Einzelverkäufer und kleine Marken haben meistens nicht das Geld für ein komplettes Produkt-Fotoshooting. In dieser Anleitung erstellen und starten wir eine Gradio-App, die ein einzelnes Eingabebild in e-commerce-taugliche Produktrenderings aus verschiedenen Blickwinkeln (Weitwinkel, Makro, ±45°, von oben) umwandelt. Dazu nutzen wir „ Qwen-Image-Edit-2509“ mit LoRA-basierten virtuellen Kamerasteuerungen für reproduzierbare KI-Produktfotografie.
Unter der Haube nutzen wir:
- Grundmodell:
Qwen/Qwen-Image-Edit-2509(Apache-2.0) - Winkelsteuerung LoRA:
dx8152/Qwen-Edit-2509-Multiple-angles - Optional speed LoRA:
lightx2v/Qwen-Image-Lightning
In diesem Tutorial lernst du, wie du:
- Lade die Qwen-Bearbeitungspipeline und stapele mehrere LoRAs.
- Steuere Kamerabewegungen mit robusten Winkelmakros.
- Entwickle eine übersichtliche Gradio-Benutzeroberfläche für Entwickler und E-Commerce-Teams.
- Speicher einfach alle Ergebnisse als ZIP-Datei, damit du sie schnell weitergeben kannst.
Wenn du mehr darüber erfahren möchtest, wie Bilddaten im Deep Learning verarbeitet werden, schau dir den Lernpfad „Bildverarbeitung in Python“.
Warum Qwen Image Edit mit mehreren Blickwinkeln LoRA verwenden?
Qwen-Image-Edit-2509 ist die neueste Version von Qwens Bildbearbeitungsmodell mit verbesserter Konsistenz und Multi-Bildbearbeitung. Das Multiple-Angles LoRA bringt zuverlässige „virtuelle Kamera”-Steuerungen rein, sodass du sagen kannst:
- Wechsel zum Weitwinkelobjektiv
- Die Kamera auf Nahaufnahme stellen
- Dreh die Linse um 45 Grad nach links.
- Die Kamera auf die Vogelperspektive umstellen
Diese Befehle formulieren dasselbe Produkt immer wieder neu, ohne dass es wie ein neues Produkt wirkt.
Schritt-für-Schritt-Anleitung zur Bildbearbeitung mit Qwen: Einen Produktfoto-Booster erstellen
In dieser Anleitung erstellen wir eine App, die ein einzelnes Produktbild in ein studiofähiges Winkel-Set verwandelt (einschließlich Winkeln wie Weitwinkel, Nahaufnahme, 45° links/rechts und von oben), mit optionalen Lifestyle-Voreinstellungen und einem schnellen Vorschaumodus. Es nutzt das Modell „ Qwen/Qwen-Image-Edit-2509 “ und ein Multiple-Angles-LoRA, verpackt in einer Gradio-Benutzeroberfläche.
Wir gehen von der Einrichtung der Umgebung über das Laden von Modellen und Generierungshilfen bis hin zu einer Web-Benutzeroberfläche.
Schritt 1: Was du brauchen solltest
Installiere zuerst alle Laufzeitabhängigkeiten. Wir nutzen PyTorch mit CUDA-Wheels, Hugging Face-Tools, die Diffusers-Bibliothek, Gradio für die Benutzeroberfläche und Pillow/OpenCV für die Bildverarbeitung.
pip install -q torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install -q transformers>=4.44.0 accelerate>=0.33.0 safetensors>=0.4.3
pip install -q pillow>=10.2.0 huggingface_hub>=0.24.0 opencv-python-headless>=4.9.0.80
pip install -q numpy>=1.26.0 gradio>=4.0.0
pip install -q git+https://github.com/huggingface/diffusersHier ist, was jede Voraussetzung macht:
- CUDA Wheels: Die PyTorch-Zeile zeigt auf NVIDIA CUDA 12.1-Wheels für die GPU-Beschleunigung.
