Los vendedores individuales y las marcas pequeñas rara vez disponen del presupuesto necesario para realizar una sesión fotográfica completa del producto. En esta guía, crearemos y ejecutaremos una aplicación Gradio que transforma una sola imagen de entrada en representaciones de productos desde múltiples ángulos (amplio, macro, ±45°, desde arriba) listas para el comercio electrónico, utilizando Qwen-Image-Edit-2509 con controles de cámara virtual basados en LoRA para obtener fotografías de productos reproducibles mediante IA.
Bajo el capó, utilizamos:
- Modelo básico:
Qwen/Qwen-Image-Edit-2509(Apache-2.0) - Control del ángulo LoRA:
dx8152/Qwen-Edit-2509-Multiple-angles - Velocidad opcional LoRA:
lightx2v/Qwen-Image-Lightning
En este tutorial, aprenderás a:
- Carga el canal de edición Qwen y apila varios LoRA.
- Mueve la cámara con macros de ángulo robustas.
- Crea una interfaz de usuario Gradio limpia para creadores y equipos de comercio electrónico.
- Exporta todos los resultados en un archivo ZIP para facilitar su entrega.
Si deseas obtener más información sobre cómo se procesan los datos de imagen en el aprendizaje profundo, consulta la programa de habilidades Procesamiento de imágenes en Python.
¿Por qué utilizar Qwen Image Edit con múltiples ángulos LoRA?
Qwen-Image-Edit-2509 es la última versión del modelo de edición de imágenes de Qwen, con una mayor coherencia y edición de múltiples imágenes. LoRA de múltiples ángulos inyecta controles fiables de «cámara virtual» para que puedas decir:
- Cambia el objetivo a gran angular (turn to wide-angle).
- Cambiar a un primer plano (turn to close-up)
- Gira la lente 45 grados hacia la izquierda (rotate 45° left).
- Cambiar la cámara a vista superior (top-down view)
Estos comandos reformulan constantemente el mismo producto sin dar la impresión de que se trata de un producto nuevo.
Tutorial paso a paso para editar imágenes con Qwen: Creación de un potenciador de fotografías de productos
En esta guía, crearemos una aplicación que transforma una sola imagen de producto en un conjunto de ángulos listos para el estudio (incluidos ángulos como gran angular, primer plano, 45° izquierda/derecha y vista superior), con ajustes preestablecidos opcionales de estilo de vida y modo de vista previa rápida. Utiliza un model Qwen/Qwen-Image-Edit-2509 y un Multiple-Angles LoRA integrados en una interfaz de usuario Gradio.
Pasaremos de la configuración del entorno a la carga de modelos, los ayudantes de generación y una interfaz de usuario web.
Paso 1: Requisitos previos
En primer lugar, instala todas las dependencias de tiempo de ejecución. Utilizamos PyTorch con CUDA wheels, herramientas Hugging Face, la biblioteca Diffusers, Gradio para la interfaz de usuario y Pillow/OpenCV para el manejo de imágenes.
pip install -q torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install -q transformers>=4.44.0 accelerate>=0.33.0 safetensors>=0.4.3
pip install -q pillow>=10.2.0 huggingface_hub>=0.24.0 opencv-python-headless>=4.9.0.80
pip install -q numpy>=1.26.0 gradio>=4.0.0
pip install -q git+https://github.com/huggingface/diffusersA continuación se explica la función de cada requisito previo:
- Ruedas CUDA: La línea PyTorch apunta a las ruedas NVIDIA CUDA 12.1 para la aceleración de la GPU.
- Transformadores y difusores: Transformers gestiona las configuraciones y los tokenizadores, mientras que Diffusers proporciona el procesamiento de texto (
QwenImageEditPlusPipeline). - Safetensors: Proporcionan un formato tensor seguro (más rápido y seguro que Pickle).
- OpenCV-headless y Pillow: Proporciona una sólida entrada/salida de imágenes y cambio de tamaño para el preprocesamiento y posprocesamiento.
- Gradio: Es una interfaz de usuario web rápida que funciona localmente y en Colab.
Una vez preparado el entorno, podemos autenticarnos en Hugging Face (opcional) y cargar los modelos.
