas.
Y, por último, veamos la conversión ONNX para los modelos scikit-learn:
from sklearn.ensemble import RandomForestClassifier
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Train a simple model
model = RandomForestClassifier(n_estimators=10)
model.fit(X_train, y_train)
# Define input type and shape
initial_type = [('float_input', FloatTensorType([None, 4]))]
# Convert to ONNX
onnx_model = convert_sklearn(model, initial_types=initial_type)
# Save the model
with open("sklearn_model.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())Al igual que TensorFlow, DataCamp también ofrece un curso gratuito sobre aprendizaje supervisado con scikit-learn. Échale un vistazo si el fragmento anterior te resulta confuso.
¡Y eso es todo!
Ahora puedes ejecutar este fragmento de código para validar tu modelo convertido:
import onnx
import onnxruntime as ort
import numpy as np
# Load and check the ONNX model
onnx_model = onnx.load("simple_model.onnx")
onnx.checker.check_model(onnx_model)
# Run inference with ONNX Runtime
session = ort.InferenceSession("simple_model.onnx")
input_name = session.get_inputs()[0].name
# Create test input
test_input = np.random.randn(1, 10).astype(np.float32)
# Get prediction
onnx_output = session.run(None, {input_name: test_input})
# Compare with original model
with torch.no_grad():
original_output = model(torch.from_numpy(test_input))
# Check if outputs match (within floating point tolerance)
np.testing.assert_allclose(
original_output.numpy(),
onnx_output[0],
rtol=1e-3,
atol=1e-5
)
print("Model conversion successful - outputs match!")
Ejecuta esta validación cada vez que conviertas un modelo. Las pequeñas diferencias numéricas son normales (las operaciones matemáticas con coma flotante no son exactas), pero las grandes diferencias significan que algo salió mal durante la conversión.
Para terminar, aquí tienes dos advertencias importantes que debes tener en cuenta:
A continuación, hablemos de ONNX Runtime.
En esta sección, te mostraré cómo usar ONNX Runtime para cargar modelos y realizar predicciones. Te guiaré a través de las opciones de aceleración de hardware y te mostraré dónde destaca ONNX Runtime en la producción.
ONNX Runtime es un motor de inferencia multiplataforma. Microsoft lo desarrolló para ejecutar modelos ONNX rápidamente en cualquier hardware: CPU, GPU, chips móviles y aceleradores de IA especializados.
Así es como funciona: Cargas un modelo ONNX y ONNX Runtime crea un plan de ejecución. Analiza el gráfico computacional, aplica optimizaciones y determina la mejor manera de ejecutar operaciones en tu hardware. A continuación, ejecuta la inferencia utilizando el plan optimizado.
La arquitectura separa la lógica de ejecución del código específico del hardware. Los proveedores de ejecución se encargan de la interfaz de hardware. ¿Quieres ejecutarlo en GPU NVIDIA? Utiliza el proveedor de ejecución CUDA. ¿Quieres Apple Silicon? Tu código subyacente permanece igual.
ONNX Runtime cuenta con los siguientes proveedores de ejecución:
CPUExecutionProvider: Proveedor predeterminado, funciona en todas partes.
CUDAExecutionProvider: GPU NVIDIA con CUDA
TensorRTExecutionProvider: GPU NVIDIA con optimización TensorRT
CoreMLExecutionProvider: Dispositivos Apple (macOS, iOS)
DmlExecutionProvider: DirectML para Windows (funciona con cualquier GPU)
OpenVINOExecutionProvider: CPU y GPU Intel
ROCMExecutionProvider: GPU AMD
Cada proveedor traduce las operaciones ONNX a instrucciones específicas del hardware. El proveedor de CPU utiliza operaciones de CPU estándar. El proveedor CUDA utiliza cuDNN y cuBLAS. El proveedor TensorRT compila tu modelo en núcleos GPU optimizados, etc.
Puedes cargar un modelo ONNX con tres líneas de código:
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession("simple_model.onnx")
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].nameEl sistema de control de tracción y control de estabilidad ( InferenceSession ) se encarga de todo el trabajo pesado. Carga el modelo, valida el gráfico y se prepara para la inferencia. De forma predeterminada, utiliza el proveedor de ejecución de la CPU.
Ahora ejecuta la inferencia:
import numpy as np
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession("simple_model.onnx")
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
# Prepare input data
input_data = np.random.randn(1, 10).astype(np.float32)
# Run inference
outputs = session.run(
[output_name],
{input_name: input_data},
)
# Get predictions
predictions = outputs[0]
print(predictions.shape)
El método ` run() ` toma dos argumentos. Primero, una lista de nombres de salida (o None para todas las salidas). Segundo, un diccionario que asigna nombres de entrada a arreglos numpy.
Las formas de entrada deben coincidir. Si tu modelo espera [1, 10] y pasas [1, 10, 3], la inferencia fallará.