- Transformatoren und Diffusoren: Transformers kümmert sich um Konfigurationen und Tokenizer, während Diffusers die „
QwenImageEditPlusPipeline“ bereitstellt. - Safetensors: Sie bieten ein sicheres Tensorformat (schneller und sicherer als Pickle).
- OpenCV-headless und Pillow-: Es bietet zuverlässige Bild-E/A und Größenanpassung für die Vor- und Nachbearbeitung.
- Gradio: Es ist eine schnelle Web-Benutzeroberfläche, die lokal und in Colab läuft.
Wenn alles fertig ist, können wir uns bei Hugging Face anmelden (optional) und Modelle laden.
Schritt 2: Hugging Face-Authentifizierung
Manche Modelle oder Adapter brauchen vielleicht eine Authentifizierung von HuggingFace. Mit diesem Schritt meldest du dich einmalig für die Sitzung an.
from huggingface_hub import login
import os
HF_TOKEN = "Your_HF_Token" # @param {type:"string"}
if HF_TOKEN:
login(token=HF_TOKEN)
print("Logged in to Hugging Face")
else:
print("WARNING: No token provided. Continuing without authentication")Melde dich erst mal bei deinem HuggingFace-Konto an und such in deinen Kontoeinstellungen nach den Zugriffstoken. Klick auf „Neues Token erstellen“ und mach ein neues Token mit dem Typ „Lesen“. Wähle die benötigten Berechtigungen aus und erstelle ein neues Token.
In der Produktion/Colab solltest du Tokens nicht fest codieren, sondern lieber Umgebungsvariablen oder Colab „Secrets” nutzen.
Schritt 3: Lade das Modell und richte die Pipeline ein.
In diesem Abschnitt richten wir die Qwen-Image-Edit-Pipeline ein, laden die Winkel LoRA und fügen einen Fast-Toggle mit GPU-bewussten Einstellungen hinzu. Beachte, dass dieser Code auf einer A100-GPU mit viel RAM gut läuft.
Schritt 3.1: Importe und GPU-Konfiguration
Jetzt importieren wir die Kernbibliotheken und erkennen die GPU, um Präzision, Attention Slicing und VAE Slicing automatisch für mehr Stabilität einzustellen.
import io
import zipfile
from typing import List, Tuple, Optional
import gc
import torch
from PIL import Image
from diffusers import QwenImageEditPlusPipeline
import gradio as gr
def get_gpu_config():
if not torch.cuda.is_available():
return {
'device': 'cpu',
'dtype': torch.float32,
'gpu_name': 'CPU',
'vram_gb': 0,
'max_batch': 1,
'enable_attention_slicing': True,
'enable_vae_slicing': True,
}
gpu_name = torch.cuda.get_device_name(0)
vram_gb = torch.cuda.get_device_properties(0).total_memory / 1e9
if 'T4' in gpu_name or vram_gb < 20:
return {
'device': 'cuda',
'dtype': torch.bfloat16,
'gpu_name': gpu_name,
'vram_gb': vram_gb,
'max_batch': 1,
'enable_attention_slicing': True,
'enable_vae_slicing': True,
}
else:
return {
'device': 'cuda',
'dtype': torch.bfloat16,
'gpu_name': gpu_name,
'vram_gb': vram_gb,
'max_batch': 2,
'enable_attention_slicing': False,
'enable_vae_slicing': False,
}
gpu_config = get_gpu_config()
HF_BASE_MODEL = "Qwen/Qwen-Image-Edit-2509"
LORA_ANGLES = "dx8152/Qwen-Edit-2509-Multiple-angles"
LORA_LIGHTNING = "lightx2v/Qwen-Image-Lightning"
ANGLE_MACROS = {
"Wide-angle": "将镜头转为广角镜头",
"Close-up": "将镜头转为特写镜头",
"Forward": "将镜头向前移动",
"Left": "将镜头向左移动",
"Right": "将镜头向右移动",
"Down": "将镜头向下移动",
"Rotate 45° Left": "将镜头向左旋转45度",
