Vendedores individuais e pequenas marcas raramente têm orçamento para uma sessão fotográfica completa do produto. Neste guia, vamos criar e rodar um aplicativo Gradio que transforma uma única imagem de entrada em renderizações de produtos com vários ângulos (amplo, macro, ±45°, de cima para baixo) prontas para comércio eletrônico, usando um Qwen-Image-Edit-2509 d com controles de câmera virtual baseados em LoRA para fotografia de produtos com IA reproduzível.
Por trás dos bastidores, a gente usa:
- Modelo básico:
Qwen/Qwen-Image-Edit-2509(Apache-2.0) - Controle de ângulo LoRA:
dx8152/Qwen-Edit-2509-Multiple-angles - Velocidade opcional LoRA:
lightx2v/Qwen-Image-Lightning
Neste tutorial, você vai aprender a:
- Carregue o pipeline de edição Qwen e empilhe vários LoRAs.
- Mova a câmera com macros de ângulo robustas.
- Crie uma interface de usuário Gradio simples para criadores e equipes de comércio eletrônico.
- Exporte todos os resultados como um arquivo ZIP para facilitar a transferência.
Se você quiser saber mais sobre como os dados de imagem são processados no aprendizado profundo, dê uma olhada na trilha de habilidades Processamento de imagens em Python.
Por que usar o Qwen Image Edit com múltiplos ângulos LoRA?
O Qwen-Image-Edit-2509 é a última versão do modelo de edição de imagens da Qwen, com consistência melhorada e edição de várias imagens. O Multiple-Angles LoRA injeta controles confiáveis de “câmera virtual” para que você possa dizer:
- Trocar a lente por uma grande angular
- Mudar a câmera para um close-up
- Gire a lente 45 graus para a esquerda.
- Mudar a câmera para uma visão de cima (top-down view)
Esses comandos reformulam consistentemente o mesmo produto sem criar a ilusão de um novo produto.
Tutorial passo a passo para editar imagens no Qwen: Criando um impulsionador de fotos de produtos
Neste guia, vamos criar um aplicativo que transforma uma única imagem de produto em um conjunto de ângulos prontos para estúdio (incluindo ângulos como amplo, close-up, 45° esquerda/direita e de cima para baixo), com predefinições opcionais de estilo de vida e modo de visualização rápida. Ele usa um model Qwen/Qwen-Image-Edit-2509 e e um Multiple-Angles LoRA dentro de uma interface Gradio.
Vamos passar da configuração do ambiente para o carregamento do modelo, auxiliares de geração e uma interface de usuário web.
Passo 1: Pré-requisitos
Primeiro, instale todas as dependências de tempo de execução. Usamos PyTorch com CUDA wheels, ferramentas Hugging Face, biblioteca Diffusers, Gradio para a interface do usuário e Pillow/OpenCV para processamento de imagens.
pip install -q torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install -q transformers>=4.44.0 accelerate>=0.33.0 safetensors>=0.4.3
pip install -q pillow>=10.2.0 huggingface_hub>=0.24.0 opencv-python-headless>=4.9.0.80
pip install -q numpy>=1.26.0 gradio>=4.0.0
pip install -q git+https://github.com/huggingface/diffusersAqui está o que cada pré-requisito faz:
- Rodas CUDA: A linha PyTorch aponta para as rodas NVIDIA CUDA 12.1 para aceleração de GPU.
- Transformadores e difusores: O Transformers cuida das configurações e tokenizadores, enquanto o Diffusers faz a transformação de texto em vetores (
QwenImageEditPlusPipeline). - Safetensors: Eles oferecem um formato tensor seguro (mais rápido e seguro que o Pickle).
- OpenCV-headless e Pillow: Ele oferece entrada/saída de imagem robusta e redimensionamento para pré/pós-processamento.
- Gradio: É uma interface de usuário rápida que funciona localmente e no Colab.
Com o ambiente pronto, podemos fazer a autenticação em Hugging Face (opcional) e carregar os modelos.