Si deseas aceleración por GPU, solo tienes que especificar los proveedores de ejecución al crear la sesión:
# For NVIDIA GPUs with CUDA
session = ort.InferenceSession(
"model.onnx",
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
# For Apple Silicon
session = ort.InferenceSession(
"model.onnx",
providers=['CoreMLExecutionProvider', 'CPUExecutionProvider']
)
# For Intel hardware
session = ort.InferenceSession(
"model.onnx",
providers=['OpenVINOExecutionProvider', 'CPUExecutionProvider']
)Enumera los proveedores por orden de prioridad. ONNX Runtime prueba el primer proveedor y, si no está disponible, recurre al siguiente. Incluye siempre CPUExecutionProvider como último recurso.
Puedes comprobar qué proveedor se está utilizando realmente:
import numpy as np
import onnxruntime as ort
# Create an inference session
session = ort.InferenceSession(
"simple_model.onnx", providers=["CoreMLExecutionProvider", "CPUExecutionProvider"]
)
# Get input and output names
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
# Prepare input data
input_data = np.random.randn(1, 10).astype(np.float32)
# Run inference
outputs = session.run(
[output_name],
{input_name: input_data},
)
# Get predictions
predictions = outputs[0]
print(predictions.shape)
print("Providers:")
print(session.get_providers())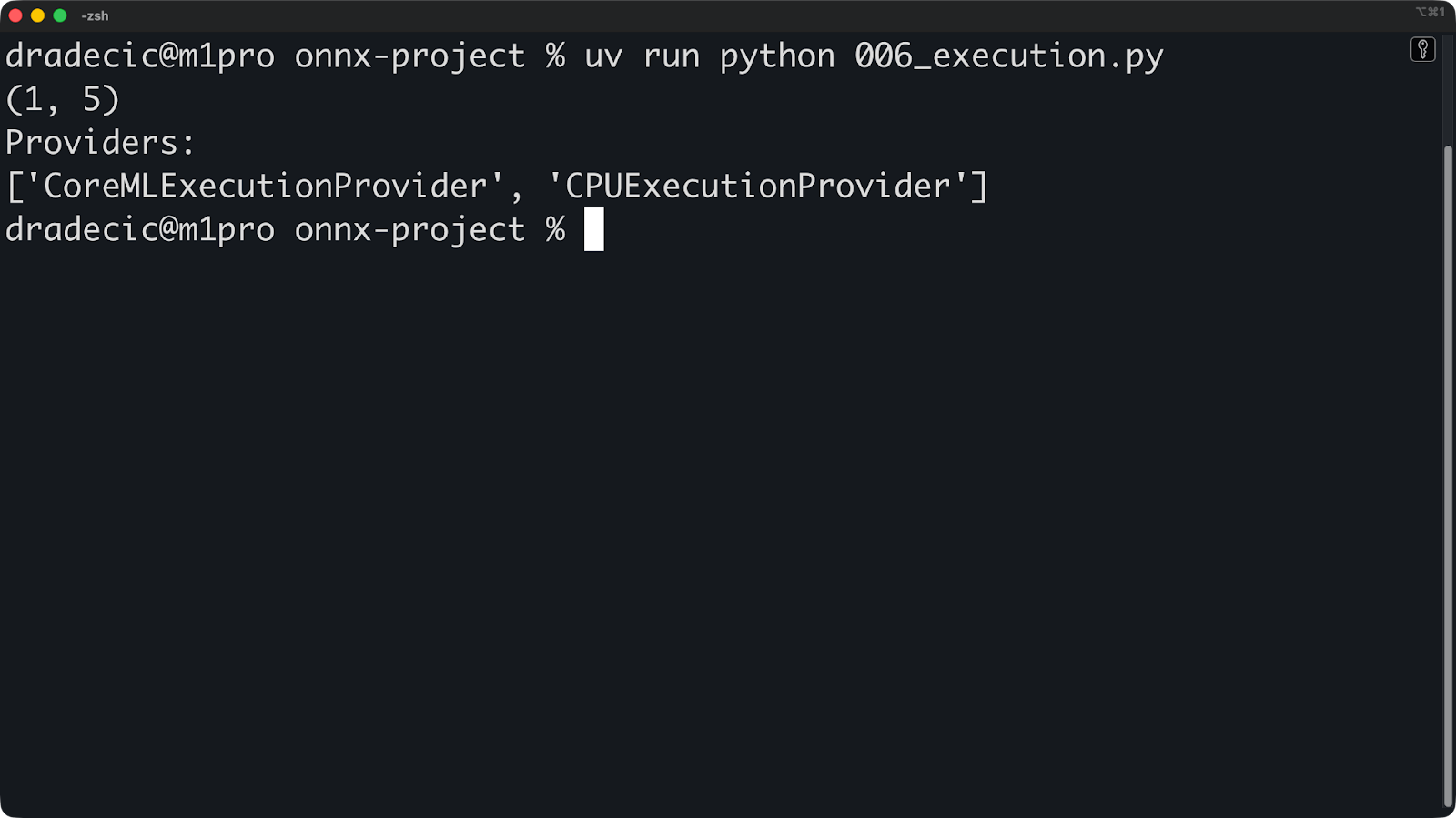
Si ves « ["CPUExecutionProvider"] » cuando esperas una GPU, significa que el proveedor de GPU no está disponible. Las causas más comunes pueden ser la falta de controladores, un paquete ONNX Runtime incorrecto o una GPU incompatible.