"Rotate 45° Right": "将镜头向右旋转45度",
"Top-down": "将镜头转为俯视",
}
BACKGROUND_PRESETS = {
"(None)": None,
"Pure Studio (white seamless)": "in a professional studio with seamless white background, soft shadows, product centered",
"Soft Gray Studio": "in a professional studio with seamless soft gray background, gentle vignette, softbox lighting",
"Lifestyle (cozy desk)": "on a cozy wooden desk near a window, soft natural light, minimal props",
"Lifestyle (marble)": "on a clean white marble surface, bright daylight, subtle reflections",
"Lifestyle (outdoor)": "outdoors on a neutral table, soft shade, bokeh background",
}
ASPECT_RATIOS = {
"1:1 (Square)": (1024, 1024),
"4:3 (Standard)": (1024, 768),
"3:4 (Portrait)": (768, 1024),
"16:9 (Widescreen)": (1024, 576),
"9:16 (Mobile)": (576, 1024),
"3:2 (Photo)": (1024, 683),
"2:3 (Portrait Photo)": (683, 1024),
}Hier sind die wichtigsten Teile der obigen Code-Blöcke:
- Automatische GPU-Konfiguration (
get_gpu_config-Funktion): Wir checken, welcher Beschleuniger verfügbar ist, und geben ein kleines Konfigurationswörterbuch zurück, mit dem man das Gerät (CPU/CUDA), den Datentyp (wie bfloat16 auf der GPU) und das Speicherverhalten auswählen kann: - Auf der CPU verwenden wir standardmäßig float32 und aktivieren aus Sicherheitsgründen Attention/VAE-Slicing.
- Bei T4 / <20 GB VRAM behalten wir bfloat16 bei, aktivieren aber Slicing, um OOMs zu vermeiden.
- Bei GPUs mit mehr als 20 GB (wie A100) deaktivieren wir das Slicing und lassen größere Batches zu, um die Geschwindigkeit zu erhöhen.
- Modell-IDs und Adapter: Wir laden „
Qwen-Image-Edit-2509“ als Haupteditor, zusammen mit „Multiple-angles LoRA“ für die Kamerasteuerung, und mischen optional „Lightning LoRA“ ein, wenn du auf den Schnellmodusumschalten. HF_BASE_MODEL = "Qwen/Qwen-Image-Edit-2509"ist das wichtigste Tool für die Bildbearbeitung.LORA_ANGLES = "dx8152/Qwen-Edit-2509-Multiple-angles"fügt Steuerelemente für die „virtuelle Kamera“ hinzu.LORA_LIGHTNING = "lightx2v/Qwen-Image-Lightning"ist ein optionaler Geschwindigkeitsadapter für schnelle Vorschauen.
Hey, nur mal so als Hinweis: Für den HQ-Modusbleibt nur der Winkeladapter aktiv.
- Winkelmakros:
ANGLE_MACROS ordnet Bezeichnungen wie „Weitwinkel“ oder „Von oben“ den entsprechenden chinesischen Befehlen zu, die LoRA zuverlässig versteht. Diese Befehle bewegen die virtuelle Kamera immer gleich (bewegen/drehen/zoomen), ohne dass sich die Identität ändert. - Hintergrundvoreinstellungen:
BACKGROUND_PRESETS sind kurze englische Ausdrücke wie „Marmoroberfläche“ oder „weiches graues Studio“, die wir in die endgültige Eingabeaufforderung einbauen. Sie sind orthogonal zu den Winkelmakros und kümmern sich um die Steuerung der Szene. - Seitenverhältnisse (
ASPECT_RATIOS): Damit können wir Leinwände (1:1, 4:3, 16:9 usw.) erstellen und die Eingabe vor der Inferenz in der Größe anpassen oder zentrieren, sodass die Ausgaben nach der Generierung nicht mehr zugeschnitten werden müssen.
Wir haben jetzt die GPU und die Adapter eingerichtet. Lass uns die Diffusers-Pipeline instanziieren und als Nächstes die LoRAs anschließen.