Paso 2: Autenticación Hugging Face
Algunos modelos o adaptadores pueden requerir autenticación por parte de HuggingFace. Este paso te permite iniciar sesión una vez para la sesión.
from huggingface_hub import login
import os
HF_TOKEN = "Your_HF_Token" # @param {type:"string"}
if HF_TOKEN:
login(token=HF_TOKEN)
print("Logged in to Hugging Face")
else:
print("WARNING: No token provided. Continuing without authentication")Empieza por iniciar sesión en tu cuenta de HuggingFace y busca los tokens de acceso en la configuración de tu cuenta. Haz clic en Crear nuevo token y genera un nuevo token con el tipo de token Leer. Selecciona los permisos necesarios y genera un nuevo token.
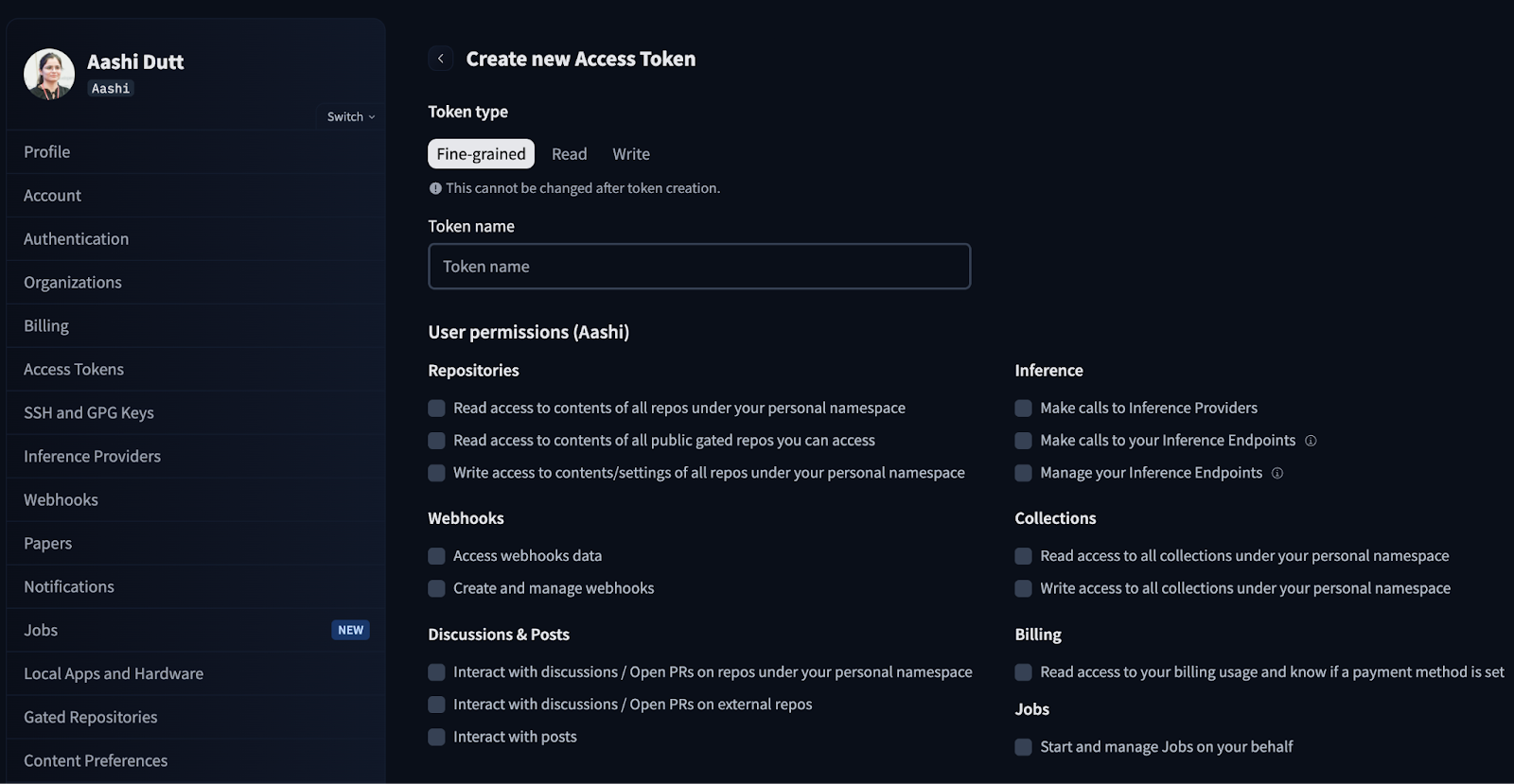
En producción/Colab, no codifiques tokens de forma rígida, sino que utiliza variables de entorno o «secretos» de Colab.