La configuración no termina aquí. Puedes optimizar aún más el proveedor de ejecución para obtener un mejor rendimiento:
providers = [
(
"TensorRTExecutionProvider",
{
"device_id": 0,
"trt_max_workspace_size": 2147483648, # 2GB
"trt_fp16_enable": True, # Use FP16 precision
},
),
"CUDAExecutionProvider",
"CPUExecutionProvider",
]
session = ort.InferenceSession("simple_model.onnx", providers=providers)Puedes consultar la documentación oficial de ONNX Runtime para obtener una lista de todas las opciones disponibles para el proveedor que elijas.
Lo impresionante de ONNX Runtime es que funciona en cualquier lugar: servidores, navegadores y dispositivos móviles.
ONNX Runtime Web lleva la inferencia a los navegadores mediante WebAssembly y WebGL. Tu modelo se ejecuta en el lado del cliente sin enviar datos a los servidores. Esto funciona muy bien para aplicaciones sensibles a la privacidad, como el análisis de imágenes médicas o el procesamiento de documentos.
A continuación, se muestra un ejemplo sencillo de cómo puedes utilizar ONNX Runtime en un archivo HTML sencillo:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>ONNXRuntime Web Demo</title>
</head>
<body>
<h1>ONNXRuntime Web Demo</h1>
<!-- Load ONNXRuntime-Web from CDN -->
<script src="<https://cdn.jsdelivr.net/npm/onnxruntime-web/dist/ort.min.js>"></script>
<script>
async function runModel() {
// Create inference session
const session = await ort.InferenceSession.create('./simple_model.onnx');
// Prepare input
const inputData = new Float32Array(10).fill(0).map(() => Math.random());
const tensor = new ort.Tensor('float32', inputData, [1, 10]);
// Run inference
const results = await session.run({ input: tensor });
const output = results.output;
console.log('Output shape:', output.dims);
console.log('Output values:', output.data);
}
runModel();
</script>
</body>
</html>
Para la implementación móvil, puedes utilizar ONNX Runtime Mobile, una versión ligera optimizada para iOS y Android. Elimina las funciones innecesarias y reduce el tamaño del archivo binario.
Este es un ejemplo de configuración para iOS:
import onnxruntime_objc
let modelPath = Bundle.main.path(forResource: "simple_model", ofType: "onnx")!
let session = try ORTSession(modelPath: modelPath)
let inputData = // Your input as Data
let inputTensor = try ORTValue(tensorData: inputData,
elementType: .float,
shape: [1, 10])
let outputs = try session.run(withInputs: ["input": inputTensor])O, si utilizas Python para crear una API REST, puedes incluir ONNX Runtime en uno de tus puntos de conexión siguiendo este procedimiento:
from fastapi import FastAPI
import onnxruntime as ort
import numpy as np
app = FastAPI()
session = ort.InferenceSession("simple_model.onnx")
@app.post("/predict")
async def predict(data: dict):
input_data = np.array(data["input"]).astype(np.float32)
outputs = session.run(None, {"input": input_data})
return {"prediction": outputs[0].tolist()}¡Y eso es todo! Otros entornos utilizarán un enfoque similar, pero ya te haces una idea: ONNX Runtime es fácil de usar. A continuación, hablemos de la optimización.
En esta sección, mostraré cómo hacer que los modelos ONNX sean más rápidos y pequeños mediante la cuantificación y las optimizaciones de gráficos. Te explicaré las técnicas más importantes para implementaciones en el mundo real.
La cuantificación reduce la precisión de tu modelo para hacerlo más rápido y pequeño.
En lugar de almacenar los pesos como números flotantes de 32 bits, los almacenas como números enteros de 8 bits. Esto reduce el uso de memoria en un 75 % y acelera la inferencia, ya que las operaciones matemáticas con números enteros son más rápidas que las operaciones matemáticas con números de coma flotante en la mayoría de los equipos.
La cuantificación dinámica convierte los pesos a una precisión menor, pero mantiene las activaciones (valores intermedios durante la inferencia) con toda su precisión. Es el método de cuantificación más sencillo, ya que no necesitas datos de calibración.
A continuación se explica cómo aplicar la cuantificación dinámica:
from onnxruntime.quantization import quantize_dynamic, QuantType
# Quantize the model
quantize_dynamic(
model_input="model.onnx",
model_output="model_quantized.onnx",
weight_type=QuantType.QUInt8 # 8-bit unsigned integers
)Eso es todo. Tu modelo cuantificado ahora utiliza enteros sin signo de 8 bits y está listo para usar.
La cuantificación estática convierte tanto los pesos como las activaciones a una precisión menor. Es más agresivo y rápido que la cuantificación dinámica, pero necesitas datos de calibración representativos para medir los rangos de activación.