Schritt 3.2: Pipeline
Als Nächstes laden wir die Basis-Pipeline „Qwen Edit“, aktivieren Speicheroptimierungen entsprechend der GPU und stapeln „Multiple-Angles LoRA“. Wir haben auch einen Modus-Schalter eingebaut, mit dem du Lightning LoRA für schnelle Vorschauen hinzufügen kannst.
pipe = QwenImageEditPlusPipeline.from_pretrained(
HF_BASE_MODEL,
torch_dtype=gpu_config['dtype'],
)
pipe = pipe.to(gpu_config['device'])
if gpu_config['enable_attention_slicing']:
pipe.enable_attention_slicing()
if gpu_config['enable_vae_slicing']:
pipe.enable_vae_slicing()
pipe.load_lora_weights(LORA_ANGLES, adapter_name="angles")
current_mode = {"fast": False}
def set_pipeline_mode(use_lightning: bool):
global current_mode
if use_lightning and not current_mode["fast"]:
pipe.load_lora_weights(LORA_LIGHTNING, adapter_name="lightning")
pipe.set_adapters(["angles", "lightning"], adapter_weights=[1.0, 1.0])
current_mode["fast"] = True
elif not use_lightning and current_mode["fast"]:
pipe.set_adapters(["angles"], adapter_weights=[1.0])
current_mode["fast"] = False
elif not use_lightning and not current_mode["fast"]:
pipe.set_adapters(["angles"], adapter_weights=[1.0])
set_pipeline_mode(False)Der obige Code ist die Pipeline-Setup-Ebene für die App „Product Shot Booster“, die folgende Funktionen hat:
- Pipeline-Initialisierung: Es instanziiert das „
QwenImageEditPlusPipeline” aus dem Basismodell (Qwen/Qwen-Image-Edit-2509), verschiebt es auf das erkannte Gerät (CPU/GPU) und stellt die Tensor-Genauigkeit (torch_dtype) entsprechend deiner Hardware ein. - Speichersicherheit: Bei kleineren GPUs sorgt es dafür, dass die Aufmerksamkeit und das VAE-Slicing den Spitzenbedarf an VRAM reduzieren und Speicherfehler vermeiden, während ein bisschen Geschwindigkeit für mehr Stabilität geopfert wird.
- LoRA composition: Es lädt das Multiple-Angles-LoRA, um wiederholbare „virtuelle Kamera“-Steuerungen (bewegen/drehen/zoomen) zu bieten, und mischt optional das Lightning-LoRA für schnellere Vorschauen.
- Modusumschaltlogik: Die Hilfsfunktion „
set_pipeline_mode()“ und das Flag „current_mode“ regeln den HQ- und Fast-Status, verhindern unnötige Lightning-Neuladungen und lassen dich zwischen Adaptern wechseln.
Jetzt ist die Pipeline fertig. Kommen wir jetzt zu den Funktionen zur Generierung von Verkabelungen und der Gradio-Benutzeroberfläche.
Schritt 4: Generierungsfunktionen
Die Generierungsfunktionen machen die Stromerzeugung, indem sie Eingabeaufforderungen erstellen, die Größe an das gewünschte Seitenverhältnis anpassen, die Pipeline über ausgewählte Winkel laufen lassen und die Ergebnisse zum Download in einer ZIP-Datei verpacken.
Schritt 4.1: Prompt Composer und Bildgrößenänderungs-Helfer
Bevor wir das Modell aufrufen, normalisieren wir die Eingaben mit zwei stateless Helfern:
compose_prompt()Funktion: Diese Funktion setzt einen einzigen Befehlsstring aus Kamerawinkel, Hintergrundvoreinstellung, benutzerdefinierter Szene und Stilhinweisen zusammen. Kurze Sätze helfen dabei, die Analyse von Qwens Anweisungen stabil zu halten und verhindern, dass ein Teil überbewertet wird.resize_image()Funktion: Das Quellbild wird mit einer Skalierungsstrategie an das Zielseitenverhältnis angepasst, die Lanczos-Resampling-Funktion sorgt für hochwertiges Verkleinern/Vergrößern und ein zentrierter Ausschnitt sorgt dafür, dass das Hauptmotiv im Bild bleibt.