Passo 2: Autenticação Hugging Face
Alguns modelos ou adaptadores podem precisar de autenticação da HuggingFace. Esta etapa faz o login uma vez para a sessão.
from huggingface_hub import login
import os
HF_TOKEN = "Your_HF_Token" # @param {type:"string"}
if HF_TOKEN:
login(token=HF_TOKEN)
print("Logged in to Hugging Face")
else:
print("WARNING: No token provided. Continuing without authentication")Comece fazendo login na sua conta HuggingFace e procurando por Access Tokens nas configurações da sua conta. Clique em Criar novo token e gere um novo token com o tipo de token Leitura. Escolha as permissões que você precisa e crie um novo token.
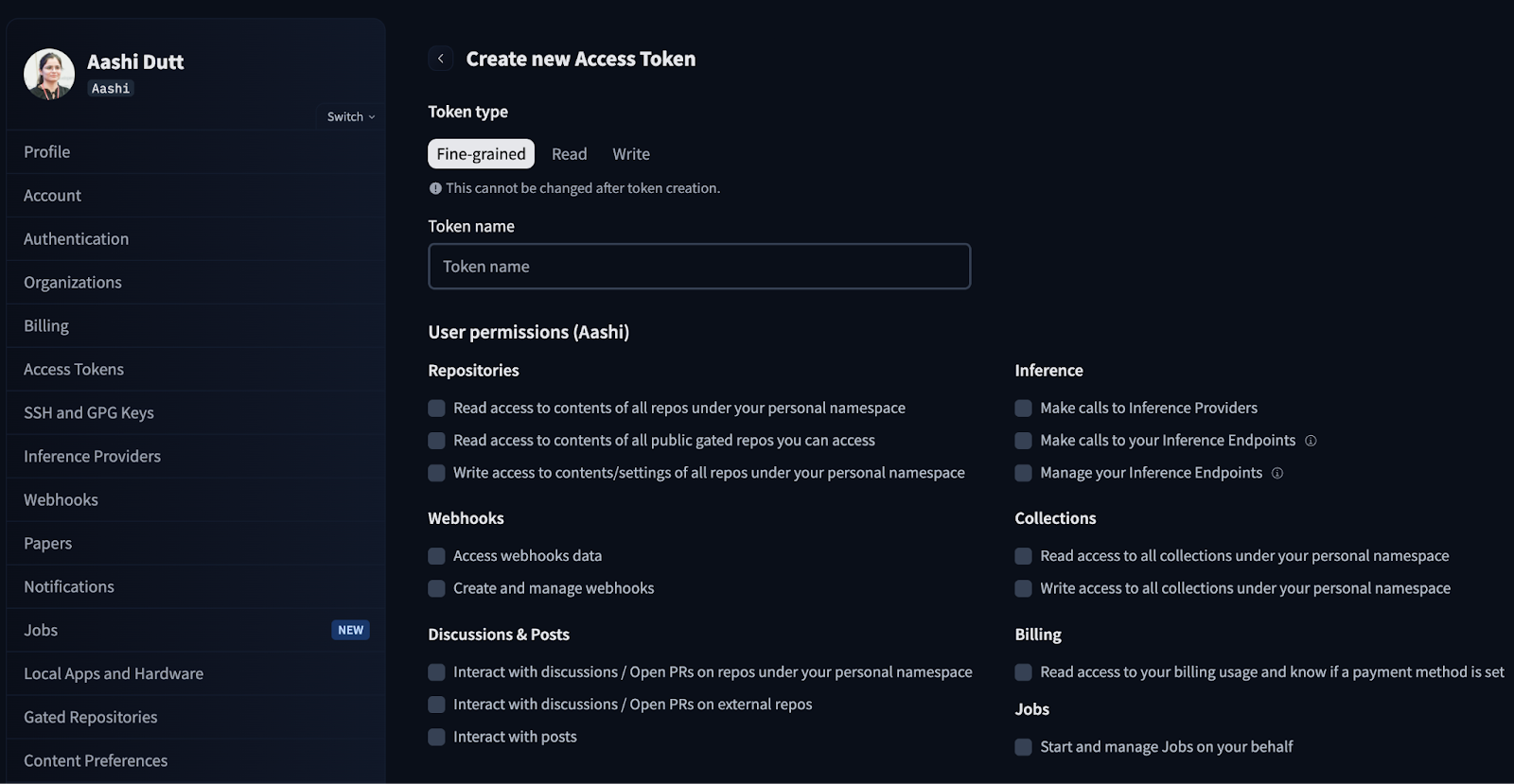
Na produção/Colab, não codifique tokens, use variáveis de ambiente ou “Segredos” do Colab.