A continuación, se presenta una estrategia general para aplicar la cuantificación estática:
from onnxruntime.quantization import quantize_static, CalibrationDataReader
import numpy as np
# Create a calibration data reader
class DataReader(CalibrationDataReader):
def __init__(self, calibration_data):
self.data = calibration_data
self.index = 0
def get_next(self):
if self.index >= len(self.data):
return None
batch = {"input": self.data[self.index]}
self.index += 1
return batch
# Load calibration data (100-1000 samples from your dataset)
calibration_data = [np.random.randn(1, 10).astype(np.float32)
for _ in range(100)]
data_reader = DataReader(calibration_data)
# Quantize
quantize_static(
model_input="model.onnx",
model_output="model_static_quantized.onnx",
calibration_data_reader=data_reader
)Los datos de calibración deben representar tu carga de trabajo de inferencia real, por lo que no utilices datos aleatorios como los que he mostrado anteriormente. Utiliza muestras reales de tu conjunto de datos.
En general, la cuantificación tiene algunas ventajas y desventajas que debes conocer como ingeniero de machine learning. Estas son las ventajas:
Y estas son las ventajas y desventajas:
La cuantificación también destaca en los modelos lingüísticos de gran tamaño y la IA generativa. Un modelo de 7B parámetros en FP32 ocupa 28 GB de memoria. Cuantificado a INT8, se reduce a 7 GB. Cuantificado a INT4, ocupa 3,5 GB, lo suficientemente pequeño como para ejecutarse en hardware de consumo.
Las optimizaciones gráficas reescriben el gráfico computacional de tu modelo para hacerlo más rápido.
El concepto de fusión de nodos combina múltiples operaciones en una sola operación. Si tu modelo tiene una capa Conv seguida de BatchNorm y luego ReLU, el optimizador las fusiona en un nodo e ConvBnRelu. Esto reduce el tráfico de memoria y acelera la ejecución.
Así es como se ve el gráfico antes de la fusión:
Input -> Conv -> BatchNorm -> ReLU -> OutputSe simplifica después de la fusión:
Input -> ConvBnRelu -> OutputHay dos conceptos más que debes conocer en lo que respecta a la optimización de gráficos:
Así es como puedes habilitar las optimizaciones de gráficos en ONNX Runtime:
import onnxruntime as ort
# Set optimization level
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# Create session with optimizations
session = ort.InferenceSession(
"simple_model.onnx",
sess_options,
providers=["CPUExecutionProvider"]
)ONNX Runtime tiene los siguientes niveles de optimización:
ORT_DISABLE_ALL: Sin optimizaciones (útil para la depuración)
ORT_ENABLE_BASIC: Optimizaciones seguras que no modifican los resultados numéricos
ORT_ENABLE_EXTENDED: Las optimizaciones agresivas pueden presentar pequeñas diferencias numéricas.
ORT_ENABLE_ALL: Todas las optimizaciones, incluidas las transformaciones de diseño.
Utiliza ORT_ENABLE_ALL para la producción. La aceleración compensa las pequeñas diferencias numéricas.
Puedes ejecutar este fragmento de código para guardar modelos optimizados y reutilizarlos:
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
sess_options.optimized_model_filepath = "model_optimized.onnx"
# This creates and saves the optimized model
session = ort.InferenceSession("simple_model.onnx", sess_options)Las optimizaciones de gráficos funcionan independientemente del marco en el que se haya creado el modelo. Un patrón PyTorch Conv-BN-ReLU y un patrón TensorFlow Conv-BN-ReLU se fusionan de la misma manera. Esta es la ventaja de la optimización compartida: escribes la optimización una vez y la aplicas a modelos de cualquier marco.
A continuación, hablemos del despliegue.
En esta sección, voy a repasar tres escenarios de implementación: dispositivos periféricos, infraestructura de nube y navegadores web. Te mostraré los retos y las soluciones para cada entorno.
El principal reto de los dispositivos periféricos es que tienen recursos limitados.
Tu teléfono inteligente tiene entre 4 y 16 GB de RAM. Una Raspberry Pi tiene aún menos. Los dispositivos IoT pueden tener 512 MB o menos. No puedes simplemente aplicar un modelo de 7B parámetros a estos dispositivos y esperar que funcione.
Empieza con la cuantificación. Los modelos INT8 deben ser tu referencia. Utiliza INT4 si puedes tolerar la pérdida de precisión. Esto hace que tu modelo sea lo suficientemente pequeño como para caber en la memoria.
Cuando se trata de implementar en dispositivos periféricos, ONNX Runtime Mobile es tu mejor aliado. Elimina las funciones del servidor que no necesitas y optimiza la duración de la batería. El binario es más pequeño, el arranque es más rápido y el consumo de energía es menor.
A continuación, te explicamos cómo puedes añadirlo a tu proyecto de aplicación móvil:
# iOS
pod 'onnxruntime-mobile-objc'
# Android
implementation 'com.microsoft.onnxruntime:onnxruntime-android:latest.version'Los proveedores de ejecución gestionan las diferencias de hardware. Los dispositivos Android utilizan CPU ARM, algunos tienen GPU de diferentes proveedores y los teléfonos más nuevos tienen NPU (unidades de procesamiento neuronal). No quieres escribir código para cada chip.