def compose_prompt(angle_phrase: str,
bg_preset_text: Optional[str],
custom_scene: str,
extra_style: str) -> str:
parts = [angle_phrase]
if bg_preset_text:
parts.append(f"{bg_preset_text}")
if custom_scene.strip():
parts.append(custom_scene.strip())
if extra_style.strip():
parts.append(extra_style.strip())
return " | ".join(parts)
def resize_image(img: Image.Image, target_size: Tuple[int, int]) -> Image.Image:
target_w, target_h = target_size
orig_w, orig_h = img.size
scale = max(target_w / orig_w, target_h / orig_h)
new_w = int(orig_w * scale)
new_h = int(orig_h * scale)
img = img.resize((new_w, new_h), Image.Resampling.LANCZOS)
left = (new_w - target_w) // 2
top = (new_h - target_h) // 2
img = img.crop((left, top, left + target_w, top + target_h))
return imgDie beiden oben genannten Funktionen machen Folgendes:
- Zusammenstellbare Eingabeaufforderung: Wir verbinden Teile mit „ | “, damit die Satzteile optisch klar voneinander getrennt sind, während Qwen-Edit die Zeichensetzung übernimmt und für eine konsistente Analyse sorgt, ohne den letzten Satzteil zu bevorzugen. Wir nutzen auch „
.strip()“ mit Benutzertest, um leere Fragmente zu vermeiden. - Mathe zum Vergrößern: Das sorgt dafür, dass das Bild in beiden Dimensionen die Zielfläche komplett ausfüllt.
- Lanczos-Resampling: Das ist ein hochwertiger Filter, der beim Downsampling feine Details beibehält und beim Upscaling Aliasing reduziert.
- Mittlere Ausschnitt: Nach der Größenänderung schneiden wir die genaue Zielfläche aus der Mitte aus, um die typische Komposition zu behalten und unerwartete, nicht mittige Schnitte zu vermeiden.
Jetzt, wo die Helfer bereit sind, können wir eine Schleife zur Erzeugung mehrerer Blickwinkel ausführen und die Ergebnisse zusammenfassen.
Schritt 4.2: Bilder erstellen
Als Nächstes checken wir die Eingaben, passen das Bild an das gewählte Seitenverhältnis an, durchlaufen die ausgewählten Winkel und lassen die Pipeline in „ inference_mode “ laufen. Zum Schluss liefern wir eine ZIP-Datei mit allen erstellten Bildern.
def generate_images(
source_img: Image.Image,
angle_keys: List[str],
bg_key: str,
custom_scene: str,
extra_style: str,
aspect_ratio: str,
use_lightning: bool,
seed: int,
steps: int,
guidance_scale: float,
true_cfg_scale: float,
images_per_prompt: int,
progress=gr.Progress()
) -> List[Image.Image]:
if source_img is None:
return [], "WARNING: Please upload an image first!"
if not angle_keys:
return [], "WARNING: Please select at least one angle!"
target_size = ASPECT_RATIOS[aspect_ratio]
source_img = resize_image(source_img, target_size)
set_pipeline_mode(use_lightning)
results = []
generator = torch.manual_seed(seed)
bg_preset_text = BACKGROUND_PRESETS.get(bg_key)
total_angles = len(angle_keys)
for idx, angle_name in enumerate(angle_keys):
progress((idx + 1) / total_angles, f"Generating {angle_name}...")