Passo 3: Carregar modelo e configurar pipeline
Nesta seção, vamos configurar o pipeline Qwen-Image-Edit, carregar o LoRA angles e adicionar um Fast toggle com configurações compatíveis com GPU. Observe que esse código funciona bem em uma GPU A100 com muita RAM.
Passo 3.1: Importações e configuração da GPU
Agora, vamos importar as bibliotecas principais e detectar a GPU para definir automaticamente a precisão, o attention slicing e o VAE slicing para garantir a estabilidade.
import io
import zipfile
from typing import List, Tuple, Optional
import gc
import torch
from PIL import Image
from diffusers import QwenImageEditPlusPipeline
import gradio as gr
def get_gpu_config():
if not torch.cuda.is_available():
return {
'device': 'cpu',
'dtype': torch.float32,
'gpu_name': 'CPU',
'vram_gb': 0,
'max_batch': 1,
'enable_attention_slicing': True,
'enable_vae_slicing': True,
}
gpu_name = torch.cuda.get_device_name(0)
vram_gb = torch.cuda.get_device_properties(0).total_memory / 1e9
if 'T4' in gpu_name or vram_gb < 20:
return {
'device': 'cuda',
'dtype': torch.bfloat16,
'gpu_name': gpu_name,
'vram_gb': vram_gb,
'max_batch': 1,
'enable_attention_slicing': True,
'enable_vae_slicing': True,
}
else:
return {
'device': 'cuda',
'dtype': torch.bfloat16,
'gpu_name': gpu_name,
'vram_gb': vram_gb,
'max_batch': 2,
'enable_attention_slicing': False,
'enable_vae_slicing': False,
}
gpu_config = get_gpu_config()
HF_BASE_MODEL = "Qwen/Qwen-Image-Edit-2509"
LORA_ANGLES = "dx8152/Qwen-Edit-2509-Multiple-angles"
LORA_LIGHTNING = "lightx2v/Qwen-Image-Lightning"
ANGLE_MACROS = {
"Wide-angle": "将镜头转为广角镜头",
"Close-up": "将镜头转为特写镜头",
"Forward": "将镜头向前移动",
"Left": "将镜头向左移动",
"Right": "将镜头向右移动",
"Down": "将镜头向下移动",
"Rotate 45° Left": "将镜头向左旋转45度",
"Rotate 45° Right": "将镜头向右旋转45度",
"Top-down": "将镜头转为俯视",
}
BACKGROUND_PRESETS = {
"(None)": None,
"Pure Studio (white seamless)": "in a professional studio with seamless white background, soft shadows, product centered",
"Soft Gray Studio": "in a professional studio with seamless soft gray background, gentle vignette, softbox lighting",
"Lifestyle (cozy desk)": "on a cozy wooden desk near a window, soft natural light, minimal props",
"Lifestyle (marble)": "on a clean white marble surface, bright daylight, subtle reflections",
"Lifestyle (outdoor)": "outdoors on a neutral table, soft shade, bokeh background",
}
ASPECT_RATIOS = {
"1:1 (Square)": (1024, 1024),
"4:3 (Standard)": (1024, 768),
"3:4 (Portrait)": (768, 1024),
"16:9 (Widescreen)": (1024, 576),
"9:16 (Mobile)": (576, 1024),
"3:2 (Photo)": (1024, 683),
"2:3 (Portrait Photo)": (683, 1024),
}Aqui estão os principais componentes dos blocos de código acima:
- Configuração automática da GPU (função
get_gpu_config): A gente detecta o acelerador disponível e devolve um pequeno dicionário de configuração que é usado pra escolher o dispositivo (CPU/CUDA), o tipo de dados (como bfloat16 na GPU) e os comportamentos da memória: - Na CPU, usamos float32 como padrão e ativamos o corte de atenção/VAE por segurança.