Consulta este fragmento de código para elegir el proveedor de ejecución adecuado:
# iOS - use CoreML for Apple Silicon optimization
session = ort.InferenceSession(
"simple_model.onnx",
providers=["CoreMLExecutionProvider", "CPUExecutionProvider"]
)
# Android - use NNAPI for hardware acceleration
session = ort.InferenceSession(
"simple_model.onnx",
providers=["NnapiExecutionProvider", "CPUExecutionProvider"]
)CoreML en iOS utiliza el Neural Engine (la NPU de Apple). NNAPI en Android utiliza cualquier acelerador que tenga tu dispositivo: GPU, DSP o NPU. El proveedor abstrae el hardware para que tu código permanezca igual. Cuando salga un nuevo chip con mejor rendimiento, solo tendrás que actualizar el proveedor de ejecución y tu aplicación funcionará más rápido sin necesidad de cambiar el código.
La implementación en la nube te ofrece una escalabilidad ilimitada y el hardware más reciente.
Puedes implementar modelos ONNX en cualquier nube: AWS, Azure, GCP o tus propios servidores. El patrón es el mismo: contenedoriza tu servicio de inferencia e impleméntalo detrás de un equilibrador de carga.
Aquí tienes un pequeño ejemplo de Python FastAPI:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import onnxruntime as ort
import numpy as np
import logging
app = FastAPI()
logger = logging.getLogger(__name__)
# Load model at startup
session = None
@app.on_event("startup")
async def load_model():
global session
session = ort.InferenceSession(
"simple_model.onnx",
providers=[
"CUDAExecutionProvider",
"CoreMLExecutionProvider",
"CPUExecutionProvider",
],
)
logger.info("Model loaded successfully")
class PredictionRequest(BaseModel):
input: list
class PredictionResponse(BaseModel):
prediction: list
inference_time_ms: float
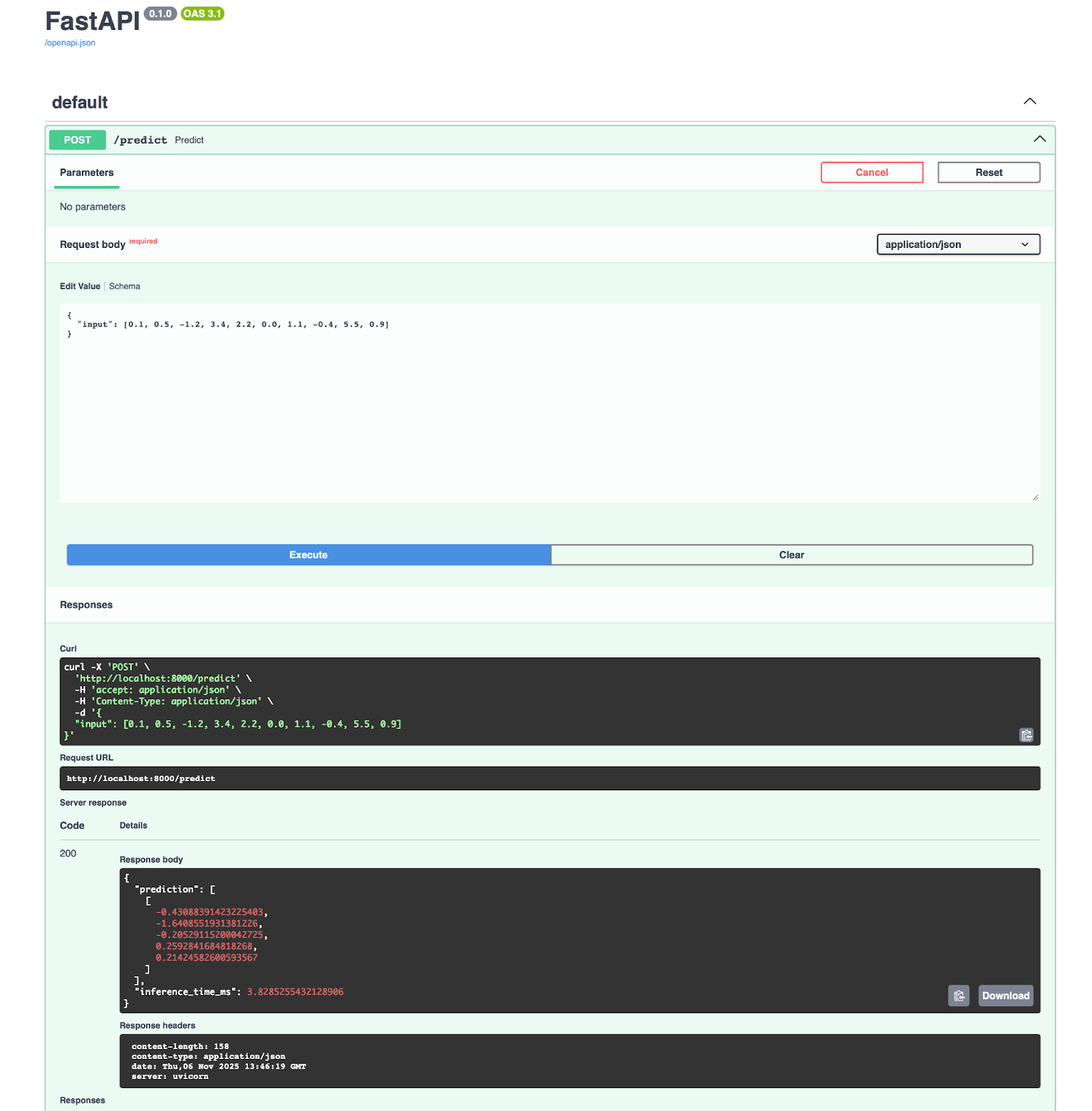
@app.post("/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
try:
import time
start = time.time()
# Input shape: (1, 10)
input_data = np.array(request.input, dtype=np.float32).reshape(1, 10)
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_data})
inference_time = (time.time() - start) * 1000
return PredictionResponse(
prediction=outputs[0].tolist(), inference_time_ms=inference_time
)
except Exception as e:
logger.error(f"Prediction failed: {str(e)}")
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health():
return {"status": "healthy", "model_loaded": session is not None}Este ejemplo de FastAPI, aunque pequeño, no es el más fácil de comprender para los ingenieros de machine learning. Puedes dominar los fundamentos con nuestro curso gratuito curso Introducción a FastAPI.
A continuación, puedes contenerizarlo con Docker:
FROM python:3.13-slim
WORKDIR /app