angle_phrase = ANGLE_MACROS[angle_name]
full_prompt = compose_prompt(angle_phrase, bg_preset_text, custom_scene, extra_style)
inputs = {
"image": [source_img],
"prompt": full_prompt,
"generator": generator,
"true_cfg_scale": true_cfg_scale,
"negative_prompt": " ",
"num_inference_steps": steps,
"guidance_scale": guidance_scale,
"num_images_per_prompt": images_per_prompt,
"height": target_size[1],
"width": target_size[0],
}
with torch.inference_mode():
out = pipe(**inputs)
for img_idx, im in enumerate(out.images):
results.append(im)
if 'T4' in gpu_config['gpu_name']:
torch.cuda.empty_cache()
return results
def create_zip(images: List[Image.Image]) -> Optional[str]:
if not images:
return None
zip_path = "/content/product_shot_booster.zip"
with zipfile.ZipFile(zip_path, mode="w", compression=zipfile.ZIP_DEFLATED) as zf:
zf.writestr("manifest.txt", "Product Shot Booster Export\nGenerated angles exported as PNG files.\n")
for idx, img in enumerate(images):
buf = io.BytesIO()
img.save(buf, format="PNG")
zf.writestr(f"angle_{idx+1:03d}.png", buf.getvalue())
return zip_pathDie Funktion „ generate_images() “ macht es möglich, mehrere Winkel zu erzeugen und zu exportieren, indem sie:
- Überprüfen, normalisieren und einrichten: Es sucht nach einem hochgeladenen Bild und ausgewählten Blickwinkeln, passt das Bild dann an das gewählte Seitenverhältnis an (Größe ändern und zentrieren) und wechselt über „
set_pipeline_mode(use_lightning)“ zwischen HQ- und Fast-Modus. - Effiziente Schlussfolgerung: Für jeden Winkel wird eine einzelne Befehlszeichenfolge erstellt, die das Winkelmakro, die Hintergrundvoreinstellung, die Szene und den Stil enthält. Dann bereitet es die Diffusor-Eingaben vor und läuft unter
torch.inference_mode(), um Speicherplatz zu sparen. Bei GPUs mit wenig VRAM (wie einer T4) helfen Aufrufe wie „torch.cuda.empty_cache()“ pro Winkel, die Fragmentierung zu reduzieren. - Ergebnisse mit UI-Feedback zusammenfassen: Es aktualisiert endlich den Fortschritt von Gradio, wenn jeder Winkel fertig ist, und sammelt alle Ausgaben in einer Liste, damit sie später komprimiert werden können.
Die Funktion „ create_zip(images) “ macht einen portablen Export, der eine ZIP-Datei mit einer kurzen „ manifest.txt“ schreibt und Bilder über In-Memory (BytesIO) für verlustfreie Dateien codiert und None zurück, wenn keine Bilder vorhanden sind.