Paso 3: Cargar modelo y configurar canalización
En esta sección, configuraremos el proceso Qwen-Image-Edit, cargaremos los ángulos LoRA y añadiremos un conmutador rápido con ajustes compatibles con GPU. Ten en cuenta que este código se ejecuta de manera eficiente en una GPU A100 con mucha RAM.
Paso 3.1: Importaciones y configuración de la GPU
Ahora, importaremos las bibliotecas principales y detectaremos la GPU para configurar automáticamente la precisión, el corte de atención y el corte VAE para garantizar la estabilidad.
import io
import zipfile
from typing import List, Tuple, Optional
import gc
import torch
from PIL import Image
from diffusers import QwenImageEditPlusPipeline
import gradio as gr
def get_gpu_config():
if not torch.cuda.is_available():
return {
'device': 'cpu',
'dtype': torch.float32,
'gpu_name': 'CPU',
'vram_gb': 0,
'max_batch': 1,
'enable_attention_slicing': True,
'enable_vae_slicing': True,
}
gpu_name = torch.cuda.get_device_name(0)
vram_gb = torch.cuda.get_device_properties(0).total_memory / 1e9
if 'T4' in gpu_name or vram_gb < 20:
return {
'device': 'cuda',
'dtype': torch.bfloat16,
'gpu_name': gpu_name,
'vram_gb': vram_gb,
'max_batch': 1,
'enable_attention_slicing': True,
'enable_vae_slicing': True,
}
else:
return {
'device': 'cuda',
'dtype': torch.bfloat16,
'gpu_name': gpu_name,
'vram_gb': vram_gb,
'max_batch': 2,
'enable_attention_slicing': False,
'enable_vae_slicing': False,
}
gpu_config = get_gpu_config()
HF_BASE_MODEL = "Qwen/Qwen-Image-Edit-2509"
LORA_ANGLES = "dx8152/Qwen-Edit-2509-Multiple-angles"
LORA_LIGHTNING = "lightx2v/Qwen-Image-Lightning"
ANGLE_MACROS = {
"Wide-angle": "将镜头转为广角镜头",
"Close-up": "将镜头转为特写镜头",
"Forward": "将镜头向前移动",
"Left": "将镜头向左移动",
"Right": "将镜头向右移动",
"Down": "将镜头向下移动",
"Rotate 45° Left": "将镜头向左旋转45度",
"Rotate 45° Right": "将镜头向右旋转45度",
"Top-down": "将镜头转为俯视",
}
BACKGROUND_PRESETS = {
"(None)": None,
"Pure Studio (white seamless)": "in a professional studio with seamless white background, soft shadows, product centered",
"Soft Gray Studio": "in a professional studio with seamless soft gray background, gentle vignette, softbox lighting",
"Lifestyle (cozy desk)": "on a cozy wooden desk near a window, soft natural light, minimal props",
"Lifestyle (marble)": "on a clean white marble surface, bright daylight, subtle reflections",
"Lifestyle (outdoor)": "outdoors on a neutral table, soft shade, bokeh background",
}
ASPECT_RATIOS = {
"1:1 (Square)": (1024, 1024),
"4:3 (Standard)": (1024, 768),
"3:4 (Portrait)": (768, 1024),
"16:9 (Widescreen)": (1024, 576),
"9:16 (Mobile)": (576, 1024),
"3:2 (Photo)": (1024, 683),
"2:3 (Portrait Photo)": (683, 1024),
}Estos son los componentes clave de los bloques de código anteriores:
- Configuración automática de la GPU (función
get_gpu_config): Detectamos el acelerador disponible y devolvemos un pequeño diccionario de configuración que se utiliza para elegir el dispositivo (CPU/CUDA), el tipo de datos (como bfloat16 en la GPU) y los comportamientos de la memoria: - En la CPU, utilizamos float32 de forma predeterminada y habilitamos el corte de atención/VAE por seguridad.