# Install dependencies
RUN pip install onnx onnxruntime onnxscript fastapi pydantic numpy uvicorn
# Copy model and code
COPY simple_model.onnx .
COPY main.py .
# Expose port
EXPOSE 8000
# Run the service
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]Todo entusiasta del machine learning debe conocer los conceptos básicos de Docker. Toma nuestra curso Introducción a Docker para aprender por fin a implementar un modelo de machine learning.
Obtendrás una aplicación que se ejecuta en el puerto 8000, en la que podrás abrir los documentos directamente y probar el punto final de predicción:
Si utilizas Azure Machine Learning, te alegrará saber que se integra directamente con ONNX. Puedes implementar tu modelo en tres pasos:
from azureml.core import Workspace, Model
from azureml.core.webservice import AciWebservice, Webservice
# Register model
ws = Workspace.from_config()
model = Model.register(
workspace=ws, model_path="simple_model.onnx", model_name="my-onnx-model"
)
# Deploy
deployment_config = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1)
service = Model.deploy(
workspace=ws,
name="onnx-service",
models=[model],
deployment_config=deployment_config,
)Azure se encarga del escalado, la supervisión y las actualizaciones. Obtienes registro automático, seguimiento de solicitudes y comprobaciones de estado.
Si eres nuevo en Azure Machine Learning, lee nuestra Guía para principiantes para aprender rápidamente los conceptos básicos.
Si hablamos de flujos de trabajo de MLOps necesitáis estos componentes:
Aquí tienes un fragmento de código que puedes utilizar:
import prometheus_client as prom
import onnxruntime as ort
import numpy as np
# Define metrics
inference_duration = prom.Histogram(
"model_inference_duration_seconds", "Time spent processing inference"
)
inference_count = prom.Counter("model_inference_total", "Total number of inferences")
# Load model
session = ort.InferenceSession("simple_model.onnx")
@app.post("/predict")
@inference_duration.time()
async def predict(request: PredictionRequest):
inference_count.inc()
# Input shape: (1, 10)
input_data = np.array(request.input, dtype=np.float32).reshape(1, 10)
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_data})
return {"prediction": outputs[0].tolist()}Desde ahí, puedes escalar horizontalmente ejecutando varias instancias de servicio detrás de un equilibrador de carga. ONNX Runtime no tiene estado, por lo que cualquier instancia puede gestionar cualquier solicitud.
ONNX Runtime Web ejecuta modelos directamente en navegadores utilizando WebAssembly y WebGL.
En lugar de enviar datos a un servidor, envías el modelo al navegador una vez y ejecutas la inferencia localmente. Los usuarios obtienen respuestas instantáneas sin latencia de red.