Sobald die Erstellung und Verpackung fertig sind, kann die Benutzeroberfläche einen Multi-Angle-Pass starten und das komplette Winkelpaket mit einem Klick zum Download anbieten.
Schritt 5: Gradio-Benutzeroberfläche
Mit dieser Benutzeroberfläche kannst du Produktbilder hochladen, Blickwinkel und Seitenverhältnisse auswählen, eine Hintergrundvorlage aussuchen, Stilhinweise festlegen und Bilder aus mehreren Blickwinkeln im Handumdrehen erstellen.
with gr.Blocks(title="Product Shot Booster", theme=gr.themes.Soft()) as demo:
gr.Markdown("<h1 style='text-align: center;font-weight: bold;'>Product Shot Booster</h1>")
with gr.Row():
with gr.Column(scale=1):
input_image = gr.Image(
label="Product Image",
type="pil",
height=300
)
angle_choices = gr.CheckboxGroup(
choices=list(ANGLE_MACROS.keys()),
value=["Wide-angle", "Close-up", "Rotate 45° Left", "Rotate 45° Right", "Top-down"],
label="Camera Angles"
)
aspect_ratio = gr.Dropdown(
choices=list(ASPECT_RATIOS.keys()),
value="1:1 (Square)",
label="Aspect Ratio"
)
bg_preset = gr.Dropdown(
choices=list(BACKGROUND_PRESETS.keys()),
value="(None)",
label="Background"
)
custom_scene = gr.Textbox(
label="Custom Scene",
placeholder="e.g., 'on a matte black table with soft reflections'",
lines=2
)
extra_style = gr.Textbox(
label="Style Notes",
value="studio-grade lighting, high clarity, ecommerce-ready composition",
lines=2
)
with gr.Column(scale=2):
output_gallery = gr.Gallery(
label="Generated Images",
show_label=True,
columns=3,
height="auto",
object_fit="contain"
)
info_output = gr.Markdown("")
zip_output = gr.File(label="Download ZIP")
with gr.Accordion("Advanced Settings", open=False):
with gr.Row():
use_lightning = gr.Checkbox(
label="Fast Mode (Lightning LoRA)",
value=('T4' in gpu_config['gpu_name']),
info="Enable for faster generation (recommended for T4)"
)
seed = gr.Number(
label="Seed",
value=123,
precision=0
)
steps = gr.Slider(
label="Inference Steps",
minimum=10,
maximum=60,
value=28,
step=1
)
with gr.Row():
guidance_scale = gr.Slider(
label="Guidance Scale",
minimum=0.0,
maximum=8.0,
value=1.0,
step=0.1
)
true_cfg_scale = gr.Slider(
label="True CFG Scale",
minimum=0.0,
maximum=10.0,
value=4.0,
step=0.1
)
images_per_prompt = gr.Slider(
label="Images per Angle",
minimum=1,
maximum=4,
value=1,
step=1
)
generate_btn = gr.Button("Generate", variant="primary", size="lg")
def generate_and_zip(*args):
images = generate_images(*args)
zip_file = create_zip(images) if images else None
return images, zip_file
generate_btn.click(
fn=generate_and_zip,
inputs=[
input_image,
angle_choices,
bg_preset,
custom_scene,
extra_style,
aspect_ratio,
use_lightning,
seed,
steps,
guidance_scale,
true_cfg_scale,
images_per_prompt
],
outputs=[output_gallery, zip_output]
)
demo.launch(share=True, debug=True, show_error=True)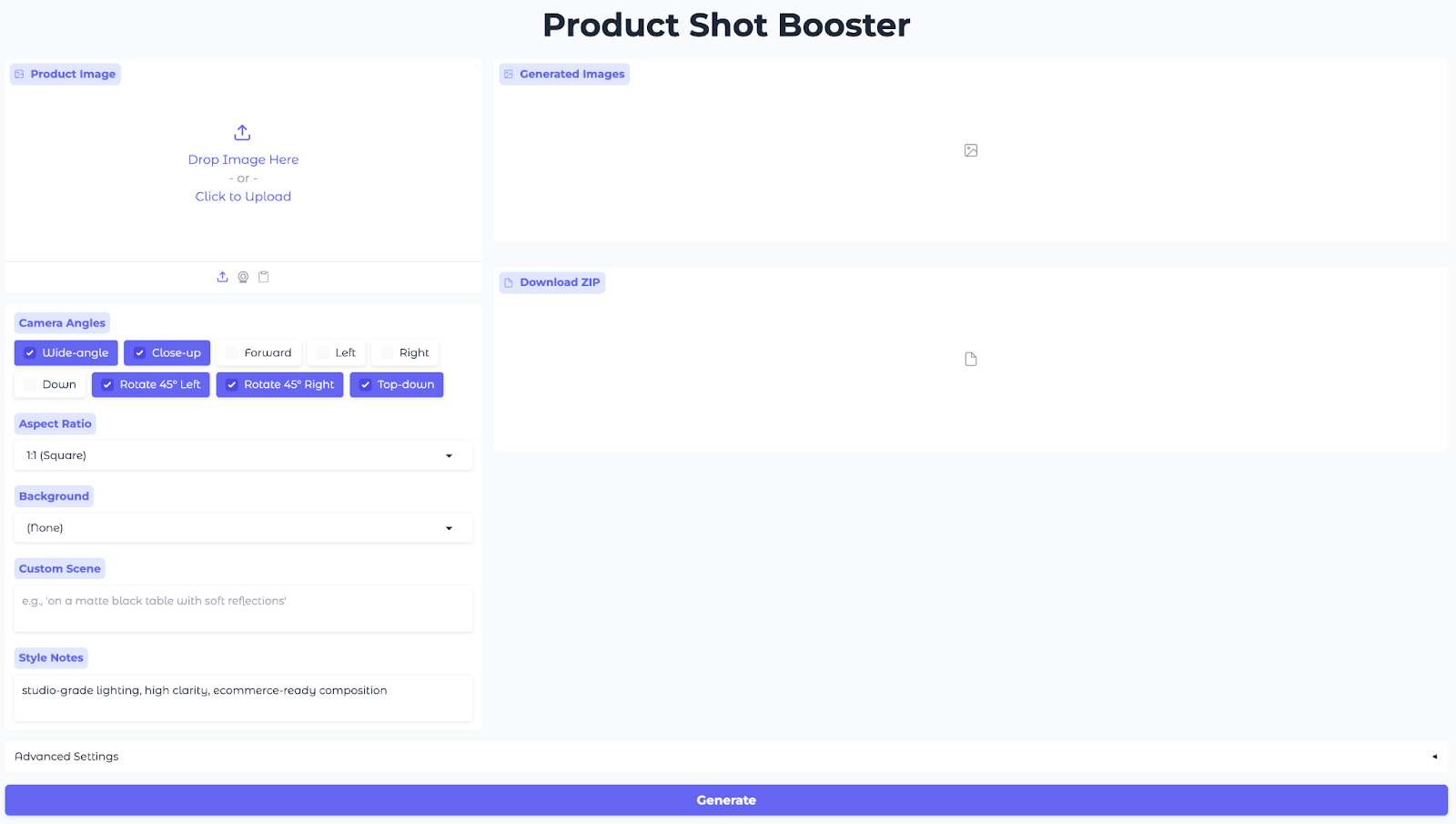
Der obige Code erstellt eine interaktive Gradio-App, die eine einzelne Generierungsaktion mit der Inferenz verbindet und eine gemeinsam nutzbare Web-Benutzeroberfläche bereitstellt, indem sie Folgendes verwendet:
- Eingaben (linke Spalte): Im linken Bereich wird alles zusammengestellt, was das Modell braucht: mit „
gr.Image“ kannst du Produktfotos hochladen, „gr.CheckboxGroup“ ist für Kamerawinkel, zwei „gr.Dropdowns“ für Seitenverhältnis und Hintergrundvoreinstellungen und zwei „gr.Textbox“-Felder für benutzerdefinierte Szenen und Stilnotizen, um das Aussehen zu optimieren. - Ausgaben (rechte Spalte): Die Funktion „
gr.Gallery“ zeigt alle erstellten Winkel in einem Raster an, sodass du die Kompositionen auf einen Blick vergleichen kannst. Die Komponente „gr.File“ bietet ZIP-Dateien mit PNGs zum schnellen Download. - Erweiterte Einstellungen: Mit „
gr.Checkbox“ kannst du den Fast Mode (Lightning LoRA) für schnelle Vorschauen auf T4-Klasse-GPUs aktivieren, während „Seed“ und „Steps“ die Reproduzierbarkeit und den Kompromiss zwischen Qualität und Zeit einstellen. „Guidance“ und „True-CFG“ steuern die Bearbeitungsstärke im Verhältnis zur Identitätsstabilität, und mit „Images per Angle“ kannst du mehrere Varianten pro Kameramakro auf einmal erstellen. - Schnittstellenverkabelung (Aktion): Ein einziger„ “-Button verbindet alle Eingaben mit der Funktion „
generate_images()“ (die Qwen Edit mit den ausgewählten Adaptern ausführt) und dann mit der Funktion „create_zip()“ (die die Ausgaben packt) und schickt sowohl die Galerie als auch die ZIP-Datei zurück zur Benutzeroberfläche. - App-Start: Schließlich startet die Methode „
demo.launch()“ die Web-App und gibt eine öffentliche Freigabe-URL raus – super für Colab-Sessions, schnelle Demos oder um Leuten einen Link zu schicken, damit sie das Tool selbst ausprobieren können.
Zum Schluss klickst du auf Generieren und schau dir das gerenderte Vollwinkelpaket an.
Hier sind die Ergebnisse meiner Experimente mit diesem Modell. Zuerst kannst du sehen, wie die Produkte je nach den verschiedenen eingestellten Parametern angezeigt werden.