- En T4 / <20 GB de VRAM, mantenemos bfloat16 pero habilitamos el corte para evitar OOM.
- En GPU de más de 20 GB (como A100), desactivamos el corte y permitimos lotes más grandes para ganar velocidad.
- Identificadores de modelo y adaptadores: Cargamos
Qwen-Image-Edit-2509como editor principal, junto con LoRA de múltiples ángulos para el control de la cámara, y opcionalmente combinamos Lightning LoRA cuando se activa el modo rápido. modo rápido. HF_BASE_MODEL = "Qwen/Qwen-Image-Edit-2509"es la columna vertebral principal de la edición de imágenes.LORA_ANGLES = "dx8152/Qwen-Edit-2509-Multiple-angles"añade controles de «cámara virtual».LORA_LIGHTNING = "lightx2v/Qwen-Image-Lightning"es un adaptador de velocidad opcional para previsualizaciones rápidas.
Nota: para modo HQ, solo el adaptador de ángulos permanece activo.
- Macros angulares:
ANGLE_MACROS asigna etiquetas como «Gran angular» o «Desde arriba» a comandos equivalentes en chino que LoRA entiende de forma fiable. Estos comandos mueven constantemente la cámara virtual (mover/girar/acercar/alejar) sin cambiar la identidad. - Ajustes preestablecidos de fondo:
BACKGROUND_PRESETS son fragmentos cortos en inglés como «marble surface» (superficie de mármol) o «soft gray studio» (estudio gris suave) que se fusionan en la indicación final. Son ortogonales a las macros de ángulo y se encargan de controlar la escena. - Relaciones de aspecto (
ASPECT_RATIOS): Esto nos permite generar lienzos (1:1, 4:3, 16:9, etc.) y cambiar el tamaño o recortar al centro la entrada antes de la inferencia, de modo que las salidas no necesiten un recorte posterior a la generación.
Ahora tenemos la GPU y los adaptadores configurados. Instanciemos el pipeline Diffusers y conectemos los LoRA a continuación.
Paso 3.2: Tubería
A continuación, cargamos el pipeline base Qwen Edit, habilitamos las optimizaciones de memoria según la GPU y apilamos el LoRA de ángulos múltiples. También implementamos un cambio de modo para añadir opcionalmente Lightning LoRA para obtener vistas previas rápidas.
pipe = QwenImageEditPlusPipeline.from_pretrained(
HF_BASE_MODEL,
torch_dtype=gpu_config['dtype'],
)
pipe = pipe.to(gpu_config['device'])
if gpu_config['enable_attention_slicing']:
pipe.enable_attention_slicing()
if gpu_config['enable_vae_slicing']:
pipe.enable_vae_slicing()
pipe.load_lora_weights(LORA_ANGLES, adapter_name="angles")
current_mode = {"fast": False}
def set_pipeline_mode(use_lightning: bool):
global current_mode
if use_lightning and not current_mode["fast"]:
pipe.load_lora_weights(LORA_LIGHTNING, adapter_name="lightning")
pipe.set_adapters(["angles", "lightning"], adapter_weights=[1.0, 1.0])
current_mode["fast"] = True
elif not use_lightning and current_mode["fast"]:
pipe.set_adapters(["angles"], adapter_weights=[1.0])
current_mode["fast"] = False
elif not use_lightning and not current_mode["fast"]:
pipe.set_adapters(["angles"], adapter_weights=[1.0])
set_pipeline_mode(False)El código anterior es la capa de configuración del proceso para la aplicación Product Shot Booster, que realiza las siguientes funciones:
- Inicialización del canal: Instancia el modelo de red neuronal convolucional (
QwenImageEditPlusPipeline) desde el modelo base (Qwen/Qwen-Image-Edit-2509), lo traslada al dispositivo detectado (CPU/GPU) y establece la precisión del tensor (torch_dtype) en función de tu hardware. - Seguridad de la memoria: En GPU más pequeñas, permite reducir el pico de VRAM y evitar errores de memoria insuficiente mediante la atención y el corte VAE, a cambio de una pequeña pérdida de velocidad a cambio de estabilidad.