Para empezar, solo tienes que crear un archivo HTML que utilice un script JS en línea:
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<script src="<https://cdn.jsdelivr.net/npm/onnxruntime-web/dist/ort.min.js>"></script>
</head>
<body>
<script>
async function run() {
try {
const session = await ort.InferenceSession.create("simple_model.onnx", {
executionProviders: ["wasm"]
});
console.log("Session loaded:", session);
// Inspect names
console.log("Inputs:", session.inputNames);
console.log("Outputs:", session.outputNames);
const inputName = session.inputNames[0];
const inputData = new Float32Array(10).fill(0).map(() => Math.random());
const tensor = new ort.Tensor("float32", inputData, [1, 10]);
const feeds = {};
feeds[inputName] = tensor;
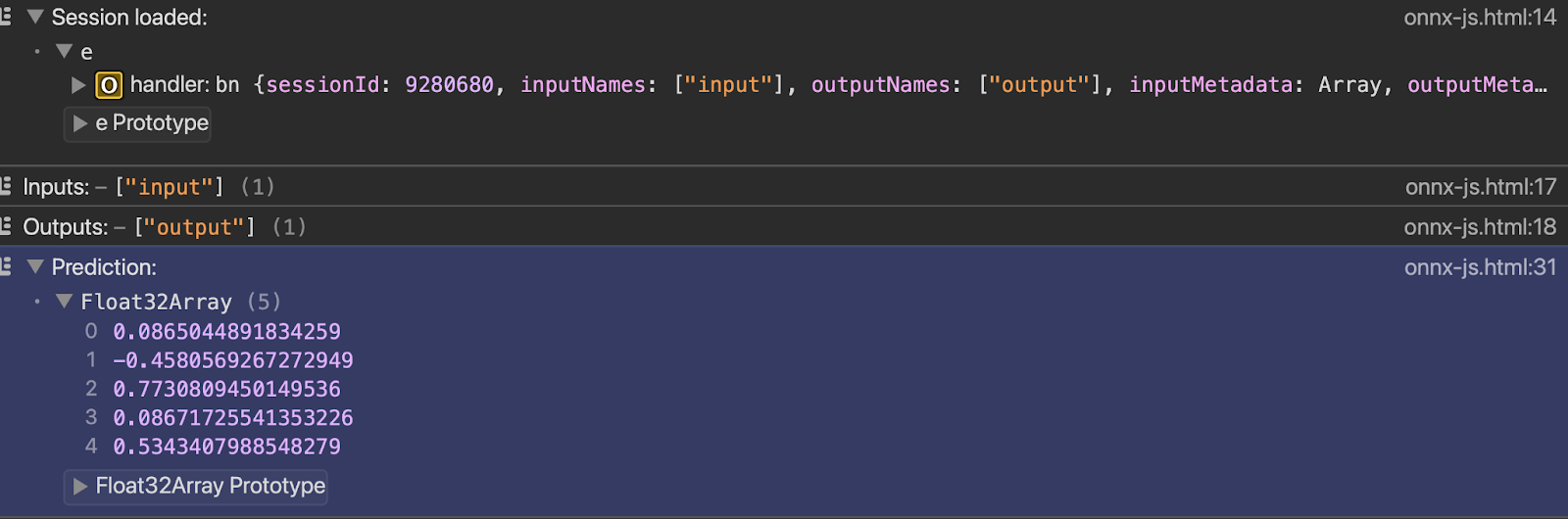
const results = await session.run(feeds);
const outputName = session.outputNames[0];
console.log("Prediction:", results[outputName].data);
} catch (err) {
console.error("ERROR:", err);
}
}
run();
</script>
</body>
</html>Podrás ver el resultado en la consola tan pronto como abras el archivo con el servidor en vivo:
Y, por último, hablemos de un par de temas avanzados.
Las operaciones estándar de ONNX cubren la mayoría de los casos de uso, pero si necesitas más, esta es la sección que te interesa.
Hablaré sobre los operadores personalizados y la implementación de modelos de lenguaje grandes. Te explicaré cuándo necesitas estas funciones avanzadas y qué ventajas e inconvenientes conllevan.
ONNX incluye cientos de operaciones, pero es posible que tu modelo utilice alguna específica.
Los operadores personalizados te permiten definir operaciones que no existen en el conjunto de operadores ONNX estándar. Tú mismo escribes la lógica de la operación e indicas a ONNX Runtime cómo ejecutarla. Esto amplía las capacidades integradas de ONNX.
¿Cuándo necesitas operadores personalizados? Cuando utilizas investigaciones de vanguardia que ONNX aún no admite. O cuando hayas creado operaciones propias específicas para tu dominio. O cuando necesitas optimizaciones específicas para el hardware que las operaciones estándar no pueden proporcionar.
Pero aquí está el problema: los operadores personalizados rompen la portabilidad. Tu modelo no funcionará en sistemas que no tengan tu implementación de operador personalizada. Si exportas un modelo PyTorch con operaciones personalizadas a ONNX, debes empaquetar esas operaciones por separado y registrarlas en ONNX Runtime.
La implementación se vuelve más difícil. Cada entorno necesita tu biblioteca de operadores personalizada. Los dispositivos periféricos, los servidores en la nube y los navegadores necesitan la misma implementación. Se pierde la mayor ventaja de ONNX: escribir una vez, ejecutar en cualquier lugar.