- No T4 / <20 GB de VRAM, a gente mantém o bfloat16, mas ativa o slicing pra evitar OOMs.
- Em GPUs de 20 GB+ (como A100), desativamos o corte e permitimos um lote maior para aumentar a velocidade.
- IDs de modelos e adaptadores: Carregamos o
Qwen-Image-Edit-2509como editor principal, junto com o Multiple-angles LoRA para controlar a câmera e, se quiser, podemos misturar o Lightning LoRA quando você alternar para o Modo Rápido. HF_BASE_MODEL = "Qwen/Qwen-Image-Edit-2509"é a principal ferramenta de edição de imagens.LORA_ANGLES = "dx8152/Qwen-Edit-2509-Multiple-angles"adiciona controles de “câmera virtual”.LORA_LIGHTNING = "lightx2v/Qwen-Image-Lightning"é um adaptador de velocidade opcional para visualizações rápidas.
Observação: para o Modo HQ, só o adaptador de ângulos continua ativo.
- Macros angulares:
ANGLE_MACROS mapeia rótulos como “Grande angular” ou “Top-down” para comandos chineses equivalentes que o angles LoRA entende de forma confiável. Esses comandos movem a câmera virtual (movimentação/rotação/zoom) de forma consistente, sem alterar a identidade. - Predefinições de fundo:
BACKGROUND_PRESETS são pequenos trechos em inglês, tipo “superfície de mármore”, “estúdio cinza suave”, que juntamos na sugestão final. Elas são ortogonais às macros de ângulo e são responsáveis por controlar a cena. - Proporções (
ASPECT_RATIOS): Isso nos permite criar telas (1:1, 4:3, 16:9, etc.) e redimensionar ou recortar o centro da entrada antes da inferência, para que as saídas não precisem de recorte pós-geração.
Agora temos a GPU e os adaptadores configurados. Vamos instanciar o pipeline Diffusers e conectar os LoRAs em seguida.
Passo 3.2: Pipeline
Depois, carregamos o pipeline básico do Qwen Edit, ativamos as otimizações de memória de acordo com a GPU e empilhamos o Multiple-Angles LoRA. Também implementamos uma mudança de modo para adicionar opcionalmente o Lightning LoRA para visualizações rápidas.
pipe = QwenImageEditPlusPipeline.from_pretrained(
HF_BASE_MODEL,
torch_dtype=gpu_config['dtype'],
)
pipe = pipe.to(gpu_config['device'])
if gpu_config['enable_attention_slicing']:
pipe.enable_attention_slicing()
if gpu_config['enable_vae_slicing']:
pipe.enable_vae_slicing()
pipe.load_lora_weights(LORA_ANGLES, adapter_name="angles")
current_mode = {"fast": False}
def set_pipeline_mode(use_lightning: bool):
global current_mode
if use_lightning and not current_mode["fast"]:
pipe.load_lora_weights(LORA_LIGHTNING, adapter_name="lightning")
pipe.set_adapters(["angles", "lightning"], adapter_weights=[1.0, 1.0])
current_mode["fast"] = True
elif not use_lightning and current_mode["fast"]:
pipe.set_adapters(["angles"], adapter_weights=[1.0])
current_mode["fast"] = False
elif not use_lightning and not current_mode["fast"]:
pipe.set_adapters(["angles"], adapter_weights=[1.0])
set_pipeline_mode(False)O código acima é a camada de configuração do pipeline para o aplicativo Product Shot Booster, que faz o seguinte:
- Inicialização do pipeline: Ele instancia o
QwenImageEditPlusPipelinea partir do modelo base (Qwen/Qwen-Image-Edit-2509), move-o para o dispositivo detectado (CPU/GPU) e define a precisão do tensor (torch_dtype) com base no seu hardware. - Segurança da memória: Em GPUs menores, permite que a atenção e o corte VAE reduzam o pico de VRAM e evitem erros de memória insuficiente, trocando um pouco de velocidade por estabilidade.
- Composição LoRA: Ele carrega o LoRA de múltiplos ângulos para fornecer controles repetíveis de “câmera virtual” (mover/girar/zoom) e, opcionalmente, combina o LoRA Lightning para visualizações mais rápidas.
- Lógica de mudança de modo: A função auxiliar
set_pipeline_mode()e um sinalizadorcurrent_modegerenciam os estados HQ e Fast, evitando recargas redundantes do Lightning e permitindo que você alterne adaptadores.
Agora o pipeline está pronto. Vamos passar para as funções de geração de fiação e a interface do usuário do Gradio.
Passo 4: Funções de geração
As funções de geração geram energia criando prompts, redimensionando para a proporção desejada, executando o pipeline em ângulos selecionados e empacotando os resultados para download em um arquivo zip.
Passo 4.1: Prompt Composer e auxiliares de redimensionamento de imagens
Antes de chamarmos o modelo, normalizamos as entradas com dois auxiliares sem estado:
compose_prompt()função: Essa função junta uma única sequência de instruções a partir do ângulo da câmera, predefinição de fundo, cena personalizada e notas de estilo. Cláusulas curtas ajudam a manter a análise das instruções do Qwen estável e evitam dar peso demais a qualquer parte.resize_image()função: Ele ajusta a imagem original à proporção desejada usando uma estratégia de escala para cobertura, a reamostragem Lanczos ajuda com o redimensionamento para cima/baixo de alta qualidade e um recorte central para que o assunto principal fique no enquadramento.
def compose_prompt(angle_phrase: str,
bg_preset_text: Optional[str],
custom_scene: str,
extra_style: str) -> str:
parts = [angle_phrase]
if bg_preset_text:
parts.append(f"{bg_preset_text}")
if custom_scene.strip():
parts.append(custom_scene.strip())
if extra_style.strip():
parts.append(extra_style.strip())
return " | ".join(parts)
def resize_image(img: Image.Image, target_size: Tuple[int, int]) -> Image.Image:
target_w, target_h = target_size
orig_w, orig_h = img.size
scale = max(target_w / orig_w, target_h / orig_h)
new_w = int(orig_w * scale)
new_h = int(orig_h * scale)
img = img.resize((new_w, new_h), Image.Resampling.LANCZOS)
left = (new_w - target_w) // 2
top = (new_h - target_h) // 2
img = img.crop((left, top, left + target_w, top + target_h))
return imgAs duas funções acima fazem o seguinte:
- Prompt composable: A gente junta as partes com “|” pra manter as cláusulas visualmente distintas, enquanto o Qwen-Edit cuida da pontuação e faz uma análise consistente sem favorecer a última cláusula. Também usamos
.strip()com texto do usuário para evitar fragmentos vazios. - Matemática de escala para cobertura: Isso garante que a imagem redimensionada cubra totalmente a tela de destino em ambas as dimensões.
- Reamostragem de Lanczos: É um filtro de alta qualidade que mantém os detalhes finos quando reduz a resolução e diminui o aliasing quando aumenta a resolução.
- Corte central: Depois de redimensionar, recortamos a tela exata do centro para manter a composição típica e evitar cortes fora do centro inesperados.
Com os auxiliares prontos, agora podemos executar um loop de geração de múltiplos ângulos e empacotar os resultados.
Passo 4.2: Gerar imagens
Depois, a gente valida as entradas, ajusta a imagem ao aspecto escolhido, faz um loop sobre os ângulos selecionados e executa o pipeline em inference_mode. Por fim, a gente devolve um arquivo zip com todas as imagens geradas.
def generate_images(
source_img: Image.Image,
angle_keys: List[str],
bg_key: str,
custom_scene: str,
extra_style: str,
aspect_ratio: str,
use_lightning: bool,
seed: int,
steps: int,
guidance_scale: float,
true_cfg_scale: float,
images_per_prompt: int,
progress=gr.Progress()
) -> List[Image.Image]:
if source_img is None:
return [], "WARNING: Please upload an image first!"
if not angle_keys:
return [], "WARNING: Please select at least one angle!"
target_size = ASPECT_RATIOS[aspect_ratio]
source_img = resize_image(source_img, target_size)
set_pipeline_mode(use_lightning)
results = []
generator = torch.manual_seed(seed)
bg_preset_text = BACKGROUND_PRESETS.get(bg_key)
total_angles = len(angle_keys)
for idx, angle_name in enumerate(angle_keys):
progress((idx + 1) / total_angles, f"Generating {angle_name}...")
angle_phrase = ANGLE_MACROS[angle_name]
full_prompt = compose_prompt(angle_phrase, bg_preset_text, custom_scene, extra_style)
inputs = {
"image": [source_img],
"prompt": full_prompt,
"generator": generator,
"true_cfg_scale": true_cfg_scale,
"negative_prompt": " ",
"num_inference_steps": steps,
"guidance_scale": guidance_scale,
"num_images_per_prompt": images_per_prompt,
"height": target_size[1],
"width": target_size[0],
}
with torch.inference_mode():
out = pipe(**inputs)
for img_idx, im in enumerate(out.images):
results.append(im)
if 'T4' in gpu_config['gpu_name']:
torch.cuda.empty_cache()
return results
def create_zip(images: List[Image.Image]) -> Optional[str]:
if not images:
return None
zip_path = "/content/product_shot_booster.zip"
with zipfile.ZipFile(zip_path, mode="w", compression=zipfile.ZIP_DEFLATED) as zf:
zf.writestr("manifest.txt", "Product Shot Booster Export\nGenerated angles exported as PNG files.\n")
for idx, img in enumerate(images):
buf = io.BytesIO()
img.save(buf, format="PNG")
zf.writestr(f"angle_{idx+1:03d}.png", buf.getvalue())
return zip_pathA função generate_images() faz a geração e exportação de múltiplos ângulos por meio de:
- Validar, normalizar e configurar: Ele verifica se há uma imagem carregada e ângulos selecionados, depois ajusta a imagem ao aspecto escolhido (redimensiona e centraliza o recorte) e alterna entre os modos HQ e Rápido através de
set_pipeline_mode(use_lightning). - Inferência eficiente: Para cada ângulo, ele cria uma única sequência de instruções que inclui macro de ângulo, predefinição de fundo, cena e estilo. Em seguida, prepara as entradas dos difusores e executa sob
torch.inference_mode()para economizar memória. Em GPUs com pouca VRAM (como uma T4), chamadas comotorch.cuda.empty_cache()por ângulo ajudam a reduzir a fragmentação. - Resultados agregados com feedback da interface do usuário: Ele finalmente atualiza o progresso do Gradio conforme cada ângulo é concluído e junta todos os resultados em uma lista atualiza o progresso do Gradio à medida que cada ângulo é concluído e reúne todas as saídas em uma lista para compactação downstream.
A função create_zip(images) oferece uma exportação portátil que grava um arquivo zip com um breve manifest.txtjunto com imagens codificadas via in-memory (BytesIO) para arquivos sem perdas e retorna None se não houver imagens.
Com a geração e a embalagem finalizadas, a interface do usuário pode acionar uma passagem multi-ângulo e oferecer um download com um clique do pacote de ângulos completo.
Passo 5: Interface do usuário do Gradio
Essa interface permite que os usuários enviem uma imagem do produto, escolham ângulos e proporções, selecionem uma predefinição de fundo, definam notas de estilo e criem imagens com vários ângulos na hora.
with gr.Blocks(title="Product Shot Booster", theme=gr.themes.Soft()) as demo:
gr.Markdown("<h1 style='text-align: center;font-weight: bold;'>Product Shot Booster</h1>")
with gr.Row():
with gr.Column(scale=1):
input_image = gr.Image(
label="Product Image",
type="pil",
height=300
)
angle_choices = gr.CheckboxGroup(
choices=list(ANGLE_MACROS.keys()),
value=["Wide-angle", "Close-up", "Rotate 45° Left", "Rotate 45° Right", "Top-down"],
label="Camera Angles"
)
aspect_ratio = gr.Dropdown(
choices=list(ASPECT_RATIOS.keys()),
value="1:1 (Square)",
label="Aspect Ratio"
)
bg_preset = gr.Dropdown(
choices=list(BACKGROUND_PRESETS.keys()),
value="(None)",
label="Background"
)
custom_scene = gr.Textbox(
label="Custom Scene",
placeholder="e.g., 'on a matte black table with soft reflections'",
lines=2
)
extra_style = gr.Textbox(
label="Style Notes",
value="studio-grade lighting, high clarity, ecommerce-ready composition",
lines=2
)
with gr.Column(scale=2):
output_gallery = gr.Gallery(
label="Generated Images",
show_label=True,
columns=3,
height="auto",
object_fit="contain"
)
info_output = gr.Markdown("")
zip_output = gr.File(label="Download ZIP")
with gr.Accordion("Advanced Settings", open=False):
with gr.Row():
use_lightning = gr.Checkbox(
label="Fast Mode (Lightning LoRA)",
value=('T4' in gpu_config['gpu_name']),
info="Enable for faster generation (recommended for T4)"
)
seed = gr.Number(
label="Seed",
value=123,
precision=0
)
steps = gr.Slider(
label="Inference Steps",
minimum=10,
maximum=60,
value=28,
step=1
)
with gr.Row():
guidance_scale = gr.Slider(
label="Guidance Scale",
minimum=0.0,
maximum=8.0,
value=1.0,
step=0.1
)
true_cfg_scale = gr.Slider(
label="True CFG Scale",
minimum=0.0,
maximum=10.0,
value=4.0,
step=0.1
)
images_per_prompt = gr.Slider(
label="Images per Angle",
minimum=1,
maximum=4,
value=1,
step=1
)
generate_btn = gr.Button("Generate", variant="primary", size="lg")
def generate_and_zip(*args):
images = generate_images(*args)
zip_file = create_zip(images) if images else None
return images, zip_file
generate_btn.click(
fn=generate_and_zip,
inputs=[
input_image,
angle_choices,
bg_preset,
custom_scene,
extra_style,
aspect_ratio,
use_lightning,
seed,
steps,
guidance_scale,
true_cfg_scale,
images_per_prompt
],
outputs=[output_gallery, zip_output]
)
demo.launch(share=True, debug=True, show_error=True)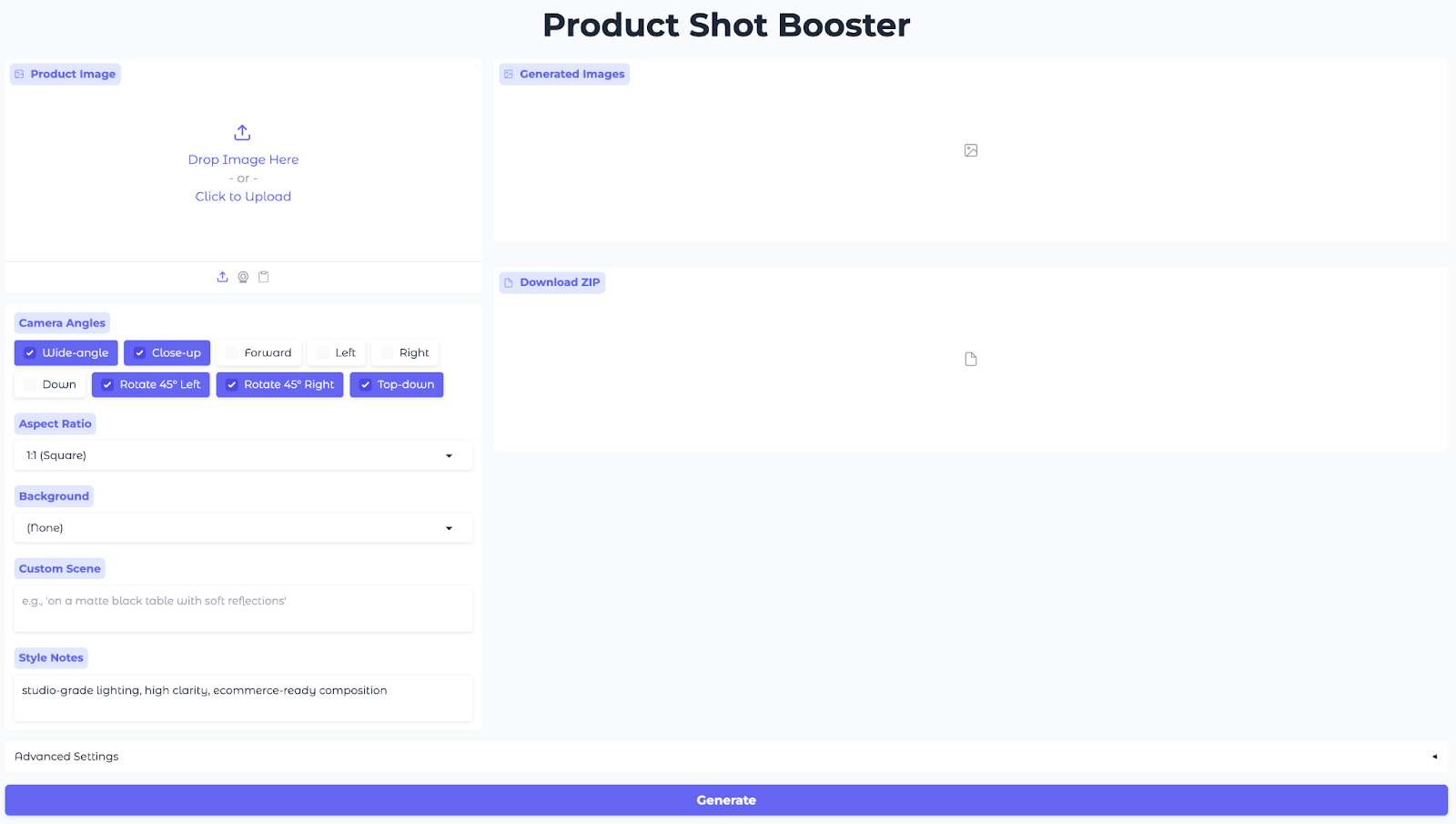
O código acima cria um aplicativo Gradio interativo que conecta uma única ação de geração à inferência e mostra uma interface de usuário da web que pode ser compartilhada, usando:
- Entradas (coluna esquerda): O painel esquerdo junta tudo o que o modelo precisa usando um campo “
gr.Image” (Upload de foto do produto) para carregar a foto do produto, um campo “gr.CheckboxGroup” (Upload de foto da câmera) para ângulos de câmera, dois campos “gr.Dropdowns” (Upload de foto de fundo) para proporção da imagem e predefinições de fundo e dois campos “gr.Textbox” (Upload de foto de cena) para cena personalizada e notas de estilo para ajustar o visual. - Resultados (coluna da direita): Um método
gr.Gallerymostra todos os ângulos gerados em uma grade para que você possa comparar as composições rapidamente, e um componentegr.Fileoferece ZIP de PNGs para download rápido. - Configurações avançadas: A opção “
gr.Checkbox” (Modo rápido) ativa o Modo Rápido (Lightning LoRA) para visualizações rápidas em GPUs da classe T4, enquanto as opções “Seed” (Semente) e “Steps” (Passos) ajustam a reprodutibilidade e o equilíbrio entre qualidade e tempo. As opções “Guidance” (Seleção de pontos de controle) e “True-CFG” (Seleção de pontos de controle) controlam a intensidade da edição em relação à estabilidade da identidade, e a opção “Images per Angle” (Seleção de pontos de controle) permite produzir várias variantes por macro da câmera de uma só vez. - Fiação da interface (ação): Um único botão“Gerar” ( ) conecta todas as entradas a uma função“Gerar galeria” (
generate_images()) (que executa o Qwen Edit com os adaptadores selecionados) e, em seguida, a uma função “Gerar ZIP” (create_zip()) (que empacota as saídas), devolvendo a galeria e o ZIP à interface. - Lançamento do aplicativo: Por fim, o método `
demo.launch()` inicia o aplicativo web e fornece uma URL pública compartilhável — perfeita para sessões do Colab, demonstrações rápidas ou para enviar aos interessados um link para que eles mesmos experimentem a ferramenta.
Por fim, clique em Gerar e veja a renderização do pacote em ângulo completo.
Aqui estão os resultados das minhas experiências com esse modelo. Primeiro, dá pra ver como os produtos são mostrados com base nos diferentes parâmetros definidos.