- Composición de LoRA: Carga el LoRA de múltiples ángulos para proporcionar controles repetibles de «cámara virtual» (mover/girar/acercar) y, opcionalmente, combina el LoRA Lightning para obtener vistas previas más rápidas.
- Lógica de cambio de modo: La función auxiliar «
set_pipeline_mode()» y el indicador «current_mode» gestionan los estados HQ y Fast, lo que evita recargas redundantes de Lightning y te permite cambiar de adaptador.
Ahora la tubería está lista. Pasemos ahora a las funciones de generación de cableado y a la interfaz de usuario de Gradio.
Paso 4: Funciones de generación
Las funciones de generación generan energía mediante la creación de indicaciones, el cambio de tamaño a la relación de aspecto deseada, la ejecución del proceso en los ángulos seleccionados y el empaquetado de los resultados para su descarga en un archivo zip.
Paso 4.1: Prompt Composer y Image Resize Helpers
Antes de invocar el modelo, normalizamos las entradas con dos ayudantes sin estado:
compose_prompt()función: Esta función reúne una única cadena de instrucciones a partir del ángulo de la cámara, el fondo preestablecido, la escena personalizada y las notas de estilo. Las cláusulas concisas ayudan a mantener estable el análisis sintáctico de las instrucciones de Qwen y evitan sobrevalorar ninguna parte.resize_image()función: Ajusta la imagen original a la relación de aspecto deseada utilizando una estrategia de escalado para cubrir, el remuestreo Lanczos ayuda a obtener una alta calidad al reducir o ampliar la imagen, y un recorte central para que el sujeto principal permanezca en el encuadre.
def compose_prompt(angle_phrase: str,
bg_preset_text: Optional[str],
custom_scene: str,
extra_style: str) -> str:
parts = [angle_phrase]
if bg_preset_text:
parts.append(f"{bg_preset_text}")
if custom_scene.strip():
parts.append(custom_scene.strip())
if extra_style.strip():
parts.append(extra_style.strip())
return " | ".join(parts)
def resize_image(img: Image.Image, target_size: Tuple[int, int]) -> Image.Image:
target_w, target_h = target_size
orig_w, orig_h = img.size
scale = max(target_w / orig_w, target_h / orig_h)
new_w = int(orig_w * scale)
new_h = int(orig_h * scale)
img = img.resize((new_w, new_h), Image.Resampling.LANCZOS)
left = (new_w - target_w) // 2
top = (new_h - target_h) // 2
img = img.crop((left, top, left + target_w, top + target_h))
return imgLas dos funciones anteriores realizan las siguientes tareas:
- Mensaje configurable: Unimos las partes con « | » para mantener las cláusulas visualmente diferenciadas, mientras que Qwen-Edit se encarga de la puntuación y produce un análisis coherente sin sesgar hacia la última cláusula. También utilizamos
.strip()con texto de usuario para evitar fragmentos vacíos. - Matemáticas de escala para cubrir: Esto garantiza que la imagen redimensionada cubra completamente el lienzo de destino en ambas dimensiones.
- Lanczos resampling: Es un filtro de alta calidad que conserva los detalles más precisos al reducir la resolución y reduce el aliasing al aumentar la resolución.
- Recorte central: Después de cambiar el tamaño, recortamos el lienzo objetivo exacto desde el centro para conservar la composición típica y evitar recortes descentrados inesperados.
Con los ayudantes listos, ahora podemos ejecutar un bucle de generación multiángulo y empaquetar los resultados.
Paso 4.2: Generar imágenes
A continuación, validamos las entradas, ajustamos la imagen al aspecto elegido, recorremos los ángulos seleccionados y ejecutamos el proceso en inference_mode. Por último, devolvemos un archivo zip con todas las imágenes generadas.
def generate_images(
source_img: Image.Image,
angle_keys: List[str],
bg_key: str,
custom_scene: str,
extra_style: str,
aspect_ratio: str,
use_lightning: bool,
seed: int,
steps: int,
guidance_scale: float,
true_cfg_scale: float,
images_per_prompt: int,
progress=gr.Progress()
) -> List[Image.Image]:
if source_img is None:
return [], "WARNING: Please upload an image first!"
if not angle_keys:
return [], "WARNING: Please select at least one angle!"
target_size = ASPECT_RATIOS[aspect_ratio]
source_img = resize_image(source_img, target_size)
set_pipeline_mode(use_lightning)
results = []
generator = torch.manual_seed(seed)
bg_preset_text = BACKGROUND_PRESETS.get(bg_key)
total_angles = len(angle_keys)
for idx, angle_name in enumerate(angle_keys):
progress((idx + 1) / total_angles, f"Generating {angle_name}...")
angle_phrase = ANGLE_MACROS[angle_name]
full_prompt = compose_prompt(angle_phrase, bg_preset_text, custom_scene, extra_style)
inputs = {
"image": [source_img],
"prompt": full_prompt,
"generator": generator,
"true_cfg_scale": true_cfg_scale,
"negative_prompt": " ",
"num_inference_steps": steps,
"guidance_scale": guidance_scale,
"num_images_per_prompt": images_per_prompt,
"height": target_size[1],
"width": target_size[0],
}
with torch.inference_mode():
out = pipe(**inputs)
for img_idx, im in enumerate(out.images):
results.append(im)
if 'T4' in gpu_config['gpu_name']:
torch.cuda.empty_cache()
return results
def create_zip(images: List[Image.Image]) -> Optional[str]:
if not images:
return None
zip_path = "/content/product_shot_booster.zip"
with zipfile.ZipFile(zip_path, mode="w", compression=zipfile.ZIP_DEFLATED) as zf:
zf.writestr("manifest.txt", "Product Shot Booster Export\nGenerated angles exported as PNG files.\n")
for idx, img in enumerate(images):
buf = io.BytesIO()
img.save(buf, format="PNG")
zf.writestr(f"angle_{idx+1:03d}.png", buf.getvalue())
return zip_pathLa función generate_images() implementa la generación y exportación de múltiples ángulos mediante:
- Validar, normalizar y configurar: Comprueba comprueba si hay una imagen cargada y ángulos seleccionados, luego ajusta la imagen al aspecto elegido (cambia el tamaño y recorta al centro) y alterna entre el modo HQ y el modo rápido a través de
set_pipeline_mode(use_lightning). - Inferencia eficiente: Para cada ángulo, crea una única cadena de instrucciones que incluye la macro de ángulo, el ajuste preestablecido de fondo, la escena y el estilo. A continuación, prepara las entradas de los difusores y se ejecuta en
torch.inference_mode()para ahorrar memoria. En GPU con poca VRAM (como una T4), llamadas comotorch.cuda.empty_cache()por ángulo ayudan a reducir la fragmentación. - Resultados agregados con comentarios de la interfaz de usuario: Finalmente actualiza el progreso de Gradio a medida que se completa cada ángulo y recopila todos los resultados en una lista para comprimirlos posteriormente.
La función create_zip(images) proporciona una exportación portátil que escribe un archivo zip con una breve descripción manifest.txtjunto con la codificación de imágenes a través de la memoria (BytesIO) para archivos sin pérdida y devuelve None si no hay imágenes presentes.
Una vez finalizados la generación y el empaquetado, la interfaz de usuario puede activar un pase multángulo y ofrecer la descarga con un solo clic del paquete de ángulos completo.
Paso 5: Interfaz de usuario de Gradio
Esta interfaz de usuario permite a los usuarios subir una imagen del producto, seleccionar ángulos y relaciones de aspecto, elegir un fondo preestablecido, establecer notas de estilo y generar imágenes desde múltiples ángulos sobre la marcha.
with gr.Blocks(title="Product Shot Booster", theme=gr.themes.Soft()) as demo:
gr.Markdown("<h1 style='text-align: center;font-weight: bold;'>Product Shot Booster</h1>")
with gr.Row():
with gr.Column(scale=1):
input_image = gr.Image(
label="Product Image",
type="pil",
height=300
)
angle_choices = gr.CheckboxGroup(
choices=list(ANGLE_MACROS.keys()),
value=["Wide-angle", "Close-up", "Rotate 45° Left", "Rotate 45° Right", "Top-down"],
label="Camera Angles"
)
aspect_ratio = gr.Dropdown(
choices=list(ASPECT_RATIOS.keys()),
value="1:1 (Square)",
label="Aspect Ratio"
)
bg_preset = gr.Dropdown(
choices=list(BACKGROUND_PRESETS.keys()),
value="(None)",
label="Background"
)
custom_scene = gr.Textbox(
label="Custom Scene",
placeholder="e.g., 'on a matte black table with soft reflections'",
lines=2
)
extra_style = gr.Textbox(
label="Style Notes",
value="studio-grade lighting, high clarity, ecommerce-ready composition",
lines=2
)
with gr.Column(scale=2):
output_gallery = gr.Gallery(
label="Generated Images",
show_label=True,
columns=3,
height="auto",
object_fit="contain"
)
info_output = gr.Markdown("")
zip_output = gr.File(label="Download ZIP")
with gr.Accordion("Advanced Settings", open=False):
with gr.Row():
use_lightning = gr.Checkbox(
label="Fast Mode (Lightning LoRA)",
value=('T4' in gpu_config['gpu_name']),
info="Enable for faster generation (recommended for T4)"
)
seed = gr.Number(
label="Seed",
value=123,
precision=0
)
steps = gr.Slider(
label="Inference Steps",
minimum=10,
maximum=60,
value=28,
step=1
)
with gr.Row():
guidance_scale = gr.Slider(
label="Guidance Scale",
minimum=0.0,
maximum=8.0,
value=1.0,
step=0.1
)
true_cfg_scale = gr.Slider(
label="True CFG Scale",
minimum=0.0,
maximum=10.0,
value=4.0,
step=0.1
)
images_per_prompt = gr.Slider(
label="Images per Angle",
minimum=1,
maximum=4,
value=1,
step=1
)
generate_btn = gr.Button("Generate", variant="primary", size="lg")
def generate_and_zip(*args):
images = generate_images(*args)
zip_file = create_zip(images) if images else None
return images, zip_file
generate_btn.click(
fn=generate_and_zip,
inputs=[
input_image,
angle_choices,
bg_preset,
custom_scene,
extra_style,
aspect_ratio,
use_lightning,
seed,
steps,
guidance_scale,
true_cfg_scale,
images_per_prompt
],
outputs=[output_gallery, zip_output]
)
demo.launch(share=True, debug=True, show_error=True)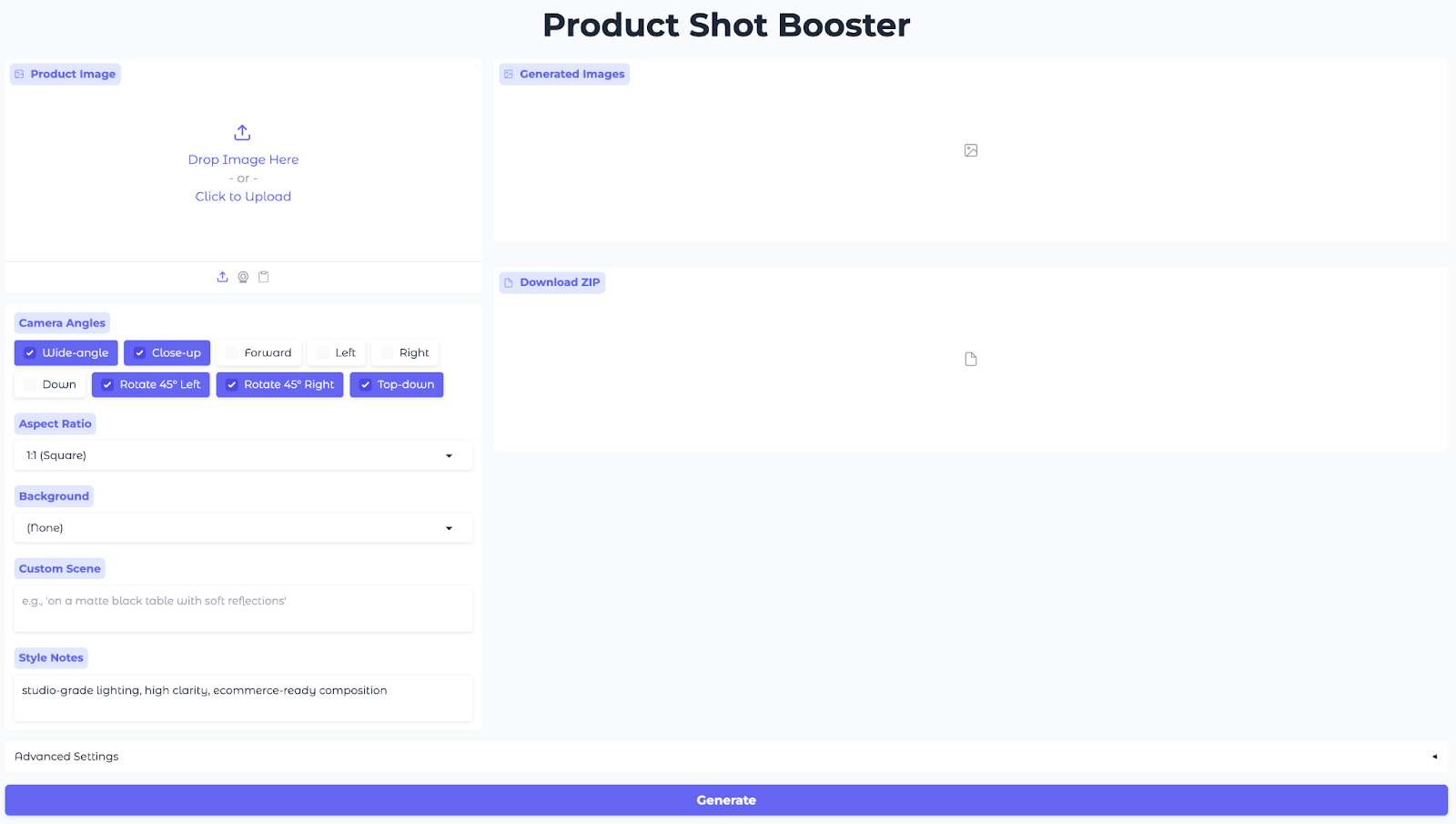
El código anterior crea una aplicación Gradio interactiva que conecta una única acción de generación a la inferencia y expone una interfaz de usuario web compartible, utilizando:
- Entradas (columna izquierda): El panel izquierdo recopila todo lo que necesita el modelo utilizando un campo «
gr.Image» (Imagen de fondo) para cargar la foto del producto, un campo «gr.CheckboxGroup» (Ángulos de cámara) para los ángulos de cámara, dos campos «gr.Dropdowns» (Relación de aspecto y ajustes preestablecidos de fondo) para la relación de aspecto y los ajustes preestablecidos de fondo, y dos campos «gr.Textbox» (Notas de escena y estilo) para ajustar el aspecto. - Resultados (columna derecha): El método «
gr.Gallery» muestra todos los ángulos generados en una parilla para que puedas comparar las composiciones de un vistazo, y el componente «gr.File» ofrece archivos ZIP de PNG para descargarlos rápidamente. - Configuración avanzada:
gr.Checkboxa activa el modo rápido (Lightning LoRA) para obtener vistas previas rápidas en GPU de clase T4, mientras que Seed y Steps ajustan la reproducibilidad y la relación entre calidad y tiempo.GuidanceyTrue-CFGcontrolan la intensidad de la edición frente a la estabilidad de la identidad, yImages per Anglete permite producir múltiples variantes por macro de cámara de una sola vez. - Cableado de la interfaz (acción): Un único botón« » (Generar galería) conecta todas las entradas a la función «
generate_images()» (Generar galería) (que ejecuta Qwen Edit con los adaptadores seleccionados) y, a continuación, a la función «create_zip()» (Generar ZIP) (que empaqueta las salidas), devolviendo tanto la galería como el ZIP a la interfaz. - Lanzamiento de la aplicación: Por último, el método
demo.launch()inicia la aplicación web y proporciona una URL pública para compartir, perfecta para sesiones de Colab, demostraciones rápidas o para enviar a las partes interesadas un enlace para que prueben la herramienta por ustedes mismos.
Por último, pulsa Generar y observa cómo se renderiza un paquete de ángulo completo.
Aquí están los resultados de mis experimentos con este modelo. En primer lugar, puedes ver cómo se muestran los productos en función de los diferentes parámetros establecidos.