Aquí tienes un pequeño ejemplo práctico de operadores personalizados, para que puedas ver cómo funcionan:
import numpy as np
import onnxruntime as ort
from onnxruntime import InferenceSession, SessionOptions
# Define the custom operation
def custom_square(x):
return x * x
# Register the custom op with ONNX Runtime
# This tells ONNX Runtime how to execute "CustomSquare" operations
class CustomSquareOp:
@staticmethod
def forward(x):
return np.square(x).astype(np.float32)
# Create a simple ONNX model with a custom op using the helper
from onnx import helper, TensorProto
import onnx
# Create a graph with custom operator
node = helper.make_node(
"CustomSquare", # Custom operation name
["input"],
["output"],
domain="custom.ops", # Custom domain
)
graph = helper.make_graph(
[node],
"custom_op_model",
[helper.make_tensor_value_info("input", TensorProto.FLOAT, [1, 10])],
[helper.make_tensor_value_info("output", TensorProto.FLOAT, [1, 10])],
)
model = helper.make_model(graph)
onnx.save(model, "custom_op_model.onnx")
# To use this model, you'd need to implement the custom op in C++
# and register it with ONNX Runtime - Python-only custom ops aren't supported
print("Custom operator model created - requires C++ implementation to run")La mayoría de los equipos evitan los operadores personalizados siempre que es posible. Prueba primero con combinaciones de operaciones estándar. Opta por la personalización solo cuando las operaciones estándar no puedan expresar tu funcionamiento o cuando el rendimiento lo exija.
La memoria es un problema cuando se trata de los LLM. Un modelo de 7B parámetros necesita 28 GB en FP32, 14 GB en FP16 y 7 GB en INT8. La mayoría del hardware de consumo no puede soportar eso. Necesitas cuantificación, y a menudo cuantificación agresiva a INT4 o INT3.
Si eres nuevo en el mundo de los LLM y quieres aprender más, nuestro curso Conceptos de modelos de lenguaje grandes (LLM) es un excelente punto de partida.
La gestión de la caché KV es importante para la generación autorregresiva. Cada token que generes debe hacer referencia a todos los tokens anteriores. La caché crece con la longitud de la secuencia. Las conversaciones largas consumen memoria rápidamente. ONNX Runtime GenAI incluye un manejo optimizado de la caché KV que reutiliza la memoria y reduce la sobrecarga.
La velocidad de inferencia depende de tu hardware y del tamaño del modelo. Los modelos más pequeños (con menos de 3B parámetros) funcionan bien en las GPU de consumo. Los modelos más grandes necesitan múltiples GPU o aceleradores de inferencia especializados. ONNX Runtime admite la inferencia multi-GPU a través de proveedores de ejecución, pero es necesario dividir el modelo entre los dispositivos manualmente.
Flash Attention acelera el mecanismo de atención en los transformadores. La atención estándar es O(n²) en longitud de secuencia, lo que hace que se ralentice rápidamente. Flash Attention reduce el movimiento de la memoria y mejora la velocidad sin alterar los resultados. ONNX Runtime incluye optimizaciones de Flash Attention para el hardware compatible.
Es posible entrenar modelos LLM con ONNX Runtime, pero es poco habitual. La mayoría de los equipos entrenan con PyTorch o JAX y luego exportan a ONNX solo para la inferencia. ONNX Runtime Training existe para el ajuste fino y el preentrenamiento continuo, pero el ecosistema en torno al entrenamiento con PyTorch es más maduro.
Las cargas de trabajo de IA generativa reciben un tratamiento especial en ONNX Runtime. Las extensiones GenAI proporcionan API de alto nivel para la generación de texto, el mantenimiento del estado entre llamadas y la gestión de estrategias de búsqueda por haz o muestreo. Esto te evita tener que implementar tú mismo la lógica de generación.
El panorama de LLM cambia rápidamente, y las actualizaciones de ONNX Runtime hacen todo lo posible por mantenerse al día. El conjunto de operadores y las optimizaciones se actualizan periódicamente, pero siempre hay un desfase entre la investigación y el soporte listo para la producción.
Ahora ya sabes cómo convertir modelos de cualquier marco de trabajo, optimizarlos para su producción e implementarlos en cualquier lugar.
ONNX elimina la fricción entre el entrenamiento y la implementación. Entrena en PyTorch porque es ideal para la investigación. Implementa con ONNX Runtime porque es rápido y funciona en cualquier lugar. Cuantifica a INT8 y reduce tus costes de inferencia a la mitad. Cambia de CPU a GPU sin modificar el código. Traslada modelos entre proveedores de nube sin dependencia de un único proveedor.
ONNX es lo que lo hace posible.
El ecosistema sigue mejorando. La compatibilidad con la IA generativa mejora con cada versión: inferencia LLM más rápida, mejor gestión de la memoria y nuevas técnicas de optimización. La compatibilidad con hardware se amplía a más aceleradores y dispositivos periféricos. La comunidad crea herramientas que facilitan el uso de ONNX. Puedes participar probando nuevas funciones, informando de problemas o contribuyendo con código a través de los repositorios de GitHub.
¿Listo para el siguiente nivel? Maestría Conceptos de inteligencia artificial explicable (XAI) para dejar de pensar en los modelos como cajas negras.
Aprende con DataCamp
programa
Curso
Curso
blog
Natassha Selvaraj
15 min
Tutorial
Arjun Sarkar
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita

